
Forwarded from Graph Machine Learning
DeepMind's Traffic Prediction with Advanced Graph Neural Networks
A new blog post by DeepMind has been released recently that describes how you can apply GNN for travel time predictions. There are not many details about the model itself (which makes me wonder if deep net trained across all supersegments would suffice), but there are curious details about training.
1. As the road network is huge I suppose, they use sampling sampling of subgraphs in proportion to traffic density. This should be similar to GraphSAGE-like approaches.
2. Sampled subgraphs can vary a lot in a single batch. So they use RL to select subgraph properly. I guess it's some form of imitation learning that selects graphs in a batch based on some objective value.
3. They use MetaGradients algorithm to select a learning rate, which was previously used to parametrize returns in RL. I guess it parametrizes learning rate instead in this blog post.
A new blog post by DeepMind has been released recently that describes how you can apply GNN for travel time predictions. There are not many details about the model itself (which makes me wonder if deep net trained across all supersegments would suffice), but there are curious details about training.
1. As the road network is huge I suppose, they use sampling sampling of subgraphs in proportion to traffic density. This should be similar to GraphSAGE-like approaches.
2. Sampled subgraphs can vary a lot in a single batch. So they use RL to select subgraph properly. I guess it's some form of imitation learning that selects graphs in a batch based on some objective value.
3. They use MetaGradients algorithm to select a learning rate, which was previously used to parametrize returns in RL. I guess it parametrizes learning rate instead in this blog post.
Google DeepMind
Traffic prediction with advanced Graph Neural Networks
By partnering with Google, DeepMind is able to bring the benefits of AI to billions of people all over the world. From reuniting a speech-impaired user with his original voice, to helping users...
Data Science by ODS.ai 🦜
Nvidia announced new card RTX 3090 RTX 3090 is roughly 2 times more powerful than 2080. There is probably no point in getting 3080 because RAM volume is only 10G. But what really matters, is how it was presented. Purely technological product for mostly…
#NVidia performance per dollar
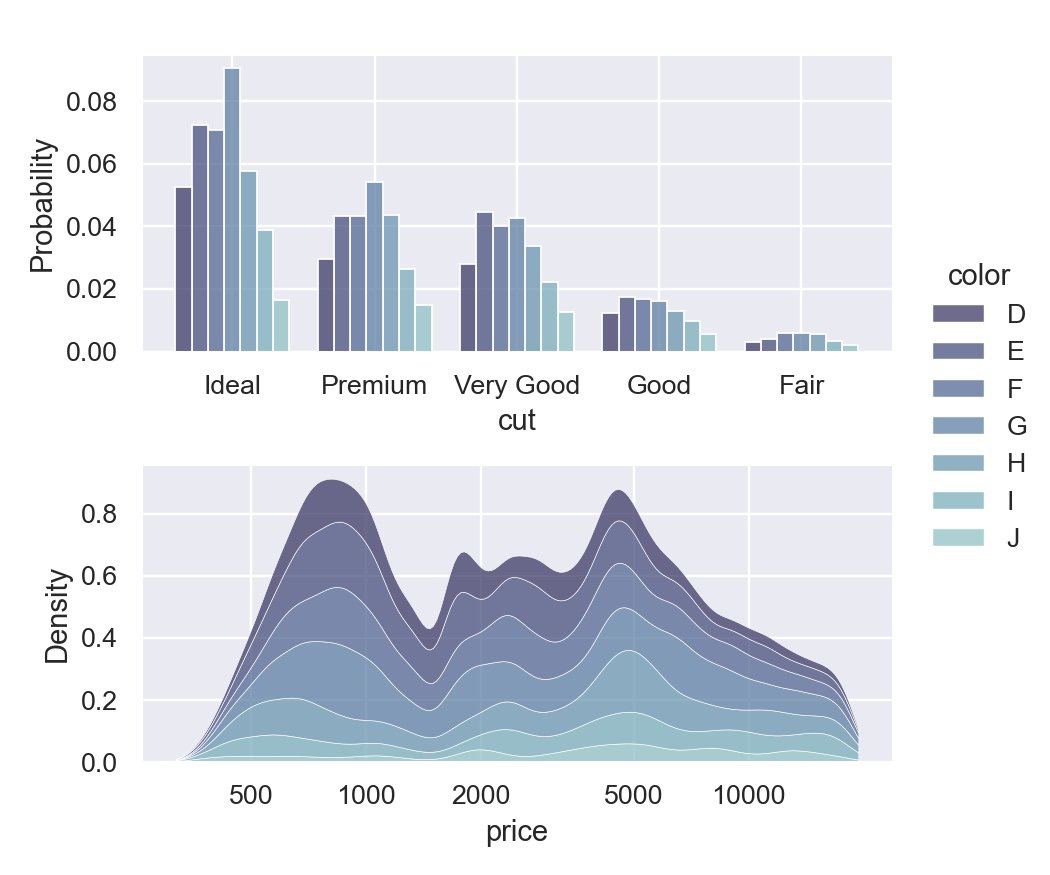
🔥New Seaborn vizaulization library release
- completely new and improved distributions module, with a modern API and many new features, like these histograms and kernel density plots
- support for empirical distribution plots, a better way to compare multiple distributions
