
NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers
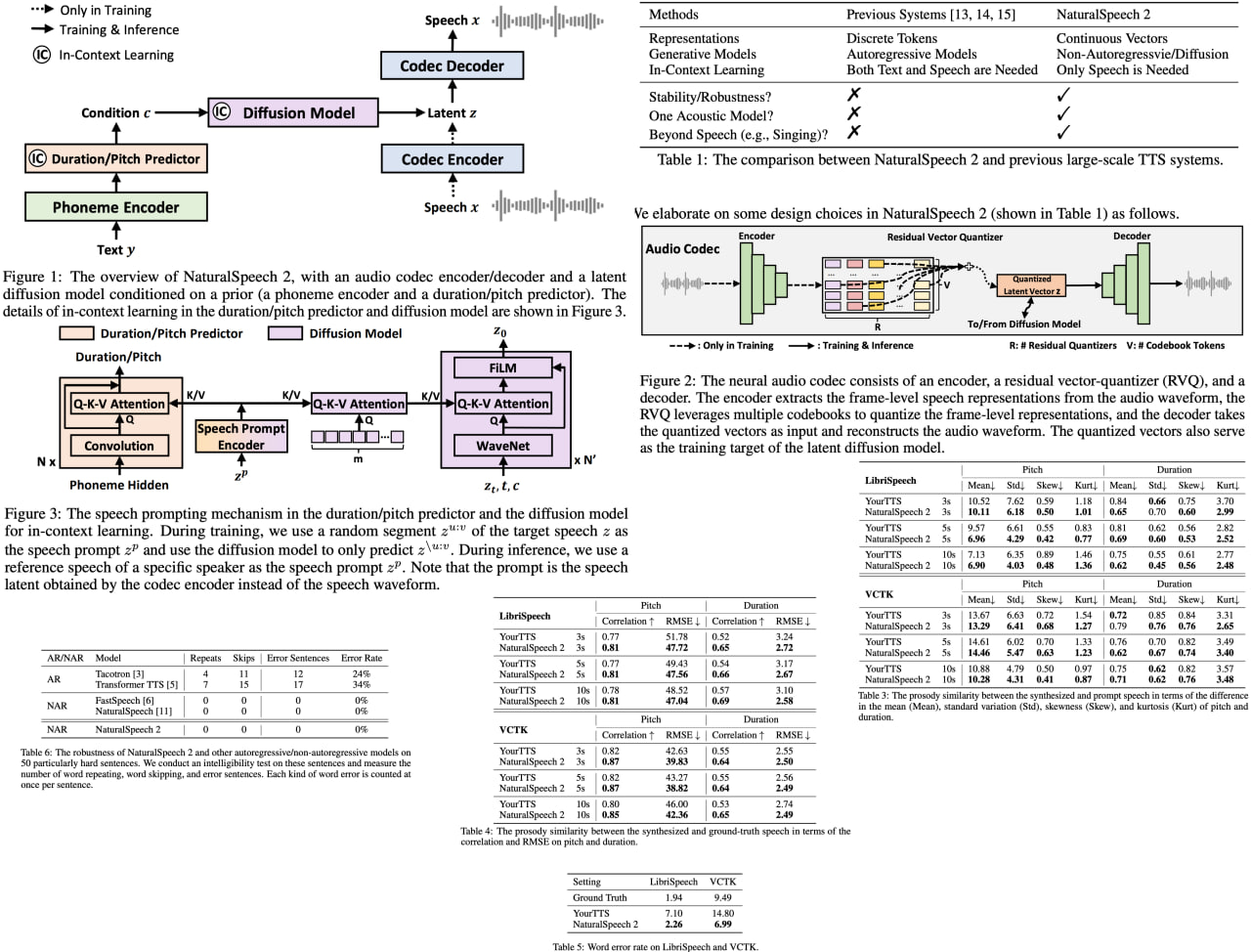
In the rapidly evolving domain of text-to-speech (TTS) technology, an exciting breakthrough has been made with the development of NaturalSpeech 2. This innovative system brings new levels of diversity to the table, by uniquely capturing a wide range of human speech characteristics such as speaker identities, prosodies, and even styles like singing. By employing a neural audio codec and residual vector quantizers, it transcends the limitations of existing TTS systems, which often suffer from unstable prosody, word skipping/repeating issues, and subpar voice quality.
