
Когда появилась машинная поэзия и в чем особенности стихов, созданных именно нейросетями? Чем такая поэзия отличается от авторской? Представляет ли она какую-нибудь ценность для литературоведения? И так ли легко определить, что написано человеком, а что — алгоритмом?
Ответы на эти и другие вопросы в нашем сегодняшнем лонгриде о нейросетевой поэзии и смерти автора.
#knowhow #neuropoetry #sysblok
https://telegra.ph/Nejroseti-i-smert-avtora-11-14
Ответы на эти и другие вопросы в нашем сегодняшнем лонгриде о нейросетевой поэзии и смерти автора.
#knowhow #neuropoetry #sysblok
https://telegra.ph/Nejroseti-i-smert-avtora-11-14
Telegraph
Нейросети и смерть автора
Если заходит разговор о нейросетевой генерации стихов, эрудированные люди сразу вспоминают множественные прецеденты машинной поэзии из прошлого. Все думают, что компьютер сочинял стихи уже тысячу лет (ну ладно, не тысячу, но такие опыты и правда ставились…
Предиктивный ввод текста на клавиатуре мобильного телефона известен нам по крайней мере с 70-х годов. Наверное, большинство из нас знакомы с Т9 , «Text on 9 keys» — алгоритмом, который позволял ускорить набор текста на кнопочных телефонах.
Сегодня мы рассказываем о том, как работает Т9 и его преемник iTap, подсказывающий слова на современных мобильных устройствах с полноценной qwerty-клавиатурой.
#knowhow #nlp #sysblok
https://telegra.ph/Zemlya-emu-puhovik-Kak-rabotaet-T9-11-22
Сегодня мы рассказываем о том, как работает Т9 и его преемник iTap, подсказывающий слова на современных мобильных устройствах с полноценной qwerty-клавиатурой.
#knowhow #nlp #sysblok
https://telegra.ph/Zemlya-emu-puhovik-Kak-rabotaet-T9-11-22
Telegraph
Земля ему пуховик. Как работает Т9?
Т9 Технологии интеллектуального (предиктивного) ввода текста стали развиваться задолго до первых мобильных устройств. В 50-е годы XX века человек по имени Чжан Цзицзинь создал систему ассоциативных кластеров текста, чтобы облегчить себе работу. Он был наборщиком…
https://telegra.ph/CHto-takoe-geodannye-chast-I-12-12
Новогодние праздники — отличная возможность уделить немного времени самообразованию. В нашей рубрике #knowhow уже вышли статьи о мультинарративе, нейросетевой поэзии, технологиях предиктивного ввода и биологических основах искусственных нейросетей, а сегодня мы обратимся к совершенно новой теме — геоданным.
Итак, наш картограф Нелли Бурцева буквально на пальцах объясняет, что такое геоинформационные системы (ГИС) и как формально представить данные о расположении объектов в пространстве.
Новогодние праздники — отличная возможность уделить немного времени самообразованию. В нашей рубрике #knowhow уже вышли статьи о мультинарративе, нейросетевой поэзии, технологиях предиктивного ввода и биологических основах искусственных нейросетей, а сегодня мы обратимся к совершенно новой теме — геоданным.
Итак, наш картограф Нелли Бурцева буквально на пальцах объясняет, что такое геоинформационные системы (ГИС) и как формально представить данные о расположении объектов в пространстве.
Telegraph
Что такое геоданные (часть I)
Все в мире каким-то образом расположено в пространстве. Например, стул. Рядом с вами наверняка есть стул. Стул стоит на полу в метре от вас. Одновременно он стоит в трех метрах вот от той стены или, например, в углу. Еще он стоит на, предположим, седьмом…
Сегодня мы возвращаемся к рубрике #knowhow и продолжаем наш разговор о геоданных. В новой серии — геоиды, эллипсоиды и различные системы координат.
https://telegra.ph/CHto-takoe-geodannye-chast-II-12-23
https://telegra.ph/CHto-takoe-geodannye-chast-II-12-23
{kind=link}
В заключительной части нашего мини-курса о пространственных данных — различные проекции географических карт и «проблема апельсина».
#knowhow #sysblok
https://telegra.ph/CHto-takoe-geodannye-chast-III-01-01
#knowhow #sysblok
https://telegra.ph/CHto-takoe-geodannye-chast-III-01-01
Telegraph
Что такое геоданные (часть III)
В предыдущей части мы вкратце разобрались, как можно добиться приличной точности при определении географических координат на Земле, то есть на объемной фигуре. И это замечательно — пока мы остаемся в трехмерном пространстве. Но технологии пока не позволяют…
Пожалуй, слово «нейросеть» сейчас знает каждый — настолько повсеместно они используются и настолько много о них говорят. Всем хочется найти понятное объяснение того, как работают нейросети, но в интернете обычно рассказывают либо слишком сложные вещи, либо очевидные.