- better overall handling of categorical, datetime, and log-scaled data
- new perceptually-uniform colormaps that are optimized for use in scatter or line plots
- an API update that requires keyword arguments in most places, laying the groundwork for smoother integration of planned future enhancements
Medium post: https://medium.com/@michaelwaskom/announcing-the-release-of-seaborn-0-11-3df0341af042
Whats new: https://seaborn.pydata.org/whatsnew.html
#vizualization #seaborn
- completely new and improved distributions module, with a modern API and many new features, like these histograms and kernel density plots
- support for empirical distribution plots, a better way to compare multiple distributions
- better overall handling of categorical, datetime, and log-scaled data
- new perceptually-uniform colormaps that are optimized for use in scatter or line plots
- an API update that requires keyword arguments in most places, laying the groundwork for smoother integration of planned future enhancements
Medium post: https://medium.com/@michaelwaskom/announcing-the-release-of-seaborn-0-11-3df0341af042
Whats new: https://seaborn.pydata.org/whatsnew.html
#vizualization #seaborn
{kind=link}
😱Full body 3D scan with the iPhone
Our friends from in3D.io released their app for digitizing humans with simple UX — just with a single scan of 360 turn. They use TrueDepth camera in iPhones to get photoreal quality.
Avatar is auto-rigged, there are a bunch of funny animations available in the app. You can export the model to a file, GTA V or Second Life.
Looking forward to Fortnite integration after Epic Games solve their issues!
Website: https://in3D.io
App: https://apple.co/3h7LEsT
#3dmodel #3dscan #truedepth #dstartup #ios
Our friends from in3D.io released their app for digitizing humans with simple UX — just with a single scan of 360 turn. They use TrueDepth camera in iPhones to get photoreal quality.
Avatar is auto-rigged, there are a bunch of funny animations available in the app. You can export the model to a file, GTA V or Second Life.
Looking forward to Fortnite integration after Epic Games solve their issues!
Website: https://in3D.io
App: https://apple.co/3h7LEsT
#3dmodel #3dscan #truedepth #dstartup #ios
Forwarded from Binary Tree
Diagrams lets you draw the cloud system architecture in Python code. It was born for prototyping a new system architecture design without any design tools. You can also describe or visualize the existing system architecture as well. Diagrams currently supports main major providers including: AWS, Azure, GCP, Kubernetes, Alibaba Cloud, Oracle Cloud etc... It also supports On-Premise nodes, SaaS and major Programming frameworks and languages.
