
How Tesla Truck design affects design of all autonomous vehicles
#design #selfdriving #autonomousvehicle #rl #scania
#design #selfdriving #autonomousvehicle #rl #scania
Data Science by ODS.ai 🦜
🤖 The NetHack Learning Environment #Facebook launched new Reinforcement Learning environment for training agents based on #NetHack game. Nethack has nothing to do with what is considered common cybersecurity now, but it is an early terminal-based Minecraft…
Update from #Facebook on #Nethack learning Environment.
Link: https://ai.facebook.com/blog/nethack-learning-environment-to-advance-deep-reinforcement-learning
Publication: https://arxiv.org/abs/2006.13760
#RL
Link: https://ai.facebook.com/blog/nethack-learning-environment-to-advance-deep-reinforcement-learning
Publication: https://arxiv.org/abs/2006.13760
#RL
Salesforce opensourced AI-framework for economic RL
AI Economist is capable of learning dynamic tax policies that optimize equality along with productivity in simulated economies, outperforming alternative tax systems.
Github: https://github.com/salesforce/ai-economist
Blog post with results: https://blog.einstein.ai/the-ai-economist/
Blog post with release: https://blog.einstein.ai/the-ai-economist-moonshot/
#Salesforce #gym #RL #economics #AIEconomics #animalcrossing #AIEconomist
AI Economist is capable of learning dynamic tax policies that optimize equality along with productivity in simulated economies, outperforming alternative tax systems.
Github: https://github.com/salesforce/ai-economist
Blog post with results: https://blog.einstein.ai/the-ai-economist/
Blog post with release: https://blog.einstein.ai/the-ai-economist-moonshot/
#Salesforce #gym #RL #economics #AIEconomics #animalcrossing #AIEconomist
YouTube
Introducing the AI Economist
See how Salesforce Research is using AI to drive positive, social change, with the AI Economist.
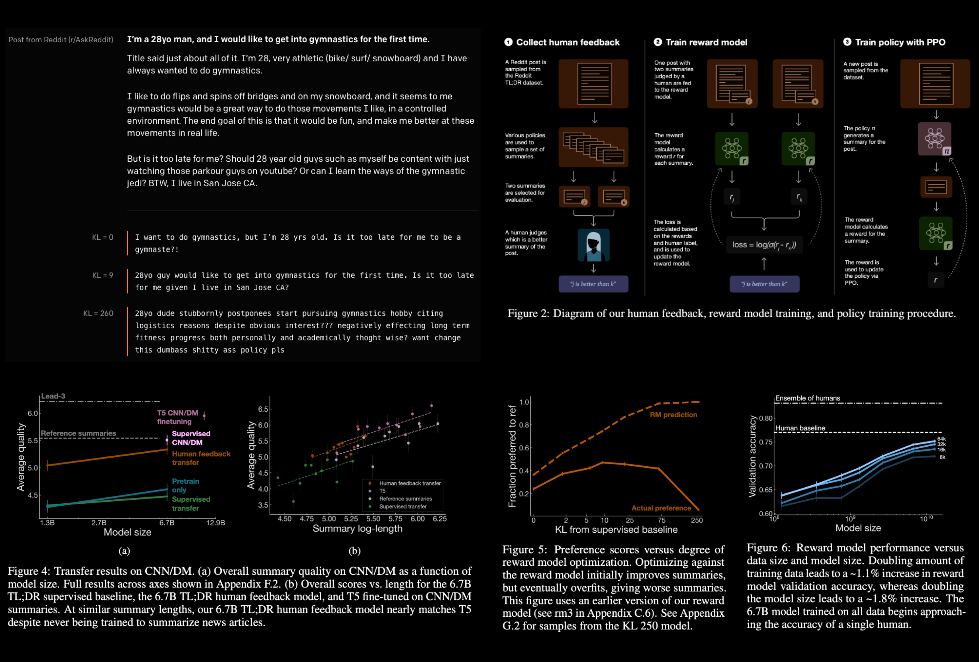
learning to summarize from human feedback
by openai
the authors collect a high-quality dataset of human comparisons between summaries, train a model to predict the human-preferred summary & use that model as a reward function to fine-tune a summarization policy using reinforcement learning. they apply this method to a version of the tl;dr dataset of reddit posts & find that their models significantly outperform both human reference summaries & much larger models fine-tuned with supervised learning alone
the researchers focused on english text summarization, as it’s a challenging problem where the notion of what makes a "good summary" is difficult to capture without human input
these models also transfer to cnn/dm news articles, producing summaries nearly as good as the human reference without any news-specific fine-tuning. furthermore, they conduct extensive analyses to understand the human feedback dataset & fine-tuned models. they establish that their reward model generalizes to a new dataset & that optimizing their reward model results in better summaries than optimizing rouge according to humans
blogpost: https://openai.com/blog/learning-to-summarize-with-human-feedback/
paper: https://arxiv.org/abs/2009.01325
code: https://github.com/openai/summarize-from-feedback
#nlp #rl #summarize
by openai