Мы попытались доступно изложить базовые идеи, стоящие за созданием нейронных сетей. Статья не претендует на полноту и абсолютную научную точность. Зато мы постарались быть понятными.
#knowhow #sysblok
https://telegra.ph/Kak-rabotaet-nejroset-12-12
Мы попытались доступно изложить базовые идеи, стоящие за созданием нейронных сетей. Статья не претендует на полноту и абсолютную научную точность. Зато мы постарались быть понятными.
#knowhow #sysblok
https://telegra.ph/Kak-rabotaet-nejroset-12-12
Telegraph
Как работает нейросеть
Нейросети сегодня используют везде. Они помогают «умной» видеокамере распознать лицо, банкомату — цифры на чеке, а гугл-переводчику — найти на картинке слово и верно перевести его. Всем хочется найти понятное объяснение того, как работают нейросети, но в…
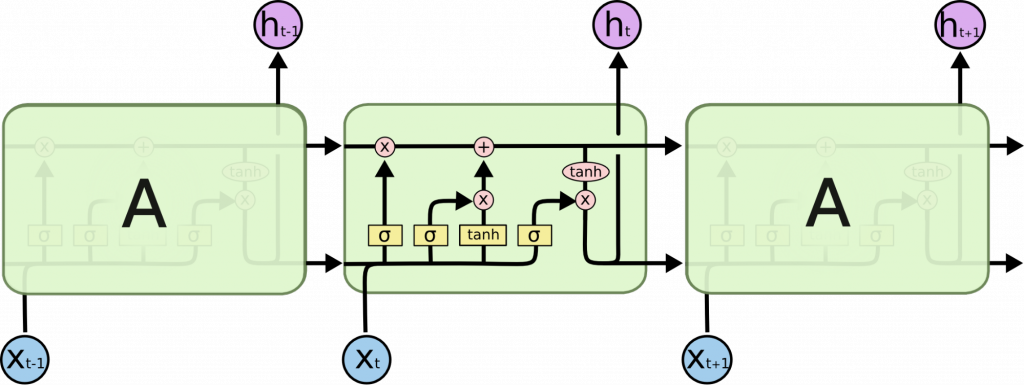
Мама мыла LSTM: как устроены рекуррентные нейросети с долгой краткосрочной памятью
#knowhow
Системный Блокъ подготовил крафтовый техно-лонгрид, в котором разбирается по винтикам одна из самых ходовых технологий в современной компьютерной лингвистике — рекуррентные нейросети с архитектурой LSTM.
Именно на LSTM-сетях впервые взлетел качественный нейросетевой машинный перевод. Несмотря на бум нейросетей-трансформеров, о которых мы расскажем в наших следующих техно-лонгридах, рекуррентные LSTM-сети остаются одним из популярнейших рабочих инструментов в задачах машинной обработки естественного языка.
Зачем обрабатывать текст на компьютере
Было бы круто научить компьютер генерировать связный текст, выделять логические конструкции, потом делать с ними что-нибудь интересное, как умеет человек. Может получиться чат-бот, поисковая машина, «умная» клавиатура на телефоне, онлайн-переводчик, генератор пересказов.
Эти задачи решает обработка естественного языка. С ней есть сложности: в языке бывают омонимы, бывают многозначные слова. А что делать, если «Трофей не поместился в чемодан, потому что он был слишком большим»? Как тут программе сориентироваться, к чему относится слово «он»?
К счастью, речь людей статистически предсказуема. Есть популярные цепочки слов, которые повторяют почти все. Велика вероятность после слов «чайник уже» найти слово «вскипел». И напротив, есть последовательности, которые никогда не услышишь в речи. Например, «чайник уже… обиделся».
О чем рассказываем в статье:
— Как использовать неслучайность речи
— Как работает языковая модель на цепях Маркова без нейросетей
— Что такое рекуррентность
— Как RNN сохраняет свое состояние и передает его дальше
— Почему неэффективно передавать контекст со слоя на слой
— Что происходит внутри одного слоя нейронов
— Как работает LSTM — Long Short Term Memory
— Как реализуется забывание контекста в LSTM
— Как реализуется запоминание контекста в LSTM
— Как реализуется запись новых значений в контекст
— Как получается предсказание LSTM
Обо всем этом — в нашей статье: https://sysblok.ru/knowhow/mama-myla-lstm-kak-ustroeny-rekurrentnye-nejroseti-s-dolgoj-kratkosrochnoj-pamjatju/
#knowhow
Системный Блокъ подготовил крафтовый техно-лонгрид, в котором разбирается по винтикам одна из самых ходовых технологий в современной компьютерной лингвистике — рекуррентные нейросети с архитектурой LSTM.
Именно на LSTM-сетях впервые взлетел качественный нейросетевой машинный перевод. Несмотря на бум нейросетей-трансформеров, о которых мы расскажем в наших следующих техно-лонгридах, рекуррентные LSTM-сети остаются одним из популярнейших рабочих инструментов в задачах машинной обработки естественного языка.