#python, #diagram, #drawing, #prototyping, #architecture
#python, #diagram, #drawing, #prototyping, #architecture
👍1
pytorch lightning bolts
from linear, logistic regression on tpu-s to pre-trained gan-s
plb – is a collection of pytorch lightning implementations of popular models that are well tested and optimized for speed on multiple gpu-s and tpu-s
it is a new community built dl research and production toolbox, featuring a collection of well established and sota models and components, pre-trained weights, callbacks, loss functions, data sets, and data modules
everything is implemented in lightning and tested benchmarked, documented, and works on cpu-s, tpu-s, gpu-s, and 16-bit precision
more u can read at the blog post
github: https://github.com/PyTorchLightning/pytorch-lightning-bolts
#pytorchlightning #bolts #multiple
from linear, logistic regression on tpu-s to pre-trained gan-s
plb – is a collection of pytorch lightning implementations of popular models that are well tested and optimized for speed on multiple gpu-s and tpu-s
it is a new community built dl research and production toolbox, featuring a collection of well established and sota models and components, pre-trained weights, callbacks, loss functions, data sets, and data modules
everything is implemented in lightning and tested benchmarked, documented, and works on cpu-s, tpu-s, gpu-s, and 16-bit precision
more u can read at the blog post
github: https://github.com/PyTorchLightning/pytorch-lightning-bolts
#pytorchlightning #bolts #multiple
{kind=link}
👍1
Data Science by ODS.ai 🦜
Open Data Science Online Event Announce & Call for speakers! Data Fest 2020 - Online & Global, September 19-20 Data Fest is global free conference series where we unite all researchers, engineers, and developers around Data Science and related areas. Most…
🎉🥳DataFest2020 THIS WEEK🥳🎉
Get reeeeeeady! You probably noticed that we published LESS content than usual because we were preparing something speciiiiiiialll.
Now we present you amazing: https://fest.ai
Open!
Free!
Online!
Data Science event open for everyone!
Book upcoming weekends for something worthy!
Link: https://fest.ai/2020/
Get reeeeeeady! You probably noticed that we published LESS content than usual because we were preparing something speciiiiiiialll.
Now we present you amazing: https://fest.ai
Open!
Free!
Online!
Data Science event open for everyone!
Book upcoming weekends for something worthy!
Link: https://fest.ai/2020/
fest.ai
Data Fest
Largest free and open Data Science conference
Now talk about something special!
Data Fest (this is why we are less active in the channel) going worldwide and the first worldwide Data Fest 2020 will be online (you know why, don't you)
And this year it will be held in a quite unusual online format 😉 Register now so you don't waste your time on the weekend: ods.ai/events/datafest2020/join
There will be three types of activities at Data Fest 2020:
1️⃣ YouTube broadcast: https://youtu.be/J-boEj53LZk that anyone can watch;
2️⃣ Tracks. To access the tracks, you need to be registered on ods.ai - all tracks' activities will be happening there;
3️⃣ Networking with the coolest ODS community members at https://spatial.chat. To get there, you also need to register at ods.ai/events/datafest2020/join.
See you at the fest! And we hope it will be amazing.
Data Fest (this is why we are less active in the channel) going worldwide and the first worldwide Data Fest 2020 will be online (you know why, don't you)
And this year it will be held in a quite unusual online format 😉 Register now so you don't waste your time on the weekend: ods.ai/events/datafest2020/join
There will be three types of activities at Data Fest 2020:
1️⃣ YouTube broadcast: https://youtu.be/J-boEj53LZk that anyone can watch;
2️⃣ Tracks. To access the tracks, you need to be registered on ods.ai - all tracks' activities will be happening there;
3️⃣ Networking with the coolest ODS community members at https://spatial.chat. To get there, you also need to register at ods.ai/events/datafest2020/join.
See you at the fest! And we hope it will be amazing.
Forwarded from Spark in me (Alexander)
Silero Speech-To-Text Models V1 Released
We are proud to announce that we have released our high-quality (i.e. on par with premium Google models) speech-to-text Models for the following languages:
- English
- German
- Spanish
Why this is a big deal:
- STT Research is typically focused on huge compute budgets
- Pre-trained models and recipes did not generalize well, were difficult to use even as-is, relied on obsolete tech
- Until now STT community lacked easy to use high quality production grade STT models
How we solve it:
- We publish a set of pre-trained high-quality models for popular languages
- Our models are embarrassingly easy to use
- Our models are fast and can be run on commodity hardware
Even if you do not work with STT, please give us a star / share!
