
Microsoft released new version of High-Performance, Open-Source, Deep Learning Toolkit
https://news.developer.nvidia.com/microsoft-releases-new-version-of-high-performance-open-source-deep-learning-toolkit/
#microsoft #nvidia #news
https://news.developer.nvidia.com/microsoft-releases-new-version-of-high-performance-open-source-deep-learning-toolkit/
#microsoft #nvidia #news
Microsoft’s AI course is now open and free
Microsoft Professional Program for Artificial Intelligence — previously being available only to employees is now available at edx.org for free. Program includes 10 courses from basic python programming to deep learning and reinforcement learning disciplines.
https://academy.microsoft.com/en-us/professional-program/tracks/artificial-intelligence/
#mooc #microsoft #course
Microsoft Professional Program for Artificial Intelligence — previously being available only to employees is now available at edx.org for free. Program includes 10 courses from basic python programming to deep learning and reinforcement learning disciplines.
https://academy.microsoft.com/en-us/professional-program/tracks/artificial-intelligence/
#mooc #microsoft #course
Docs
Training
Master core concepts at your speed and on your schedule. Whether you've got 15 minutes or an hour, you can develop practical skills through interactive modules and paths. You can also register to learn from an instructor. Learn and grow your way.
Microsoft Research announced Open Data project! This single, cloud-hosted location offers datasets representing many years of data curation and research efforts by Microsoft.
https://www.microsoft.com/en-us/research/blog/announcing-microsoft-research-open-data-datasets-by-microsoft-research-now-available-in-the-cloud/
#data #microsoft #opensource
https://www.microsoft.com/en-us/research/blog/announcing-microsoft-research-open-data-datasets-by-microsoft-research-now-available-in-the-cloud/
#data #microsoft #opensource
Microsoft Research
Announcing Microsoft Research Open Data - Datasets by Microsoft Research now available in the cloud - Microsoft Research
The Microsoft Research Outreach team has worked extensively with the external research community to enable adoption of cloud-based research infrastructure over the past few years. Through this process, we experienced the ubiquity of Jim Gray’s fourth paradigm…
Introducing MASS – A pre-training method that outperforms BERT and GPT in sequence to sequence language generation tasks
Researchers from Microsoft Research Asia have introduced MASS—a new pre-training method that claimed to achieve better results than BERT and GPT.
Link: https://www.microsoft.com/en-us/research/blog/introducing-mass-a-pre-training-method-that-outperforms-bert-and-gpt-in-sequence-to-sequence-language-generation-tasks/
#nlp #microsoft
Researchers from Microsoft Research Asia have introduced MASS—a new pre-training method that claimed to achieve better results than BERT and GPT.
Link: https://www.microsoft.com/en-us/research/blog/introducing-mass-a-pre-training-method-that-outperforms-bert-and-gpt-in-sequence-to-sequence-language-generation-tasks/
#nlp #microsoft
Microsoft Research
Introducing MASS – A pre-training method that outperforms BERT and GPT in sequence to sequence language generation tasks
Pre-training is a hot topic in NLP research and models like BERT and GPT have definitely delivered exciting breakthroughs. The challenge is in upping our game in finer sequence to sequence based language generation tasks. Enter MASS. Click the link in our…
Microsoft open-sourced scripts and notebooks to pre-train and finetune BERT natural language model with domain-specific texts
Github: https://github.com/microsoft/AzureML-BERT
Earlier: https://yangx.top/opendatascience/837
#Bert #Microsoft #NLP #dl
Github: https://github.com/microsoft/AzureML-BERT
Earlier: https://yangx.top/opendatascience/837
#Bert #Microsoft #NLP #dl
GitHub
GitHub - microsoft/AzureML-BERT: End-to-End recipes for pre-training and fine-tuning BERT using Azure Machine Learning Service
End-to-End recipes for pre-training and fine-tuning BERT using Azure Machine Learning Service - microsoft/AzureML-BERT
Deep Learning Image Segmentation for Ecommerce Catalogue Visual Search
Microsoft’s article on image segmentation
Link: https://www.microsoft.com/developerblog/2018/04/18/deep-learning-image-segmentation-for-ecommerce-catalogue-visual-search/
#CV #DL #Segmentation #Microsoft
Microsoft’s article on image segmentation
Link: https://www.microsoft.com/developerblog/2018/04/18/deep-learning-image-segmentation-for-ecommerce-catalogue-visual-search/
#CV #DL #Segmentation #Microsoft
{kind=link}
Open-source library provides explanation for machine learning through diverse counterfactuals
This is a development of #interpretable ML. Library to explore “what-if” scenarios for ML models.
Blog post: https://www.microsoft.com/en-us/research/blog/open-source-library-provides-explanation-for-machine-learning-through-diverse-counterfactuals/
Paper: https://www.microsoft.com/en-us/research/publication/explaining-machine-learning-classifiers-through-diverse-counterfactual-examples/
Github: https://github.com/microsoft/dice
#Microsoft #ML #opensource
This is a development of #interpretable ML. Library to explore “what-if” scenarios for ML models.
