
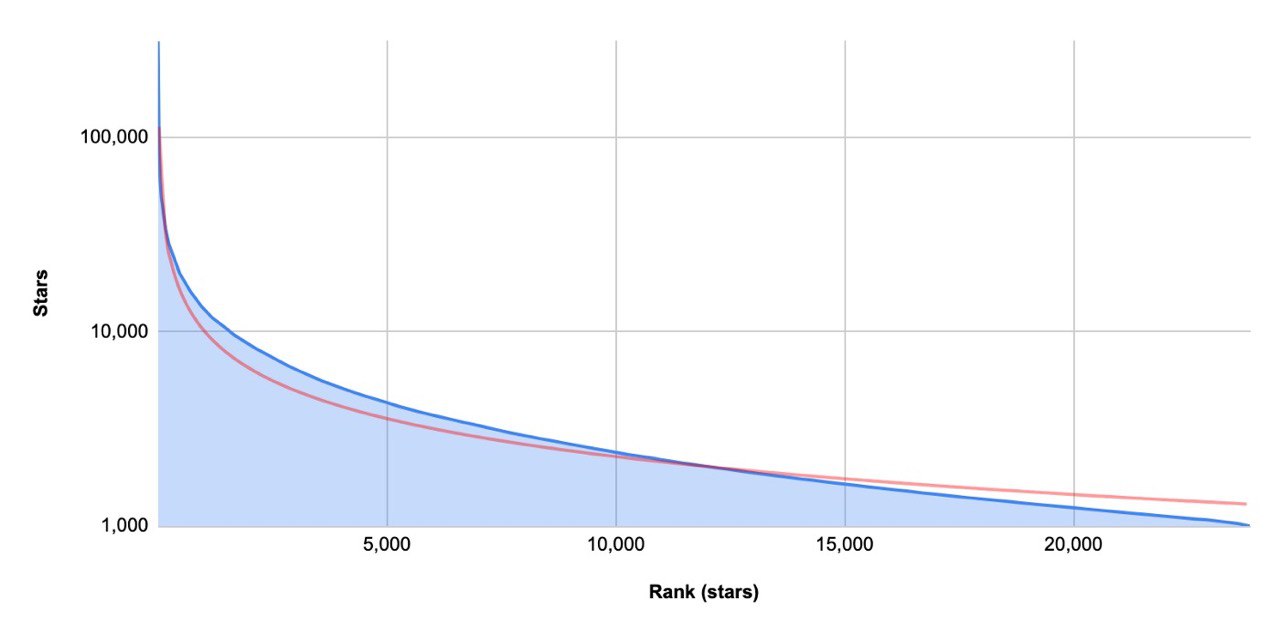
Overview of Open Source projects growth metrics
Quantative analytics of top starred repositories.
Link: https://medium.com/runacapital/open-source-growth-benchmarks-and-the-20-fastest-growing-oss-startups-d3556a669fe6
#opensource #analytics #statistics #growth
Quantative analytics of top starred repositories.
Link: https://medium.com/runacapital/open-source-growth-benchmarks-and-the-20-fastest-growing-oss-startups-d3556a669fe6
#opensource #analytics #statistics #growth
{kind=link}
Ultimate post on where to start learning DS
Most common request we received through the years was to share insights and advices on how to start career in data science and to recommend decent cources. Apparently, using hashtag #wheretostart wasn't enough so we were sharing some general advices.
So we assembled a through guide on how to start learning machine learning and created another #ultimatepost (in a form of a github repo, so it will be keep updated and anyone can submit worthy piece of advice to it).
We welcome you to share your stories and advices on how to start rolling into data science, as well as to spread the link to the repo to those your friends who might benefit from it.
Link: Ultimate post
#entrylevel #beginner #junior #MOOC #learndatascience #courses #mlcourse #opensource
Most common request we received through the years was to share insights and advices on how to start career in data science and to recommend decent cources. Apparently, using hashtag #wheretostart wasn't enough so we were sharing some general advices.
So we assembled a through guide on how to start learning machine learning and created another #ultimatepost (in a form of a github repo, so it will be keep updated and anyone can submit worthy piece of advice to it).
We welcome you to share your stories and advices on how to start rolling into data science, as well as to spread the link to the repo to those your friends who might benefit from it.
Link: Ultimate post
#entrylevel #beginner #junior #MOOC #learndatascience #courses #mlcourse #opensource
{kind=link}
👍13😁2❤1
Open Software Packaging for Science
#opensource alternative to #conda.
Mamba (drop-in replacement) direct link: https://github.com/TheSnakePit/mamba
Link: https://medium.com/@QuantStack/open-software-packaging-for-science-61cecee7fc23
#python #packagemanagement
#opensource alternative to #conda.