Зачем обрабатывать текст на компьютере
Было бы круто научить компьютер генерировать связный текст, выделять логические конструкции, потом делать с ними что-нибудь интересное, как умеет человек. Может получиться чат-бот, поисковая машина, «умная» клавиатура на телефоне, онлайн-переводчик, генератор пересказов.
Эти задачи решает обработка естественного языка. С ней есть сложности: в языке бывают омонимы, бывают многозначные слова. А что делать, если «Трофей не поместился в чемодан, потому что он был слишком большим»? Как тут программе сориентироваться, к чему относится слово «он»?
К счастью, речь людей статистически предсказуема. Есть популярные цепочки слов, которые повторяют почти все. Велика вероятность после слов «чайник уже» найти слово «вскипел». И напротив, есть последовательности, которые никогда не услышишь в речи. Например, «чайник уже… обиделся».
О чем рассказываем в статье:
— Как использовать неслучайность речи
— Как работает языковая модель на цепях Маркова без нейросетей
— Что такое рекуррентность
— Как RNN сохраняет свое состояние и передает его дальше
— Почему неэффективно передавать контекст со слоя на слой
— Что происходит внутри одного слоя нейронов
— Как работает LSTM — Long Short Term Memory
— Как реализуется забывание контекста в LSTM
— Как реализуется запоминание контекста в LSTM
— Как реализуется запись новых значений в контекст
— Как получается предсказание LSTM
Обо всем этом — в нашей статье: https://sysblok.ru/knowhow/mama-myla-lstm-kak-ustroeny-rekurrentnye-nejroseti-s-dolgoj-kratkosrochnoj-pamjatju/
{kind=link}
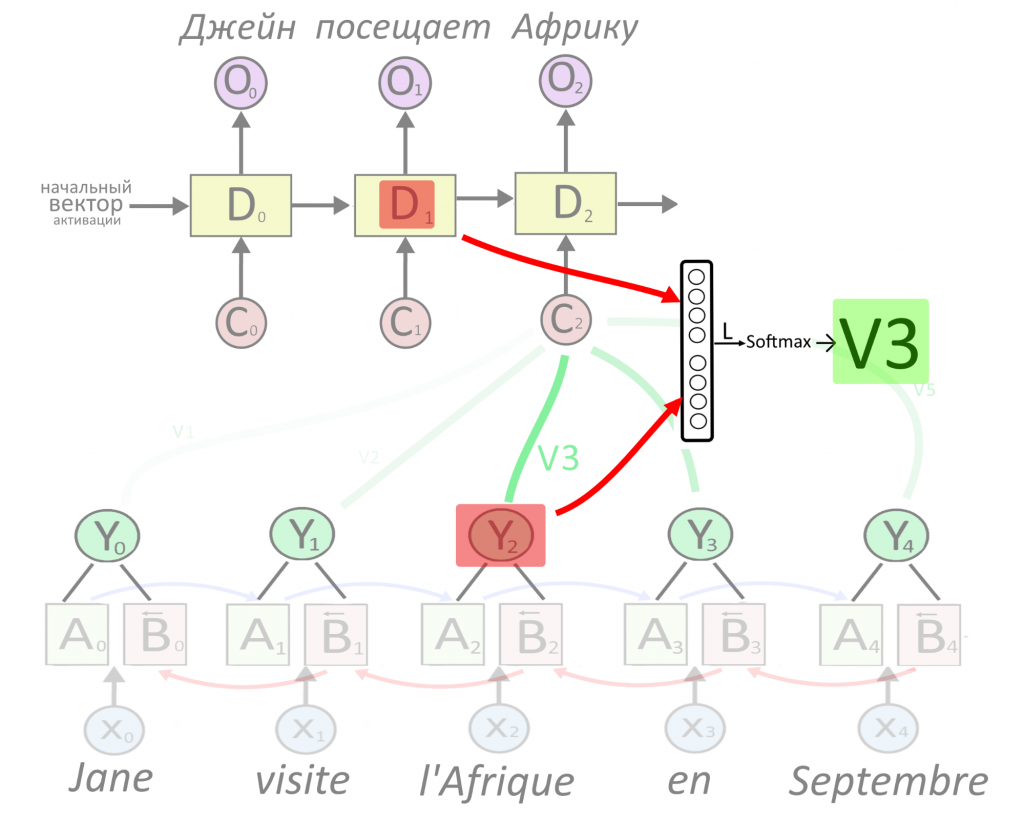
Внимание — все, что вам нужно: как работает attention в нейросетях
#knowhow
Мы продолжаем серию постов об устройстве нейронных сетей. В прошлом материале «Системный Блокъ» рассказывал о том, зачем нужны рекуррентные нейросети (RNN), что такое рекуррентность и как добавить нейросети долгосрочной памяти.
Сегодня рассказываем о механизме внимания, на котором работают в 2020 году все действительно крутые нейросети. Почему внимание стало killer-фичей диплернинга, что под капотом у attention mechanism, как нейросеть понимает, какие признаки текста или картинки важнее других.
