
Как прошла летняя школа ANR-Lab «Web-scraping and API for social scientific research»
5 августа завершилась летняя школа «Web-scraping and API for social scientific research», которую провела сотрудница ANR-Lab Лика Капустина.
Почти два месяца участники учились самостоятельно собирать и обрабатывать данные с веб-страниц и через API с помощью Python. Школа вышла практикоориентированной: каждое занятие представляло из себя небольшой проект по сбору и обработке данных. Помимо практики на Python, на каждом занятии участники обсуждали, какие социально-научные исследования могут быть реализованы на основе данных, собранных на занятии, а также этические вопросы их использования.
На заключительном занятии участники школы под руководством сотрудников ANR-Lab представили собственные проекты, основанные на сборе данных из открытых источников.
Подробнее о проектах и впечатлениях участников — по ссылке!
5 августа завершилась летняя школа «Web-scraping and API for social scientific research», которую провела сотрудница ANR-Lab Лика Капустина.
Почти два месяца участники учились самостоятельно собирать и обрабатывать данные с веб-страниц и через API с помощью Python. Школа вышла практикоориентированной: каждое занятие представляло из себя небольшой проект по сбору и обработке данных. Помимо практики на Python, на каждом занятии участники обсуждали, какие социально-научные исследования могут быть реализованы на основе данных, собранных на занятии, а также этические вопросы их использования.
На заключительном занятии участники школы под руководством сотрудников ANR-Lab представили собственные проекты, основанные на сборе данных из открытых источников.
Подробнее о проектах и впечатлениях участников — по ссылке!
Мастер-класс DASS «Анализ данных без кода»
22 августа, 18.30 приглашаем вас на мастер-класс от нашей магистерской программы «Аналитика данных и прикладная статистика».
Этот мастер-класс идеально подходит для всех, кто хочет освоит анализ данных, не имея опыта в программировании. Программа мастер-класса включает:
🔸Введение в Orange: установка и базовая настройка
🔹Основы визуализации данных
🔸Примеры анализа данных в различных областях
🔹Практическая работа с реальными данными
В ходе мастер-класса вы научитесь эффективно использовать Orange для анализа данных и визуализации, а также получите ответы на все ваши вопросы.
Для участия необходимо зарегистрироваться.
22 августа, 18.30 приглашаем вас на мастер-класс от нашей магистерской программы «Аналитика данных и прикладная статистика».
Этот мастер-класс идеально подходит для всех, кто хочет освоит анализ данных, не имея опыта в программировании. Программа мастер-класса включает:
🔸Введение в Orange: установка и базовая настройка
🔹Основы визуализации данных
🔸Примеры анализа данных в различных областях
🔹Практическая работа с реальными данными
В ходе мастер-класса вы научитесь эффективно использовать Orange для анализа данных и визуализации, а также получите ответы на все ваши вопросы.
Для участия необходимо зарегистрироваться.
Forwarded from Вышка Онлайн
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Вышка Онлайн
This media is not supported in your browser
VIEW IN TELEGRAM
Друзья, обновление в сегодняшних мероприятиях:
🔸 В 18.30 приходите на трансляцию Вышки Онлайн с нашей студенткой Марией Ермолаевой.
🔹А в 19.00 ждём вас на мастер-классе DASS «Анализ данных без кода», регистрация - здесь.
До встречи!
🔸 В 18.30 приходите на трансляцию Вышки Онлайн с нашей студенткой Марией Ермолаевой.
🔹А в 19.00 ждём вас на мастер-классе DASS «Анализ данных без кода», регистрация - здесь.
До встречи!
Telegram
Вышка Онлайн
УЖЕ СЕГОДНЯ!
🧚В 18:30 состоится трансляция со студентом магистратуры Вышки Онлайн!
Отдадим прямой эфир в управление Марии Ермолаевой, студентке 2-го курса онлайн-магистратуры «Data Analytics and Social Statistics».
Она поделится с вами своим личным…
🧚В 18:30 состоится трансляция со студентом магистратуры Вышки Онлайн!
Отдадим прямой эфир в управление Марии Ермолаевой, студентке 2-го курса онлайн-магистратуры «Data Analytics and Social Statistics».