Mamba (drop-in replacement) direct link: https://github.com/TheSnakePit/mamba
Link: https://medium.com/@QuantStack/open-software-packaging-for-science-61cecee7fc23
#python #packagemanagement
GitHub
GitHub - mamba-org/mamba: The Fast Cross-Platform Package Manager
The Fast Cross-Platform Package Manager. Contribute to mamba-org/mamba development by creating an account on GitHub.
👍1
Data Science by ODS.ai 🦜
Ultimate post on where to start learning DS Most common request we received through the years was to share insights and advices on how to start career in data science and to recommend decent cources. Apparently, using hashtag #wheretostart wasn't enough…
Hands on ML notebook series
Updated our ultimate post with a series of Jupyter notebooks that walk you through the fundamentals of Machine Learning and Deep Learning in python using Scikit-Learn and TensorFlow.
Link: https://github.com/ageron/handson-ml
#wheretostart #opensource #jupyter
Updated our ultimate post with a series of Jupyter notebooks that walk you through the fundamentals of Machine Learning and Deep Learning in python using Scikit-Learn and TensorFlow.
Link: https://github.com/ageron/handson-ml
#wheretostart #opensource #jupyter
GitHub
GitHub - ageron/handson-ml: ⛔️ DEPRECATED – See https://github.com/ageron/handson-ml3 instead.
⛔️ DEPRECATED – See https://github.com/ageron/handson-ml3 instead. - ageron/handson-ml
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://yangx.top/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://yangx.top/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
👍56🔥15❤6🥰2😁2🎉2⚡1👎1👏1
Hi, our friends @mike0sv and @agusch1n just open-sourced MLEM - a tool that helps you deploy your ML models as part of the DVC ecosystem
It’s a Python library + Command line tool.
TLDR:
📦 MLEM can package an ML model into a Docker image or a Python package, and deploy it to Heroku (we made them promise to add SageMaker, K8s and Seldon-core soon :parrot:).
⚙️ MLEM saves all model metadata to a human-readable text file: Python environment, model methods, model input & output data schema and more.
💅 MLEM helps you turn your Git repository into a Model Registry with features like ML model lifecycle management.
Read more in release blogpost: https://dvc.org/blog/MLEM-release
Also, check out the project: https://github.com/iterative/mlem
And the website: https://mlem.ai
Guys are happy to hear your feedback, discuss how this could be helpful for you, how MLEM compares to MLflow, etc.
Ask in the comments!
#mlops #opensource #deployment #dvc
It’s a Python library + Command line tool.
TLDR:
📦 MLEM can package an ML model into a Docker image or a Python package, and deploy it to Heroku (we made them promise to add SageMaker, K8s and Seldon-core soon :parrot:).
⚙️ MLEM saves all model metadata to a human-readable text file: Python environment, model methods, model input & output data schema and more.
💅 MLEM helps you turn your Git repository into a Model Registry with features like ML model lifecycle management.
Read more in release blogpost: https://dvc.org/blog/MLEM-release
Also, check out the project: https://github.com/iterative/mlem
And the website: https://mlem.ai
Guys are happy to hear your feedback, discuss how this could be helpful for you, how MLEM compares to MLflow, etc.
Ask in the comments!
#mlops #opensource #deployment #dvc
🔥32👍13👎3🤔1
Forwarded from DataGym Channel [Power of data]
#opensource : RuLeanALBERT от Yandex Research
2.9B трансформер для русского, которая влезет в домашнюю ПеКарню ресерчера
Мало того, что это самая большая БЕРТ-подобная модель для русского языка, которая показывает крутые результаты в бенчмарках, так еще и с кодом для fine-tuning-а
GitHub
А в статье можете узнать, как обучалась эта модель (а-ля коллаборативное глубокое обучение) на фреймворке по децентрализованному обучению Hivemind
2.9B трансформер для русского, которая влезет в домашнюю ПеКарню ресерчера
Мало того, что это самая большая БЕРТ-подобная модель для русского языка, которая показывает крутые результаты в бенчмарках, так еще и с кодом для fine-tuning-а
GitHub
А в статье можете узнать, как обучалась эта модель (а-ля коллаборативное глубокое обучение) на фреймворке по децентрализованному обучению Hivemind
GitHub
GitHub - yandex-research/RuLeanALBERT: RuLeanALBERT is a pretrained masked language model for the Russian language that uses a…
RuLeanALBERT is a pretrained masked language model for the Russian language that uses a memory-efficient architecture. - yandex-research/RuLeanALBERT
👍28❤3
OBELISC: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
The OBELICS dataset is a game-changer in the world of machine learning and AI! Unlike existing closed-source datasets, OBELICS is a vast, open-source, web-scale dataset specially curated for training large multimodal models. Boasting 141 million web pages from Common Crawl, 353 million high-quality images, and an impressive 115 billion text tokens, OBELICS sets a new standard in the richness and diversity of training data.