Blog post: https://www.microsoft.com/en-us/research/blog/open-source-library-provides-explanation-for-machine-learning-through-diverse-counterfactuals/
Paper: https://www.microsoft.com/en-us/research/publication/explaining-machine-learning-classifiers-through-diverse-counterfactual-examples/
Github: https://github.com/microsoft/dice
#Microsoft #ML #opensource
Microsoft Research
DiCE: Employing counterfactuals to explain machine learning algorithms
Microsoft researchers & collaborators created an open-source library to explore “what-if” scenarios for machine learning models. Learn how their method generates multiple diverse counterfactuals at once & gives insight into ML algorithm decision making.
Microsoft Research 2019 reflection—a year of progress on technology’s toughest challenges
Highlights:
* MT-DNN — a model for learning universal language embeddings that combines the multi-task learning and the language model pre-training of BERT.
* Guidelines for human-AI interaction design
* AirSim, coming from strong MS background with flight simulations, for AI realisting testing environment.
* Sand Dance, a data visualization tool included in Visual Studio Code
* Icecaps — a toolkit for conversation modeling
Link: https://www.microsoft.com/en-us/research/blog/microsoft-research-2019-reflection-a-year-of-progress-on-technologys-toughest-challenges/
#microsoft #yearinreview
Highlights:
* MT-DNN — a model for learning universal language embeddings that combines the multi-task learning and the language model pre-training of BERT.
* Guidelines for human-AI interaction design
* AirSim, coming from strong MS background with flight simulations, for AI realisting testing environment.
* Sand Dance, a data visualization tool included in Visual Studio Code
* Icecaps — a toolkit for conversation modeling
Link: https://www.microsoft.com/en-us/research/blog/microsoft-research-2019-reflection-a-year-of-progress-on-technologys-toughest-challenges/
#microsoft #yearinreview
Microsoft Research
Microsoft Research 2019 reflection—a year of progress on technology’s toughest challenges
In 2019, Microsoft researchers assembled guidelines for human-AI interaction design, explored gender bias in machine learning, and created numerous technologies that improved accessibility. Learn how these advances emphasize inclusivity.
ZeRO, DeepSpeed & Turing-NLG
ZeRO: Memory Optimization Towards Training A Trillion Parameter Models
Turing-NLG: A 17-billion-parameter language model by Microsoft
Microsoft is releasing an open-source library called DeepSpeed, which vastly advances large model training by improving scale, speed, cost, and usability, unlocking the ability to train 100-billion-parameter models; compatible with PyTorch.
ZeRO – is a new parallelized optimizer that greatly reduces the resources needed for model and data parallelism while massively increasing the number of parameters that can be trained.
ZeRO has three main optimization stages, which correspond to the partitioning of optimizer states, gradients, and parameters. When enabled cumulatively:
0. Optimizer State Partitioning (
1. Add Gradient Partitioning (
2. Add Parameter Partitioning (
They have used these breakthroughs to create Turing Natural Language Generation (Turing-NLG), the largest publicly known language model at 17 billion parameters, which you can learn more about in this accompanying blog post. Also, the abstract for Turing-NLG had been written by their own model
ZeRO & DeepSpeed: https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
paper: https://arxiv.org/abs/1910.02054
github: https://github.com/microsoft/DeepSpeed
Turing-NLG: https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
#nlp #dl #ml #microsoft #deepspeed #optimization
ZeRO: Memory Optimization Towards Training A Trillion Parameter Models
Turing-NLG: A 17-billion-parameter language model by Microsoft
Microsoft is releasing an open-source library called DeepSpeed, which vastly advances large model training by improving scale, speed, cost, and usability, unlocking the ability to train 100-billion-parameter models; compatible with PyTorch.
ZeRO – is a new parallelized optimizer that greatly reduces the resources needed for model and data parallelism while massively increasing the number of parameters that can be trained.
