
ODS breakfast in Paris! See you this Saturday at 10:30 at Malongo Café, 50 Rue Saint-André des Arts.
TabNine showed deep learning code autocomplete tool based on GPT-2 architecture.
Video demonstrates the concept. Hopefully, it will allow us to write code with less bugs, not more.
Link: https://tabnine.com/blog/deep
Something relatively similar by Microsoft: https://visualstudio.microsoft.com/ru/services/intellicode
#GPT2 #TabNine #autocomplete #product #NLP #NLU #codegeneration
Video demonstrates the concept. Hopefully, it will allow us to write code with less bugs, not more.
Link: https://tabnine.com/blog/deep
Something relatively similar by Microsoft: https://visualstudio.microsoft.com/ru/services/intellicode
#GPT2 #TabNine #autocomplete #product #NLP #NLU #codegeneration
Great collection of practical rules for routine DS engineering / research job.
Machine Learning in a company is 10% Data Science & 90% other challenges, this pdf provides a great deal of principals and solutions to deal with them.
We can only recommend saving this post to your Saved Messages by forwarding it to yourself.
Link: http://martin.zinkevich.org/rules_of_ml/rules_of_ml.pdf
#cheatsheet #advice #practical #common #shouldbesaved
Machine Learning in a company is 10% Data Science & 90% other challenges, this pdf provides a great deal of principals and solutions to deal with them.
We can only recommend saving this post to your Saved Messages by forwarding it to yourself.
Link: http://martin.zinkevich.org/rules_of_ml/rules_of_ml.pdf
#cheatsheet #advice #practical #common #shouldbesaved
YouTokenToMe, new tool for text tokenisation from VK team
Meet new enhanced tokenisation tool on steroids. Works 7-10 times faster alphabetic languages and 40 to 50 times faster on logographic languages, than alternatives.
Under the hood (watch source) there is C++ implementation with python bindings, using Byte Pair Encoding (BPE) algorithm. YouTokenToMe beats #SentencePiece by Google and #fastBPE, created by a researcher from Facebook AI Research in terms of speed.
Github: https://github.com/vkcom/YouTokenToMe
Medium: https://medium.com/@vktech/youtokentome-a-tool-for-quick-text-tokenization-from-the-vk-team-aa6341215c5a
Byte Pair Encoding: https://arxiv.org/abs/1508.07909
Meet new enhanced tokenisation tool on steroids. Works 7-10 times faster alphabetic languages and 40 to 50 times faster on logographic languages, than alternatives.
Under the hood (watch source) there is C++ implementation with python bindings, using Byte Pair Encoding (BPE) algorithm. YouTokenToMe beats #SentencePiece by Google and #fastBPE, created by a researcher from Facebook AI Research in terms of speed.
Github: https://github.com/vkcom/YouTokenToMe
Medium: https://medium.com/@vktech/youtokentome-a-tool-for-quick-text-tokenization-from-the-vk-team-aa6341215c5a
Byte Pair Encoding: https://arxiv.org/abs/1508.07909
{kind=link}
Data Science by ODS.ai 🦜
YouTokenToMe, new tool for text tokenisation from VK team Meet new enhanced tokenisation tool on steroids. Works 7-10 times faster alphabetic languages and 40 to 50 times faster on logographic languages, than alternatives. Under the hood (watch source)…
This improvement for everyday used toolset deserves minimum 50 claps at Medium and a Star on github!
Let’s give VK research team appreciation from the community they deserve 👏!!
Let’s give VK research team appreciation from the community they deserve 👏!!
What’s wrong with transformer architecture: an overview
How the Transformers broke NLP leaderboards and why that can be bad for industry.
Link: https://hackingsemantics.xyz/2019/leaderboards/
#NLP #overview #transformer #BERT #XLNet
How the Transformers broke NLP leaderboards and why that can be bad for industry.
Link: https://hackingsemantics.xyz/2019/leaderboards/
#NLP #overview #transformer #BERT #XLNet
Hacking semantics
How the Transformers broke NLP leaderboards
With the huge Transformer-based models such as BERT, GPT-2, and XLNet, are we losing track of how the state-of-the-art performance is achieved?