But it's not just about the numbers; it's about results. To prove its mettle, models with 9 and 80 billion parameters were trained on OBELICS, showcasing competitive performance across various multimodal benchmarks. Named IDEFICS, these models outperformed or matched their closed-source counterparts, proving that OBELICS isn't just a theoretical concept—it's a practical, high-impact alternative.
Paper link: https://huggingface.co/papers/2306.16527
Model card link: https://huggingface.co/HuggingFaceM4/idefics-80b-instruct
Blogpost link: https://huggingface.co/blog/idefics
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-obelisc
#deeplearning #cv #nlp #largelanguagemodel #opensource
The OBELICS dataset is a game-changer in the world of machine learning and AI! Unlike existing closed-source datasets, OBELICS is a vast, open-source, web-scale dataset specially curated for training large multimodal models. Boasting 141 million web pages from Common Crawl, 353 million high-quality images, and an impressive 115 billion text tokens, OBELICS sets a new standard in the richness and diversity of training data.
But it's not just about the numbers; it's about results. To prove its mettle, models with 9 and 80 billion parameters were trained on OBELICS, showcasing competitive performance across various multimodal benchmarks. Named IDEFICS, these models outperformed or matched their closed-source counterparts, proving that OBELICS isn't just a theoretical concept—it's a practical, high-impact alternative.
Paper link: https://huggingface.co/papers/2306.16527
Model card link: https://huggingface.co/HuggingFaceM4/idefics-80b-instruct
Blogpost link: https://huggingface.co/blog/idefics
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-obelisc
#deeplearning #cv #nlp #largelanguagemodel #opensource
{kind=link}
👍8🔥3❤2🥰1
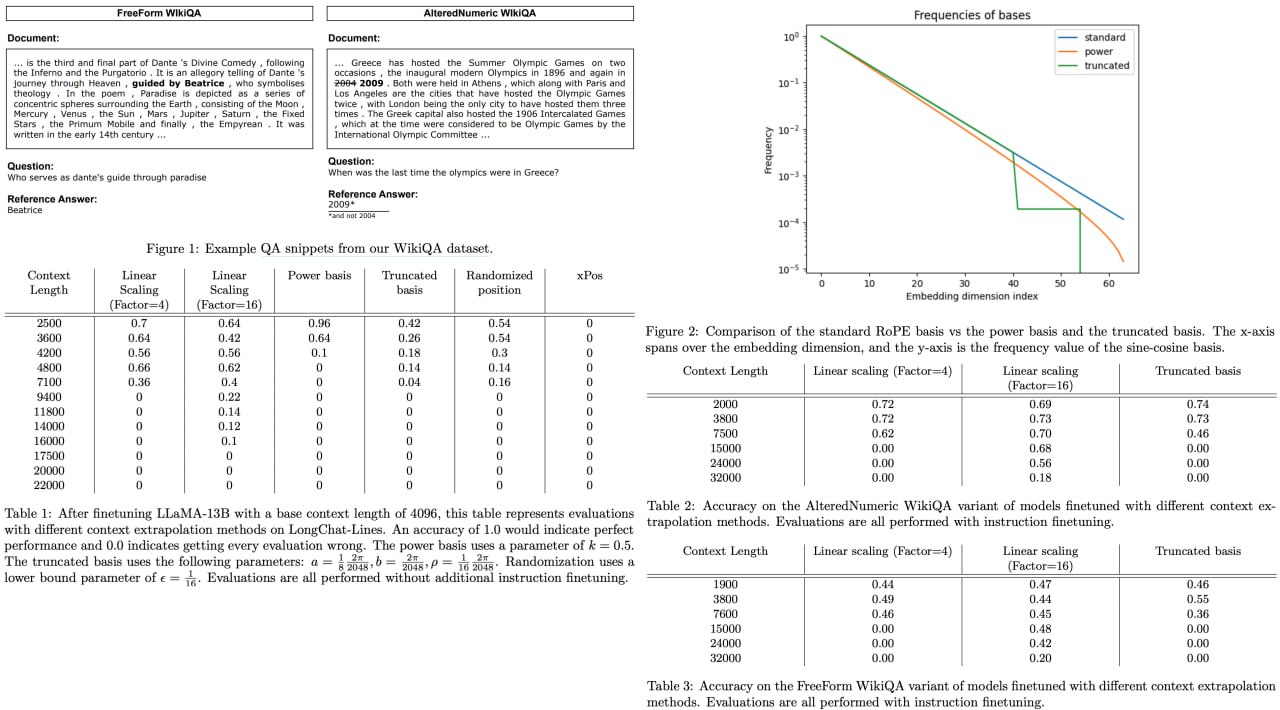
Giraffe: Adventures in Expanding Context Lengths in LLMs
Modern Large Language Models (LLMs) have revolutionized our ability to process and understand vast amounts of textual data. Yet, these models, like LLaMA and LLaMA2, often come with a caveat: they're constrained by fixed context lengths, which means they're limited in handling longer sequences of input data at evaluation. This paper tackles that constraint by investigating a variety of methods for "context length extrapolation," which essentially enables these models to understand and work with longer text sequences. Among the techniques explored, the paper introduces an innovative "truncated basis" strategy for altering positional encodings within the attention mechanism, promising a more scalable future for LLMs.
