
Clothing Dataset: Call for Action
Help to collect a public-domain dataset with images of clothes
Medium post: https://medium.com/data-science-insider/clothing-dataset-call-for-action-3cad023246c1
#dataset #clothing #cv #calltoarms
Help to collect a public-domain dataset with images of clothes
Medium post: https://medium.com/data-science-insider/clothing-dataset-call-for-action-3cad023246c1
#dataset #clothing #cv #calltoarms
{kind=link}
Forwarded from Spark in me (Alexander)
Ukrainian Open STT 1000 Hours
Following the path of Open STT in Russian, now you can enjoy a similar dataset in Ukrainian:
- Torrent Link
- GitHub Link
Congratulations to our Ukrainian friends for finally publishing a diverse easily downloadable dataset!
Their pages / dataset UX is still a bit rough on the edges, but compared how fast for example Common Voice accumulates data (130 hours for Russian and 43 hours for Ukrainian), UA Open STT and Open STT remain the best resource for respective languages to date.
Also unlike the majority of STT datasets which are (i) behind a paywall or sponsored by corporations (ii) have limited scope / domains (iii) fit some sort of agenda (i.e. use more GPUs than necessary, use our bloated tools, etc), this dataset is legit made by real people.
Also recently corporations have taken up the trend of rehashing publicly available data, which is cool, but unique data is still nowhere to be seen for obvious reasons (except for Common Voice, which is decent only for English).
#dataset
Following the path of Open STT in Russian, now you can enjoy a similar dataset in Ukrainian:
- Torrent Link
- GitHub Link
Congratulations to our Ukrainian friends for finally publishing a diverse easily downloadable dataset!
Their pages / dataset UX is still a bit rough on the edges, but compared how fast for example Common Voice accumulates data (130 hours for Russian and 43 hours for Ukrainian), UA Open STT and Open STT remain the best resource for respective languages to date.
Also unlike the majority of STT datasets which are (i) behind a paywall or sponsored by corporations (ii) have limited scope / domains (iii) fit some sort of agenda (i.e. use more GPUs than necessary, use our bloated tools, etc), this dataset is legit made by real people.
Also recently corporations have taken up the trend of rehashing publicly available data, which is cool, but unique data is still nowhere to be seen for obvious reasons (except for Common Voice, which is decent only for English).
#dataset
GitHub
GitHub - snakers4/open_stt: Open STT
Open STT. Contribute to snakers4/open_stt development by creating an account on GitHub.
👍1
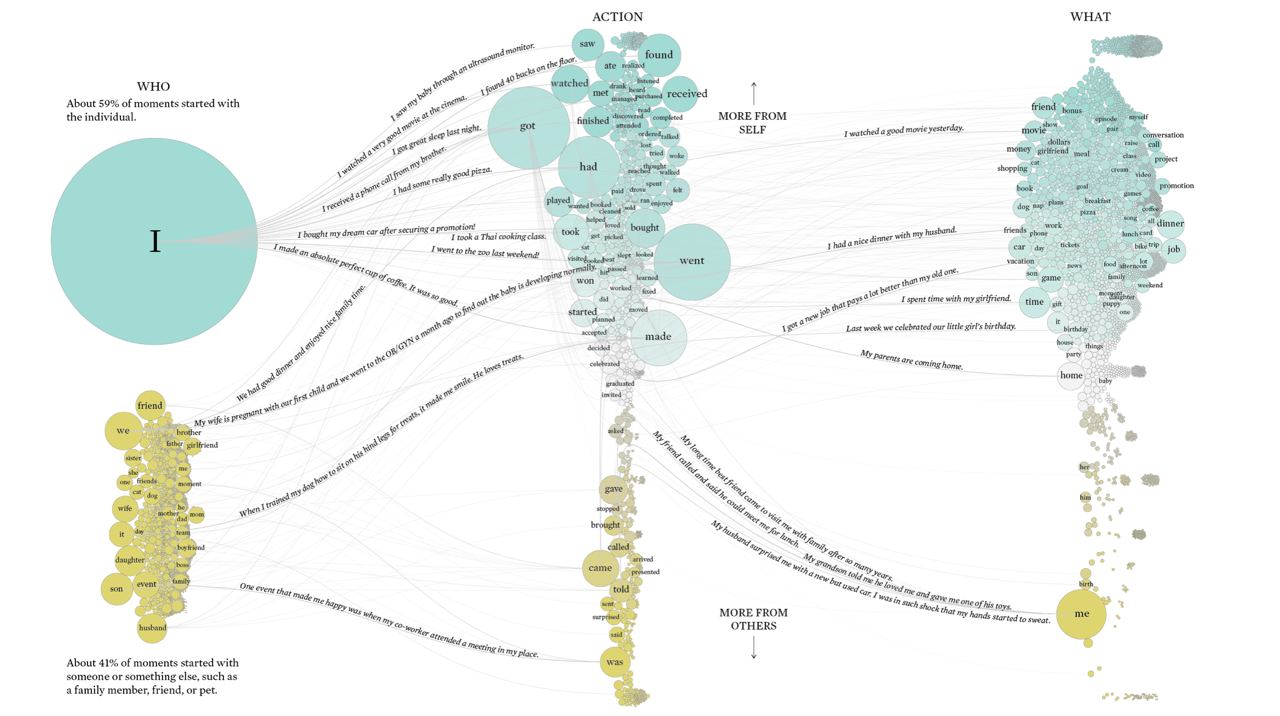
Counting Happiness and Where it Comes From
Researches asked 10 000 Mechanical Turk participants to name 10 things which are making them happy, resulting in creation of HappyDB.
