
Поясни за смайлик: смех и слезы в интернете
#philology
Рассказываем, как люди начали пользоваться эмотиконами и как теперь их семантику изучают компьютерными методами. Посвящается тем, кто хотя бы раз не понял, что означает сообщение со смайликом.
В письменной речи смайлики — главный способ выражения эмоций: они заменяют интонацию и жесты; могут выступать в качестве слов или выражать отношение говорящего к ситуации.
Смайлики не всегда легко проинтерпретировать, однако и со словами может возникнуть та же проблема. Чтобы понять значение слова, мы обычно смотрим на контекст. Со смайликами этот метод тоже работает. Если контекст не помогает, можно обратиться к словарю.
Разработчики Unicode создали настоящий словарь с описаниями изображений, но вряд ли люди туда часто заглядывают, потому что у смайликов есть преимущество перед словами — визуальная информация. Глядя на слово, мы понимаем его значение, потому что оно уже хранится у нас в голове, а картинку мы сравниваем с образами из повседневной жизни и поэтому можем угадать значение по визуальному сходству.
Цифровые исследования семантики смайликов
Специалисты в области NLP используют эти идеи для переноса значения смайликов в машиночитаемый формат. Ученые уже давно пользуются моделями, которые переводят слово в вектор его контекста, то есть совместной встречаемости с другими словами. Word2vec — одна из самых популярных моделей такого типа, основанная на нейросетевых технологиях. Используемый в ней алгоритм Skip-Gram пытается предсказать контекст справа и слева по центральному слову.
Впервые анализ эмодзи провели в 2015 году. Томас Димсон, один из разработчиков Инстаграма, обучил word2vec на выборке в 50 млн комментариев и поделился результатами с пользователями. Оказалось, что самые популярные эмодзи довольно устойчиво ассоциируются с тем, что они изображают. Так, флаги стран соотносятся с хэштегами, содержащими их названия, а смеющиеся смайлики — с сокращениями ‘lol’, ‘lmao’ и различными вариациями смеха. Подробнее об этом исследовании — в нашей статье.
Чуть позже вышла статья группы испанских ученых под руководством Франческо Барбери. Ученые представили модель, обученную на текстах англоязычного Твиттера, и проанализировали результаты ее работы. Для оценки близости смайликов были предложены два критерия:
1. сходство (можно ли заменить один смайлик другим);
2. соотнесенность (можно ли встретить эти смайлики в одном контексте).
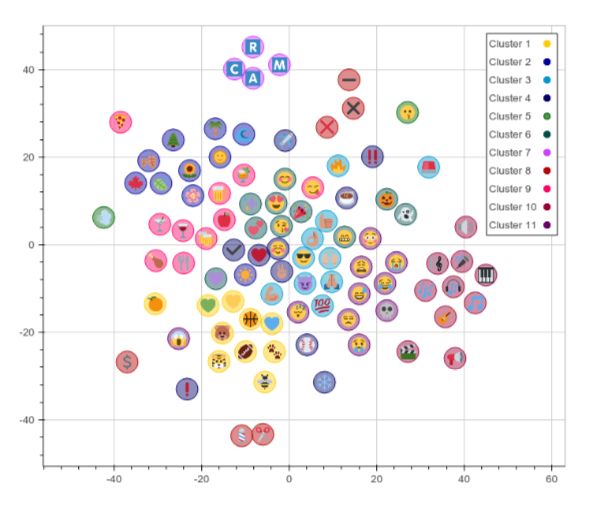
Группа респондентов также оценила 50 пар смайликов по этим двум критериям. Коэффициент корреляции между оценками людей и сходством, предсказанным моделью, оказался довольно высоким. Кроме того, авторы работы провели кластеризацию 100 самых популярных смайликов.
Чтобы было проще заметить близость изображений, авторы визуализировали векторы значений смайликов, предварительно сократив их размерность с 300 измерений до 2 при помощи метода t-SNE. Визуализация прикреплена ниже: чем ближе смайлики, тем больше они похожи. На графике видно, что модель довольно успешно объединяет в группы изображения еды, музыки, буквенных символов и растений.
Лондонские NLP-специалисты пошли другим путем. В 2016 году они представили своеобразное расширение для традиционной предобученной модели word2vec — emoji2vec. Ученые обучили модель на описании 1661 эмодзи. Emoji2vec значительно превосходит своего предшественника по предсказательной силе. Подход с анализом словарных статей для смайликов хорош тем, что он не зависит от кодировки смайлика: вектор значения, хранящийся в модели, един для различных вариантов одного изображения.
С 2019 года группа программистов из Индии занимается созданием модели, учитывающей как визуальное сходство смайликов, так и сходство векторных представлений их значений, однако попытки пока не увенчались успехом.
Аня Аксенова
Подробнее читайте по ссылке: https://sysblok.ru/philology/pojasni-za-smajlik-smeh-i-slezy-v-internete/
#philology
Рассказываем, как люди начали пользоваться эмотиконами и как теперь их семантику изучают компьютерными методами. Посвящается тем, кто хотя бы раз не понял, что означает сообщение со смайликом.
В письменной речи смайлики — главный способ выражения эмоций: они заменяют интонацию и жесты; могут выступать в качестве слов или выражать отношение говорящего к ситуации.
Смайлики не всегда легко проинтерпретировать, однако и со словами может возникнуть та же проблема. Чтобы понять значение слова, мы обычно смотрим на контекст. Со смайликами этот метод тоже работает. Если контекст не помогает, можно обратиться к словарю.
Разработчики Unicode создали настоящий словарь с описаниями изображений, но вряд ли люди туда часто заглядывают, потому что у смайликов есть преимущество перед словами — визуальная информация. Глядя на слово, мы понимаем его значение, потому что оно уже хранится у нас в голове, а картинку мы сравниваем с образами из повседневной жизни и поэтому можем угадать значение по визуальному сходству.
Цифровые исследования семантики смайликов
Специалисты в области NLP используют эти идеи для переноса значения смайликов в машиночитаемый формат. Ученые уже давно пользуются моделями, которые переводят слово в вектор его контекста, то есть совместной встречаемости с другими словами. Word2vec — одна из самых популярных моделей такого типа, основанная на нейросетевых технологиях. Используемый в ней алгоритм Skip-Gram пытается предсказать контекст справа и слева по центральному слову.
Впервые анализ эмодзи провели в 2015 году. Томас Димсон, один из разработчиков Инстаграма, обучил word2vec на выборке в 50 млн комментариев и поделился результатами с пользователями. Оказалось, что самые популярные эмодзи довольно устойчиво ассоциируются с тем, что они изображают. Так, флаги стран соотносятся с хэштегами, содержащими их названия, а смеющиеся смайлики — с сокращениями ‘lol’, ‘lmao’ и различными вариациями смеха. Подробнее об этом исследовании — в нашей статье.
Чуть позже вышла статья группы испанских ученых под руководством Франческо Барбери. Ученые представили модель, обученную на текстах англоязычного Твиттера, и проанализировали результаты ее работы. Для оценки близости смайликов были предложены два критерия:
1. сходство (можно ли заменить один смайлик другим);
2. соотнесенность (можно ли встретить эти смайлики в одном контексте).
Группа респондентов также оценила 50 пар смайликов по этим двум критериям. Коэффициент корреляции между оценками людей и сходством, предсказанным моделью, оказался довольно высоким. Кроме того, авторы работы провели кластеризацию 100 самых популярных смайликов.
Чтобы было проще заметить близость изображений, авторы визуализировали векторы значений смайликов, предварительно сократив их размерность с 300 измерений до 2 при помощи метода t-SNE. Визуализация прикреплена ниже: чем ближе смайлики, тем больше они похожи. На графике видно, что модель довольно успешно объединяет в группы изображения еды, музыки, буквенных символов и растений.
Лондонские NLP-специалисты пошли другим путем. В 2016 году они представили своеобразное расширение для традиционной предобученной модели word2vec — emoji2vec. Ученые обучили модель на описании 1661 эмодзи. Emoji2vec значительно превосходит своего предшественника по предсказательной силе. Подход с анализом словарных статей для смайликов хорош тем, что он не зависит от кодировки смайлика: вектор значения, хранящийся в модели, един для различных вариантов одного изображения.
С 2019 года группа программистов из Индии занимается созданием модели, учитывающей как визуальное сходство смайликов, так и сходство векторных представлений их значений, однако попытки пока не увенчались успехом.
Аня Аксенова
Подробнее читайте по ссылке: https://sysblok.ru/philology/pojasni-za-smajlik-smeh-i-slezy-v-internete/
{kind=link}
Лев Толстой онлайн: цифровые проекты о творчестве и жизни писателя
#philology
Портал tolstoy.ru — самый крупный ресурс о творчестве и деятельности писателя. Здесь собрана вся информация о жизни и творчестве писателя, а также о посвященных ему исследовательских проектах, музеях и событиях.
Проект «Весь Толстой в один клик»
Задача проекта «Весь Толстой в один клик» заключалась в оцифровке и распознавании текста в полном собрании сочинений Толстого. В основу легло единственное полное 90-томное собрание Л. Н. Толстого и том именного указателя. В него вошли все сохранившиеся и доступные на момент публикации произведения, рассказы, повести, дневники и письма.
Электронное собрание сочинений, а также дневники и записные книжки Толстого доступны на сайте tolstoy.ru для бесплатного скачивания в форматах PDF, FB2, MOBI и EPUB. А на сайте readingtolstoy.ru можно отметить себя на интерактивной карте читателей Толстого.
Веб-приложение «91-й том. Указатель к Толстому»
91-й том — это бумажный указатель к 90-томнику. Он состоит из указателей произведений, адресатов корреспонденции и других собственных имен, которые упоминает Толстой. Ресурс помогает пользователям и специалистам в исследовании жизни Толстого и связи между томами. Приложение также имеет своего бота в соцсети «Телеграм».
Акция «Каренина. Живое издание»
В начале октября 2014 года музей-усадьба Л. Н. Толстого «Ясная Поляна» и компания Google организовали масштабную акцию «Каренина. Живое издание». Впервые «Анну Каренину» прочли вслух за 36 часов в прямом эфире на платформах Google+ и YouTube. Их можно найти на YouTube под хэштегом #KareninaLive. Среди читателей были потомки Толстого, знаменитые артисты, спортсмены, музыканты, журналисты и даже государственные деятели.
Поисковик «Толстой Digital»
«Толстой Digital» — это семантическое издание, в котором тексты Толстого дополняются метаданными. Для писем, например, это дата и время написания и адресат, а в перспективе появится внутритекстовая семантическая разметка. Так тексты превратились в базу данных, которая позволяет «отвечать» на некоторые умные запросы пользователей. К примеру, ресурс показывает все письма Толстого Фету за определенный период времени.
Романы Толстого в приложении «Живые страницы»
Приложение «Живые страницы» превращает текст произведений в интерактивную литературную энциклопедию. В нем доступно три произведения Толстого: «Война и Мир», «Анна Каренина» и «Воскресение». В приложении можно отслеживать перемещение героев, смотреть календарь событий и карточки персонажей, проходить тесты и многое другое.
Проект «Приложения к музею. Студенты — Толстому»
Этот проект объединяет несколько проектов студентов ВШЭ.
Каторжный путь героев «Воскресения». Интерактивная карта, авторы которой воссоздали географический контекст произведения. На ней также отмечены все ключевые события романа.
География «Севастопольских рассказов». Интерактивная карта, создатели которой указали на ней места действий в рассказах и добавили материалы из дневников самого Толстого.