У применения RNN в области обработки и понимания естественного языка есть три основные проблемы:
1. RNN работает медленно и недостаточно эффективно;
2. RNN учитывает только прошлый контекст, а не все предложение;
3. в RNN контекст со временем размывается.
Чтобы решить вторую проблему, используют двунаправленную RNN. Она обрабатывает предложение один раз слева направо, другой раз — справа налево, и только потом начинает предсказывать.
А механизм внимания решает третью проблему. Его цель — заставить нейросеть сильнее сосредоточиться на важном слове в дальнем конце предложения. Контекст — это сумма векторов всех слов в предложении. «Подсветить» важное слово в контексте — значит умножить его вектор на большое число («вес внимания»). Чтобы понять, какое слово сейчас важно, потребуется еще одна нейросеть (внутри нейросети).
О чем рассказываем в статье:
— Какие бывают типы рекуррентных архитектур
— Чем хороша архитектура «энкодер — декодер» для машинного перевода
— Как работает двунаправленная RNN
— В чем заключается идея механизма внимания
— Как сделан механизм внимания в энкодере
— Как сделан механизм внимания в декодере
— Как получить вес внимания и понять, что на самом деле важно «запомнить»
— Как работает функция активации Softmax
https://sysblok.ru/knowhow/vnimanie-vse-chto-vam-nuzhno-kak-rabotaet-attention-v-nejrosetjah/
#knowhow
Мы продолжаем серию постов об устройстве нейронных сетей. В прошлом материале «Системный Блокъ» рассказывал о том, зачем нужны рекуррентные нейросети (RNN), что такое рекуррентность и как добавить нейросети долгосрочной памяти.
Сегодня рассказываем о механизме внимания, на котором работают в 2020 году все действительно крутые нейросети. Почему внимание стало killer-фичей диплернинга, что под капотом у attention mechanism, как нейросеть понимает, какие признаки текста или картинки важнее других.
У применения RNN в области обработки и понимания естественного языка есть три основные проблемы:
1. RNN работает медленно и недостаточно эффективно;
2. RNN учитывает только прошлый контекст, а не все предложение;
3. в RNN контекст со временем размывается.
Чтобы решить вторую проблему, используют двунаправленную RNN. Она обрабатывает предложение один раз слева направо, другой раз — справа налево, и только потом начинает предсказывать.
А механизм внимания решает третью проблему. Его цель — заставить нейросеть сильнее сосредоточиться на важном слове в дальнем конце предложения. Контекст — это сумма векторов всех слов в предложении. «Подсветить» важное слово в контексте — значит умножить его вектор на большое число («вес внимания»). Чтобы понять, какое слово сейчас важно, потребуется еще одна нейросеть (внутри нейросети).
О чем рассказываем в статье:
— Какие бывают типы рекуррентных архитектур
— Чем хороша архитектура «энкодер — декодер» для машинного перевода
— Как работает двунаправленная RNN
— В чем заключается идея механизма внимания
— Как сделан механизм внимания в энкодере
— Как сделан механизм внимания в декодере
— Как получить вес внимания и понять, что на самом деле важно «запомнить»
— Как работает функция активации Softmax
https://sysblok.ru/knowhow/vnimanie-vse-chto-vam-nuzhno-kak-rabotaet-attention-v-nejrosetjah/
{kind=link}
Поделись наушником своим: как устроены рекомендации Spotify
#musicology #knowhow
Стриминг имеет две принципиально важные черты потребления: массовизация легальной покупки музыки и культура рекомендации. Нельзя сказать, что рекомендации — это идея исключительно стримингового сервиса Spotify. До этого идею рекомендации развивали и другие компании — Spotify просто удачно скомпилировала известные инструменты в систему и постоянно ее улучшает.
Рекомендательные инструменты Spotify
1. Пользователь «оценивает» пользователя
Первый метод по созданию рекомендаций — коллаборативная фильтрация (Collaborative Filtering). Про этот инструмент мы подробно рассказывали в другой нашей статье. Впервые его внедрили на Last.fm, а популяризировал Netflix. У этого американского сервиса видеостриминга метод строится на основе оценок, которые зрители ставят сериалам, фильмам и шоу.
У Spotify оценок нет — поэтому там рекомендации работают на основе косвенного фидбека — можно сказать, что пользователи оставляют оценки в виде метаданных: количество прослушиваний, лайк или пропуск трека (до тридцатой секунды), посещение страницы артиста, прослушивание альбома с песней и т. д.
На основе анализа метаданных высчитывается оценка, которая вкладывается в отдельную ячейку матрицы: по горизонтали — оценки одного из 286 миллионов пользователей (по данным на июль 2020 года), по вертикали — оценки одного трека (более 50 миллионов по заявлениям компании). Получается, что Spotify хранит 14,3 квадриллиона оценок!
