
Как нейросети генерируют ложные варианты для тестов
#nlp
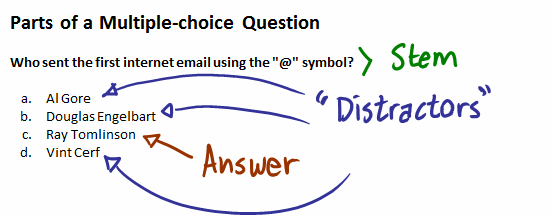
Составлять тесты сложно: кроме правильного ответа надо придумать и неправильные. Причем придумать их с умом: чтобы варианты не были слишком очевидно неверными — но и не оказались бы при этом подходящей альтернативой верному варианту.
В англоязычной литературе для неправильных вариантов ответа в тестах существует специальное название — дистракторы (distractors, букв. «отвлекатели»). Подбор хороших дистракторов при разработке тестов очень важен. Сейчас ученые пробуют автоматически генерировать дистракторы с помощью нейросетей.
Если у нас есть хорошие примеры дистракторов, сделанных людьми, мы можем включить их в обучающую выборку и решать задачу обучения нейросети с учителем (supervised learning). А если таких примеров нет, мы будем обучать нейросеть без учителя (unsupervised learning).
Когда и как применяют обучение с учителем
Задача порождения дистракторов сводится к подбору списка слов-кандидатов и обучению ранжированию. Вопросы нужного формата обычно собираются из оцифрованных копий учебников или интернет-ресурсов.
Алгоритм должен присваивать наиболее высокие ранги словам или предложениям, которые являются дистракторами для данного вопроса, то есть помечены как дистракторы в тестовой выборке.
Получив на вход текст вопроса и текст «кандидата в дистракторы», классификатор должен «решить», насколько хорошо данный ответ может сойти за правильный в контексте данного вопроса, выдав определенную вероятность в виде числа. Подтверждением успешного обучения является получение настоящими дистракторами большего, чем у остальных кандидатов, рейтинга.
Когда применяют обучение без учителя
Когда готовый пул вопросов нужного формата отсутствует, применяют unsupervised-подход. Такая ситуация возникает, когда сами вопросы генерируются из определенного корпуса текстов. В таком случае к ним нет готового обучающего набора отвлекающих неправильных ответов.
Пример такого варианта — gap-filling questions. Это вопросы, которые получаются, если заменить какое-либо слова или словосочетание в корпусном предложении на пропуск. Задача проходящего тест — догадаться, какая единица должна быть на месте пропуска.
Как проводят обучение без учителя (на примере корпуса ошибок REALEC)
Для языкового тестирования gap-filling questions можно получить, используя специальный корпус ошибок. Так называют корпуса, которые содержат тексты, написанные не-носителями определенного языка. Эти тексты содержат области, размеченные как ошибки, а также их исправления.
Корпус ошибок REALEC содержит тексты на английском языке, написанные русскоязычными студентами в качестве письменных заданий-эссе. В системе LangExBank каждый тестовый вопрос — предложение корпуса REALEC, в котором область ошибки заменена на пропуск. Таким образом, правильный ответ и один неправильный ответ в исходных данных уже есть — это исправление и оригинальная область ошибки. Задача — получить ещё 2–3 неправильных варианта.
В LangExBank реализована генерация дистракторов из вопросов, полученных на основе лексических ошибок и ошибок на употребление предлогов. Для подбора дистракторов используется классификатор в виде рекуррентной нейронной сети. Нейросеть должна заполнить пропуск, но в обучение модели внесена принципиальная поправка: если модель предсказывала правильный вариант (т. е. слово-исправление), штраф для неё увеличивался в 2 раза.
Так как в датасете изначально не содержатся дистракторы, качество сгенерированных вариантов можно проверить только вручную. Результаты пока далеки от совершенства, поэтому платформа поддерживает редактирование полученных из корпуса тестов.
Устройство нейросети и примеры ее работы — в нашей статье: https://sysblok.ru/linguistics/zaputat-nelzja-ugadat-kak-nejroseti-generirujut-lozhnye-primanki-dlja-testov/
Никита Логин
#nlp
Составлять тесты сложно: кроме правильного ответа надо придумать и неправильные. Причем придумать их с умом: чтобы варианты не были слишком очевидно неверными — но и не оказались бы при этом подходящей альтернативой верному варианту.
В англоязычной литературе для неправильных вариантов ответа в тестах существует специальное название — дистракторы (distractors, букв. «отвлекатели»). Подбор хороших дистракторов при разработке тестов очень важен. Сейчас ученые пробуют автоматически генерировать дистракторы с помощью нейросетей.
Если у нас есть хорошие примеры дистракторов, сделанных людьми, мы можем включить их в обучающую выборку и решать задачу обучения нейросети с учителем (supervised learning). А если таких примеров нет, мы будем обучать нейросеть без учителя (unsupervised learning).
Когда и как применяют обучение с учителем
Задача порождения дистракторов сводится к подбору списка слов-кандидатов и обучению ранжированию. Вопросы нужного формата обычно собираются из оцифрованных копий учебников или интернет-ресурсов.
Алгоритм должен присваивать наиболее высокие ранги словам или предложениям, которые являются дистракторами для данного вопроса, то есть помечены как дистракторы в тестовой выборке.
Получив на вход текст вопроса и текст «кандидата в дистракторы», классификатор должен «решить», насколько хорошо данный ответ может сойти за правильный в контексте данного вопроса, выдав определенную вероятность в виде числа. Подтверждением успешного обучения является получение настоящими дистракторами большего, чем у остальных кандидатов, рейтинга.
Когда применяют обучение без учителя
Когда готовый пул вопросов нужного формата отсутствует, применяют unsupervised-подход. Такая ситуация возникает, когда сами вопросы генерируются из определенного корпуса текстов. В таком случае к ним нет готового обучающего набора отвлекающих неправильных ответов.
Пример такого варианта — gap-filling questions. Это вопросы, которые получаются, если заменить какое-либо слова или словосочетание в корпусном предложении на пропуск. Задача проходящего тест — догадаться, какая единица должна быть на месте пропуска.
Как проводят обучение без учителя (на примере корпуса ошибок REALEC)
Для языкового тестирования gap-filling questions можно получить, используя специальный корпус ошибок. Так называют корпуса, которые содержат тексты, написанные не-носителями определенного языка. Эти тексты содержат области, размеченные как ошибки, а также их исправления.
Корпус ошибок REALEC содержит тексты на английском языке, написанные русскоязычными студентами в качестве письменных заданий-эссе. В системе LangExBank каждый тестовый вопрос — предложение корпуса REALEC, в котором область ошибки заменена на пропуск. Таким образом, правильный ответ и один неправильный ответ в исходных данных уже есть — это исправление и оригинальная область ошибки. Задача — получить ещё 2–3 неправильных варианта.
В LangExBank реализована генерация дистракторов из вопросов, полученных на основе лексических ошибок и ошибок на употребление предлогов. Для подбора дистракторов используется классификатор в виде рекуррентной нейронной сети. Нейросеть должна заполнить пропуск, но в обучение модели внесена принципиальная поправка: если модель предсказывала правильный вариант (т. е. слово-исправление), штраф для неё увеличивался в 2 раза.
Так как в датасете изначально не содержатся дистракторы, качество сгенерированных вариантов можно проверить только вручную. Результаты пока далеки от совершенства, поэтому платформа поддерживает редактирование полученных из корпуса тестов.
Устройство нейросети и примеры ее работы — в нашей статье: https://sysblok.ru/linguistics/zaputat-nelzja-ugadat-kak-nejroseti-generirujut-lozhnye-primanki-dlja-testov/
Никита Логин
{kind=link}
Мы с Тамарой ходим парой: как работает современный алгоритм токенизации текстов
#nlp
За последние несколько лет NLP совершила огромный скачок. Перевести текст в машиночитаемый формат можно с помощью различных инструментов: от матриц совместной встречаемости и Word2Vec до RNN и трансформеров.
