
Предиктивный ввод текста на клавиатуре мобильного телефона известен нам по крайней мере с 70-х годов. Наверное, большинство из нас знакомы с Т9 , «Text on 9 keys» — алгоритмом, который позволял ускорить набор текста на кнопочных телефонах.
Сегодня мы рассказываем о том, как работает Т9 и его преемник iTap, подсказывающий слова на современных мобильных устройствах с полноценной qwerty-клавиатурой.
#knowhow #nlp #sysblok
https://telegra.ph/Zemlya-emu-puhovik-Kak-rabotaet-T9-11-22
Сегодня мы рассказываем о том, как работает Т9 и его преемник iTap, подсказывающий слова на современных мобильных устройствах с полноценной qwerty-клавиатурой.
#knowhow #nlp #sysblok
https://telegra.ph/Zemlya-emu-puhovik-Kak-rabotaet-T9-11-22
Telegraph
Земля ему пуховик. Как работает Т9?
Т9 Технологии интеллектуального (предиктивного) ввода текста стали развиваться задолго до первых мобильных устройств. В 50-е годы XX века человек по имени Чжан Цзицзинь создал систему ассоциативных кластеров текста, чтобы облегчить себе работу. Он был наборщиком…
Специальные чат-боты для изучения иностранного языка завоевывают популярность во всем мире. Почему это работает?
Чат-бот — идеальный собеседник для обучения: перед ним не стыдно, с ним можно переписываться примерно как с приятелями в мессенджере, а еще он не устает. И не требует почасовой оплаты! Как говорится, what’s not to like?
#education #nlp #sysblok
https://telegra.ph/Ne-stydno-i-veselo-chem-horoshi-yazykovye-boty-11-22
Чат-бот — идеальный собеседник для обучения: перед ним не стыдно, с ним можно переписываться примерно как с приятелями в мессенджере, а еще он не устает. И не требует почасовой оплаты! Как говорится, what’s not to like?
#education #nlp #sysblok
https://telegra.ph/Ne-stydno-i-veselo-chem-horoshi-yazykovye-boty-11-22
Telegraph
Не стыдно и весело: чем хороши языковые боты
Кто хоть раз не проводил скучный вечер за троллингом голосового помощника Алисы? В режиме «болталки» Алиса пытается поддерживать беседу, генерировать остроумные ответы, играть в простые языковые игры — то есть, быть приятным собеседником. Но это работает…
Наверное, каждый хоть раз пробовал поболтать с яндексовской Алисой. Но знаете ли вы что-нибудь о ее предшественнице Элизе и о том, когда человек впервые смог поговорить с роботом?
Если нет, то скорее читайте нашу статью о бабушке современных чат-ботов!
#nlp #sysblok
https://telegra.ph/Rozhdenie-govoryashchih-mashin-11-22
Если нет, то скорее читайте нашу статью о бабушке современных чат-ботов!
#nlp #sysblok
https://telegra.ph/Rozhdenie-govoryashchih-mashin-11-22
Telegraph
Рождение говорящих машин
Человеку захотелось поговорить с роботом уже к середине прошлого века: в 1950 году Айзек Азимов выпускает сборник рассказов «Я, Робот» вместе с тремя законами робототехники, и в этом же году Алан Тьюринг публикует статью «Вычислительные машины и разум», где…
Краудсорсинг в Digital Humanities: опыт Латвийского фольклорного архива
#nlp #philology
Из фольклорных и диалектологических экспедиций ученые привозят множество материалов — тетрадей и аудиозаписей — и передают их в научные институты и университеты. Сейчас записи расшифровываются и классифицируются в цифровом виде, а в доцифровую эпоху — выписывались на карточки. Поэтому большинство материалов существует в виде специализированных изданий, формат которых не позволяет ничего посмотреть или посчитать в текстах автоматически. Только некоторые из таких изданий были оцифрованы и стали доступны для широкой публики.
Волонтеры помогают расшифровывать оцифрованные тексты
В Латвии предложили масштабное и современное решение этой проблемы. В декабре 2014 года Фольклорный архив Латвии к своему 90-летию запустил портал garamantas.lv (garamantas означает духовное наследие или фольклор).
Оцифрованные сканы рукописных листов загружаются в специально разработанную систему, где указаны необходимые метаданные: номер коллекции в архиве, описание коллекции, номера соответствующих архивных единиц и др. Для волонтеров-расшифровщиков разработали подробную инструкцию, а интерфейс доступен на разных языках.
В архиве есть не только латышские материалы, но и ливские песни, русский и белорусский фольклор, тексты на идише и латышском цыганском. Поэтому для участия в расшифровке необязательно знать латышский: в объемной коллекции русского фольклора, собранной Иваном Фридрихом в Латгалии (восточной Латвии), еще достаточно нерасшифрованных текстов. Также, «переписывать» слова со сканов можно и вообще без знания языка.
В 2016 году запустили отдельные «дочерние» ресурсы проекта — «Кудесники столетия» и «Языковая толока» (Valodas talka). «Языковая толока» была направлена на школьников: в течение двух с половиной месяцев им предлагалось поучаствовать в расшифровке рукописей. К окончанию акции собрали статистику об участниках, и наградили самых активных призами. Таким образом удалось привлечь много новых участников и расшифровать более десяти тысяч отсканированных изображений.
Другие проекты фольклорного архива: читаем стихи и поём
В 2017 году, к 150-летию поэта Эдуарда Вейденбаума, запустили акцию «Читай вслух!». Суть акции такова: люди выбирали любое стихотворение из представленных на портале и читали его под запись. Получилась своеобразная база данных с записями латышской речи, хоть и ограниченная конечным списком стихотворных текстов: можно послушать один и тот же текст, зачитанный людьми разных возрастов и из разных мест.
Затем прошли еще две похожие акции: со стихами для детей латышских поэтов-классиков и со стихами столетней давности (написанными или опубликованными в 1919 году).
В начале 2019 года запустили проект «Пой с архивом»: теперь можно не только послушать отдельные музыкальные записи из коллекций архива, но и загрузить свою версию. Пока что на странице этого проекта доступно не очень много записей, но даже в них представлены записи, собранные не только в Латвии, и не только на латышском.
Вот, например, песня, записанная в сибирской латышской деревне Нижняя Буланка в 1991 году (ноты здесь). А вот версия известной латышской народной песни «Kur tu teci, gailīti mans» (Куда бежишь, мой петушок?) на латышском цыганском. Среди выложенных записей есть также песни на ливском, русском и белорусском.
Опыт Латвийского фольклорного архива в некоторой степени уникален — прежде всего благодаря материалу, который представлен в его коллекциях. В то же время он универсален как пример успешного привлечения обычных людей к работе с культурным наследием страны.
Наталья Перкова
#nlp #philology
Из фольклорных и диалектологических экспедиций ученые привозят множество материалов — тетрадей и аудиозаписей — и передают их в научные институты и университеты. Сейчас записи расшифровываются и классифицируются в цифровом виде, а в доцифровую эпоху — выписывались на карточки. Поэтому большинство материалов существует в виде специализированных изданий, формат которых не позволяет ничего посмотреть или посчитать в текстах автоматически. Только некоторые из таких изданий были оцифрованы и стали доступны для широкой публики.
Волонтеры помогают расшифровывать оцифрованные тексты
В Латвии предложили масштабное и современное решение этой проблемы. В декабре 2014 года Фольклорный архив Латвии к своему 90-летию запустил портал garamantas.lv (garamantas означает духовное наследие или фольклор).
Оцифрованные сканы рукописных листов загружаются в специально разработанную систему, где указаны необходимые метаданные: номер коллекции в архиве, описание коллекции, номера соответствующих архивных единиц и др. Для волонтеров-расшифровщиков разработали подробную инструкцию, а интерфейс доступен на разных языках.
В архиве есть не только латышские материалы, но и ливские песни, русский и белорусский фольклор, тексты на идише и латышском цыганском. Поэтому для участия в расшифровке необязательно знать латышский: в объемной коллекции русского фольклора, собранной Иваном Фридрихом в Латгалии (восточной Латвии), еще достаточно нерасшифрованных текстов. Также, «переписывать» слова со сканов можно и вообще без знания языка.
В 2016 году запустили отдельные «дочерние» ресурсы проекта — «Кудесники столетия» и «Языковая толока» (Valodas talka). «Языковая толока» была направлена на школьников: в течение двух с половиной месяцев им предлагалось поучаствовать в расшифровке рукописей. К окончанию акции собрали статистику об участниках, и наградили самых активных призами. Таким образом удалось привлечь много новых участников и расшифровать более десяти тысяч отсканированных изображений.
Другие проекты фольклорного архива: читаем стихи и поём
В 2017 году, к 150-летию поэта Эдуарда Вейденбаума, запустили акцию «Читай вслух!». Суть акции такова: люди выбирали любое стихотворение из представленных на портале и читали его под запись. Получилась своеобразная база данных с записями латышской речи, хоть и ограниченная конечным списком стихотворных текстов: можно послушать один и тот же текст, зачитанный людьми разных возрастов и из разных мест.
Затем прошли еще две похожие акции: со стихами для детей латышских поэтов-классиков и со стихами столетней давности (написанными или опубликованными в 1919 году).
В начале 2019 года запустили проект «Пой с архивом»: теперь можно не только послушать отдельные музыкальные записи из коллекций архива, но и загрузить свою версию. Пока что на странице этого проекта доступно не очень много записей, но даже в них представлены записи, собранные не только в Латвии, и не только на латышском.
Вот, например, песня, записанная в сибирской латышской деревне Нижняя Буланка в 1991 году (ноты здесь). А вот версия известной латышской народной песни «Kur tu teci, gailīti mans» (Куда бежишь, мой петушок?) на латышском цыганском. Среди выложенных записей есть также песни на ливском, русском и белорусском.
Опыт Латвийского фольклорного архива в некоторой степени уникален — прежде всего благодаря материалу, который представлен в его коллекциях. В то же время он универсален как пример успешного привлечения обычных людей к работе с культурным наследием страны.
Наталья Перкова
{kind=link}
Как AI помогает журналистам и почему профессия журналист умрет не скоро
#nlp
Профессию журналиста начали хоронить еще в 2015 году. Тогда в Америке говорили, что компьютер получит Пулитцеровскую премию в течение пяти лет, а к 2030 году 90% журналистских материалов будут создавать роботы.