Затем система высчитывает векторы пользователя и векторы отдельных треков. Чем ближе вектор трека к вектору пользователя, тем больше вероятность, что этот трек ему порекомендуют.
2. Нейросеть оценивает музыку
Второй метод аналитики — анализ самой музыки. Нейросеть оценивает энергичность треков, присутствие вокала, темп, тональность и так далее. Это позволяет создавать кластеры, которые примеряются на пользователя в комплексе.
Такой анализ важен при рассмотрении треков, которые невозможно оценить другими методами. Например, так анализируют треки начинающих исполнителей, которые слушают крайне мало людей, и еще меньше людей о них пишут.
В данном случае используется сверточная нейронная сеть. Ее задача — сжать объект, не потеряв при этом отношения между его элементами. В таком случае мы можем выявить не просто отношения между отдельно взятыми элементами, но и какую-либо общую тенденцию.
3. Нейросеть оценивает текст песни
Третий метод — анализ текста медиа. На серверах собираются тексты о музыкальных композициях, которые представлены на платформе. Затем с помощью инструментов NLP нейросеть анализирует, какими словами описывают те или иные песни в медиа. Полученные данные агрегируются, после чего вырабатывается система своеобразных тегов. Это не теги/хэштеги в привычном для нас twitter-понимании — «хэштег привязан к событию» —, а скорее бирки — «тег привязан к характеристике».
Например, музыку польской группы Behemoth блоггеры и музыкальные критики никогда в жизни не назовут милой группой — скорее там будут превалировать характеристики вроде «черный», «тяжелый», «эпатажный», «сатанинский» и т. д. Поэтому поляков не порекомендуют любителям Кэти Перри.
Хоумскрин с ИИ
Домашний экран вашего Spotify — это искусственный интеллект «Bandits for Recommendations as Treatments» (BaRT). Он работает на основе полок: одна полка — одна тематика. BaRT — хороший личный ассистент в подборе музыки, если вы долго слушаете музыку на одной полке. Также оценивается и продолжительность прослушивания одного трека. Меньше тридцати секунд не считается, после тридцатой, каждая новая идет треку «в актив», композиции наподобие этой будут чаще появляться в вашем плейлисте.
Алгоритм Spotify защищен от разового прослушивания — если вы включите «Happy Birthday to You» или один раз послушали «шум дождя» перед сном — это не повлияет на ваши рекомендации.
А о системе сбора и хранения данных Spotify — читайте в нашей статье: https://sysblok.ru/musicology/podelis-naushnikom-svoim-eshhe-raz-o-tom-kak-ustroeny-rekomendacii-spotify/
Артур Хисматулин
#musicology #knowhow
Стриминг имеет две принципиально важные черты потребления: массовизация легальной покупки музыки и культура рекомендации. Нельзя сказать, что рекомендации — это идея исключительно стримингового сервиса Spotify. До этого идею рекомендации развивали и другие компании — Spotify просто удачно скомпилировала известные инструменты в систему и постоянно ее улучшает.
Рекомендательные инструменты Spotify
1. Пользователь «оценивает» пользователя
Первый метод по созданию рекомендаций — коллаборативная фильтрация (Collaborative Filtering). Про этот инструмент мы подробно рассказывали в другой нашей статье. Впервые его внедрили на Last.fm, а популяризировал Netflix. У этого американского сервиса видеостриминга метод строится на основе оценок, которые зрители ставят сериалам, фильмам и шоу.
У Spotify оценок нет — поэтому там рекомендации работают на основе косвенного фидбека — можно сказать, что пользователи оставляют оценки в виде метаданных: количество прослушиваний, лайк или пропуск трека (до тридцатой секунды), посещение страницы артиста, прослушивание альбома с песней и т. д.
На основе анализа метаданных высчитывается оценка, которая вкладывается в отдельную ячейку матрицы: по горизонтали — оценки одного из 286 миллионов пользователей (по данным на июль 2020 года), по вертикали — оценки одного трека (более 50 миллионов по заявлениям компании). Получается, что Spotify хранит 14,3 квадриллиона оценок!
Затем система высчитывает векторы пользователя и векторы отдельных треков. Чем ближе вектор трека к вектору пользователя, тем больше вероятность, что этот трек ему порекомендуют.
2. Нейросеть оценивает музыку
Второй метод аналитики — анализ самой музыки. Нейросеть оценивает энергичность треков, присутствие вокала, темп, тональность и так далее. Это позволяет создавать кластеры, которые примеряются на пользователя в комплексе.
Такой анализ важен при рассмотрении треков, которые невозможно оценить другими методами. Например, так анализируют треки начинающих исполнителей, которые слушают крайне мало людей, и еще меньше людей о них пишут.
В данном случае используется сверточная нейронная сеть. Ее задача — сжать объект, не потеряв при этом отношения между его элементами. В таком случае мы можем выявить не просто отношения между отдельно взятыми элементами, но и какую-либо общую тенденцию.