А в качестве первого шага в обработке любого текста обычно проводится токенизация. На этом этапе происходит разделение текста на более мелкие единицы — на предложения и слова. Затем обычно создается словарь, в который заносятся уникальные лексемы, встретившиеся в корпусе или тексте. На этих этапах ученые сталкиваются с несколькими проблемами.
Проблема 1: языки с богатой морфологией
Это языки с развитыми системами склонений и спряжений слов. При работе с текстами на этих языках сложность возникает при составлении словаря, когда нужно найти и объединить все словоформы одной и той же лексемы.
Пример — русский язык, в котором есть падежи. При переводе слова в векторное пространство нужно учитывать, что стол, столу и столом – это одно слово в разных падежных формах, а не 3 уникальных лексемы. Чтобы решить эту задачу, текст можно предварительно лемматизировать, или применить стемминг (от английского stem – стебель), то есть просто отрезать у слов окончания.
Проблема 2: языки с продуктивным сложением основ
В германских языках (в английском, немецком, шведском и т.д.) очень продуктивно образуются новые сложные слова. Значения таких слов выводятся из значения их элементов, их можно создавать бесконечно долго, и большинство из них не зафиксировано в “бумажном” словаре.
При работе с этими языками сложность также возникает на этапе составления словаря. При составлении словаря модели ориентируются на частотность (например, сохраняем слово, если оно встретилось чаще пяти раз), поэтому не будут запоминать такое длинное и сложное слово.
Проблема 3: определение границ слова
Современные лингвисты до сих пор не могут придумать универсальное определение понятию слово и в каждой конкретной ситуации объясняют его по-разному. Для нас, привыкших к языкам европейского типа, слово — это набор букв между пробелами и знаками препинания. По таким разделителям компьютер тоже может легко найти слово.
Но в английском языке многие сложные слова пишутся раздельно, я в японском, наоборот, между словами вообще нет пробелов. Поэтому универсальный токенизатор создать было нелегко.
Решение — Byte Pair Encoding
Первый настоящий прорыв в этом направлении был сделан исследователями из Эдинбургского университета. Они создали подслова в нейронном машинном переводе, используя алгоритм BPE — Byte Pair Encoding.
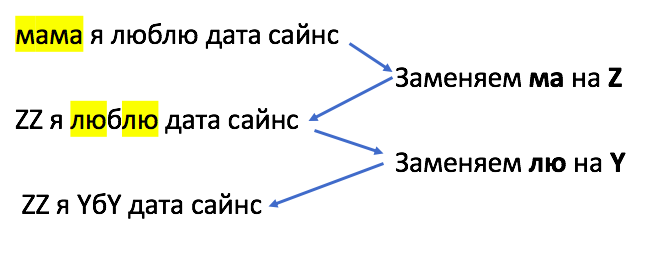
Изначально BPE был представлен как простой алгоритм сжатия данных без потерь. В феврале 1994 года Филипп Гейдж в статье «Новый алгоритм сжатия данных» описал метод, который работает так: самые частотные пары символов заменяются на другой символ, который не встречается в данных, при этом объем используемой памяти снижается с двух байт до одного. Пример кодировки прикрепляем ниже.
Для задач NLP алгоритм BPE был немного изменен: часто встречающиеся группы символов не заменяются на другой символ, а объединяются в токен и добавляются в словарь. Алгоритм токенизации на основе BPE позволяет моделям узнавать как можно больше слов при ограниченном объеме словаря и выглядит так:
Шаг 0. Создаем словарь.
Шаг 1. Представляем слова из текста как списки букв.
Шаг 2. Считаем количество вхождений каждой пары букв.
Шаг 3. Объединяем самые частотные в токен и добавляем в словарь.
Шаг 4. Повторяем шаг 3 до тех пор, пока не получим словарь заданного размера.
Сегодня схемы токенизации подслов стали нормой в самых продвинутых моделях, включая очень популярное семейство контекстных моделей, таких как BERT, GPT-2, RoBERTa и т. д.
https://sysblok.ru/nlp/7250/
Анна Аксенова
#nlp
За последние несколько лет NLP совершила огромный скачок. Перевести текст в машиночитаемый формат можно с помощью различных инструментов: от матриц совместной встречаемости и Word2Vec до RNN и трансформеров.
А в качестве первого шага в обработке любого текста обычно проводится токенизация. На этом этапе происходит разделение текста на более мелкие единицы — на предложения и слова. Затем обычно создается словарь, в который заносятся уникальные лексемы, встретившиеся в корпусе или тексте. На этих этапах ученые сталкиваются с несколькими проблемами.
Проблема 1: языки с богатой морфологией
Это языки с развитыми системами склонений и спряжений слов. При работе с текстами на этих языках сложность возникает при составлении словаря, когда нужно найти и объединить все словоформы одной и той же лексемы.
Пример — русский язык, в котором есть падежи. При переводе слова в векторное пространство нужно учитывать, что стол, столу и столом – это одно слово в разных падежных формах, а не 3 уникальных лексемы. Чтобы решить эту задачу, текст можно предварительно лемматизировать, или применить стемминг (от английского stem – стебель), то есть просто отрезать у слов окончания.
Проблема 2: языки с продуктивным сложением основ
В германских языках (в английском, немецком, шведском и т.д.) очень продуктивно образуются новые сложные слова. Значения таких слов выводятся из значения их элементов, их можно создавать бесконечно долго, и большинство из них не зафиксировано в “бумажном” словаре.
При работе с этими языками сложность также возникает на этапе составления словаря. При составлении словаря модели ориентируются на частотность (например, сохраняем слово, если оно встретилось чаще пяти раз), поэтому не будут запоминать такое длинное и сложное слово.
Проблема 3: определение границ слова
Современные лингвисты до сих пор не могут придумать универсальное определение понятию слово и в каждой конкретной ситуации объясняют его по-разному. Для нас, привыкших к языкам европейского типа, слово — это набор букв между пробелами и знаками препинания. По таким разделителям компьютер тоже может легко найти слово.
Но в английском языке многие сложные слова пишутся раздельно, я в японском, наоборот, между словами вообще нет пробелов. Поэтому универсальный токенизатор создать было нелегко.
Решение — Byte Pair Encoding
Первый настоящий прорыв в этом направлении был сделан исследователями из Эдинбургского университета. Они создали подслова в нейронном машинном переводе, используя алгоритм BPE — Byte Pair Encoding.
Изначально BPE был представлен как простой алгоритм сжатия данных без потерь. В феврале 1994 года Филипп Гейдж в статье «Новый алгоритм сжатия данных» описал метод, который работает так: самые частотные пары символов заменяются на другой символ, который не встречается в данных, при этом объем используемой памяти снижается с двух байт до одного. Пример кодировки прикрепляем ниже.
Для задач NLP алгоритм BPE был немного изменен: часто встречающиеся группы символов не заменяются на другой символ, а объединяются в токен и добавляются в словарь. Алгоритм токенизации на основе BPE позволяет моделям узнавать как можно больше слов при ограниченном объеме словаря и выглядит так:
Шаг 0. Создаем словарь.
Шаг 1. Представляем слова из текста как списки букв.
Шаг 2. Считаем количество вхождений каждой пары букв.
Шаг 3. Объединяем самые частотные в токен и добавляем в словарь.
Шаг 4. Повторяем шаг 3 до тех пор, пока не получим словарь заданного размера.
Сегодня схемы токенизации подслов стали нормой в самых продвинутых моделях, включая очень популярное семейство контекстных моделей, таких как BERT, GPT-2, RoBERTa и т. д.
https://sysblok.ru/nlp/7250/
Анна Аксенова
{kind=link}
Как работает GPT-2 и в чем его особенности
#nlp #knowhow
GPT-2 — нейросеть, которая способна генерировать образцы синтетического текста с вполне логичным повествованием, если задать ей любое начало. Модель учитывает стиль и содержание заданного ей фрагмента и уже на их основании создает свое продолжение истории. На момент релиза в ней было рекордное число параметров — 1,5 млрд против обычных 100–300 млн.
