
#NLP #News (by Sebastian Ruder):
* 2020 NLP wish lists
* #HuggingFace + #fastai
* #NeurIPS 2019
* #GPT2 things
* #ML Interviews
blog post: http://newsletter.ruder.io/archive/211277
* 2020 NLP wish lists
* #HuggingFace + #fastai
* #NeurIPS 2019
* #GPT2 things
* #ML Interviews
blog post: http://newsletter.ruder.io/archive/211277
Data Science by ODS.ai 🦜
YouTokenToMe, new tool for text tokenisation from VK team Meet new enhanced tokenisation tool on steroids. Works 7-10 times faster alphabetic languages and 40 to 50 times faster on logographic languages, than alternatives. Under the hood (watch source)…
New rust tokenization library from #HuggingFace
Tokenization is a process of converting strings in model input tensors. Library provides BPE/Byte-Level-BPE/WordPiece/SentencePiece tokenization, computes exhaustive set of outputs (offset mappings, attention masks, special token masks).
Library has python and node.js bindings.
The quoted post contains information on another fast #tokenization implementation. Looking forward for speed comparison.
Install:
Github: https://github.com/huggingface/tokenizers/tree/master/tokenizers
#NLU #NLP #Transformers #Rust #NotOnlyPython
Tokenization is a process of converting strings in model input tensors. Library provides BPE/Byte-Level-BPE/WordPiece/SentencePiece tokenization, computes exhaustive set of outputs (offset mappings, attention masks, special token masks).
Library has python and node.js bindings.
The quoted post contains information on another fast #tokenization implementation. Looking forward for speed comparison.
Install:
pip install tokenizersGithub: https://github.com/huggingface/tokenizers/tree/master/tokenizers
#NLU #NLP #Transformers #Rust #NotOnlyPython
GitHub
tokenizers/tokenizers at main · huggingface/tokenizers
💥 Fast State-of-the-Art Tokenizers optimized for Research and Production - huggingface/tokenizers
{kind=link}
the latest news from :hugging_face_mask:
[0] Helsinki-NLP
With v2.9.1 released 1,008 machine translation models, covering of 140 different languages trained with marian-nmt
link to models: https://huggingface.co/models?search=Helsinki-NLP%2Fopus-mt
[1] updated colab notebook with the new Trainer
colab: https://t.co/nGQxwqwwZu?amp=1
[2] NLP – library to easily share & load data/metrics already providing access to 99+ datasets!
features
– get them all: built-in interoperability with pytorch, tensorflow, pandas, numpy
– simple transparent pythonic API
– strive on large datasets: nlp frees you from RAM memory limits
– smart cache: process once reuse forever
– add your dataset
colab: https://t.co/37pfogRWIZ?amp=1
github: https://github.com/huggingface/nlp
#nlp #huggingface #helsinki #marian #trainer # #data #metrics
[0] Helsinki-NLP
With v2.9.1 released 1,008 machine translation models, covering of 140 different languages trained with marian-nmt
link to models: https://huggingface.co/models?search=Helsinki-NLP%2Fopus-mt
[1] updated colab notebook with the new Trainer
colab: https://t.co/nGQxwqwwZu?amp=1
[2] NLP – library to easily share & load data/metrics already providing access to 99+ datasets!
