
Sketch Engine и Маяковский. Часть II: «несоветский» поэт Революции
#knowhow #philology
В прошлой статье о Sketch Engine мы при помощи инструментов «Word Sketch Difference», «Word Sketch» и «Concordance» показали, как человек Маяковского после Революции хоть и стал активным деятелем, но перестал быть личностью. Он стал представителем так называемого массового человека.
Теперь узнаем, что же говорит поэт о Советском государстве и России в целом.
В стране Советов
Обратимся снова к Word Sketch Difference. Выберем режим «Lemma», который поможет нам сравнить контексты двух разных слов. Посмотрим на слова «Россия» и «Совет».
Со словом «Совет» связаны «союз», «федерация», «свобода», «страна», «съезд», «власть», это очень конкретные вещи. А вот «Россия» встречается в более абстрактных контекстах: «сердце России», «снега России», «столпы России (императорской)» и «Встал от сна России труп ― ожила громада, дым дымит с фабричных труб, все творим, что надо». Последнее предложение снова отсылает нас к стране Советов, как к раю всех трудящихся, где нет эксплуатации человека человеком.
«Совет» более обезличен и соседствует с довольно формальными терминами, в то время как «России» соответствуют более одухотворенные, глубокие по смыслу и многозначные зависимые слова.
Мир и человек Маяковского
Теперь с помощью инструмента «Thesaurus», найдем контекстные синонимы для слов «человек» и «страна». «Thesaurus» основан на теории о распределительной семантике: он сравнивает скетчи всех слов той же части речи и оценивает, какие из них встречаются в наибольшем количестве одинаковых словосочетаний в корпусе.
Для леммы «Человек» наиболее близкими синонимами Sketch Engine определил слова «Товарищ», «День», «Год», «Глаз» и «Слово», а для леммы «Страна», казалось бы, синонимичной уже вводившимся ранее «Совету» и «России», самыми близкими контекстными синонимами оказались «Товарищ», «Человек», «Земля» и «Небо».
«Страна», и «Человек» в поэзии Маяковского тесно связаны: не зря у них есть общие синонимы, а синонимы леммы «Страна» вообще отсылают нас к «Человеку». Также образы страны и человека довольно материальны, связаны с чем-то обыденным, земным, явно осязаемым.
Революция и разочарование
С помощью инструмента «Concordance» увидим, что «Революция» у Маяковского не простой «рабочий подвиг», она живая: чего-то требует, зовет, идет по стране, она «всегда молода и готова», ей хочется дать «такие же названия, как любимым в первый день дают».
Восторженные возгласы у Маяковского вызывают исключительно две вещи: это человек во всем его великолепии и при всех его бесконечных возможностях — и Революция. Но после 1917 года на смену восторженности и предвкушению перемен приходит разочарование, и тон автора, авторская позиция меняются.
Инструмент «Wordlist» предлагает пользователю список слов, которые чаще всего встречаются в корпусе. В нашем случае для подкорпуса «До» это слова, которые чаще всего встречаются в философской лирике — «Сердце», «Душа», «Человек», «Небо». В подкорпусе «После» наряду с «Человеком» уже встречаются такие слова, как «Товарищ», «Рабочий», появляется даже образ «Ленина», что свидетельствует о явной острой социальной направленности стиха и близости к традициям гражданской лирики.
Ключевые слова поэзии Маяковского
С помощью инструмента «Keywords» можно извлечь из корпуса ключевые слова — слова, характерные для одного корпуса по сравнению с другим.
Газеты, улицы, аптеки с аптекарями вполне привычны для дореволюционного «адища города», а красное знамя (или флаг), рабочие, крестьяне, товарищи, Ленин, «всё советское» — для послереволюционного творчества Маяковского и в целом для России после 1917 года.
Как до, так и после Революции Маяковского волновали социальная и политическая стороны общественной жизни. Того требовало время. Того требовала и личная позиция Маяковского — поэта-гражданина.
Все технические подробности со скриншотами — в нашей статье: https://sysblok.ru/knowhow/sketch-engine-i-majakovskij-chast-ii-nesovetskij-pojet-revoljucii/
Мария Черных, Дарья Балуева
#knowhow #philology
В прошлой статье о Sketch Engine мы при помощи инструментов «Word Sketch Difference», «Word Sketch» и «Concordance» показали, как человек Маяковского после Революции хоть и стал активным деятелем, но перестал быть личностью. Он стал представителем так называемого массового человека.
Теперь узнаем, что же говорит поэт о Советском государстве и России в целом.
В стране Советов
Обратимся снова к Word Sketch Difference. Выберем режим «Lemma», который поможет нам сравнить контексты двух разных слов. Посмотрим на слова «Россия» и «Совет».
Со словом «Совет» связаны «союз», «федерация», «свобода», «страна», «съезд», «власть», это очень конкретные вещи. А вот «Россия» встречается в более абстрактных контекстах: «сердце России», «снега России», «столпы России (императорской)» и «Встал от сна России труп ― ожила громада, дым дымит с фабричных труб, все творим, что надо». Последнее предложение снова отсылает нас к стране Советов, как к раю всех трудящихся, где нет эксплуатации человека человеком.
«Совет» более обезличен и соседствует с довольно формальными терминами, в то время как «России» соответствуют более одухотворенные, глубокие по смыслу и многозначные зависимые слова.
Мир и человек Маяковского
Теперь с помощью инструмента «Thesaurus», найдем контекстные синонимы для слов «человек» и «страна». «Thesaurus» основан на теории о распределительной семантике: он сравнивает скетчи всех слов той же части речи и оценивает, какие из них встречаются в наибольшем количестве одинаковых словосочетаний в корпусе.
Для леммы «Человек» наиболее близкими синонимами Sketch Engine определил слова «Товарищ», «День», «Год», «Глаз» и «Слово», а для леммы «Страна», казалось бы, синонимичной уже вводившимся ранее «Совету» и «России», самыми близкими контекстными синонимами оказались «Товарищ», «Человек», «Земля» и «Небо».
«Страна», и «Человек» в поэзии Маяковского тесно связаны: не зря у них есть общие синонимы, а синонимы леммы «Страна» вообще отсылают нас к «Человеку». Также образы страны и человека довольно материальны, связаны с чем-то обыденным, земным, явно осязаемым.
Революция и разочарование
С помощью инструмента «Concordance» увидим, что «Революция» у Маяковского не простой «рабочий подвиг», она живая: чего-то требует, зовет, идет по стране, она «всегда молода и готова», ей хочется дать «такие же названия, как любимым в первый день дают».
Восторженные возгласы у Маяковского вызывают исключительно две вещи: это человек во всем его великолепии и при всех его бесконечных возможностях — и Революция. Но после 1917 года на смену восторженности и предвкушению перемен приходит разочарование, и тон автора, авторская позиция меняются.