История создания и особенности GPT-2
Первая версия GPT (Generative Pre-trained Transformer) от OpenAI появилась еще летом 2018 года. Ее обучали на выборке текстов из Wikipedia и литературных произведений. Однако выяснилось, что нейросеть быстрее учится понимать естественную речь на основе простых постов в интернете. Поэтому в 2019 году OpenAI обучили GPT на больших объемах текстов — 8 млн. страниц из интернета. Новая версия нейросети получила название GPT-2.
Особенность GPT-2 в том, что она сразу — без дообучения — показала отличные результаты, близкие к state-of-the-art. Сразу после обучения нейросеть уже готова сгенерировать текст со всеми логическими вставками: повторное упоминание имен героев, цитаты, отсылки, выдержка одного стиля на протяжении всего текста, связанное повествование.
Таким образом GPT-2 могла понять суть задания примерно как человек — просто по его виду: если есть пропуски — дописать их, задают вопрос — попытаться ответить и т. д.
Что умеет GPT-2
Помимо простого создания текстов, модель можно использовать для следующих целей:
1. Краткий пересказ текста или обобщение.
В качестве входных данных нужно подать не просто фрагмент, а целый текст, состоящий из хотя бы пары абзацев (но лучше — страниц). Если в конце добавить «TL;DR», модель выдаст краткое содержание рассказа.
2. Ответы на вопросы исходя из содержания текста.
На входе подается несколько примеров в виде «Вопрос-Ответ», в конце же дается реальный вопрос, на который нейросеть выдает по тому же макету ответ.
3. Перевод текстов.
Механизм работы с переводами похож на механизм работы с ответами на вопросы. Главное — подать модели правильное начало, то есть нужную структуру текста. В оригинале GPT-2 подавали фрагменты в виде «hello- = привет» и так далее, используя английский и французский. В итоге, когда в конце была фраза «cat = …», нейросеть, следуя логике, выдала «кошку».
О том, как обучали GPT-2 и почему OpenAI предоставили доступ к его полной версии только через год после создания — читайте в нашей статье: https://sysblok.ru/knowhow/kak-rabotaet-gpt-2-i-v-chem-ego-osobennosti/
Камилла Кубелекова, Владимир Селеверстов
#nlp #knowhow
GPT-2 — нейросеть, которая способна генерировать образцы синтетического текста с вполне логичным повествованием, если задать ей любое начало. Модель учитывает стиль и содержание заданного ей фрагмента и уже на их основании создает свое продолжение истории. На момент релиза в ней было рекордное число параметров — 1,5 млрд против обычных 100–300 млн.
История создания и особенности GPT-2
Первая версия GPT (Generative Pre-trained Transformer) от OpenAI появилась еще летом 2018 года. Ее обучали на выборке текстов из Wikipedia и литературных произведений. Однако выяснилось, что нейросеть быстрее учится понимать естественную речь на основе простых постов в интернете. Поэтому в 2019 году OpenAI обучили GPT на больших объемах текстов — 8 млн. страниц из интернета. Новая версия нейросети получила название GPT-2.
Особенность GPT-2 в том, что она сразу — без дообучения — показала отличные результаты, близкие к state-of-the-art. Сразу после обучения нейросеть уже готова сгенерировать текст со всеми логическими вставками: повторное упоминание имен героев, цитаты, отсылки, выдержка одного стиля на протяжении всего текста, связанное повествование.
Таким образом GPT-2 могла понять суть задания примерно как человек — просто по его виду: если есть пропуски — дописать их, задают вопрос — попытаться ответить и т. д.
Что умеет GPT-2
Помимо простого создания текстов, модель можно использовать для следующих целей:
1. Краткий пересказ текста или обобщение.
В качестве входных данных нужно подать не просто фрагмент, а целый текст, состоящий из хотя бы пары абзацев (но лучше — страниц). Если в конце добавить «TL;DR», модель выдаст краткое содержание рассказа.
2. Ответы на вопросы исходя из содержания текста.
На входе подается несколько примеров в виде «Вопрос-Ответ», в конце же дается реальный вопрос, на который нейросеть выдает по тому же макету ответ.
3. Перевод текстов.
Механизм работы с переводами похож на механизм работы с ответами на вопросы. Главное — подать модели правильное начало, то есть нужную структуру текста. В оригинале GPT-2 подавали фрагменты в виде «hello- = привет» и так далее, используя английский и французский. В итоге, когда в конце была фраза «cat = …», нейросеть, следуя логике, выдала «кошку».
О том, как обучали GPT-2 и почему OpenAI предоставили доступ к его полной версии только через год после создания — читайте в нашей статье: https://sysblok.ru/knowhow/kak-rabotaet-gpt-2-i-v-chem-ego-osobennosti/
Камилла Кубелекова, Владимир Селеверстов
{kind=link}
ЕГЭ для нейросетей: какую языковую модель можно назвать «умной»?
#nlp #linguistics
С развитием автоматической обработки языка (NLP) языковые модели решают все более сложные задачи. Нейросеть должна научиться понимать запрос пользователя и выдавать на него правильный и адекватный ответ. Компания OpenAi предложила решение: формулировать любую задачу ИИ как продолжение текста, введенного пользователем. Так можно делать и машинные переводчики, и вопросно-ответные системы, и вообще почти что угодно в NLP.
В языковых моделях слова представлены в виде векторов-эмбеддингов. И если на начальном этапе развития NLP эмбеддинги хранили информацию только о частотных контекстах употребления слов, то сейчас модели создают векторные представления слов с синтаксической и морфологической информацией. Ученые пытаются понять природу эмбеддингов, чтобы разобраться, почему одни модели успешны, а другие нет.
Как устроен тест
SentEval — универсальный набор тестов для оценки качества моделей, разработанный в 2018 году в Facebook. Чтобы пройти «экзамен», нужно ответить на 10 вопросов из 3 концептуальных групп: внешняя, синтаксическая и семантическая информация.
— Задания из первой группы содержат простые вопросы, например, посчитать количество слов в предложении.
— Синтаксические вопросы уже сложнее: языковой модели нужно рассчитать глубину синтаксического древа или перечислить верхнеуровневые составляющие.
— Третья часть использует синтаксические свойства предложения. Модель должна определить время глагола, число подлежащего или ответить, в каких предложениях было заменено слово.
Будущее «экзамена»
Тестирование моделей и изучение их неявных свойств постепенно становится отдельной областью науки. При изучении языковой модели BERT ученые выяснили, что внутри модели можно найти разные уровни «освоения» языка. Нижние слои специализируются на внешней информации, средние уровни лучше справляются с вопросами синтаксической группы, а верхние слои сохраняют информацию для специального задания, на которое обучается модель.
Однако пока эти выводы разделяют не все исследователи — внутреннее устройство нейросетей во многом остается «черным ящиком».
https://sysblok.ru/linguistics/egje-dlja-nejrosetej-kak-testirujut-usvoenie-jazyka-mashinami/
Анна Аксёнова
#nlp #linguistics
С развитием автоматической обработки языка (NLP) языковые модели решают все более сложные задачи. Нейросеть должна научиться понимать запрос пользователя и выдавать на него правильный и адекватный ответ. Компания OpenAi предложила решение: формулировать любую задачу ИИ как продолжение текста, введенного пользователем. Так можно делать и машинные переводчики, и вопросно-ответные системы, и вообще почти что угодно в NLP.
В языковых моделях слова представлены в виде векторов-эмбеддингов. И если на начальном этапе развития NLP эмбеддинги хранили информацию только о частотных контекстах употребления слов, то сейчас модели создают векторные представления слов с синтаксической и морфологической информацией. Ученые пытаются понять природу эмбеддингов, чтобы разобраться, почему одни модели успешны, а другие нет.
Как устроен тест
SentEval — универсальный набор тестов для оценки качества моделей, разработанный в 2018 году в Facebook. Чтобы пройти «экзамен», нужно ответить на 10 вопросов из 3 концептуальных групп: внешняя, синтаксическая и семантическая информация.