Она поделится с вами своим личным…
Как использовать социальные сети для сбора информации в чрезвычайных ситуациях?
Будь то наводнение, лесной пожар, террористическая атака или военные действия, зачастую Telegram-каналы и СМИ собирают публикации местных жителей и пострадавших о происшествии для того, чтобы показать, как именно разворачиваются события в отсутствии официальных данных. Авторы статьи «Twitter* analysis in emergency management: recent research and trends» показывают, как данные из социальных сетей могут быть полезны в случаях, когда и сами власти не обладают всей информацией для быстрого и эффективного решения проблемы.
Авторы собрали обзор литературы о том, какие стратегии исследователи менеджмента ЧС выбирают на этапах:
🔸 сбора данных (APIs, скрепинг HTML-страниц социальных сетей, использование готовых приложений);
🔹 подготовки данных (фильтрация, очистка, токенизация и перевод в матричный вид);
🔸 анализа данных (контент-анализ, сетевой анализ, анализ метаданных, NLP модели и пространственный анализ).
Только некоторые из представленных в статье исследований:
🔹Wong, C. M. L., & Jensen, O. (2022). The paradox of trust: perceived risk and public compliance during the COVID-19 pandemic in Singapore. In COVID-19 (pp. 189-198). Routledge.
Контент-анализ данных из социальных сетей позволил изучить взаимосвязь между доверием к правительству, восприятием рисков и соблюдением ограничений в первые месяцы COVID-19 в Сингапуре.
🔸Schempp, T., Zhang, H., Schmidt, A., Hong, M., & Akerkar, R. (2019). A framework to integrate social media and authoritative data for disaster relief detection and distribution optimization. International Journal of Disaster Risk Reduction.
Статистический анализ в связке с анализом геотегов позволили сформировать представления о потребностях и ресурсах (например, питьевой воды или спасательных шлюпках) в различных зонах стихийных бедствий.
🔹Gulesan, O. B., Anil, E., & Boluk, P. S. (2021). Social media-based emergency management to detect earthquakes and organize civilian volunteers. International Journal of Disaster Risk Reduction.
K-Nearest Neighbors (KNN), Support Vector Machine (SVM), и the Naive Bayes алгоритм используются для анализа аномалий в твитах для мгновенной идентификации землетрясений, потребностей пострадавших и предложений помощи.
🔸Beedasy, J., Zuniga, A. F. S., Chandler, T., & Slack, T. (2020). Online community discourse during the Deepwater Horizon oil spill: an analysis of Twitter interactions. International Journal of Disaster Risk Reduction.
Контент-анализ, МЛ-модели и SNA применены для анализа формирования дискурса вокруг разлива нефти на скважине Deepwater Horizon в 2010 году.
🔹Hunt, K., Wang, B., & Zhuang, J. (2020). Misinformation debunking and cross-platform information sharing through Twitter during Hurricanes Harvey and Irma: a case study on shelters and ID checks. Natural Hazards, 103(1), 861-883.
Статистический анализ дополнительно созданных метрик твитов (продолжительность жизни, разоблачение и кросс-платформенные источники) позволил проанализровать особенности борьбы со слухами о проверке миграционного статуса на входе в укрытия во время ураганов Харви и Ирма.
Если вы интересуетесь анализом ЧС в России, эта статья станет отличным погружением в методы и примеры работ. Несмотря на блокировку Twitter/X*, подобные исследования можно проводить на базе ВКонтакте, который дает доступ к своему API.
* - заблокирован в России
Будь то наводнение, лесной пожар, террористическая атака или военные действия, зачастую Telegram-каналы и СМИ собирают публикации местных жителей и пострадавших о происшествии для того, чтобы показать, как именно разворачиваются события в отсутствии официальных данных. Авторы статьи «Twitter* analysis in emergency management: recent research and trends» показывают, как данные из социальных сетей могут быть полезны в случаях, когда и сами власти не обладают всей информацией для быстрого и эффективного решения проблемы.
