
Краудсорсинг в Digital Humanities: опыт Латвийского фольклорного архива
#nlp #philology
Из фольклорных и диалектологических экспедиций ученые привозят множество материалов — тетрадей и аудиозаписей — и передают их в научные институты и университеты. Сейчас записи расшифровываются и классифицируются в цифровом виде, а в доцифровую эпоху — выписывались на карточки. Поэтому большинство материалов существует в виде специализированных изданий, формат которых не позволяет ничего посмотреть или посчитать в текстах автоматически. Только некоторые из таких изданий были оцифрованы и стали доступны для широкой публики.
Волонтеры помогают расшифровывать оцифрованные тексты
В Латвии предложили масштабное и современное решение этой проблемы. В декабре 2014 года Фольклорный архив Латвии к своему 90-летию запустил портал garamantas.lv (garamantas означает духовное наследие или фольклор).
Оцифрованные сканы рукописных листов загружаются в специально разработанную систему, где указаны необходимые метаданные: номер коллекции в архиве, описание коллекции, номера соответствующих архивных единиц и др. Для волонтеров-расшифровщиков разработали подробную инструкцию, а интерфейс доступен на разных языках.
В архиве есть не только латышские материалы, но и ливские песни, русский и белорусский фольклор, тексты на идише и латышском цыганском. Поэтому для участия в расшифровке необязательно знать латышский: в объемной коллекции русского фольклора, собранной Иваном Фридрихом в Латгалии (восточной Латвии), еще достаточно нерасшифрованных текстов. Также, «переписывать» слова со сканов можно и вообще без знания языка.
В 2016 году запустили отдельные «дочерние» ресурсы проекта — «Кудесники столетия» и «Языковая толока» (Valodas talka). «Языковая толока» была направлена на школьников: в течение двух с половиной месяцев им предлагалось поучаствовать в расшифровке рукописей. К окончанию акции собрали статистику об участниках, и наградили самых активных призами. Таким образом удалось привлечь много новых участников и расшифровать более десяти тысяч отсканированных изображений.
Другие проекты фольклорного архива: читаем стихи и поём
В 2017 году, к 150-летию поэта Эдуарда Вейденбаума, запустили акцию «Читай вслух!». Суть акции такова: люди выбирали любое стихотворение из представленных на портале и читали его под запись. Получилась своеобразная база данных с записями латышской речи, хоть и ограниченная конечным списком стихотворных текстов: можно послушать один и тот же текст, зачитанный людьми разных возрастов и из разных мест.
Затем прошли еще две похожие акции: со стихами для детей латышских поэтов-классиков и со стихами столетней давности (написанными или опубликованными в 1919 году).
В начале 2019 года запустили проект «Пой с архивом»: теперь можно не только послушать отдельные музыкальные записи из коллекций архива, но и загрузить свою версию. Пока что на странице этого проекта доступно не очень много записей, но даже в них представлены записи, собранные не только в Латвии, и не только на латышском.
Вот, например, песня, записанная в сибирской латышской деревне Нижняя Буланка в 1991 году (ноты здесь). А вот версия известной латышской народной песни «Kur tu teci, gailīti mans» (Куда бежишь, мой петушок?) на латышском цыганском. Среди выложенных записей есть также песни на ливском, русском и белорусском.
Опыт Латвийского фольклорного архива в некоторой степени уникален — прежде всего благодаря материалу, который представлен в его коллекциях. В то же время он универсален как пример успешного привлечения обычных людей к работе с культурным наследием страны.
Наталья Перкова
#nlp #philology
Из фольклорных и диалектологических экспедиций ученые привозят множество материалов — тетрадей и аудиозаписей — и передают их в научные институты и университеты. Сейчас записи расшифровываются и классифицируются в цифровом виде, а в доцифровую эпоху — выписывались на карточки. Поэтому большинство материалов существует в виде специализированных изданий, формат которых не позволяет ничего посмотреть или посчитать в текстах автоматически. Только некоторые из таких изданий были оцифрованы и стали доступны для широкой публики.
Волонтеры помогают расшифровывать оцифрованные тексты
В Латвии предложили масштабное и современное решение этой проблемы. В декабре 2014 года Фольклорный архив Латвии к своему 90-летию запустил портал garamantas.lv (garamantas означает духовное наследие или фольклор).
Оцифрованные сканы рукописных листов загружаются в специально разработанную систему, где указаны необходимые метаданные: номер коллекции в архиве, описание коллекции, номера соответствующих архивных единиц и др. Для волонтеров-расшифровщиков разработали подробную инструкцию, а интерфейс доступен на разных языках.
В архиве есть не только латышские материалы, но и ливские песни, русский и белорусский фольклор, тексты на идише и латышском цыганском. Поэтому для участия в расшифровке необязательно знать латышский: в объемной коллекции русского фольклора, собранной Иваном Фридрихом в Латгалии (восточной Латвии), еще достаточно нерасшифрованных текстов. Также, «переписывать» слова со сканов можно и вообще без знания языка.
В 2016 году запустили отдельные «дочерние» ресурсы проекта — «Кудесники столетия» и «Языковая толока» (Valodas talka). «Языковая толока» была направлена на школьников: в течение двух с половиной месяцев им предлагалось поучаствовать в расшифровке рукописей. К окончанию акции собрали статистику об участниках, и наградили самых активных призами. Таким образом удалось привлечь много новых участников и расшифровать более десяти тысяч отсканированных изображений.
Другие проекты фольклорного архива: читаем стихи и поём
В 2017 году, к 150-летию поэта Эдуарда Вейденбаума, запустили акцию «Читай вслух!». Суть акции такова: люди выбирали любое стихотворение из представленных на портале и читали его под запись. Получилась своеобразная база данных с записями латышской речи, хоть и ограниченная конечным списком стихотворных текстов: можно послушать один и тот же текст, зачитанный людьми разных возрастов и из разных мест.
Затем прошли еще две похожие акции: со стихами для детей латышских поэтов-классиков и со стихами столетней давности (написанными или опубликованными в 1919 году).
В начале 2019 года запустили проект «Пой с архивом»: теперь можно не только послушать отдельные музыкальные записи из коллекций архива, но и загрузить свою версию. Пока что на странице этого проекта доступно не очень много записей, но даже в них представлены записи, собранные не только в Латвии, и не только на латышском.
Вот, например, песня, записанная в сибирской латышской деревне Нижняя Буланка в 1991 году (ноты здесь). А вот версия известной латышской народной песни «Kur tu teci, gailīti mans» (Куда бежишь, мой петушок?) на латышском цыганском. Среди выложенных записей есть также песни на ливском, русском и белорусском.
Опыт Латвийского фольклорного архива в некоторой степени уникален — прежде всего благодаря материалу, который представлен в его коллекциях. В то же время он универсален как пример успешного привлечения обычных людей к работе с культурным наследием страны.
Наталья Перкова
{kind=link}
Индивидуальный стиль переводчика: как определить автора перевода
#philology
В задаче определения авторства хорошие результаты показывает метод Дельта, опубликованный в 2002 году. Теперь мы точно знаем, что Роберт Гэлбрейт — псевдоним Джоан Роулинг, а уверенность в том, что «Тихий Дон» написал Шолохов, а не Федор Крюков, сильно возросла. Вы и сами можете в этом убедиться: Дельту интегрировали в функции Stylo — библиотеку для языка R.
Сейчас ученые ищут способ точно определять автора перевода. В этой статье разбираемся:
1. Можно ли использовать метод Дельта для определения переводчика?
2. Какие еще инструменты могут помочь для решения этой задачи?
Метод Дельта
Возможности применения этого метода изучает филолог и стилометрист Дэвид Хувер в своем исследовании The Invisible Translator Revisited.
Он использует функцию classify — инструмент, который при помощи машинного обучения определяет, насколько точно он может угадать «класс» документа на основе стилометрических признаков. Классом может быть автор, переводчик, жанр, временной период, и т. д. Также классификатор нужно обучать — на тренировочной и тестовой выборках.
Ученый выяснил, что авторский сигнал сильнее сигнала переводчика, который «пробивается» из-под стиля автора только в определенных ситуациях.
Чтобы уловить именно отпечаток переводчика, нужно ослабить значимость автора. Для этого Дэвид Хувер создал выборки так, чтобы в тренировочной и тестовой выборках авторы произведений были разные, а переводчики — одинаковые.
В итоге две разные модели машинного обучения угадали переводчика в 81.2% и 93.9% случаев.
Метод Зета
У переводных текстов есть одна особенность: многие слова, которые часто встречаются у одного переводчика, избегаются другими, и то же верно наоборот. Такие слова называются отличительными словами.
Зета-анализ для нашей задачи работает так: он сравнивает, насколько постоянны включение и исключение набора отличительных слов в равных по размеру сегментах текста, на которые разделены произведения.