Сегодня специалисты говорят скорее о новых возможностях использования ИИ в журналистике. Поэтому мы сделали подборку журналистских AI-проектов последних лет.
ИИ сообщает итоги выборов
В ночь после последних всеобщих выборов в Великобритании BBC News опубликовали около 700 новостей о результатах голосования. Так жители 650 избирательных округов Соединенного Королевства узнали о результатах голосования на своей территории в режиме реального времени. Это стало возможным благодаря компьютерной модели, обученной на шаблонах, созданных журналистами-людьми.
ИИ определяет, кто пришел на вечеринку
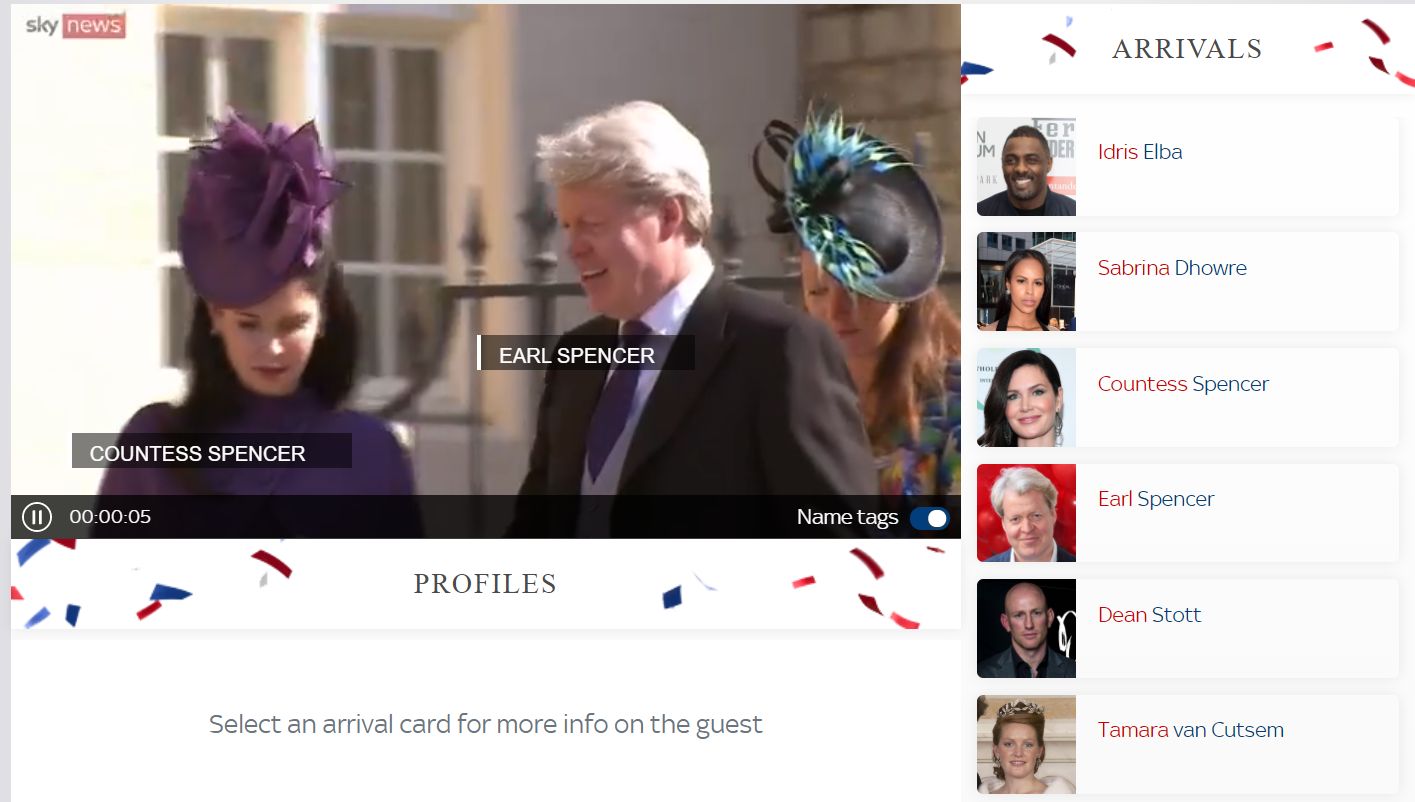
Британский канал Sky News впервые опробовал возможности AI в 2018 году во время скандальной свадьбы принца Гарри и Меган Маркл. С помощью технологии распознавания лиц они определяли, кто пришел на королевское торжество. Результатом стал проект «Кто есть кто» на сайте телеканала.
ИИ определяет, что пользователи хотели бы прочесть в СМИ
Новинка 2020 года — сервис, отслеживающий темы, которые вызывают интерес у читателей, но недостаточно освещены в СМИ. Сервис собирает данные об эффективности контента более чем 600 тысяч статей, публикуемых на 3000 сайтах, в день.
ИИ пишет шаблонные новости для регионов
С 2018 года в Великобритании работает автоматизированная редакция RADAR. Журналист-человек пишет шаблон новости для каждого из возможных сценариев — например, бум, скромный рост или резкое падение преступлений. Затем на основе открытых данных программа создает версии для каждой из 391 областей Великобритании на основе статистики этого региона.
ИИ на спортивных трибунах
Летом 2019 года на Уимблдоне компания IBM представила технологию искусственного интеллекта, которая отслеживает эмоции и характерные жесты спортсменов и зрителей во время матчей. Затем программа выделяет самые захватывающие моменты и создает яркие видео.
В конце 2019 года они представили похожую технологию, но уже обученную комментировать футбольные матчи.
ИИ обрабатывает документы
Летом 2019 года журналистам слили архив, раскрывающий схемы ухода от налогов транснациональных компаний, а модель машинного обучения, созданная в Quartz AI Studio, помогла обработать 200 тысяч документов. Результатом работы 54 журналистов стал интернациональный проект Mauritius Leaks, а создатели модели поделились кодом на GitHub.
ИИ модерирует комментарии
В The New York Times для модерирования комментариев стали использовать бесплатный инструмент Perspective, разработанный Jigsaw и Google с помощью машинного обучения. Модератор-код находит ненормативную лексику, буллинг в комментариях и оценивает их токсичность. Модератор-человек использует эту информацию для сортировки записей и для обратной связи с комментаторами в режиме реального времени.
ИИ оценивает лояльность пользователей
Дата-отдел South China Morning Post создал алгоритм для прогнозирования лояльности читателей и оптимизации маркетинговых кампаний за счет этих данных.
ИИ решает, кому продавать подписку
В редакции швейцарской немецкоязычной газеты Neue Zürcher Zeitung используют искусственный интеллект, чтобы предсказать, кто из читателей и в какой момент готов оформить платную подписку. Использование этого алгоритма повысило коэффициент конверсии на 82%, утверждают представители Neue Zürcher Zeitung.
https://sysblok.ru/linguistics/zhurnalisty-vs-roboty-neravnyj-boj/
#nlp
Профессию журналиста начали хоронить еще в 2015 году. Тогда в Америке говорили, что компьютер получит Пулитцеровскую премию в течение пяти лет, а к 2030 году 90% журналистских материалов будут создавать роботы.
Сегодня специалисты говорят скорее о новых возможностях использования ИИ в журналистике. Поэтому мы сделали подборку журналистских AI-проектов последних лет.
ИИ сообщает итоги выборов
В ночь после последних всеобщих выборов в Великобритании BBC News опубликовали около 700 новостей о результатах голосования. Так жители 650 избирательных округов Соединенного Королевства узнали о результатах голосования на своей территории в режиме реального времени. Это стало возможным благодаря компьютерной модели, обученной на шаблонах, созданных журналистами-людьми.
ИИ определяет, кто пришел на вечеринку
Британский канал Sky News впервые опробовал возможности AI в 2018 году во время скандальной свадьбы принца Гарри и Меган Маркл. С помощью технологии распознавания лиц они определяли, кто пришел на королевское торжество. Результатом стал проект «Кто есть кто» на сайте телеканала.
ИИ определяет, что пользователи хотели бы прочесть в СМИ
Новинка 2020 года — сервис, отслеживающий темы, которые вызывают интерес у читателей, но недостаточно освещены в СМИ. Сервис собирает данные об эффективности контента более чем 600 тысяч статей, публикуемых на 3000 сайтах, в день.
ИИ пишет шаблонные новости для регионов
С 2018 года в Великобритании работает автоматизированная редакция RADAR. Журналист-человек пишет шаблон новости для каждого из возможных сценариев — например, бум, скромный рост или резкое падение преступлений. Затем на основе открытых данных программа создает версии для каждой из 391 областей Великобритании на основе статистики этого региона.
ИИ на спортивных трибунах
Летом 2019 года на Уимблдоне компания IBM представила технологию искусственного интеллекта, которая отслеживает эмоции и характерные жесты спортсменов и зрителей во время матчей. Затем программа выделяет самые захватывающие моменты и создает яркие видео.
В конце 2019 года они представили похожую технологию, но уже обученную комментировать футбольные матчи.
ИИ обрабатывает документы
Летом 2019 года журналистам слили архив, раскрывающий схемы ухода от налогов транснациональных компаний, а модель машинного обучения, созданная в Quartz AI Studio, помогла обработать 200 тысяч документов. Результатом работы 54 журналистов стал интернациональный проект Mauritius Leaks, а создатели модели поделились кодом на GitHub.
ИИ модерирует комментарии
В The New York Times для модерирования комментариев стали использовать бесплатный инструмент Perspective, разработанный Jigsaw и Google с помощью машинного обучения. Модератор-код находит ненормативную лексику, буллинг в комментариях и оценивает их токсичность. Модератор-человек использует эту информацию для сортировки записей и для обратной связи с комментаторами в режиме реального времени.
ИИ оценивает лояльность пользователей
Дата-отдел South China Morning Post создал алгоритм для прогнозирования лояльности читателей и оптимизации маркетинговых кампаний за счет этих данных.
ИИ решает, кому продавать подписку
В редакции швейцарской немецкоязычной газеты Neue Zürcher Zeitung используют искусственный интеллект, чтобы предсказать, кто из читателей и в какой момент готов оформить платную подписку. Использование этого алгоритма повысило коэффициент конверсии на 82%, утверждают представители Neue Zürcher Zeitung.
https://sysblok.ru/linguistics/zhurnalisty-vs-roboty-neravnyj-boj/
{kind=link}
Генерация текстов с помощью моделей Plug and Play от Uber AI
#nlp
Нейросети уже научились правдоподобно дописывать текст за человеком, но есть проблема: их сложно заставить генерировать текст в нужной тональности или по конкретной тематике. Рассказываем про решение, которое позволяет «донастраивать» языковую модель под себя.