Путь Л. Н. Толстого. Интерактивная карта о путешествии писателя на протяжении жизни с текстовыми заметками и фотографиями.
Кулинарная книга Л. Н. Толстого. Авторы опирались на роман «Война и мир» и брали оттуда рецепты блюд. Получилось раскрытие кулинарных тайн XIX века.
Путешествие бельчонка Тима по усадьбе Л. Н. Толстого в Хамовниках. Детский аудиогид для детей до 8 лет. Он состоит из сказок Льва Николаевича, записей его голоса и музыки, а также содержит рассказы об экспонатах и истории московской усадьбы в Хамовниках.
Больше подробностей — в нашей статье: https://sysblok.ru/philology/lev-tolstoj-onlajn-cifrovye-proekty-o-tvorchestve-i-zhizni-pisatelja/
Варвара Гузий
#philology
Портал tolstoy.ru — самый крупный ресурс о творчестве и деятельности писателя. Здесь собрана вся информация о жизни и творчестве писателя, а также о посвященных ему исследовательских проектах, музеях и событиях.
Проект «Весь Толстой в один клик»
Задача проекта «Весь Толстой в один клик» заключалась в оцифровке и распознавании текста в полном собрании сочинений Толстого. В основу легло единственное полное 90-томное собрание Л. Н. Толстого и том именного указателя. В него вошли все сохранившиеся и доступные на момент публикации произведения, рассказы, повести, дневники и письма.
Электронное собрание сочинений, а также дневники и записные книжки Толстого доступны на сайте tolstoy.ru для бесплатного скачивания в форматах PDF, FB2, MOBI и EPUB. А на сайте readingtolstoy.ru можно отметить себя на интерактивной карте читателей Толстого.
Веб-приложение «91-й том. Указатель к Толстому»
91-й том — это бумажный указатель к 90-томнику. Он состоит из указателей произведений, адресатов корреспонденции и других собственных имен, которые упоминает Толстой. Ресурс помогает пользователям и специалистам в исследовании жизни Толстого и связи между томами. Приложение также имеет своего бота в соцсети «Телеграм».
Акция «Каренина. Живое издание»
В начале октября 2014 года музей-усадьба Л. Н. Толстого «Ясная Поляна» и компания Google организовали масштабную акцию «Каренина. Живое издание». Впервые «Анну Каренину» прочли вслух за 36 часов в прямом эфире на платформах Google+ и YouTube. Их можно найти на YouTube под хэштегом #KareninaLive. Среди читателей были потомки Толстого, знаменитые артисты, спортсмены, музыканты, журналисты и даже государственные деятели.
Поисковик «Толстой Digital»
«Толстой Digital» — это семантическое издание, в котором тексты Толстого дополняются метаданными. Для писем, например, это дата и время написания и адресат, а в перспективе появится внутритекстовая семантическая разметка. Так тексты превратились в базу данных, которая позволяет «отвечать» на некоторые умные запросы пользователей. К примеру, ресурс показывает все письма Толстого Фету за определенный период времени.
Романы Толстого в приложении «Живые страницы»
Приложение «Живые страницы» превращает текст произведений в интерактивную литературную энциклопедию. В нем доступно три произведения Толстого: «Война и Мир», «Анна Каренина» и «Воскресение». В приложении можно отслеживать перемещение героев, смотреть календарь событий и карточки персонажей, проходить тесты и многое другое.
Проект «Приложения к музею. Студенты — Толстому»
Этот проект объединяет несколько проектов студентов ВШЭ.
Каторжный путь героев «Воскресения». Интерактивная карта, авторы которой воссоздали географический контекст произведения. На ней также отмечены все ключевые события романа.
География «Севастопольских рассказов». Интерактивная карта, создатели которой указали на ней места действий в рассказах и добавили материалы из дневников самого Толстого.
Путь Л. Н. Толстого. Интерактивная карта о путешествии писателя на протяжении жизни с текстовыми заметками и фотографиями.
Кулинарная книга Л. Н. Толстого. Авторы опирались на роман «Война и мир» и брали оттуда рецепты блюд. Получилось раскрытие кулинарных тайн XIX века.
Путешествие бельчонка Тима по усадьбе Л. Н. Толстого в Хамовниках. Детский аудиогид для детей до 8 лет. Он состоит из сказок Льва Николаевича, записей его голоса и музыки, а также содержит рассказы об экспонатах и истории московской усадьбы в Хамовниках.
Больше подробностей — в нашей статье: https://sysblok.ru/philology/lev-tolstoj-onlajn-cifrovye-proekty-o-tvorchestve-i-zhizni-pisatelja/
Варвара Гузий
{kind=link}
Эволюция литературы: может ли Дарвин объяснить Конан Дойла и футуризм
#philology
В отличие от биологии, в филологии нет общепринятой теории эволюции литературы. Никто до конца не понимает, почему одни книги оказываются в центре внимания и входят в канон, другие остаются неизвестными, а третьи переживают период славы, но быстро забываются. Но были (и есть) те, кто пытается адаптировать теорию эволюции к анализу словесности. Рассказываем о двух подходах к объяснению эволюции литературы.
Подход формалистов
Юрий Тынянов, участник кружка формалистов, предложил смотреть на литературу как на поле со своими «центром» и «периферией», в рамках которого литературные тексты конкурируют друг с другом за место в центре литературного процесса. Согласно Тынянову, в центр далеко не всегда попадает самый «лучший» и образцовый литературный продукт. Наоборот: попасть в центр и сместить то, что было до него, имеет возможность скорее «патологическая» литература — нечто случайное, слабое и сначала даже не осознаваемое как литературный факт.
Таким образом формалисты вступают в скрытую полемику с дарвинизмом: по их мнению, в литературном процессе именно слабый и неприспособленный побеждает сильного и приспособленного, а не наоборот.
Дарвинистский подход
Современный социолог литературы Франко Моретти, наоборот, сравнивает процесс эволюции литературы с бойней, где мясниками оказываются «сами читатели, которые читают роман, А, (но не В, С, D, E, F, G, H…) и так поддерживают жизнь, А в следующем поколении». Получается, что роман «А» выживает из поколения в поколение, потому что именно к нему по той или иной причине приковано читательское внимание, и уже впоследствии роман «А» канонизируется академическим сообществом, а не наоборот.
Чтобы понять, почему одни художественные тексты выживают и читаются из поколения в поколение, а другие нет, рассмотрим два эксперимента, которые поставил Моретти.
Первый эксперимент: как Шерлок Холмс уцелел в бойне
Моретти вместе со студентами проанализировал нескольких десятков детективных рассказов, написанных в эпоху Конана Дойла. Они смотрели на то, как функционируют улики в этих рассказах, после чего разделили все рассказы на группы:
— рассказы с дешифруемыми уликами: на основе улик читатели самостоятельно могут прийти к разгадке;
— рассказы с функциональными уликами: улики помогают детективу (но не читателю) раскрыть дело;
— рассказы с упоминаемыми уликами: улики не выполняют никакой функции;
— рассказы без улик.
После анализа Моретти сделал следующие выводы: самой успешной категорией рассказов оказалась первая — рассказы с дешифруемыми уликами. В основном в этой группе оказались именно рассказы Конана Дойла. А отсутствие в детективных рассказах дешифруемых улик оказалось существенной причиной, по которой они не прошли «естественный отбор».
Второй эксперимент: эволюционные скачки
Расширив выборку, Моретти также замечает, что рассказы с дешифруемыми уликами в период с 1891 по 1900 не приживаются, а произведения без них появляются все чаще. Парадокс: то, что впоследствии победило литературных конкурентов и оказалось доминирующим, сначала вообще не воспринималось как нечто серьезное и важное в рамках литературного процесса.
Поэтому Моретти отказывается от дарвиновского принципа «природа не делает скачков» и заявляет, что литература развивается и меняется ТОЛЬКО через скачки. Подтверждает это феномен Агаты Кристи, укоренившей улики в детективе: «Скачок — Конан Дойл. Еще прыжок — Кристи», — пишет Моретти.
Дарвинизм и антидарвинизм в литературной эволюции: единство противоположностей
Кажется, что выводы, к которым пришел Моретти, не противоречат теории литературной эволюции, которую предложили формалисты. Открытие Моретти укладывается в теорию формальной школы: такой формальный прием, как дешифруемая улика, изначально находившийся на периферии, перемещается в центр литературного процесса.
https://sysblok.ru/philology/jevoljucija-literatury-mozhet-li-darvin-objasnit-konan-dojla-i-futurizm/
Вячеслав Кутепов
#philology
В отличие от биологии, в филологии нет общепринятой теории эволюции литературы. Никто до конца не понимает, почему одни книги оказываются в центре внимания и входят в канон, другие остаются неизвестными, а третьи переживают период славы, но быстро забываются. Но были (и есть) те, кто пытается адаптировать теорию эволюции к анализу словесности. Рассказываем о двух подходах к объяснению эволюции литературы.
Подход формалистов
Юрий Тынянов, участник кружка формалистов, предложил смотреть на литературу как на поле со своими «центром» и «периферией», в рамках которого литературные тексты конкурируют друг с другом за место в центре литературного процесса. Согласно Тынянову, в центр далеко не всегда попадает самый «лучший» и образцовый литературный продукт. Наоборот: попасть в центр и сместить то, что было до него, имеет возможность скорее «патологическая» литература — нечто случайное, слабое и сначала даже не осознаваемое как литературный факт.
Таким образом формалисты вступают в скрытую полемику с дарвинизмом: по их мнению, в литературном процессе именно слабый и неприспособленный побеждает сильного и приспособленного, а не наоборот.
Дарвинистский подход
Современный социолог литературы Франко Моретти, наоборот, сравнивает процесс эволюции литературы с бойней, где мясниками оказываются «сами читатели, которые читают роман, А, (но не В, С, D, E, F, G, H…) и так поддерживают жизнь, А в следующем поколении». Получается, что роман «А» выживает из поколения в поколение, потому что именно к нему по той или иной причине приковано читательское внимание, и уже впоследствии роман «А» канонизируется академическим сообществом, а не наоборот.
Чтобы понять, почему одни художественные тексты выживают и читаются из поколения в поколение, а другие нет, рассмотрим два эксперимента, которые поставил Моретти.
Первый эксперимент: как Шерлок Холмс уцелел в бойне
Моретти вместе со студентами проанализировал нескольких десятков детективных рассказов, написанных в эпоху Конана Дойла. Они смотрели на то, как функционируют улики в этих рассказах, после чего разделили все рассказы на группы:
— рассказы с дешифруемыми уликами: на основе улик читатели самостоятельно могут прийти к разгадке;
— рассказы с функциональными уликами: улики помогают детективу (но не читателю) раскрыть дело;
— рассказы с упоминаемыми уликами: улики не выполняют никакой функции;
— рассказы без улик.
После анализа Моретти сделал следующие выводы: самой успешной категорией рассказов оказалась первая — рассказы с дешифруемыми уликами. В основном в этой группе оказались именно рассказы Конана Дойла. А отсутствие в детективных рассказах дешифруемых улик оказалось существенной причиной, по которой они не прошли «естественный отбор».
Второй эксперимент: эволюционные скачки
Расширив выборку, Моретти также замечает, что рассказы с дешифруемыми уликами в период с 1891 по 1900 не приживаются, а произведения без них появляются все чаще. Парадокс: то, что впоследствии победило литературных конкурентов и оказалось доминирующим, сначала вообще не воспринималось как нечто серьезное и важное в рамках литературного процесса.