the authors collect a high-quality dataset of human comparisons between summaries, train a model to predict the human-preferred summary & use that model as a reward function to fine-tune a summarization policy using reinforcement learning. they apply this method to a version of the tl;dr dataset of reddit posts & find that their models significantly outperform both human reference summaries & much larger models fine-tuned with supervised learning alone
the researchers focused on english text summarization, as it’s a challenging problem where the notion of what makes a "good summary" is difficult to capture without human input
these models also transfer to cnn/dm news articles, producing summaries nearly as good as the human reference without any news-specific fine-tuning. furthermore, they conduct extensive analyses to understand the human feedback dataset & fine-tuned models. they establish that their reward model generalizes to a new dataset & that optimizing their reward model results in better summaries than optimizing rouge according to humans
blogpost: https://openai.com/blog/learning-to-summarize-with-human-feedback/
paper: https://arxiv.org/abs/2009.01325
code: https://github.com/openai/summarize-from-feedback
#nlp #rl #summarize
{kind=link}
Ford is reported to work on a two-leg human-shaped delivery robot
#RL #bostondynamics #delivery #autonomousrobots
#RL #bostondynamics #delivery #autonomousrobots
Waymo started driverless tests in Phoenix
This #Google company plans to expand tests to cover whole state later.
Blog: https://blog.waymo.com/2020/10/waymo-is-opening-its-fully-driverless.html
Redditers’ experience: https://www.reddit.com/r/waymo/comments/j7rphd/4_minute_full_video_in_waymo_one_no_driver_short/
#autonomousrobots #selfdriving #rl #DL
This #Google company plans to expand tests to cover whole state later.
Blog: https://blog.waymo.com/2020/10/waymo-is-opening-its-fully-driverless.html
Redditers’ experience: https://www.reddit.com/r/waymo/comments/j7rphd/4_minute_full_video_in_waymo_one_no_driver_short/
#autonomousrobots #selfdriving #rl #DL
QVMix and QVMix-Max: Extending the Deep Quality-Value Family of Algorithms to Cooperative Multi-Agent Reinforcement Learning
Paper extends the Deep Quality-Value (DQV) family of al-
gorithms to multi-agent reinforcement learning and outperforms #SOTA
ArXiV: https://arxiv.org/abs/2012.12062
#DQV #RL #Starcraft
Paper extends the Deep Quality-Value (DQV) family of al-
gorithms to multi-agent reinforcement learning and outperforms #SOTA
ArXiV: https://arxiv.org/abs/2012.12062
#DQV #RL #Starcraft
This media is not supported in your browser
VIEW IN TELEGRAM
Habitat 2.0: Training home assistant robots with faster simulation and new benchmarks
Facebook released a new simulation platform to train robots in. Yeah, virtual robots in virtual environment, which can be a real space replica. This work brings us closer to domestic use of assistive robots.
Project website: https://ai.facebook.com/blog/habitat-20-training-home-assistant-robots-with-faster-simulation-and-new-benchmarks
Paper: https://ai.facebook.com/research/publications/habitat-2.0-training-home-assistants-to-rearrange-their-habitat
#Facebook #DigitalTwin #VR #RL #assistiverobots
Facebook released a new simulation platform to train robots in. Yeah, virtual robots in virtual environment, which can be a real space replica. This work brings us closer to domestic use of assistive robots.