— Задания из первой группы содержат простые вопросы, например, посчитать количество слов в предложении.
— Синтаксические вопросы уже сложнее: языковой модели нужно рассчитать глубину синтаксического древа или перечислить верхнеуровневые составляющие.
— Третья часть использует синтаксические свойства предложения. Модель должна определить время глагола, число подлежащего или ответить, в каких предложениях было заменено слово.
Будущее «экзамена»
Тестирование моделей и изучение их неявных свойств постепенно становится отдельной областью науки. При изучении языковой модели BERT ученые выяснили, что внутри модели можно найти разные уровни «освоения» языка. Нижние слои специализируются на внешней информации, средние уровни лучше справляются с вопросами синтаксической группы, а верхние слои сохраняют информацию для специального задания, на которое обучается модель.
Однако пока эти выводы разделяют не все исследователи — внутреннее устройство нейросетей во многом остается «черным ящиком».
https://sysblok.ru/linguistics/egje-dlja-nejrosetej-kak-testirujut-usvoenie-jazyka-mashinami/
Анна Аксёнова
{kind=link}
По словам их узнаете их: как вычисляли автора «Беовульфа»
#philology #nlp
Древнеанглийская поэма «Беовульф» — цельная работа одного автора или комбинация нескольких текстов? Чтобы ответить на этот вопрос, ученые проанализировали древнеанглийскую литературу количественными методами компьютерной лингвистики.
I. Что говорят количественные методы?
Анализ пауз
Сначала проанализировали смысловые паузы. Исследователи подсчитали отношение внутристрочных и смысловых пауз в обеих частях «Беовульфа» Получилось, что отношения для первой и второй части находятся в пределах 4% друг от друга. Чтобы подтвердить результаты, их также сравнили с другими древнеанглийскими поэмами и древнегреческим эпосом.
Анализ метра
Затем проанализировали метр «Беовульфа». Для этого использовалась классификация, предложенная Сиверсом, который делит полустроки на пять основных звуковых паттернов. Были исследованы как общая частота пяти типов, так и их последовательность в «Беовульфе». Оказалось, что уровень использования каждого типа остается линейным по всему тексту, без заметного сдвига в районе строки 2300 (конец первой части поэмы).
Анализ сложных существительных
Наконец, рассмотрели распределение сложных (составных) существительных по тексту «Беовульфа» и по всему корпусу древнеанглйской поэзии. Сложные существительные — такие как hran-rád «море» (букв. «дорога китов») и bán-hús «тело» (букв. «дом костей») — типичны для древнеанглийской поэзии.
Для определения авторства особенно важно подсчитать использование гапаксов — слов, встретившееся в некотором корпусе текстов только один раз. Доля гапаксов в текстах разных авторов сильно разнится, а в «Беовульфе» линейна по всему тексту, без изменений в области строки 2300. Небольшая нелинейность около строки 1500 соответствует битве Беовульфа с матерью Гренделя. Это место в поэме изобилует сложными словами.
II. Критика исследования
Воспроизводимость — важное свойство научных экспериментов. Группа ученых попыталась воспроизвести это исследование и пришла к выводу, что все четыре главных характеристики, которые были использованы для «количественного профилирования» древнеанглийской поэзии, либо имеют методологически сомнительные параметры (что ведет к неверной интерпретации результатов атрибуции текстов), либо неоптимальное воплощение, либо и то, и другое.
Критики также нашли серьезные ошибки в коде и никак не объясненные пропуски в данных, а одну часть результатов не получилось воспроизвести. Недостатки методологии ставят под вопрос главные выводы исследования.
https://sysblok.ru/philology/po-slovam-ih-uznaete-ih-kak-vychisljali-avtora-beovulfa/
Ксения Кашлева
#philology #nlp
Древнеанглийская поэма «Беовульф» — цельная работа одного автора или комбинация нескольких текстов? Чтобы ответить на этот вопрос, ученые проанализировали древнеанглийскую литературу количественными методами компьютерной лингвистики.
I. Что говорят количественные методы?
Анализ пауз
Сначала проанализировали смысловые паузы. Исследователи подсчитали отношение внутристрочных и смысловых пауз в обеих частях «Беовульфа» Получилось, что отношения для первой и второй части находятся в пределах 4% друг от друга. Чтобы подтвердить результаты, их также сравнили с другими древнеанглийскими поэмами и древнегреческим эпосом.
Анализ метра
Затем проанализировали метр «Беовульфа». Для этого использовалась классификация, предложенная Сиверсом, который делит полустроки на пять основных звуковых паттернов. Были исследованы как общая частота пяти типов, так и их последовательность в «Беовульфе». Оказалось, что уровень использования каждого типа остается линейным по всему тексту, без заметного сдвига в районе строки 2300 (конец первой части поэмы).
Анализ сложных существительных
Наконец, рассмотрели распределение сложных (составных) существительных по тексту «Беовульфа» и по всему корпусу древнеанглйской поэзии. Сложные существительные — такие как hran-rád «море» (букв. «дорога китов») и bán-hús «тело» (букв. «дом костей») — типичны для древнеанглийской поэзии.
Для определения авторства особенно важно подсчитать использование гапаксов — слов, встретившееся в некотором корпусе текстов только один раз. Доля гапаксов в текстах разных авторов сильно разнится, а в «Беовульфе» линейна по всему тексту, без изменений в области строки 2300. Небольшая нелинейность около строки 1500 соответствует битве Беовульфа с матерью Гренделя. Это место в поэме изобилует сложными словами.
II. Критика исследования
Воспроизводимость — важное свойство научных экспериментов. Группа ученых попыталась воспроизвести это исследование и пришла к выводу, что все четыре главных характеристики, которые были использованы для «количественного профилирования» древнеанглийской поэзии, либо имеют методологически сомнительные параметры (что ведет к неверной интерпретации результатов атрибуции текстов), либо неоптимальное воплощение, либо и то, и другое.
Критики также нашли серьезные ошибки в коде и никак не объясненные пропуски в данных, а одну часть результатов не получилось воспроизвести. Недостатки методологии ставят под вопрос главные выводы исследования.
https://sysblok.ru/philology/po-slovam-ih-uznaete-ih-kak-vychisljali-avtora-beovulfa/
Ксения Кашлева
{kind=link}
История стилометрии: как в разное время люди искали авторов текстов
#nlp
В 1440 году итальянский гуманист Лоренцо Валла написал трактат «О подложности Константинова дара», в котором доказал, что текст этой грамоты — подделка, написанная средневековой латынью VIII века, а не IV века, как предполагалось. До этого «Константинов дар» использовался римскими папами для получения светской власти над Неаполитанским королевством в XV веке.
Эта работа — первый пример определения авторства текста с опорой на сам текст. К сожалению, в ситуациях, когда временного разрыва между текстом и событием нет, такой метод не применим.
Появление стилометрии
В конце XIX веке ученые предположили, что для определения авторства и датировки текстов можно использовать количественные методы, то есть искать в текстах частотные атомарные факты.
Эти идеи развивали Томас Менденхолл, Винцетий Лютославский и Николай Морозов. После появления ЭВМ Фредерик Мостеллер и Дэвид Уоллес, наконец, успешно применили этот метод. Они выяснили, что автором 12 спорных памфлетов из «Записок федералиста» — сборника статей в поддержку утверждения Конституции США — был Джеймс Мэдисон (4-й президент США).
Современная стилометрия
Большинство современных стилометрических исследований опираются на метод Дельты, придуманный Джоном Барроузом (John Burrows) в конце 1990-х — начале 2000-х годов. В его основе лежит подсчет разницы в частотностях между наиболее частотными словами в спорном тексте и тех трудах, чье авторство не вызывает сомнения. Чем меньше дельта, тем выше вероятность, что текст принадлежит ближайшему автору.