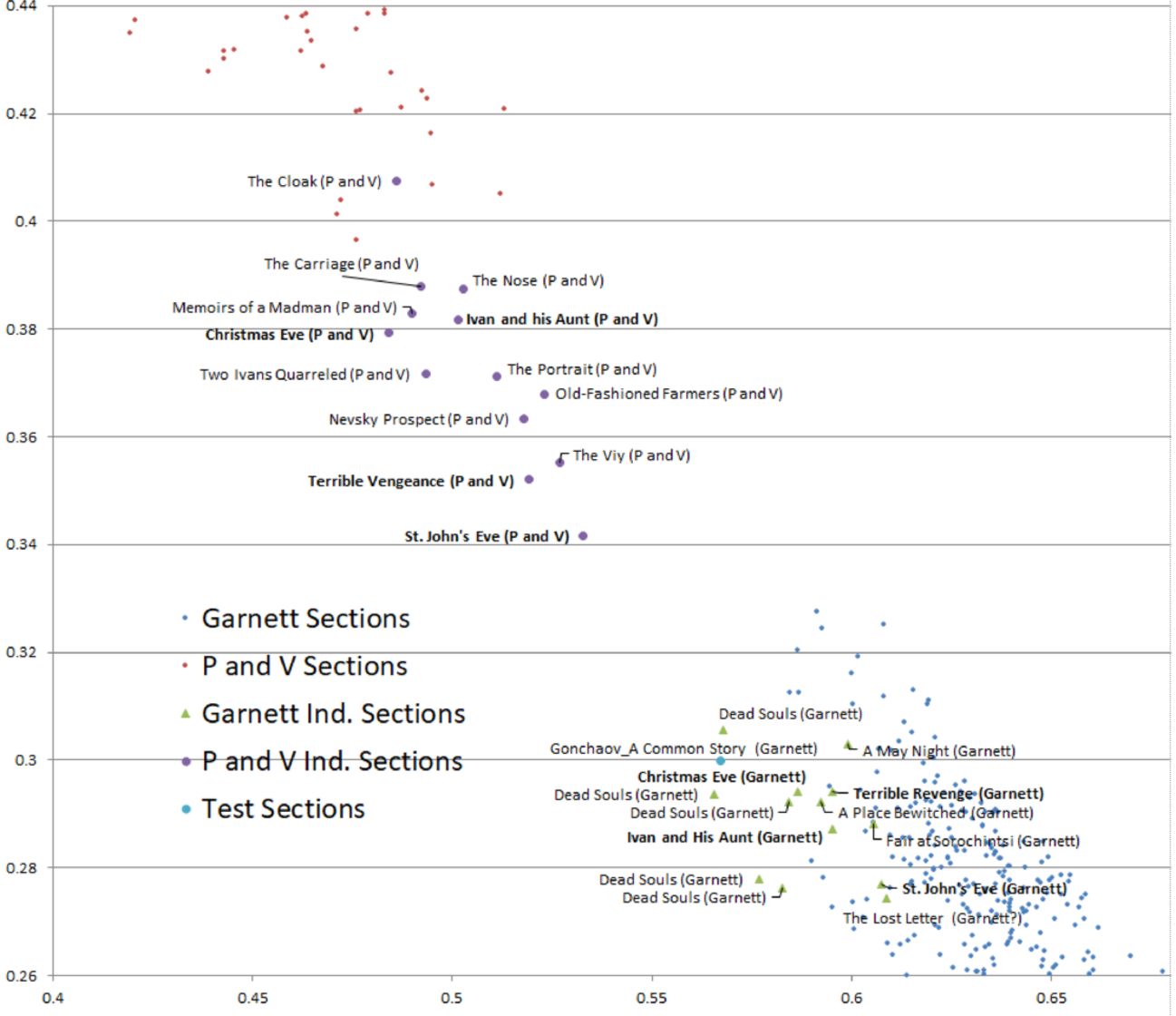
Если изобразить результат работы этого метода на графике (прикреплен ниже), то даже два перевода одного и того же текста разными переводчиками не будут находится рядом. Чем больше частотность отличительных слов, тем дальше их «разведет» по разным сторонам.
Полный рассказ с примерами и скриншотами по ссылке: https://sysblok.ru/philology/est-li-stil-u-perevodchika-a-esli-najdem/
#philology
В задаче определения авторства хорошие результаты показывает метод Дельта, опубликованный в 2002 году. Теперь мы точно знаем, что Роберт Гэлбрейт — псевдоним Джоан Роулинг, а уверенность в том, что «Тихий Дон» написал Шолохов, а не Федор Крюков, сильно возросла. Вы и сами можете в этом убедиться: Дельту интегрировали в функции Stylo — библиотеку для языка R.
Сейчас ученые ищут способ точно определять автора перевода. В этой статье разбираемся:
1. Можно ли использовать метод Дельта для определения переводчика?
2. Какие еще инструменты могут помочь для решения этой задачи?
Метод Дельта
Возможности применения этого метода изучает филолог и стилометрист Дэвид Хувер в своем исследовании The Invisible Translator Revisited.
Он использует функцию classify — инструмент, который при помощи машинного обучения определяет, насколько точно он может угадать «класс» документа на основе стилометрических признаков. Классом может быть автор, переводчик, жанр, временной период, и т. д. Также классификатор нужно обучать — на тренировочной и тестовой выборках.
Ученый выяснил, что авторский сигнал сильнее сигнала переводчика, который «пробивается» из-под стиля автора только в определенных ситуациях.
Чтобы уловить именно отпечаток переводчика, нужно ослабить значимость автора. Для этого Дэвид Хувер создал выборки так, чтобы в тренировочной и тестовой выборках авторы произведений были разные, а переводчики — одинаковые.
В итоге две разные модели машинного обучения угадали переводчика в 81.2% и 93.9% случаев.
Метод Зета
У переводных текстов есть одна особенность: многие слова, которые часто встречаются у одного переводчика, избегаются другими, и то же верно наоборот. Такие слова называются отличительными словами.
Зета-анализ для нашей задачи работает так: он сравнивает, насколько постоянны включение и исключение набора отличительных слов в равных по размеру сегментах текста, на которые разделены произведения.
Если изобразить результат работы этого метода на графике (прикреплен ниже), то даже два перевода одного и того же текста разными переводчиками не будут находится рядом. Чем больше частотность отличительных слов, тем дальше их «разведет» по разным сторонам.
Полный рассказ с примерами и скриншотами по ссылке: https://sysblok.ru/philology/est-li-stil-u-perevodchika-a-esli-najdem/
{kind=link}
Вся классика в один клик: как выделить из текста события
#philology
Школьники, зависающие на сайтах с краткими содержаниями, многое бы отдали за чудо-ресурс, которому можно было бы отдать художественное произведение и получить взамен описание событий в тексте. Рассказываем, как работает технология извлечения событий из художественных текстов и что она позволяет узнать о литературе уже сейчас.
Художественные произведения — сложный материал для анализа, так как они длинные, структура событий в них сложная и запутанная, а их первостепенная цель — эмоциональное воздействие на читателя.
Сбор и разметка данных
Ученые собрали корпус на основе текстов, публично доступных на ресурсе Project Gutenberg. В корпусе есть и произведения, относящиеся высокому литературному стилю («Улисс» Джеймса Джойса), и более массовая литература («Рваный Дик» Горацио Элджера). Все тексты были опубликованы до 1923 г. и из каждого взяты первые 2000 слов, чтобы уравнять все произведения.
Исследователи решили, что их интересуют события, действительно произошедшие в произведении. При разметке они руководствовались следующими правилами:
1. Полярность: размечались только произошедшие события с положительной полярностью. События-отрицания не размечались как произошедшие.
2. Грамматическое время: размечались события, выраженные глаголами в настоящем или прошедшем времени.
3. Универсальность: все универсальные события, описывающие обыденные действия, которые могли бы выглядеть и быть описаны абсолютно так же в другом произведении (например, собаки лаяли) не размечались.
4. Модальность: размечались только те события, о которых говорилось с уверенностью.
Помимо самих событий, авторы также размечали триггеры к ним — одно слово, которое может описать событие. В корпусе из 210 532 токенов-слов получилось 7 849 событий; результат разметки находится в открытом доступе.
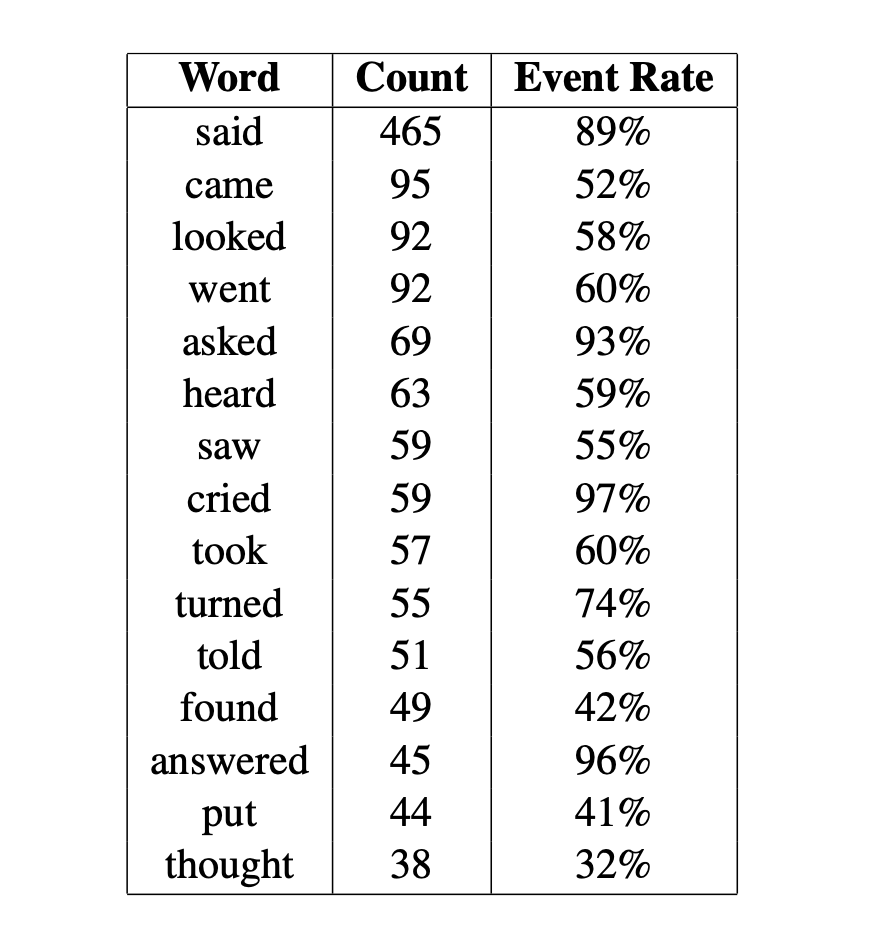
В результате оказалось, что большинство событий можно разбить на четыре категории: разговор, движение, восприятие и обладание. Таблица ниже показывает, как часто встречались слова из этих категорий.
Анализ событий с помощью нейросетей
Из полученного датасета сделали два набора признаковых описаний: в одном из них использовалось векторное описание слов, в другом, помимо векторного описания, были лингвистические признаки: часть речи, информация о контексте, информация о семантике слова, полученная при помощи WordNet, и специфическая информация о конкретном слове (например, если это bare plural — существительное во множественном числе, которое используется в основном для того, чтобы фраза получила универсальное прочтение: «Кошки любят молоко»).