Инструмент «Wordlist» предлагает пользователю список слов, которые чаще всего встречаются в корпусе. В нашем случае для подкорпуса «До» это слова, которые чаще всего встречаются в философской лирике — «Сердце», «Душа», «Человек», «Небо». В подкорпусе «После» наряду с «Человеком» уже встречаются такие слова, как «Товарищ», «Рабочий», появляется даже образ «Ленина», что свидетельствует о явной острой социальной направленности стиха и близости к традициям гражданской лирики.
Ключевые слова поэзии Маяковского
С помощью инструмента «Keywords» можно извлечь из корпуса ключевые слова — слова, характерные для одного корпуса по сравнению с другим.
Газеты, улицы, аптеки с аптекарями вполне привычны для дореволюционного «адища города», а красное знамя (или флаг), рабочие, крестьяне, товарищи, Ленин, «всё советское» — для послереволюционного творчества Маяковского и в целом для России после 1917 года.
Как до, так и после Революции Маяковского волновали социальная и политическая стороны общественной жизни. Того требовало время. Того требовала и личная позиция Маяковского — поэта-гражданина.
Все технические подробности со скриншотами — в нашей статье: https://sysblok.ru/knowhow/sketch-engine-i-majakovskij-chast-ii-nesovetskij-pojet-revoljucii/
Мария Черных, Дарья Балуева
{kind=link}
TEI: как можно кодировать тексты при оцифровке рукописей
#knowhow #digitalheritage
Сохранение текстов в электронном формате дает много новых возможностей: высокая скорость поиска информации, легкость правки, мультимедиа, гиперссылки. Поэтому появляется все больше проектов по оцифровке текстов из архивных документов, рукописей и древних надписей.
Однако, чтобы при оцифровке не утратить важную информацию, необходимо сохранять тексты со всеми нюансами и разночтениями, а также дополнять метаданными. Для этих целей был создан TEI — Text Encoding Initiative. Это машиночитаемый язык, который упрощает работу с текстом и выделяет необходимую информацию тегами.
На языке TEI можно хранить электронные текстовые источники, сведения об авторе, выходные данные, первоисточники, параметры рукописи, критический аппарат и многое другое.
Как устроен TEI
TEI был разработан в 1987 году, а кодифицирован в 1990-м. Это была попытка создать максимально исчерпывающий инструментарий разметки любых текстов: в нем есть единая система, набор рекомендаций и практик. И в отличие от других форматов, TEI можно обогащать и персонализировать в соответствии со специальными задачами.
Работа TEI основывается на формате кодирования текста XML. Самая главная часть синтаксиса XML — это теги, которые однозначно выделяют некоторые кусочки текста для компьютера. В XML нет готового предзаданного набора тегов: можно ставить свои удобные теги.
Этот формат отличается от других разметок (HTML, TeX) тем, что в XML теги принято использовать для описания содержания, а не внешнего вида или расположения текста. Например, можно описать квартиру или пошаговый рецепт приготовления хлеба. Смысл и интерпретация каждого тега задаются отдельно, то есть при кодировании нет определенного синтаксиса в виде слов.
Одной из особенностей кодирования является избирательность. TEI раскрывает только те особенности текста, которые интересуют кодировщика.
И конечно, кроме разметки самого текста TEI хранит множество мета-информации: время написания, дата публикации, библиография, особенности рукописи, даже гендеры действующих лиц — все это можно закодировать по стандартной процедуре.
О примерах использования TEI — в нашей статье: https://sysblok.ru/digital-heritage/tei-tekstovyj-instrumentarij-kotoryj-smog/
Полина Долгова
#knowhow #digitalheritage
Сохранение текстов в электронном формате дает много новых возможностей: высокая скорость поиска информации, легкость правки, мультимедиа, гиперссылки. Поэтому появляется все больше проектов по оцифровке текстов из архивных документов, рукописей и древних надписей.
Однако, чтобы при оцифровке не утратить важную информацию, необходимо сохранять тексты со всеми нюансами и разночтениями, а также дополнять метаданными. Для этих целей был создан TEI — Text Encoding Initiative. Это машиночитаемый язык, который упрощает работу с текстом и выделяет необходимую информацию тегами.
На языке TEI можно хранить электронные текстовые источники, сведения об авторе, выходные данные, первоисточники, параметры рукописи, критический аппарат и многое другое.
Как устроен TEI
TEI был разработан в 1987 году, а кодифицирован в 1990-м. Это была попытка создать максимально исчерпывающий инструментарий разметки любых текстов: в нем есть единая система, набор рекомендаций и практик. И в отличие от других форматов, TEI можно обогащать и персонализировать в соответствии со специальными задачами.
Работа TEI основывается на формате кодирования текста XML. Самая главная часть синтаксиса XML — это теги, которые однозначно выделяют некоторые кусочки текста для компьютера. В XML нет готового предзаданного набора тегов: можно ставить свои удобные теги.
Этот формат отличается от других разметок (HTML, TeX) тем, что в XML теги принято использовать для описания содержания, а не внешнего вида или расположения текста. Например, можно описать квартиру или пошаговый рецепт приготовления хлеба. Смысл и интерпретация каждого тега задаются отдельно, то есть при кодировании нет определенного синтаксиса в виде слов.
Одной из особенностей кодирования является избирательность. TEI раскрывает только те особенности текста, которые интересуют кодировщика.
И конечно, кроме разметки самого текста TEI хранит множество мета-информации: время написания, дата публикации, библиография, особенности рукописи, даже гендеры действующих лиц — все это можно закодировать по стандартной процедуре.
О примерах использования TEI — в нашей статье: https://sysblok.ru/digital-heritage/tei-tekstovyj-instrumentarij-kotoryj-smog/
Полина Долгова
{kind=link}
Как работают трансформеры — крутейшие нейросети наших дней
#knowhow
Трансформер — самая модная сегодня нейросетевая архитектура. Она появилась в 2017 и перевернула всю обработку языка машинами. Мы расскажем о структуре трансформера без кода — чтобы потом при взгляде на код вы могли понять, что он делает.
Трансформер придумали ученые из Google Research и Google Brain. Целью исследований была обработка естественного языка, но позже другие авторы адаптировали трансформерную архитектуру под любые последовательности. Сегодня если нейросеть распознает или генерирует текст, музыку или голос, скорее всего, где-то замешан трансформер.
В первой части нашей статьи
• Расскажем, что такое «внимание на себя» (self-attention) и зачем нужна нейросеть с прямой связью
• Введем новые термины, которые придумали изобретатели трансформера
• Расскажем подробнее о dot product attention, «скалярном внимании», (обычно это название не переводят).