Поэтому Моретти отказывается от дарвиновского принципа «природа не делает скачков» и заявляет, что литература развивается и меняется ТОЛЬКО через скачки. Подтверждает это феномен Агаты Кристи, укоренившей улики в детективе: «Скачок — Конан Дойл. Еще прыжок — Кристи», — пишет Моретти.
Дарвинизм и антидарвинизм в литературной эволюции: единство противоположностей
Кажется, что выводы, к которым пришел Моретти, не противоречат теории литературной эволюции, которую предложили формалисты. Открытие Моретти укладывается в теорию формальной школы: такой формальный прием, как дешифруемая улика, изначально находившийся на периферии, перемещается в центр литературного процесса.
https://sysblok.ru/philology/jevoljucija-literatury-mozhet-li-darvin-objasnit-konan-dojla-i-futurizm/
Вячеслав Кутепов
{kind=link}
Цифровой Ван Гог: на грани вечности
#arts #philology
Винсент Ван Гог активно творил всего 10 лет, но его творчество оставило значительный след в живописи. Одни знают об этом художнике благодаря легенде об отрезанном ухе. Другие вспоминают его единственную проданную картину «Подсолнухи». Третьи — вдохновляется его биографией и поиском призвания как автора.
Представляем вашему вниманию проекты, которые будут полезны как исследователям, так и поклонникам мастера.
Литературный корпус «Vincent van Gogh. The Letters»
В основе литературного корпуса лежат письма, которые писал и получал Ван Гог в 1853–1890-е гг. Сейчас на сайте проекта находятся 903 письма, 820 из которых отправил сам Винсент. Каждому письму присвоили свой номер и добавили ссылки на копии/черновики/связанные материалы. Основными получателями были брат Тео и друзья-художники Поль Гоген и Эмиль Бернар.
Помимо писем, исследователи собрали материалы о самом художнике, архив его работ, черновиков (25 «родственных рукописей») и редакторских эссе, а также биографию Винсента и переписку его родственников.
Мультимедийные выставки
Жизнь и творчество Ван Гога распадается на два периода — мрачный голландский и яркий французский. Переписка с братом Тео демонстрирует изменения в мировоззрении художника и его отношении к творчеству.
Австралийская компания GRANDE EXHIBITIONS создала два мультимедийных проекта, посвященных жизни и творчеству Ван Гога. В обоих использовалась технология Cinema360. Изображения проецировались на экраны, стены, и пол, что визуально меняло геометрию зала и создавало эффект погружения.
Выставка «Ван Гог. Ожившие полотна» рассказывала о творчестве самого художника. В 2014 году в центральном зале центра дизайна ARTPLAY показали больше 3000 тематических изображений: картины мастера, письма и записи. Вместе с ними использовались звуковые эффекты: крики птиц, голоса людей, шелест и др.
Проект «Ван Гог. Письма к Тео» заострял внимание на отношениях художника с братом. К 400 картинам добавили закадровый текст в исполнении актера Владимира Зайцева, который также озвучивал Винсента в исполнении Уильяма Дефо в фильме «Ван Гог. На пороге вечности».
Фильм «Ван Гог: С любовью, Винсент»
«Ван Гог: С любовью, Винсент» — это полнометражный анимационный фильм, над которым трудилась команда из 100 художников. После съемок художники два года вручную отрисовывали масляными красками 62450 кадров на холсте согласно технике Ван Гога. Все кадры перетекает друг в друга, из-за чего фильм воспринимается как одна большая живая картина.
Сюжет повествует о событиях после гибели мастера. Сын старого почтальона берётся за расследование причины смерти Ван Гога. Для этого он приезжает в деревню, где Винсент жил в последнее время. В разговорах с очевидцами и свидетелями герой понимает, что виновник унёс с собой много тайн. Каждый рассказывает свою версию, которая не совпадает со словами других. Противоречия в рассказах наводят главного героя на мысль о возможном убийстве художника.
Глубокое погружение
Современные технологии позволили не только перенести картины Ван Гога на экран, но и проникнуть внутрь них. Цифровой художник Петрос Врелис создал интерактивное изображение «Звездной ночи». При прикосновении к сенсорному экрану зритель влияет на визуальную и звуковую составляющие: вместе с изменениями картины запускается музыка, которая создает эффект присутствия.
Автор Мак Каули пошёл дальше: на основе картины «Ночь в кафе» он создал видеоряд, который мы прикрепили ниже. Технология позволяет подробно изучить произведение изнутри, посмотреть на мир глазами Ван Гога и словно увидеть мгновение в движении.
В музее Ван Гога в Амстердаме посетители могут рассматривать картины под специальным микроскопом, который позволяет разглядеть каждый штрих и мазок на картине, волоски с кисточки, фактуры и объём краски на отдельных участках.
https://sysblok.ru/philology/cifrovoj-van-gog-na-grani-vechnosti/
Варвара Гузий
#arts #philology
Винсент Ван Гог активно творил всего 10 лет, но его творчество оставило значительный след в живописи. Одни знают об этом художнике благодаря легенде об отрезанном ухе. Другие вспоминают его единственную проданную картину «Подсолнухи». Третьи — вдохновляется его биографией и поиском призвания как автора.
Представляем вашему вниманию проекты, которые будут полезны как исследователям, так и поклонникам мастера.
Литературный корпус «Vincent van Gogh. The Letters»
В основе литературного корпуса лежат письма, которые писал и получал Ван Гог в 1853–1890-е гг. Сейчас на сайте проекта находятся 903 письма, 820 из которых отправил сам Винсент. Каждому письму присвоили свой номер и добавили ссылки на копии/черновики/связанные материалы. Основными получателями были брат Тео и друзья-художники Поль Гоген и Эмиль Бернар.
Помимо писем, исследователи собрали материалы о самом художнике, архив его работ, черновиков (25 «родственных рукописей») и редакторских эссе, а также биографию Винсента и переписку его родственников.
Мультимедийные выставки
Жизнь и творчество Ван Гога распадается на два периода — мрачный голландский и яркий французский. Переписка с братом Тео демонстрирует изменения в мировоззрении художника и его отношении к творчеству.
Австралийская компания GRANDE EXHIBITIONS создала два мультимедийных проекта, посвященных жизни и творчеству Ван Гога. В обоих использовалась технология Cinema360. Изображения проецировались на экраны, стены, и пол, что визуально меняло геометрию зала и создавало эффект погружения.
Выставка «Ван Гог. Ожившие полотна» рассказывала о творчестве самого художника. В 2014 году в центральном зале центра дизайна ARTPLAY показали больше 3000 тематических изображений: картины мастера, письма и записи. Вместе с ними использовались звуковые эффекты: крики птиц, голоса людей, шелест и др.
Проект «Ван Гог. Письма к Тео» заострял внимание на отношениях художника с братом. К 400 картинам добавили закадровый текст в исполнении актера Владимира Зайцева, который также озвучивал Винсента в исполнении Уильяма Дефо в фильме «Ван Гог. На пороге вечности».
Фильм «Ван Гог: С любовью, Винсент»
«Ван Гог: С любовью, Винсент» — это полнометражный анимационный фильм, над которым трудилась команда из 100 художников. После съемок художники два года вручную отрисовывали масляными красками 62450 кадров на холсте согласно технике Ван Гога. Все кадры перетекает друг в друга, из-за чего фильм воспринимается как одна большая живая картина.
Сюжет повествует о событиях после гибели мастера. Сын старого почтальона берётся за расследование причины смерти Ван Гога. Для этого он приезжает в деревню, где Винсент жил в последнее время. В разговорах с очевидцами и свидетелями герой понимает, что виновник унёс с собой много тайн. Каждый рассказывает свою версию, которая не совпадает со словами других. Противоречия в рассказах наводят главного героя на мысль о возможном убийстве художника.
Глубокое погружение
Современные технологии позволили не только перенести картины Ван Гога на экран, но и проникнуть внутрь них. Цифровой художник Петрос Врелис создал интерактивное изображение «Звездной ночи». При прикосновении к сенсорному экрану зритель влияет на визуальную и звуковую составляющие: вместе с изменениями картины запускается музыка, которая создает эффект присутствия.
Автор Мак Каули пошёл дальше: на основе картины «Ночь в кафе» он создал видеоряд, который мы прикрепили ниже. Технология позволяет подробно изучить произведение изнутри, посмотреть на мир глазами Ван Гога и словно увидеть мгновение в движении.
В музее Ван Гога в Амстердаме посетители могут рассматривать картины под специальным микроскопом, который позволяет разглядеть каждый штрих и мазок на картине, волоски с кисточки, фактуры и объём краски на отдельных участках.
https://sysblok.ru/philology/cifrovoj-van-gog-na-grani-vechnosti/
Варвара Гузий
YouTube
The Night Cafe - An Immersive VR Tribute to Vincent van Gogh
The Night Cafe is an immersive VR environment that allows you to explore the world of Vincent van Gogh first hand. Take a moment to enjoy his iconic sunflowe...
Цифровая филология 1910: как Андрей Белый вычислял отклонения ямба
#philology
Попытки применять точные методы в исследованиях стихотворений делались литературоведами задолго до возникновения компьютерных технологий и digital humanities. В начале XX века к точности в анализе поэтических текстов стремился русский поэт-символист Андрей Белый. Он одним из первых ввел в исследование стиха количественные методы.
Белый был не чужд математики. Он родился в семье декана физико-математического факультета Московского университета, и окончив гимназию, сам поступил на этот же факультет. Позднее, работая над теорией стиха, Андрей Белый решил охарактеризовать русский четырехстопный ямб методом, который сегодня назвали бы анализом данных. Он вручную проанализировал расстановку ударения в 16092 строках 27 отечественных поэтов.
Эволюция ямба
Для своего исследования Белый обратился к стихотворениям 27 отечественных поэтов, в которых доминирующим размером был четырехстопный ямб, и исследовал частотность и характеристику ускорений ямба в русской поэзии. Под ускорением Белый подразумевает наличие в стихотворении стопы, в которой есть лишний безударный слог — именно она и дает эффект ускорения, которое «слышит ухо». Пример ускорения на третьей стопе: «Чего-то ищет в небесах» (Тютчев).
Белый предлагает нам статистику по ускорениям на 596 строк у каждого поэта, отмечая частотность отклонений на той или иной стопе. Интересно, что правильный ямб составляет всего лишь 25% от всей выборки, а 75% приходится на ускорения от ямба. Как замечает Белый, именно через увеличение или уменьшение количества ускорений на той или иной стопе четырехстопный ямб и эволюционировал.
Всего Белый выделяет пять темпов, возможных при отклонении от ямба:
1. Наименьшее количество ускорений на первой стопе (13), максимальное на второй (139) и наименьшее количество ускорений на первой и третьей стопе одновременно (5) с максимальным на второй и третьей одновременно (11) было у Ломоносова;
2. К наибольшему количеству ускорений на первой стопе (46), максимальному на второй (139), наибольшему на первой и третьей одновременно (26) и наименьшему на второй и третьей стопе (1) пришел Державин;
3. Наименьшее количество отклонений на третьей стопе (230) демонстрирует Капнист;
4. Падение отклонений на второй стопе (33) и увеличение отклонений на третьей (313) показывает Батюшков;
5. Увеличение количества отклонений на второй и третьей стопах одновременно (44), много ускорений на второй стопе (52), и увеличение суммы ускорений первой стопы (99) замечаются у Жуковского.