Языковая модель Plug and Play (PPLM)
Plug and Play Language Model позволяет пользователю подключать одну или несколько моделей для каждого из желаемых параметров (позитив или негатив, тематика и т. п.) в большую предобученную языковую модель (LM). Обучение или настройка этой языковой модели не требуется, что позволяет исследователям использовать лучшие языковые модели.
Например, без подключения PPLM предварительно обученная модель GPT-2-medium генерирует такое продолжение:
The food is awful. -> The staff are rude and lazy. The food is disgusting — even by my standards.
(Еда ужасна. -> Персонал грубый и ленивый. Еда отвратительна даже по моим стандартам.)
А подключив PPLM и настроив ее так, чтобы она завершила предложение позитивно, модель генерирует такой текст:
The food is awful, but there is also the music, the story and the magic! The «Avenged Sevenfold» is a masterfully performed rock musical that will have a strong presence all over the world.
(Еда ужасна, но еще здесь есть музыка, сюжет, магическая атмосфера. «Avenged Sevenfold» — мастерски исполненный рок-мюзикл, который получит признание по всему миру.)
Задаем тему
В качестве дополнительной модели исследователи использовали мешок слов (Bag of words, BoW) для различных тем, где вероятность темы определяется суммой вероятностей каждого слова в мешке.
Какое бы начало мы ни задали, нейросеть выдаст связный текст по заданной теме.
Задаем тональность
Здесь в качестве дополнительной модели исследователи используют дискриминатор PPLM-Discrim, обученный на наборе данных, размеченном по тональности.
При генерации использовали дискриминатор с 5000 параметрами (1025 параметров на класс (- -, -, 0, +, + +)), обученный на наборе данных SST-5. 5000 параметров — это ничтожно мало по сравнению с количеством параметров в основной модели (LM), и обучать такую модель гораздо легче и быстрее.
Проводим детоксикацию текста
Модели, обученные на большом количестве текстов в Интернете, могут отражать предвзятость и токсичность, присутствующие в исходных данных. Чтобы этого не допустить, при использовании PPLM нужно также подключить классификатор токсичности в качестве модели атрибута и обновить латентность с отрицательным градиентом.
Исследователи из Uber AI провели тест, в котором добровольные оценщики отметили токсичность пятисот образцов текста, сгенерированных PPLM с детоксикацией, и сравнили их с базовой моделью GPT-2. В среднем доля токсичной речи снизилась с 63,6% до 4,6%.
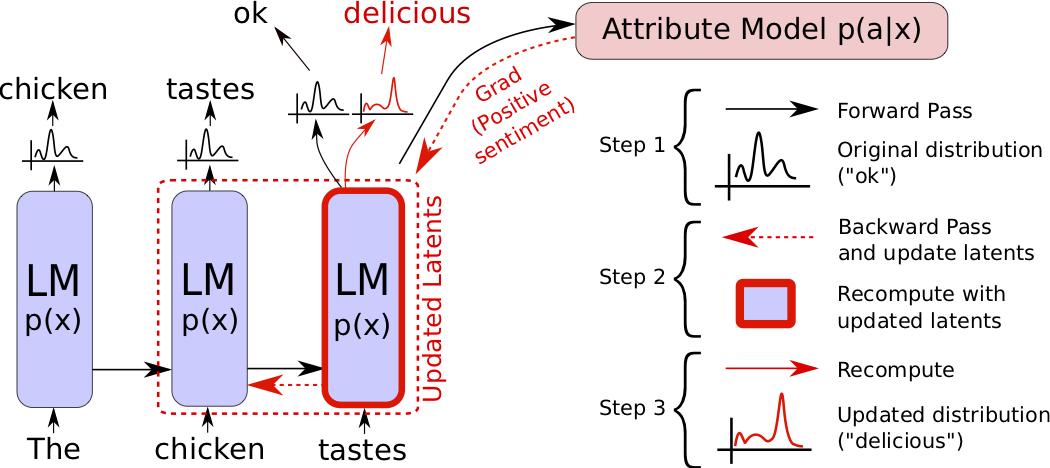
Принцип работы PPLM
Представлен на прикрепленной схеме. Алгоритм PPLM производит прямой и обратный обход нейронной сети, состоящей из двух подсетей — базовой предобученной языковой модели (LM) и модели классификатора по заданному пользователем атрибуту (attribute model).
Код моделей можно посмотреть здесь и здесь. Также доступна интерактивная демонстрация работы моделей.
Полный текст с примерами работы генераторов:
https://sysblok.ru/linguistics/kak-upravljat-mamontom-generiruem-nuzhnye-teksty-s-pomoshhju-modelej-plug-and-play/
#nlp
Нейросети уже научились правдоподобно дописывать текст за человеком, но есть проблема: их сложно заставить генерировать текст в нужной тональности или по конкретной тематике. Рассказываем про решение, которое позволяет «донастраивать» языковую модель под себя.
Языковая модель Plug and Play (PPLM)
Plug and Play Language Model позволяет пользователю подключать одну или несколько моделей для каждого из желаемых параметров (позитив или негатив, тематика и т. п.) в большую предобученную языковую модель (LM). Обучение или настройка этой языковой модели не требуется, что позволяет исследователям использовать лучшие языковые модели.
Например, без подключения PPLM предварительно обученная модель GPT-2-medium генерирует такое продолжение:
The food is awful. -> The staff are rude and lazy. The food is disgusting — even by my standards.
(Еда ужасна. -> Персонал грубый и ленивый. Еда отвратительна даже по моим стандартам.)
А подключив PPLM и настроив ее так, чтобы она завершила предложение позитивно, модель генерирует такой текст:
The food is awful, but there is also the music, the story and the magic! The «Avenged Sevenfold» is a masterfully performed rock musical that will have a strong presence all over the world.
(Еда ужасна, но еще здесь есть музыка, сюжет, магическая атмосфера. «Avenged Sevenfold» — мастерски исполненный рок-мюзикл, который получит признание по всему миру.)
Задаем тему
В качестве дополнительной модели исследователи использовали мешок слов (Bag of words, BoW) для различных тем, где вероятность темы определяется суммой вероятностей каждого слова в мешке.
Какое бы начало мы ни задали, нейросеть выдаст связный текст по заданной теме.
Задаем тональность
Здесь в качестве дополнительной модели исследователи используют дискриминатор PPLM-Discrim, обученный на наборе данных, размеченном по тональности.
При генерации использовали дискриминатор с 5000 параметрами (1025 параметров на класс (- -, -, 0, +, + +)), обученный на наборе данных SST-5. 5000 параметров — это ничтожно мало по сравнению с количеством параметров в основной модели (LM), и обучать такую модель гораздо легче и быстрее.
Проводим детоксикацию текста
Модели, обученные на большом количестве текстов в Интернете, могут отражать предвзятость и токсичность, присутствующие в исходных данных. Чтобы этого не допустить, при использовании PPLM нужно также подключить классификатор токсичности в качестве модели атрибута и обновить латентность с отрицательным градиентом.
Исследователи из Uber AI провели тест, в котором добровольные оценщики отметили токсичность пятисот образцов текста, сгенерированных PPLM с детоксикацией, и сравнили их с базовой моделью GPT-2. В среднем доля токсичной речи снизилась с 63,6% до 4,6%.
Принцип работы PPLM
Представлен на прикрепленной схеме. Алгоритм PPLM производит прямой и обратный обход нейронной сети, состоящей из двух подсетей — базовой предобученной языковой модели (LM) и модели классификатора по заданному пользователем атрибуту (attribute model).
Код моделей можно посмотреть здесь и здесь. Также доступна интерактивная демонстрация работы моделей.
Полный текст с примерами работы генераторов:
https://sysblok.ru/linguistics/kak-upravljat-mamontom-generiruem-nuzhnye-teksty-s-pomoshhju-modelej-plug-and-play/
{kind=link}
Как устроен шрифт Брайля и зачем его распознавать
Рассказывает Ася Ройтберг, инициатор разработки алгоритма распознавания Брайля
#nlp #society
Больше всего распознавание Брайля и его автоматический перевод нужны людям, которые много взаимодействуют с незрячими — обычно это родственники и учителя, — а в некоторых случаях это нужно и самим незрячим людям.
Учителя в школах для слабовидящих обычно читают Брайль глазами, поэтому проверять тетради диктантов из белых точек на белом фоне очень тяжело. Родители часто не могут помочь своему незрячему ребенку с уроками или почитать вместе одну книгу. Также, только в некоторых регионах у незрячих детей есть возможность участвовать в школьных олимпиадах.
Еще одна проблема — оцифровка и переиздание брайлевских книг, изданных в доцифровую эпоху.
Но главная цель — помочь незрячим людям расширить круг общения. Если убрать «языковой барьер», преподавать незрячим людям смогут люди, не умеющие бегло читать на Брайле.
Как устроен шрифт Брайля
Шрифт Брайля изначально придумали для армии. Предполагалось, что с помощью него солдаты смогут бесшумно общаться в полной темноте. В армии язык не пошел: зрячим людям оказалось не под силу читать пальцами рельефные точки. Но не пропадать же изобретению — рельефному шрифту решили научить слепых детей.
Один из этих детей — Луи Брайль — доработал систему, и в итоге получился рельефно-точечный шрифт. Он состоит из выпуклых точек и промежутков, причем точки четко организованы.
Один символ шрифта Брайля — решетка 3×2, в каждой из шести ячеек которой может быть (или не быть) рельефная точка. Получается всего 64 комбинации точек и пустот, поэтому для передачи кириллицы, латиницы, других видов письменности и даже музыкальных нот используют одни и те же символы.
Как и в других письменностях, Брайль бывает печатным и «рукописным». На вид символы не отличаются — отличается способ письма. Печатный вариант — это пластиковые округлые выпуклые точки, наверняка вы видели такие в лифтах или в подписях в музеях. Здесь можно конвертировать в Брайль русский текст, а здесь — текст на латинице.