Links
- https://github.com/snakers4/silero-models
We are proud to announce that we have released our high-quality (i.e. on par with premium Google models) speech-to-text Models for the following languages:
- English
- German
- Spanish
Why this is a big deal:
- STT Research is typically focused on huge compute budgets
- Pre-trained models and recipes did not generalize well, were difficult to use even as-is, relied on obsolete tech
- Until now STT community lacked easy to use high quality production grade STT models
How we solve it:
- We publish a set of pre-trained high-quality models for popular languages
- Our models are embarrassingly easy to use
- Our models are fast and can be run on commodity hardware
Even if you do not work with STT, please give us a star / share!
Links
- https://github.com/snakers4/silero-models
GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly…
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models
Forwarded from Находки в опенсорсе
⚡Breaking news!
GitHub CLI 1.0 is now available!
GitHub CLI brings GitHub to your terminal. It reduces context switching, helps you focus, and enables you to more easily script and create your own workflows.
With GitHub CLI 1.0, you can:
- Run your entire GitHub workflow from the terminal, from issues through releases
- Call the GitHub API to script nearly any action, and set a custom alias for any command
- Connect to GitHub Enterprise Server in addition to GitHub.com
https://github.blog/2020-09-17-github-cli-1-0-is-now-available/
GitHub CLI 1.0 is now available!
GitHub CLI brings GitHub to your terminal. It reduces context switching, helps you focus, and enables you to more easily script and create your own workflows.
With GitHub CLI 1.0, you can:
- Run your entire GitHub workflow from the terminal, from issues through releases
- Call the GitHub API to script nearly any action, and set a custom alias for any command
- Connect to GitHub Enterprise Server in addition to GitHub.com
https://github.blog/2020-09-17-github-cli-1-0-is-now-available/
The GitHub Blog
GitHub CLI 1.0 is now available
GitHub CLI brings GitHub to your terminal. It reduces context switching, helps you focus, and enables you to more easily script and create your own workflows. Earlier this year, we…
Forwarded from Catalyst | Community
Official announcement 🎉
We are launching new open source deep learning course with Catalyst.
Course notebooks and assigments will be in English. Lectures and seminar videos - in Russian (we are working on their translation).
Catalyst is a PyTorch ecosystem framework for Deep Learning research and development. It focuses on reproducibility, rapid experimentation and codebase reuse. This means that you can seamlessly run training loop with metrics, model checkpointing, advanced logging and distributed training support without the boilerplate code.
In this course we will dive into back-propagation algorithm. After that we will go through computer vision, generative adversarial networks and metric learning tasks. We will also talk about NLP and RecSys best practices with RL applications for them. Last but not least, we will speak about day-to-day engineering tricks, that every MLE should know about. During the course you will need to pass several kaggle competitions and deploy our own machine learning microservice in the end of the course.
Join our slack and let's accelerate your DL RnD with Catalyst 🚀
Github: https://github.com/catalyst-team/dl-course
Stepik: https://stepik.org/course/83344
Slack: https://join.slack.com/t/catalyst-team-core/shared_invite/zt-d9miirnn-z86oKDzFMKlMG4fgFdZafw
We are launching new open source deep learning course with Catalyst.
Course notebooks and assigments will be in English. Lectures and seminar videos - in Russian (we are working on their translation).
Catalyst is a PyTorch ecosystem framework for Deep Learning research and development. It focuses on reproducibility, rapid experimentation and codebase reuse. This means that you can seamlessly run training loop with metrics, model checkpointing, advanced logging and distributed training support without the boilerplate code.
In this course we will dive into back-propagation algorithm. After that we will go through computer vision, generative adversarial networks and metric learning tasks. We will also talk about NLP and RecSys best practices with RL applications for them. Last but not least, we will speak about day-to-day engineering tricks, that every MLE should know about. During the course you will need to pass several kaggle competitions and deploy our own machine learning microservice in the end of the course.