• Расскажем о том, как из «скалярного внимания» сделать «взвешенное скалярное внимание»
• Объясним, зачем одну и ту же операцию «взвешенного скалярного внимания» повторять несколько раз с разными настройками: так получится описание «multi-head attention» — «многоголового внимания». Именно этот механизм задействован в нейросети-трансформере.
https://sysblok.ru/knowhow/kak-rabotajut-transformery-krutejshie-nejroseti-nashih-dnej/
Во второй части нашей статьи
• Добавим нормализацию;
• Добавим позиционное кодирование (перед самым первым слоем энкодера);
• Разберем устройство декодера, его отличия от энкодера;
• Сравним внимание «на себя» и не на себя;
• Объясним, что является результатом работы нейросети;
• Расскажем, что такое маскировка значений и зачем она нужна;
https://sysblok.ru/knowhow/nejroseti-transformery-iznutri-kak-rabotaet-dekoder/
Владимир Селеверстов
#knowhow
Трансформер — самая модная сегодня нейросетевая архитектура. Она появилась в 2017 и перевернула всю обработку языка машинами. Мы расскажем о структуре трансформера без кода — чтобы потом при взгляде на код вы могли понять, что он делает.
Трансформер придумали ученые из Google Research и Google Brain. Целью исследований была обработка естественного языка, но позже другие авторы адаптировали трансформерную архитектуру под любые последовательности. Сегодня если нейросеть распознает или генерирует текст, музыку или голос, скорее всего, где-то замешан трансформер.
В первой части нашей статьи
• Расскажем, что такое «внимание на себя» (self-attention) и зачем нужна нейросеть с прямой связью
• Введем новые термины, которые придумали изобретатели трансформера
• Расскажем подробнее о dot product attention, «скалярном внимании», (обычно это название не переводят).
• Расскажем о том, как из «скалярного внимания» сделать «взвешенное скалярное внимание»
• Объясним, зачем одну и ту же операцию «взвешенного скалярного внимания» повторять несколько раз с разными настройками: так получится описание «multi-head attention» — «многоголового внимания». Именно этот механизм задействован в нейросети-трансформере.
https://sysblok.ru/knowhow/kak-rabotajut-transformery-krutejshie-nejroseti-nashih-dnej/
Во второй части нашей статьи
• Добавим нормализацию;
• Добавим позиционное кодирование (перед самым первым слоем энкодера);
• Разберем устройство декодера, его отличия от энкодера;
• Сравним внимание «на себя» и не на себя;
• Объясним, что является результатом работы нейросети;
• Расскажем, что такое маскировка значений и зачем она нужна;
https://sysblok.ru/knowhow/nejroseti-transformery-iznutri-kak-rabotaet-dekoder/
Владимир Селеверстов
{kind=link}
Как работает GPT-2 и в чем его особенности
#nlp #knowhow
GPT-2 — нейросеть, которая способна генерировать образцы синтетического текста с вполне логичным повествованием, если задать ей любое начало. Модель учитывает стиль и содержание заданного ей фрагмента и уже на их основании создает свое продолжение истории. На момент релиза в ней было рекордное число параметров — 1,5 млрд против обычных 100–300 млн.
История создания и особенности GPT-2
Первая версия GPT (Generative Pre-trained Transformer) от OpenAI появилась еще летом 2018 года. Ее обучали на выборке текстов из Wikipedia и литературных произведений. Однако выяснилось, что нейросеть быстрее учится понимать естественную речь на основе простых постов в интернете. Поэтому в 2019 году OpenAI обучили GPT на больших объемах текстов — 8 млн. страниц из интернета. Новая версия нейросети получила название GPT-2.
Особенность GPT-2 в том, что она сразу — без дообучения — показала отличные результаты, близкие к state-of-the-art. Сразу после обучения нейросеть уже готова сгенерировать текст со всеми логическими вставками: повторное упоминание имен героев, цитаты, отсылки, выдержка одного стиля на протяжении всего текста, связанное повествование.
Таким образом GPT-2 могла понять суть задания примерно как человек — просто по его виду: если есть пропуски — дописать их, задают вопрос — попытаться ответить и т. д.
Что умеет GPT-2
Помимо простого создания текстов, модель можно использовать для следующих целей:
1. Краткий пересказ текста или обобщение.
В качестве входных данных нужно подать не просто фрагмент, а целый текст, состоящий из хотя бы пары абзацев (но лучше — страниц). Если в конце добавить «TL;DR», модель выдаст краткое содержание рассказа.
2. Ответы на вопросы исходя из содержания текста.
На входе подается несколько примеров в виде «Вопрос-Ответ», в конце же дается реальный вопрос, на который нейросеть выдает по тому же макету ответ.
3. Перевод текстов.
Механизм работы с переводами похож на механизм работы с ответами на вопросы. Главное — подать модели правильное начало, то есть нужную структуру текста. В оригинале GPT-2 подавали фрагменты в виде «hello- = привет» и так далее, используя английский и французский. В итоге, когда в конце была фраза «cat = …», нейросеть, следуя логике, выдала «кошку».
О том, как обучали GPT-2 и почему OpenAI предоставили доступ к его полной версии только через год после создания — читайте в нашей статье: https://sysblok.ru/knowhow/kak-rabotaet-gpt-2-i-v-chem-ego-osobennosti/
Камилла Кубелекова, Владимир Селеверстов
#nlp #knowhow
GPT-2 — нейросеть, которая способна генерировать образцы синтетического текста с вполне логичным повествованием, если задать ей любое начало. Модель учитывает стиль и содержание заданного ей фрагмента и уже на их основании создает свое продолжение истории. На момент релиза в ней было рекордное число параметров — 1,5 млрд против обычных 100–300 млн.
История создания и особенности GPT-2
Первая версия GPT (Generative Pre-trained Transformer) от OpenAI появилась еще летом 2018 года. Ее обучали на выборке текстов из Wikipedia и литературных произведений. Однако выяснилось, что нейросеть быстрее учится понимать естественную речь на основе простых постов в интернете. Поэтому в 2019 году OpenAI обучили GPT на больших объемах текстов — 8 млн. страниц из интернета. Новая версия нейросети получила название GPT-2.
Особенность GPT-2 в том, что она сразу — без дообучения — показала отличные результаты, близкие к state-of-the-art. Сразу после обучения нейросеть уже готова сгенерировать текст со всеми логическими вставками: повторное упоминание имен героев, цитаты, отсылки, выдержка одного стиля на протяжении всего текста, связанное повествование.
Таким образом GPT-2 могла понять суть задания примерно как человек — просто по его виду: если есть пропуски — дописать их, задают вопрос — попытаться ответить и т. д.
Что умеет GPT-2
Помимо простого создания текстов, модель можно использовать для следующих целей:
1. Краткий пересказ текста или обобщение.
В качестве входных данных нужно подать не просто фрагмент, а целый текст, состоящий из хотя бы пары абзацев (но лучше — страниц). Если в конце добавить «TL;DR», модель выдаст краткое содержание рассказа.
2. Ответы на вопросы исходя из содержания текста.
На входе подается несколько примеров в виде «Вопрос-Ответ», в конце же дается реальный вопрос, на который нейросеть выдает по тому же макету ответ.
3. Перевод текстов.
Механизм работы с переводами похож на механизм работы с ответами на вопросы. Главное — подать модели правильное начало, то есть нужную структуру текста. В оригинале GPT-2 подавали фрагменты в виде «hello- = привет» и так далее, используя английский и французский. В итоге, когда в конце была фраза «cat = …», нейросеть, следуя логике, выдала «кошку».