The researchers put their theories to the test with three brand-new evaluation tasks—FreeFormQA, AlteredNumericQA, and LongChat-Lines—providing a more nuanced measure of model performance than the traditionally used metric of perplexity. Their findings? Linear scaling came out on top as the most effective way to extend the context length, but the truncated basis method showed potential for future exploration. To propel the research community even further, the paper releases three game-changing long-context models, named Giraffe, with context lengths ranging from 4k to an astonishing 32k.
Paper link: https://arxiv.org/abs/2308.10882
Code link: https://github.com/abacusai/Long-Context
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-giraffe
#deeplearning #cv #nlp #largelanguagemodel #opensource #largecontext
Modern Large Language Models (LLMs) have revolutionized our ability to process and understand vast amounts of textual data. Yet, these models, like LLaMA and LLaMA2, often come with a caveat: they're constrained by fixed context lengths, which means they're limited in handling longer sequences of input data at evaluation. This paper tackles that constraint by investigating a variety of methods for "context length extrapolation," which essentially enables these models to understand and work with longer text sequences. Among the techniques explored, the paper introduces an innovative "truncated basis" strategy for altering positional encodings within the attention mechanism, promising a more scalable future for LLMs.
The researchers put their theories to the test with three brand-new evaluation tasks—FreeFormQA, AlteredNumericQA, and LongChat-Lines—providing a more nuanced measure of model performance than the traditionally used metric of perplexity. Their findings? Linear scaling came out on top as the most effective way to extend the context length, but the truncated basis method showed potential for future exploration. To propel the research community even further, the paper releases three game-changing long-context models, named Giraffe, with context lengths ranging from 4k to an astonishing 32k.
Paper link: https://arxiv.org/abs/2308.10882
Code link: https://github.com/abacusai/Long-Context
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-giraffe
#deeplearning #cv #nlp #largelanguagemodel #opensource #largecontext
{kind=link}
👍13❤3🔥3
What is this attraction of unprecedented generosity? Your queries will probably be used to train new models (although this is not accurate).
https://docs.mistral.ai/getting-started/models/
#mistral #opensource
@opendatascience
Please open Telegram to view this post
VIEW IN TELEGRAM
👍10🔥9❤5😱4👏1
Forwarded from Machinelearning
Курс содержит пошаговые инструкции с примерами кода, которые помогут научиться создавать автономных агентов с использованием машинного обучения.
Фокус на AI-агентах:
Если вас интересует именно разработка агентов — например, для симуляций, игр или интерактивных систем — данный курс будет полезен.
Каждый урок включает в себя:
- Лекцию, (видео уроки появятся в марте 2025 года)
- Примеры кода на Python с поддержкой Azure AI Foundry и Github Models
- Практические задания
- Ссылки на полезные дополнительные ресурсы
Если это ваш первый опыт работы с агентами, у Microsoft есть еще 1 курс «Генеративный ИИ для начинающих», который содержит 21 урок по построению моделей с помощью GenAI, лучше начать с него.
Переведен на 9 различных языков (русского нет).
▪ Github
@ai_machinelearning_big_data
#course #Microsoft #aiagents #ai #ml #opensource #freecourse
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥9👍6❤1
Forwarded from Китай.AI
🔮 CN-AI-MODELS | ИИ модели Китая
🔥 DeepSeek-V3-0324: мощное обновление DeepSeek
Китайская компания DeepSeek неожиданно представила новую версию своей модели — DeepSeek-V3-0324. Несмотря на скромное название "незначительного обновления", эта модель уже вызвала волну обсуждений благодаря своим впечатляющим характеристикам и демократичной цене. При этом разработчики не меняли базовую архитектуру, а лишь улучшили методы обучения!
👉 Кратко: Новая модель превосходит топовые западные аналоги (Claude-3.7-Sonnet, GPT-4.5) в математике и программировании, при этом стоимость её использования в разы ниже!