Так Джон Барроуз изобрел первый универсальный инструмент для атрибуции текста. Его главный плюс в том, что результаты легко верифицировать экспериментально, а недостаток — что достоверно он работает только на больших текстах, не менее 5–10 тыс. слов.
Некоторые результаты стилометрических исследований
Например, подтвердилось мнение о том, что часть пьесы «Генрих VI» Шекспир писал в соавторстве с Кристофером Марло — одним из тех людей, кому иногда приписывают авторство Шекспира. Некоторые издательства уже указывают, что «Генрих VI» был написан в соавторстве.
Также мы уже писали о других исследованиях и их результатах:
• об определении автора «Сна в красном тереме»;
• об авторстве пьес Мольера;
• об авторстве анонимных статей революционной эпохи;
• о подлинности «Слова о полку Игореве».
https://sysblok.ru/knowhow/stilometrija-kak-v-raznoe-vremja-ljudi-iskali-avtorov-tekstov/
Алина Затонская, Даниил Скоринкин
#nlp
В 1440 году итальянский гуманист Лоренцо Валла написал трактат «О подложности Константинова дара», в котором доказал, что текст этой грамоты — подделка, написанная средневековой латынью VIII века, а не IV века, как предполагалось. До этого «Константинов дар» использовался римскими папами для получения светской власти над Неаполитанским королевством в XV веке.
Эта работа — первый пример определения авторства текста с опорой на сам текст. К сожалению, в ситуациях, когда временного разрыва между текстом и событием нет, такой метод не применим.
Появление стилометрии
В конце XIX веке ученые предположили, что для определения авторства и датировки текстов можно использовать количественные методы, то есть искать в текстах частотные атомарные факты.
Эти идеи развивали Томас Менденхолл, Винцетий Лютославский и Николай Морозов. После появления ЭВМ Фредерик Мостеллер и Дэвид Уоллес, наконец, успешно применили этот метод. Они выяснили, что автором 12 спорных памфлетов из «Записок федералиста» — сборника статей в поддержку утверждения Конституции США — был Джеймс Мэдисон (4-й президент США).
Современная стилометрия
Большинство современных стилометрических исследований опираются на метод Дельты, придуманный Джоном Барроузом (John Burrows) в конце 1990-х — начале 2000-х годов. В его основе лежит подсчет разницы в частотностях между наиболее частотными словами в спорном тексте и тех трудах, чье авторство не вызывает сомнения. Чем меньше дельта, тем выше вероятность, что текст принадлежит ближайшему автору.
Так Джон Барроуз изобрел первый универсальный инструмент для атрибуции текста. Его главный плюс в том, что результаты легко верифицировать экспериментально, а недостаток — что достоверно он работает только на больших текстах, не менее 5–10 тыс. слов.
Некоторые результаты стилометрических исследований
Например, подтвердилось мнение о том, что часть пьесы «Генрих VI» Шекспир писал в соавторстве с Кристофером Марло — одним из тех людей, кому иногда приписывают авторство Шекспира. Некоторые издательства уже указывают, что «Генрих VI» был написан в соавторстве.
Также мы уже писали о других исследованиях и их результатах:
• об определении автора «Сна в красном тереме»;
• об авторстве пьес Мольера;
• об авторстве анонимных статей революционной эпохи;
• о подлинности «Слова о полку Игореве».
https://sysblok.ru/knowhow/stilometrija-kak-v-raznoe-vremja-ljudi-iskali-avtorov-tekstov/
Алина Затонская, Даниил Скоринкин
{kind=link}
Как нейросеть заменяет нецензурную лексику на эвфемизмы
#knowhow #nlp
Машинное обучение разрешает менять стилистику текста без изменения содержания. Например, нейросеть сгенерировала песни в стиле Егора Летова, а также ведет аккаунт Neural Meduza в Twitter`е. Однако методы генерации и стилизации текстов приносят и практическую пользу.
ВКонтакте фильтрует комментарии
ВКонтакте тестирует новые функции: сервис учится фильтровать оскорбительные комментарии в сообществах, а также предупреждать пользователей о неприемлемом тоне высказываний. Так как диаметральная смена окраски комментариев — это нарушение свободы слова, нашли полумеру: нецензурная лексика будет заменяться эвфемизмами, а остальные высказывания — «сглаживаться».
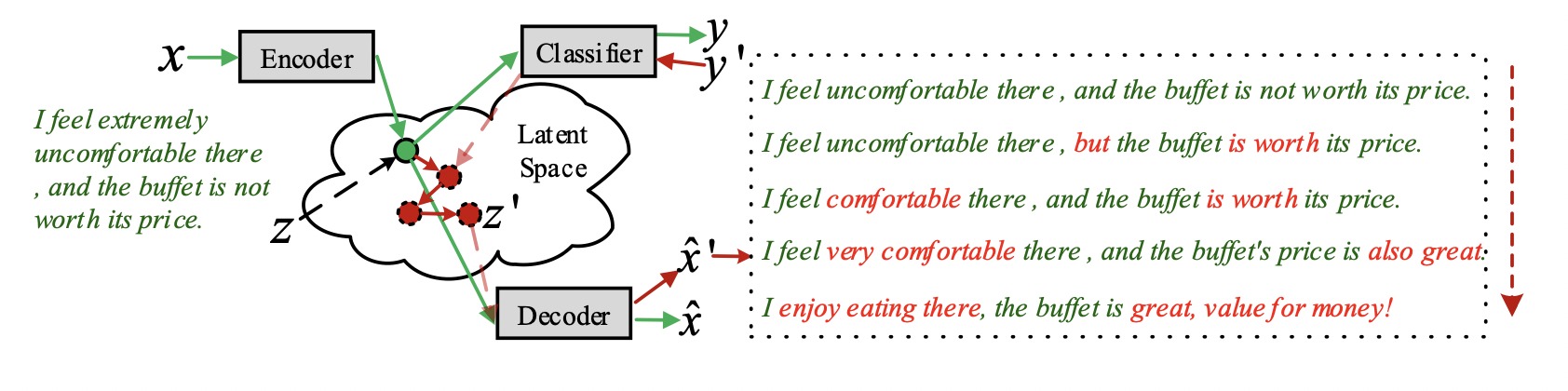
Перенос стиля: как это работает
Перенос стиля основан на изменении векторных представлений текстов. Мы уже рассказывали, как создаются такие вектора.
Чтобы научиться переносить стиль текста, потребуется:
1. два корпуса текстов с противоположными стилями: положительный и отрицательный, токсичный и обычный и т.д.
2. автокодировщик, который нужно обучить тому, как представлять тексты в виде векторов
Алгоритм следующий:
1. обучаем кодировщик на обоих корпусах
2. получаем векторные представления текстов стиля 1
3. изменяем полученные вектора в соответствии с векторами текста стиля 2
4. подаем измененные вектора на вход декодировщику
5. получаем тексты стиля 2
Основная задача — изменить векторы так, чтобы на выходе получился текст нужного стиля. Для этого берем векторные представления текстов для обоих корпусов и обучаем на них новую нейронную сеть определять стиль текста. После обучения пытаемся её обмануть: берём вектор текста стиля 1 и добавляем шум. Шум подбираем таким образом, чтобы нейросеть перепутала стиль и на выходе мы получили текст стиля 2.
Альтернативное решение
Есть более сложный и продвинутый метод, который позволяет менять стиль и содержание текста независимо друг от друга. В этом случае вся информация о стиле содержится в одной части вектора, а информация о содержании — в другой.
https://sysblok.ru/knowhow/v-prostranstve-tekstov-detoksikacija-kommentariev-poddelka-otzyvov-i-nejrocenzura/
Михаил Ким
#knowhow #nlp
Машинное обучение разрешает менять стилистику текста без изменения содержания. Например, нейросеть сгенерировала песни в стиле Егора Летова, а также ведет аккаунт Neural Meduza в Twitter`е. Однако методы генерации и стилизации текстов приносят и практическую пользу.