More impressively, NaturalSpeech 2 enhances the "zero-shot" capability, a crucial factor for diverse speech synthesis. By designing a unique speech prompting mechanism, it facilitates in-context learning in both the diffusion model and the duration/pitch predictor. Its expansive training on 44K hours of speech and singing data has yielded unprecedented results. NaturalSpeech 2 significantly outperforms previous TTS systems in prosody/timbre similarity, robustness, and voice quality, even demonstrating novel zero-shot singing synthesis.
Project link: https://speechresearch.github.io/naturalspeech2/
Paper link: https://arxiv.org/pdf/2304.09116.pdf
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-naturalspeech2
#deeplearning #nlp #tts #texttospeech
In the rapidly evolving domain of text-to-speech (TTS) technology, an exciting breakthrough has been made with the development of NaturalSpeech 2. This innovative system brings new levels of diversity to the table, by uniquely capturing a wide range of human speech characteristics such as speaker identities, prosodies, and even styles like singing. By employing a neural audio codec and residual vector quantizers, it transcends the limitations of existing TTS systems, which often suffer from unstable prosody, word skipping/repeating issues, and subpar voice quality.
More impressively, NaturalSpeech 2 enhances the "zero-shot" capability, a crucial factor for diverse speech synthesis. By designing a unique speech prompting mechanism, it facilitates in-context learning in both the diffusion model and the duration/pitch predictor. Its expansive training on 44K hours of speech and singing data has yielded unprecedented results. NaturalSpeech 2 significantly outperforms previous TTS systems in prosody/timbre similarity, robustness, and voice quality, even demonstrating novel zero-shot singing synthesis.
Project link: https://speechresearch.github.io/naturalspeech2/
Paper link: https://arxiv.org/pdf/2304.09116.pdf
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-naturalspeech2
#deeplearning #nlp #tts #texttospeech
{kind=link}
🔥13👍5🆒2
DarkBERT: A Language Model for the Dark Side of the Internet
The researchers have developed a novel model called DarkBERT, which specifically focuses on the linguistically complex and often misunderstood domain of the Dark Web. This innovative model stands out due to its unique pretraining on Dark Web data, which allows it to handle the extreme lexical and structural diversity characteristic of the Dark Web. This is a critical development considering the clear differences that exist in language use between the Dark Web and the Surface Web, a factor that can often hinder accurate textual analysis.
DarkBERT isn't just a novelty, but a robust, high-performing language model that consistently outshines current popular models like BERT and RoBERTa in various use cases. These findings shed light on the considerable advantages that a domain-specific model like DarkBERT can offer. More than anything else, DarkBERT promises to be a vital resource for future research on the Dark Web, setting a new standard for language models in this intriguing and intricate realm.
Paper link: https://arxiv.org/abs/2305.08596
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-darkbert
#deeplearning #nlp #darkweb #cybersecurity
The researchers have developed a novel model called DarkBERT, which specifically focuses on the linguistically complex and often misunderstood domain of the Dark Web. This innovative model stands out due to its unique pretraining on Dark Web data, which allows it to handle the extreme lexical and structural diversity characteristic of the Dark Web. This is a critical development considering the clear differences that exist in language use between the Dark Web and the Surface Web, a factor that can often hinder accurate textual analysis.
DarkBERT isn't just a novelty, but a robust, high-performing language model that consistently outshines current popular models like BERT and RoBERTa in various use cases. These findings shed light on the considerable advantages that a domain-specific model like DarkBERT can offer. More than anything else, DarkBERT promises to be a vital resource for future research on the Dark Web, setting a new standard for language models in this intriguing and intricate realm.
