
Coconet: the ML model behind 20th of March Bach Doodle
Network trained to recreate Bach's music.
Link: https://magenta.tensorflow.org/coconet
#magenta #google #audiolearning
Network trained to recreate Bach's music.
Link: https://magenta.tensorflow.org/coconet
#magenta #google #audiolearning
Magenta
Coconet: the ML model behind today’s Bach Doodle
Have you seen today’s Doodle? Join us to celebrate J.S. Bach’s 334th birthday with the first AI-powered Google Doodle. You can create your own melody, an...
🔥Quasi-Breaking: An Algorithm Inks a Record Deal With Warner Music
Endel uses machine learning to create personalized tracks meant to help people focus, relax and sleep better by inputting factors such as heart rate, time of day, location and weather.
Looking forward to actual music-generating algorithm being signed up for label.
Link: https://hypebeast.com/2019/3/endel-algorithm-record-deal-warner-music
#MLHype #audiolearning #DL #Endel
Endel uses machine learning to create personalized tracks meant to help people focus, relax and sleep better by inputting factors such as heart rate, time of day, location and weather.
Looking forward to actual music-generating algorithm being signed up for label.
Link: https://hypebeast.com/2019/3/endel-algorithm-record-deal-warner-music
#MLHype #audiolearning #DL #Endel
HYPEBEAST
An Algorithm Inks Distribution Partnership With Warner Music
This is the future.
🔥Singing voice conversion system developed at FAIR-Tel Aviv.
This can transform someone's singing voice into someone else's voice.
YouTube: https://www.youtube.com/watch?v=IEpkGenLnjw
Link: https://venturebeat.com/2019/04/16/facebooks-ai-can-convert-one-singers-voice-into-another/
ArXiV: https://arxiv.org/abs/1904.06590
#voiceconversion #audiolearning #DL #Facebook
This can transform someone's singing voice into someone else's voice.
YouTube: https://www.youtube.com/watch?v=IEpkGenLnjw
Link: https://venturebeat.com/2019/04/16/facebooks-ai-can-convert-one-singers-voice-into-another/
ArXiV: https://arxiv.org/abs/1904.06590
#voiceconversion #audiolearning #DL #Facebook
OpenAI’s MuseNet architecture to generate music.
#MuseNet — neural network which discovered how to generate music from first 5 or so notes, using many different instruments and styles.
Post: https://openai.com/blog/musenet/
MuseNet will play an experimental concert today from 12–3pm PT on livestream: http://twitch.tv/openai
#audiolearning #musicgeneration #OpenAI #soundgeneration
#MuseNet — neural network which discovered how to generate music from first 5 or so notes, using many different instruments and styles.
Post: https://openai.com/blog/musenet/
MuseNet will play an experimental concert today from 12–3pm PT on livestream: http://twitch.tv/openai
#audiolearning #musicgeneration #OpenAI #soundgeneration
Openai
MuseNet
We’ve created MuseNet, a deep neural network that can generate 4-minute musical compositions with 10 different instruments, and can combine styles from country to Mozart to the Beatles. MuseNet was not explicitly programmed with our understanding of music…
Speech synthesis from neural decoding of spoken sentences
Researchers tapped the brains of five epilepsy patients who had been implanted with electrodes to map the source of seizures, according to a paper published by #Nature. During a lull in the procedure, they had the patients read English-language texts aloud. They recorded the fluctuating voltage as the brain controlled the muscles involved in speaking. Later, they fed the voltage measurements into a synthesizer.
Nature: https://www.nature.com/articles/s41586-019-1119-1
Paper: https://www.biorxiv.org/content/biorxiv/early/2018/11/29/481267.full.pdf
YouTube: https://www.youtube.com/watch?v=kbX9FLJ6WKw
#DeepDiveWeekly #DL #speech #audiolearning
Researchers tapped the brains of five epilepsy patients who had been implanted with electrodes to map the source of seizures, according to a paper published by #Nature. During a lull in the procedure, they had the patients read English-language texts aloud. They recorded the fluctuating voltage as the brain controlled the muscles involved in speaking. Later, they fed the voltage measurements into a synthesizer.