О том, как обучали GPT-2 и почему OpenAI предоставили доступ к его полной версии только через год после создания — читайте в нашей статье: https://sysblok.ru/knowhow/kak-rabotaet-gpt-2-i-v-chem-ego-osobennosti/
Камилла Кубелекова, Владимир Селеверстов
{kind=link}
Редакционное расстояние: что это и где используется
#knowhow #glossary
Чаще всего редакционное расстояние (edit distance) применяется в компьютерной лингвистике и биоинформатике. В этих областях нередко возникают задачи, когда надо понять, насколько две строки формально близки. То есть редакционные расстояния говорят не о смысловой близости слов или предложений, а только о близости их формы.
Как вычислить редакционное расстояние
Чтобы узнать редакционное расстояние между двумя строками, нужно посчитать минимальное количество посимвольных операций, которые нужно сделать, чтобы превратить первую строку во вторую. Таких операций всего четыре:
• удаление
• вставка
• замена
• перестановка соседних символов.
В операции может участвовать только один символ в строке. Количество операций — это и есть редакционное расстояние между двумя строками. Простейший пример: чтобы превратить «сон» в «слон», нужно произвести одну операцию: вставить букву «л» после «с».
Виды редакционных расстояний
Есть несколько основных редакционных расстояний. Основное отличие между ними — набор операций, который разрешено использовать. Расстояние Хэмминга разрешает только замены. Расстояние Джаро-Винклера — только перестановки.
Одно из самых известных редакционных расстояний — расстояние Левенштейна, которое разрешает все операции, кроме перестановки.
Попробуем посчитать расстояние Левенштейна между словами «карета» и «ракета». Чтобы превратить карету в ракету, нужно:
1) поменять первую букву — «к» на «р», после этой операции штраф равен 1, и у нас есть слово «какета»
2) поменять третью букву — «р» на «к», после этой операции штраф равен 2, и мы получили нужное слово «ракета».
Расстояние Левенштейна между словами «карета» и «ракета» равно двум.
А расстояние Дамерау-Левенштейна разрешает все четыре операции: замену, вставку, удаление и перестановку соседних символов.
Иногда измеряют пословное расстояние Левенштейна — при таком подходе за единицу принимается не один символ, а одно слово. Тогда между предложениями «Я люблю лингвистику» и «Я люблю компьютерную лингвистику» расстояние будет равно 1, а не 14, как было бы в случае посимвольных операций.
Мы также можем давать разный штраф за разные операции. Например, решить, что мы очень не любим замены символов и давать за них не 1, а 2 балла. В этом случае говорят, что операции имеют разный вес, и называют полученный результат взвешенным расстоянием Левенштейна.
Где применяют редакционное расстояние
В компьютерной лингвистике возникает множество задач, где нужно посчитать формальную меру близости между строками: например, для проверки орфографии, или для сравнения, насколько похожи два предложения. Первые системы автоматической проверки орфографии фактически сводились к подсчету редакционного расстояния Левенштейна или Дамерау-Левенштейна с использованием сложной системы штрафов. Система шла от слова к слову и проверяла, есть ли такое слово в словаре, а когда встречала слово, которого нет в словаре, то пыталась заменить его на наиболее близкое по редакционному расстоянию слово из словаря. Сейчас расстояние Левенштейна редко используется как единственный признак близости, но очень часто как один из.
В биоинформатике редакционные расстояния используются для определения похожести друг на друга разных участков ДНК или РНК, которые в таком случае представляются как последовательность, состоящая из A, G, C, U и T — это первые буквы четырех азотистых основания, которые могут входить в состав ДНК или РНК: аденин, гуанин и цитозин, урацил и тимин.
Бывают и неочевидные применения, например, определение, на что больше похожа буква на нечеткой фотографии текста, на «Л» или «П». В таком случае буквы представляют как стоящие друг над другом строки, состоящие из черных и белых пикселей.
https://sysblok.ru/knowhow/chto-takoe-redakcionnoe-rasstojanie/
https://sysblok.ru/glossary/rasstojanie-levenshtejna/
Ася Ройтберг
#knowhow #glossary
Чаще всего редакционное расстояние (edit distance) применяется в компьютерной лингвистике и биоинформатике. В этих областях нередко возникают задачи, когда надо понять, насколько две строки формально близки. То есть редакционные расстояния говорят не о смысловой близости слов или предложений, а только о близости их формы.
Как вычислить редакционное расстояние
Чтобы узнать редакционное расстояние между двумя строками, нужно посчитать минимальное количество посимвольных операций, которые нужно сделать, чтобы превратить первую строку во вторую. Таких операций всего четыре:
• удаление
• вставка
• замена
• перестановка соседних символов.
В операции может участвовать только один символ в строке. Количество операций — это и есть редакционное расстояние между двумя строками. Простейший пример: чтобы превратить «сон» в «слон», нужно произвести одну операцию: вставить букву «л» после «с».
Виды редакционных расстояний
Есть несколько основных редакционных расстояний. Основное отличие между ними — набор операций, который разрешено использовать. Расстояние Хэмминга разрешает только замены. Расстояние Джаро-Винклера — только перестановки.
Одно из самых известных редакционных расстояний — расстояние Левенштейна, которое разрешает все операции, кроме перестановки.
Попробуем посчитать расстояние Левенштейна между словами «карета» и «ракета». Чтобы превратить карету в ракету, нужно:
1) поменять первую букву — «к» на «р», после этой операции штраф равен 1, и у нас есть слово «какета»
2) поменять третью букву — «р» на «к», после этой операции штраф равен 2, и мы получили нужное слово «ракета».
Расстояние Левенштейна между словами «карета» и «ракета» равно двум.
А расстояние Дамерау-Левенштейна разрешает все четыре операции: замену, вставку, удаление и перестановку соседних символов.
Иногда измеряют пословное расстояние Левенштейна — при таком подходе за единицу принимается не один символ, а одно слово. Тогда между предложениями «Я люблю лингвистику» и «Я люблю компьютерную лингвистику» расстояние будет равно 1, а не 14, как было бы в случае посимвольных операций.
Мы также можем давать разный штраф за разные операции. Например, решить, что мы очень не любим замены символов и давать за них не 1, а 2 балла. В этом случае говорят, что операции имеют разный вес, и называют полученный результат взвешенным расстоянием Левенштейна.
Где применяют редакционное расстояние
В компьютерной лингвистике возникает множество задач, где нужно посчитать формальную меру близости между строками: например, для проверки орфографии, или для сравнения, насколько похожи два предложения. Первые системы автоматической проверки орфографии фактически сводились к подсчету редакционного расстояния Левенштейна или Дамерау-Левенштейна с использованием сложной системы штрафов. Система шла от слова к слову и проверяла, есть ли такое слово в словаре, а когда встречала слово, которого нет в словаре, то пыталась заменить его на наиболее близкое по редакционному расстоянию слово из словаря. Сейчас расстояние Левенштейна редко используется как единственный признак близости, но очень часто как один из.