В школах для слабовидящих детей учат писать «рукописным» Брайлем. Технически это протыкание дырочек специальным шилом (или просто ручкой) в листе бумаги, вставленном в специальный трафарет. На трафарете пишут зеркально: точки продавливают шилом с обратной стороны листа справа-налево. В этом видео подробно показывается, как пишут Брайлем.
Также есть брайлевские печатные машинки. Здесь можно посмотреть, какие они бывают. У них 6 больших кнопок — по кнопке на каждую из шести точек в брайлевской букве, и седьмая клавиша — пробел.
Брайлевские тексты иногда печатают с двух сторон, тогда на странице присутствуют одновременно и выпуклые точки текста, и впадины на местах точек текста с другой стороны листа. Такие тексты очень плохо распознаются с помощью компьютерного зрения и оптического распознавания символов.
Что сделано и не сделано в сфере распознавания Брайля
Распознать Брайль значит взять фотографию или скан текста на Брайле и превратить в машиночитаемые брайлевские символы (а дальше можно сразу конвертировать его в обычный текст на кириллице, латинице и т. д.).
Распознавание Брайля — проект без коммерческого потенциала. Для многих задач эта технология уже не актуальна: есть технические средства, помогающие незрячим при чтение и письме. С ними люди отлично могут набирать текст на компьютере и пользоваться любыми мессенджерами, а рукописный Брайль остается только на этапе начального обучения письму.
К сожалению, все эти технические средства довольно дорогие. В России брайлевская строка и брайлевский дисплей доступны совсем немногим.
Электронные помощники также не решают проблему оцифровки старых книг на Брайле. Но для этого есть аппаратно-программный комплекс — большая и дорогая железная машина с 3D сканером внутри, которая может распознавать только печатный Брайль.
https://sysblok.ru/nlp/kak-ustroen-shrift-brajlja-i-zachem-ego-raspoznavat/
Рассказывает Ася Ройтберг, инициатор разработки алгоритма распознавания Брайля
#nlp #society
Больше всего распознавание Брайля и его автоматический перевод нужны людям, которые много взаимодействуют с незрячими — обычно это родственники и учителя, — а в некоторых случаях это нужно и самим незрячим людям.
Учителя в школах для слабовидящих обычно читают Брайль глазами, поэтому проверять тетради диктантов из белых точек на белом фоне очень тяжело. Родители часто не могут помочь своему незрячему ребенку с уроками или почитать вместе одну книгу. Также, только в некоторых регионах у незрячих детей есть возможность участвовать в школьных олимпиадах.
Еще одна проблема — оцифровка и переиздание брайлевских книг, изданных в доцифровую эпоху.
Но главная цель — помочь незрячим людям расширить круг общения. Если убрать «языковой барьер», преподавать незрячим людям смогут люди, не умеющие бегло читать на Брайле.
Как устроен шрифт Брайля
Шрифт Брайля изначально придумали для армии. Предполагалось, что с помощью него солдаты смогут бесшумно общаться в полной темноте. В армии язык не пошел: зрячим людям оказалось не под силу читать пальцами рельефные точки. Но не пропадать же изобретению — рельефному шрифту решили научить слепых детей.
Один из этих детей — Луи Брайль — доработал систему, и в итоге получился рельефно-точечный шрифт. Он состоит из выпуклых точек и промежутков, причем точки четко организованы.
Один символ шрифта Брайля — решетка 3×2, в каждой из шести ячеек которой может быть (или не быть) рельефная точка. Получается всего 64 комбинации точек и пустот, поэтому для передачи кириллицы, латиницы, других видов письменности и даже музыкальных нот используют одни и те же символы.
Как и в других письменностях, Брайль бывает печатным и «рукописным». На вид символы не отличаются — отличается способ письма. Печатный вариант — это пластиковые округлые выпуклые точки, наверняка вы видели такие в лифтах или в подписях в музеях. Здесь можно конвертировать в Брайль русский текст, а здесь — текст на латинице.
В школах для слабовидящих детей учат писать «рукописным» Брайлем. Технически это протыкание дырочек специальным шилом (или просто ручкой) в листе бумаги, вставленном в специальный трафарет. На трафарете пишут зеркально: точки продавливают шилом с обратной стороны листа справа-налево. В этом видео подробно показывается, как пишут Брайлем.
Также есть брайлевские печатные машинки. Здесь можно посмотреть, какие они бывают. У них 6 больших кнопок — по кнопке на каждую из шести точек в брайлевской букве, и седьмая клавиша — пробел.
Брайлевские тексты иногда печатают с двух сторон, тогда на странице присутствуют одновременно и выпуклые точки текста, и впадины на местах точек текста с другой стороны листа. Такие тексты очень плохо распознаются с помощью компьютерного зрения и оптического распознавания символов.
Что сделано и не сделано в сфере распознавания Брайля
Распознать Брайль значит взять фотографию или скан текста на Брайле и превратить в машиночитаемые брайлевские символы (а дальше можно сразу конвертировать его в обычный текст на кириллице, латинице и т. д.).
Распознавание Брайля — проект без коммерческого потенциала. Для многих задач эта технология уже не актуальна: есть технические средства, помогающие незрячим при чтение и письме. С ними люди отлично могут набирать текст на компьютере и пользоваться любыми мессенджерами, а рукописный Брайль остается только на этапе начального обучения письму.
К сожалению, все эти технические средства довольно дорогие. В России брайлевская строка и брайлевский дисплей доступны совсем немногим.
Электронные помощники также не решают проблему оцифровки старых книг на Брайле. Но для этого есть аппаратно-программный комплекс — большая и дорогая железная машина с 3D сканером внутри, которая может распознавать только печатный Брайль.
https://sysblok.ru/nlp/kak-ustroen-shrift-brajlja-i-zachem-ego-raspoznavat/
{kind=link}
Обзор сервиса Talk To Books от Google
#nlp
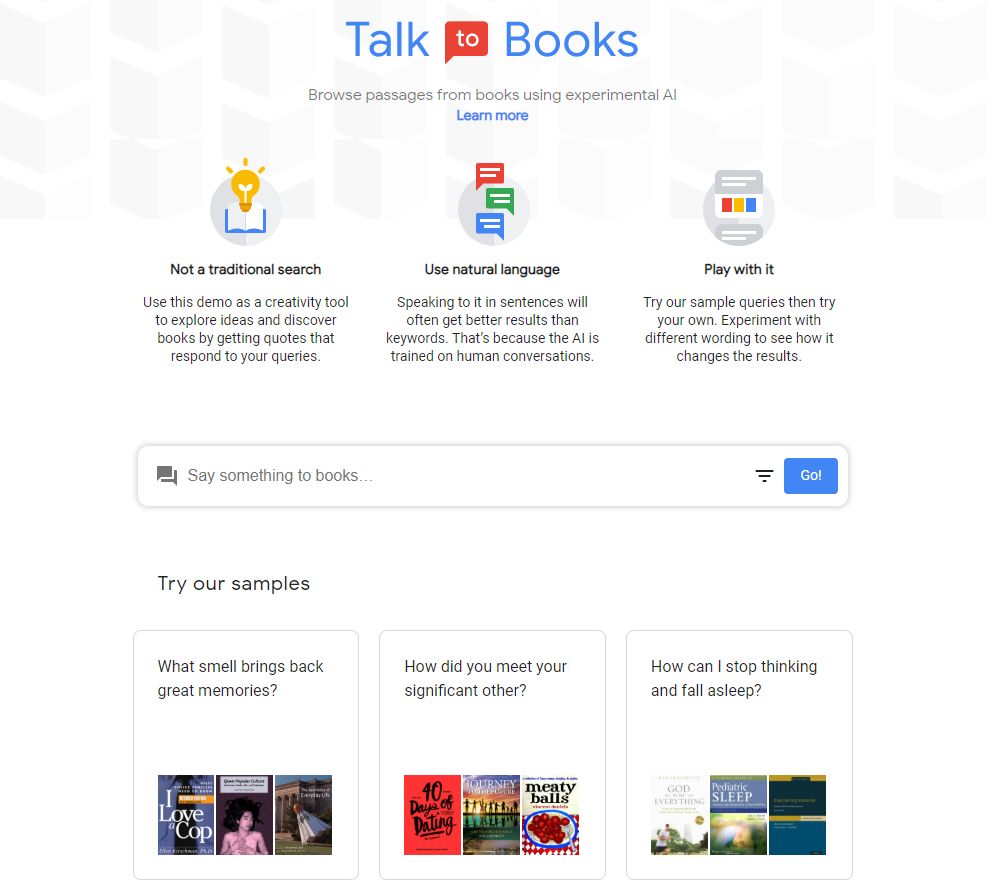
Talk To Books — поисковой сервис, который ответит на любой вопрос не набором ссылок на статьи или сайты, а цитатами из книг, которых в базе сервиса более 100 тысяч. Это экспериментальный сервис от Google из серии Semantic Experiences. В этой серии Google разрабатывает инструменты, которые учат искусственный интеллект понимать естественный язык не по ключевым словам, а используя семантику.
Talk to Books ищет ответы, основываясь на семантике предложений. Нейронную сеть сервиса обучали на реальных диалогах между людьми. В качестве входных данных взяли миллиард пар высказываний по схеме вопрос — ответ или высказывание — реакция на него. Затем в систему загрузили тексты книг, и искусственный интеллект стал искать в них строчки, которые вероятнее всего могли бы стать ответом на запрос.
Ответ на запрос — это не просто вырванная цитата из книги. Пользователь видит целый абзац, в котором предполагаемый ответ выделен жирным шрифтом. После цитаты дана ссылка на конкретную страницу книги и на саму книгу. Книги также разделены на категории, по которым можно настроить фильтр для поиска ответов.
Talk to Books доступен только на английском языке и пока что работает не идеально, однако ему уже можно найти практическое применение. Например, его можно использовать для поиска книг для чтения. Также, преподаватели английского предлагают ученикам тренироваться в нем составлять вопросительные предложения.
Полный обзор сервиса со скриншотами по ссылке: https://sysblok.ru/nlp/kak-pogovorit-so-100-000-knig-talk-to-books/
#nlp
Talk To Books — поисковой сервис, который ответит на любой вопрос не набором ссылок на статьи или сайты, а цитатами из книг, которых в базе сервиса более 100 тысяч. Это экспериментальный сервис от Google из серии Semantic Experiences. В этой серии Google разрабатывает инструменты, которые учат искусственный интеллект понимать естественный язык не по ключевым словам, а используя семантику.