Simultaneous food and facial recognition at a Foxconn factory canteen, Shenzhen China
#video #foodlearning #facerecogniction #dl #cv #foxconn
#video #foodlearning #facerecogniction #dl #cv #foxconn
Deep Learning Image Segmentation for Ecommerce Catalogue Visual Search
Microsoft’s article on image segmentation
Link: https://www.microsoft.com/developerblog/2018/04/18/deep-learning-image-segmentation-for-ecommerce-catalogue-visual-search/
#CV #DL #Segmentation #Microsoft
Microsoft’s article on image segmentation
Link: https://www.microsoft.com/developerblog/2018/04/18/deep-learning-image-segmentation-for-ecommerce-catalogue-visual-search/
#CV #DL #Segmentation #Microsoft
{kind=link}
Google AI research on learning better simulation methods for partial differential equations
New research shows how machine learning can improve high-performance computing for solving partial differential equations, with potential applications that range from modeling #climatechange to simulating fusion reactions. Learn all about it here
Link: https://ai.googleblog.com/2019/07/learning-better-simulation-methods-for.html
#PDE #DE #GoogleAI
New research shows how machine learning can improve high-performance computing for solving partial differential equations, with potential applications that range from modeling #climatechange to simulating fusion reactions. Learn all about it here
Link: https://ai.googleblog.com/2019/07/learning-better-simulation-methods-for.html
#PDE #DE #GoogleAI
On the concept of 'intellectual debt'
There is technical debt — when you know you should rewrite some stuff, or implement some features, but they don't seem critical at the moment. So article introduces a concept of 'intellectual debt', which resies with more broad and common use of #MachineLearning and #DeepLearning (specially, the latter). What happens when AI gives us seemingly correct answers that we wouldn't have thought of ourselves, without any theory to explain them?
Link: https://www.newyorker.com/tech/annals-of-technology/the-hidden-costs-of-automated-thinking
#Meta #common #lyrics
There is technical debt — when you know you should rewrite some stuff, or implement some features, but they don't seem critical at the moment. So article introduces a concept of 'intellectual debt', which resies with more broad and common use of #MachineLearning and #DeepLearning (specially, the latter). What happens when AI gives us seemingly correct answers that we wouldn't have thought of ourselves, without any theory to explain them?
Link: https://www.newyorker.com/tech/annals-of-technology/the-hidden-costs-of-automated-thinking
#Meta #common #lyrics
The New Yorker
The Hidden Costs of Automated Thinking
Overreliance on artificial intelligence may put us in intellectual debt.
New dataset with adversarial examples
Natural Adversarial Examples are real-world and unmodified examples which cause classifiers to be consistently confused. The new dataset has 7,500 images, which we personally labeled over several months.
ArXiV: https://arxiv.org/abs/1907.07174
Dataset and code: https://github.com/hendrycks/natural-adv-examples
#Dataset #Adversarial
Natural Adversarial Examples are real-world and unmodified examples which cause classifiers to be consistently confused. The new dataset has 7,500 images, which we personally labeled over several months.
ArXiV: https://arxiv.org/abs/1907.07174
Dataset and code: https://github.com/hendrycks/natural-adv-examples
#Dataset #Adversarial
{kind=link}
Release of 27 pretrained models for NLP / NLU for PyTorch
Hugging Face open sources a new library that contains up to 27 pretrained models to conduct state-of-the-art NLP/NLU tasks.
Link: https://medium.com/dair-ai/pytorch-transformers-for-state-of-the-art-nlp-3348911ffa5b
#SOTA #NLP #NLU #PyTorch #opensource
Hugging Face open sources a new library that contains up to 27 pretrained models to conduct state-of-the-art NLP/NLU tasks.