В биоинформатике редакционные расстояния используются для определения похожести друг на друга разных участков ДНК или РНК, которые в таком случае представляются как последовательность, состоящая из A, G, C, U и T — это первые буквы четырех азотистых основания, которые могут входить в состав ДНК или РНК: аденин, гуанин и цитозин, урацил и тимин.
Бывают и неочевидные применения, например, определение, на что больше похожа буква на нечеткой фотографии текста, на «Л» или «П». В таком случае буквы представляют как стоящие друг над другом строки, состоящие из черных и белых пикселей.
https://sysblok.ru/knowhow/chto-takoe-redakcionnoe-rasstojanie/
https://sysblok.ru/glossary/rasstojanie-levenshtejna/
Ася Ройтберг
{kind=link}
Определяем дату написания картины онлайн
#knowhow #research
Когда цифровизация стала глобальным трендом, в открытом доступе появились тематические датасеты, которые состоят из десятков тысяч картин различных авторов и эпох. Работая с такими датасетами, можно генерировать дополнительные метаданные — в нашем случаем это возраст изображений, тем самым автоматизируя работу искусствоведов.
Возможность определять возраст или стиль изображений полезна не только искусствоведам и коллекционерам. С помощью этого инструмента можно изучать тенденции современного искусства и выявлять закономерности, которые позволяют понять, к стилю какой из эпох более всего склонен автор.
Задача и стратегии ее решения
Ключевая фигура в решении задачи — сверточная нейронная сеть для выделения признаков на изображениях. Рассматривались архитектуры ResNet18 и VGG-19, однако последняя дала лучшие результаты.
Если не углубляться в теоретические основы глубокого обучения, то сверточные сети можно описать как алгоритм последовательного сжатия изображений, который способен выделять их ключевые особенности на разных уровнях абстракции (подробнее можно почитать на хабре).
Примененив сверточную сеть с обрезанными полносвязными слоями, мы вычисляем матрицу Грама, а также применяем классификацию или регрессию. В нашем случае в роли модели классификатора выступает SVM.
Матрица Грама является специальным представлением изображения — это матрица попарных скалярных произведения численного значения пикселей. Её использование позволяет конвертировать преобразованную сверточной сетью картину в формат, удобный для определения стиля. Матрица Грама сглаживает пространственную структуру, позволяя получить больше информации о текстуре изображения, чем о присутствующих на ней конкретных объектах.
В итоге оказалось, что наилучший MSE даёт VGG-19, а лучшее значение F1-меры достигается той же сетью с батч-нормализацией. Использование F1 в данной задаче обусловлено отсутствием в выбранном датасете баланса классов, каждый из которых представлял собой временной промежуток в 50 лет. Применение этой метрики позволяет более объективно оценить качество моделей.
Результаты и их интерпретация
Использование матрицы Грама позволило почти в два раза улучшить качество моделей на представленном датасете. Для многих классов ошибочных классификаций совсем немного.
Однако использование информации о стиле для определения временного отрезка гарантированно работает только для эпохи премодерна, которой характерно последовательное совершенствование техник изобразительного искусства.
Наш небольшой эксперимент показал, что задача определения возраста картины может быть решена посредством использования методов искусственного интеллекта. Следующий этап — увеличение количества данных, усложнение модели, масштабирование задачи на XX и XXI века, а также увеличение количества временных промежутков.
Код проекта можно найти на github.
Модель работает онлайн — протестировать можно здесь.
https://sysblok.ru/knowhow/opredeljaem-datu-napisanija-kartiny-onlajn-bez-registracii-i-sms/
Дарья Петрова, Вадим Порватов, Валерий Покровский
#knowhow #research
Когда цифровизация стала глобальным трендом, в открытом доступе появились тематические датасеты, которые состоят из десятков тысяч картин различных авторов и эпох. Работая с такими датасетами, можно генерировать дополнительные метаданные — в нашем случаем это возраст изображений, тем самым автоматизируя работу искусствоведов.
Возможность определять возраст или стиль изображений полезна не только искусствоведам и коллекционерам. С помощью этого инструмента можно изучать тенденции современного искусства и выявлять закономерности, которые позволяют понять, к стилю какой из эпох более всего склонен автор.
Задача и стратегии ее решения
Ключевая фигура в решении задачи — сверточная нейронная сеть для выделения признаков на изображениях. Рассматривались архитектуры ResNet18 и VGG-19, однако последняя дала лучшие результаты.
Если не углубляться в теоретические основы глубокого обучения, то сверточные сети можно описать как алгоритм последовательного сжатия изображений, который способен выделять их ключевые особенности на разных уровнях абстракции (подробнее можно почитать на хабре).
Примененив сверточную сеть с обрезанными полносвязными слоями, мы вычисляем матрицу Грама, а также применяем классификацию или регрессию. В нашем случае в роли модели классификатора выступает SVM.
Матрица Грама является специальным представлением изображения — это матрица попарных скалярных произведения численного значения пикселей. Её использование позволяет конвертировать преобразованную сверточной сетью картину в формат, удобный для определения стиля. Матрица Грама сглаживает пространственную структуру, позволяя получить больше информации о текстуре изображения, чем о присутствующих на ней конкретных объектах.
В итоге оказалось, что наилучший MSE даёт VGG-19, а лучшее значение F1-меры достигается той же сетью с батч-нормализацией. Использование F1 в данной задаче обусловлено отсутствием в выбранном датасете баланса классов, каждый из которых представлял собой временной промежуток в 50 лет. Применение этой метрики позволяет более объективно оценить качество моделей.
Результаты и их интерпретация
Использование матрицы Грама позволило почти в два раза улучшить качество моделей на представленном датасете. Для многих классов ошибочных классификаций совсем немного.
Однако использование информации о стиле для определения временного отрезка гарантированно работает только для эпохи премодерна, которой характерно последовательное совершенствование техник изобразительного искусства.
Наш небольшой эксперимент показал, что задача определения возраста картины может быть решена посредством использования методов искусственного интеллекта. Следующий этап — увеличение количества данных, усложнение модели, масштабирование задачи на XX и XXI века, а также увеличение количества временных промежутков.
Код проекта можно найти на github.
Модель работает онлайн — протестировать можно здесь.
https://sysblok.ru/knowhow/opredeljaem-datu-napisanija-kartiny-onlajn-bez-registracii-i-sms/
Дарья Петрова, Вадим Порватов, Валерий Покровский
{kind=link}
Как нейросеть реставрирует старые советские мультфильмы
#arts #knowhow
Главная проблема старых мультфильмов — низкое разрешение видеозаписи. Нейросеть DeepHD увеличивает изображение и делает его четким. Программа работает не только со старыми пленками, но и с прямыми трансляциями. Задача алгоритма — убрать шумы и искажения, которые возникают в процессе передачи или сжатия картинки.