Paper link: https://arxiv.org/abs/2305.08596
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-darkbert
#deeplearning #nlp #darkweb #cybersecurity
{kind=link}
😈21👍10❤7🌚4😁2🤬2
Chain of Hindsight Aligns Language Models with Feedback
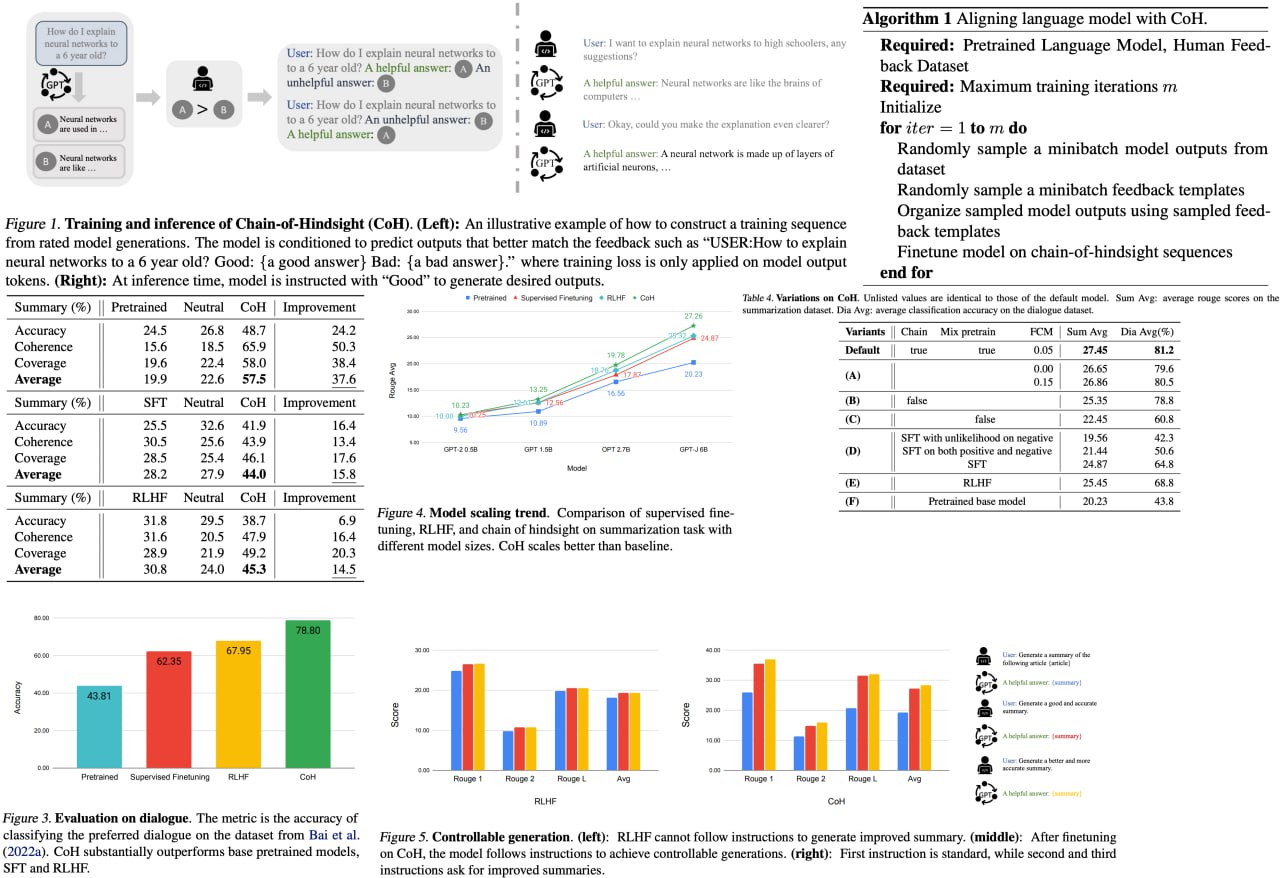
AI language models are becoming a major part of our digital world. The challenge, however, lies in aligning these models with human preferences to be genuinely useful and valuable. Current methods, although successful in many ways, have limitations - they are either inefficient in utilizing data or depend heavily on challenging reward functions and reinforcement learning.
Here comes "Chain of Hindsight," an exciting, novel technique inspired by human learning mechanisms. It can learn from any form of feedback, even transforming it into language for fine-tuning the model. This approach conditions the model on a sequence of model generations paired with feedback, helping it learn to correct negative attributes or errors. It is significantly outperforming previous methods, particularly showing major strides in summarization and dialogue tasks.
Paper link: https://arxiv.org/abs/2302.02676
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coh
#deeplearning #nlp #llm
AI language models are becoming a major part of our digital world. The challenge, however, lies in aligning these models with human preferences to be genuinely useful and valuable. Current methods, although successful in many ways, have limitations - they are either inefficient in utilizing data or depend heavily on challenging reward functions and reinforcement learning.
Here comes "Chain of Hindsight," an exciting, novel technique inspired by human learning mechanisms. It can learn from any form of feedback, even transforming it into language for fine-tuning the model. This approach conditions the model on a sequence of model generations paired with feedback, helping it learn to correct negative attributes or errors. It is significantly outperforming previous methods, particularly showing major strides in summarization and dialogue tasks.