Авторы собрали обзор литературы о том, какие стратегии исследователи менеджмента ЧС выбирают на этапах:
🔸 сбора данных (APIs, скрепинг HTML-страниц социальных сетей, использование готовых приложений);
🔹 подготовки данных (фильтрация, очистка, токенизация и перевод в матричный вид);
🔸 анализа данных (контент-анализ, сетевой анализ, анализ метаданных, NLP модели и пространственный анализ).
Только некоторые из представленных в статье исследований:
🔹Wong, C. M. L., & Jensen, O. (2022). The paradox of trust: perceived risk and public compliance during the COVID-19 pandemic in Singapore. In COVID-19 (pp. 189-198). Routledge.
Контент-анализ данных из социальных сетей позволил изучить взаимосвязь между доверием к правительству, восприятием рисков и соблюдением ограничений в первые месяцы COVID-19 в Сингапуре.
🔸Schempp, T., Zhang, H., Schmidt, A., Hong, M., & Akerkar, R. (2019). A framework to integrate social media and authoritative data for disaster relief detection and distribution optimization. International Journal of Disaster Risk Reduction.
Статистический анализ в связке с анализом геотегов позволили сформировать представления о потребностях и ресурсах (например, питьевой воды или спасательных шлюпках) в различных зонах стихийных бедствий.
🔹Gulesan, O. B., Anil, E., & Boluk, P. S. (2021). Social media-based emergency management to detect earthquakes and organize civilian volunteers. International Journal of Disaster Risk Reduction.
K-Nearest Neighbors (KNN), Support Vector Machine (SVM), и the Naive Bayes алгоритм используются для анализа аномалий в твитах для мгновенной идентификации землетрясений, потребностей пострадавших и предложений помощи.
🔸Beedasy, J., Zuniga, A. F. S., Chandler, T., & Slack, T. (2020). Online community discourse during the Deepwater Horizon oil spill: an analysis of Twitter interactions. International Journal of Disaster Risk Reduction.
Контент-анализ, МЛ-модели и SNA применены для анализа формирования дискурса вокруг разлива нефти на скважине Deepwater Horizon в 2010 году.
🔹Hunt, K., Wang, B., & Zhuang, J. (2020). Misinformation debunking and cross-platform information sharing through Twitter during Hurricanes Harvey and Irma: a case study on shelters and ID checks. Natural Hazards, 103(1), 861-883.
Статистический анализ дополнительно созданных метрик твитов (продолжительность жизни, разоблачение и кросс-платформенные источники) позволил проанализровать особенности борьбы со слухами о проверке миграционного статуса на входе в укрытия во время ураганов Харви и Ирма.
Если вы интересуетесь анализом ЧС в России, эта статья станет отличным погружением в методы и примеры работ. Несмотря на блокировку Twitter/X*, подобные исследования можно проводить на базе ВКонтакте, который дает доступ к своему API.
* - заблокирован в России
SpringerLink
Twitter analysis in emergency management: recent research and trends
Social Network Analysis and Mining - A disaster is an unexpected event with negative consequences for individuals and societies. Typically it is interfering with a community’s or...
Мастер-класс DASS «Программа Pajek для анализа и визуализации комплексных сетей»
29 августа в 18.30 приглашаем вас на последний летний мастер-класс, посвященный работе в программе для анализа и визуализации больших сетей Pajek.
Мастер-класс проведет заведующая ANR-Lab Дарья Мальцева, которая изучала программу Pajek в процессе стажировок в Университете Любляны и совместной работы с проф. Владимиром Батагелем.
Участники мастер-класса познакомятся с базовым функционалом программы Pajek, научатся создавать и изменять сетевые данные, рассчитывать базовые сетевые метрики для отдельных узлов и сетей в целом, делать визуализации сетей, а также узнают о возможностях продвинутого анализа сетевых данных различных типов (двумодальные, ацикличные, многореляционные сети, кластеризация и блокмоделинг и др.). Мастер-класс будет нацелен на то, чтобы участники получили полное представление о процессе работы с сетевыми данными и смогли работать в программе Pajek в ходе своих исследований.
Регистрация по ссылке!