ВКонтакте фильтрует комментарии
ВКонтакте тестирует новые функции: сервис учится фильтровать оскорбительные комментарии в сообществах, а также предупреждать пользователей о неприемлемом тоне высказываний. Так как диаметральная смена окраски комментариев — это нарушение свободы слова, нашли полумеру: нецензурная лексика будет заменяться эвфемизмами, а остальные высказывания — «сглаживаться».
Перенос стиля: как это работает
Перенос стиля основан на изменении векторных представлений текстов. Мы уже рассказывали, как создаются такие вектора.
Чтобы научиться переносить стиль текста, потребуется:
1. два корпуса текстов с противоположными стилями: положительный и отрицательный, токсичный и обычный и т.д.
2. автокодировщик, который нужно обучить тому, как представлять тексты в виде векторов
Алгоритм следующий:
1. обучаем кодировщик на обоих корпусах
2. получаем векторные представления текстов стиля 1
3. изменяем полученные вектора в соответствии с векторами текста стиля 2
4. подаем измененные вектора на вход декодировщику
5. получаем тексты стиля 2
Основная задача — изменить векторы так, чтобы на выходе получился текст нужного стиля. Для этого берем векторные представления текстов для обоих корпусов и обучаем на них новую нейронную сеть определять стиль текста. После обучения пытаемся её обмануть: берём вектор текста стиля 1 и добавляем шум. Шум подбираем таким образом, чтобы нейросеть перепутала стиль и на выходе мы получили текст стиля 2.
Альтернативное решение
Есть более сложный и продвинутый метод, который позволяет менять стиль и содержание текста независимо друг от друга. В этом случае вся информация о стиле содержится в одной части вектора, а информация о содержании — в другой.
https://sysblok.ru/knowhow/v-prostranstve-tekstov-detoksikacija-kommentariev-poddelka-otzyvov-i-nejrocenzura/
Михаил Ким
{kind=link}
Как работает BERT
#knowhow #nlp
BERT или Bidirectional Encoder Representations from Transformers — это нейросетевая модель-трансформер от Google, на которой строится большинство инструментов автоматической обработки языка. Код модели выложен в открытый доступ. Саму нейросеть можно запустить как на локальном компьютере, так и на бесплатном серверном GPU на Google Colab.
Эмбеддинги и бенчмарки
Языковая модель работает с текстом, но для компьютера текст сам по себе ничего не значит. Чтобы закодировать текст в осмысленные числа, люди придумали векторные представления слов, которые основаны на контекстах употребления этих слов. Такие векторные представления называются эмбеддинги. Они кодируют семантические близости слов, причем с учетом контекста конкретного предложения.
Языковая модель принимает на вход эмбеддинги токенов и выдает результат в зависимости от задачи: стандартный набор задач, который выполняют на стандартном наборе данных, чтобы доказать, что нейросеть справляется с пониманием текста. Стандартные задачи называются в NLP бенчмарками («ориентир», «отметка» по-английски). BERT тестировали на наборах бенчмарков GLUE — «Оценка общего
понимания языка», SQuAD и SWAG.
Обучение нейросети
В зависимости от конечной цели используют либо машинное обучение с учителем (supervised learning), либо без него (unsupervised learning).
Для сложных нейросетей используют процессы «предобучения» и «дообучения». В первом методе нейросеть прогоняют на больших объемах текстов. Во втором – обнуляют финальный слой весов и тренируют модель на новом наборе данных.
Обучение BERT
Новшество BERTа — в способе предобучения. Ранние архитектуры, чтобы обучиться, предсказывали, какое слово вероятнее будет стоять следующим, учитывая слова до него. BERT же предобучается на «маскированной языковой модели»: нужно предсказать слово не в конце предложения, а посередине. Главная задача — угадать, какие слова пропущены (выдать числовой код) и сказать, подходит ли второе предложение к первому.
Для дообучения (файнтьюнинга) в BERT не нужно стирать «часть памяти» модели. Вместо этого «поверх» модели добавляют новый слой нейронов. Его матрицы весов заполнены случайными числами, которые настраивают так, чтобы на новой задаче ошибка была минимальной.
BERT используется в Google: поначалу эта модель работала только для английского языка, позже добавили в поиск и на других языках. Нейросеть можно использовать для модерации текстов, поиска ответов на юридические вопросы, оптимизации работы с SEO-сайтами. Кроме того, практически половина NLP использует BERT и BERT-подобные архитектуры.
https://sysblok.ru/knowhow/kak-ustroena-nejroset-bert-ot-google/
Камилла Кубелекова, Владимир Селеверстов
#knowhow #nlp
BERT или Bidirectional Encoder Representations from Transformers — это нейросетевая модель-трансформер от Google, на которой строится большинство инструментов автоматической обработки языка. Код модели выложен в открытый доступ. Саму нейросеть можно запустить как на локальном компьютере, так и на бесплатном серверном GPU на Google Colab.
Эмбеддинги и бенчмарки
Языковая модель работает с текстом, но для компьютера текст сам по себе ничего не значит. Чтобы закодировать текст в осмысленные числа, люди придумали векторные представления слов, которые основаны на контекстах употребления этих слов. Такие векторные представления называются эмбеддинги. Они кодируют семантические близости слов, причем с учетом контекста конкретного предложения.
Языковая модель принимает на вход эмбеддинги токенов и выдает результат в зависимости от задачи: стандартный набор задач, который выполняют на стандартном наборе данных, чтобы доказать, что нейросеть справляется с пониманием текста. Стандартные задачи называются в NLP бенчмарками («ориентир», «отметка» по-английски). BERT тестировали на наборах бенчмарков GLUE — «Оценка общего
понимания языка», SQuAD и SWAG.
Обучение нейросети
В зависимости от конечной цели используют либо машинное обучение с учителем (supervised learning), либо без него (unsupervised learning).
Для сложных нейросетей используют процессы «предобучения» и «дообучения». В первом методе нейросеть прогоняют на больших объемах текстов. Во втором – обнуляют финальный слой весов и тренируют модель на новом наборе данных.
Обучение BERT
Новшество BERTа — в способе предобучения. Ранние архитектуры, чтобы обучиться, предсказывали, какое слово вероятнее будет стоять следующим, учитывая слова до него. BERT же предобучается на «маскированной языковой модели»: нужно предсказать слово не в конце предложения, а посередине. Главная задача — угадать, какие слова пропущены (выдать числовой код) и сказать, подходит ли второе предложение к первому.
Для дообучения (файнтьюнинга) в BERT не нужно стирать «часть памяти» модели. Вместо этого «поверх» модели добавляют новый слой нейронов. Его матрицы весов заполнены случайными числами, которые настраивают так, чтобы на новой задаче ошибка была минимальной.
BERT используется в Google: поначалу эта модель работала только для английского языка, позже добавили в поиск и на других языках. Нейросеть можно использовать для модерации текстов, поиска ответов на юридические вопросы, оптимизации работы с SEO-сайтами. Кроме того, практически половина NLP использует BERT и BERT-подобные архитектуры.
https://sysblok.ru/knowhow/kak-ustroena-nejroset-bert-ot-google/
Камилла Кубелекова, Владимир Селеверстов
{kind=link}
UniLM — языковая модель для тех, кому мало BERT
#nlp
Мы уже рассказывали о языковых моделях BERT и GPT-2. Теперь разбираемся, как работает еще одна нейросетевая языковая модель.
UniLM расшифровывается как Unified pre-training Language Model. По архитектуре это многослойный трансформер, предварительно обученный на больших объемах текста. В отличие от BERT, UniLM используют как для задач понимания естественного языка (NLU), так и для генерации задач для NLU — NLG (Natural Language Generation).
Обучение нейросети
Обычно для обучения нейросетей используются три типа задач языкового моделирования (LM, Language Model): однонаправленная LM, двунаправленная LM, sequence-to-sequence LM. В случае с UniLM происходит единый процесс обучения и используется одна языковая модель Transformeк с общими параметрами и архитектурой для различных видов моделирования. Сеть не нужно отдельно обучать каждой задаче и отдельно хранить результаты.