3. Нейросеть оценивает текст песни
Третий метод — анализ текста медиа. На серверах собираются тексты о музыкальных композициях, которые представлены на платформе. Затем с помощью инструментов NLP нейросеть анализирует, какими словами описывают те или иные песни в медиа. Полученные данные агрегируются, после чего вырабатывается система своеобразных тегов. Это не теги/хэштеги в привычном для нас twitter-понимании — «хэштег привязан к событию» —, а скорее бирки — «тег привязан к характеристике».
Например, музыку польской группы Behemoth блоггеры и музыкальные критики никогда в жизни не назовут милой группой — скорее там будут превалировать характеристики вроде «черный», «тяжелый», «эпатажный», «сатанинский» и т. д. Поэтому поляков не порекомендуют любителям Кэти Перри.
Хоумскрин с ИИ
Домашний экран вашего Spotify — это искусственный интеллект «Bandits for Recommendations as Treatments» (BaRT). Он работает на основе полок: одна полка — одна тематика. BaRT — хороший личный ассистент в подборе музыки, если вы долго слушаете музыку на одной полке. Также оценивается и продолжительность прослушивания одного трека. Меньше тридцати секунд не считается, после тридцатой, каждая новая идет треку «в актив», композиции наподобие этой будут чаще появляться в вашем плейлисте.
Алгоритм Spotify защищен от разового прослушивания — если вы включите «Happy Birthday to You» или один раз послушали «шум дождя» перед сном — это не повлияет на ваши рекомендации.
А о системе сбора и хранения данных Spotify — читайте в нашей статье: https://sysblok.ru/musicology/podelis-naushnikom-svoim-eshhe-raz-o-tom-kak-ustroeny-rekomendacii-spotify/
Артур Хисматулин
{kind=link}
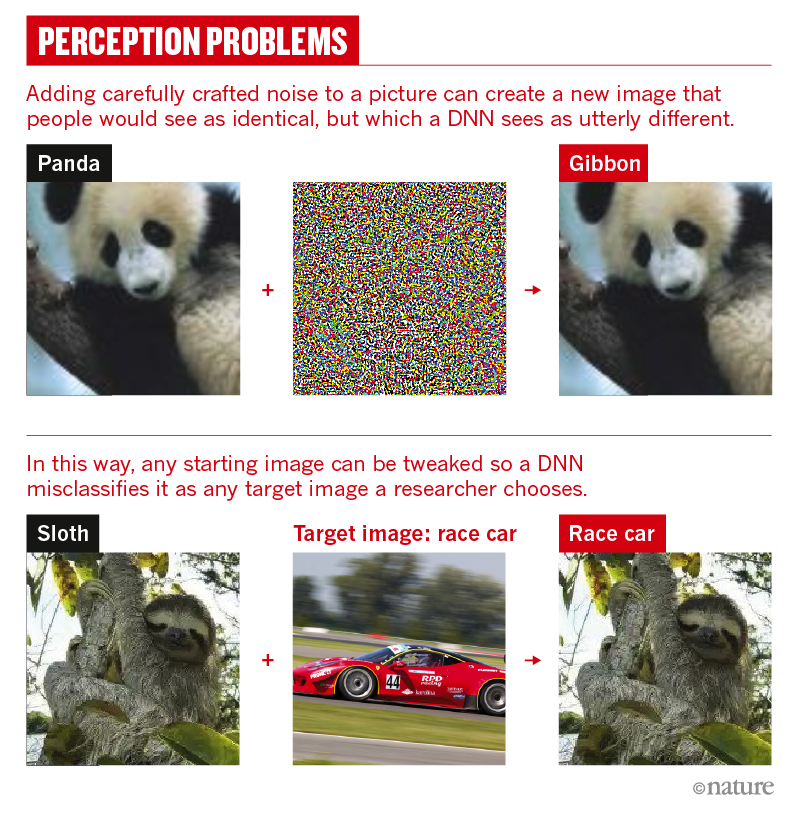
Почему нейросеть так легко обмануть
#knowhow
С каждым годом искусственный интеллект все больше входит в нашу жизнь: ему уже доверили не только мелочи вроде подбора контекстной рекламы, но и более серьезные задачи — управление беспилотными автомобилями и даже диагностику пациентов. Случаи, когда ошибка ИИ привела бы к серьезным последствиям для человека — редкость, но риск такой ошибки велик.
Исследования показали, что минимальные изменения в любых типах входных данных способны запутать ИИ. Достаточно с расчетом наклеить стикеры на дорожный знак, нанести определенный узор на шляпу или очки или добавить белый шум в аудиозапись, чтобы система распознавания совершила ошибку там, где человек без раздумий ответил бы верно.
Как учится нейронная сеть
В основе любой современной технологии, нуждающейся в распознавании образов, лежит глубокая нейронная сеть. Это искусственная сеть, состоящая из множества цифровых нейронов, упорядоченных в слои так, чтобы приблизительно повторять архитектуру человеческого мозга.