Nature: https://www.nature.com/articles/s41586-019-1119-1
Paper: https://www.biorxiv.org/content/biorxiv/early/2018/11/29/481267.full.pdf
YouTube: https://www.youtube.com/watch?v=kbX9FLJ6WKw
#DeepDiveWeekly #DL #speech #audiolearning
Nature
Speech synthesis from neural decoding of spoken sentences
Nature - A neural decoder uses kinematic and sound representations encoded in human cortical activity to synthesize audible sentences, which are readily identified and transcribed by listeners.
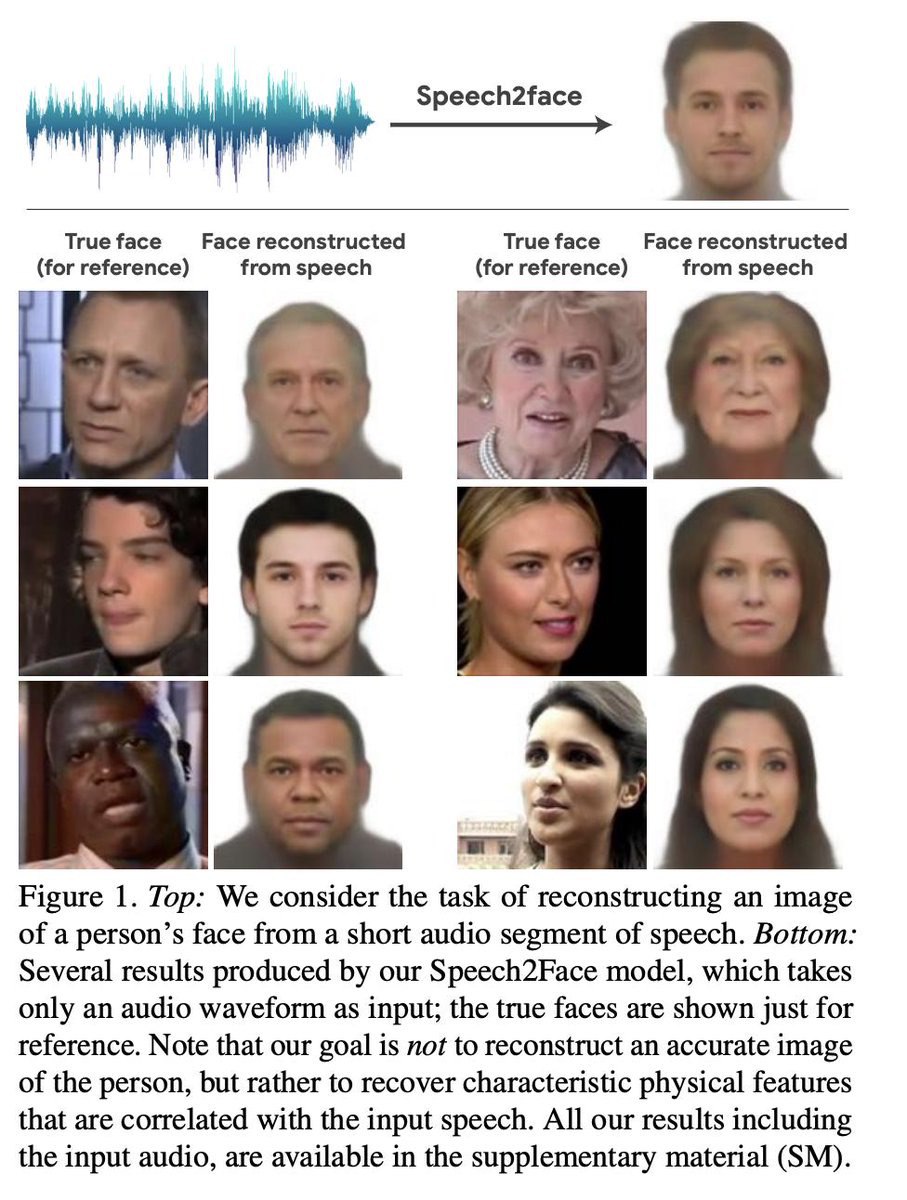
Recovering person appereance from person’s speech
As the result of the research, much resembling facial image of a person reconstructed from short audio recording of that person speaking.