Talk to Books ищет ответы, основываясь на семантике предложений. Нейронную сеть сервиса обучали на реальных диалогах между людьми. В качестве входных данных взяли миллиард пар высказываний по схеме вопрос — ответ или высказывание — реакция на него. Затем в систему загрузили тексты книг, и искусственный интеллект стал искать в них строчки, которые вероятнее всего могли бы стать ответом на запрос.
Ответ на запрос — это не просто вырванная цитата из книги. Пользователь видит целый абзац, в котором предполагаемый ответ выделен жирным шрифтом. После цитаты дана ссылка на конкретную страницу книги и на саму книгу. Книги также разделены на категории, по которым можно настроить фильтр для поиска ответов.
Talk to Books доступен только на английском языке и пока что работает не идеально, однако ему уже можно найти практическое применение. Например, его можно использовать для поиска книг для чтения. Также, преподаватели английского предлагают ученикам тренироваться в нем составлять вопросительные предложения.
Полный обзор сервиса со скриншотами по ссылке: https://sysblok.ru/nlp/kak-pogovorit-so-100-000-knig-talk-to-books/
{kind=link}
Как сделать чат-бота с помощью DeepPavlov
#nlp
Сегодня уже мало кому нужно объяснять, что такое чат-боты. Мы неизбежно сталкиваемся с ними, когда хотим открыть вклад в банке, уточнить тариф у мобильного оператора или просто заказать пиццу.
Чат-боты вызывают интерес у бизнеса, ищущего способы сократить расходы на колл-центры и улучшить взаимодействие с клиентами. Кто-то идет дальше — и создает Алису, способную болтать на разные темы, развлекая вас, когда вам скучно, а значит, повышая вашу лояльность.
Наряду с разработкой таких ботов-гигантов, как Алекса, Сири и Алиса, за которыми стоят крупнейшие IT-корпорации, появляются и доступные инструменты для создания своих небольших, но полноценных целеориентированных чат-ботов. Отличным примером этого служат инструменты из библиотеки DeepPavlov от группы разработчиков на базе МФТИ.
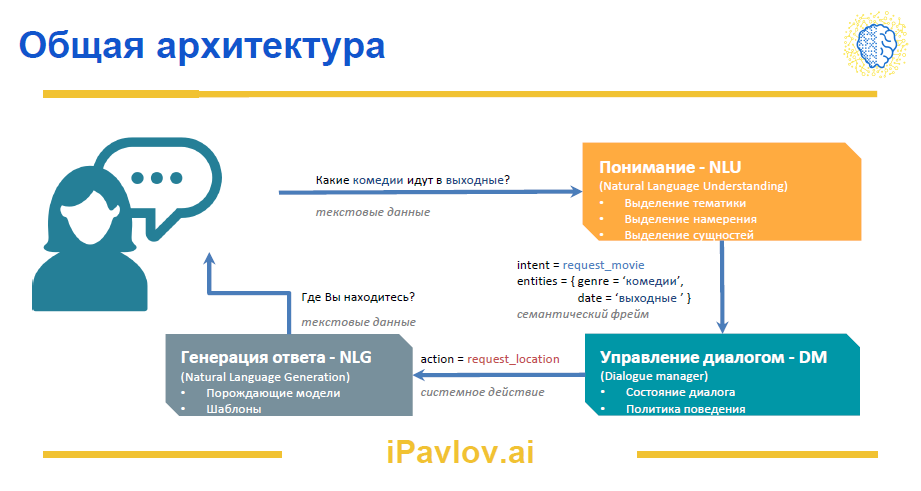
Как устроены чат-боты
На прикрепленной схеме — общая архитектура диалоговой системы чат-бота. В статье рассказываем обо всех ее компонентах и отвечаем на вопросы:
- как научить бота понимать пользователя?
- как управлять диалогом?
- как генерировать сообщения?
-как инструменты DeepPavlov могут упростить создание бота?
Полезные инструменты DeepPavlov
- предобученные модели нейронных сетей на основе BERT для классификации входящего сообщения, то есть определения домена — предметной области — разговора и интента — намерения — пользователя.
- модели для решения задачи NER — распознавания именованных сущностей, — стабильно показывающие высокое качество для русского языка (F1 score до 98.1).
- специальный компонент slotfiller в пайплайне распознавания именованных сущностей — для вставки распознанных сущностей в слоты.
- удобный спеллчекинг, помогающий справляться с опечатками в сообщениях пользователей и не плодить лишних сущностей — все вариации написания в рамках определенного порога приводятся к одному слову.
- несколько доступных конфигураций для целеориентированных ботов — для решения задач управления диалогом.
Подробный рассказ по ссылке: https://sysblok.ru/nlp/trudno-byt-botom-kak-sdelat-chatbota-s-pomoshhju-deeppavlov/
#nlp
Сегодня уже мало кому нужно объяснять, что такое чат-боты. Мы неизбежно сталкиваемся с ними, когда хотим открыть вклад в банке, уточнить тариф у мобильного оператора или просто заказать пиццу.
Чат-боты вызывают интерес у бизнеса, ищущего способы сократить расходы на колл-центры и улучшить взаимодействие с клиентами. Кто-то идет дальше — и создает Алису, способную болтать на разные темы, развлекая вас, когда вам скучно, а значит, повышая вашу лояльность.
Наряду с разработкой таких ботов-гигантов, как Алекса, Сири и Алиса, за которыми стоят крупнейшие IT-корпорации, появляются и доступные инструменты для создания своих небольших, но полноценных целеориентированных чат-ботов. Отличным примером этого служат инструменты из библиотеки DeepPavlov от группы разработчиков на базе МФТИ.
Как устроены чат-боты
На прикрепленной схеме — общая архитектура диалоговой системы чат-бота. В статье рассказываем обо всех ее компонентах и отвечаем на вопросы:
- как научить бота понимать пользователя?
- как управлять диалогом?
- как генерировать сообщения?
-как инструменты DeepPavlov могут упростить создание бота?
Полезные инструменты DeepPavlov
- предобученные модели нейронных сетей на основе BERT для классификации входящего сообщения, то есть определения домена — предметной области — разговора и интента — намерения — пользователя.
- модели для решения задачи NER — распознавания именованных сущностей, — стабильно показывающие высокое качество для русского языка (F1 score до 98.1).
- специальный компонент slotfiller в пайплайне распознавания именованных сущностей — для вставки распознанных сущностей в слоты.
- удобный спеллчекинг, помогающий справляться с опечатками в сообщениях пользователей и не плодить лишних сущностей — все вариации написания в рамках определенного порога приводятся к одному слову.
- несколько доступных конфигураций для целеориентированных ботов — для решения задач управления диалогом.
Подробный рассказ по ссылке: https://sysblok.ru/nlp/trudno-byt-botom-kak-sdelat-chatbota-s-pomoshhju-deeppavlov/
{kind=link}
Как работают семантические поисковые системы
На примере поисковика по стихам А. С. Пушкина
#nlp
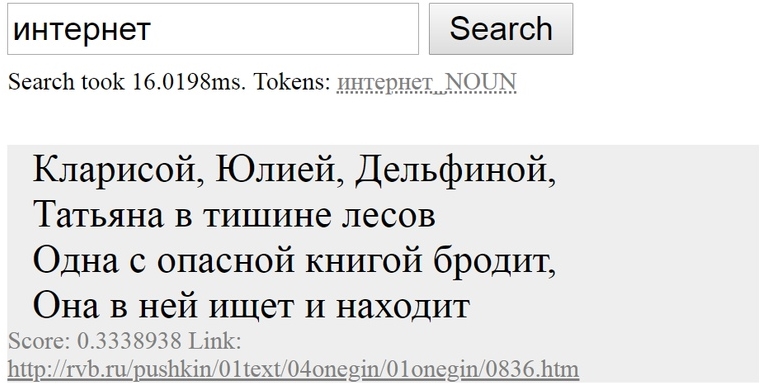
Как найти «то, не знаю что», а если точнее — совершить нечеткий поиск? Вот бы можно было найти в интернете «похожую мысль», «что-нибудь по теме» или «такое же по смыслу». Жаль, что напрямую со смыслом слов Гугл пока что работать не умеет… Зато нечто похожее умеет маленький поисковик по стихам Пушкина.
Посмотрите на скрине ниже, что нашел этот поисковик по запросу «интернет». Как так получилось, что, хотя Пушкин не писал про интернет, поисковик нашел в его стихах строчки про книгу, в которой можно «искать и найти»? Ответ: благодаря семантическим векторам.
Семантический вектор слова
Лингвист Джон Руперт Фёрс однажды сказал: «Слово узнаешь по его окружению». Грубо говоря, на этой гипотезе строится основа дистрибутивной семантики — направления лингвистики, которое вычисляет, насколько близки два слова по смыслу, исходя из частоты их совместной встречаемости в текстовых корпусах.
Так можно найти синонимы и антонимы к слову или классифицировать его в тематический «отдел»; автоматически определить тематику документа, не давая прочесть его человеку; постараться смоделировать перифразы или выяснить правила сочетаемости слов.
Для таких операций каждому новому слову нужно присвоить набор чисел, характеризующий его смысл. Этот набор называется семантическим вектором слова. Его вычисляют на больших корпусах текстов.
В 2013 году Томаш Миколов разработал систему Word2vec, которая строит для слов векторы заданной размерности. Метод Миколова состоит в применении двух нейронных моделей: continuous bag-of-words (CBOW) и skip-gram. Первый предсказывает слово на основе данного контекста, а второй — наоборот, старается угадать контекст данного слова. В результате слова, встречающиеся в тексте в одинаковом окружении (а следовательно, имеющие схожий смысл), в векторном представлении будут иметь близкие координаты.
Семантический поисковик по стихам А. С. Пушкина
На сайте RusVectores выложены готовые наборы семантических векторов для огромного числа слов, полученные после обработки различных корпусов текстов алгоритмами word2vec с разными параметрами. Эти «векторные модели» можно скачать и использовать как готовую базу данных семантических векторов. Пользуясь этой возможностью, пользователь GitLab opennota написал семантический поисковик по стихам А. С. Пушкина.
Интерфейс программы — поле запроса, где пользователь может ввести слово или группу слов. Введенный запрос сохраняется в буфер обмена, где морфологический анализатор pymorphy2 распознает формы и леммы слов.