Project website: https://ai.facebook.com/blog/habitat-20-training-home-assistant-robots-with-faster-simulation-and-new-benchmarks
Paper: https://ai.facebook.com/research/publications/habitat-2.0-training-home-assistants-to-rearrange-their-habitat
#Facebook #DigitalTwin #VR #RL #assistiverobots
Mava: a scalable, research framework for multi-agent reinforcement learning
The framework integrates with popular MARL environments such as PettingZoo, SMAC, RoboCup, OpenSpiel, Flatland , as well as a few custom environments.
Mava includes distributed implementations of multi-agent versions of ddpg, d4pg, dqn, ppo, as well as DIAL, VDN and QMIX.
ArXiV: https://arxiv.org/pdf/2107.01460.pdf
GitHub: https://github.com/instadeepai/Mava
#MARL #RL #dl
The framework integrates with popular MARL environments such as PettingZoo, SMAC, RoboCup, OpenSpiel, Flatland , as well as a few custom environments.
Mava includes distributed implementations of multi-agent versions of ddpg, d4pg, dqn, ppo, as well as DIAL, VDN and QMIX.
ArXiV: https://arxiv.org/pdf/2107.01460.pdf
GitHub: https://github.com/instadeepai/Mava
#MARL #RL #dl
GitHub
GitHub - instadeepai/Mava: 🦁 A research-friendly codebase for fast experimentation of multi-agent reinforcement learning in JAX
🦁 A research-friendly codebase for fast experimentation of multi-agent reinforcement learning in JAX - instadeepai/Mava
Acquisition of Chess Knowledge in AlphaZero
69-pages paper of analysis how #AlphaZero plays chess. TLDR: lots of concepts self-learned by neural network can be mapped to human concepts.
This means that generally speaking we can train neural networks to do some task and then learn something from them. Opposite is also true: we might imagine teaching neural networks some human concepts in order to maek them more efficient.
Post: https://en.chessbase.com/post/acquisition-of-chess-knowledge-in-alphazero
Paper: https://arxiv.org/pdf/2111.09259.pdf
#RL
69-pages paper of analysis how #AlphaZero plays chess. TLDR: lots of concepts self-learned by neural network can be mapped to human concepts.
This means that generally speaking we can train neural networks to do some task and then learn something from them. Opposite is also true: we might imagine teaching neural networks some human concepts in order to maek them more efficient.
Post: https://en.chessbase.com/post/acquisition-of-chess-knowledge-in-alphazero
Paper: https://arxiv.org/pdf/2111.09259.pdf
#RL
Chess News
Acquisition of Chess Knowledge in AlphaZero
Researchers at DeepMind and Google Brain, in collaboration with Grandmaster Vladimir Kramnik, are working to explore what chess can teach us about AI and vice versa. Using Chessbase’s extensive historical chess data along with the AlphaZero neural network…
👍3💩1
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://yangx.top/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://yangx.top/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
👍56🔥15❤8🥰2😁2🎉2⚡1👎1👏1
CORL: Offline Reinforcement Learning Library
Offline RL is a fresh paradigm that makes RL similar to the supervised learning, thus making it better applicable to the real-world problems. There is a whole bunch of recently developed Offline RL aglorithms, however, there was nots many of reliable open-sourced implementations for such algorithms
Our friends from @tinkoffai do some research in this direction and they recently open-sourced their internal offline RL library.
The main features are:
- Single-file implementations
- SOTA algorithms (Decision Transformer, AWAC, BC, CQL, IQL, TD3+BC, SAC-N, EDAC)
- Benchmarked on widely used D4RL datasets (results match performances reported in the original papers)
- Wandb logs for all of the experiments
Hope you will like it and the whole new world of Offline RL!
Github: https://github.com/tinkoff-ai/CORL
#tinkoff #RL #offline_lib
Offline RL is a fresh paradigm that makes RL similar to the supervised learning, thus making it better applicable to the real-world problems. There is a whole bunch of recently developed Offline RL aglorithms, however, there was nots many of reliable open-sourced implementations for such algorithms
Our friends from @tinkoffai do some research in this direction and they recently open-sourced their internal offline RL library.
The main features are:
- Single-file implementations
- SOTA algorithms (Decision Transformer, AWAC, BC, CQL, IQL, TD3+BC, SAC-N, EDAC)
- Benchmarked on widely used D4RL datasets (results match performances reported in the original papers)
- Wandb logs for all of the experiments
Hope you will like it and the whole new world of Offline RL!