features
– get them all: built-in interoperability with pytorch, tensorflow, pandas, numpy
– simple transparent pythonic API
– strive on large datasets: nlp frees you from RAM memory limits
– smart cache: process once reuse forever
– add your dataset
colab: https://t.co/37pfogRWIZ?amp=1
github: https://github.com/huggingface/nlp
#nlp #huggingface #helsinki #marian #trainer # #data #metrics
{kind=link}
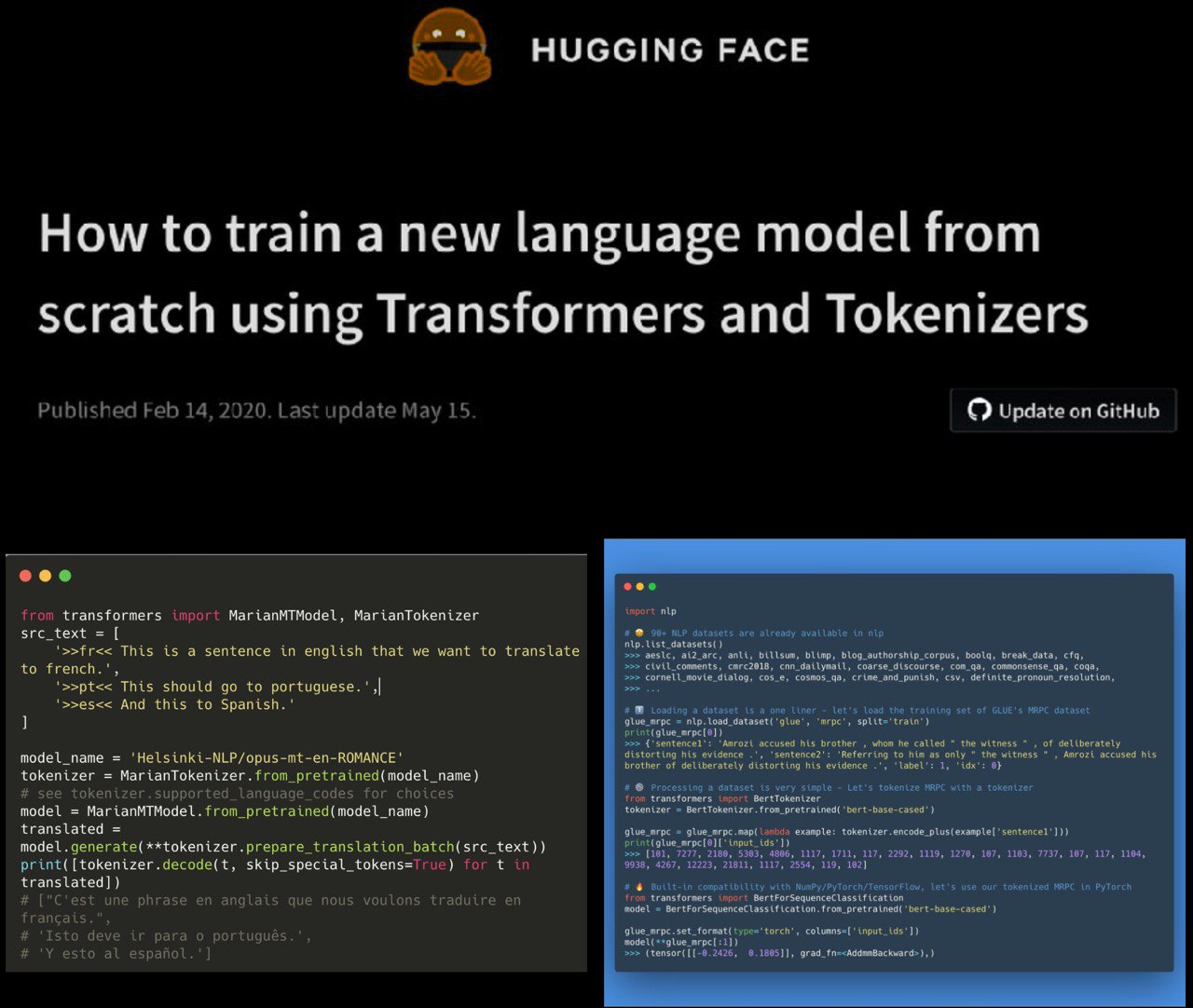
The Reformer – Pushing the limits of language modeling
Patrick von Platen @ huggingface
The Reformer model was introduced by Kitaev, Kaiser et al. `20 – it is one of the most memory-efficient transformer models for long sequence modeling as of today.
The goal of this blog post is to give an in-depth understanding of each of the next four Reformer features:
[0] reformer self-attention layer – how to efficiently implement self-attention without being restricted to a local context?
[1] chunked feed forward layers – how to get a better time-memory trade-off for large feed forward layers?
[2] reversible residual layers – how to drastically reduce memory consumption in training by a smart residual architecture?
[3] axial positional encodings – how to make positional encodings usable for extremely large input sequences?
This long blog post can better allow you to understand how the model works to correctly set configurations
blog post: https://huggingface.co/blog/reformer
#nlp #reformer #huggingface #transformers
Patrick von Platen @ huggingface
The Reformer model was introduced by Kitaev, Kaiser et al. `20 – it is one of the most memory-efficient transformer models for long sequence modeling as of today.