ZeRO has three main optimization stages, which correspond to the partitioning of optimizer states, gradients, and parameters. When enabled cumulatively:
0. Optimizer State Partitioning (
P_os_) – 4x memory reduction, same communication volume as data parallelism1. Add Gradient Partitioning (
P_os+g_) – 8x memory reduction, same communication volume as data parallelism2. Add Parameter Partitioning (
P_os+g+p_) – memory reduction is linear with data parallelism degree N_d_They have used these breakthroughs to create Turing Natural Language Generation (Turing-NLG), the largest publicly known language model at 17 billion parameters, which you can learn more about in this accompanying blog post. Also, the abstract for Turing-NLG had been written by their own model
ZeRO & DeepSpeed: https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
paper: https://arxiv.org/abs/1910.02054
github: https://github.com/microsoft/DeepSpeed
Turing-NLG: https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
#nlp #dl #ml #microsoft #deepspeed #optimization
{kind=link}
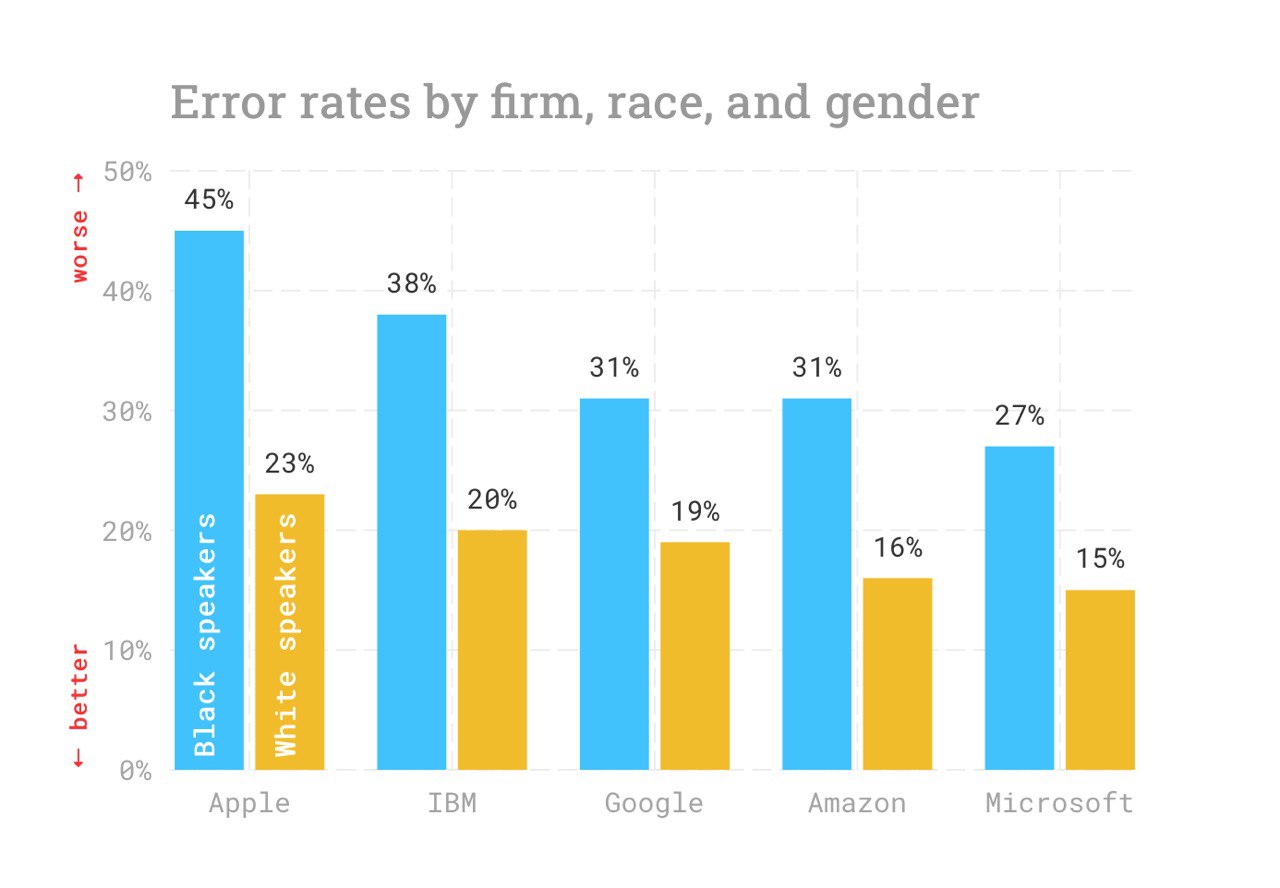
Racial Disparities in Automated Speech Recognition
To no surprise, speech recognition tools have #bias due to the lack of diversity in the datasets. Group of explorers addressed that issue and provided their’s research results as a paper and #reproducible research repo.
Project link: https://fairspeech.stanford.edu
Paper: https://www.pnas.org/cgi/doi/10.1073/pnas.1915768117
Github: https://github.com/stanford-policylab/asr-disparities
#speechrecognition #voice #audiolearning #dl #microsoft #google #apple #ibm #amazon
To no surprise, speech recognition tools have #bias due to the lack of diversity in the datasets. Group of explorers addressed that issue and provided their’s research results as a paper and #reproducible research repo.
Project link: https://fairspeech.stanford.edu
Paper: https://www.pnas.org/cgi/doi/10.1073/pnas.1915768117
Github: https://github.com/stanford-policylab/asr-disparities
#speechrecognition #voice #audiolearning #dl #microsoft #google #apple #ibm #amazon
{kind=link}