And since that DB is open, Nathan Yau analyzed and vizualized this database in the perspective of subjects and actions, producing intersting visualization.
Hope that daily reading @opendatascience makes you at least content, if not happy.
Happines reason visualization link: https://flowingdata.com/2021/07/29/counting-happiness
HappyDB link: https://megagon.ai/projects/happydb-a-happiness-database-of-100000-happy-moments/
#dataset #emotions #visualization
Researches asked 10 000 Mechanical Turk participants to name 10 things which are making them happy, resulting in creation of HappyDB.
And since that DB is open, Nathan Yau analyzed and vizualized this database in the perspective of subjects and actions, producing intersting visualization.
Hope that daily reading @opendatascience makes you at least content, if not happy.
Happines reason visualization link: https://flowingdata.com/2021/07/29/counting-happiness
HappyDB link: https://megagon.ai/projects/happydb-a-happiness-database-of-100000-happy-moments/
#dataset #emotions #visualization
{kind=link}
👍2
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://yangx.top/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://yangx.top/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
👍56🔥15❤8🥰2😁2🎉2⚡1👎1👏1
Forwarded from Machinelearning
🗿 StyleNeRF: A Style-based 3D-Aware Generator for High-resolution Image Synthesis
Github: https://github.com/facebookresearch/StyleNeRF
Video: http://jiataogu.me/style_nerf
Paper: https://arxiv.org/abs/2110.08985
Project: http://jiataogu.me/style_nerf/
Dataset: https://github.com/facebookresearch/StyleNeRF#dataset
@ai_machinelearning_big_data
Github: https://github.com/facebookresearch/StyleNeRF
Video: http://jiataogu.me/style_nerf
Paper: https://arxiv.org/abs/2110.08985
Project: http://jiataogu.me/style_nerf/
Dataset: https://github.com/facebookresearch/StyleNeRF#dataset
@ai_machinelearning_big_data
👍23❤7💩1
Segment Anything
The Segment Anything project aims to democratize image segmentation in computer vision, a core task used across various applications such as scientific imagery analysis and photo editing. Traditionally, accurate segmentation models require specialized expertise, AI training infrastructure, and large amounts of annotated data. This project introduces a new task, dataset, and model for image segmentation to overcome these challenges and make segmentation more accessible.
The researchers are releasing the Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), the largest segmentation dataset to date. These resources will enable a wide range of applications and further research into foundational models for computer vision. The SA-1B dataset is available for research purposes, while the SAM is provided under the permissive Apache 2.0 open license. Users can explore the demo to try SAM with their own images.
Paper link: https://arxiv.org/abs/2304.02643
Code link: https://github.com/facebookresearch/segment-anything
Demo link: https://segment-anything.com/demo
Blogpost link: https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
Dataset link: https://ai.facebook.com/datasets/segment-anything/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-sam
#deeplearning #cv #pytorch #imagesegmentation #dataset
The Segment Anything project aims to democratize image segmentation in computer vision, a core task used across various applications such as scientific imagery analysis and photo editing. Traditionally, accurate segmentation models require specialized expertise, AI training infrastructure, and large amounts of annotated data. This project introduces a new task, dataset, and model for image segmentation to overcome these challenges and make segmentation more accessible.
The researchers are releasing the Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), the largest segmentation dataset to date. These resources will enable a wide range of applications and further research into foundational models for computer vision. The SA-1B dataset is available for research purposes, while the SAM is provided under the permissive Apache 2.0 open license. Users can explore the demo to try SAM with their own images.
Paper link: https://arxiv.org/abs/2304.02643
Code link: https://github.com/facebookresearch/segment-anything
Demo link: https://segment-anything.com/demo
Blogpost link: https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
Dataset link: https://ai.facebook.com/datasets/segment-anything/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-sam
#deeplearning #cv #pytorch #imagesegmentation #dataset
{kind=link}
🔥13👍5❤1
Forwarded from Machinelearning
NVIDIA представила новый подход к обучению моделей для сложных математических задач, заняв первое место в конкурсе Kaggle AIMO-2.
Секрет — в огромном датасете OpenMathReasoning, который состоит из 540 тыс. уникальных задач с Art of Problem Solving, 3,2 млн. многошаговых решений (CoT) и 1,7 млн. примеров с интеграцией кода (TIR).
Для сравнения: это в разы больше, чем в популярных аналогах MATH и GSM8K. Все это дополнено 566 тыс. примеров для обучения генеративному выбору решений (GenSelect) — методу, который лучше, чем классическое голосование большинством.
OpenMathReasoning создавался тщательно и ответственно. Сначала задачи фильтровались через Qwen2.5-32B, чтобы убрать простые или дублирующие бенчмарки. Затем DeepSeek-R1 и QwQ-32B генерировали решения, а итеративная тренировка с жесткой фильтрацией улучшала качество. Например, код в TIR-решениях должен был не просто проверять шаги, а давать принципиально новые вычисления — вроде перебора вариантов или численного решения уравнений.
Модели OpenMath-Nemotron (1,5B–32B параметров), обученные на этом наборе данных показали SOTA-результаты. 14B-версия в режиме TIR решает 76,3% задач AIME24 против 65,8% у базового DeepSeek-R1. А с GenSelect, который анализирует 16 кандидатов за раз, точность взлетает до 90%. Даже 1,5B-модель с GenSelect обгоняет 32B-гиганты в отдельных тестах.
@ai_machinelearning_big_data
#AI #ML #Math #Dataset #NVIDIA
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍5🔥3❤1