Исследователи определили свою задачу как выявление связи между рассматриваемым словом и событием. Для этого использовались нейронные сети двух различных архитектур — одно- и двунаправленная LSTM и свёрточная нейронная сеть (CNN). В итоге лучшей комбинацией стала двунаправленная LSTM-сеть, в которой векторное описание слов было получено при помощи BERT — модели, которая для вычисления вектора слова также учитывает его контекст. Такая модель выделила события с F-мерой 73.9.
Дальнее чтение корпуса
Ученые решили посмотреть, отличаются ли предсказания сети для текстов разного уровня литературного мастерства.
В среднем в высокохудожественных произведениях оказалось чуть меньше событий (4.6% против 5.5%), которые чуть более подробно описаны: в среднем между двумя найденными событиями более «элитного» текста помещалось 23.4 слова, а в менее элитарных текстах — 19.2 слова.
Также авторы сравнили произведения, разделив их по популярности, но здесь различий не обнаружили: во всех текстах в среднем случалось около 4.5% событий примерно одной длины.
Дарья Максимова
https://sysblok.ru/philology/vsja-klassika-v-odin-klik-kak-vydelit-iz-teksta-sobytija/
#philology
Школьники, зависающие на сайтах с краткими содержаниями, многое бы отдали за чудо-ресурс, которому можно было бы отдать художественное произведение и получить взамен описание событий в тексте. Рассказываем, как работает технология извлечения событий из художественных текстов и что она позволяет узнать о литературе уже сейчас.
Художественные произведения — сложный материал для анализа, так как они длинные, структура событий в них сложная и запутанная, а их первостепенная цель — эмоциональное воздействие на читателя.
Сбор и разметка данных
Ученые собрали корпус на основе текстов, публично доступных на ресурсе Project Gutenberg. В корпусе есть и произведения, относящиеся высокому литературному стилю («Улисс» Джеймса Джойса), и более массовая литература («Рваный Дик» Горацио Элджера). Все тексты были опубликованы до 1923 г. и из каждого взяты первые 2000 слов, чтобы уравнять все произведения.
Исследователи решили, что их интересуют события, действительно произошедшие в произведении. При разметке они руководствовались следующими правилами:
1. Полярность: размечались только произошедшие события с положительной полярностью. События-отрицания не размечались как произошедшие.
2. Грамматическое время: размечались события, выраженные глаголами в настоящем или прошедшем времени.
3. Универсальность: все универсальные события, описывающие обыденные действия, которые могли бы выглядеть и быть описаны абсолютно так же в другом произведении (например, собаки лаяли) не размечались.
4. Модальность: размечались только те события, о которых говорилось с уверенностью.
Помимо самих событий, авторы также размечали триггеры к ним — одно слово, которое может описать событие. В корпусе из 210 532 токенов-слов получилось 7 849 событий; результат разметки находится в открытом доступе.
В результате оказалось, что большинство событий можно разбить на четыре категории: разговор, движение, восприятие и обладание. Таблица ниже показывает, как часто встречались слова из этих категорий.
Анализ событий с помощью нейросетей
Из полученного датасета сделали два набора признаковых описаний: в одном из них использовалось векторное описание слов, в другом, помимо векторного описания, были лингвистические признаки: часть речи, информация о контексте, информация о семантике слова, полученная при помощи WordNet, и специфическая информация о конкретном слове (например, если это bare plural — существительное во множественном числе, которое используется в основном для того, чтобы фраза получила универсальное прочтение: «Кошки любят молоко»).
Исследователи определили свою задачу как выявление связи между рассматриваемым словом и событием. Для этого использовались нейронные сети двух различных архитектур — одно- и двунаправленная LSTM и свёрточная нейронная сеть (CNN). В итоге лучшей комбинацией стала двунаправленная LSTM-сеть, в которой векторное описание слов было получено при помощи BERT — модели, которая для вычисления вектора слова также учитывает его контекст. Такая модель выделила события с F-мерой 73.9.
Дальнее чтение корпуса
Ученые решили посмотреть, отличаются ли предсказания сети для текстов разного уровня литературного мастерства.
В среднем в высокохудожественных произведениях оказалось чуть меньше событий (4.6% против 5.5%), которые чуть более подробно описаны: в среднем между двумя найденными событиями более «элитного» текста помещалось 23.4 слова, а в менее элитарных текстах — 19.2 слова.
Также авторы сравнили произведения, разделив их по популярности, но здесь различий не обнаружили: во всех текстах в среднем случалось около 4.5% событий примерно одной длины.
Дарья Максимова
https://sysblok.ru/philology/vsja-klassika-v-odin-klik-kak-vydelit-iz-teksta-sobytija/
{kind=link}
Как вычислить эмоции компьютерными методами
Рассказываем на примере анализа песен группы Битлз.
#philology
В 1996 году психолог Синтия Уиссел опубликовала статью, в которой сравнила между собой песни Пола МакКартни и Джона Леннона при помощи методов традиционной и эмоциональной стилометрии. В статье Уиссел пытается ответить на два вопроса:
1. Действительно ли песни Джона грустнее песен Пола?
2. Как менялась эмоциональная составляющая песен Битлз на протяжении четырех стадий их творчества (1962–1964, 1965–1966, 1967–1968, 1969–1970)?
Методы стилометрического анализа
Стилометрия часто использует измерения слова в качестве минимальной единицы. Из слова можно получить множество качеств для изучения текста: длину, частотность и др. Нас интересует коннотация. Коннотации каждого слова вычисляются разными способами опрашивания информантов. Затем результаты документируются в словарях эмоций (Dictionary of Affect). Один из таких словарей Уиссел сама и составила.
Измеряют коннотацию по трем шкалам: оценка, сила и активность. Вместе эти факторы описывают эмоцию человека по отношению к тому, что это слово обозначает, и их достаточно для дифференцирования значений большинства слов. У каждой шкалы две крайности: у оценки это «плохой» и «хороший», у силы — «сильный» и «слабый», а у активности — «активный» и «неактивный».
Для стилометрического исследования не обязательно рассматривать все три шкалы. В статье Уиссел рассматривает только оценку и активность, используя значения из своего словаря. Каждому слову в словаре даны значения на двух семибалльных шкалах: оценки и активности. К примеру, слово delighted ‘восхищенный’ имеет значения 6.4 (оценка) и 4.2 (активность), а gloomy ‘угрюмый’ — 3.2 (оценка) и 2.4 (активность).
Анализ текстов песен группы Битлз
Уиссел посчитала, какой процент наиболее «приятных» и наиболее «активных» слов (в топ 25% по оценке и активности соответственно) присутствует в их песнях на протяжении четырех периодов их творчества. Кроме того, она сконструировала из этих двух шкал еще четыре и тоже их подсчитала:
1. «Радостность» (Cheerfulness) — наиболее приятные и наиболее активные
2. «Гадкость» (Nastiness) — наименее приятные и наиболее активные
3. «Мягкость» (Softness) — наиболее приятные и наименее активные
4. «Грустность» (Sadness) — наименее приятные и наименее активные
Оказалось, что МакКартни использовал на 2% больше «приятных» слов, чем Леннон, который использовал больше «гадких», «мягких» и «грустных» слов.
Часы эмоций
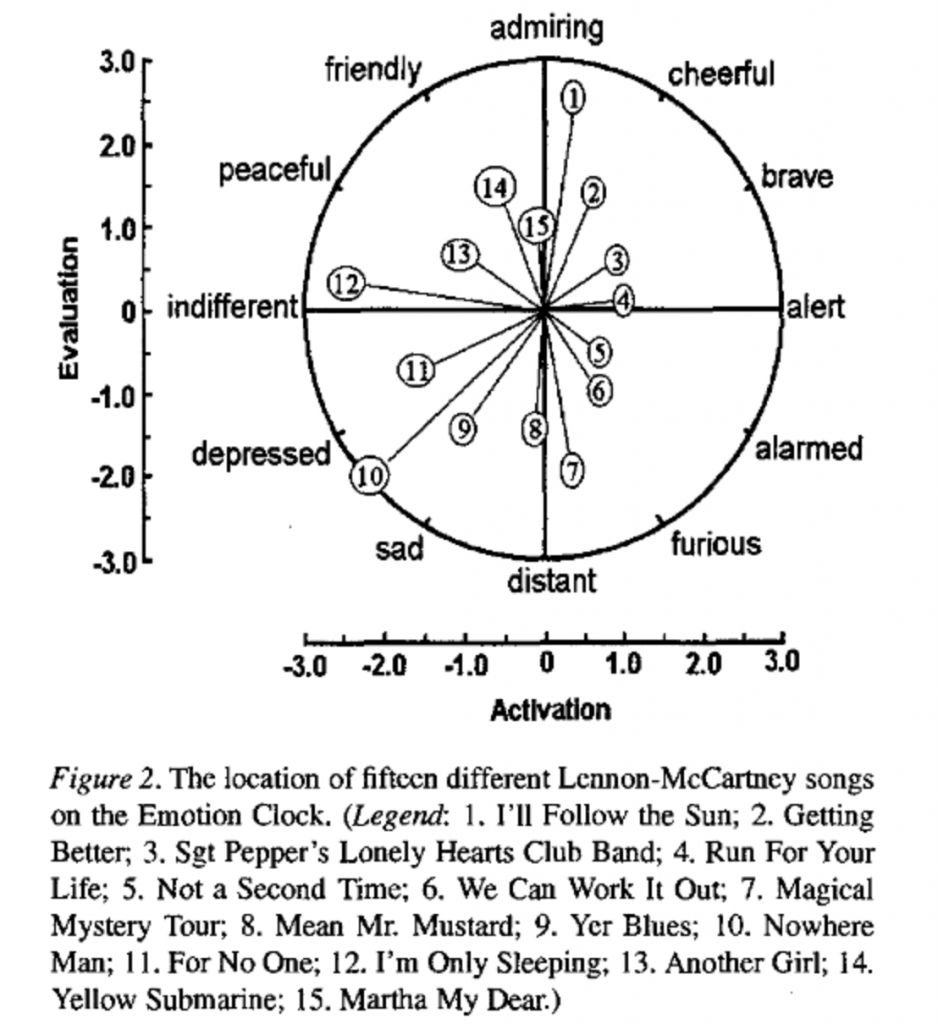
Для наглядной демонстрации результатов своих исследований Уиссел использовала т.н. часы эмоций. Схема прикреплена ниже.
