
learning to summarize from human feedback
by openai
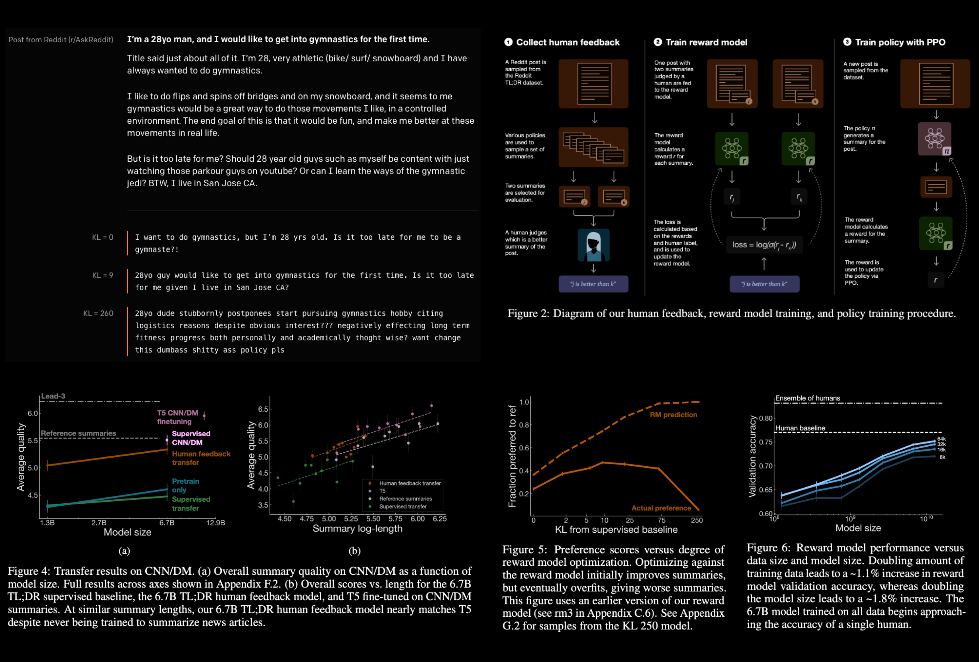
the authors collect a high-quality dataset of human comparisons between summaries, train a model to predict the human-preferred summary & use that model as a reward function to fine-tune a summarization policy using reinforcement learning. they apply this method to a version of the tl;dr dataset of reddit posts & find that their models significantly outperform both human reference summaries & much larger models fine-tuned with supervised learning alone
the researchers focused on english text summarization, as it’s a challenging problem where the notion of what makes a "good summary" is difficult to capture without human input
these models also transfer to cnn/dm news articles, producing summaries nearly as good as the human reference without any news-specific fine-tuning. furthermore, they conduct extensive analyses to understand the human feedback dataset & fine-tuned models. they establish that their reward model generalizes to a new dataset & that optimizing their reward model results in better summaries than optimizing rouge according to humans
blogpost: https://openai.com/blog/learning-to-summarize-with-human-feedback/
paper: https://arxiv.org/abs/2009.01325
code: https://github.com/openai/summarize-from-feedback
#nlp #rl #summarize
by openai
the authors collect a high-quality dataset of human comparisons between summaries, train a model to predict the human-preferred summary & use that model as a reward function to fine-tune a summarization policy using reinforcement learning. they apply this method to a version of the tl;dr dataset of reddit posts & find that their models significantly outperform both human reference summaries & much larger models fine-tuned with supervised learning alone
the researchers focused on english text summarization, as it’s a challenging problem where the notion of what makes a "good summary" is difficult to capture without human input
these models also transfer to cnn/dm news articles, producing summaries nearly as good as the human reference without any news-specific fine-tuning. furthermore, they conduct extensive analyses to understand the human feedback dataset & fine-tuned models. they establish that their reward model generalizes to a new dataset & that optimizing their reward model results in better summaries than optimizing rouge according to humans
blogpost: https://openai.com/blog/learning-to-summarize-with-human-feedback/
paper: https://arxiv.org/abs/2009.01325
code: https://github.com/openai/summarize-from-feedback
#nlp #rl #summarize
{kind=link}