29 августа в 18.30 приглашаем вас на последний летний мастер-класс, посвященный работе в программе для анализа и визуализации больших сетей Pajek.
Мастер-класс проведет заведующая ANR-Lab Дарья Мальцева, которая изучала программу Pajek в процессе стажировок в Университете Любляны и совместной работы с проф. Владимиром Батагелем.
Участники мастер-класса познакомятся с базовым функционалом программы Pajek, научатся создавать и изменять сетевые данные, рассчитывать базовые сетевые метрики для отдельных узлов и сетей в целом, делать визуализации сетей, а также узнают о возможностях продвинутого анализа сетевых данных различных типов (двумодальные, ацикличные, многореляционные сети, кластеризация и блокмоделинг и др.). Мастер-класс будет нацелен на то, чтобы участники получили полное представление о процессе работы с сетевыми данными и смогли работать в программе Pajek в ходе своих исследований.
Регистрация по ссылке!
День открытых дверей с выпускницей программы
1 сентября в 13.00 онлайн программа «Data Analytics and Social Statistics» («Аналитика данных и прикладная статистика») проведет день открытых дверей с выпускницей программы Диной Яковлевой.
Дина расскажет, кому подойдёт данная программа, и какие карьерные перспективы появляются у ее выпускников. А также, можно ли успешно влиться в обучение на программе без опыта в математике или программировании. И как можно применить полученные знания уже в процессе обучения.
Язык семинара — русский.
Для участия необходимо зарегистрироваться.
1 сентября в 13.00 онлайн программа «Data Analytics and Social Statistics» («Аналитика данных и прикладная статистика») проведет день открытых дверей с выпускницей программы Диной Яковлевой.
Дина расскажет, кому подойдёт данная программа, и какие карьерные перспективы появляются у ее выпускников. А также, можно ли успешно влиться в обучение на программе без опыта в математике или программировании. И как можно применить полученные знания уже в процессе обучения.
Язык семинара — русский.
Для участия необходимо зарегистрироваться.
Forwarded from Вышка Онлайн
Please open Telegram to view this post
VIEW IN TELEGRAM
Привлекают ли белки-хирурги цитируемость? Отвечает ChatGPT 🐿🎓
В своем исследовании Майк Телволл задаётся вопросом, может ли такая LLM как ChatGPT заменить рецензента, решающего, какие статьи заслуживают публикации, а какие нет.
Для этого он самостоятельно оценил по специальной шкале 50 своих статей, часть из которых была опубликована, а часть — забракована автором или рецензентами. Затем сформулировал критерии этой шкалы и обучил модель давать по ней оценки статьям.
Сравнение оценок человека и ChatGPT показало, что модель оценивает статьи неточно (большое среднее отклонение) и объясняет только 25% дисперсии человеческих оценок. При повторах, модель оценивала одни и те же статьи по-разному.
Наконец, Телволл заменил в слабой статье людей на белок, получив заголовок «Do squirrel surgeons generate more citation impact?». ChatGPT высоко оценил оригинальность статьи, ее методологическую точность и потенциальное влияние на науку и практику.
Да, вероятно, LLM смогут когда-нибудь стать подспорьем рецензентов, но нужно помнить, что ChatGPT — это всё ещё тот самый узник «китайской комнаты» Джона Сёрля, бездумно сопоставлющий незнакомые иероглифы. Модели смогут заменить рецензентов только тогда, когда они же полностью заменят и авторов, и респондентов.
В своем исследовании Майк Телволл задаётся вопросом, может ли такая LLM как ChatGPT заменить рецензента, решающего, какие статьи заслуживают публикации, а какие нет.
Для этого он самостоятельно оценил по специальной шкале 50 своих статей, часть из которых была опубликована, а часть — забракована автором или рецензентами. Затем сформулировал критерии этой шкалы и обучил модель давать по ней оценки статьям.
Сравнение оценок человека и ChatGPT показало, что модель оценивает статьи неточно (большое среднее отклонение) и объясняет только 25% дисперсии человеческих оценок. При повторах, модель оценивала одни и те же статьи по-разному.