📊 Ключевые преимущества:
✔️ Улучшенная производительность в:
- Математических задачах (
- Программировании (
- Общих знаниях (
✔️ Новые возможности:
- Генерация сложных отчетов (до 3000 слов без потери качества)
- Улучшено форматирование ответов
- Улучшен вызов инструментов (tool calls)
✔️ Улучшения для разработчиков:
- Создает сложные веб-страницы (до 1000 строк кода за один проход)
- Пишет чистый HTML5, CSS и JavaScript с адаптивным дизайном
- Превращает короткие описания в работающие сайты
💡 Технические детали:
- Параметры модели: 660B (не 680B, как ошибочно предполагали)
- Лицензия: MIT (свободна для коммерческого использования)
- Работает даже на Mac Studio M3 Ultra (~20 токенов/сек)
🔗 Где попробовать?
Модель уже доступна на HuggingFace и официальной платформе.
#КитайскийИИ #КитайAI #DeepSeek #ИскусственныйИнтеллект #Программирование #OpenSource
🔥 DeepSeek-V3-0324: мощное обновление DeepSeek
Китайская компания DeepSeek неожиданно представила новую версию своей модели — DeepSeek-V3-0324. Несмотря на скромное название "незначительного обновления", эта модель уже вызвала волну обсуждений благодаря своим впечатляющим характеристикам и демократичной цене. При этом разработчики не меняли базовую архитектуру, а лишь улучшили методы обучения!
👉 Кратко: Новая модель превосходит топовые западные аналоги (Claude-3.7-Sonnet, GPT-4.5) в математике и программировании, при этом стоимость её использования в разы ниже!
📊 Ключевые преимущества:
✔️ Улучшенная производительность в:
- Математических задачах (
MATH-500, AIME 2024)- Программировании (
LiveCodeBench)- Общих знаниях (
MMLU-Pro, GPQA)✔️ Новые возможности:
- Генерация сложных отчетов (до 3000 слов без потери качества)
- Улучшено форматирование ответов
- Улучшен вызов инструментов (tool calls)
✔️ Улучшения для разработчиков:
- Создает сложные веб-страницы (до 1000 строк кода за один проход)
- Пишет чистый HTML5, CSS и JavaScript с адаптивным дизайном
- Превращает короткие описания в работающие сайты
💡 Технические детали:
- Параметры модели: 660B (не 680B, как ошибочно предполагали)
- Лицензия: MIT (свободна для коммерческого использования)
- Работает даже на Mac Studio M3 Ultra (~20 токенов/сек)
🔗 Где попробовать?
Модель уже доступна на HuggingFace и официальной платформе.
#КитайскийИИ #КитайAI #DeepSeek #ИскусственныйИнтеллект #Программирование #OpenSource
🔥11❤2
Forwarded from Анализ данных (Data analysis)
🎉 Выпущен Техрепорт Wan! 🚀
📖 https://arxiv.org/abs/2503.20314
Wan 2.1 — это открытый инструмент для генерации видео от Alibaba.
В отчете описана архитектура модели, конвейер обработки данных, обучение модели, повышение ее эффективности, алгоритм редактирования видео и т. д.
🟢 Официальный сайт: https://wan.video
🟢 Github: https://github.com/Wan-Video/Wan2.1
🟢 HF: https://huggingface.co/Wan-AI
🟢 Modelscope: https://modelscope.cn/organization/Wan-AI
#WAN #OpenSource #VideoGeneration
📖 https://arxiv.org/abs/2503.20314
Wan 2.1 — это открытый инструмент для генерации видео от Alibaba.
В отчете описана архитектура модели, конвейер обработки данных, обучение модели, повышение ее эффективности, алгоритм редактирования видео и т. д.
#WAN #OpenSource #VideoGeneration
Please open Telegram to view this post
VIEW IN TELEGRAM
👍8❤2🔥2
Forwarded from Machinelearning
Этот открытый учебник считается де-факто стандартом и одним из самых авторитетных и всеобъемлющих ресурсов для изучения областей обработки естественного языка (NLP), вычислительной лингвистики и обработки речи.
Книга разделена на три части, включающие 24 основные главы и 8 приложений.
Темы охватывают широкий спектр, включая:
Для каждой главы доступны слайды в форматах PPTX и PDF, что делает ресурс полезным для преподавателей.
Для всех, кто заинтересован в изучении NLP это фантастически полезный ресурс.
@ai_machinelearning_big_data
#freebook #opensource #nlp
Please open Telegram to view this post
VIEW IN TELEGRAM
👍7❤2🔥2
Forwarded from Искусственный интеллект. Высокие технологии
Обычно в генерации видео модели обрабатывают весь ролик "размазанным" шумом — как бы в целом.
А тут модель управляет шумом отдельно для каждого кадра, и делает это с помощью векторизованных "timesteps" (временных шагов) — более гибко, точно и эффективно.