Белый делает следующий вывод: беднота или, наоборот, обилие ускорений, во-первых, индивидуализирует стиль поэта и, во-вторых, реформирует четырехстопный ямб вообще, то есть задает те или иные «тренды» в написании стихотворений этим размером. Так главными его реформаторами оказываются Жуковский и Батюшков, но совсем не Пушкин. Пушкин только доводит начатую ими работу до конца: он повторяет сумму ускорений Батюшкова (33) и немного увеличивает ускорения третьей стопы (341) — так реформа завершается.
В русской поэзии первой половины XIX в., как замечает Белый, было стремление «увеличить до крайности ускорение первой стопы и уменьшить до крайности ускорение второй», которое проявилось в большей степени у Баратынского.
Белый также обнаружил, что отклонения от ямба образуют в стихотворениях различные геометрические фигуры, которые, вполне вероятно, могут сказать нам о содержании того или иного поэтического текста много нового. Об этом — в нашей статье: https://sysblok.ru/philology/cifrovaja-filologija-1910-kak-andrej-belyj-vychisljal-otklonenija-jamba/
Вячеслав Кутепов
#philology
Попытки применять точные методы в исследованиях стихотворений делались литературоведами задолго до возникновения компьютерных технологий и digital humanities. В начале XX века к точности в анализе поэтических текстов стремился русский поэт-символист Андрей Белый. Он одним из первых ввел в исследование стиха количественные методы.
Белый был не чужд математики. Он родился в семье декана физико-математического факультета Московского университета, и окончив гимназию, сам поступил на этот же факультет. Позднее, работая над теорией стиха, Андрей Белый решил охарактеризовать русский четырехстопный ямб методом, который сегодня назвали бы анализом данных. Он вручную проанализировал расстановку ударения в 16092 строках 27 отечественных поэтов.
Эволюция ямба
Для своего исследования Белый обратился к стихотворениям 27 отечественных поэтов, в которых доминирующим размером был четырехстопный ямб, и исследовал частотность и характеристику ускорений ямба в русской поэзии. Под ускорением Белый подразумевает наличие в стихотворении стопы, в которой есть лишний безударный слог — именно она и дает эффект ускорения, которое «слышит ухо». Пример ускорения на третьей стопе: «Чего-то ищет в небесах» (Тютчев).
Белый предлагает нам статистику по ускорениям на 596 строк у каждого поэта, отмечая частотность отклонений на той или иной стопе. Интересно, что правильный ямб составляет всего лишь 25% от всей выборки, а 75% приходится на ускорения от ямба. Как замечает Белый, именно через увеличение или уменьшение количества ускорений на той или иной стопе четырехстопный ямб и эволюционировал.
Всего Белый выделяет пять темпов, возможных при отклонении от ямба:
1. Наименьшее количество ускорений на первой стопе (13), максимальное на второй (139) и наименьшее количество ускорений на первой и третьей стопе одновременно (5) с максимальным на второй и третьей одновременно (11) было у Ломоносова;
2. К наибольшему количеству ускорений на первой стопе (46), максимальному на второй (139), наибольшему на первой и третьей одновременно (26) и наименьшему на второй и третьей стопе (1) пришел Державин;
3. Наименьшее количество отклонений на третьей стопе (230) демонстрирует Капнист;
4. Падение отклонений на второй стопе (33) и увеличение отклонений на третьей (313) показывает Батюшков;
5. Увеличение количества отклонений на второй и третьей стопах одновременно (44), много ускорений на второй стопе (52), и увеличение суммы ускорений первой стопы (99) замечаются у Жуковского.
Белый делает следующий вывод: беднота или, наоборот, обилие ускорений, во-первых, индивидуализирует стиль поэта и, во-вторых, реформирует четырехстопный ямб вообще, то есть задает те или иные «тренды» в написании стихотворений этим размером. Так главными его реформаторами оказываются Жуковский и Батюшков, но совсем не Пушкин. Пушкин только доводит начатую ими работу до конца: он повторяет сумму ускорений Батюшкова (33) и немного увеличивает ускорения третьей стопы (341) — так реформа завершается.
В русской поэзии первой половины XIX в., как замечает Белый, было стремление «увеличить до крайности ускорение первой стопы и уменьшить до крайности ускорение второй», которое проявилось в большей степени у Баратынского.
Белый также обнаружил, что отклонения от ямба образуют в стихотворениях различные геометрические фигуры, которые, вполне вероятно, могут сказать нам о содержании того или иного поэтического текста много нового. Об этом — в нашей статье: https://sysblok.ru/philology/cifrovaja-filologija-1910-kak-andrej-belyj-vychisljal-otklonenija-jamba/
Вячеслав Кутепов
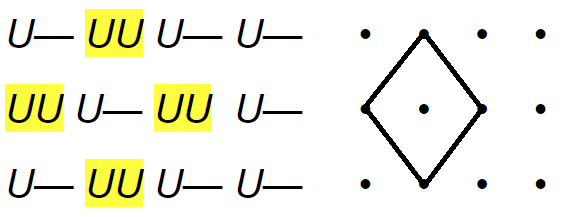{kind=link}
Ресурсы для цифровых стиховедов: поэтические корпуса
#philology #survey
Поэтический корпус — это электронная коллекция стихотворных текстов. Корпус отличается от электронной библиотеки тем, что в нем есть разметка. В поэтических корпусах размечают формальные показатели стиха: метрику, рифму, строфику. Общеизвестных доступных корпусов с такой разметкой четыре: поэтический подкорпус Национального корпуса русского языка (НКРЯ), а также Башкирский, Чешский и Персидский поэтические корпуса.
На базе поэтических корпусов проводятся количественные стиховедческие исследования, например, исследование семантического ореола метра, акцентологические исследования (исследования ударения), ставятся эксперименты по автоматическому определению авторства и изучается творчество отдельных поэтов.
Поэтический подкорпус НКРЯ
Поэтический корпус в составе Национального корпуса русского языка — первый в истории поэтический корпус. На данный момент объем корпуса — 89 124 текстов, 12 407 747 слов. В корпусе представлен 951 автор.
Стиховедческая разметка поэтического подкорпуса НКРЯ включает метр, строфику, клаузулы и другие параметры. Помимо стиховедческой, в поэтическом подкорпусе есть морфологическая и метатекстовая разметка (автор, дата создания, жанр). По метру, строфике, клаузуле и другим признакам можно искать информацию и задавать подкорпус. Определения сложных слов можно искать в терминологическом указателе.
В подкорпусе доступны полные тексты всех произведений. Напрямую из корпуса их скачать нельзя, но мы уже рассказывали, как написать программу для скачивания текстов.
Башкирский поэтический корпус
Объём Башкирского поэтического корпуса составляет более 1,8 млн слов. Коллекция текстов состоит из произведений 103 башкирских поэтов XX и начала XXI века. Авторские права на использованные стихотворения остаются за поэтами.
Для грамматического разбора словоформ Б. В. Орехов и А. А. Галлямов разработали систему автоматического морфологического анализа Bashmorph. А для поиска словоформ по базе была адаптирована поисковая система Восточноармянского национального корпуса, созданная компанией Corpus Technologies.
Тексты в корпусе снабжены морфологической разметкой и стиховедческой разметкой, которая позволяет осуществлять поиск в строках, написанных определенным метром, в зоне рифмовки и т. д. Корпус поддерживает два вида поиска — лексический и грамматический, можно искать как само слово, так и формы по определенным грамматическим признакам. Также есть возможность задавать корпус отдельного автора.
Чешский поэтический корпус
На данный момент в корпусе чешского стиха собраны тексты чешских поэтов XIX — начала XX веков, и его объем более 14,6 млн слов. Каждой словоформе в корпусе присвоена начальная форма данного слова, фонетическая транскрипция и грамматические категории; для каждого стиха определены метр, число стоп, тип клаузулы и метрическая схема.
На основе корпуса создано приложение «Эвфонометр». Эвфония — это учение о благозвучии, раздел поэтики, изучающий в стихе качественную сторону речевых звуков, накладывающих известную эмоциональную окраску на художественное произведение. С помощью Эвфонометра можно вычислить степень благозвучия любого поэтического текста в корпусе.
Персидский поэтический корпус
Персидский поэтический корпус был опубликован весной 2020 года и строился по той же модели, что и все предыдущие. Он содержит тексты классической персидской поэзии IX–XVII веков в объеме 4,3 млн словоупотреблений. Это 16 842 произведения или 330 723 бейта — так называется минимальная строфическая единица тюркской и персидской поэзии. Тексты морфологически размечены, доступен поиск по словам в позиции редифа и рифмы, часть текстов размечена метрически.
Больше подробностей — в нашей статье: https://sysblok.ru/philology/resursy-dlja-cifrovyh-stihovedov-pojeticheskie-korpusa/
Ольга Лисицкая
#philology #survey
Поэтический корпус — это электронная коллекция стихотворных текстов. Корпус отличается от электронной библиотеки тем, что в нем есть разметка. В поэтических корпусах размечают формальные показатели стиха: метрику, рифму, строфику. Общеизвестных доступных корпусов с такой разметкой четыре: поэтический подкорпус Национального корпуса русского языка (НКРЯ), а также Башкирский, Чешский и Персидский поэтические корпуса.
На базе поэтических корпусов проводятся количественные стиховедческие исследования, например, исследование семантического ореола метра, акцентологические исследования (исследования ударения), ставятся эксперименты по автоматическому определению авторства и изучается творчество отдельных поэтов.
Поэтический подкорпус НКРЯ
Поэтический корпус в составе Национального корпуса русского языка — первый в истории поэтический корпус. На данный момент объем корпуса — 89 124 текстов, 12 407 747 слов. В корпусе представлен 951 автор.
Стиховедческая разметка поэтического подкорпуса НКРЯ включает метр, строфику, клаузулы и другие параметры. Помимо стиховедческой, в поэтическом подкорпусе есть морфологическая и метатекстовая разметка (автор, дата создания, жанр). По метру, строфике, клаузуле и другим признакам можно искать информацию и задавать подкорпус. Определения сложных слов можно искать в терминологическом указателе.
В подкорпусе доступны полные тексты всех произведений. Напрямую из корпуса их скачать нельзя, но мы уже рассказывали, как написать программу для скачивания текстов.
Башкирский поэтический корпус
Объём Башкирского поэтического корпуса составляет более 1,8 млн слов. Коллекция текстов состоит из произведений 103 башкирских поэтов XX и начала XXI века. Авторские права на использованные стихотворения остаются за поэтами.
Для грамматического разбора словоформ Б. В. Орехов и А. А. Галлямов разработали систему автоматического морфологического анализа Bashmorph. А для поиска словоформ по базе была адаптирована поисковая система Восточноармянского национального корпуса, созданная компанией Corpus Technologies.
Тексты в корпусе снабжены морфологической разметкой и стиховедческой разметкой, которая позволяет осуществлять поиск в строках, написанных определенным метром, в зоне рифмовки и т. д. Корпус поддерживает два вида поиска — лексический и грамматический, можно искать как само слово, так и формы по определенным грамматическим признакам. Также есть возможность задавать корпус отдельного автора.
Чешский поэтический корпус
На данный момент в корпусе чешского стиха собраны тексты чешских поэтов XIX — начала XX веков, и его объем более 14,6 млн слов. Каждой словоформе в корпусе присвоена начальная форма данного слова, фонетическая транскрипция и грамматические категории; для каждого стиха определены метр, число стоп, тип клаузулы и метрическая схема.