Наконец, Телволл заменил в слабой статье людей на белок, получив заголовок «Do squirrel surgeons generate more citation impact?». ChatGPT высоко оценил оригинальность статьи, ее методологическую точность и потенциальное влияние на науку и практику.
Да, вероятно, LLM смогут когда-нибудь стать подспорьем рецензентов, но нужно помнить, что ChatGPT — это всё ещё тот самый узник «китайской комнаты» Джона Сёрля, бездумно сопоставлющий незнакомые иероглифы. Модели смогут заменить рецензентов только тогда, когда они же полностью заменят и авторов, и респондентов.
Sciendo
Can ChatGPT evaluate research quality?
Purpose
Assess whether ChatGPT 4.0 is accurate enough to perform research evaluations on journal articles to automate this...
Assess whether ChatGPT 4.0 is accurate enough to perform research evaluations on journal articles to automate this...
Forwarded from DASS (MASNA) Admissions
Анализируй и визуализируй!
Уже сегодня в 18.30 состоится уникальный мастер-класс DASS «Программа Pajek для анализа и визуализации комплексных сетей».
Мастер-класс проведет заведующая ANR-Lab Дарья Мальцева, которая изучала программу Pajek в процессе стажировок в Университете Любляны и совместной работы с профессором Владимиром Батагелем.
Участники мастер-класса познакомятся с базовым функционалом программы Pajek, научатся создавать и изменять сетевые данные, рассчитывать базовые сетевые метрики для отдельных узлов и сетей в целом, делать визуализации сетей, а также узнают о возможностях продвинутого анализа сетевых данных различных типов (двумодальные, ацикличные, многореляционные сети, кластеризация и блокмоделинг и др.).
Подключайтесь в 18.30
Уже сегодня в 18.30 состоится уникальный мастер-класс DASS «Программа Pajek для анализа и визуализации комплексных сетей».
Мастер-класс проведет заведующая ANR-Lab Дарья Мальцева, которая изучала программу Pajek в процессе стажировок в Университете Любляны и совместной работы с профессором Владимиром Батагелем.
Участники мастер-класса познакомятся с базовым функционалом программы Pajek, научатся создавать и изменять сетевые данные, рассчитывать базовые сетевые метрики для отдельных узлов и сетей в целом, делать визуализации сетей, а также узнают о возможностях продвинутого анализа сетевых данных различных типов (двумодальные, ацикличные, многореляционные сети, кластеризация и блокмоделинг и др.).
Подключайтесь в 18.30
Forwarded from DASS (MASNA) Admissions
This media is not supported in your browser
VIEW IN TELEGRAM
Forwarded from Выше квартилей
Анализ цитирований в российских публикациях в Web of Science
В последнем выпуске Journal of Scientometric Research в соавторстве с Дарьей Мальцевой (ВШЭ) вышла статья, посвященная библиометрическому анализу российской науки на базе 1,38 млн публикаций российских (со)авторов.
В основе работы — использование метода спектроскопии года публикации цитируемых работ (RPYS — Reference Publication Year Spectroscopy), разработанного в 2013 Вернером Марксом. Этот метод, как правило, применяется для более ограниченных датасетов (например, для публикаций одного исследователя, журнала или научной дисциплины). Для обработки миллионов записей данных метод был масштабирован авторами исследования с использованием СУБД, что позволило проанализировать исторические корни российской науки.
В качестве исходных данных был взят массив статей, индексированных в WoS до мая 2022 года, у которых хотя бы один из авторов имеет российскую аффилиацию, в виде текстовых файлов. Почти все статьи приходятся на период с 1992 по 2022 гг, до 1992 публикаций крайне мало. Общее количество ссылок в описанном массиве — более 32 млн, при этом 1,66 млн ведут на статьи, входящие в исходный датасет.