Paper link: https://arxiv.org/abs/2302.02676
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coh
#deeplearning #nlp #llm
{kind=link}
🔥9👍4❤1🥰1🤔1
QLoRA: Efficient Finetuning of Quantized LLMs
Thia paper introduces QLoRA, a novel finetuning approach that decreases memory usage significantly, while maintaining impressive performance. Imagine this - a 65 billion parameter model finetuned on a single 48GB GPU, while preserving full 16-bit task performance. This method involves backpropagating gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters, a method that opens up new frontiers in machine learning. The icing on the cake is their high-performing model family, Guanaco, which trumps all previously released models on the Vicuna benchmark, achieving a staggering 99.3% of the performance level of ChatGPT with just 24 hours of finetuning on a single GPU.
The study also unveils several innovative techniques to conserve memory without compromising performance. These include 4-bit NormalFloat (NF4), an innovative data type that is theoretically optimal for normally distributed weights, double quantization for average memory footprint reduction, and paged optimizers to handle memory spikes. The QLoRA approach was applied to finetune more than 1000 models, leading to a detailed analysis of instruction following and chatbot performance across various model types and scales. The results affirm that QLoRA finetuning on a small, high-quality dataset yields state-of-the-art results, even with smaller models than previously used. A notable finding is that GPT-4 evaluations offer a cost-effective alternative to human evaluation. All models and code, including CUDA kernels for 4-bit training, have been released by the researchers.
Paper link: https://arxiv.org/abs/2305.14314
Code link: https://github.com/artidoro/qlora
CUDA kernels link: https://github.com/TimDettmers/bitsandbytes
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-qlora
#deeplearning #nlp #llm #quantization
Thia paper introduces QLoRA, a novel finetuning approach that decreases memory usage significantly, while maintaining impressive performance. Imagine this - a 65 billion parameter model finetuned on a single 48GB GPU, while preserving full 16-bit task performance. This method involves backpropagating gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters, a method that opens up new frontiers in machine learning. The icing on the cake is their high-performing model family, Guanaco, which trumps all previously released models on the Vicuna benchmark, achieving a staggering 99.3% of the performance level of ChatGPT with just 24 hours of finetuning on a single GPU.
The study also unveils several innovative techniques to conserve memory without compromising performance. These include 4-bit NormalFloat (NF4), an innovative data type that is theoretically optimal for normally distributed weights, double quantization for average memory footprint reduction, and paged optimizers to handle memory spikes. The QLoRA approach was applied to finetune more than 1000 models, leading to a detailed analysis of instruction following and chatbot performance across various model types and scales. The results affirm that QLoRA finetuning on a small, high-quality dataset yields state-of-the-art results, even with smaller models than previously used. A notable finding is that GPT-4 evaluations offer a cost-effective alternative to human evaluation. All models and code, including CUDA kernels for 4-bit training, have been released by the researchers.
Paper link: https://arxiv.org/abs/2305.14314
Code link: https://github.com/artidoro/qlora
CUDA kernels link: https://github.com/TimDettmers/bitsandbytes
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-qlora
#deeplearning #nlp #llm #quantization
{kind=link}
👍18🔥7❤5
StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners
In a ground-breaking exploration of visual representation learning, researchers have leveraged synthetic images produced by leading text-to-image models, specifically Stable Diffusion, achieving promising results. The study uncovers two key insights - firstly, when configured correctly, self-supervised methods trained on synthetic images can match or even outperform those trained on real images. This suggests an exciting avenue for efficient and effective representation learning, reducing the need for extensive real image datasets.
Secondly, the researchers have devised a novel approach called StableRep, a multi-positive contrastive learning method that treats multiple images, generated from the same text prompt, as mutual positives. The compelling finding is that StableRep, trained solely with synthetic images, outperforms representations learned by prominent methods such as SimCLR and CLIP, even when these used real images. In a striking demonstration, when language supervision is added, StableRep trained with 20M synthetic images outperforms CLIP trained with a whopping 50M real images. These findings not only underscore the potential of synthetic data but also pave the way for more efficient, large-scale visual representation learning.
Paper link: https://arxiv.org/abs/2306.00984
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-stablerep
#deeplearning #cv #nlp #stablediffusion #texttoimage #syntheticdata
In a ground-breaking exploration of visual representation learning, researchers have leveraged synthetic images produced by leading text-to-image models, specifically Stable Diffusion, achieving promising results. The study uncovers two key insights - firstly, when configured correctly, self-supervised methods trained on synthetic images can match or even outperform those trained on real images. This suggests an exciting avenue for efficient and effective representation learning, reducing the need for extensive real image datasets.