Join our slack and let's accelerate your DL RnD with Catalyst 🚀
Github: https://github.com/catalyst-team/dl-course
Stepik: https://stepik.org/course/83344
Slack: https://join.slack.com/t/catalyst-team-core/shared_invite/zt-d9miirnn-z86oKDzFMKlMG4fgFdZafw
{kind=link}
Survivorship bias
This is when people tend to focus on available data, ignoring what they don't see.
Link: https://en.wikipedia.org/wiki/Survivorship_bias
#bias
This is when people tend to focus on available data, ignoring what they don't see.
Link: https://en.wikipedia.org/wiki/Survivorship_bias
#bias
{kind=link}
Tracking historical changes in trustworthiness using machine learning analyses of facial cues in paintings
Paper about how social perception of trustworthiness changed through times. Indeed, that depends on cultural and temporal context a lot.
As an addition, researches designed an algorithm to automatically generate trustworthiness evaluations for the facial action units (smile, eye brows, etc.).
Nature: https://www.nature.com/articles/s41467-020-18566-7.epdf
Second article: http://tlab.princeton.edu/publication_files/Social%20attributions%20from%20faces%20bias%20human%20choices.pdf
#CV #facial #trust #computationalsociology
Paper about how social perception of trustworthiness changed through times. Indeed, that depends on cultural and temporal context a lot.
As an addition, researches designed an algorithm to automatically generate trustworthiness evaluations for the facial action units (smile, eye brows, etc.).
Nature: https://www.nature.com/articles/s41467-020-18566-7.epdf
Second article: http://tlab.princeton.edu/publication_files/Social%20attributions%20from%20faces%20bias%20human%20choices.pdf
#CV #facial #trust #computationalsociology
{kind=link}
Forwarded from Pavel Durov
Today we are adding native support for comments in channels. So once you update Telegram, you’ll be able to leave comments in some channels, including this one.
Throughout the next 10 days I’ll be posting stuff here to try this feature out.
What I like about our implementation of comments is that they are indistinguishable from a group chat. In fact, all comments in a channel are hosted in a group attached to that channel.
This allows for many possibilities both for commenters (e.g. adding voice messages, stickers, GIFs etc. to comments) and for admins (e.g. limiting voice messages, stickers, GIFs etc. in comments).
Throughout the next 10 days I’ll be posting stuff here to try this feature out.
What I like about our implementation of comments is that they are indistinguishable from a group chat. In fact, all comments in a channel are hosted in a group attached to that channel.
This allows for many possibilities both for commenters (e.g. adding voice messages, stickers, GIFs etc. to comments) and for admins (e.g. limiting voice messages, stickers, GIFs etc. in comments).
Scalable digital fitting room based on the first full-body Deepfake
The next generation of Deepfake does the full-body swap including head, hair, skin tone and body shape modification. Practically the new technology aims to be applied for a brand agnostic digital fitting room, that works on the existing content and doesn't require content creation on the brand side.
To demonstrate other applications and raise interest of the community, developer created a video, demonstrating many features of the new generation of Deepfake.
YouTube: https://www.youtube.com/watch?v=15q41GjtyZs
Link: http://www.beyondbelief.ai
#deepfake #fittingroom #CV #DL
The next generation of Deepfake does the full-body swap including head, hair, skin tone and body shape modification. Practically the new technology aims to be applied for a brand agnostic digital fitting room, that works on the existing content and doesn't require content creation on the brand side.
To demonstrate other applications and raise interest of the community, developer created a video, demonstrating many features of the new generation of Deepfake.