На основе корпуса создано приложение «Эвфонометр». Эвфония — это учение о благозвучии, раздел поэтики, изучающий в стихе качественную сторону речевых звуков, накладывающих известную эмоциональную окраску на художественное произведение. С помощью Эвфонометра можно вычислить степень благозвучия любого поэтического текста в корпусе.
Персидский поэтический корпус
Персидский поэтический корпус был опубликован весной 2020 года и строился по той же модели, что и все предыдущие. Он содержит тексты классической персидской поэзии IX–XVII веков в объеме 4,3 млн словоупотреблений. Это 16 842 произведения или 330 723 бейта — так называется минимальная строфическая единица тюркской и персидской поэзии. Тексты морфологически размечены, доступен поиск по словам в позиции редифа и рифмы, часть текстов размечена метрически.
Больше подробностей — в нашей статье: https://sysblok.ru/philology/resursy-dlja-cifrovyh-stihovedov-pojeticheskie-korpusa/
Ольга Лисицкая
{kind=link}
Джеймс против Джойса: можно ли измерить сложность художественной литературы
#philology
Художественный текст сложный по определению, так как авторы используют средства художественной выразительности — метафоры, эксперименты с синтаксисом и лексической многозначностью, аллюзии и др. Кроме того, понимание сложности текста меняется. То, что было ново и непривычно для читателя начала XX века, читателя XXI века не удивит и покажется простым в восприятии.
В этой статье рассказываем, как исследователи из Кембриджского университета измеряли сложность разнообразных по жанру и стилю произведений английской литературы XIX–XX веков.
Индекс Флеша
Чтобы найти индекс Флеша, вычисляют среднюю длину предложений в тексте, а также количество слогов в словах. Подробнее об индексе Флеша мы уже рассказывали в другой нашей статье.
Выяснилось, что многие тексты первой половины XIX века, например, «Чувство и чувствительность» Остин, имеют по этому критерию показатели выше, чем у авангардных романов Джойса «Улисс» и «Поминки по Финнегану».
Поэтому меры удобочитаемости (readability) не дают объективной картины для художественной литературы.
Абстрактность используемых слов
Существует словарь, в котором слова размечены носителями языка по степени абстрактности-конкретности: испытуемые оценивали слова, ставя баллы от 1 до 5 напротив каждого слова. Каждый текст из выборки был оценен по среднему значению конкретности тех слов, которые есть и в словаре, и в самом тексте.
Вестерн Кормака Маккарни «Кровавый меридиан» предсказуемо оказался в самом верху шкалы конкретности. Однако авангардный «Улисс» соседствует с приключенческим романом «Остров сокровищ» Стивенсона, а степень конкретности Джойса остается одинаковой, несмотря на значительную эволюцию его стиля от реалистических «Дублинцев» до экспериментального романа «Поминки по Финнегану».
Этот факт ставит под сомнение тезис, что по лексической абстрактности можно судить о сложности текста.
Измерение культурного контекста
Исследователи Ewan Jones и Paul Nulty предлагают новую методику определения сложности художественного текста: они измеряют сложность текста в сравнении с окружающим его контекстом — большим текстовым корпусом. Для своей задачи исследователи использовали Google Books Fiction — раздел с английской художественной литературой с 1800 по 1915 год, который состоит из примерно 7.1 миллиардов токенов.
Ключевой параметр — относительная частота употребления слов: чем больше в тексте знакомых слов, тем текст для нас «предсказуемее», легче. Для каждого слова в датасете и в «испытуемых» произведениях из первых экспериментов вычисляется мера Ципфа: насколько часто встречается слово в конкретном произведении и насколько часто встречается оно же во всем корпусе. При этом учитываются только те слова, которые встречаются и там, и там.
Затем меру Ципфа в корпусе для каждого слова сравнили с мерой Ципфа каждого конкретного произведения. Наименьшее значение получил роман «Поминки по Финнегану» (Finnegan’s Wake) Джойса, а наибольшее — «Крылья голубки» (Wings of the dove) Джеймса.
Кажется, это значит, что Джойс максимально отличается от литературного контекста, а Джеймс максимально на него похож. Но это не так: близость к контексту определяется близостью к среднему значению, т. к. сравнивается относительная сложность произведений.
Наиболее близкий к контексту текст — это «Записки Пиквикского клуба» Диккенса: именно его показатель ближе всего к общему среднему по корпусу. А экстремумы — это непохожесть на контекст, причем эта непохожесть может быть как простотой, так и сложностью.
https://sysblok.ru/philology/dzhejms-protiv-dzhojsa-o-slozhnosti-v-hudozhestvennoj-literature/
Мария Захарова
#philology
Художественный текст сложный по определению, так как авторы используют средства художественной выразительности — метафоры, эксперименты с синтаксисом и лексической многозначностью, аллюзии и др. Кроме того, понимание сложности текста меняется. То, что было ново и непривычно для читателя начала XX века, читателя XXI века не удивит и покажется простым в восприятии.
В этой статье рассказываем, как исследователи из Кембриджского университета измеряли сложность разнообразных по жанру и стилю произведений английской литературы XIX–XX веков.
Индекс Флеша
Чтобы найти индекс Флеша, вычисляют среднюю длину предложений в тексте, а также количество слогов в словах. Подробнее об индексе Флеша мы уже рассказывали в другой нашей статье.
Выяснилось, что многие тексты первой половины XIX века, например, «Чувство и чувствительность» Остин, имеют по этому критерию показатели выше, чем у авангардных романов Джойса «Улисс» и «Поминки по Финнегану».
Поэтому меры удобочитаемости (readability) не дают объективной картины для художественной литературы.
Абстрактность используемых слов
Существует словарь, в котором слова размечены носителями языка по степени абстрактности-конкретности: испытуемые оценивали слова, ставя баллы от 1 до 5 напротив каждого слова. Каждый текст из выборки был оценен по среднему значению конкретности тех слов, которые есть и в словаре, и в самом тексте.
Вестерн Кормака Маккарни «Кровавый меридиан» предсказуемо оказался в самом верху шкалы конкретности. Однако авангардный «Улисс» соседствует с приключенческим романом «Остров сокровищ» Стивенсона, а степень конкретности Джойса остается одинаковой, несмотря на значительную эволюцию его стиля от реалистических «Дублинцев» до экспериментального романа «Поминки по Финнегану».
Этот факт ставит под сомнение тезис, что по лексической абстрактности можно судить о сложности текста.
Измерение культурного контекста
Исследователи Ewan Jones и Paul Nulty предлагают новую методику определения сложности художественного текста: они измеряют сложность текста в сравнении с окружающим его контекстом — большим текстовым корпусом. Для своей задачи исследователи использовали Google Books Fiction — раздел с английской художественной литературой с 1800 по 1915 год, который состоит из примерно 7.1 миллиардов токенов.
Ключевой параметр — относительная частота употребления слов: чем больше в тексте знакомых слов, тем текст для нас «предсказуемее», легче. Для каждого слова в датасете и в «испытуемых» произведениях из первых экспериментов вычисляется мера Ципфа: насколько часто встречается слово в конкретном произведении и насколько часто встречается оно же во всем корпусе. При этом учитываются только те слова, которые встречаются и там, и там.
Затем меру Ципфа в корпусе для каждого слова сравнили с мерой Ципфа каждого конкретного произведения. Наименьшее значение получил роман «Поминки по Финнегану» (Finnegan’s Wake) Джойса, а наибольшее — «Крылья голубки» (Wings of the dove) Джеймса.
Кажется, это значит, что Джойс максимально отличается от литературного контекста, а Джеймс максимально на него похож. Но это не так: близость к контексту определяется близостью к среднему значению, т. к. сравнивается относительная сложность произведений.
Наиболее близкий к контексту текст — это «Записки Пиквикского клуба» Диккенса: именно его показатель ближе всего к общему среднему по корпусу. А экстремумы — это непохожесть на контекст, причем эта непохожесть может быть как простотой, так и сложностью.
https://sysblok.ru/philology/dzhejms-protiv-dzhojsa-o-slozhnosti-v-hudozhestvennoj-literature/
Мария Захарова
{kind=link}
Как выделяют и классифицируют сущности в художественных текстах
#nlp #philology
Человек схватывает новую информацию на лету: из контекста, из интонации, из невербального общения. А как помочь компьютеру понять, что Гарри — волшебник, Гендальф — майар, а Джон Сноу — одновременно Старк и Таргариен?
В NLP эти задачи называются Named-entity recognition (NER), то есть выделение сущностей, и Entity Typing (ET) — классификация сущностей. С помощью NER и ET филологи подсчитывают, сколько раз появляется персонаж в тексте, строят сеть связей между героями книг и собирают все прозвища героя, а историки работают с оцифрованными текстами древних рукописей.
Какие корпуса используют для классифицируют сущности
Обычно для выделения особенностей сущности и их классификации используются тексты Википедии. Этот метод работает, если нужно разобрать текст о реальном мире. Но если мы скормим программе текст «Властелина Колец», она выдаст неполный результат, т. к. в Википедии не хватает информации о вымышленных вселенных.
Эту проблему решили исследователи из Института Макса Планка. Они создали систему ENTIFY (ENtity TYping on FIctional texts), которая может работать с художественными текстами, в том числе и фэнтези и science-fiction вселенными.
В основе ENTYFI лежит тот же принцип, что и в базовых инструментах NLP — поиск и классификация сущностей, но к корпусу текстов из Википедии добавляются размеченные тексты с платформы fandom.com (ранее Wikia). Это платформа, которая позволяет создавать отдельные тематические википедии о вселенных из книг, кино, игр и т. д. Поэтому ENTYFI смогла определить, что «Фродо Бэггинс» — «хоббит» из племени «мохноног» (harfoot).
Как работает ENTYFI
Сначала статьи Wikia объединяются в группы, в которых все статьи описывают одну и ту же вселенную — Властелин колец, Гарри Поттер, Марвел и др. Затем программа ранжирует массив «каноничных вселенных» по количеству совпадений в статьях Wikia об одной вселенной и анализируемом тексте и с помощью нейросети LSTM выделяются сущности. Дальше программа ищет найденные в тексте сущности в корпусах Wikia и Википедии.
Одновременно с этими процессами проходят еще два: авторы ENTYFI называют их Unsupervised typing и KB lookup. Unsupervised typing — это поиск класса сущности внутри того предложения, в котором сущность найдена. ET при нахождении сущности подразделяет ее на токены (слова в ней), находит их класс (метку) и добавляет к ним префиксы — элементы разметки текста.