Это пространство с двумя осями — оценки и активности. Значения, которые проставляются в этой системе координат, не абсолютные: они нормализованы относительно корпуса из около 50 текстов, включающих в себя художественную литературу, эссе студентов, описания людьми собственных эмоций.
Чем интенсивнее эмоции в тексте, тем вектор (т. е. расстояние от центра до точки, обозначающей текст) будет длиннее, а в зависимости от угла, который образует этот вектор, меняется и общее настроение текста. Для этого и нужна окружность, на которой обозначены различные эмоции.
В среднем все песни Битлз оказываются более «радостными», чем подобранный корпус. А по отдельности песни по-разному располагаются на часах: самой «депрессивной» оказывается песня Джона Леннона «Nowhere Man», самой «приятной» — песня Пола Маккартни «I’ll Follow the Sun».
Сложно понять, насколько эти данные достоверны. Однако интересно, что субъективное мнение критиков, что песни Джона более грустные, как будто подтверждается методами эмоциональной стилометрии. Если два разных подхода к анализу текстов приходят к одному выводу, оба подхода становятся легитимнее, и поэтому, возможно, у эмоциональной стилометрии есть право на существование.
Миша Сонькин
https://sysblok.ru/philology/kak-menjalis-pesni-bitlov-i-mozhno-li-vychislit-jemocii-kompjuternymi-metodami/
Рассказываем на примере анализа песен группы Битлз.
#philology
В 1996 году психолог Синтия Уиссел опубликовала статью, в которой сравнила между собой песни Пола МакКартни и Джона Леннона при помощи методов традиционной и эмоциональной стилометрии. В статье Уиссел пытается ответить на два вопроса:
1. Действительно ли песни Джона грустнее песен Пола?
2. Как менялась эмоциональная составляющая песен Битлз на протяжении четырех стадий их творчества (1962–1964, 1965–1966, 1967–1968, 1969–1970)?
Методы стилометрического анализа
Стилометрия часто использует измерения слова в качестве минимальной единицы. Из слова можно получить множество качеств для изучения текста: длину, частотность и др. Нас интересует коннотация. Коннотации каждого слова вычисляются разными способами опрашивания информантов. Затем результаты документируются в словарях эмоций (Dictionary of Affect). Один из таких словарей Уиссел сама и составила.
Измеряют коннотацию по трем шкалам: оценка, сила и активность. Вместе эти факторы описывают эмоцию человека по отношению к тому, что это слово обозначает, и их достаточно для дифференцирования значений большинства слов. У каждой шкалы две крайности: у оценки это «плохой» и «хороший», у силы — «сильный» и «слабый», а у активности — «активный» и «неактивный».
Для стилометрического исследования не обязательно рассматривать все три шкалы. В статье Уиссел рассматривает только оценку и активность, используя значения из своего словаря. Каждому слову в словаре даны значения на двух семибалльных шкалах: оценки и активности. К примеру, слово delighted ‘восхищенный’ имеет значения 6.4 (оценка) и 4.2 (активность), а gloomy ‘угрюмый’ — 3.2 (оценка) и 2.4 (активность).
Анализ текстов песен группы Битлз
Уиссел посчитала, какой процент наиболее «приятных» и наиболее «активных» слов (в топ 25% по оценке и активности соответственно) присутствует в их песнях на протяжении четырех периодов их творчества. Кроме того, она сконструировала из этих двух шкал еще четыре и тоже их подсчитала:
1. «Радостность» (Cheerfulness) — наиболее приятные и наиболее активные
2. «Гадкость» (Nastiness) — наименее приятные и наиболее активные
3. «Мягкость» (Softness) — наиболее приятные и наименее активные
4. «Грустность» (Sadness) — наименее приятные и наименее активные
Оказалось, что МакКартни использовал на 2% больше «приятных» слов, чем Леннон, который использовал больше «гадких», «мягких» и «грустных» слов.
Часы эмоций
Для наглядной демонстрации результатов своих исследований Уиссел использовала т.н. часы эмоций. Схема прикреплена ниже.
Это пространство с двумя осями — оценки и активности. Значения, которые проставляются в этой системе координат, не абсолютные: они нормализованы относительно корпуса из около 50 текстов, включающих в себя художественную литературу, эссе студентов, описания людьми собственных эмоций.
Чем интенсивнее эмоции в тексте, тем вектор (т. е. расстояние от центра до точки, обозначающей текст) будет длиннее, а в зависимости от угла, который образует этот вектор, меняется и общее настроение текста. Для этого и нужна окружность, на которой обозначены различные эмоции.
В среднем все песни Битлз оказываются более «радостными», чем подобранный корпус. А по отдельности песни по-разному располагаются на часах: самой «депрессивной» оказывается песня Джона Леннона «Nowhere Man», самой «приятной» — песня Пола Маккартни «I’ll Follow the Sun».
Сложно понять, насколько эти данные достоверны. Однако интересно, что субъективное мнение критиков, что песни Джона более грустные, как будто подтверждается методами эмоциональной стилометрии. Если два разных подхода к анализу текстов приходят к одному выводу, оба подхода становятся легитимнее, и поэтому, возможно, у эмоциональной стилометрии есть право на существование.
Миша Сонькин
https://sysblok.ru/philology/kak-menjalis-pesni-bitlov-i-mozhno-li-vychislit-jemocii-kompjuternymi-metodami/
{kind=link}
Поясни за смайлик: смех и слезы в интернете
#philology
Рассказываем, как люди начали пользоваться эмотиконами и как теперь их семантику изучают компьютерными методами. Посвящается тем, кто хотя бы раз не понял, что означает сообщение со смайликом.
В письменной речи смайлики — главный способ выражения эмоций: они заменяют интонацию и жесты; могут выступать в качестве слов или выражать отношение говорящего к ситуации.
Смайлики не всегда легко проинтерпретировать, однако и со словами может возникнуть та же проблема. Чтобы понять значение слова, мы обычно смотрим на контекст. Со смайликами этот метод тоже работает. Если контекст не помогает, можно обратиться к словарю.
Разработчики Unicode создали настоящий словарь с описаниями изображений, но вряд ли люди туда часто заглядывают, потому что у смайликов есть преимущество перед словами — визуальная информация. Глядя на слово, мы понимаем его значение, потому что оно уже хранится у нас в голове, а картинку мы сравниваем с образами из повседневной жизни и поэтому можем угадать значение по визуальному сходству.
Цифровые исследования семантики смайликов
Специалисты в области NLP используют эти идеи для переноса значения смайликов в машиночитаемый формат. Ученые уже давно пользуются моделями, которые переводят слово в вектор его контекста, то есть совместной встречаемости с другими словами. Word2vec — одна из самых популярных моделей такого типа, основанная на нейросетевых технологиях. Используемый в ней алгоритм Skip-Gram пытается предсказать контекст справа и слева по центральному слову.
Впервые анализ эмодзи провели в 2015 году. Томас Димсон, один из разработчиков Инстаграма, обучил word2vec на выборке в 50 млн комментариев и поделился результатами с пользователями. Оказалось, что самые популярные эмодзи довольно устойчиво ассоциируются с тем, что они изображают. Так, флаги стран соотносятся с хэштегами, содержащими их названия, а смеющиеся смайлики — с сокращениями ‘lol’, ‘lmao’ и различными вариациями смеха. Подробнее об этом исследовании — в нашей статье.
Чуть позже вышла статья группы испанских ученых под руководством Франческо Барбери. Ученые представили модель, обученную на текстах англоязычного Твиттера, и проанализировали результаты ее работы. Для оценки близости смайликов были предложены два критерия:
1. сходство (можно ли заменить один смайлик другим);
2. соотнесенность (можно ли встретить эти смайлики в одном контексте).
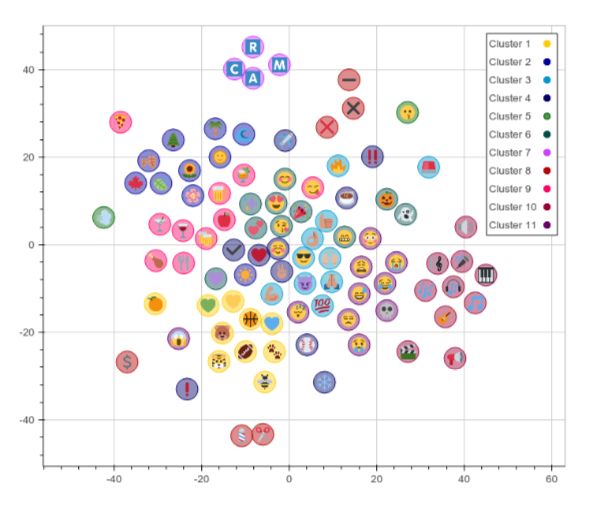
Группа респондентов также оценила 50 пар смайликов по этим двум критериям. Коэффициент корреляции между оценками людей и сходством, предсказанным моделью, оказался довольно высоким. Кроме того, авторы работы провели кластеризацию 100 самых популярных смайликов.
Чтобы было проще заметить близость изображений, авторы визуализировали векторы значений смайликов, предварительно сократив их размерность с 300 измерений до 2 при помощи метода t-SNE. Визуализация прикреплена ниже: чем ближе смайлики, тем больше они похожи. На графике видно, что модель довольно успешно объединяет в группы изображения еды, музыки, буквенных символов и растений.
Лондонские NLP-специалисты пошли другим путем. В 2016 году они представили своеобразное расширение для традиционной предобученной модели word2vec — emoji2vec. Ученые обучили модель на описании 1661 эмодзи. Emoji2vec значительно превосходит своего предшественника по предсказательной силе. Подход с анализом словарных статей для смайликов хорош тем, что он не зависит от кодировки смайлика: вектор значения, хранящийся в модели, един для различных вариантов одного изображения.