YouTube: https://www.youtube.com/watch?v=15q41GjtyZs
Link: http://www.beyondbelief.ai
#deepfake #fittingroom #CV #DL
YouTube
#Deepfake 2.0: create full body fakes on any photo from one selfie in 0.1 seconds
Hi, my name is Alexey, I am from the Netherlands. Today I want to show you what I spent the last two years of my life on: the next generation of Deepfake, which can generate "fakes" from one selfie only. In contrast to the old good one, the 2.0 version generates…
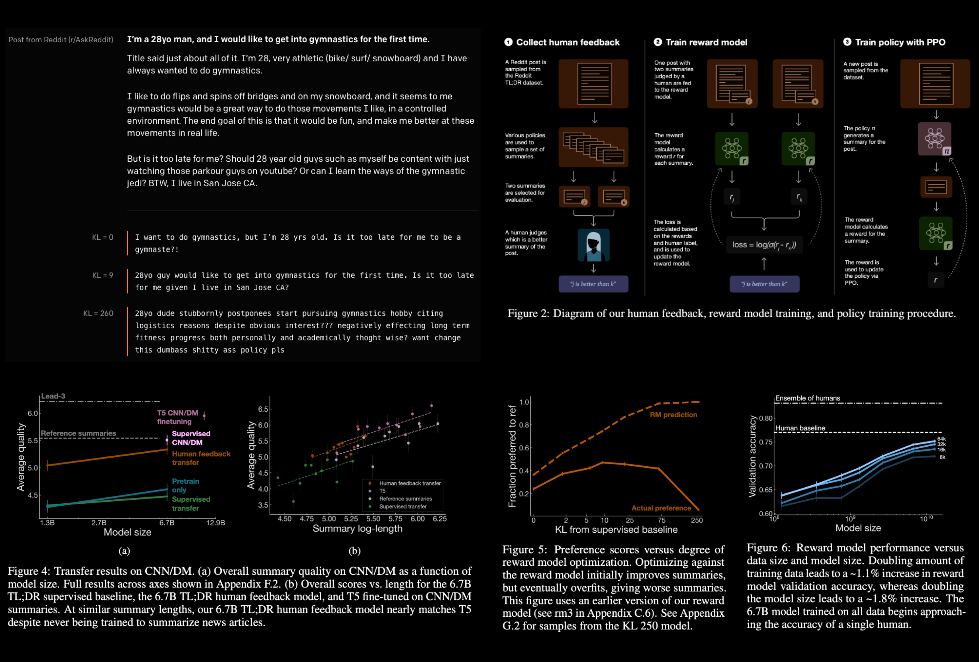
learning to summarize from human feedback
by openai
the authors collect a high-quality dataset of human comparisons between summaries, train a model to predict the human-preferred summary & use that model as a reward function to fine-tune a summarization policy using reinforcement learning. they apply this method to a version of the tl;dr dataset of reddit posts & find that their models significantly outperform both human reference summaries & much larger models fine-tuned with supervised learning alone
the researchers focused on english text summarization, as it’s a challenging problem where the notion of what makes a "good summary" is difficult to capture without human input
these models also transfer to cnn/dm news articles, producing summaries nearly as good as the human reference without any news-specific fine-tuning. furthermore, they conduct extensive analyses to understand the human feedback dataset & fine-tuned models. they establish that their reward model generalizes to a new dataset & that optimizing their reward model results in better summaries than optimizing rouge according to humans
blogpost: https://openai.com/blog/learning-to-summarize-with-human-feedback/
paper: https://arxiv.org/abs/2009.01325
code: https://github.com/openai/summarize-from-feedback
#nlp #rl #summarize
by openai
the authors collect a high-quality dataset of human comparisons between summaries, train a model to predict the human-preferred summary & use that model as a reward function to fine-tune a summarization policy using reinforcement learning. they apply this method to a version of the tl;dr dataset of reddit posts & find that their models significantly outperform both human reference summaries & much larger models fine-tuned with supervised learning alone
the researchers focused on english text summarization, as it’s a challenging problem where the notion of what makes a "good summary" is difficult to capture without human input
these models also transfer to cnn/dm news articles, producing summaries nearly as good as the human reference without any news-specific fine-tuning. furthermore, they conduct extensive analyses to understand the human feedback dataset & fine-tuned models. they establish that their reward model generalizes to a new dataset & that optimizing their reward model results in better summaries than optimizing rouge according to humans
blogpost: https://openai.com/blog/learning-to-summarize-with-human-feedback/
paper: https://arxiv.org/abs/2009.01325
code: https://github.com/openai/summarize-from-feedback
#nlp #rl #summarize
{kind=link}
NVidia released a technology to change face alignment on video
Nvidia has unveiled AI face-alignment that means you're always looking at the camera during video calls. Its new Maxine platform uses GANs to reconstruct the unseen parts of your head — just like a deepfake.