The goal of this blog post is to give an in-depth understanding of each of the next four Reformer features:
[0] reformer self-attention layer – how to efficiently implement self-attention without being restricted to a local context?
[1] chunked feed forward layers – how to get a better time-memory trade-off for large feed forward layers?
[2] reversible residual layers – how to drastically reduce memory consumption in training by a smart residual architecture?
[3] axial positional encodings – how to make positional encodings usable for extremely large input sequences?
This long blog post can better allow you to understand how the model works to correctly set configurations
blog post: https://huggingface.co/blog/reformer
#nlp #reformer #huggingface #transformers
huggingface.co
The Reformer - Pushing the limits of language modeling
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
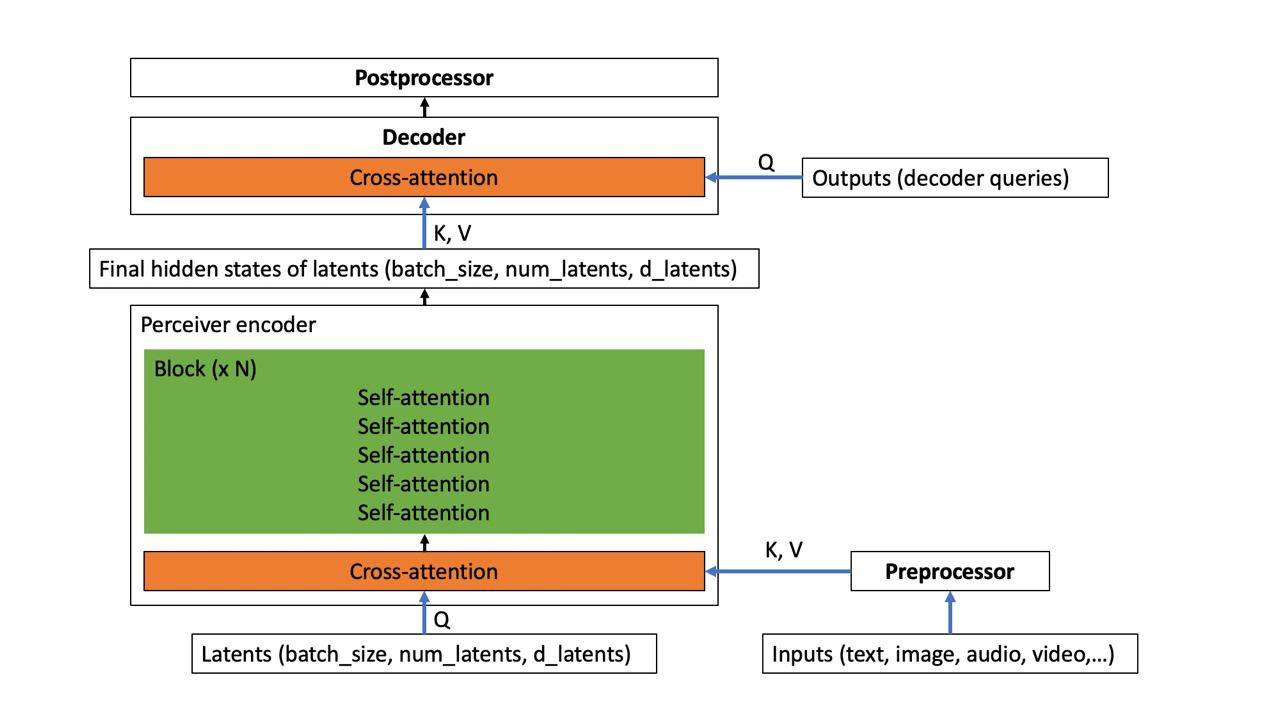
Perceiver IO: a scalable, fully-attentional model that works on any modality
#HuggingFace added neural network which is capable of working on all kinds of modailities: text, images, audio, video, coordinates, etc to the transformers library.
Blog: https://huggingface.co/blog/perceiver
#HuggingFace added neural network which is capable of working on all kinds of modailities: text, images, audio, video, coordinates, etc to the transformers library.