Согласно результатам исследования:
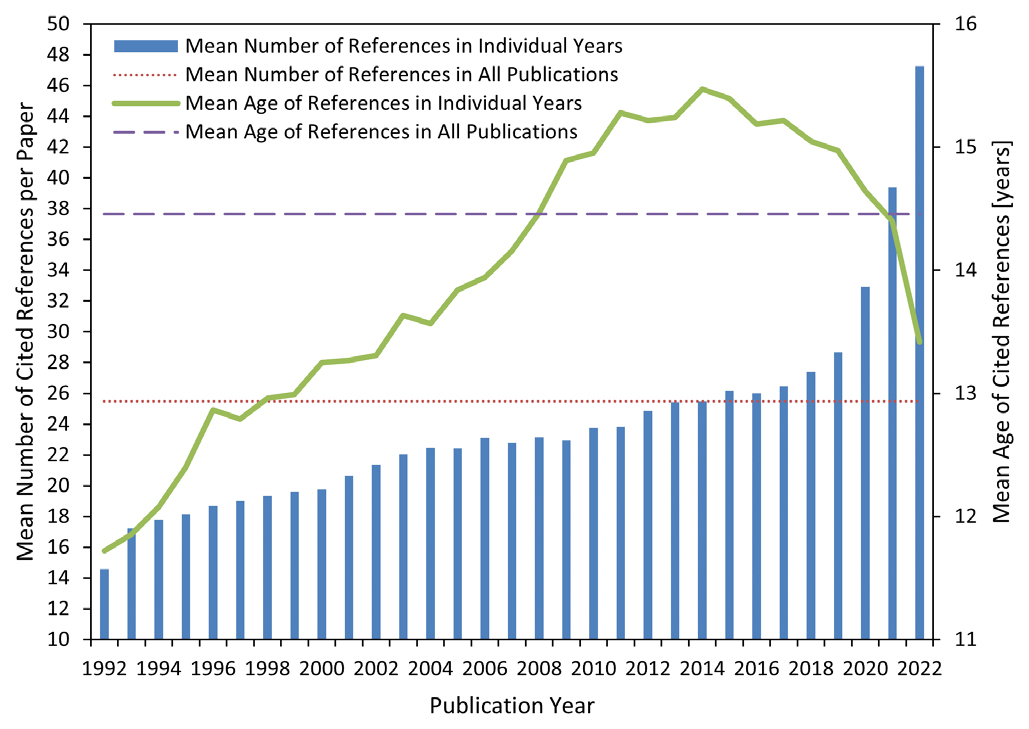
🔹 Количество ссылок в статьях заметно возросло с течением времени: если в 1992 г. в публикации приводилось в среднем 15 ссылок, то в 2022 г. их было 47.
🔹 Один из основных объектов анализа — разница в «возрасте» между статьей и публикациями, которая она цитирует. Подавляющее большинство ссылок приходится на группу 20+ лет — это означает, что российская наука в значительной степени опиралась на более «старые» фундаментальные исследования.
🔹 Общий средний возраст цитируемых статей составил 14,5 лет, и в рассматриваемый период (с 1992 по 2022) он увеличился примерно на 14%. Следует отметить и динамику: так, средний возраст достигает пика (15,5 лет) в 2014 г., а затем снижается. Таким образом, авторы публикаций, написанных после 2014 года, начинают чаще цитировать более «свежие» статьи.
Если говорить о научных журналах, то во все периоды чаще всего цитировались Physical Review Letters, Physical Review B, Physical Review D, The Astrophysical Journal, The Journal of Chemical Physics и Journal of the American Chemical Society, а также Nature и Science. До 2000 года в топ-10 входили также «Доклады Академии Наук СССР», но после 2000-х цитировать их практически перестали.
Так или иначе, подавляющее число цитирований приходится на долю естественных наук, что отмечают и сами авторы.
#обзор #цитирования #RPYS #WebofScience
В последнем выпуске Journal of Scientometric Research в соавторстве с Дарьей Мальцевой (ВШЭ) вышла статья, посвященная библиометрическому анализу российской науки на базе 1,38 млн публикаций российских (со)авторов.
В основе работы — использование метода спектроскопии года публикации цитируемых работ (RPYS — Reference Publication Year Spectroscopy), разработанного в 2013 Вернером Марксом. Этот метод, как правило, применяется для более ограниченных датасетов (например, для публикаций одного исследователя, журнала или научной дисциплины). Для обработки миллионов записей данных метод был масштабирован авторами исследования с использованием СУБД, что позволило проанализировать исторические корни российской науки.