Новая модель генерации видео на базе Mochi1-Preview и поддерживает:
🔹 Text-to-Video
🔹 Image-to-Video
🔹 Frame Interpolation
🔹 Video Transitions
🔹 Looping, удлинение видео и многое другое
⚡ Эффективность:
▪ 16× H800 GPU
▪ 0.1k GPU-часов
▪ Обучение: 500 итераций, batch size 32
▪ По заявления разработчиков - стоимость обучения всего 100$ 🤯
▪Github
▪Paper
▪Dataset
▪Model
#diffusion #videogen #pusa #opensource #AI #text2video #mochi1 #fvdm
@vistehno
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍8❤2🥰2
Forwarded from Китай.AI
🔮 CN-AI-MODELS | ИИ модели Китая
🎬 MAGI-1: Китайский ИИ для генерации видео с точностью до секунды
Компания Sand AI представила революционную модель для создания видео — MAGI-1. Это первый в мире авторегрессионный видеогенератор с контролем времени на уровне секунд. На GitHub проект за сутки собрал уже более 1k звезд.
🔹 Почему это важно?
MAGI-1 преодолевает ключевые проблемы AI-видео: рваные переходы, неестественные движения и ограниченную длину роликов.
📌 Ключевые особенности:
✔Бесконечное продолжение — создает плавные длинные сцены без склеек
✔Точный контроль времени — можно задать действия для каждой секунды
✔Естественная динамика — движения выглядят живо и реалистично
✔8K-качество — сверхчеткое изображение
🛠 Технические детали:
- Архитектура: VAE + Transformer (сжатие 8x пространственное, 4x временное)
- Метод: авторегрессивная дениойзинг-диффузия по блокам (24 кадра)
- Инновации: causal attention, QK-Norm, GQA, SwiGLU
- Размеры моделей: 24B и 4.5B параметров
💡 Почему это прорыв?
1. Открытый доступ (веса + код)
2. Работает даже на RTX 4090
3. В 2.6× эффективнее аналогов (MFU 58%)
4. Лидер VBench-I2V (89.28 баллов)
Основатели проекта — звезды AI-исследований:
👨💻 Цао Юэ (эксперт CNN, 60k цитирований)
👨💻 Чжан Чжэн (соавтор Swin Transformer)
Онлайн-демо | GitHub
#КитайскийИИ #КитайAI #ГенерацияВидео #Нейросети #OpenSource
🎬 MAGI-1: Китайский ИИ для генерации видео с точностью до секунды
Компания Sand AI представила революционную модель для создания видео — MAGI-1. Это первый в мире авторегрессионный видеогенератор с контролем времени на уровне секунд. На GitHub проект за сутки собрал уже более 1k звезд.
🔹 Почему это важно?
MAGI-1 преодолевает ключевые проблемы AI-видео: рваные переходы, неестественные движения и ограниченную длину роликов.
📌 Ключевые особенности:
✔Бесконечное продолжение — создает плавные длинные сцены без склеек
✔Точный контроль времени — можно задать действия для каждой секунды
✔Естественная динамика — движения выглядят живо и реалистично
✔8K-качество — сверхчеткое изображение
🛠 Технические детали:
- Архитектура: VAE + Transformer (сжатие 8x пространственное, 4x временное)
- Метод: авторегрессивная дениойзинг-диффузия по блокам (24 кадра)
- Инновации: causal attention, QK-Norm, GQA, SwiGLU
- Размеры моделей: 24B и 4.5B параметров
💡 Почему это прорыв?
1. Открытый доступ (веса + код)
2. Работает даже на RTX 4090
3. В 2.6× эффективнее аналогов (MFU 58%)
4. Лидер VBench-I2V (89.28 баллов)
Основатели проекта — звезды AI-исследований:
👨💻 Цао Юэ (эксперт CNN, 60k цитирований)
👨💻 Чжан Чжэн (соавтор Swin Transformer)
Онлайн-демо | GitHub
#КитайскийИИ #КитайAI #ГенерацияВидео #Нейросети #OpenSource
sand.ai
Magi
Magi is the first autoregressive video model with top-tier quality output. Magi is a powerful AI video generator that transforms your ideas into stunning videos for free. Extend videos effortlessly with cutting-edge Generative AI tech!
❤3
Forwarded from Китай.AI
🔮 CN-AI-MODELS | ИИ модели Китая
🔥 Qwen3: новый уровень открытых ИИ-моделей от Alibaba!
Китайский гигант Alibaba представил третье поколение своей флагманской ИИ-серии Qwen — мощные языковые модели с полностью открытой лицензией Apache 2.0.