Для каждого слова запроса из предварительно рассчитанной модели word2vec извлекается семантический вектор. В случае, если поисковой запрос содержал несколько слов, их векторы суммируются и нормализуются.
Извлечение векторов отдельных слов, их суммирование и нормализация происходит также для каждого четверостишия из используемой базы данных: эта процедура реализуется при запуске программы. В результате для каждого четверостишия составляется единый семантический вектор.
После получения нормализованного вектора поискового запроса рассчитываются показатели косинусной близости вектора запроса и каждого из векторов четверостиший. Показатели сравниваются и программа выдает строфы, чей семантический вектор ближе всего к вектору слов из поискового запроса.
Поиск дает результаты и тогда, когда очевидно, что слова из поискового запроса не могут встречаться в произведениях Пушкина.
Данный пример демонстрирует, что при помощи инструментов word2vec и проекта RusVectores можно проводить семантический анализ и категоризацию текстов, выполняя поиск по нечетким критериям. Исследователь, работающий с подобной системой, сможет отыскать нестандартные контексты и значения лексических единиц на большом объеме данных.
Владимир Селеверстов
Больше подробностей в статье: https://sysblok.ru/philology/pushkin-terminator-i-zvezdolet/
На примере поисковика по стихам А. С. Пушкина
#nlp
Как найти «то, не знаю что», а если точнее — совершить нечеткий поиск? Вот бы можно было найти в интернете «похожую мысль», «что-нибудь по теме» или «такое же по смыслу». Жаль, что напрямую со смыслом слов Гугл пока что работать не умеет… Зато нечто похожее умеет маленький поисковик по стихам Пушкина.
Посмотрите на скрине ниже, что нашел этот поисковик по запросу «интернет». Как так получилось, что, хотя Пушкин не писал про интернет, поисковик нашел в его стихах строчки про книгу, в которой можно «искать и найти»? Ответ: благодаря семантическим векторам.
Семантический вектор слова
Лингвист Джон Руперт Фёрс однажды сказал: «Слово узнаешь по его окружению». Грубо говоря, на этой гипотезе строится основа дистрибутивной семантики — направления лингвистики, которое вычисляет, насколько близки два слова по смыслу, исходя из частоты их совместной встречаемости в текстовых корпусах.
Так можно найти синонимы и антонимы к слову или классифицировать его в тематический «отдел»; автоматически определить тематику документа, не давая прочесть его человеку; постараться смоделировать перифразы или выяснить правила сочетаемости слов.
Для таких операций каждому новому слову нужно присвоить набор чисел, характеризующий его смысл. Этот набор называется семантическим вектором слова. Его вычисляют на больших корпусах текстов.
В 2013 году Томаш Миколов разработал систему Word2vec, которая строит для слов векторы заданной размерности. Метод Миколова состоит в применении двух нейронных моделей: continuous bag-of-words (CBOW) и skip-gram. Первый предсказывает слово на основе данного контекста, а второй — наоборот, старается угадать контекст данного слова. В результате слова, встречающиеся в тексте в одинаковом окружении (а следовательно, имеющие схожий смысл), в векторном представлении будут иметь близкие координаты.
Семантический поисковик по стихам А. С. Пушкина
На сайте RusVectores выложены готовые наборы семантических векторов для огромного числа слов, полученные после обработки различных корпусов текстов алгоритмами word2vec с разными параметрами. Эти «векторные модели» можно скачать и использовать как готовую базу данных семантических векторов. Пользуясь этой возможностью, пользователь GitLab opennota написал семантический поисковик по стихам А. С. Пушкина.
Интерфейс программы — поле запроса, где пользователь может ввести слово или группу слов. Введенный запрос сохраняется в буфер обмена, где морфологический анализатор pymorphy2 распознает формы и леммы слов.
Для каждого слова запроса из предварительно рассчитанной модели word2vec извлекается семантический вектор. В случае, если поисковой запрос содержал несколько слов, их векторы суммируются и нормализуются.
Извлечение векторов отдельных слов, их суммирование и нормализация происходит также для каждого четверостишия из используемой базы данных: эта процедура реализуется при запуске программы. В результате для каждого четверостишия составляется единый семантический вектор.
После получения нормализованного вектора поискового запроса рассчитываются показатели косинусной близости вектора запроса и каждого из векторов четверостиший. Показатели сравниваются и программа выдает строфы, чей семантический вектор ближе всего к вектору слов из поискового запроса.
Поиск дает результаты и тогда, когда очевидно, что слова из поискового запроса не могут встречаться в произведениях Пушкина.
Данный пример демонстрирует, что при помощи инструментов word2vec и проекта RusVectores можно проводить семантический анализ и категоризацию текстов, выполняя поиск по нечетким критериям. Исследователь, работающий с подобной системой, сможет отыскать нестандартные контексты и значения лексических единиц на большом объеме данных.
Владимир Селеверстов
Больше подробностей в статье: https://sysblok.ru/philology/pushkin-terminator-i-zvezdolet/
{kind=link}
Памяти А. А. Зализняка
#nlp #linguistics
Андрей Анатольевич Зализняк (1935–2017) был выдающимся советским и российским лингвистом и академиком РАН. Он занимался широким кругом проблем, начиная от словоизменения в русском языке и заканчивая древненовгородским диалектом.
И хотя А. А. Зализняк никогда не был и не считался «компьютерным лингвистом», его работы по русскому словоизменению легли в основу всех морфологических анализаторов для русского языка. А от морфологического анализа зависит работа поисковиков, машинных переводчиков и даже чатботов вроде «Алисы».
«Системный Блокъ» создал цикл из четырех статей, посвященных трудам и открытиям А. А. Зализняка.
Берестяные грамоты от раскопа до компьютера
А. А. Зализняк нашел существенное отличие северо-западных говоров от остальных, что привело к пересмотру уже сложившейся схемы диалектов Древней Руси. Источником сведений об этих говорах стали берестяные грамоты, первую из которых нашли в 1951 г.
Оказалось, что в X—XI вв. на территории восточного славянства членение было не таким, как можно представить на основании сегодняшнего разделения языков (великорусский, украинский, белорусский), а иным: северо-запад отличался от всех остальных говоров. Иными словами, существовала группа древненовгородских и древнепсковских диалектов и классическая форма древнерусского языка, объединявшая Киев, Суздаль, Ростов, будущую Москву и территорию Белоруссии. Это и были две главные составные части будущего русского языка.
https://sysblok.ru/nlp/berestjanye-gramoty-ot-raskopa-do-kompjutera-pamjati-a-a-zaliznjaka-chast-i/
«Слово о полку Игореве» как улика
Существует мнение, что «Слово о полку Игореве» написано не в XII веке, а несколькими веками позднее, то есть является стилизацией под древность, а не истинным памятником древнерусской словесности. А. А. Зализняк рассматривает проблему подлинности «Слова» с лингвистической точки зрения и последовательно доказывает невозможность никакой другой датировки, кроме XII века.
https://sysblok.ru/nlp/slovo-o-polku-igoreve-kak-ulika-pamjati-a-a-zaliznjaka-chast-ii/
Акцентуаторы
Русское ударение свободно и подвижно. А. А. Зализняк мечтал о программе, которая сможет расставлять ударения в тексте автоматически.
Магистры из НИУ ВШЭ воплотили его идею в жизнь и создали акцентуатор для русского языка sStress. Это автоматическая система, принимающая на вход текст на русском языке и расставляющая в нем ударения. В основе этого акцентуатора лежит рекуррентная нейронная сеть LSTM, обученная на акцентологическом подкорпусе Национального корпуса русского языка.
В качестве базы данных молодые ученые используют «Грамматический словарь русского языка» (1985) А. А. Зализняка, который насчитывает более 100 000 слов с указанным ударением (и ударной парадигмой). Второй источник — Транскрипции Русского национального корпуса (РНЦ) (Гришина, 2003). Разговорный корпус был собран из записей речи люди и стенограмм русских фильмов с расставленными ударениями.
https://sysblok.ru/nlp/akcentuatory-pamjati-a-a-zaliznjaka-chast-iii/
Морфология
Поисковики, умеющие обрабатывать русскоязычные запросы, а также навигаторы, голосовые команды и онлайн-переводчики, работающие с русским языком, появились бы на несколько лет позже, если бы не «Грамматический словарь русского языка» А. А. Зализняка — первое полное описание грамматических форм русского языка, по которому для каждого слова можно построить все его словоформы.
Словарь Зализняка лег в основу автоматического порождения всех словоизменительных форм в русском интернете. Его концепция используется для описания большинства русских слов в Викисловаре. Яндекс может не только корректно склонять и спрягать русские слова, но и строить гипотезы о том, как будет изменяться любое незнакомое системе слово.
https://sysblok.ru/nlp/morfologija-pamjati-a-a-zaliznjaka-chast-iv/
#nlp #linguistics
Андрей Анатольевич Зализняк (1935–2017) был выдающимся советским и российским лингвистом и академиком РАН. Он занимался широким кругом проблем, начиная от словоизменения в русском языке и заканчивая древненовгородским диалектом.
И хотя А. А. Зализняк никогда не был и не считался «компьютерным лингвистом», его работы по русскому словоизменению легли в основу всех морфологических анализаторов для русского языка. А от морфологического анализа зависит работа поисковиков, машинных переводчиков и даже чатботов вроде «Алисы».
«Системный Блокъ» создал цикл из четырех статей, посвященных трудам и открытиям А. А. Зализняка.
Берестяные грамоты от раскопа до компьютера
А. А. Зализняк нашел существенное отличие северо-западных говоров от остальных, что привело к пересмотру уже сложившейся схемы диалектов Древней Руси. Источником сведений об этих говорах стали берестяные грамоты, первую из которых нашли в 1951 г.