В качестве исходных данных был взят массив статей, индексированных в WoS до мая 2022 года, у которых хотя бы один из авторов имеет российскую аффилиацию, в виде текстовых файлов. Почти все статьи приходятся на период с 1992 по 2022 гг, до 1992 публикаций крайне мало. Общее количество ссылок в описанном массиве — более 32 млн, при этом 1,66 млн ведут на статьи, входящие в исходный датасет.
Согласно результатам исследования:
🔹 Количество ссылок в статьях заметно возросло с течением времени: если в 1992 г. в публикации приводилось в среднем 15 ссылок, то в 2022 г. их было 47.
🔹 Один из основных объектов анализа — разница в «возрасте» между статьей и публикациями, которая она цитирует. Подавляющее большинство ссылок приходится на группу 20+ лет — это означает, что российская наука в значительной степени опиралась на более «старые» фундаментальные исследования.
🔹 Общий средний возраст цитируемых статей составил 14,5 лет, и в рассматриваемый период (с 1992 по 2022) он увеличился примерно на 14%. Следует отметить и динамику: так, средний возраст достигает пика (15,5 лет) в 2014 г., а затем снижается. Таким образом, авторы публикаций, написанных после 2014 года, начинают чаще цитировать более «свежие» статьи.
Если говорить о научных журналах, то во все периоды чаще всего цитировались Physical Review Letters, Physical Review B, Physical Review D, The Astrophysical Journal, The Journal of Chemical Physics и Journal of the American Chemical Society, а также Nature и Science. До 2000 года в топ-10 входили также «Доклады Академии Наук СССР», но после 2000-х цитировать их практически перестали.
Так или иначе, подавляющее число цитирований приходится на долю естественных наук, что отмечают и сами авторы.
#обзор #цитирования #RPYS #WebofScience
{kind=link}
Вебинар "Как анализировать рынок труда: сравнение россйских и международных рекрутинговых платформ"
5 сентября в 18:30 онлайн программа «Data Analytics and Social Statistics» («Аналитика данных и прикладная статистика») проводит семинар по изучению рынка труда аналитиков данных.
Мы изучили компетенции, формируемые у выпускников, и сравнили их с вакансиями, представленными на рекрутинговых платформах.
На вебинаре мы расскажем:
🔸 Какие курсы программы DASS могут помочь в анализе рынка труда.
🔹 Какие навыки по сбору данных, которым мы учим на программе, пригодятся для работы с рекрутинговыми платформами.
🔸 В чем заключается специфика вакансий аналитиков данных.
🔹 Каковы сходства и отличия российских и международных вакансий по анализу данных.
🔸 Как прикладной сетевой анализ поможет в понимании рынка труда.
Язык семинара — русский.
Для участия необходимо зарегистрироваться.
5 сентября в 18:30 онлайн программа «Data Analytics and Social Statistics» («Аналитика данных и прикладная статистика») проводит семинар по изучению рынка труда аналитиков данных.
Мы изучили компетенции, формируемые у выпускников, и сравнили их с вакансиями, представленными на рекрутинговых платформах.
На вебинаре мы расскажем:
🔸 Какие курсы программы DASS могут помочь в анализе рынка труда.
🔹 Какие навыки по сбору данных, которым мы учим на программе, пригодятся для работы с рекрутинговыми платформами.
🔸 В чем заключается специфика вакансий аналитиков данных.
🔹 Каковы сходства и отличия российских и международных вакансий по анализу данных.
🔸 Как прикладной сетевой анализ поможет в понимании рынка труда.
Язык семинара — русский.
Для участия необходимо зарегистрироваться.
Forwarded from DASS (MASNA) Admissions
Через полчаса состоится вебинар с выпускницей программы Диной Яковлевой.
Дина расскажет, какие карьерные перспективы появляются у выпускников программы "Аналитика данных и прикладная статистика".
Язык семинара — русский.
Подключайтесь в 13.00
Дина расскажет, какие карьерные перспективы появляются у выпускников программы "Аналитика данных и прикладная статистика".
Язык семинара — русский.
Подключайтесь в 13.00