📌 Основные модели серии:
• Qwen3-235B-A22B (флагман) — 235 млрд параметров с 22 млрд активных - конкурирует с Grok-3 и Gemini Pro
• Qwen3-30B-A3B — в 10x эффективнее аналогов при 3 млрд активируемых параметров
• 6 Dense-моделей (0.6B–32B) с полным открытым исходным кодом
💡 Ключевые инновации:
→ Режимы "Размышление/Без размышления" для баланса скорости и качества ответов
→ Поддержка 119 языков (рекорд среди открытых моделей)
→ Улучшенные возможности для работы с агентами и MCP
→ В 2x больше данных для обучения vs Qwen2.5 (36 трлн токенов)
→ Экономичность: запуск полной модели требует всего 4 видеокарты H20, а использование видеопамяти на 66% меньше, чем у аналогов
→ Qwen3-0.6B можно запустить даже на смартфоне!
GitHub
Для развертывания разработчики рекомендуют использовать SGLang и vLLM, для локального применения — Ollama или LMStudio.
Подробнее в блоге разработчиков
📊 С выпуском Owen 3, Qwen стал самым крупным семейством открытых моделей в мире опередив Llama:
✅ Свыше 200 моделей
✅ Более 300 млн загрузок
✅ 100 000+ производных архитектур
🔥 Qwen3: новый уровень открытых ИИ-моделей от Alibaba!
Китайский гигант Alibaba представил третье поколение своей флагманской ИИ-серии Qwen — мощные языковые модели с полностью открытой лицензией Apache 2.0.
📌 Основные модели серии:
• Qwen3-235B-A22B (флагман) — 235 млрд параметров с 22 млрд активных - конкурирует с Grok-3 и Gemini Pro
• Qwen3-30B-A3B — в 10x эффективнее аналогов при 3 млрд активируемых параметров
• 6 Dense-моделей (0.6B–32B) с полным открытым исходным кодом
💡 Ключевые инновации:
→ Режимы "Размышление/Без размышления" для баланса скорости и качества ответов
→ Поддержка 119 языков (рекорд среди открытых моделей)
→ Улучшенные возможности для работы с агентами и MCP
→ В 2x больше данных для обучения vs Qwen2.5 (36 трлн токенов)
→ Экономичность: запуск полной модели требует всего 4 видеокарты H20, а использование видеопамяти на 66% меньше, чем у аналогов
→ Qwen3-0.6B можно запустить даже на смартфоне!
|
HuggingFace |
ModelScope |GitHub
Для развертывания разработчики рекомендуют использовать SGLang и vLLM, для локального применения — Ollama или LMStudio.
Подробнее в блоге разработчиков
📊 С выпуском Owen 3, Qwen стал самым крупным семейством открытых моделей в мире опередив Llama:
✅ Свыше 200 моделей
✅ Более 300 млн загрузок
✅ 100 000+ производных архитектур
chat.qwen.ai
Qwen Chat
Qwen Chat offers comprehensive functionality spanning chatbot, image and video understanding, image generation, document processing, web search integration, tool utilization, and artifacts.
❤3🔥2👍1
Forwarded from Китай.AI
🔮 CN-AI-MODELS | ИИ модели Китая
🚀 Alibaba представил DianJin-R1 — мощную языковую модель для финансовых задач
Команда Alibaba Cloud и Университет Сучжоу разработали инновационную модель с открытым исходным кодом, которая превосходит аналоги в области финансового анализа.
🔍 В двух словах:
- Модель доступна в двух версиях: 7B и 32B параметров
- Обучена на уникальных финансовых датасетах + мультиагентный синтез данных
- Превышает производительность DeepSeek-R1 и QwQ в тестах
📊 Ключевые особенности:
1️⃣Открытые данные и модели:
- Дамп DianJin-R1-Data включает CFLUE, FinQA и CCC (китайская нормативная проверка)
- Модели на Hugging Face, ModelScope и GitHub
2️⃣Технологии обучения:
- Двухэтапная оптимизация: Supervised Fine-Tuning + Reinforcement Learning
- Система вознаграждений за структурированные выводы и точность
3️⃣Мультиагентный синтез:
- Платформа Tongyi Dianjin генерирует сложные финансовые кейсы через взаимодействие ИИ-агентов
⚙️ Технические детали:
• Использованы Qwen2.5-7B/32B-Instruct как база
• GRPO (Group Relative Policy Optimization) для RL-фазы
• Фичинг: 38k+ экзаменационных вопросов (CFLUE) + 8k англоязычных QA (FinQA)
🔥 Результаты тестов:
▫️ DianJin-R1-7B сравним с топовой QwQ при меньших ресурсах
▫️ DianJin-R1-32B лидирует во всех категориях
"Это не просто шаг вперед в финтехе — мы переосмыслили подход к обучению ИИ для регуляторных задач" — команда разработчиков.
Официальный сайт | Hugging Face | GitHub
Подробнее в оригинальной статье.
#КитайскийИИ #КитайAI #FinTech #LLM #OpenSource #Alibaba #Qwen
🚀 Alibaba представил DianJin-R1 — мощную языковую модель для финансовых задач
Команда Alibaba Cloud и Университет Сучжоу разработали инновационную модель с открытым исходным кодом, которая превосходит аналоги в области финансового анализа.