Работа нейросети
Технология состоит из двух этапов:
• устранение помех — восстановление деталей.
• увеличение изображения — преобразование картинки в карты признаков и уменьшение расстояния между ними.
Программу обучали на картинках высокого качества, которые уменьшали для приближения к действительности. После обработки «дискриминатор» проверял достоверность исходного и улучшенного изображений. Если «подделку» было трудно отличить от «подлинника», результат работы нейросети считался положительным. С помощью новых датасетов, программа научилась различать объекты различных размеров и качеств.
DeepHD в кино
В мае 2018 года нейросеть испытали на нескольких советских фильмах: «Летят журавли», «Судьба человека», «Иваново детство» и др. У героев фильмов улучшились мимика и фактура одежды, исчезли пересветы.
С помощью технологии также улучшили 10 анимационных лент «Союзмультфильма»: «Котенок по имени Гав», «Дюймовочка», «Аленький цветочек» и др. Персонажи стали четче, повысилось качество фонов, вернулись детали, пропавшие при оцифровке. Все картины можно посмотреть на «КиноПоиске».
Альтернативные способы реставрации
Реставраторы-любители считают, что можно обойтись и без DeepHD. Вначале исходник, оцифрованный в Adobe Premier, разбивают на куски. После поправляют цвет, повышают резкость и убирают шумы. Это можно сделать с помощью программ Conbustion или VirtualDubMod. Восстановление займет много времени, но результат будет похож на DeepHD.
https://sysblok.ru/arts/vozvrashhenie-chetkogo-popugaja-kak-nejroset-restavriruet-starye-sovetskie-multfilmy/
Варвара Гузий
#arts #knowhow
Главная проблема старых мультфильмов — низкое разрешение видеозаписи. Нейросеть DeepHD увеличивает изображение и делает его четким. Программа работает не только со старыми пленками, но и с прямыми трансляциями. Задача алгоритма — убрать шумы и искажения, которые возникают в процессе передачи или сжатия картинки.
Работа нейросети
Технология состоит из двух этапов:
• устранение помех — восстановление деталей.
• увеличение изображения — преобразование картинки в карты признаков и уменьшение расстояния между ними.
Программу обучали на картинках высокого качества, которые уменьшали для приближения к действительности. После обработки «дискриминатор» проверял достоверность исходного и улучшенного изображений. Если «подделку» было трудно отличить от «подлинника», результат работы нейросети считался положительным. С помощью новых датасетов, программа научилась различать объекты различных размеров и качеств.
DeepHD в кино
В мае 2018 года нейросеть испытали на нескольких советских фильмах: «Летят журавли», «Судьба человека», «Иваново детство» и др. У героев фильмов улучшились мимика и фактура одежды, исчезли пересветы.
С помощью технологии также улучшили 10 анимационных лент «Союзмультфильма»: «Котенок по имени Гав», «Дюймовочка», «Аленький цветочек» и др. Персонажи стали четче, повысилось качество фонов, вернулись детали, пропавшие при оцифровке. Все картины можно посмотреть на «КиноПоиске».
Альтернативные способы реставрации
Реставраторы-любители считают, что можно обойтись и без DeepHD. Вначале исходник, оцифрованный в Adobe Premier, разбивают на куски. После поправляют цвет, повышают резкость и убирают шумы. Это можно сделать с помощью программ Conbustion или VirtualDubMod. Восстановление займет много времени, но результат будет похож на DeepHD.
https://sysblok.ru/arts/vozvrashhenie-chetkogo-popugaja-kak-nejroset-restavriruet-starye-sovetskie-multfilmy/
Варвара Гузий
YouTube
Хиты «Союзмультфильма» в DeepHD
Вам всегда хотелось рассмотреть наряд Снежной Королевы и живность в «Путешествии муравья» во всех подробностях? Теперь это возможно: в Яндексе появилась собственная технология DeepHD, улучшающая изображения и видео при помощи искусственного интеллекта.
Смотрите…
Смотрите…
Как нейросеть заменяет нецензурную лексику на эвфемизмы
#knowhow #nlp
Машинное обучение разрешает менять стилистику текста без изменения содержания. Например, нейросеть сгенерировала песни в стиле Егора Летова, а также ведет аккаунт Neural Meduza в Twitter`е. Однако методы генерации и стилизации текстов приносят и практическую пользу.
ВКонтакте фильтрует комментарии
ВКонтакте тестирует новые функции: сервис учится фильтровать оскорбительные комментарии в сообществах, а также предупреждать пользователей о неприемлемом тоне высказываний. Так как диаметральная смена окраски комментариев — это нарушение свободы слова, нашли полумеру: нецензурная лексика будет заменяться эвфемизмами, а остальные высказывания — «сглаживаться».
Перенос стиля: как это работает
Перенос стиля основан на изменении векторных представлений текстов. Мы уже рассказывали, как создаются такие вектора.
Чтобы научиться переносить стиль текста, потребуется:
1. два корпуса текстов с противоположными стилями: положительный и отрицательный, токсичный и обычный и т.д.
2. автокодировщик, который нужно обучить тому, как представлять тексты в виде векторов
Алгоритм следующий:
1. обучаем кодировщик на обоих корпусах
2. получаем векторные представления текстов стиля 1
3. изменяем полученные вектора в соответствии с векторами текста стиля 2
4. подаем измененные вектора на вход декодировщику
5. получаем тексты стиля 2
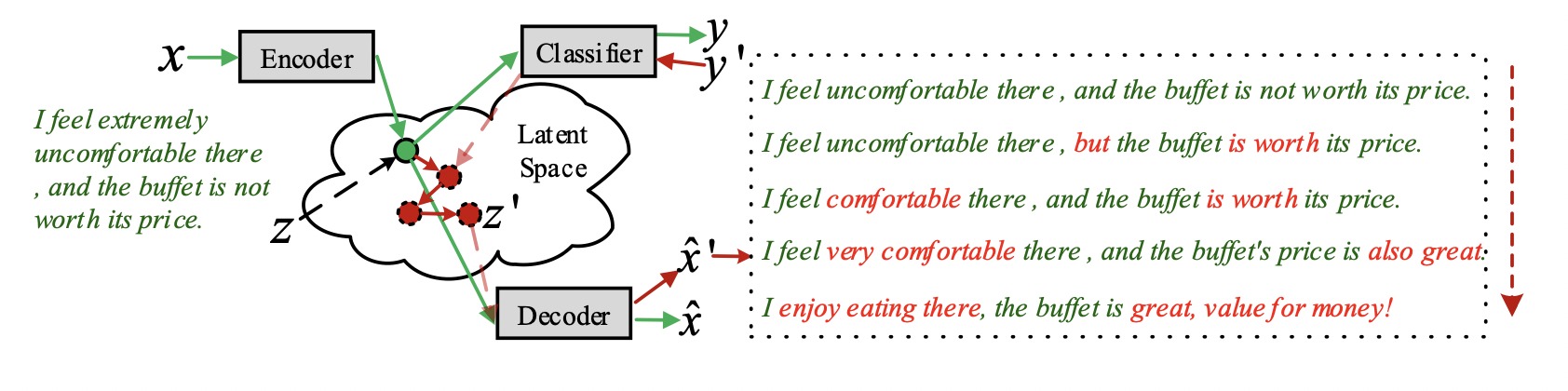
Основная задача — изменить векторы так, чтобы на выходе получился текст нужного стиля. Для этого берем векторные представления текстов для обоих корпусов и обучаем на них новую нейронную сеть определять стиль текста. После обучения пытаемся её обмануть: берём вектор текста стиля 1 и добавляем шум. Шум подбираем таким образом, чтобы нейросеть перепутала стиль и на выходе мы получили текст стиля 2.