Secondly, the researchers have devised a novel approach called StableRep, a multi-positive contrastive learning method that treats multiple images, generated from the same text prompt, as mutual positives. The compelling finding is that StableRep, trained solely with synthetic images, outperforms representations learned by prominent methods such as SimCLR and CLIP, even when these used real images. In a striking demonstration, when language supervision is added, StableRep trained with 20M synthetic images outperforms CLIP trained with a whopping 50M real images. These findings not only underscore the potential of synthetic data but also pave the way for more efficient, large-scale visual representation learning.
Paper link: https://arxiv.org/abs/2306.00984
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-stablerep
#deeplearning #cv #nlp #stablediffusion #texttoimage #syntheticdata
{kind=link}
🔥8👍5❤4👀4👏1
BiomedGPT: A Unified and Generalist Biomedical Generative Pre-trained Transformer for Vision, Language, and Multimodal Tasks
Introducing the groundbreaking Biomedical Generative Pre-trained Transformer (BiomedGPT) model, this paper revolutionizes the field of biomedicine by offering a unified and generalist approach. BiomedGPT harnesses the power of self-supervision on extensive and diverse datasets, enabling it to effortlessly handle multi-modal inputs and excel in a wide range of downstream tasks. In a series of comprehensive experiments, BiomedGPT astoundingly outperforms its predecessors, emerging as the unrivaled leader across five distinct tasks and a staggering 20 public datasets encompassing over 15 unique biomedical modalities. Its ability to deliver expansive and all-encompassing representations of biomedical data heralds a significant advancement in the field, with promising implications for improving healthcare outcomes.
Through meticulous ablation studies, the efficacy of BiomedGPT's multi-modal and multi-task pretraining approach is vividly showcased. This groundbreaking model effortlessly transfers its vast knowledge to previously unseen data, demonstrating its versatility and adaptability. The implications of this research are profound, paving the way for the development of unified and all-encompassing models for biomedicine.
Paper link: https://arxiv.org/abs/2305.17100
Code link: https://github.com/taokz/BiomedGPT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-biomedgpt
#deeplearning #nlp #selfsupervised #gpt #biomedicine
Introducing the groundbreaking Biomedical Generative Pre-trained Transformer (BiomedGPT) model, this paper revolutionizes the field of biomedicine by offering a unified and generalist approach. BiomedGPT harnesses the power of self-supervision on extensive and diverse datasets, enabling it to effortlessly handle multi-modal inputs and excel in a wide range of downstream tasks. In a series of comprehensive experiments, BiomedGPT astoundingly outperforms its predecessors, emerging as the unrivaled leader across five distinct tasks and a staggering 20 public datasets encompassing over 15 unique biomedical modalities. Its ability to deliver expansive and all-encompassing representations of biomedical data heralds a significant advancement in the field, with promising implications for improving healthcare outcomes.
Through meticulous ablation studies, the efficacy of BiomedGPT's multi-modal and multi-task pretraining approach is vividly showcased. This groundbreaking model effortlessly transfers its vast knowledge to previously unseen data, demonstrating its versatility and adaptability. The implications of this research are profound, paving the way for the development of unified and all-encompassing models for biomedicine.
Paper link: https://arxiv.org/abs/2305.17100
Code link: https://github.com/taokz/BiomedGPT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-biomedgpt
#deeplearning #nlp #selfsupervised #gpt #biomedicine
{kind=link}
👍11❤10🔥5🐳1
Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision
AI-assistant agents like ChatGPT have largely depended on supervised fine-tuning and reinforcement learning from human feedback. But, this method brings its own set of challenges - high costs, potential biases, and constraints on the true potential of these AI agents. What if there was a more effective, self-sufficient way to align AI output with human intentions? Enter Self-ALIGN, a groundbreaking methodology that marries principle-driven reasoning and the generative capabilities of large language models. This promising approach takes the AI realm by storm, offering a novel way to ensure our AI models are more helpful, ethical, and reliable - all with minimal human intervention.
Self-ALIGN is a multistage process that works by generating synthetic prompts from a large language model, augmenting prompt diversity, and leveraging a concise set of human-written principles to guide AI models. When applied to the LLaMA-65b base language model, it led to the creation of a new AI assistant, Dromedary, using less than 300 lines of human annotations. Dromedary not only outshines several state-of-the-art AI systems, such as Text-Davinci-003 and Alpaca, but it does so on a variety of benchmark datasets.