Blog: https://huggingface.co/blog/perceiver
{kind=link}
👍4❤1🔥1🤔1
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://yangx.top/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://yangx.top/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
👍56🔥15❤6🥰2😁2🎉2⚡1👎1👏1
Data Science by ODS.ai 🦜
Some stats to get the perspective of the development of #dalle «Used 1000 prompts in Dalle over the last 2 days, about 9 hours each day. Of those, saved ~300. 50 I like enough to share w/ socials. 12 enough to rework for future projects. 3 were perfect,…
Tips & Tricks on Image Generation
Generating images with AI tools is a skill, which can be improved and enhanced. So here is couple of articles, covering tips & tricks on how to generate better images with #midjourney. Most interesting one is #huggingface prompt generator, which uses #NLP model to generate sample prompts.
As an example, we tried to reproduce and improve our group avatar, following ideas in the articles. Prompt for an illustration to this post was generated with query
Midjourney Prompt Generator: https://huggingface.co/spaces/doevent/prompt-generator
List of Midjourney prompts: https://www.followchain.org/midjourney-prompts/
An advanced guide to writing prompts for Midjourney ( text-to-image): https://medium.com/mlearning-ai/an-advanced-guide-to-writing-prompts-for-midjourney-text-to-image-aa12a1e33b6
#visualization #gan #generation #generatinveart #aiart #artgentips
Generating images with AI tools is a skill, which can be improved and enhanced. So here is couple of articles, covering tips & tricks on how to generate better images with #midjourney. Most interesting one is #huggingface prompt generator, which uses #NLP model to generate sample prompts.
As an example, we tried to reproduce and improve our group avatar, following ideas in the articles. Prompt for an illustration to this post was generated with query
ferrofluids in form of a brain, beautiful connections chaos, swirling black network --ar 3:4 --iw 9 --q 2 --s 1250Midjourney Prompt Generator: https://huggingface.co/spaces/doevent/prompt-generator
List of Midjourney prompts: https://www.followchain.org/midjourney-prompts/
An advanced guide to writing prompts for Midjourney ( text-to-image): https://medium.com/mlearning-ai/an-advanced-guide-to-writing-prompts-for-midjourney-text-to-image-aa12a1e33b6
#visualization #gan #generation #generatinveart #aiart #artgentips
👍29🔥13❤3👏3
Forwarded from Machinelearning
1. Руководство по дистилляции от OpenAI
Руководство содержит подробное описание процесса передачи знаний от более крупной модели к компактной, c сохранением высокой производительности модели.
Основные аспекты, рассмотренные в руководстве:
- Сохранение выходных данных крупной модели: Создание набора данных, содержащего предсказания большой модели, которые будут использоваться для обучения меньшей модели.
- Оценка производительности моделей: Сравнительный анализ точности и эффективности как крупной, так и компактной моделей на основе различных метрик.
- Создание обучающих данных для компактной модели: Использование предсказаний крупной модели для генерации обучающего набора данных, способствующего эффективному обучению меньшей модели.
- Оценка дообученной компактной модели: Проверка производительности и точности компактной модели после процесса дистилляции для подтверждения соответствия требованиям.
2. Учебник по дистилляции знаний от PyTorch
Руководство от PyTorch, которое содержит практическое введение в технику передачи знаний для развёртывания моделей на устройствах с ограниченными вычислительными ресурсами.
Основные аспекты руководства:
- Извлечение скрытых представлений: В гайде показано, как получить промежуточные представления из обученной модели для дальнейшего использования.
- Модификация циклов обучения в PyTorch: Здесь рассматривается интеграция дополнительных функций в стандартные циклы обучения для эффективной передачи знаний.
- На примере показан процесс обучения компактной модели, с ипользованием предсказания более сложной модели в качестве ориентира.
Руководство содержит пошаговые инструкции и примеры кода, что делает его ценным ресурсом, если вы хотите научиться оптимизировать свои модели для использования в средах с ограниченными ресурсами.
▪Ссылка
3. Jetson Introduction to Knowledge Distillation от Nvidia
В данном руководстве рассматривается процесс передачи знаний от модели OpenCLIP (vision-language model) к модели ResNet18 для классификации на наборе данных STL10.
Особое внимание уделяется тому, как выбор данных, методы дистилляции и архитектура модели, влияют на итоговую точность.