Нейросеть обучается на больших дата-сетах — например, множестве изображений котов и собак. Самостоятельно или с учителем нейросеть выявляет из картинок паттерны, которые помогают ей определить, кто на фотографии. Затем использует эти паттерны, чтобы делать прогнозы относительно новых примеров.
Как обмануть нейронную сеть
В 2013 году исследователи Google показали, что достаточно изменить в картинке всего несколько пикселей, и правильно определенное в первый раз изображение после небольшой оптимизации покажется классификатору незнакомым. Поддельные изображения назвали адверсальными примерами.
Годом позже ученые обратили внимание на то, что нейронная сеть видит предметы даже там, где их нет. Можно создать изображения, которые будут неузнаваемы для людей, но с 99,9% вероятностью знакомыми для ИИ. Например, королевский пингвин в узоре из волнистых линий.
В 2018 году стало известно, что объект достаточно повернуть, чтобы ввести в заблуждение самые сильные классификаторы изображений. Скорее всего, это происходит, потому что предметы под другим ракурсом сильно отличаются от примеров, на которых сеть обучалась.
В 2019 обнаружили, что даже неподдельные, сырые изображения могут заставить самые сильные нейронные сети делать непредсказуемые оплошности. Например, ИИ может определить гриб как крендель или стрекозу как крышку люка, потому что нейросеть фокусируется на цвете изображения, текстуре или заднем плане.
Как сделать нейросеть сильнее
Ученые предлагают дать ИИ больше информации об объекте, скармливая ему адверсальные примеры и исправляя его ошибки. Для нейросетей устраивают «адверсальные тренировки», в которых одна сеть учится определять объекты, а другая изменяет их, чтобы запутать ее. Но обучая нейросеть противостоять одному виду атак, можно ослабить ее к другим.
Поскольку большинство адверсальных атак работает, внося крошечные изменения в составные части входных данных — например, незаметно изменяя цвет пикселей в изображении до тех пор, пока это не приведет к ошибочной классификации, — исследователи также предложили включить формулу ошибки в нейросеть. Так она сможет просчитывать изменения самостоятельно и не менять свое решение.
Также есть предложение объединить глубокую нейронную сеть с символическим искусственным интеллектом, который был основным до появления машинного обучения. С помощью символического ИИ машины рассуждали, используя жестко запрограммированные представления о мире: что он состоит из дискретных объектов, которые находятся друг с другом в различных отношениях.
Но ИИ хорош ровно настолько насколько хороши примеры, на которых его обучали. Чтобы приблизить его к идеалу, нужно позволить ему учиться в более богатой среде, которую он сможет самостоятельно исследовать. Также может помочь обучение в трехмерной среде — реальной или смоделированной.
https://sysblok.ru/neuroscience/pochemu-nejroset-tak-legko-obmanut/
Алена Завьялова
#knowhow
С каждым годом искусственный интеллект все больше входит в нашу жизнь: ему уже доверили не только мелочи вроде подбора контекстной рекламы, но и более серьезные задачи — управление беспилотными автомобилями и даже диагностику пациентов. Случаи, когда ошибка ИИ привела бы к серьезным последствиям для человека — редкость, но риск такой ошибки велик.
Исследования показали, что минимальные изменения в любых типах входных данных способны запутать ИИ. Достаточно с расчетом наклеить стикеры на дорожный знак, нанести определенный узор на шляпу или очки или добавить белый шум в аудиозапись, чтобы система распознавания совершила ошибку там, где человек без раздумий ответил бы верно.
Как учится нейронная сеть
В основе любой современной технологии, нуждающейся в распознавании образов, лежит глубокая нейронная сеть. Это искусственная сеть, состоящая из множества цифровых нейронов, упорядоченных в слои так, чтобы приблизительно повторять архитектуру человеческого мозга.
Нейросеть обучается на больших дата-сетах — например, множестве изображений котов и собак. Самостоятельно или с учителем нейросеть выявляет из картинок паттерны, которые помогают ей определить, кто на фотографии. Затем использует эти паттерны, чтобы делать прогнозы относительно новых примеров.
Как обмануть нейронную сеть
В 2013 году исследователи Google показали, что достаточно изменить в картинке всего несколько пикселей, и правильно определенное в первый раз изображение после небольшой оптимизации покажется классификатору незнакомым. Поддельные изображения назвали адверсальными примерами.
Годом позже ученые обратили внимание на то, что нейронная сеть видит предметы даже там, где их нет. Можно создать изображения, которые будут неузнаваемы для людей, но с 99,9% вероятностью знакомыми для ИИ. Например, королевский пингвин в узоре из волнистых линий.
В 2018 году стало известно, что объект достаточно повернуть, чтобы ввести в заблуждение самые сильные классификаторы изображений. Скорее всего, это происходит, потому что предметы под другим ракурсом сильно отличаются от примеров, на которых сеть обучалась.