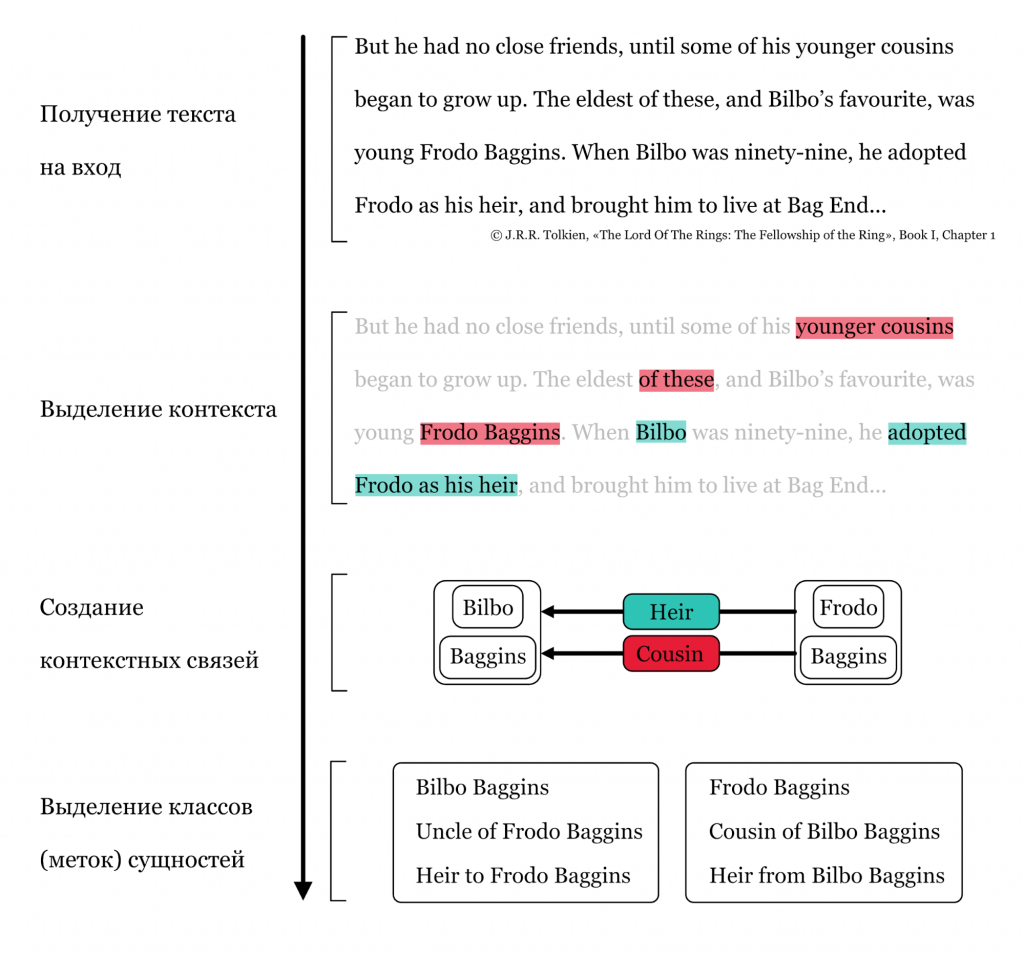
KB lookup — метод, позволяющий вычислить класс (метку) сущности через контекст, который есть в анализируемом тексте. Сначала программа анализирует то, что вокруг сущности (не обязательно близко по тексту), выделяет контекст, формирует связи и из этих связей выделяет классы (метки) сущности. На прикрепленной схеме показано, как программа понимает, что Фродо — «cousin» Бильбо и его наследник.
Информация консолидируется методами Inductive logic programming — Индуктивного логического программирования. Система перепроверяет метки (классы), которые она присвоила персонажам.
Сопоставляя факты, ENTYFI узнает, что Дрого Бэггинс, отец Фродо Бэггинса, ещё и троюродный брат Бильбо Бэггинса по мужской линии; а Примула Брендибак, мать Фродо Бэггинса — двоюродная сестра Бильбо Бэггинса по женской линии. Следовательно, Фродо Бэггинс — дважды племянник Бильбо Бэггинса: двоюродный по матери и троюродный по отцу. Поэтому в «борьбе» меток cousin и nephew победит последняя — потому что Фродо действительно племянник, а не кузен Бильбо.
Авторы ENTYFI выложили исходный код программы на Github.
Также есть демонстратор возможностей библиотеки SpaCy для Python.
https://sysblok.ru/philology/bjegginsy-kolca-i-saurony-kak-nauchit-kompjuter-ponimat-kto-est-kto/
Артур Хисматулин
#nlp #philology
Человек схватывает новую информацию на лету: из контекста, из интонации, из невербального общения. А как помочь компьютеру понять, что Гарри — волшебник, Гендальф — майар, а Джон Сноу — одновременно Старк и Таргариен?
В NLP эти задачи называются Named-entity recognition (NER), то есть выделение сущностей, и Entity Typing (ET) — классификация сущностей. С помощью NER и ET филологи подсчитывают, сколько раз появляется персонаж в тексте, строят сеть связей между героями книг и собирают все прозвища героя, а историки работают с оцифрованными текстами древних рукописей.
Какие корпуса используют для классифицируют сущности
Обычно для выделения особенностей сущности и их классификации используются тексты Википедии. Этот метод работает, если нужно разобрать текст о реальном мире. Но если мы скормим программе текст «Властелина Колец», она выдаст неполный результат, т. к. в Википедии не хватает информации о вымышленных вселенных.
Эту проблему решили исследователи из Института Макса Планка. Они создали систему ENTIFY (ENtity TYping on FIctional texts), которая может работать с художественными текстами, в том числе и фэнтези и science-fiction вселенными.
В основе ENTYFI лежит тот же принцип, что и в базовых инструментах NLP — поиск и классификация сущностей, но к корпусу текстов из Википедии добавляются размеченные тексты с платформы fandom.com (ранее Wikia). Это платформа, которая позволяет создавать отдельные тематические википедии о вселенных из книг, кино, игр и т. д. Поэтому ENTYFI смогла определить, что «Фродо Бэггинс» — «хоббит» из племени «мохноног» (harfoot).
Как работает ENTYFI
Сначала статьи Wikia объединяются в группы, в которых все статьи описывают одну и ту же вселенную — Властелин колец, Гарри Поттер, Марвел и др. Затем программа ранжирует массив «каноничных вселенных» по количеству совпадений в статьях Wikia об одной вселенной и анализируемом тексте и с помощью нейросети LSTM выделяются сущности. Дальше программа ищет найденные в тексте сущности в корпусах Wikia и Википедии.
Одновременно с этими процессами проходят еще два: авторы ENTYFI называют их Unsupervised typing и KB lookup. Unsupervised typing — это поиск класса сущности внутри того предложения, в котором сущность найдена. ET при нахождении сущности подразделяет ее на токены (слова в ней), находит их класс (метку) и добавляет к ним префиксы — элементы разметки текста.
KB lookup — метод, позволяющий вычислить класс (метку) сущности через контекст, который есть в анализируемом тексте. Сначала программа анализирует то, что вокруг сущности (не обязательно близко по тексту), выделяет контекст, формирует связи и из этих связей выделяет классы (метки) сущности. На прикрепленной схеме показано, как программа понимает, что Фродо — «cousin» Бильбо и его наследник.
Информация консолидируется методами Inductive logic programming — Индуктивного логического программирования. Система перепроверяет метки (классы), которые она присвоила персонажам.
Сопоставляя факты, ENTYFI узнает, что Дрого Бэггинс, отец Фродо Бэггинса, ещё и троюродный брат Бильбо Бэггинса по мужской линии; а Примула Брендибак, мать Фродо Бэггинса — двоюродная сестра Бильбо Бэггинса по женской линии. Следовательно, Фродо Бэггинс — дважды племянник Бильбо Бэггинса: двоюродный по матери и троюродный по отцу. Поэтому в «борьбе» меток cousin и nephew победит последняя — потому что Фродо действительно племянник, а не кузен Бильбо.
Авторы ENTYFI выложили исходный код программы на Github.
Также есть демонстратор возможностей библиотеки SpaCy для Python.
https://sysblok.ru/philology/bjegginsy-kolca-i-saurony-kak-nauchit-kompjuter-ponimat-kto-est-kto/
Артур Хисматулин
{kind=link}
Sketch Engine и Маяковский. Часть I: человек до и после революции
#philology #knowhow
Sketch Engine — инструмент для корпусных исследований, то есть исследований, которые выполняются на материале корпусов, больших электронных коллекций текстов. Sketch Engine может быть полезен не только исследователям-лингвистам и филологам, но и лексикографам, переводчикам и тем, кто изучает и преподает язык.
Почему такое название — «скетч»? Скетч — это быстрый набросок, пробная версия рисунка. Очень простой и незавершенный, скетч, тем не менее, передает общий замысел рисунка: мы уже понимаем, что хочет изобразить художник. Так и Sketch Engine позволяет создать «скетч», набросок, образ отдельного слова, текста или даже целого корпуса. С его помощью мы можем например, понять, в каких контекстах встречается интересующее нас слово, какие у интересующего нас текста или корпуса ключевые слова, а затем уже интерпретировать и использовать полученные результаты.
При помощи Sketch Engine мы попробуем провести «расследование», чтобы выяснить, какой лирический герой чаще появляется в творчестве Маяковского: поэт-агитатор на пароходе современности или отвергнутый и непонятый всеми романтик, каким автор предстает перед нами в своей любовной лирике.
Чтобы создать свой корпус и работать с ним, мы воспользовались бесплатной онлайн-версией проекта, которая действует 30 дней. Тексты Владимира Маяковского мы скачали из поэтического подкорпуса НКРЯ.
Анализ с помощью «Word Sketch»
Мы разбили свой корпус на подкорпусы «до» и «после» Революции. Это позволит нам, например, оценить частоту появления одного и того же слова в разных подкорпусах или сравнить ключевые слова разных подкорпусов.
Мы хотим узнать, как меняется образ человека в стихотворениях Маяковского: в инструменте «Word Sketch» задаем лемму «Человек» и запускаем программу для обоих подкорпусов. Теперь попробуем интерпретировать полученные результаты.
Что делает человек в стихах Маяковского, написанных до революции? Ничего особенного: он рождается, растет, ждет чего-то, дичает и в итоге исчезает. А вот после революции он деятелен и полон энергии: ходит, ездит, прыгает, готов ринуться куда-то… в общем, живет полной жизнью.
Если мы предположим, что главным героем поэзии Маяковского был простой рабочий, представитель пролетариата, то такие перемены могли быть связаны с изменением социального положения героя, установлением новой власти и радужными перспективами социализма.
Анализ с помощью «Concordance»
Образ человека не исчерпывается действиями. С помощью инструмента «Concordance» посмотрим на расширенный контекст слова «Человек», то есть, не просто на сочетания слов, а на целые предложения, в которых встречается указанное слово.
При анализе полученных данных увидим, что до 1917 года в творчестве Маяковского было много восклицаний и побудительных предложений, был призыв к действию («Эй, человек, землю саму зови на вальс!»). А после 1917 года предложения становятся утвердительными, в них прославляется человек, его всесилие и могущество («миром правит сам человек», «Люди двигают горами»).
Почему так мало призыва брать новые высоты в послереволюционном периоде творчества Маяковского? После революции в творчестве Маяковского часто встречается образ «искусственных людей»: «Этими — и добрыми, и кобры лютей, Союз до краев загружен». Они — порождение бюрократической системы, которая рождается вместе с молодым Советским государством, хоть и совершенно противоречит его идее.
Благодаря «Sketch Engine» мы выяснили, что человек у Маяковского, хоть и стал деятельным после Революции, но стал не личностью, а винтиком в системе. Виной всему бюрократия, которая возникла в государстве, которое изначально должно было быть основано на всеобщем равенстве и принципах справедливости.
А все технические подробности со скриншотами — в нашей статье: https://sysblok.ru/philology/sketch-engine-i-majakovskij-chast-i-chelovek-do-i-posle-revoljucii/
Мария Черных, Дарья Балуева
#philology #knowhow
Sketch Engine — инструмент для корпусных исследований, то есть исследований, которые выполняются на материале корпусов, больших электронных коллекций текстов. Sketch Engine может быть полезен не только исследователям-лингвистам и филологам, но и лексикографам, переводчикам и тем, кто изучает и преподает язык.