Представление текста в UniLM такое же, как в BERT: сначала текст токенизируется, для этого используется алгоритм WordPiece: текст делится на ограниченный набор «подслов», частей слов. Из входной последовательности токенов случайным образом выбираются некоторые токены и заменяются на специальный токен MASK. Далее нейросеть обучается предсказывать замененные токены — стандартный на сегодня способ тренировки языковых моделей.
Для различных задач языкового моделирования используются различные матрицы масок.
• однонаправленная LM — использование left-to-right, right-to-left задач языкового моделирования.
• двунаправленная LM — кодировка контекстной информации и генерация контекстных представлений текста.
• sequence-to-sequence LM — при генерации токена участвуют токены из первой последовательности (источника), а из второй (целевой) последовательности берутся только токены слева от целевого токена и сам целевой токен. В итоге, для токенов в целевой последовательности блокируются токены, расположенные справа от них.
Архитектура UniLM соответствует архитектуре BERT LARGE. Размер словаря — 28 996 токенов, максимальная длина входной последовательности — 512. Вероятность маскирования токена составляет 15%. Процедура обучения состоит из 770 000 шагов.
Результаты работы UniLM
Нейросетевая языковая модель использовалась для задач автоматического реферирования — генерации краткого резюме входного текста. В качестве входных данных использовался датасет CNN / Daily Mail и корпус Gigaword для дообучения модели.
Так же модель тестировали на задаче ответов на вопросы — QA (Question Answering). Задача состоит в том, чтобы ответить на вопрос с учетом отрывка текста. Есть два варианта задачи: с извлечением ответа из текста и с порождением ответа на основе текста. Эксперименты показали, что при генерации ответов UniLM по качеству превосходит результаты лучших на момент проведения экспериментов моделей: Seq2Seq и PGNet.
Применение модели
Архитектура UniLM подходит для решения задач языкового моделирования, однако для конкретной задачи по-прежнему требуется дообучение на специфических данных для конкретной задачи. Это ограничивает применение языковой модели в практических целях: к примеру, для исправления грамматики или генерации рецензии к короткому рассказу трудно собрать набор дообучающих данных.
Нередко случается, что большие предобученные модели не обобщаются для узкоспециализированных задач. Поэтому появляются модели, для обучения которых используют метод контекстного обучения.
https://sysblok.ru/nlp/unilm-jazykovaja-model-dlja-teh-komu-malo-bert/
Светлана Бесаева
#nlp
Мы уже рассказывали о языковых моделях BERT и GPT-2. Теперь разбираемся, как работает еще одна нейросетевая языковая модель.
UniLM расшифровывается как Unified pre-training Language Model. По архитектуре это многослойный трансформер, предварительно обученный на больших объемах текста. В отличие от BERT, UniLM используют как для задач понимания естественного языка (NLU), так и для генерации задач для NLU — NLG (Natural Language Generation).
Обучение нейросети
Обычно для обучения нейросетей используются три типа задач языкового моделирования (LM, Language Model): однонаправленная LM, двунаправленная LM, sequence-to-sequence LM. В случае с UniLM происходит единый процесс обучения и используется одна языковая модель Transformeк с общими параметрами и архитектурой для различных видов моделирования. Сеть не нужно отдельно обучать каждой задаче и отдельно хранить результаты.
Представление текста в UniLM такое же, как в BERT: сначала текст токенизируется, для этого используется алгоритм WordPiece: текст делится на ограниченный набор «подслов», частей слов. Из входной последовательности токенов случайным образом выбираются некоторые токены и заменяются на специальный токен MASK. Далее нейросеть обучается предсказывать замененные токены — стандартный на сегодня способ тренировки языковых моделей.
Для различных задач языкового моделирования используются различные матрицы масок.
• однонаправленная LM — использование left-to-right, right-to-left задач языкового моделирования.
• двунаправленная LM — кодировка контекстной информации и генерация контекстных представлений текста.
• sequence-to-sequence LM — при генерации токена участвуют токены из первой последовательности (источника), а из второй (целевой) последовательности берутся только токены слева от целевого токена и сам целевой токен. В итоге, для токенов в целевой последовательности блокируются токены, расположенные справа от них.
Архитектура UniLM соответствует архитектуре BERT LARGE. Размер словаря — 28 996 токенов, максимальная длина входной последовательности — 512. Вероятность маскирования токена составляет 15%. Процедура обучения состоит из 770 000 шагов.
Результаты работы UniLM
Нейросетевая языковая модель использовалась для задач автоматического реферирования — генерации краткого резюме входного текста. В качестве входных данных использовался датасет CNN / Daily Mail и корпус Gigaword для дообучения модели.
Так же модель тестировали на задаче ответов на вопросы — QA (Question Answering). Задача состоит в том, чтобы ответить на вопрос с учетом отрывка текста. Есть два варианта задачи: с извлечением ответа из текста и с порождением ответа на основе текста. Эксперименты показали, что при генерации ответов UniLM по качеству превосходит результаты лучших на момент проведения экспериментов моделей: Seq2Seq и PGNet.
Применение модели
Архитектура UniLM подходит для решения задач языкового моделирования, однако для конкретной задачи по-прежнему требуется дообучение на специфических данных для конкретной задачи. Это ограничивает применение языковой модели в практических целях: к примеру, для исправления грамматики или генерации рецензии к короткому рассказу трудно собрать набор дообучающих данных.
Нередко случается, что большие предобученные модели не обобщаются для узкоспециализированных задач. Поэтому появляются модели, для обучения которых используют метод контекстного обучения.
https://sysblok.ru/nlp/unilm-jazykovaja-model-dlja-teh-komu-malo-bert/
Светлана Бесаева
{kind=link}
Анализ тональности отзывов о запрещенных веществах
#nlp
Язык интернета имеет свои особенности, и его активно исследуют лингвисты. Однако мало известно о характеристиках русского языка, используемого для нелегальной деятельности в DarkNet'е. DarkNet — это та часть интернета, которая не индексируется поисковыми системами и требует специального софта для входа. Именно там происходит большая часть нелегальной онлайн-активности
Сбор материала
Цель нашего мини-исследования: выявить и описать специфические лексические средства, используемые в отзывах о запрещенных веществах. Для этого мы провели анализ тональности — это автоматическое определение отрицательности или положительности отзыва. С помощью анализа можно выявить эмоционально окрашенную лексику.
Для этого с одной из крупнейших площадок для продажи наркотических веществ в DarkNet'е были собраны тренировочная и тестовая выборки. В тренировочную выборку входят 1000 отзывов о пяти разных наркотических веществах; в тестовую — 200 отзывов. Положительные отзывы были размечены как 1, а отрицательные как -1.
Обучение модели
• приведение всех слов в начальную форму, удаление стоп-слов. Длина всех положительных отзывов составила 10403 слова, а отрицательных — 10624.
• превращение текстов в цифровые вектора с помощью TF-IDF и Count Vectorizer'а.
• разделение отзывов по лексическому составу. Для этого воспользуемся decision_function: функция сообщает, где в пространстве значений, по мнению модели, лежит тот или иной отзыв. Итог: большая часть положительных отзывов имеют схожую лексику — как и большинство отрицательных.
• определение характерных слов для положительных и отрицательных отзывов. Для этого использовали модели логистической регрессии (Logistic Regression) и метода опорных векторов (Support Vector Machines).
Характеристика отзывов
Самым решающим словом для определения отрицательности отзыва является «ненаход», а для положительности — «касание». «Ненаход» обозначает ситуацию, когда покупатель не обнаружил на месте приобретенный товар. Слово «клад» фигурирует в жалобах на неудачные места для тайников. Кроме того, в пределах двух слов от «клада» 35 раз встречается слово «ненаход».
«Касание» наоборот значит, что тайник было легко забрать. «Касание» может употребляться как в качестве самостоятельного слова, так и с предлогом в, а также с глаголами забрать, снять и поднять.