🔍 В двух словах:
- Модель доступна в двух версиях: 7B и 32B параметров
- Обучена на уникальных финансовых датасетах + мультиагентный синтез данных
- Превышает производительность DeepSeek-R1 и QwQ в тестах
📊 Ключевые особенности:
1️⃣Открытые данные и модели:
- Дамп DianJin-R1-Data включает CFLUE, FinQA и CCC (китайская нормативная проверка)
- Модели на Hugging Face, ModelScope и GitHub
2️⃣Технологии обучения:
- Двухэтапная оптимизация: Supervised Fine-Tuning + Reinforcement Learning
- Система вознаграждений за структурированные выводы и точность
3️⃣Мультиагентный синтез:
- Платформа Tongyi Dianjin генерирует сложные финансовые кейсы через взаимодействие ИИ-агентов
⚙️ Технические детали:
• Использованы Qwen2.5-7B/32B-Instruct как база
• GRPO (Group Relative Policy Optimization) для RL-фазы
• Фичинг: 38k+ экзаменационных вопросов (CFLUE) + 8k англоязычных QA (FinQA)
🔥 Результаты тестов:
▫️ DianJin-R1-7B сравним с топовой QwQ при меньших ресурсах
▫️ DianJin-R1-32B лидирует во всех категориях
"Это не просто шаг вперед в финтехе — мы переосмыслили подход к обучению ИИ для регуляторных задач" — команда разработчиков.
Официальный сайт | Hugging Face | GitHub
Подробнее в оригинальной статье.
#КитайскийИИ #КитайAI #FinTech #LLM #OpenSource #Alibaba #Qwen
huggingface.co
DianJin (Qwen DianJin)
Org profile for Qwen DianJin on Hugging Face, the AI community building the future.
👍2❤1
Forwarded from Machine learning Interview
🧠 One RL to See Them All
MiniMax-AI представили Orsta-7B и Orsta-32B — мощные мультимодальные модели, обученные по новой методике V-Triune:
🔧 V-Triune объединяет:
• форматирование данных на уровне задач,
• расчет награды через кастомные верификаторы,
• мониторинг метрик по источникам.
💥 Результаты?
📈 Orsta-32B даёт **+14.1% прирост** на MEGA-Bench Core по сравнению с QwenVL-2.5!
От OCR и распознавания объектов до визуального рассуждения и математических задач — одна RL-схема покрывает всё.
📦 Модели уже доступны:
- huggingface.co/collections/One-RL-to-See-Them-All/one-rl-to-see-them-all-6833d27abce23898b2f9815a
- github.com/MiniMax-AI/One-RL-to-See-Them-All
Открытая, мощная, готовая к запуску.
#AI #Orsta #MiniMax #VisionLanguage #RLHF #VLM #Multimodal #OpenSource #HuggingFace
MiniMax-AI представили Orsta-7B и Orsta-32B — мощные мультимодальные модели, обученные по новой методике V-Triune:
🔧 V-Triune объединяет:
• форматирование данных на уровне задач,
• расчет награды через кастомные верификаторы,
• мониторинг метрик по источникам.
💥 Результаты?
📈 Orsta-32B даёт **+14.1% прирост** на MEGA-Bench Core по сравнению с QwenVL-2.5!
От OCR и распознавания объектов до визуального рассуждения и математических задач — одна RL-схема покрывает всё.
📦 Модели уже доступны:
- huggingface.co/collections/One-RL-to-See-Them-All/one-rl-to-see-them-all-6833d27abce23898b2f9815a
- github.com/MiniMax-AI/One-RL-to-See-Them-All
Открытая, мощная, готовая к запуску.
#AI #Orsta #MiniMax #VisionLanguage #RLHF #VLM #Multimodal #OpenSource #HuggingFace
👍4❤1🔥1
Forwarded from Machinelearning
— GPT-OSS-120B — 117B параметров, запускается на одной H100 (80GB)
— GPT-OSS-20B — 21B параметров, работает на 16GB GPU
💡 Оба варианта — MoE-модели (Mixture of Experts) с 4-битной квантизацией (MXFP4)
• Архитектура Token-choice MoE с SwiGLU
• Контекст до 128K токенов с RoPE
• Модель заточена на CoT (chain-of-thought)
• Поддержка instruction-following и tool-use
• Совместима с transformers, vLLM, llama.cpp, ollama
• Используется тот же токенизатор, что и в GPT-4o
Младшая модель может запускаться даже на локальном железе!
https://github.com/huggingface/transformers/releases/tag/v4.55.0
🚀 Попробовать можно тут: https://www.gpt-oss.com/
@ai_machinelearning_big_data
#openai #opensource #chatgpt
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥8❤4👍3