Paper link: https://arxiv.org/abs/2305.03047
Code link: https://mitibmdemos.draco.res.ibm.com/dromedary
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dromedary
#deeplearning #nlp #llm
AI-assistant agents like ChatGPT have largely depended on supervised fine-tuning and reinforcement learning from human feedback. But, this method brings its own set of challenges - high costs, potential biases, and constraints on the true potential of these AI agents. What if there was a more effective, self-sufficient way to align AI output with human intentions? Enter Self-ALIGN, a groundbreaking methodology that marries principle-driven reasoning and the generative capabilities of large language models. This promising approach takes the AI realm by storm, offering a novel way to ensure our AI models are more helpful, ethical, and reliable - all with minimal human intervention.
Self-ALIGN is a multistage process that works by generating synthetic prompts from a large language model, augmenting prompt diversity, and leveraging a concise set of human-written principles to guide AI models. When applied to the LLaMA-65b base language model, it led to the creation of a new AI assistant, Dromedary, using less than 300 lines of human annotations. Dromedary not only outshines several state-of-the-art AI systems, such as Text-Davinci-003 and Alpaca, but it does so on a variety of benchmark datasets.
Paper link: https://arxiv.org/abs/2305.03047
Code link: https://mitibmdemos.draco.res.ibm.com/dromedary
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dromedary
#deeplearning #nlp #llm
{kind=link}
👍8❤7😁3🔥2
Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
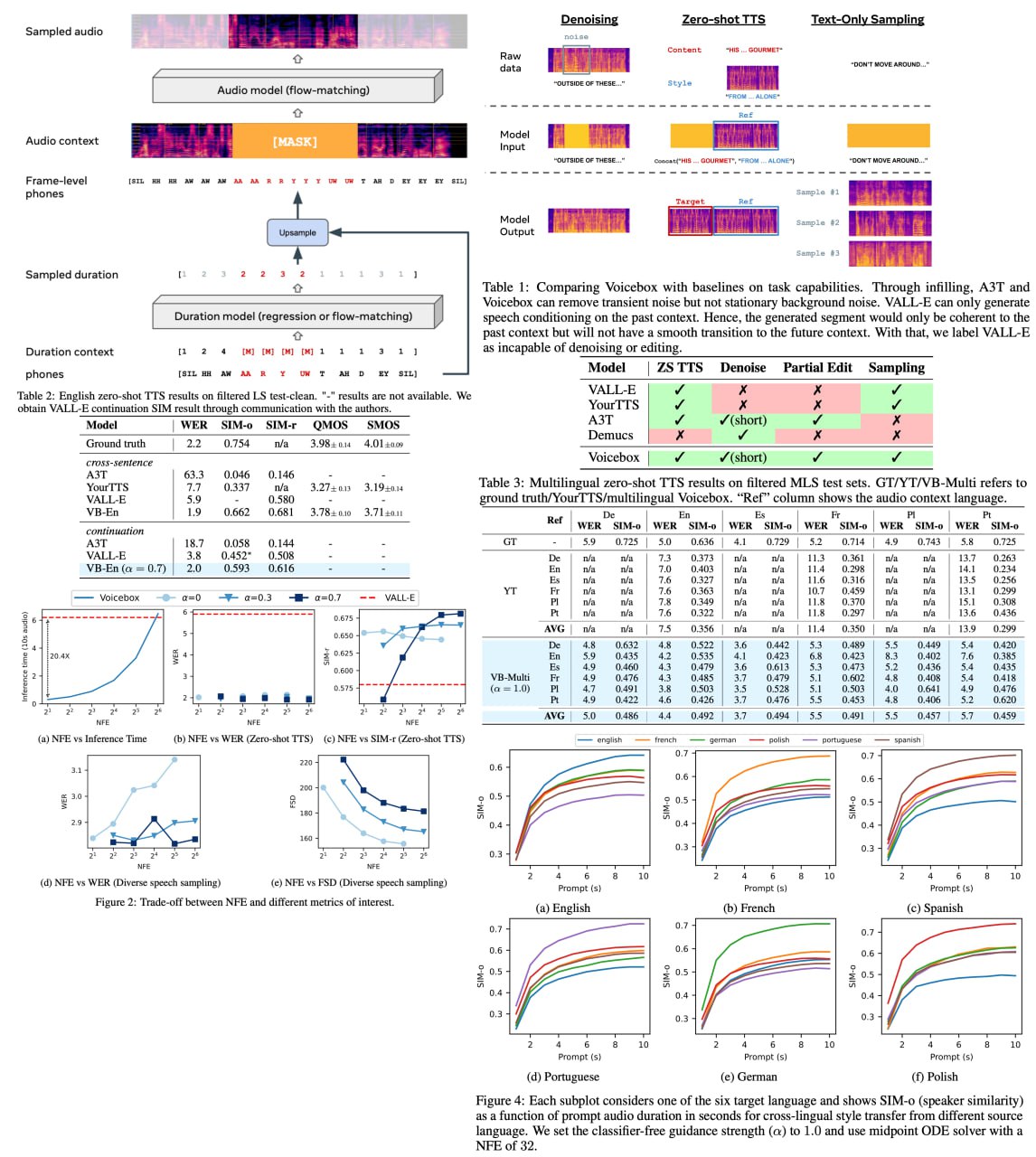
In the ever-evolving field of natural language processing and computer vision research, the revolution is being led by large-scale generative models like GPT and DALL-E. These models have the remarkable capability of generating high fidelity text or image outputs, and more importantly, they possess a 'generalist' character, able to solve tasks that they weren't explicitly trained to accomplish. However, when it comes to speech generative models, there's still a significant gap in terms of scale and task generalization. Enter, Voicebox - a pioneering advancement set to redefine the landscape of speech generation technology.