Link: https://medium.com/dair-ai/pytorch-transformers-for-state-of-the-art-nlp-3348911ffa5b
#SOTA #NLP #NLU #PyTorch #opensource
{kind=link}
ODS breakfast in Paris! See you this Saturday at 10:30 at Malongo Café, 50 Rue Saint-André des Arts.
Filter autoselect in VSCO by Google
#VSCO used #TensorFlow Lite to develop the 'For This Photo' feature, which uses on-device ML to suggest photo filter presets from a curated list.
YouTube: https://www.youtube.com/watch?v=fHbjfeitIvE
Link: https://medium.com/tensorflow/suggesting-presets-for-images-building-for-this-photo-at-vsco-9b94041c4ba4
#mobile #device #cv #dl
#VSCO used #TensorFlow Lite to develop the 'For This Photo' feature, which uses on-device ML to suggest photo filter presets from a curated list.
YouTube: https://www.youtube.com/watch?v=fHbjfeitIvE
Link: https://medium.com/tensorflow/suggesting-presets-for-images-building-for-this-photo-at-vsco-9b94041c4ba4
#mobile #device #cv #dl
YouTube
VSCO — For This Photo
Baidu's recent paper: Hubless Nearest Neighbor Search
Hubless Nearest Neighbor Search, a new method for Bilingual Lexicon Induction, improves retrieval accuracy significantly. Empirical results show HNN outperforms NN, ISF and other state-of-the-art.
Github: https://github.com/baidu-research/HNN
Paper: https://github.com/baidu-research/HNN/blob/master/doc/HNN.pdf
#ACL2019 #NLP #NLU
Hubless Nearest Neighbor Search, a new method for Bilingual Lexicon Induction, improves retrieval accuracy significantly. Empirical results show HNN outperforms NN, ISF and other state-of-the-art.
Github: https://github.com/baidu-research/HNN
Paper: https://github.com/baidu-research/HNN/blob/master/doc/HNN.pdf
#ACL2019 #NLP #NLU
GitHub
baidu-research/HNN
Contribute to baidu-research/HNN development by creating an account on GitHub.
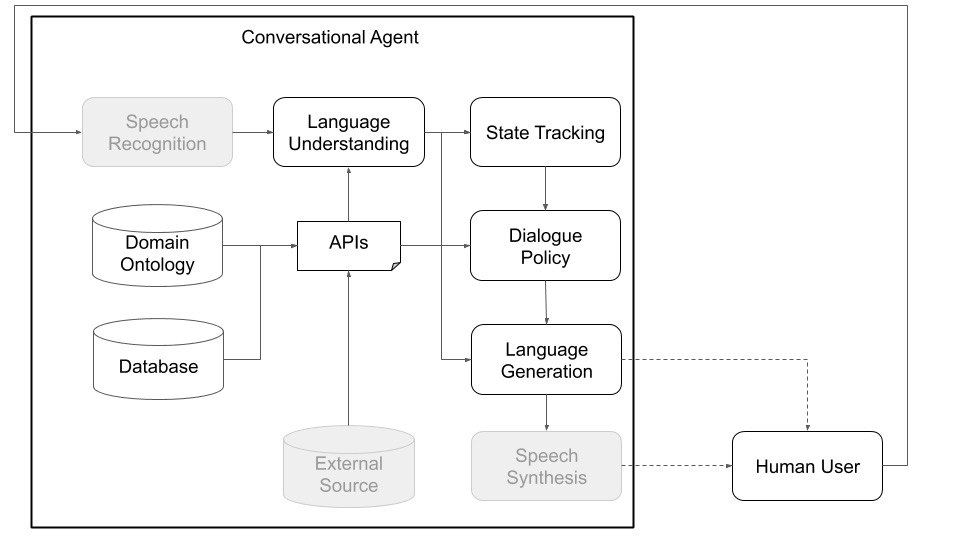
Plato Research Dialogue System: A Flexible Conversational AI Platform
The Plato Research Dialogue System is a platform #Uber developed to enable experts and non-experts alike to quickly build, train, and deploy conversational AI agents.