Альтернативное решение
Есть более сложный и продвинутый метод, который позволяет менять стиль и содержание текста независимо друг от друга. В этом случае вся информация о стиле содержится в одной части вектора, а информация о содержании — в другой.
https://sysblok.ru/knowhow/v-prostranstve-tekstov-detoksikacija-kommentariev-poddelka-otzyvov-i-nejrocenzura/
Михаил Ким
#knowhow #nlp
Машинное обучение разрешает менять стилистику текста без изменения содержания. Например, нейросеть сгенерировала песни в стиле Егора Летова, а также ведет аккаунт Neural Meduza в Twitter`е. Однако методы генерации и стилизации текстов приносят и практическую пользу.
ВКонтакте фильтрует комментарии
ВКонтакте тестирует новые функции: сервис учится фильтровать оскорбительные комментарии в сообществах, а также предупреждать пользователей о неприемлемом тоне высказываний. Так как диаметральная смена окраски комментариев — это нарушение свободы слова, нашли полумеру: нецензурная лексика будет заменяться эвфемизмами, а остальные высказывания — «сглаживаться».
Перенос стиля: как это работает
Перенос стиля основан на изменении векторных представлений текстов. Мы уже рассказывали, как создаются такие вектора.
Чтобы научиться переносить стиль текста, потребуется:
1. два корпуса текстов с противоположными стилями: положительный и отрицательный, токсичный и обычный и т.д.
2. автокодировщик, который нужно обучить тому, как представлять тексты в виде векторов
Алгоритм следующий:
1. обучаем кодировщик на обоих корпусах
2. получаем векторные представления текстов стиля 1
3. изменяем полученные вектора в соответствии с векторами текста стиля 2
4. подаем измененные вектора на вход декодировщику
5. получаем тексты стиля 2
Основная задача — изменить векторы так, чтобы на выходе получился текст нужного стиля. Для этого берем векторные представления текстов для обоих корпусов и обучаем на них новую нейронную сеть определять стиль текста. После обучения пытаемся её обмануть: берём вектор текста стиля 1 и добавляем шум. Шум подбираем таким образом, чтобы нейросеть перепутала стиль и на выходе мы получили текст стиля 2.
Альтернативное решение
Есть более сложный и продвинутый метод, который позволяет менять стиль и содержание текста независимо друг от друга. В этом случае вся информация о стиле содержится в одной части вектора, а информация о содержании — в другой.
https://sysblok.ru/knowhow/v-prostranstve-tekstov-detoksikacija-kommentariev-poddelka-otzyvov-i-nejrocenzura/
Михаил Ким
{kind=link}
Transkribus: как компьютерное зрение помогает переводить тексты сирийских мистиков
#digitalheritage #knowhow
Transkribus — платформа для оцифровки и распознавания текста на основе технологии HTR (Handwritten Text Recognition), которая позволяет обучать специальные модули распознавания текста. Обученные модули способны распознавать рукописные, машинописные и печатные документы на самых разных языках.
Например, на классическом сирийском — главном языке восточного христианства. К сожалению, пласт текстов так и остался неизученным: сюда относится всемирная хроника Йоханнана бар Пенкайе. В издании 300 рукописных страниц — все нужно набрать вручную, а это долго и требует постоянной высокой концентрации внимания. Transkribus ускорил процесс.
Обучение нейросети
• сбор необходимого количества данных для модуля — для Transkribus это 80 страниц. Язык или тип письменности не важны.
• распознавание почерка — программу тренируют на собранных данных. Чем их больше, тем точнее будет работать модуль.
• сравнение транскрипций — программа сравнивает первоначально распозанный текст с правильной отредактированной версией.
Ошибки Transkribus
После тренировки модуля эффективность оценивается на тестовом образце. Она оценивается по проценту ошибочных символов. Модули, которые распознают тексты с ошибочностью менее 10%, считаются эффективными.
Три условия для хорошей работы модуля:
• хорошее качество транскрипции, которую вы производили, когда обучали модуль;
• аккуратность/неаккуратность почерка;
• хорошая сохранность рукописи (высокое разрешение и контрастность отсканированного изображения).
Сирийские средневековые рукописи писались профессиональными писцами, в них мало индивидуальных особенностей и не отличаются почерки. С таким материалом Transkribus справляется точнее и лучше.
Функции платформы
Разработчики платформы говорят, что существует 70 публичных модулей и 8 400 частных. Среди них есть и сирийские модули , разработанные Beth Mardutho — организацией, занимающейся изучением сирийского наследия. Для разных видов сирийского письма — серто, эстрангело, восточносирийское — сделаны отдельные модули.
С помощью платформы можно массово детализировать рукописи и создавать корпуса: функционирует поиск по ключевым словам или по регулярным фрагментам в уже распознанном тексте. Transkribus способен распознавать и оцифровывать тексты на языках, относящимся к историческим периодам, что делает нейросеть полезной для пользователей.
https://sysblok.ru/digital-heritage/transkribus-kak-kompjuternoe-zrenie-pomogaet-perevodit-teksty-sirijskih-mistikov/
Ксения Костомарова
#digitalheritage #knowhow
Transkribus — платформа для оцифровки и распознавания текста на основе технологии HTR (Handwritten Text Recognition), которая позволяет обучать специальные модули распознавания текста. Обученные модули способны распознавать рукописные, машинописные и печатные документы на самых разных языках.
Например, на классическом сирийском — главном языке восточного христианства. К сожалению, пласт текстов так и остался неизученным: сюда относится всемирная хроника Йоханнана бар Пенкайе. В издании 300 рукописных страниц — все нужно набрать вручную, а это долго и требует постоянной высокой концентрации внимания. Transkribus ускорил процесс.
Обучение нейросети
• сбор необходимого количества данных для модуля — для Transkribus это 80 страниц. Язык или тип письменности не важны.
• распознавание почерка — программу тренируют на собранных данных. Чем их больше, тем точнее будет работать модуль.
• сравнение транскрипций — программа сравнивает первоначально распозанный текст с правильной отредактированной версией.
Ошибки Transkribus
После тренировки модуля эффективность оценивается на тестовом образце. Она оценивается по проценту ошибочных символов. Модули, которые распознают тексты с ошибочностью менее 10%, считаются эффективными.