Voicebox is an exceptionally versatile text-guided generative model for speech at an impressive scale. Trained on over 50K hours of unfiltered, unenhanced speech data, Voicebox is a non-autoregressive flow-matching model, designed to infill speech, given an audio context and text. Much like its predecessors, Voicebox is able to perform a wide range of tasks through in-context learning, but with an added flexibility - it can condition on future context. The applications are boundless - from mono or cross-lingual zero-shot text-to-speech synthesis to noise removal, content editing, style conversion, and diverse sample generation. What's truly phenomenal is Voicebox's capability to outshine the state-of-the-art zero-shot TTS model, VALL-E, on both intelligibility and audio similarity metrics, while being a staggering 20 times faster.
Paper link: https://research.facebook.com/publications/voicebox-text-guided-multilingual-universal-speech-generation-at-scale/
Blogpost link: https://ai.facebook.com/blog/voicebox-generative-ai-model-speech/
Project link: https://voicebox.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-voicebox
#deeplearning #nlp #speechgeneration #texttospeech
In the ever-evolving field of natural language processing and computer vision research, the revolution is being led by large-scale generative models like GPT and DALL-E. These models have the remarkable capability of generating high fidelity text or image outputs, and more importantly, they possess a 'generalist' character, able to solve tasks that they weren't explicitly trained to accomplish. However, when it comes to speech generative models, there's still a significant gap in terms of scale and task generalization. Enter, Voicebox - a pioneering advancement set to redefine the landscape of speech generation technology.
Voicebox is an exceptionally versatile text-guided generative model for speech at an impressive scale. Trained on over 50K hours of unfiltered, unenhanced speech data, Voicebox is a non-autoregressive flow-matching model, designed to infill speech, given an audio context and text. Much like its predecessors, Voicebox is able to perform a wide range of tasks through in-context learning, but with an added flexibility - it can condition on future context. The applications are boundless - from mono or cross-lingual zero-shot text-to-speech synthesis to noise removal, content editing, style conversion, and diverse sample generation. What's truly phenomenal is Voicebox's capability to outshine the state-of-the-art zero-shot TTS model, VALL-E, on both intelligibility and audio similarity metrics, while being a staggering 20 times faster.
Paper link: https://research.facebook.com/publications/voicebox-text-guided-multilingual-universal-speech-generation-at-scale/
Blogpost link: https://ai.facebook.com/blog/voicebox-generative-ai-model-speech/
Project link: https://voicebox.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-voicebox
#deeplearning #nlp #speechgeneration #texttospeech
{kind=link}
👍13❤5🔥3🤔1
Multilingual End to End Entity Linking
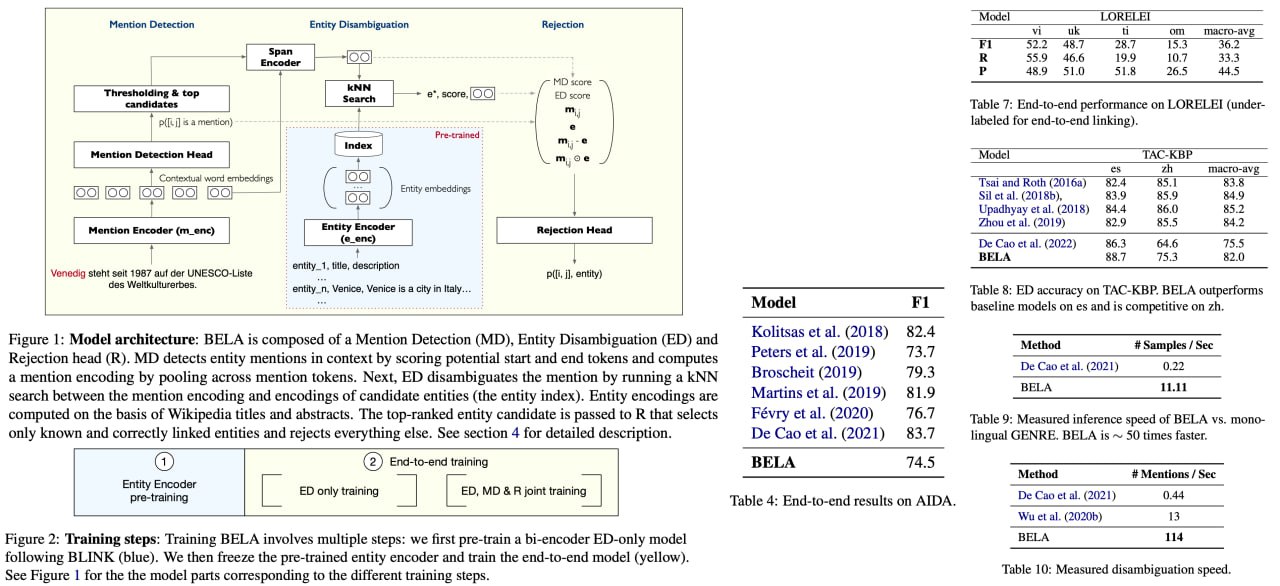