Почему такое название — «скетч»? Скетч — это быстрый набросок, пробная версия рисунка. Очень простой и незавершенный, скетч, тем не менее, передает общий замысел рисунка: мы уже понимаем, что хочет изобразить художник. Так и Sketch Engine позволяет создать «скетч», набросок, образ отдельного слова, текста или даже целого корпуса. С его помощью мы можем например, понять, в каких контекстах встречается интересующее нас слово, какие у интересующего нас текста или корпуса ключевые слова, а затем уже интерпретировать и использовать полученные результаты.
При помощи Sketch Engine мы попробуем провести «расследование», чтобы выяснить, какой лирический герой чаще появляется в творчестве Маяковского: поэт-агитатор на пароходе современности или отвергнутый и непонятый всеми романтик, каким автор предстает перед нами в своей любовной лирике.
Чтобы создать свой корпус и работать с ним, мы воспользовались бесплатной онлайн-версией проекта, которая действует 30 дней. Тексты Владимира Маяковского мы скачали из поэтического подкорпуса НКРЯ.
Анализ с помощью «Word Sketch»
Мы разбили свой корпус на подкорпусы «до» и «после» Революции. Это позволит нам, например, оценить частоту появления одного и того же слова в разных подкорпусах или сравнить ключевые слова разных подкорпусов.
Мы хотим узнать, как меняется образ человека в стихотворениях Маяковского: в инструменте «Word Sketch» задаем лемму «Человек» и запускаем программу для обоих подкорпусов. Теперь попробуем интерпретировать полученные результаты.
Что делает человек в стихах Маяковского, написанных до революции? Ничего особенного: он рождается, растет, ждет чего-то, дичает и в итоге исчезает. А вот после революции он деятелен и полон энергии: ходит, ездит, прыгает, готов ринуться куда-то… в общем, живет полной жизнью.
Если мы предположим, что главным героем поэзии Маяковского был простой рабочий, представитель пролетариата, то такие перемены могли быть связаны с изменением социального положения героя, установлением новой власти и радужными перспективами социализма.
Анализ с помощью «Concordance»
Образ человека не исчерпывается действиями. С помощью инструмента «Concordance» посмотрим на расширенный контекст слова «Человек», то есть, не просто на сочетания слов, а на целые предложения, в которых встречается указанное слово.
При анализе полученных данных увидим, что до 1917 года в творчестве Маяковского было много восклицаний и побудительных предложений, был призыв к действию («Эй, человек, землю саму зови на вальс!»). А после 1917 года предложения становятся утвердительными, в них прославляется человек, его всесилие и могущество («миром правит сам человек», «Люди двигают горами»).
Почему так мало призыва брать новые высоты в послереволюционном периоде творчества Маяковского? После революции в творчестве Маяковского часто встречается образ «искусственных людей»: «Этими — и добрыми, и кобры лютей, Союз до краев загружен». Они — порождение бюрократической системы, которая рождается вместе с молодым Советским государством, хоть и совершенно противоречит его идее.
Благодаря «Sketch Engine» мы выяснили, что человек у Маяковского, хоть и стал деятельным после Революции, но стал не личностью, а винтиком в системе. Виной всему бюрократия, которая возникла в государстве, которое изначально должно было быть основано на всеобщем равенстве и принципах справедливости.
А все технические подробности со скриншотами — в нашей статье: https://sysblok.ru/philology/sketch-engine-i-majakovskij-chast-i-chelovek-do-i-posle-revoljucii/
Мария Черных, Дарья Балуева
{kind=link}
Sketch Engine и Маяковский. Часть II: «несоветский» поэт Революции
#knowhow #philology
В прошлой статье о Sketch Engine мы при помощи инструментов «Word Sketch Difference», «Word Sketch» и «Concordance» показали, как человек Маяковского после Революции хоть и стал активным деятелем, но перестал быть личностью. Он стал представителем так называемого массового человека.
Теперь узнаем, что же говорит поэт о Советском государстве и России в целом.
В стране Советов
Обратимся снова к Word Sketch Difference. Выберем режим «Lemma», который поможет нам сравнить контексты двух разных слов. Посмотрим на слова «Россия» и «Совет».
Со словом «Совет» связаны «союз», «федерация», «свобода», «страна», «съезд», «власть», это очень конкретные вещи. А вот «Россия» встречается в более абстрактных контекстах: «сердце России», «снега России», «столпы России (императорской)» и «Встал от сна России труп ― ожила громада, дым дымит с фабричных труб, все творим, что надо». Последнее предложение снова отсылает нас к стране Советов, как к раю всех трудящихся, где нет эксплуатации человека человеком.
«Совет» более обезличен и соседствует с довольно формальными терминами, в то время как «России» соответствуют более одухотворенные, глубокие по смыслу и многозначные зависимые слова.
Мир и человек Маяковского
Теперь с помощью инструмента «Thesaurus», найдем контекстные синонимы для слов «человек» и «страна». «Thesaurus» основан на теории о распределительной семантике: он сравнивает скетчи всех слов той же части речи и оценивает, какие из них встречаются в наибольшем количестве одинаковых словосочетаний в корпусе.
Для леммы «Человек» наиболее близкими синонимами Sketch Engine определил слова «Товарищ», «День», «Год», «Глаз» и «Слово», а для леммы «Страна», казалось бы, синонимичной уже вводившимся ранее «Совету» и «России», самыми близкими контекстными синонимами оказались «Товарищ», «Человек», «Земля» и «Небо».
«Страна», и «Человек» в поэзии Маяковского тесно связаны: не зря у них есть общие синонимы, а синонимы леммы «Страна» вообще отсылают нас к «Человеку». Также образы страны и человека довольно материальны, связаны с чем-то обыденным, земным, явно осязаемым.
Революция и разочарование
С помощью инструмента «Concordance» увидим, что «Революция» у Маяковского не простой «рабочий подвиг», она живая: чего-то требует, зовет, идет по стране, она «всегда молода и готова», ей хочется дать «такие же названия, как любимым в первый день дают».
Восторженные возгласы у Маяковского вызывают исключительно две вещи: это человек во всем его великолепии и при всех его бесконечных возможностях — и Революция. Но после 1917 года на смену восторженности и предвкушению перемен приходит разочарование, и тон автора, авторская позиция меняются.
Инструмент «Wordlist» предлагает пользователю список слов, которые чаще всего встречаются в корпусе. В нашем случае для подкорпуса «До» это слова, которые чаще всего встречаются в философской лирике — «Сердце», «Душа», «Человек», «Небо». В подкорпусе «После» наряду с «Человеком» уже встречаются такие слова, как «Товарищ», «Рабочий», появляется даже образ «Ленина», что свидетельствует о явной острой социальной направленности стиха и близости к традициям гражданской лирики.
Ключевые слова поэзии Маяковского
С помощью инструмента «Keywords» можно извлечь из корпуса ключевые слова — слова, характерные для одного корпуса по сравнению с другим.
Газеты, улицы, аптеки с аптекарями вполне привычны для дореволюционного «адища города», а красное знамя (или флаг), рабочие, крестьяне, товарищи, Ленин, «всё советское» — для послереволюционного творчества Маяковского и в целом для России после 1917 года.
Как до, так и после Революции Маяковского волновали социальная и политическая стороны общественной жизни. Того требовало время. Того требовала и личная позиция Маяковского — поэта-гражданина.
Все технические подробности со скриншотами — в нашей статье: https://sysblok.ru/knowhow/sketch-engine-i-majakovskij-chast-ii-nesovetskij-pojet-revoljucii/
Мария Черных, Дарья Балуева
#knowhow #philology
В прошлой статье о Sketch Engine мы при помощи инструментов «Word Sketch Difference», «Word Sketch» и «Concordance» показали, как человек Маяковского после Революции хоть и стал активным деятелем, но перестал быть личностью. Он стал представителем так называемого массового человека.
Теперь узнаем, что же говорит поэт о Советском государстве и России в целом.
В стране Советов
Обратимся снова к Word Sketch Difference. Выберем режим «Lemma», который поможет нам сравнить контексты двух разных слов. Посмотрим на слова «Россия» и «Совет».
Со словом «Совет» связаны «союз», «федерация», «свобода», «страна», «съезд», «власть», это очень конкретные вещи. А вот «Россия» встречается в более абстрактных контекстах: «сердце России», «снега России», «столпы России (императорской)» и «Встал от сна России труп ― ожила громада, дым дымит с фабричных труб, все творим, что надо». Последнее предложение снова отсылает нас к стране Советов, как к раю всех трудящихся, где нет эксплуатации человека человеком.
«Совет» более обезличен и соседствует с довольно формальными терминами, в то время как «России» соответствуют более одухотворенные, глубокие по смыслу и многозначные зависимые слова.
Мир и человек Маяковского
Теперь с помощью инструмента «Thesaurus», найдем контекстные синонимы для слов «человек» и «страна». «Thesaurus» основан на теории о распределительной семантике: он сравнивает скетчи всех слов той же части речи и оценивает, какие из них встречаются в наибольшем количестве одинаковых словосочетаний в корпусе.
Для леммы «Человек» наиболее близкими синонимами Sketch Engine определил слова «Товарищ», «День», «Год», «Глаз» и «Слово», а для леммы «Страна», казалось бы, синонимичной уже вводившимся ранее «Совету» и «России», самыми близкими контекстными синонимами оказались «Товарищ», «Человек», «Земля» и «Небо».
«Страна», и «Человек» в поэзии Маяковского тесно связаны: не зря у них есть общие синонимы, а синонимы леммы «Страна» вообще отсылают нас к «Человеку». Также образы страны и человека довольно материальны, связаны с чем-то обыденным, земным, явно осязаемым.
Революция и разочарование
С помощью инструмента «Concordance» увидим, что «Революция» у Маяковского не простой «рабочий подвиг», она живая: чего-то требует, зовет, идет по стране, она «всегда молода и готова», ей хочется дать «такие же названия, как любимым в первый день дают».
Восторженные возгласы у Маяковского вызывают исключительно две вещи: это человек во всем его великолепии и при всех его бесконечных возможностях — и Революция. Но после 1917 года на смену восторженности и предвкушению перемен приходит разочарование, и тон автора, авторская позиция меняются.
Инструмент «Wordlist» предлагает пользователю список слов, которые чаще всего встречаются в корпусе. В нашем случае для подкорпуса «До» это слова, которые чаще всего встречаются в философской лирике — «Сердце», «Душа», «Человек», «Небо». В подкорпусе «После» наряду с «Человеком» уже встречаются такие слова, как «Товарищ», «Рабочий», появляется даже образ «Ленина», что свидетельствует о явной острой социальной направленности стиха и близости к традициям гражданской лирики.
Ключевые слова поэзии Маяковского
С помощью инструмента «Keywords» можно извлечь из корпуса ключевые слова — слова, характерные для одного корпуса по сравнению с другим.
Газеты, улицы, аптеки с аптекарями вполне привычны для дореволюционного «адища города», а красное знамя (или флаг), рабочие, крестьяне, товарищи, Ленин, «всё советское» — для послереволюционного творчества Маяковского и в целом для России после 1917 года.
Как до, так и после Революции Маяковского волновали социальная и политическая стороны общественной жизни. Того требовало время. Того требовала и личная позиция Маяковского — поэта-гражданина.