Три условия для хорошей работы модуля:
• хорошее качество транскрипции, которую вы производили, когда обучали модуль;
• аккуратность/неаккуратность почерка;
• хорошая сохранность рукописи (высокое разрешение и контрастность отсканированного изображения).
Сирийские средневековые рукописи писались профессиональными писцами, в них мало индивидуальных особенностей и не отличаются почерки. С таким материалом Transkribus справляется точнее и лучше.
Функции платформы
Разработчики платформы говорят, что существует 70 публичных модулей и 8 400 частных. Среди них есть и сирийские модули , разработанные Beth Mardutho — организацией, занимающейся изучением сирийского наследия. Для разных видов сирийского письма — серто, эстрангело, восточносирийское — сделаны отдельные модули.
С помощью платформы можно массово детализировать рукописи и создавать корпуса: функционирует поиск по ключевым словам или по регулярным фрагментам в уже распознанном тексте. Transkribus способен распознавать и оцифровывать тексты на языках, относящимся к историческим периодам, что делает нейросеть полезной для пользователей.
https://sysblok.ru/digital-heritage/transkribus-kak-kompjuternoe-zrenie-pomogaet-perevodit-teksty-sirijskih-mistikov/
Ксения Костомарова
Системный Блокъ
Transkribus: как компьютерное зрение помогает переводить тексты сирийских мистиков
Чтобы разобрать написанное, часто нужен натренированный глаз. Добиться этого можно двумя способами: тренировать собственное зрение или компьютерное. Как и зачем тренируют модели распознавания рукописного текста — рассказываем в нашем материале
Как работает BERT
#knowhow #nlp
BERT или Bidirectional Encoder Representations from Transformers — это нейросетевая модель-трансформер от Google, на которой строится большинство инструментов автоматической обработки языка. Код модели выложен в открытый доступ. Саму нейросеть можно запустить как на локальном компьютере, так и на бесплатном серверном GPU на Google Colab.
Эмбеддинги и бенчмарки
Языковая модель работает с текстом, но для компьютера текст сам по себе ничего не значит. Чтобы закодировать текст в осмысленные числа, люди придумали векторные представления слов, которые основаны на контекстах употребления этих слов. Такие векторные представления называются эмбеддинги. Они кодируют семантические близости слов, причем с учетом контекста конкретного предложения.
Языковая модель принимает на вход эмбеддинги токенов и выдает результат в зависимости от задачи: стандартный набор задач, который выполняют на стандартном наборе данных, чтобы доказать, что нейросеть справляется с пониманием текста. Стандартные задачи называются в NLP бенчмарками («ориентир», «отметка» по-английски). BERT тестировали на наборах бенчмарков GLUE — «Оценка общего
понимания языка», SQuAD и SWAG.
Обучение нейросети
В зависимости от конечной цели используют либо машинное обучение с учителем (supervised learning), либо без него (unsupervised learning).
Для сложных нейросетей используют процессы «предобучения» и «дообучения». В первом методе нейросеть прогоняют на больших объемах текстов. Во втором – обнуляют финальный слой весов и тренируют модель на новом наборе данных.
Обучение BERT
Новшество BERTа — в способе предобучения. Ранние архитектуры, чтобы обучиться, предсказывали, какое слово вероятнее будет стоять следующим, учитывая слова до него. BERT же предобучается на «маскированной языковой модели»: нужно предсказать слово не в конце предложения, а посередине. Главная задача — угадать, какие слова пропущены (выдать числовой код) и сказать, подходит ли второе предложение к первому.
Для дообучения (файнтьюнинга) в BERT не нужно стирать «часть памяти» модели. Вместо этого «поверх» модели добавляют новый слой нейронов. Его матрицы весов заполнены случайными числами, которые настраивают так, чтобы на новой задаче ошибка была минимальной.
BERT используется в Google: поначалу эта модель работала только для английского языка, позже добавили в поиск и на других языках. Нейросеть можно использовать для модерации текстов, поиска ответов на юридические вопросы, оптимизации работы с SEO-сайтами. Кроме того, практически половина NLP использует BERT и BERT-подобные архитектуры.
https://sysblok.ru/knowhow/kak-ustroena-nejroset-bert-ot-google/
Камилла Кубелекова, Владимир Селеверстов
#knowhow #nlp
BERT или Bidirectional Encoder Representations from Transformers — это нейросетевая модель-трансформер от Google, на которой строится большинство инструментов автоматической обработки языка. Код модели выложен в открытый доступ. Саму нейросеть можно запустить как на локальном компьютере, так и на бесплатном серверном GPU на Google Colab.
Эмбеддинги и бенчмарки
Языковая модель работает с текстом, но для компьютера текст сам по себе ничего не значит. Чтобы закодировать текст в осмысленные числа, люди придумали векторные представления слов, которые основаны на контекстах употребления этих слов. Такие векторные представления называются эмбеддинги. Они кодируют семантические близости слов, причем с учетом контекста конкретного предложения.
Языковая модель принимает на вход эмбеддинги токенов и выдает результат в зависимости от задачи: стандартный набор задач, который выполняют на стандартном наборе данных, чтобы доказать, что нейросеть справляется с пониманием текста. Стандартные задачи называются в NLP бенчмарками («ориентир», «отметка» по-английски). BERT тестировали на наборах бенчмарков GLUE — «Оценка общего
понимания языка», SQuAD и SWAG.
Обучение нейросети
В зависимости от конечной цели используют либо машинное обучение с учителем (supervised learning), либо без него (unsupervised learning).
Для сложных нейросетей используют процессы «предобучения» и «дообучения». В первом методе нейросеть прогоняют на больших объемах текстов. Во втором – обнуляют финальный слой весов и тренируют модель на новом наборе данных.
Обучение BERT
Новшество BERTа — в способе предобучения. Ранние архитектуры, чтобы обучиться, предсказывали, какое слово вероятнее будет стоять следующим, учитывая слова до него. BERT же предобучается на «маскированной языковой модели»: нужно предсказать слово не в конце предложения, а посередине. Главная задача — угадать, какие слова пропущены (выдать числовой код) и сказать, подходит ли второе предложение к первому.
Для дообучения (файнтьюнинга) в BERT не нужно стирать «часть памяти» модели. Вместо этого «поверх» модели добавляют новый слой нейронов. Его матрицы весов заполнены случайными числами, которые настраивают так, чтобы на новой задаче ошибка была минимальной.
BERT используется в Google: поначалу эта модель работала только для английского языка, позже добавили в поиск и на других языках. Нейросеть можно использовать для модерации текстов, поиска ответов на юридические вопросы, оптимизации работы с SEO-сайтами. Кроме того, практически половина NLP использует BERT и BERT-подобные архитектуры.
https://sysblok.ru/knowhow/kak-ustroena-nejroset-bert-ot-google/
Камилла Кубелекова, Владимир Селеверстов
{kind=link}