Слово «квест» обозначает сам процесс получения товара. В положительных отзывах «квест» обычно употребляют в контексте того, как легко было найти и забрать товар. Вообще легкость получения «клада» — ключевой фактор для тональности всего отзыва.
https://sysblok.ru/nlp/kladmen-mudak-analiz-tonalnosti-otzyvov-o-zapreshhennyh-veshhestvah/
P.S. От редакции: употреблять наркотики смертельно опасно, а хранить их и тем более торговать ими — еще и уголовно наказуемо. Наш текст посвящен сугубо научному исследованию лингвистических аспектов этой противозаконной деятельности. Редакция против наркотиков, поэтому мы не раскрываем название площадки и способы попасть туда.
#nlp
Язык интернета имеет свои особенности, и его активно исследуют лингвисты. Однако мало известно о характеристиках русского языка, используемого для нелегальной деятельности в DarkNet'е. DarkNet — это та часть интернета, которая не индексируется поисковыми системами и требует специального софта для входа. Именно там происходит большая часть нелегальной онлайн-активности
Сбор материала
Цель нашего мини-исследования: выявить и описать специфические лексические средства, используемые в отзывах о запрещенных веществах. Для этого мы провели анализ тональности — это автоматическое определение отрицательности или положительности отзыва. С помощью анализа можно выявить эмоционально окрашенную лексику.
Для этого с одной из крупнейших площадок для продажи наркотических веществ в DarkNet'е были собраны тренировочная и тестовая выборки. В тренировочную выборку входят 1000 отзывов о пяти разных наркотических веществах; в тестовую — 200 отзывов. Положительные отзывы были размечены как 1, а отрицательные как -1.
Обучение модели
• приведение всех слов в начальную форму, удаление стоп-слов. Длина всех положительных отзывов составила 10403 слова, а отрицательных — 10624.
• превращение текстов в цифровые вектора с помощью TF-IDF и Count Vectorizer'а.
• разделение отзывов по лексическому составу. Для этого воспользуемся decision_function: функция сообщает, где в пространстве значений, по мнению модели, лежит тот или иной отзыв. Итог: большая часть положительных отзывов имеют схожую лексику — как и большинство отрицательных.
• определение характерных слов для положительных и отрицательных отзывов. Для этого использовали модели логистической регрессии (Logistic Regression) и метода опорных векторов (Support Vector Machines).
Характеристика отзывов
Самым решающим словом для определения отрицательности отзыва является «ненаход», а для положительности — «касание». «Ненаход» обозначает ситуацию, когда покупатель не обнаружил на месте приобретенный товар. Слово «клад» фигурирует в жалобах на неудачные места для тайников. Кроме того, в пределах двух слов от «клада» 35 раз встречается слово «ненаход».
«Касание» наоборот значит, что тайник было легко забрать. «Касание» может употребляться как в качестве самостоятельного слова, так и с предлогом в, а также с глаголами забрать, снять и поднять.
Слово «квест» обозначает сам процесс получения товара. В положительных отзывах «квест» обычно употребляют в контексте того, как легко было найти и забрать товар. Вообще легкость получения «клада» — ключевой фактор для тональности всего отзыва.
https://sysblok.ru/nlp/kladmen-mudak-analiz-tonalnosti-otzyvov-o-zapreshhennyh-veshhestvah/
P.S. От редакции: употреблять наркотики смертельно опасно, а хранить их и тем более торговать ими — еще и уголовно наказуемо. Наш текст посвящен сугубо научному исследованию лингвистических аспектов этой противозаконной деятельности. Редакция против наркотиков, поэтому мы не раскрываем название площадки и способы попасть туда.
Forwarded from Kali Novskaya
🌸Про ABBYY и будущее лингвистики🌸
#nlp #про_nlp
По тг разошёлся текст Системного Блока про ABBYY, да и правда, после истории массовых увольнений очень хотелось подвести какую-то черту. Напишу свои 5 копеек, потому что можно сказать, что вокруг ABBYY начиналась моя карьера.
ABBYY долгое время считалась самой лучшей компанией, куда мог бы устроиться лингвист.
Когда я только поступала на ОТиПЛ, туда шли работать лучшие выпускники. При этом ходило мнение, что вот, дескать, интеллектуальная эксплуатация — забирают лучших выпускников, которые могли бы быть успешными учёными, и фуллтайм заставляют писать правила на Compreno. (Ну и правда, в 2012 году там 40-60к платили, а в академии меньше.)
Помимо прочего, ABBYY оранизовывала самую большую NLP конференцию — Диалог, а также создала интернет-корпус русского языка, спонсировала кучу NLP-соревнований и shared tasks, которые распаляли многих проверить свои гипотезы на практике.
🟣 Что же теперь делать лингвистике?
Лингвистика разберётся!
Я думаю, текущий вызов даже не самый серьёзный за историю существования кафедры. Да, последние годы приходилось работать под давлением общественного мнения, хайпом LLM...ну так он пройдёт.
Аналитическая, теоретическая лингвистика нужна самой себе и другим наукам:
— как понять и описать происхождение языка,
— как определить биологические ограничения, повлиявшие на язык
— как язык влияет на мышление и обратно,
— как смоделировать максимально общую теоретическую модель языка, описывающую процессы в языках мира,
— как проверить и описать, что находится в корпусе.
Все эти вопросы остаются нужны, и остаются ключевыми вопросами лингвистики.
А языковые модели и NLP потихоньку поглощают уже другие науки:
— OpenAI нанимает филдсевских лауреатов в т ч для составления SFT датасета по математике
— они же нанимают PhD в разных дисциплинах для разметки и валидации данных.
Так что в жернова ИИ пойдут уже выпускники других специальностей. А лингвистика будет заниматься делом.
#nlp #про_nlp
По тг разошёлся текст Системного Блока про ABBYY, да и правда, после истории массовых увольнений очень хотелось подвести какую-то черту. Напишу свои 5 копеек, потому что можно сказать, что вокруг ABBYY начиналась моя карьера.
ABBYY долгое время считалась самой лучшей компанией, куда мог бы устроиться лингвист.
Когда я только поступала на ОТиПЛ, туда шли работать лучшие выпускники. При этом ходило мнение, что вот, дескать, интеллектуальная эксплуатация — забирают лучших выпускников, которые могли бы быть успешными учёными, и фуллтайм заставляют писать правила на Compreno. (Ну и правда, в 2012 году там 40-60к платили, а в академии меньше.)
Помимо прочего, ABBYY оранизовывала самую большую NLP конференцию — Диалог, а также создала интернет-корпус русского языка, спонсировала кучу NLP-соревнований и shared tasks, которые распаляли многих проверить свои гипотезы на практике.
Лингвистика разберётся!
Я думаю, текущий вызов даже не самый серьёзный за историю существования кафедры. Да, последние годы приходилось работать под давлением общественного мнения, хайпом LLM...ну так он пройдёт.
Аналитическая, теоретическая лингвистика нужна самой себе и другим наукам:
— как понять и описать происхождение языка,
— как определить биологические ограничения, повлиявшие на язык
— как язык влияет на мышление и обратно,
— как смоделировать максимально общую теоретическую модель языка, описывающую процессы в языках мира,
— как проверить и описать, что находится в корпусе.
Все эти вопросы остаются нужны, и остаются ключевыми вопросами лингвистики.
А языковые модели и NLP потихоньку поглощают уже другие науки:
— OpenAI нанимает филдсевских лауреатов в т ч для составления SFT датасета по математике
— они же нанимают PhD в разных дисциплинах для разметки и валидации данных.
Так что в жернова ИИ пойдут уже выпускники других специальностей. А лингвистика будет заниматься делом.
Please open Telegram to view this post
VIEW IN TELEGRAM
Системный Блокъ
Горький урок ABBYY: как лингвисты проиграли последнюю битву за NLP - Системный Блокъ
Недавно СМИ облетела новость об увольнении всех российских программистов из компании ABBYY (тоже в прошлом российской, а теперь уже совсем нет). Теперь, когда страсти вокруг обсуждения дискриминации сотрудников по паспорту улеглись, хочется поговорить о более…