С 2019 года группа программистов из Индии занимается созданием модели, учитывающей как визуальное сходство смайликов, так и сходство векторных представлений их значений, однако попытки пока не увенчались успехом.
Аня Аксенова
Подробнее читайте по ссылке: https://sysblok.ru/philology/pojasni-za-smajlik-smeh-i-slezy-v-internete/
#philology
Рассказываем, как люди начали пользоваться эмотиконами и как теперь их семантику изучают компьютерными методами. Посвящается тем, кто хотя бы раз не понял, что означает сообщение со смайликом.
В письменной речи смайлики — главный способ выражения эмоций: они заменяют интонацию и жесты; могут выступать в качестве слов или выражать отношение говорящего к ситуации.
Смайлики не всегда легко проинтерпретировать, однако и со словами может возникнуть та же проблема. Чтобы понять значение слова, мы обычно смотрим на контекст. Со смайликами этот метод тоже работает. Если контекст не помогает, можно обратиться к словарю.
Разработчики Unicode создали настоящий словарь с описаниями изображений, но вряд ли люди туда часто заглядывают, потому что у смайликов есть преимущество перед словами — визуальная информация. Глядя на слово, мы понимаем его значение, потому что оно уже хранится у нас в голове, а картинку мы сравниваем с образами из повседневной жизни и поэтому можем угадать значение по визуальному сходству.
Цифровые исследования семантики смайликов
Специалисты в области NLP используют эти идеи для переноса значения смайликов в машиночитаемый формат. Ученые уже давно пользуются моделями, которые переводят слово в вектор его контекста, то есть совместной встречаемости с другими словами. Word2vec — одна из самых популярных моделей такого типа, основанная на нейросетевых технологиях. Используемый в ней алгоритм Skip-Gram пытается предсказать контекст справа и слева по центральному слову.
Впервые анализ эмодзи провели в 2015 году. Томас Димсон, один из разработчиков Инстаграма, обучил word2vec на выборке в 50 млн комментариев и поделился результатами с пользователями. Оказалось, что самые популярные эмодзи довольно устойчиво ассоциируются с тем, что они изображают. Так, флаги стран соотносятся с хэштегами, содержащими их названия, а смеющиеся смайлики — с сокращениями ‘lol’, ‘lmao’ и различными вариациями смеха. Подробнее об этом исследовании — в нашей статье.
Чуть позже вышла статья группы испанских ученых под руководством Франческо Барбери. Ученые представили модель, обученную на текстах англоязычного Твиттера, и проанализировали результаты ее работы. Для оценки близости смайликов были предложены два критерия:
1. сходство (можно ли заменить один смайлик другим);
2. соотнесенность (можно ли встретить эти смайлики в одном контексте).
Группа респондентов также оценила 50 пар смайликов по этим двум критериям. Коэффициент корреляции между оценками людей и сходством, предсказанным моделью, оказался довольно высоким. Кроме того, авторы работы провели кластеризацию 100 самых популярных смайликов.
Чтобы было проще заметить близость изображений, авторы визуализировали векторы значений смайликов, предварительно сократив их размерность с 300 измерений до 2 при помощи метода t-SNE. Визуализация прикреплена ниже: чем ближе смайлики, тем больше они похожи. На графике видно, что модель довольно успешно объединяет в группы изображения еды, музыки, буквенных символов и растений.
Лондонские NLP-специалисты пошли другим путем. В 2016 году они представили своеобразное расширение для традиционной предобученной модели word2vec — emoji2vec. Ученые обучили модель на описании 1661 эмодзи. Emoji2vec значительно превосходит своего предшественника по предсказательной силе. Подход с анализом словарных статей для смайликов хорош тем, что он не зависит от кодировки смайлика: вектор значения, хранящийся в модели, един для различных вариантов одного изображения.
С 2019 года группа программистов из Индии занимается созданием модели, учитывающей как визуальное сходство смайликов, так и сходство векторных представлений их значений, однако попытки пока не увенчались успехом.
Аня Аксенова
Подробнее читайте по ссылке: https://sysblok.ru/philology/pojasni-za-smajlik-smeh-i-slezy-v-internete/
{kind=link}
Лев Толстой онлайн: цифровые проекты о творчестве и жизни писателя
#philology
Портал tolstoy.ru — самый крупный ресурс о творчестве и деятельности писателя. Здесь собрана вся информация о жизни и творчестве писателя, а также о посвященных ему исследовательских проектах, музеях и событиях.
Проект «Весь Толстой в один клик»
Задача проекта «Весь Толстой в один клик» заключалась в оцифровке и распознавании текста в полном собрании сочинений Толстого. В основу легло единственное полное 90-томное собрание Л. Н. Толстого и том именного указателя. В него вошли все сохранившиеся и доступные на момент публикации произведения, рассказы, повести, дневники и письма.
Электронное собрание сочинений, а также дневники и записные книжки Толстого доступны на сайте tolstoy.ru для бесплатного скачивания в форматах PDF, FB2, MOBI и EPUB. А на сайте readingtolstoy.ru можно отметить себя на интерактивной карте читателей Толстого.
Веб-приложение «91-й том. Указатель к Толстому»
91-й том — это бумажный указатель к 90-томнику. Он состоит из указателей произведений, адресатов корреспонденции и других собственных имен, которые упоминает Толстой. Ресурс помогает пользователям и специалистам в исследовании жизни Толстого и связи между томами. Приложение также имеет своего бота в соцсети «Телеграм».
Акция «Каренина. Живое издание»
В начале октября 2014 года музей-усадьба Л. Н. Толстого «Ясная Поляна» и компания Google организовали масштабную акцию «Каренина. Живое издание». Впервые «Анну Каренину» прочли вслух за 36 часов в прямом эфире на платформах Google+ и YouTube. Их можно найти на YouTube под хэштегом #KareninaLive. Среди читателей были потомки Толстого, знаменитые артисты, спортсмены, музыканты, журналисты и даже государственные деятели.
Поисковик «Толстой Digital»
«Толстой Digital» — это семантическое издание, в котором тексты Толстого дополняются метаданными. Для писем, например, это дата и время написания и адресат, а в перспективе появится внутритекстовая семантическая разметка. Так тексты превратились в базу данных, которая позволяет «отвечать» на некоторые умные запросы пользователей. К примеру, ресурс показывает все письма Толстого Фету за определенный период времени.
Романы Толстого в приложении «Живые страницы»
Приложение «Живые страницы» превращает текст произведений в интерактивную литературную энциклопедию. В нем доступно три произведения Толстого: «Война и Мир», «Анна Каренина» и «Воскресение». В приложении можно отслеживать перемещение героев, смотреть календарь событий и карточки персонажей, проходить тесты и многое другое.
Проект «Приложения к музею. Студенты — Толстому»
Этот проект объединяет несколько проектов студентов ВШЭ.
Каторжный путь героев «Воскресения». Интерактивная карта, авторы которой воссоздали географический контекст произведения. На ней также отмечены все ключевые события романа.
География «Севастопольских рассказов». Интерактивная карта, создатели которой указали на ней места действий в рассказах и добавили материалы из дневников самого Толстого.
Путь Л. Н. Толстого. Интерактивная карта о путешествии писателя на протяжении жизни с текстовыми заметками и фотографиями.
Кулинарная книга Л. Н. Толстого. Авторы опирались на роман «Война и мир» и брали оттуда рецепты блюд. Получилось раскрытие кулинарных тайн XIX века.
Путешествие бельчонка Тима по усадьбе Л. Н. Толстого в Хамовниках. Детский аудиогид для детей до 8 лет. Он состоит из сказок Льва Николаевича, записей его голоса и музыки, а также содержит рассказы об экспонатах и истории московской усадьбы в Хамовниках.
Больше подробностей — в нашей статье: https://sysblok.ru/philology/lev-tolstoj-onlajn-cifrovye-proekty-o-tvorchestve-i-zhizni-pisatelja/
Варвара Гузий
#philology
Портал tolstoy.ru — самый крупный ресурс о творчестве и деятельности писателя. Здесь собрана вся информация о жизни и творчестве писателя, а также о посвященных ему исследовательских проектах, музеях и событиях.
Проект «Весь Толстой в один клик»
Задача проекта «Весь Толстой в один клик» заключалась в оцифровке и распознавании текста в полном собрании сочинений Толстого. В основу легло единственное полное 90-томное собрание Л. Н. Толстого и том именного указателя. В него вошли все сохранившиеся и доступные на момент публикации произведения, рассказы, повести, дневники и письма.
Электронное собрание сочинений, а также дневники и записные книжки Толстого доступны на сайте tolstoy.ru для бесплатного скачивания в форматах PDF, FB2, MOBI и EPUB. А на сайте readingtolstoy.ru можно отметить себя на интерактивной карте читателей Толстого.
Веб-приложение «91-й том. Указатель к Толстому»
91-й том — это бумажный указатель к 90-томнику. Он состоит из указателей произведений, адресатов корреспонденции и других собственных имен, которые упоминает Толстой. Ресурс помогает пользователям и специалистам в исследовании жизни Толстого и связи между томами. Приложение также имеет своего бота в соцсети «Телеграм».
Акция «Каренина. Живое издание»
В начале октября 2014 года музей-усадьба Л. Н. Толстого «Ясная Поляна» и компания Google организовали масштабную акцию «Каренина. Живое издание». Впервые «Анну Каренину» прочли вслух за 36 часов в прямом эфире на платформах Google+ и YouTube. Их можно найти на YouTube под хэштегом #KareninaLive. Среди читателей были потомки Толстого, знаменитые артисты, спортсмены, музыканты, журналисты и даже государственные деятели.
Поисковик «Толстой Digital»
«Толстой Digital» — это семантическое издание, в котором тексты Толстого дополняются метаданными. Для писем, например, это дата и время написания и адресат, а в перспективе появится внутритекстовая семантическая разметка. Так тексты превратились в базу данных, которая позволяет «отвечать» на некоторые умные запросы пользователей. К примеру, ресурс показывает все письма Толстого Фету за определенный период времени.