ArXiV: https://arxiv.org/pdf/1905.09773v1.pdf
#speech #audiolearning #CV #DL #face
As the result of the research, much resembling facial image of a person reconstructed from short audio recording of that person speaking.
ArXiV: https://arxiv.org/pdf/1905.09773v1.pdf
#speech #audiolearning #CV #DL #face
{kind=link}
Online speech recognition with wav2letter@anywhere
Facebook have open-sourced wav2letter@anywhere, an inference framework for online speech recognition that delivers state-of-the-art performance.
Link: https://ai.facebook.com/blog/online-speech-recognition-with-wav2letteranywhere/
#wav2letter #audiolearning #soundlearning #sound #acoustic #audio #facebook
Facebook have open-sourced wav2letter@anywhere, an inference framework for online speech recognition that delivers state-of-the-art performance.
Link: https://ai.facebook.com/blog/online-speech-recognition-with-wav2letteranywhere/
#wav2letter #audiolearning #soundlearning #sound #acoustic #audio #facebook
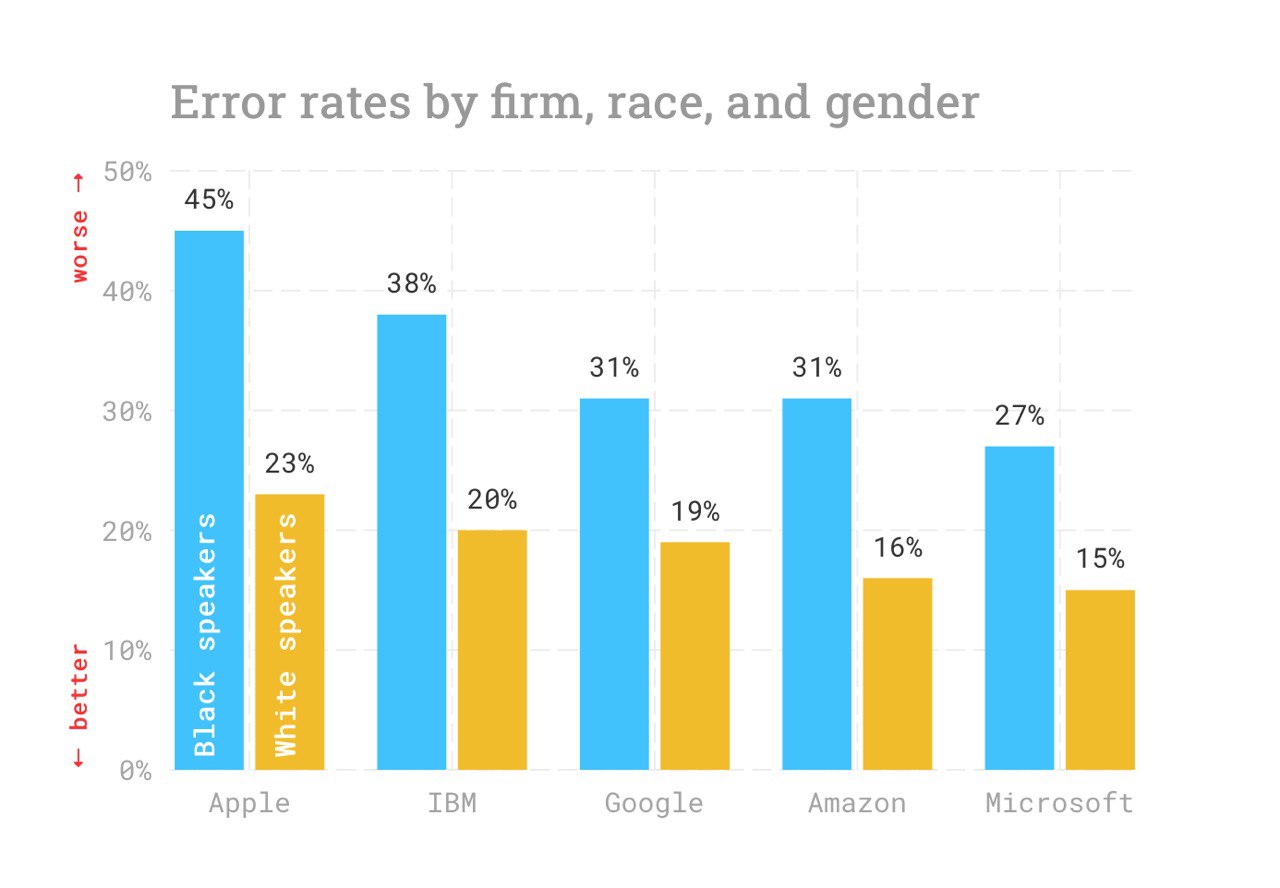
Racial Disparities in Automated Speech Recognition
To no surprise, speech recognition tools have #bias due to the lack of diversity in the datasets. Group of explorers addressed that issue and provided their’s research results as a paper and #reproducible research repo.