Оказалось, что в X—XI вв. на территории восточного славянства членение было не таким, как можно представить на основании сегодняшнего разделения языков (великорусский, украинский, белорусский), а иным: северо-запад отличался от всех остальных говоров. Иными словами, существовала группа древненовгородских и древнепсковских диалектов и классическая форма древнерусского языка, объединявшая Киев, Суздаль, Ростов, будущую Москву и территорию Белоруссии. Это и были две главные составные части будущего русского языка.
https://sysblok.ru/nlp/berestjanye-gramoty-ot-raskopa-do-kompjutera-pamjati-a-a-zaliznjaka-chast-i/
«Слово о полку Игореве» как улика
Существует мнение, что «Слово о полку Игореве» написано не в XII веке, а несколькими веками позднее, то есть является стилизацией под древность, а не истинным памятником древнерусской словесности. А. А. Зализняк рассматривает проблему подлинности «Слова» с лингвистической точки зрения и последовательно доказывает невозможность никакой другой датировки, кроме XII века.
https://sysblok.ru/nlp/slovo-o-polku-igoreve-kak-ulika-pamjati-a-a-zaliznjaka-chast-ii/
Акцентуаторы
Русское ударение свободно и подвижно. А. А. Зализняк мечтал о программе, которая сможет расставлять ударения в тексте автоматически.
Магистры из НИУ ВШЭ воплотили его идею в жизнь и создали акцентуатор для русского языка sStress. Это автоматическая система, принимающая на вход текст на русском языке и расставляющая в нем ударения. В основе этого акцентуатора лежит рекуррентная нейронная сеть LSTM, обученная на акцентологическом подкорпусе Национального корпуса русского языка.
В качестве базы данных молодые ученые используют «Грамматический словарь русского языка» (1985) А. А. Зализняка, который насчитывает более 100 000 слов с указанным ударением (и ударной парадигмой). Второй источник — Транскрипции Русского национального корпуса (РНЦ) (Гришина, 2003). Разговорный корпус был собран из записей речи люди и стенограмм русских фильмов с расставленными ударениями.
https://sysblok.ru/nlp/akcentuatory-pamjati-a-a-zaliznjaka-chast-iii/
Морфология
Поисковики, умеющие обрабатывать русскоязычные запросы, а также навигаторы, голосовые команды и онлайн-переводчики, работающие с русским языком, появились бы на несколько лет позже, если бы не «Грамматический словарь русского языка» А. А. Зализняка — первое полное описание грамматических форм русского языка, по которому для каждого слова можно построить все его словоформы.
Словарь Зализняка лег в основу автоматического порождения всех словоизменительных форм в русском интернете. Его концепция используется для описания большинства русских слов в Викисловаре. Яндекс может не только корректно склонять и спрягать русские слова, но и строить гипотезы о том, как будет изменяться любое незнакомое системе слово.
https://sysblok.ru/nlp/morfologija-pamjati-a-a-zaliznjaka-chast-iv/
{kind=link}
Как выделяют и классифицируют сущности в художественных текстах
#nlp #philology
Человек схватывает новую информацию на лету: из контекста, из интонации, из невербального общения. А как помочь компьютеру понять, что Гарри — волшебник, Гендальф — майар, а Джон Сноу — одновременно Старк и Таргариен?
В NLP эти задачи называются Named-entity recognition (NER), то есть выделение сущностей, и Entity Typing (ET) — классификация сущностей. С помощью NER и ET филологи подсчитывают, сколько раз появляется персонаж в тексте, строят сеть связей между героями книг и собирают все прозвища героя, а историки работают с оцифрованными текстами древних рукописей.
Какие корпуса используют для классифицируют сущности
Обычно для выделения особенностей сущности и их классификации используются тексты Википедии. Этот метод работает, если нужно разобрать текст о реальном мире. Но если мы скормим программе текст «Властелина Колец», она выдаст неполный результат, т. к. в Википедии не хватает информации о вымышленных вселенных.
Эту проблему решили исследователи из Института Макса Планка. Они создали систему ENTIFY (ENtity TYping on FIctional texts), которая может работать с художественными текстами, в том числе и фэнтези и science-fiction вселенными.
В основе ENTYFI лежит тот же принцип, что и в базовых инструментах NLP — поиск и классификация сущностей, но к корпусу текстов из Википедии добавляются размеченные тексты с платформы fandom.com (ранее Wikia). Это платформа, которая позволяет создавать отдельные тематические википедии о вселенных из книг, кино, игр и т. д. Поэтому ENTYFI смогла определить, что «Фродо Бэггинс» — «хоббит» из племени «мохноног» (harfoot).
Как работает ENTYFI
Сначала статьи Wikia объединяются в группы, в которых все статьи описывают одну и ту же вселенную — Властелин колец, Гарри Поттер, Марвел и др. Затем программа ранжирует массив «каноничных вселенных» по количеству совпадений в статьях Wikia об одной вселенной и анализируемом тексте и с помощью нейросети LSTM выделяются сущности. Дальше программа ищет найденные в тексте сущности в корпусах Wikia и Википедии.
Одновременно с этими процессами проходят еще два: авторы ENTYFI называют их Unsupervised typing и KB lookup. Unsupervised typing — это поиск класса сущности внутри того предложения, в котором сущность найдена. ET при нахождении сущности подразделяет ее на токены (слова в ней), находит их класс (метку) и добавляет к ним префиксы — элементы разметки текста.
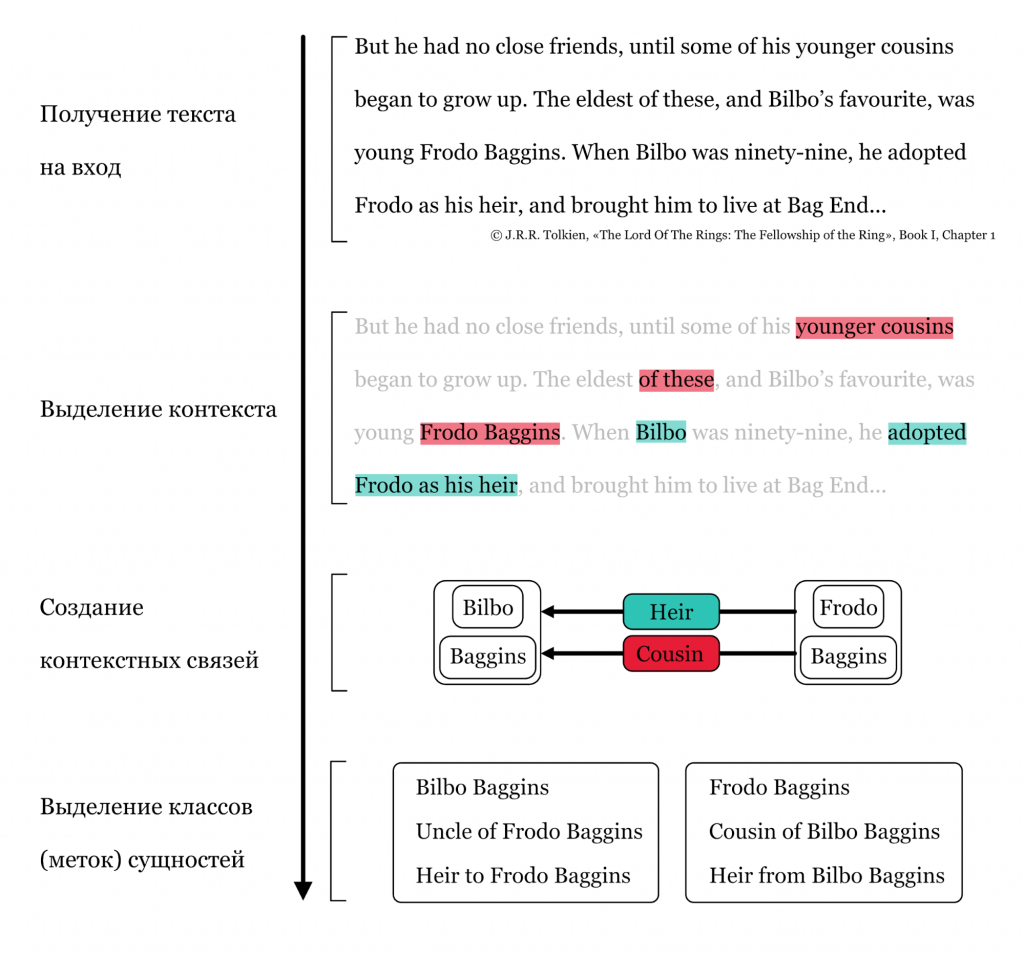
KB lookup — метод, позволяющий вычислить класс (метку) сущности через контекст, который есть в анализируемом тексте. Сначала программа анализирует то, что вокруг сущности (не обязательно близко по тексту), выделяет контекст, формирует связи и из этих связей выделяет классы (метки) сущности. На прикрепленной схеме показано, как программа понимает, что Фродо — «cousin» Бильбо и его наследник.
Информация консолидируется методами Inductive logic programming — Индуктивного логического программирования. Система перепроверяет метки (классы), которые она присвоила персонажам.
Сопоставляя факты, ENTYFI узнает, что Дрого Бэггинс, отец Фродо Бэггинса, ещё и троюродный брат Бильбо Бэггинса по мужской линии; а Примула Брендибак, мать Фродо Бэггинса — двоюродная сестра Бильбо Бэггинса по женской линии. Следовательно, Фродо Бэггинс — дважды племянник Бильбо Бэггинса: двоюродный по матери и троюродный по отцу. Поэтому в «борьбе» меток cousin и nephew победит последняя — потому что Фродо действительно племянник, а не кузен Бильбо.
Авторы ENTYFI выложили исходный код программы на Github.
Также есть демонстратор возможностей библиотеки SpaCy для Python.
https://sysblok.ru/philology/bjegginsy-kolca-i-saurony-kak-nauchit-kompjuter-ponimat-kto-est-kto/
Артур Хисматулин
#nlp #philology
Человек схватывает новую информацию на лету: из контекста, из интонации, из невербального общения. А как помочь компьютеру понять, что Гарри — волшебник, Гендальф — майар, а Джон Сноу — одновременно Старк и Таргариен?
В NLP эти задачи называются Named-entity recognition (NER), то есть выделение сущностей, и Entity Typing (ET) — классификация сущностей. С помощью NER и ET филологи подсчитывают, сколько раз появляется персонаж в тексте, строят сеть связей между героями книг и собирают все прозвища героя, а историки работают с оцифрованными текстами древних рукописей.
Какие корпуса используют для классифицируют сущности
Обычно для выделения особенностей сущности и их классификации используются тексты Википедии. Этот метод работает, если нужно разобрать текст о реальном мире. Но если мы скормим программе текст «Властелина Колец», она выдаст неполный результат, т. к. в Википедии не хватает информации о вымышленных вселенных.
Эту проблему решили исследователи из Института Макса Планка. Они создали систему ENTIFY (ENtity TYping on FIctional texts), которая может работать с художественными текстами, в том числе и фэнтези и science-fiction вселенными.