Link: https://eng.uber.com/plato-research-dialogue-system/
#ConversationalAI #converstaion #NLP #NLU
The Plato Research Dialogue System is a platform #Uber developed to enable experts and non-experts alike to quickly build, train, and deploy conversational AI agents.
Link: https://eng.uber.com/plato-research-dialogue-system/
#ConversationalAI #converstaion #NLP #NLU
{kind=link}
Model for tweaking graph visualization layout parameters
New #MachineLearning model builds a WYSIWYG interface to intuitively produce a layout you want!
Demo: http://kwonoh.net/dgl
Paper: http://arxiv.org/abs/1904.12225
#Visualization #ML
New #MachineLearning model builds a WYSIWYG interface to intuitively produce a layout you want!
Demo: http://kwonoh.net/dgl
Paper: http://arxiv.org/abs/1904.12225
#Visualization #ML
GSCNN: video segmetation architecture
Semantic segmentation GSCNN significantly outperforms DeepLabV3+ on Cityscapes benchmark.
Paper: https://arxiv.org/abs/1907.05740
Github (Project): https://github.com/nv-tlabs/GSCNN
#DL #CV #NVidiaAI #Nvidia #autonomous #selfdriving #car #RL #segmentation
Semantic segmentation GSCNN significantly outperforms DeepLabV3+ on Cityscapes benchmark.
Paper: https://arxiv.org/abs/1907.05740
Github (Project): https://github.com/nv-tlabs/GSCNN
#DL #CV #NVidiaAI #Nvidia #autonomous #selfdriving #car #RL #segmentation
Large Scale Adversarial Representation Learning
DeepMind shows that GANs can be harnessed for unsupervised representation learning, with state-of-the-art results on ImageNet. Reconstructions, as shown in paper, tend to emphasise high-level semantics over pixel-level details.
Link: https://arxiv.org/abs/1907.02544
#DeepMind #GAN #CV #DL #SOTA
DeepMind shows that GANs can be harnessed for unsupervised representation learning, with state-of-the-art results on ImageNet. Reconstructions, as shown in paper, tend to emphasise high-level semantics over pixel-level details.
Link: https://arxiv.org/abs/1907.02544
#DeepMind #GAN #CV #DL #SOTA
{kind=link}
Overview of 10 Stanford's Data Science courses
A survivor’s guide to Artificial Intelligence courses at Stanford
Link: https://huyenchip.com/2018/03/30/guide-to-Artificial-Intelligence-Stanford.html
#Staford #MOOC #course #free #rating #learning
A survivor’s guide to Artificial Intelligence courses at Stanford
Link: https://huyenchip.com/2018/03/30/guide-to-Artificial-Intelligence-Stanford.html
#Staford #MOOC #course #free #rating #learning
Chip Huyen
A survivor’s guide to Artificial Intelligence courses at Stanford (Updated Feb 2020)
Twitter thread
Top 8 trends from ICLR 2019
Overview of trends on #ICLR2019:
1. Inclusivity
2. Unsupervised representation learning & transfer learning
3. Retro ML
4. RNN is losing its luster with researchers
5. GANs are still going on strong
6. The lack of biologically inspired deep learning
7. Reinforcement learning is still the most popular topic by submissions
8. Most accepted papers will be quickly forgotten
Link: https://huyenchip.com/2019/05/12/top-8-trends-from-iclr-2019.html
#ICLR #overview
Overview of trends on #ICLR2019:
1. Inclusivity
2. Unsupervised representation learning & transfer learning
3. Retro ML
4. RNN is losing its luster with researchers
5. GANs are still going on strong
6. The lack of biologically inspired deep learning
7. Reinforcement learning is still the most popular topic by submissions
8. Most accepted papers will be quickly forgotten
Link: https://huyenchip.com/2019/05/12/top-8-trends-from-iclr-2019.html
#ICLR #overview
Huyenchip
Top 8 trends from ICLR 2019
[Twitter thread] Disclaimer: This post doesn’t reflect the view of any of the organizations I’m associated with and is probably peppered with my personal and...