Link: https://www.theverge.com/2020/10/5/21502003/nvidia-ai-videoconferencing-maxine-platform-face-gaze-alignment-gans-compression-resolution
#NVidia #deepfake #GAN
Nvidia has unveiled AI face-alignment that means you're always looking at the camera during video calls. Its new Maxine platform uses GANs to reconstruct the unseen parts of your head — just like a deepfake.
Link: https://www.theverge.com/2020/10/5/21502003/nvidia-ai-videoconferencing-maxine-platform-face-gaze-alignment-gans-compression-resolution
#NVidia #deepfake #GAN
Forwarded from Binary Tree
Python 3.9.0 is released!
Major new features of the 3.9 series, compared to 3.8
Some of the new major new features and changes in Python 3.9 are:
- PEP 573, Module State Access from C Extension Methods
- PEP 584, Union Operators in dict
- PEP 585, Type Hinting Generics In Standard Collections
- PEP 593, Flexible function and variable annotations
- PEP 602, Python adopts a stable annual release cadence
- PEP 614, Relaxing Grammar Restrictions On Decorators
- PEP 615, Support for the IANA Time Zone Database in the Standard Library
- PEP 616, String methods to remove prefixes and suffixes
- PEP 617, New PEG parser for CPython
- BPO 38379, garbage collection does not block on resurrected objects;
- BPO 38692, os.pidfd_open added that allows process management without races and signals;
- BPO 39926, Unicode support updated to version 13.0.0;
- BPO 1635741, when Python is initialized multiple times in the same process, it does not leak memory anymore;
- A number of Python builtins (range, tuple, set, frozenset, list, dict) are now sped up using PEP 590 vectorcall;
- A number of Python modules (_abc, audioop, _bz2, _codecs, _contextvars, _crypt, _functools, _json, _locale, operator, resource, time, _weakref) now use multiphase initialization as defined by PEP 489;
- A number of standard library modules (audioop, ast, grp, _hashlib, pwd, _posixsubprocess, random, select, struct, termios, zlib) are now using the stable ABI defined by PEP 384.
#python, #release
Major new features of the 3.9 series, compared to 3.8
Some of the new major new features and changes in Python 3.9 are:
- PEP 573, Module State Access from C Extension Methods
- PEP 584, Union Operators in dict
- PEP 585, Type Hinting Generics In Standard Collections
- PEP 593, Flexible function and variable annotations
- PEP 602, Python adopts a stable annual release cadence
- PEP 614, Relaxing Grammar Restrictions On Decorators
- PEP 615, Support for the IANA Time Zone Database in the Standard Library
- PEP 616, String methods to remove prefixes and suffixes
- PEP 617, New PEG parser for CPython
- BPO 38379, garbage collection does not block on resurrected objects;
- BPO 38692, os.pidfd_open added that allows process management without races and signals;
- BPO 39926, Unicode support updated to version 13.0.0;
- BPO 1635741, when Python is initialized multiple times in the same process, it does not leak memory anymore;
- A number of Python builtins (range, tuple, set, frozenset, list, dict) are now sped up using PEP 590 vectorcall;
- A number of Python modules (_abc, audioop, _bz2, _codecs, _contextvars, _crypt, _functools, _json, _locale, operator, resource, time, _weakref) now use multiphase initialization as defined by PEP 489;
- A number of standard library modules (audioop, ast, grp, _hashlib, pwd, _posixsubprocess, random, select, struct, termios, zlib) are now using the stable ABI defined by PEP 384.
#python, #release