Романы Толстого в приложении «Живые страницы»
Приложение «Живые страницы» превращает текст произведений в интерактивную литературную энциклопедию. В нем доступно три произведения Толстого: «Война и Мир», «Анна Каренина» и «Воскресение». В приложении можно отслеживать перемещение героев, смотреть календарь событий и карточки персонажей, проходить тесты и многое другое.
Проект «Приложения к музею. Студенты — Толстому»
Этот проект объединяет несколько проектов студентов ВШЭ.
Каторжный путь героев «Воскресения». Интерактивная карта, авторы которой воссоздали географический контекст произведения. На ней также отмечены все ключевые события романа.
География «Севастопольских рассказов». Интерактивная карта, создатели которой указали на ней места действий в рассказах и добавили материалы из дневников самого Толстого.
Путь Л. Н. Толстого. Интерактивная карта о путешествии писателя на протяжении жизни с текстовыми заметками и фотографиями.
Кулинарная книга Л. Н. Толстого. Авторы опирались на роман «Война и мир» и брали оттуда рецепты блюд. Получилось раскрытие кулинарных тайн XIX века.
Путешествие бельчонка Тима по усадьбе Л. Н. Толстого в Хамовниках. Детский аудиогид для детей до 8 лет. Он состоит из сказок Льва Николаевича, записей его голоса и музыки, а также содержит рассказы об экспонатах и истории московской усадьбы в Хамовниках.
Больше подробностей — в нашей статье: https://sysblok.ru/philology/lev-tolstoj-onlajn-cifrovye-proekty-o-tvorchestve-i-zhizni-pisatelja/
Варвара Гузий
{kind=link}
Эволюция литературы: может ли Дарвин объяснить Конан Дойла и футуризм
#philology
В отличие от биологии, в филологии нет общепринятой теории эволюции литературы. Никто до конца не понимает, почему одни книги оказываются в центре внимания и входят в канон, другие остаются неизвестными, а третьи переживают период славы, но быстро забываются. Но были (и есть) те, кто пытается адаптировать теорию эволюции к анализу словесности. Рассказываем о двух подходах к объяснению эволюции литературы.
Подход формалистов
Юрий Тынянов, участник кружка формалистов, предложил смотреть на литературу как на поле со своими «центром» и «периферией», в рамках которого литературные тексты конкурируют друг с другом за место в центре литературного процесса. Согласно Тынянову, в центр далеко не всегда попадает самый «лучший» и образцовый литературный продукт. Наоборот: попасть в центр и сместить то, что было до него, имеет возможность скорее «патологическая» литература — нечто случайное, слабое и сначала даже не осознаваемое как литературный факт.
Таким образом формалисты вступают в скрытую полемику с дарвинизмом: по их мнению, в литературном процессе именно слабый и неприспособленный побеждает сильного и приспособленного, а не наоборот.
Дарвинистский подход
Современный социолог литературы Франко Моретти, наоборот, сравнивает процесс эволюции литературы с бойней, где мясниками оказываются «сами читатели, которые читают роман, А, (но не В, С, D, E, F, G, H…) и так поддерживают жизнь, А в следующем поколении». Получается, что роман «А» выживает из поколения в поколение, потому что именно к нему по той или иной причине приковано читательское внимание, и уже впоследствии роман «А» канонизируется академическим сообществом, а не наоборот.
Чтобы понять, почему одни художественные тексты выживают и читаются из поколения в поколение, а другие нет, рассмотрим два эксперимента, которые поставил Моретти.
Первый эксперимент: как Шерлок Холмс уцелел в бойне
Моретти вместе со студентами проанализировал нескольких десятков детективных рассказов, написанных в эпоху Конана Дойла. Они смотрели на то, как функционируют улики в этих рассказах, после чего разделили все рассказы на группы:
— рассказы с дешифруемыми уликами: на основе улик читатели самостоятельно могут прийти к разгадке;
— рассказы с функциональными уликами: улики помогают детективу (но не читателю) раскрыть дело;
— рассказы с упоминаемыми уликами: улики не выполняют никакой функции;
— рассказы без улик.
После анализа Моретти сделал следующие выводы: самой успешной категорией рассказов оказалась первая — рассказы с дешифруемыми уликами. В основном в этой группе оказались именно рассказы Конана Дойла. А отсутствие в детективных рассказах дешифруемых улик оказалось существенной причиной, по которой они не прошли «естественный отбор».
Второй эксперимент: эволюционные скачки
Расширив выборку, Моретти также замечает, что рассказы с дешифруемыми уликами в период с 1891 по 1900 не приживаются, а произведения без них появляются все чаще. Парадокс: то, что впоследствии победило литературных конкурентов и оказалось доминирующим, сначала вообще не воспринималось как нечто серьезное и важное в рамках литературного процесса.
Поэтому Моретти отказывается от дарвиновского принципа «природа не делает скачков» и заявляет, что литература развивается и меняется ТОЛЬКО через скачки. Подтверждает это феномен Агаты Кристи, укоренившей улики в детективе: «Скачок — Конан Дойл. Еще прыжок — Кристи», — пишет Моретти.
Дарвинизм и антидарвинизм в литературной эволюции: единство противоположностей
Кажется, что выводы, к которым пришел Моретти, не противоречат теории литературной эволюции, которую предложили формалисты. Открытие Моретти укладывается в теорию формальной школы: такой формальный прием, как дешифруемая улика, изначально находившийся на периферии, перемещается в центр литературного процесса.
https://sysblok.ru/philology/jevoljucija-literatury-mozhet-li-darvin-objasnit-konan-dojla-i-futurizm/
Вячеслав Кутепов
#philology
В отличие от биологии, в филологии нет общепринятой теории эволюции литературы. Никто до конца не понимает, почему одни книги оказываются в центре внимания и входят в канон, другие остаются неизвестными, а третьи переживают период славы, но быстро забываются. Но были (и есть) те, кто пытается адаптировать теорию эволюции к анализу словесности. Рассказываем о двух подходах к объяснению эволюции литературы.
Подход формалистов
Юрий Тынянов, участник кружка формалистов, предложил смотреть на литературу как на поле со своими «центром» и «периферией», в рамках которого литературные тексты конкурируют друг с другом за место в центре литературного процесса. Согласно Тынянову, в центр далеко не всегда попадает самый «лучший» и образцовый литературный продукт. Наоборот: попасть в центр и сместить то, что было до него, имеет возможность скорее «патологическая» литература — нечто случайное, слабое и сначала даже не осознаваемое как литературный факт.
Таким образом формалисты вступают в скрытую полемику с дарвинизмом: по их мнению, в литературном процессе именно слабый и неприспособленный побеждает сильного и приспособленного, а не наоборот.
Дарвинистский подход
Современный социолог литературы Франко Моретти, наоборот, сравнивает процесс эволюции литературы с бойней, где мясниками оказываются «сами читатели, которые читают роман, А, (но не В, С, D, E, F, G, H…) и так поддерживают жизнь, А в следующем поколении». Получается, что роман «А» выживает из поколения в поколение, потому что именно к нему по той или иной причине приковано читательское внимание, и уже впоследствии роман «А» канонизируется академическим сообществом, а не наоборот.
Чтобы понять, почему одни художественные тексты выживают и читаются из поколения в поколение, а другие нет, рассмотрим два эксперимента, которые поставил Моретти.
Первый эксперимент: как Шерлок Холмс уцелел в бойне
Моретти вместе со студентами проанализировал нескольких десятков детективных рассказов, написанных в эпоху Конана Дойла. Они смотрели на то, как функционируют улики в этих рассказах, после чего разделили все рассказы на группы:
— рассказы с дешифруемыми уликами: на основе улик читатели самостоятельно могут прийти к разгадке;
— рассказы с функциональными уликами: улики помогают детективу (но не читателю) раскрыть дело;
— рассказы с упоминаемыми уликами: улики не выполняют никакой функции;
— рассказы без улик.
После анализа Моретти сделал следующие выводы: самой успешной категорией рассказов оказалась первая — рассказы с дешифруемыми уликами. В основном в этой группе оказались именно рассказы Конана Дойла. А отсутствие в детективных рассказах дешифруемых улик оказалось существенной причиной, по которой они не прошли «естественный отбор».
Второй эксперимент: эволюционные скачки
Расширив выборку, Моретти также замечает, что рассказы с дешифруемыми уликами в период с 1891 по 1900 не приживаются, а произведения без них появляются все чаще. Парадокс: то, что впоследствии победило литературных конкурентов и оказалось доминирующим, сначала вообще не воспринималось как нечто серьезное и важное в рамках литературного процесса.
Поэтому Моретти отказывается от дарвиновского принципа «природа не делает скачков» и заявляет, что литература развивается и меняется ТОЛЬКО через скачки. Подтверждает это феномен Агаты Кристи, укоренившей улики в детективе: «Скачок — Конан Дойл. Еще прыжок — Кристи», — пишет Моретти.
Дарвинизм и антидарвинизм в литературной эволюции: единство противоположностей
Кажется, что выводы, к которым пришел Моретти, не противоречат теории литературной эволюции, которую предложили формалисты. Открытие Моретти укладывается в теорию формальной школы: такой формальный прием, как дешифруемая улика, изначально находившийся на периферии, перемещается в центр литературного процесса.
https://sysblok.ru/philology/jevoljucija-literatury-mozhet-li-darvin-objasnit-konan-dojla-i-futurizm/
Вячеслав Кутепов
{kind=link}
Цифровой Ван Гог: на грани вечности
#arts #philology
Винсент Ван Гог активно творил всего 10 лет, но его творчество оставило значительный след в живописи. Одни знают об этом художнике благодаря легенде об отрезанном ухе. Другие вспоминают его единственную проданную картину «Подсолнухи». Третьи — вдохновляется его биографией и поиском призвания как автора.
Представляем вашему вниманию проекты, которые будут полезны как исследователям, так и поклонникам мастера.