В основе ENTYFI лежит тот же принцип, что и в базовых инструментах NLP — поиск и классификация сущностей, но к корпусу текстов из Википедии добавляются размеченные тексты с платформы fandom.com (ранее Wikia). Это платформа, которая позволяет создавать отдельные тематические википедии о вселенных из книг, кино, игр и т. д. Поэтому ENTYFI смогла определить, что «Фродо Бэггинс» — «хоббит» из племени «мохноног» (harfoot).
Как работает ENTYFI
Сначала статьи Wikia объединяются в группы, в которых все статьи описывают одну и ту же вселенную — Властелин колец, Гарри Поттер, Марвел и др. Затем программа ранжирует массив «каноничных вселенных» по количеству совпадений в статьях Wikia об одной вселенной и анализируемом тексте и с помощью нейросети LSTM выделяются сущности. Дальше программа ищет найденные в тексте сущности в корпусах Wikia и Википедии.
Одновременно с этими процессами проходят еще два: авторы ENTYFI называют их Unsupervised typing и KB lookup. Unsupervised typing — это поиск класса сущности внутри того предложения, в котором сущность найдена. ET при нахождении сущности подразделяет ее на токены (слова в ней), находит их класс (метку) и добавляет к ним префиксы — элементы разметки текста.
KB lookup — метод, позволяющий вычислить класс (метку) сущности через контекст, который есть в анализируемом тексте. Сначала программа анализирует то, что вокруг сущности (не обязательно близко по тексту), выделяет контекст, формирует связи и из этих связей выделяет классы (метки) сущности. На прикрепленной схеме показано, как программа понимает, что Фродо — «cousin» Бильбо и его наследник.
Информация консолидируется методами Inductive logic programming — Индуктивного логического программирования. Система перепроверяет метки (классы), которые она присвоила персонажам.
Сопоставляя факты, ENTYFI узнает, что Дрого Бэггинс, отец Фродо Бэггинса, ещё и троюродный брат Бильбо Бэггинса по мужской линии; а Примула Брендибак, мать Фродо Бэггинса — двоюродная сестра Бильбо Бэггинса по женской линии. Следовательно, Фродо Бэггинс — дважды племянник Бильбо Бэггинса: двоюродный по матери и троюродный по отцу. Поэтому в «борьбе» меток cousin и nephew победит последняя — потому что Фродо действительно племянник, а не кузен Бильбо.
Авторы ENTYFI выложили исходный код программы на Github.
Также есть демонстратор возможностей библиотеки SpaCy для Python.
https://sysblok.ru/philology/bjegginsy-kolca-i-saurony-kak-nauchit-kompjuter-ponimat-kto-est-kto/
Артур Хисматулин
{kind=link}
Как нейросети генерируют ложные варианты для тестов
#nlp
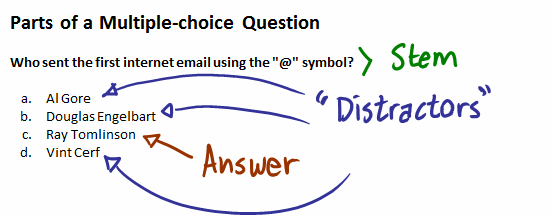
Составлять тесты сложно: кроме правильного ответа надо придумать и неправильные. Причем придумать их с умом: чтобы варианты не были слишком очевидно неверными — но и не оказались бы при этом подходящей альтернативой верному варианту.
В англоязычной литературе для неправильных вариантов ответа в тестах существует специальное название — дистракторы (distractors, букв. «отвлекатели»). Подбор хороших дистракторов при разработке тестов очень важен. Сейчас ученые пробуют автоматически генерировать дистракторы с помощью нейросетей.
Если у нас есть хорошие примеры дистракторов, сделанных людьми, мы можем включить их в обучающую выборку и решать задачу обучения нейросети с учителем (supervised learning). А если таких примеров нет, мы будем обучать нейросеть без учителя (unsupervised learning).
Когда и как применяют обучение с учителем
Задача порождения дистракторов сводится к подбору списка слов-кандидатов и обучению ранжированию. Вопросы нужного формата обычно собираются из оцифрованных копий учебников или интернет-ресурсов.
Алгоритм должен присваивать наиболее высокие ранги словам или предложениям, которые являются дистракторами для данного вопроса, то есть помечены как дистракторы в тестовой выборке.
Получив на вход текст вопроса и текст «кандидата в дистракторы», классификатор должен «решить», насколько хорошо данный ответ может сойти за правильный в контексте данного вопроса, выдав определенную вероятность в виде числа. Подтверждением успешного обучения является получение настоящими дистракторами большего, чем у остальных кандидатов, рейтинга.
Когда применяют обучение без учителя
Когда готовый пул вопросов нужного формата отсутствует, применяют unsupervised-подход. Такая ситуация возникает, когда сами вопросы генерируются из определенного корпуса текстов. В таком случае к ним нет готового обучающего набора отвлекающих неправильных ответов.
Пример такого варианта — gap-filling questions. Это вопросы, которые получаются, если заменить какое-либо слова или словосочетание в корпусном предложении на пропуск. Задача проходящего тест — догадаться, какая единица должна быть на месте пропуска.
Как проводят обучение без учителя (на примере корпуса ошибок REALEC)
Для языкового тестирования gap-filling questions можно получить, используя специальный корпус ошибок. Так называют корпуса, которые содержат тексты, написанные не-носителями определенного языка. Эти тексты содержат области, размеченные как ошибки, а также их исправления.
Корпус ошибок REALEC содержит тексты на английском языке, написанные русскоязычными студентами в качестве письменных заданий-эссе. В системе LangExBank каждый тестовый вопрос — предложение корпуса REALEC, в котором область ошибки заменена на пропуск. Таким образом, правильный ответ и один неправильный ответ в исходных данных уже есть — это исправление и оригинальная область ошибки. Задача — получить ещё 2–3 неправильных варианта.
В LangExBank реализована генерация дистракторов из вопросов, полученных на основе лексических ошибок и ошибок на употребление предлогов. Для подбора дистракторов используется классификатор в виде рекуррентной нейронной сети. Нейросеть должна заполнить пропуск, но в обучение модели внесена принципиальная поправка: если модель предсказывала правильный вариант (т. е. слово-исправление), штраф для неё увеличивался в 2 раза.
Так как в датасете изначально не содержатся дистракторы, качество сгенерированных вариантов можно проверить только вручную. Результаты пока далеки от совершенства, поэтому платформа поддерживает редактирование полученных из корпуса тестов.
Устройство нейросети и примеры ее работы — в нашей статье: https://sysblok.ru/linguistics/zaputat-nelzja-ugadat-kak-nejroseti-generirujut-lozhnye-primanki-dlja-testov/
Никита Логин
#nlp
Составлять тесты сложно: кроме правильного ответа надо придумать и неправильные. Причем придумать их с умом: чтобы варианты не были слишком очевидно неверными — но и не оказались бы при этом подходящей альтернативой верному варианту.
В англоязычной литературе для неправильных вариантов ответа в тестах существует специальное название — дистракторы (distractors, букв. «отвлекатели»). Подбор хороших дистракторов при разработке тестов очень важен. Сейчас ученые пробуют автоматически генерировать дистракторы с помощью нейросетей.
Если у нас есть хорошие примеры дистракторов, сделанных людьми, мы можем включить их в обучающую выборку и решать задачу обучения нейросети с учителем (supervised learning). А если таких примеров нет, мы будем обучать нейросеть без учителя (unsupervised learning).
Когда и как применяют обучение с учителем
Задача порождения дистракторов сводится к подбору списка слов-кандидатов и обучению ранжированию. Вопросы нужного формата обычно собираются из оцифрованных копий учебников или интернет-ресурсов.
Алгоритм должен присваивать наиболее высокие ранги словам или предложениям, которые являются дистракторами для данного вопроса, то есть помечены как дистракторы в тестовой выборке.
Получив на вход текст вопроса и текст «кандидата в дистракторы», классификатор должен «решить», насколько хорошо данный ответ может сойти за правильный в контексте данного вопроса, выдав определенную вероятность в виде числа. Подтверждением успешного обучения является получение настоящими дистракторами большего, чем у остальных кандидатов, рейтинга.
Когда применяют обучение без учителя
Когда готовый пул вопросов нужного формата отсутствует, применяют unsupervised-подход. Такая ситуация возникает, когда сами вопросы генерируются из определенного корпуса текстов. В таком случае к ним нет готового обучающего набора отвлекающих неправильных ответов.
Пример такого варианта — gap-filling questions. Это вопросы, которые получаются, если заменить какое-либо слова или словосочетание в корпусном предложении на пропуск. Задача проходящего тест — догадаться, какая единица должна быть на месте пропуска.
Как проводят обучение без учителя (на примере корпуса ошибок REALEC)
Для языкового тестирования gap-filling questions можно получить, используя специальный корпус ошибок. Так называют корпуса, которые содержат тексты, написанные не-носителями определенного языка. Эти тексты содержат области, размеченные как ошибки, а также их исправления.
Корпус ошибок REALEC содержит тексты на английском языке, написанные русскоязычными студентами в качестве письменных заданий-эссе. В системе LangExBank каждый тестовый вопрос — предложение корпуса REALEC, в котором область ошибки заменена на пропуск. Таким образом, правильный ответ и один неправильный ответ в исходных данных уже есть — это исправление и оригинальная область ошибки. Задача — получить ещё 2–3 неправильных варианта.
В LangExBank реализована генерация дистракторов из вопросов, полученных на основе лексических ошибок и ошибок на употребление предлогов. Для подбора дистракторов используется классификатор в виде рекуррентной нейронной сети. Нейросеть должна заполнить пропуск, но в обучение модели внесена принципиальная поправка: если модель предсказывала правильный вариант (т. е. слово-исправление), штраф для неё увеличивался в 2 раза.
Так как в датасете изначально не содержатся дистракторы, качество сгенерированных вариантов можно проверить только вручную. Результаты пока далеки от совершенства, поэтому платформа поддерживает редактирование полученных из корпуса тестов.
Устройство нейросети и примеры ее работы — в нашей статье: https://sysblok.ru/linguistics/zaputat-nelzja-ugadat-kak-nejroseti-generirujut-lozhnye-primanki-dlja-testov/
Никита Логин
{kind=link}