Кроме того, обсуждаются методы профилирования и оптимизации моделей для их развёртывания на устройствах NVIDIA Jetson Orin Nano.
4. Учебник по дистилляции знаний от Keras
Подробно описывается концепция дистилляции знаний и ее применение в обработке медицинских изображений.
5. Руководство по дистилляции от
huggingface 🤗
Здесь показано, как выполнять дистилляцию знаний шаг за шагом на конкретном примере.
6. Дистилляция знаний для задач компьютерного зрения от huggingface
Здесь рассматривается, как сделать файнтюн ViT-модели в MobileNet с помощью API Trainer из Transformers.
#KnowledgeDistillation #Distillation #openai #keras #tutorial #course #freecourses #huggingface #Nvidia #pytorch
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥7❤3✍1👍1
Forwarded from Machine learning Interview
🚀 Релиз от NVIDIA: Llama-Nemotron-Ultra 253B!
Llama-Nemotron-Ultra — модель с 253B параметрами, специально заточенная под задачи reasoning .
📦 Что внутри:
- LLaMA 405B, радикально преобразованная с помощью NAS pruning
- Пост-тренинг с фокусом на reasoning: SFT + RL
- Вычисления в FP8 для производительности без потери качества
- Open weights + открытые данные
🧠 Подходит для сложных задач рассуждения, настройки под кастомные пайплайны и исследований в области AGI.
🔗 Попробовать: https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1
#LLM #NVIDIA #OpenWeights #Reasoning #RLHF #FP8 #AIresearch #HuggingFace
@machinelearning_interview - подписаться
Llama-Nemotron-Ultra — модель с 253B параметрами, специально заточенная под задачи reasoning .
📦 Что внутри:
- LLaMA 405B, радикально преобразованная с помощью NAS pruning
- Пост-тренинг с фокусом на reasoning: SFT + RL
- Вычисления в FP8 для производительности без потери качества
- Open weights + открытые данные
🧠 Подходит для сложных задач рассуждения, настройки под кастомные пайплайны и исследований в области AGI.
🔗 Попробовать: https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1
#LLM #NVIDIA #OpenWeights #Reasoning #RLHF #FP8 #AIresearch #HuggingFace
@machinelearning_interview - подписаться
👍7🔥7❤3
Forwarded from Machine learning Interview
🧠 One RL to See Them All
MiniMax-AI представили Orsta-7B и Orsta-32B — мощные мультимодальные модели, обученные по новой методике V-Triune:
🔧 V-Triune объединяет:
• форматирование данных на уровне задач,
• расчет награды через кастомные верификаторы,
• мониторинг метрик по источникам.
💥 Результаты?
📈 Orsta-32B даёт **+14.1% прирост** на MEGA-Bench Core по сравнению с QwenVL-2.5!
От OCR и распознавания объектов до визуального рассуждения и математических задач — одна RL-схема покрывает всё.
📦 Модели уже доступны:
- huggingface.co/collections/One-RL-to-See-Them-All/one-rl-to-see-them-all-6833d27abce23898b2f9815a
- github.com/MiniMax-AI/One-RL-to-See-Them-All
Открытая, мощная, готовая к запуску.
#AI #Orsta #MiniMax #VisionLanguage #RLHF #VLM #Multimodal #OpenSource #HuggingFace
MiniMax-AI представили Orsta-7B и Orsta-32B — мощные мультимодальные модели, обученные по новой методике V-Triune:
🔧 V-Triune объединяет:
• форматирование данных на уровне задач,
• расчет награды через кастомные верификаторы,
• мониторинг метрик по источникам.
💥 Результаты?
📈 Orsta-32B даёт **+14.1% прирост** на MEGA-Bench Core по сравнению с QwenVL-2.5!
От OCR и распознавания объектов до визуального рассуждения и математических задач — одна RL-схема покрывает всё.
📦 Модели уже доступны:
- huggingface.co/collections/One-RL-to-See-Them-All/one-rl-to-see-them-all-6833d27abce23898b2f9815a
- github.com/MiniMax-AI/One-RL-to-See-Them-All
Открытая, мощная, готовая к запуску.
#AI #Orsta #MiniMax #VisionLanguage #RLHF #VLM #Multimodal #OpenSource #HuggingFace
👍4❤1🔥1