Литературный корпус «Vincent van Gogh. The Letters»
В основе литературного корпуса лежат письма, которые писал и получал Ван Гог в 1853–1890-е гг. Сейчас на сайте проекта находятся 903 письма, 820 из которых отправил сам Винсент. Каждому письму присвоили свой номер и добавили ссылки на копии/черновики/связанные материалы. Основными получателями были брат Тео и друзья-художники Поль Гоген и Эмиль Бернар.
Помимо писем, исследователи собрали материалы о самом художнике, архив его работ, черновиков (25 «родственных рукописей») и редакторских эссе, а также биографию Винсента и переписку его родственников.
Мультимедийные выставки
Жизнь и творчество Ван Гога распадается на два периода — мрачный голландский и яркий французский. Переписка с братом Тео демонстрирует изменения в мировоззрении художника и его отношении к творчеству.
Австралийская компания GRANDE EXHIBITIONS создала два мультимедийных проекта, посвященных жизни и творчеству Ван Гога. В обоих использовалась технология Cinema360. Изображения проецировались на экраны, стены, и пол, что визуально меняло геометрию зала и создавало эффект погружения.
Выставка «Ван Гог. Ожившие полотна» рассказывала о творчестве самого художника. В 2014 году в центральном зале центра дизайна ARTPLAY показали больше 3000 тематических изображений: картины мастера, письма и записи. Вместе с ними использовались звуковые эффекты: крики птиц, голоса людей, шелест и др.
Проект «Ван Гог. Письма к Тео» заострял внимание на отношениях художника с братом. К 400 картинам добавили закадровый текст в исполнении актера Владимира Зайцева, который также озвучивал Винсента в исполнении Уильяма Дефо в фильме «Ван Гог. На пороге вечности».
Фильм «Ван Гог: С любовью, Винсент»
«Ван Гог: С любовью, Винсент» — это полнометражный анимационный фильм, над которым трудилась команда из 100 художников. После съемок художники два года вручную отрисовывали масляными красками 62450 кадров на холсте согласно технике Ван Гога. Все кадры перетекает друг в друга, из-за чего фильм воспринимается как одна большая живая картина.
Сюжет повествует о событиях после гибели мастера. Сын старого почтальона берётся за расследование причины смерти Ван Гога. Для этого он приезжает в деревню, где Винсент жил в последнее время. В разговорах с очевидцами и свидетелями герой понимает, что виновник унёс с собой много тайн. Каждый рассказывает свою версию, которая не совпадает со словами других. Противоречия в рассказах наводят главного героя на мысль о возможном убийстве художника.
Глубокое погружение
Современные технологии позволили не только перенести картины Ван Гога на экран, но и проникнуть внутрь них. Цифровой художник Петрос Врелис создал интерактивное изображение «Звездной ночи». При прикосновении к сенсорному экрану зритель влияет на визуальную и звуковую составляющие: вместе с изменениями картины запускается музыка, которая создает эффект присутствия.
Автор Мак Каули пошёл дальше: на основе картины «Ночь в кафе» он создал видеоряд, который мы прикрепили ниже. Технология позволяет подробно изучить произведение изнутри, посмотреть на мир глазами Ван Гога и словно увидеть мгновение в движении.
В музее Ван Гога в Амстердаме посетители могут рассматривать картины под специальным микроскопом, который позволяет разглядеть каждый штрих и мазок на картине, волоски с кисточки, фактуры и объём краски на отдельных участках.
https://sysblok.ru/philology/cifrovoj-van-gog-na-grani-vechnosti/
Варвара Гузий
#arts #philology
Винсент Ван Гог активно творил всего 10 лет, но его творчество оставило значительный след в живописи. Одни знают об этом художнике благодаря легенде об отрезанном ухе. Другие вспоминают его единственную проданную картину «Подсолнухи». Третьи — вдохновляется его биографией и поиском призвания как автора.
Представляем вашему вниманию проекты, которые будут полезны как исследователям, так и поклонникам мастера.
Литературный корпус «Vincent van Gogh. The Letters»
В основе литературного корпуса лежат письма, которые писал и получал Ван Гог в 1853–1890-е гг. Сейчас на сайте проекта находятся 903 письма, 820 из которых отправил сам Винсент. Каждому письму присвоили свой номер и добавили ссылки на копии/черновики/связанные материалы. Основными получателями были брат Тео и друзья-художники Поль Гоген и Эмиль Бернар.
Помимо писем, исследователи собрали материалы о самом художнике, архив его работ, черновиков (25 «родственных рукописей») и редакторских эссе, а также биографию Винсента и переписку его родственников.
Мультимедийные выставки
Жизнь и творчество Ван Гога распадается на два периода — мрачный голландский и яркий французский. Переписка с братом Тео демонстрирует изменения в мировоззрении художника и его отношении к творчеству.
Австралийская компания GRANDE EXHIBITIONS создала два мультимедийных проекта, посвященных жизни и творчеству Ван Гога. В обоих использовалась технология Cinema360. Изображения проецировались на экраны, стены, и пол, что визуально меняло геометрию зала и создавало эффект погружения.
Выставка «Ван Гог. Ожившие полотна» рассказывала о творчестве самого художника. В 2014 году в центральном зале центра дизайна ARTPLAY показали больше 3000 тематических изображений: картины мастера, письма и записи. Вместе с ними использовались звуковые эффекты: крики птиц, голоса людей, шелест и др.
Проект «Ван Гог. Письма к Тео» заострял внимание на отношениях художника с братом. К 400 картинам добавили закадровый текст в исполнении актера Владимира Зайцева, который также озвучивал Винсента в исполнении Уильяма Дефо в фильме «Ван Гог. На пороге вечности».
Фильм «Ван Гог: С любовью, Винсент»
«Ван Гог: С любовью, Винсент» — это полнометражный анимационный фильм, над которым трудилась команда из 100 художников. После съемок художники два года вручную отрисовывали масляными красками 62450 кадров на холсте согласно технике Ван Гога. Все кадры перетекает друг в друга, из-за чего фильм воспринимается как одна большая живая картина.
Сюжет повествует о событиях после гибели мастера. Сын старого почтальона берётся за расследование причины смерти Ван Гога. Для этого он приезжает в деревню, где Винсент жил в последнее время. В разговорах с очевидцами и свидетелями герой понимает, что виновник унёс с собой много тайн. Каждый рассказывает свою версию, которая не совпадает со словами других. Противоречия в рассказах наводят главного героя на мысль о возможном убийстве художника.
Глубокое погружение
Современные технологии позволили не только перенести картины Ван Гога на экран, но и проникнуть внутрь них. Цифровой художник Петрос Врелис создал интерактивное изображение «Звездной ночи». При прикосновении к сенсорному экрану зритель влияет на визуальную и звуковую составляющие: вместе с изменениями картины запускается музыка, которая создает эффект присутствия.
Автор Мак Каули пошёл дальше: на основе картины «Ночь в кафе» он создал видеоряд, который мы прикрепили ниже. Технология позволяет подробно изучить произведение изнутри, посмотреть на мир глазами Ван Гога и словно увидеть мгновение в движении.
В музее Ван Гога в Амстердаме посетители могут рассматривать картины под специальным микроскопом, который позволяет разглядеть каждый штрих и мазок на картине, волоски с кисточки, фактуры и объём краски на отдельных участках.
https://sysblok.ru/philology/cifrovoj-van-gog-na-grani-vechnosti/
Варвара Гузий
YouTube
The Night Cafe - An Immersive VR Tribute to Vincent van Gogh
The Night Cafe is an immersive VR environment that allows you to explore the world of Vincent van Gogh first hand. Take a moment to enjoy his iconic sunflowe...
Цифровая филология 1910: как Андрей Белый вычислял отклонения ямба
#philology
Попытки применять точные методы в исследованиях стихотворений делались литературоведами задолго до возникновения компьютерных технологий и digital humanities. В начале XX века к точности в анализе поэтических текстов стремился русский поэт-символист Андрей Белый. Он одним из первых ввел в исследование стиха количественные методы.
Белый был не чужд математики. Он родился в семье декана физико-математического факультета Московского университета, и окончив гимназию, сам поступил на этот же факультет. Позднее, работая над теорией стиха, Андрей Белый решил охарактеризовать русский четырехстопный ямб методом, который сегодня назвали бы анализом данных. Он вручную проанализировал расстановку ударения в 16092 строках 27 отечественных поэтов.
Эволюция ямба
Для своего исследования Белый обратился к стихотворениям 27 отечественных поэтов, в которых доминирующим размером был четырехстопный ямб, и исследовал частотность и характеристику ускорений ямба в русской поэзии. Под ускорением Белый подразумевает наличие в стихотворении стопы, в которой есть лишний безударный слог — именно она и дает эффект ускорения, которое «слышит ухо». Пример ускорения на третьей стопе: «Чего-то ищет в небесах» (Тютчев).
Белый предлагает нам статистику по ускорениям на 596 строк у каждого поэта, отмечая частотность отклонений на той или иной стопе. Интересно, что правильный ямб составляет всего лишь 25% от всей выборки, а 75% приходится на ускорения от ямба. Как замечает Белый, именно через увеличение или уменьшение количества ускорений на той или иной стопе четырехстопный ямб и эволюционировал.
Всего Белый выделяет пять темпов, возможных при отклонении от ямба:
1. Наименьшее количество ускорений на первой стопе (13), максимальное на второй (139) и наименьшее количество ускорений на первой и третьей стопе одновременно (5) с максимальным на второй и третьей одновременно (11) было у Ломоносова;
2. К наибольшему количеству ускорений на первой стопе (46), максимальному на второй (139), наибольшему на первой и третьей одновременно (26) и наименьшему на второй и третьей стопе (1) пришел Державин;
3. Наименьшее количество отклонений на третьей стопе (230) демонстрирует Капнист;
4. Падение отклонений на второй стопе (33) и увеличение отклонений на третьей (313) показывает Батюшков;
5. Увеличение количества отклонений на второй и третьей стопах одновременно (44), много ускорений на второй стопе (52), и увеличение суммы ускорений первой стопы (99) замечаются у Жуковского.