Все технические подробности со скриншотами — в нашей статье: https://sysblok.ru/knowhow/sketch-engine-i-majakovskij-chast-ii-nesovetskij-pojet-revoljucii/
Мария Черных, Дарья Балуева
{kind=link}
По словам их узнаете их: как вычисляли автора «Беовульфа»
#philology #nlp
Древнеанглийская поэма «Беовульф» — цельная работа одного автора или комбинация нескольких текстов? Чтобы ответить на этот вопрос, ученые проанализировали древнеанглийскую литературу количественными методами компьютерной лингвистики.
I. Что говорят количественные методы?
Анализ пауз
Сначала проанализировали смысловые паузы. Исследователи подсчитали отношение внутристрочных и смысловых пауз в обеих частях «Беовульфа» Получилось, что отношения для первой и второй части находятся в пределах 4% друг от друга. Чтобы подтвердить результаты, их также сравнили с другими древнеанглийскими поэмами и древнегреческим эпосом.
Анализ метра
Затем проанализировали метр «Беовульфа». Для этого использовалась классификация, предложенная Сиверсом, который делит полустроки на пять основных звуковых паттернов. Были исследованы как общая частота пяти типов, так и их последовательность в «Беовульфе». Оказалось, что уровень использования каждого типа остается линейным по всему тексту, без заметного сдвига в районе строки 2300 (конец первой части поэмы).
Анализ сложных существительных
Наконец, рассмотрели распределение сложных (составных) существительных по тексту «Беовульфа» и по всему корпусу древнеанглйской поэзии. Сложные существительные — такие как hran-rád «море» (букв. «дорога китов») и bán-hús «тело» (букв. «дом костей») — типичны для древнеанглийской поэзии.
Для определения авторства особенно важно подсчитать использование гапаксов — слов, встретившееся в некотором корпусе текстов только один раз. Доля гапаксов в текстах разных авторов сильно разнится, а в «Беовульфе» линейна по всему тексту, без изменений в области строки 2300. Небольшая нелинейность около строки 1500 соответствует битве Беовульфа с матерью Гренделя. Это место в поэме изобилует сложными словами.
II. Критика исследования
Воспроизводимость — важное свойство научных экспериментов. Группа ученых попыталась воспроизвести это исследование и пришла к выводу, что все четыре главных характеристики, которые были использованы для «количественного профилирования» древнеанглийской поэзии, либо имеют методологически сомнительные параметры (что ведет к неверной интерпретации результатов атрибуции текстов), либо неоптимальное воплощение, либо и то, и другое.
Критики также нашли серьезные ошибки в коде и никак не объясненные пропуски в данных, а одну часть результатов не получилось воспроизвести. Недостатки методологии ставят под вопрос главные выводы исследования.
https://sysblok.ru/philology/po-slovam-ih-uznaete-ih-kak-vychisljali-avtora-beovulfa/
Ксения Кашлева
#philology #nlp
Древнеанглийская поэма «Беовульф» — цельная работа одного автора или комбинация нескольких текстов? Чтобы ответить на этот вопрос, ученые проанализировали древнеанглийскую литературу количественными методами компьютерной лингвистики.
I. Что говорят количественные методы?
Анализ пауз
Сначала проанализировали смысловые паузы. Исследователи подсчитали отношение внутристрочных и смысловых пауз в обеих частях «Беовульфа» Получилось, что отношения для первой и второй части находятся в пределах 4% друг от друга. Чтобы подтвердить результаты, их также сравнили с другими древнеанглийскими поэмами и древнегреческим эпосом.
Анализ метра
Затем проанализировали метр «Беовульфа». Для этого использовалась классификация, предложенная Сиверсом, который делит полустроки на пять основных звуковых паттернов. Были исследованы как общая частота пяти типов, так и их последовательность в «Беовульфе». Оказалось, что уровень использования каждого типа остается линейным по всему тексту, без заметного сдвига в районе строки 2300 (конец первой части поэмы).
Анализ сложных существительных
Наконец, рассмотрели распределение сложных (составных) существительных по тексту «Беовульфа» и по всему корпусу древнеанглйской поэзии. Сложные существительные — такие как hran-rád «море» (букв. «дорога китов») и bán-hús «тело» (букв. «дом костей») — типичны для древнеанглийской поэзии.
Для определения авторства особенно важно подсчитать использование гапаксов — слов, встретившееся в некотором корпусе текстов только один раз. Доля гапаксов в текстах разных авторов сильно разнится, а в «Беовульфе» линейна по всему тексту, без изменений в области строки 2300. Небольшая нелинейность около строки 1500 соответствует битве Беовульфа с матерью Гренделя. Это место в поэме изобилует сложными словами.
II. Критика исследования
Воспроизводимость — важное свойство научных экспериментов. Группа ученых попыталась воспроизвести это исследование и пришла к выводу, что все четыре главных характеристики, которые были использованы для «количественного профилирования» древнеанглийской поэзии, либо имеют методологически сомнительные параметры (что ведет к неверной интерпретации результатов атрибуции текстов), либо неоптимальное воплощение, либо и то, и другое.
Критики также нашли серьезные ошибки в коде и никак не объясненные пропуски в данных, а одну часть результатов не получилось воспроизвести. Недостатки методологии ставят под вопрос главные выводы исследования.
https://sysblok.ru/philology/po-slovam-ih-uznaete-ih-kak-vychisljali-avtora-beovulfa/
Ксения Кашлева
{kind=link}
Опубликована большая электронная коллекция романов
#news #philology
Проект «Дальнее чтение для европейской литературной истории» представил обновленную базу текстов. В каждом собрании или коллекции от 20 до 100 романов. Всего в базе 884 текста на 18 языках.
Коллекция доступна в виде архива Github. В нём есть информация о состоянии сборников, авторах и источниках.
Главная задача проекта — собрать коллекцию из 2500 полных романов и дополнить историю европейской литературы 19–20 веков. Сейчас разработчики оцифровывают и разграничивают неканонические книги, написанные женщинами в 1840–1920-х годах.
https://sysblok.ru/philology/opublikovan-otkrytyj-korpus-evropejskih-romanov/
Варвара Гузий
#news #philology
Проект «Дальнее чтение для европейской литературной истории» представил обновленную базу текстов. В каждом собрании или коллекции от 20 до 100 романов. Всего в базе 884 текста на 18 языках.
Коллекция доступна в виде архива Github. В нём есть информация о состоянии сборников, авторах и источниках.
Главная задача проекта — собрать коллекцию из 2500 полных романов и дополнить историю европейской литературы 19–20 веков. Сейчас разработчики оцифровывают и разграничивают неканонические книги, написанные женщинами в 1840–1920-х годах.
https://sysblok.ru/philology/opublikovan-otkrytyj-korpus-evropejskih-romanov/
Варвара Гузий
{kind=link}
Разделяй и определяй, или Кто автор «Сна в красном тереме»
#philology
«Сон в красном тереме» — один из «четырех великих романов Китая». В нем повествуется о двух ветвях аристократической семьи Цзя и её постепенном упадке.
Оригинальная версия Цао Сюэциня содержит 80 частей, однако в 1791 году было опубликовано новое издание Гао Э из 120 частей. До сих пор ведутся дискуссии о том, сколько авторов у «Сна в красном тереме».
Поиски истинного автора
Метод Дельты Бёрроуза применяется для установления или уточнения авторства произведений.
Дельта представляет каждый текст в виде списка частотностей скольки-то (N) самых частотных слов — обычно берут от 100 и более слов. Таким образом текст становится вектором в N-мерном пространстве. Затем между этими векторами текстов измеряются расстояния — с помощью обычных геометрических мер близости. На основе этих расстояний и устанавливается наиболее вероятное авторство. Универсальность метода была многократно подтверждена на материале разных жанров, языков и эпох. В том числе на китайских текстах.
Если разложить главы согласно алгоритму кластеризации, видно что первые 80 глав наименее схожи с позднее опубликованными. Но есть исключение: главы 10 и 11, а так же 6 и 67 (из первой части) объединяются на первом шаге друг с другом, а уже на втором — с главами второй части. Возможные причины: неточный результат Дельты, большое количество имен собственных, редактура второго автора. Последнее проверяется с помощью тематического моделирования.
Тематическое моделирование
Для проверки результатов Дельты использовали версию романа, наиболее близкую к ранним изданиям.
• Предварительная обработка — токенизация и разделение. Это важно для разделения текста на слова, так как границы не обозначены пробелами.
• Формирование списка из стоп-слов — слова, которые нельзя интерпретировать.
• Определение тем — всего 50. Выходные данные свели в соответствии с главами.
• Визуализация — согласно соотношению тем с главами. Ось X – темы, ось Y – главы; красная линия разделяет первые 80 частей и последние 40.
• Распределение слов внутри темы — слова не связаны определенным мотивом.
Метод Дельты Бёллроуза не ошибся: действительно, главы 11 и 67 отличаются от первоначального текста романа. Отличаются не только именами персонажей или сюжетом, присутствуют и стилистические различия. С большей вероятностью, главы 11 и 67 отредактировал Гао Э.
https://sysblok.ru/philology/razdeljaj-i-opredeljaj-ili-kto-avtor-sna-v-krasnom-tereme/
Вероника Ганеева
#philology
«Сон в красном тереме» — один из «четырех великих романов Китая». В нем повествуется о двух ветвях аристократической семьи Цзя и её постепенном упадке.
Оригинальная версия Цао Сюэциня содержит 80 частей, однако в 1791 году было опубликовано новое издание Гао Э из 120 частей. До сих пор ведутся дискуссии о том, сколько авторов у «Сна в красном тереме».
Поиски истинного автора
Метод Дельты Бёрроуза применяется для установления или уточнения авторства произведений.
Дельта представляет каждый текст в виде списка частотностей скольки-то (N) самых частотных слов — обычно берут от 100 и более слов. Таким образом текст становится вектором в N-мерном пространстве. Затем между этими векторами текстов измеряются расстояния — с помощью обычных геометрических мер близости. На основе этих расстояний и устанавливается наиболее вероятное авторство. Универсальность метода была многократно подтверждена на материале разных жанров, языков и эпох. В том числе на китайских текстах.
Если разложить главы согласно алгоритму кластеризации, видно что первые 80 глав наименее схожи с позднее опубликованными. Но есть исключение: главы 10 и 11, а так же 6 и 67 (из первой части) объединяются на первом шаге друг с другом, а уже на втором — с главами второй части. Возможные причины: неточный результат Дельты, большое количество имен собственных, редактура второго автора. Последнее проверяется с помощью тематического моделирования.
Тематическое моделирование
Для проверки результатов Дельты использовали версию романа, наиболее близкую к ранним изданиям.
• Предварительная обработка — токенизация и разделение. Это важно для разделения текста на слова, так как границы не обозначены пробелами.
• Формирование списка из стоп-слов — слова, которые нельзя интерпретировать.
• Определение тем — всего 50. Выходные данные свели в соответствии с главами.
• Визуализация — согласно соотношению тем с главами. Ось X – темы, ось Y – главы; красная линия разделяет первые 80 частей и последние 40.
• Распределение слов внутри темы — слова не связаны определенным мотивом.
Метод Дельты Бёллроуза не ошибся: действительно, главы 11 и 67 отличаются от первоначального текста романа. Отличаются не только именами персонажей или сюжетом, присутствуют и стилистические различия. С большей вероятностью, главы 11 и 67 отредактировал Гао Э.
https://sysblok.ru/philology/razdeljaj-i-opredeljaj-ili-kto-avtor-sna-v-krasnom-tereme/
Вероника Ганеева
{kind=link}