Github: https://github.com/tinkoff-ai/CORL
#tinkoff #RL #offline_lib
GitHub
GitHub - tinkoff-ai/CORL: High-quality single-file implementations of SOTA Offline and Offline-to-Online RL algorithms: AWAC, BC…
High-quality single-file implementations of SOTA Offline and Offline-to-Online RL algorithms: AWAC, BC, CQL, DT, EDAC, IQL, SAC-N, TD3+BC, LB-SAC, SPOT, Cal-QL, ReBRAC - tinkoff-ai/CORL
🔥25👍16🌚5💩3👏1😁1
Forwarded from Machinelearning
Глубокие исследовательские агенты — не просто чат‑боты, а полноценные ИИ‑ассистенты, способные искать информацию, взаимодействовать с инструментами, планировать и писать отчёты. Ниже — 10 мощных open‑source проектов, которые уже можно протестировать:
1. DeerFlow — модульная система от Bytedance: DeerFlow — open‑source фреймворк от Bytedance для создания модульных LLM-агентов.
Поддерживает:
- планирование действий,
- анализ кода,
- генерацию отчётов (включая Text-to-Speech),
- адаптивную интеграцию инструментов.
Создан для исследований, автоматизации и построения сложных агентных пайплайнов.
https://github.com/bytedance/deer-flow
2. Alita — самообучающийся агент с поддержкой Model Context Protocols (MCP), всё в одном модуле. Alita — агент, который сам придумывает, как ему расширить себя, не полагаясь на заранее написанные сценарии, и уже демонстрирует топовые результаты на сложных тестах.
https://github.com/CharlesQ9/Alita
3. WebThinker — автономный веб‑поиск с логикой "думай‑ищи‑пиши", RL‑обучением и глубокой навигацией
https://github.com/RUC-NLPIR/WebThinker
4. SimpleDeepSearcher — это лёгкий, но эффективный open‑source фреймворк от RUCAIBox, предназначенный для автономного веб-поиска через импровизированные многотуровые сессии:
- Использует Supervised Fine‑Tuning (SFT) вместо сложного RL, что значительно упрощает обучение и снижает вычислительные затраты
- Генерирует реалистичные траектории поиска и рассуждений, симулируя поведение пользователя в живом поисковом окружении .
- Критически отбирает данные по нескольким критериям качества: разнообразие запросов, сложность, структура ответов
5. AgenticSeek — приватный on‑device ассистент с выбором эксперта под задачу и голосовым управлением
https://github.com/Fosowl/agenticSeek
6. Suna — универсальный ассистент: браузер, CLI, работа с файлами, API, деплой
https://github.com/kortix-ai/suna
7. DeepResearcher — это комплексный open-source фреймворк от GAIR‑NLP, предназначенный для обучения LLM‑агентов, способных проводить глубокие исследования в автономном режиме, взаимодействуя с вебом. Использует несколько агентов‑браузеров, которые совместно исследуют веб и обрабатывают информацию
https://github.com/GAIR-NLP/DeepResearcher
8. Search‑R1 — агент на PPO/GRPO с поддержкой LLaMA3, Qwen2.5 и кастомных поисковиков. Агент учится эффективному циклу «думай — ищи — думай — отвечай» через RL, достигая важных улучшений в точности ответов и эффективности поиска.
https://github.com/PeterGriffinJin/Search-R1
9. ReCall — это фреймворк на основе RL, который учит LLM "должным образом" вызывать и комбинировать инструменты, используя сгенерированные задачи, без необходимости вручную собирать примеры вызовов — и всё это в открытом доступе.
https://github.com/Agent-RL/ReCall
10. OWL — мультиагентная система на CAMEL‑AI для динамического взаимодействия между агентами
https://github.com/camel-ai/owl
Агенты умеют планировать, взаимодействовать с браузером, запускать скрипты, интегрироваться с API и работать автономно.
Всё проекты — с открытым кодом. Можно изучить, собрать и доработать под свои задачи.
@ai_machinelearning_big_data
#ml #rl #aiagents #ai #agents
Please open Telegram to view this post
VIEW IN TELEGRAM
❤11👍2🔥1