Project link: https://fairspeech.stanford.edu
Paper: https://www.pnas.org/cgi/doi/10.1073/pnas.1915768117
Github: https://github.com/stanford-policylab/asr-disparities
#speechrecognition #voice #audiolearning #dl #microsoft #google #apple #ibm #amazon
To no surprise, speech recognition tools have #bias due to the lack of diversity in the datasets. Group of explorers addressed that issue and provided their’s research results as a paper and #reproducible research repo.
Project link: https://fairspeech.stanford.edu
Paper: https://www.pnas.org/cgi/doi/10.1073/pnas.1915768117
Github: https://github.com/stanford-policylab/asr-disparities
#speechrecognition #voice #audiolearning #dl #microsoft #google #apple #ibm #amazon
{kind=link}
🎙🎶Improved audio generative model from OpenAI
Wow! OpenAI just released Jukebox – neural net and service that generates music from genre, artist name, and some lyrics that you can supply. It is can generate even some singing like from corrupted magnet compact cassette.
Some of the sounds seem it is from hell. Agonizing Michel Jakson for example or Creepy Eminiem or Celien Dion
#OpenAI 's approach is to use 3 levels of quantized variational autoencoders VQVAE-2 to learn discrete representations of audio and compress audio by 8x, 32x, and 128x and use the spectral loss to reconstruct spectrograms. And after that, they use sparse transformers conditioned on lyrics to generate new patterns and upsample it to higher discrete samples and decode it to the song.
The net can even learn and generates some solo parts during the track.
explore some creepy songs: https://jukebox.openai.com/
code: https://github.com/openai/jukebox/
paper: https://cdn.openai.com/papers/jukebox.pdf
blog: https://openai.com/blog/jukebox/
#openAI #music #sound #cool #fan #creepy #vae #audiolearning #soundlearning
Wow! OpenAI just released Jukebox – neural net and service that generates music from genre, artist name, and some lyrics that you can supply. It is can generate even some singing like from corrupted magnet compact cassette.
Some of the sounds seem it is from hell. Agonizing Michel Jakson for example or Creepy Eminiem or Celien Dion
#OpenAI 's approach is to use 3 levels of quantized variational autoencoders VQVAE-2 to learn discrete representations of audio and compress audio by 8x, 32x, and 128x and use the spectral loss to reconstruct spectrograms. And after that, they use sparse transformers conditioned on lyrics to generate new patterns and upsample it to higher discrete samples and decode it to the song.
The net can even learn and generates some solo parts during the track.
explore some creepy songs: https://jukebox.openai.com/
code: https://github.com/openai/jukebox/
paper: https://cdn.openai.com/papers/jukebox.pdf
blog: https://openai.com/blog/jukebox/
#openAI #music #sound #cool #fan #creepy #vae #audiolearning #soundlearning
S2IGAN — Speech-to-Image Generation via Adversarial Learning
Authors present a framework that translates speech to images bypassing text information, thus allowing unwritten languages to potentially benefit from this technology.
ArXiV: https://arxiv.org/abs/2005.06968
Project: https://xinshengwang.github.io/project/s2igan/
#DL #audiolearning #speechrecognition
Authors present a framework that translates speech to images bypassing text information, thus allowing unwritten languages to potentially benefit from this technology.
ArXiV: https://arxiv.org/abs/2005.06968
Project: https://xinshengwang.github.io/project/s2igan/
#DL #audiolearning #speechrecognition
王新升
S2IGAN | 王新升
A framework that translates speech descriptions to photo-realistic images without using any text information.