В 2019 обнаружили, что даже неподдельные, сырые изображения могут заставить самые сильные нейронные сети делать непредсказуемые оплошности. Например, ИИ может определить гриб как крендель или стрекозу как крышку люка, потому что нейросеть фокусируется на цвете изображения, текстуре или заднем плане.
Как сделать нейросеть сильнее
Ученые предлагают дать ИИ больше информации об объекте, скармливая ему адверсальные примеры и исправляя его ошибки. Для нейросетей устраивают «адверсальные тренировки», в которых одна сеть учится определять объекты, а другая изменяет их, чтобы запутать ее. Но обучая нейросеть противостоять одному виду атак, можно ослабить ее к другим.
Поскольку большинство адверсальных атак работает, внося крошечные изменения в составные части входных данных — например, незаметно изменяя цвет пикселей в изображении до тех пор, пока это не приведет к ошибочной классификации, — исследователи также предложили включить формулу ошибки в нейросеть. Так она сможет просчитывать изменения самостоятельно и не менять свое решение.
Также есть предложение объединить глубокую нейронную сеть с символическим искусственным интеллектом, который был основным до появления машинного обучения. С помощью символического ИИ машины рассуждали, используя жестко запрограммированные представления о мире: что он состоит из дискретных объектов, которые находятся друг с другом в различных отношениях.
Но ИИ хорош ровно настолько насколько хороши примеры, на которых его обучали. Чтобы приблизить его к идеалу, нужно позволить ему учиться в более богатой среде, которую он сможет самостоятельно исследовать. Также может помочь обучение в трехмерной среде — реальной или смоделированной.
https://sysblok.ru/neuroscience/pochemu-nejroset-tak-legko-obmanut/
Алена Завьялова
{kind=link}
Обучаем Word2vec: практикум по созданию векторных моделей языка
#knowhow
Как использовать в своей повседневной работе векторные семантические модели и библиотеку Word2Vec? Это несложно: понадобится немного кода на Python и готовые векторные модели — например, с сайта RusVectores.
Word2vec — библиотека для получения векторных представлений слов на основе их совместной встречаемости в текстах. Системный Блокъ уже писал ранее о том, как работают эти модели, и вы можете освежить в памяти механизмы работы Word2vec, прочитав нашу статью.
Сейчас мы займемся более практичными и приземленными вещами: научимся использовать Word2vec в своей повседневной работе. Мы будем использовать реализацию Word2vec в библиотеке Gensim для языка программирования Python.
Что мы научимся делать
• В первой части мы научимся предобрабатывать текстовые файлы и самостоятельно тренировать векторную модель на своих данных.
• Во второй части мы разберемся, как загружать уже готовые векторные модели и работать с ними. Например, мы научимся выполнять простые операции над векторами слов, такие как «найти слово с наиболее близким вектором» или «вычислить коэффициент близости между двумя векторами слов».
• Также мы рассмотрим более сложные операции над векторами, например, «найти семантические аналоги» или «найти лишний вектор в группе слов».
Для прохождения тьюториала мы рекомендуем использовать Python3. Работоспособность кода для Python2 не гарантируется. Код из этого тьюториала также доступен в формате jupyter-тетрадки.
https://sysblok.ru/knowhow/obuchaem-word2vec-praktikum-po-sozdaniju-vektornyh-modelej-jazyka/
Елизавета Кузьменко
#knowhow
Как использовать в своей повседневной работе векторные семантические модели и библиотеку Word2Vec? Это несложно: понадобится немного кода на Python и готовые векторные модели — например, с сайта RusVectores.
Word2vec — библиотека для получения векторных представлений слов на основе их совместной встречаемости в текстах. Системный Блокъ уже писал ранее о том, как работают эти модели, и вы можете освежить в памяти механизмы работы Word2vec, прочитав нашу статью.
Сейчас мы займемся более практичными и приземленными вещами: научимся использовать Word2vec в своей повседневной работе. Мы будем использовать реализацию Word2vec в библиотеке Gensim для языка программирования Python.
Что мы научимся делать
• В первой части мы научимся предобрабатывать текстовые файлы и самостоятельно тренировать векторную модель на своих данных.
• Во второй части мы разберемся, как загружать уже готовые векторные модели и работать с ними. Например, мы научимся выполнять простые операции над векторами слов, такие как «найти слово с наиболее близким вектором» или «вычислить коэффициент близости между двумя векторами слов».
• Также мы рассмотрим более сложные операции над векторами, например, «найти семантические аналоги» или «найти лишний вектор в группе слов».
Для прохождения тьюториала мы рекомендуем использовать Python3. Работоспособность кода для Python2 не гарантируется. Код из этого тьюториала также доступен в формате jupyter-тетрадки.
https://sysblok.ru/knowhow/obuchaem-word2vec-praktikum-po-sozdaniju-vektornyh-modelej-jazyka/
Елизавета Кузьменко
{kind=link}