Introducing BELA, an unprecedented, open-source solution that is set to revolutionize the Natural Language Processing (NLP) arena! BELA addresses the complex challenge of Entity Linking, a task prevalent in many practical applications, by offering the very first fully end-to-end multilingual model. Astoundingly, it can efficiently identify and link entities in texts across an expansive range of 97 languages, a capability hitherto unseen. This marks a significant leap towards streamlining complex model stacks that have been a pervasive issue in the field.
BELA's architectural novelty lies in its adoption of a bi-encoder design. This enables it to conduct end-to-end linking of a passage in a single forward pass through a transformer, regardless of the number of entity mentions it contains. In its core Entity Disambiguation sub-task, it cleverly deploys a k-nearest neighbor (kNN) search using an encoded mention as a query in an entity index. What's even more impressive is BELA's scalability—it handles up to 16 million entities and delivers a remarkable throughput of 53 samples per second on a single GPU.
Paper link: https://arxiv.org/abs/2306.08896
Code link: https://github.com/facebookresearch/BELA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bela
#deeplearning #nlp #entitylinking #multilingual
Introducing BELA, an unprecedented, open-source solution that is set to revolutionize the Natural Language Processing (NLP) arena! BELA addresses the complex challenge of Entity Linking, a task prevalent in many practical applications, by offering the very first fully end-to-end multilingual model. Astoundingly, it can efficiently identify and link entities in texts across an expansive range of 97 languages, a capability hitherto unseen. This marks a significant leap towards streamlining complex model stacks that have been a pervasive issue in the field.
BELA's architectural novelty lies in its adoption of a bi-encoder design. This enables it to conduct end-to-end linking of a passage in a single forward pass through a transformer, regardless of the number of entity mentions it contains. In its core Entity Disambiguation sub-task, it cleverly deploys a k-nearest neighbor (kNN) search using an encoded mention as a query in an entity index. What's even more impressive is BELA's scalability—it handles up to 16 million entities and delivers a remarkable throughput of 53 samples per second on a single GPU.
Paper link: https://arxiv.org/abs/2306.08896
Code link: https://github.com/facebookresearch/BELA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bela
#deeplearning #nlp #entitylinking #multilingual
{kind=link}
👍13❤4🆒3🔥2🥰1🤔1
Practical ML Conf - The biggest offline ML conference of the year in Moscow.
- https://pmlconf.yandex.ru
- September 7, Moscow
- For speakers: offline
- For participants: offline and online (youtube)
- The conference language is Russian.
Call for propose is open https://pmlconf.yandex.ru/call_for_papers
#conference #nlp #cv #genAI #recsys #mlops #ecomm #hardware #research #offline #online
- https://pmlconf.yandex.ru
- September 7, Moscow
- For speakers: offline
- For participants: offline and online (youtube)
- The conference language is Russian.
Call for propose is open https://pmlconf.yandex.ru/call_for_papers
#conference #nlp #cv #genAI #recsys #mlops #ecomm #hardware #research #offline #online
Practical ML Conf 2025
Конференция про практический ML от Яндекса
👍23👎13🔥6👏2