Белый делает следующий вывод: беднота или, наоборот, обилие ускорений, во-первых, индивидуализирует стиль поэта и, во-вторых, реформирует четырехстопный ямб вообще, то есть задает те или иные «тренды» в написании стихотворений этим размером. Так главными его реформаторами оказываются Жуковский и Батюшков, но совсем не Пушкин. Пушкин только доводит начатую ими работу до конца: он повторяет сумму ускорений Батюшкова (33) и немного увеличивает ускорения третьей стопы (341) — так реформа завершается.
В русской поэзии первой половины XIX в., как замечает Белый, было стремление «увеличить до крайности ускорение первой стопы и уменьшить до крайности ускорение второй», которое проявилось в большей степени у Баратынского.
Белый также обнаружил, что отклонения от ямба образуют в стихотворениях различные геометрические фигуры, которые, вполне вероятно, могут сказать нам о содержании того или иного поэтического текста много нового. Об этом — в нашей статье: https://sysblok.ru/philology/cifrovaja-filologija-1910-kak-andrej-belyj-vychisljal-otklonenija-jamba/
Вячеслав Кутепов
#philology
Попытки применять точные методы в исследованиях стихотворений делались литературоведами задолго до возникновения компьютерных технологий и digital humanities. В начале XX века к точности в анализе поэтических текстов стремился русский поэт-символист Андрей Белый. Он одним из первых ввел в исследование стиха количественные методы.
Белый был не чужд математики. Он родился в семье декана физико-математического факультета Московского университета, и окончив гимназию, сам поступил на этот же факультет. Позднее, работая над теорией стиха, Андрей Белый решил охарактеризовать русский четырехстопный ямб методом, который сегодня назвали бы анализом данных. Он вручную проанализировал расстановку ударения в 16092 строках 27 отечественных поэтов.
Эволюция ямба
Для своего исследования Белый обратился к стихотворениям 27 отечественных поэтов, в которых доминирующим размером был четырехстопный ямб, и исследовал частотность и характеристику ускорений ямба в русской поэзии. Под ускорением Белый подразумевает наличие в стихотворении стопы, в которой есть лишний безударный слог — именно она и дает эффект ускорения, которое «слышит ухо». Пример ускорения на третьей стопе: «Чего-то ищет в небесах» (Тютчев).
Белый предлагает нам статистику по ускорениям на 596 строк у каждого поэта, отмечая частотность отклонений на той или иной стопе. Интересно, что правильный ямб составляет всего лишь 25% от всей выборки, а 75% приходится на ускорения от ямба. Как замечает Белый, именно через увеличение или уменьшение количества ускорений на той или иной стопе четырехстопный ямб и эволюционировал.
Всего Белый выделяет пять темпов, возможных при отклонении от ямба:
1. Наименьшее количество ускорений на первой стопе (13), максимальное на второй (139) и наименьшее количество ускорений на первой и третьей стопе одновременно (5) с максимальным на второй и третьей одновременно (11) было у Ломоносова;
2. К наибольшему количеству ускорений на первой стопе (46), максимальному на второй (139), наибольшему на первой и третьей одновременно (26) и наименьшему на второй и третьей стопе (1) пришел Державин;
3. Наименьшее количество отклонений на третьей стопе (230) демонстрирует Капнист;
4. Падение отклонений на второй стопе (33) и увеличение отклонений на третьей (313) показывает Батюшков;
5. Увеличение количества отклонений на второй и третьей стопах одновременно (44), много ускорений на второй стопе (52), и увеличение суммы ускорений первой стопы (99) замечаются у Жуковского.
Белый делает следующий вывод: беднота или, наоборот, обилие ускорений, во-первых, индивидуализирует стиль поэта и, во-вторых, реформирует четырехстопный ямб вообще, то есть задает те или иные «тренды» в написании стихотворений этим размером. Так главными его реформаторами оказываются Жуковский и Батюшков, но совсем не Пушкин. Пушкин только доводит начатую ими работу до конца: он повторяет сумму ускорений Батюшкова (33) и немного увеличивает ускорения третьей стопы (341) — так реформа завершается.
В русской поэзии первой половины XIX в., как замечает Белый, было стремление «увеличить до крайности ускорение первой стопы и уменьшить до крайности ускорение второй», которое проявилось в большей степени у Баратынского.
Белый также обнаружил, что отклонения от ямба образуют в стихотворениях различные геометрические фигуры, которые, вполне вероятно, могут сказать нам о содержании того или иного поэтического текста много нового. Об этом — в нашей статье: https://sysblok.ru/philology/cifrovaja-filologija-1910-kak-andrej-belyj-vychisljal-otklonenija-jamba/
Вячеслав Кутепов
{kind=link}
Ресурсы для цифровых стиховедов: поэтические корпуса
#philology #survey
Поэтический корпус — это электронная коллекция стихотворных текстов. Корпус отличается от электронной библиотеки тем, что в нем есть разметка. В поэтических корпусах размечают формальные показатели стиха: метрику, рифму, строфику. Общеизвестных доступных корпусов с такой разметкой четыре: поэтический подкорпус Национального корпуса русского языка (НКРЯ), а также Башкирский, Чешский и Персидский поэтические корпуса.
На базе поэтических корпусов проводятся количественные стиховедческие исследования, например, исследование семантического ореола метра, акцентологические исследования (исследования ударения), ставятся эксперименты по автоматическому определению авторства и изучается творчество отдельных поэтов.
Поэтический подкорпус НКРЯ
Поэтический корпус в составе Национального корпуса русского языка — первый в истории поэтический корпус. На данный момент объем корпуса — 89 124 текстов, 12 407 747 слов. В корпусе представлен 951 автор.
Стиховедческая разметка поэтического подкорпуса НКРЯ включает метр, строфику, клаузулы и другие параметры. Помимо стиховедческой, в поэтическом подкорпусе есть морфологическая и метатекстовая разметка (автор, дата создания, жанр). По метру, строфике, клаузуле и другим признакам можно искать информацию и задавать подкорпус. Определения сложных слов можно искать в терминологическом указателе.
В подкорпусе доступны полные тексты всех произведений. Напрямую из корпуса их скачать нельзя, но мы уже рассказывали, как написать программу для скачивания текстов.
Башкирский поэтический корпус
Объём Башкирского поэтического корпуса составляет более 1,8 млн слов. Коллекция текстов состоит из произведений 103 башкирских поэтов XX и начала XXI века. Авторские права на использованные стихотворения остаются за поэтами.
Для грамматического разбора словоформ Б. В. Орехов и А. А. Галлямов разработали систему автоматического морфологического анализа Bashmorph. А для поиска словоформ по базе была адаптирована поисковая система Восточноармянского национального корпуса, созданная компанией Corpus Technologies.
Тексты в корпусе снабжены морфологической разметкой и стиховедческой разметкой, которая позволяет осуществлять поиск в строках, написанных определенным метром, в зоне рифмовки и т. д. Корпус поддерживает два вида поиска — лексический и грамматический, можно искать как само слово, так и формы по определенным грамматическим признакам. Также есть возможность задавать корпус отдельного автора.
Чешский поэтический корпус
На данный момент в корпусе чешского стиха собраны тексты чешских поэтов XIX — начала XX веков, и его объем более 14,6 млн слов. Каждой словоформе в корпусе присвоена начальная форма данного слова, фонетическая транскрипция и грамматические категории; для каждого стиха определены метр, число стоп, тип клаузулы и метрическая схема.
На основе корпуса создано приложение «Эвфонометр». Эвфония — это учение о благозвучии, раздел поэтики, изучающий в стихе качественную сторону речевых звуков, накладывающих известную эмоциональную окраску на художественное произведение. С помощью Эвфонометра можно вычислить степень благозвучия любого поэтического текста в корпусе.
Персидский поэтический корпус
Персидский поэтический корпус был опубликован весной 2020 года и строился по той же модели, что и все предыдущие. Он содержит тексты классической персидской поэзии IX–XVII веков в объеме 4,3 млн словоупотреблений. Это 16 842 произведения или 330 723 бейта — так называется минимальная строфическая единица тюркской и персидской поэзии. Тексты морфологически размечены, доступен поиск по словам в позиции редифа и рифмы, часть текстов размечена метрически.
Больше подробностей — в нашей статье: https://sysblok.ru/philology/resursy-dlja-cifrovyh-stihovedov-pojeticheskie-korpusa/
Ольга Лисицкая
#philology #survey
Поэтический корпус — это электронная коллекция стихотворных текстов. Корпус отличается от электронной библиотеки тем, что в нем есть разметка. В поэтических корпусах размечают формальные показатели стиха: метрику, рифму, строфику. Общеизвестных доступных корпусов с такой разметкой четыре: поэтический подкорпус Национального корпуса русского языка (НКРЯ), а также Башкирский, Чешский и Персидский поэтические корпуса.
На базе поэтических корпусов проводятся количественные стиховедческие исследования, например, исследование семантического ореола метра, акцентологические исследования (исследования ударения), ставятся эксперименты по автоматическому определению авторства и изучается творчество отдельных поэтов.
Поэтический подкорпус НКРЯ
Поэтический корпус в составе Национального корпуса русского языка — первый в истории поэтический корпус. На данный момент объем корпуса — 89 124 текстов, 12 407 747 слов. В корпусе представлен 951 автор.
Стиховедческая разметка поэтического подкорпуса НКРЯ включает метр, строфику, клаузулы и другие параметры. Помимо стиховедческой, в поэтическом подкорпусе есть морфологическая и метатекстовая разметка (автор, дата создания, жанр). По метру, строфике, клаузуле и другим признакам можно искать информацию и задавать подкорпус. Определения сложных слов можно искать в терминологическом указателе.
В подкорпусе доступны полные тексты всех произведений. Напрямую из корпуса их скачать нельзя, но мы уже рассказывали, как написать программу для скачивания текстов.
Башкирский поэтический корпус
Объём Башкирского поэтического корпуса составляет более 1,8 млн слов. Коллекция текстов состоит из произведений 103 башкирских поэтов XX и начала XXI века. Авторские права на использованные стихотворения остаются за поэтами.
Для грамматического разбора словоформ Б. В. Орехов и А. А. Галлямов разработали систему автоматического морфологического анализа Bashmorph. А для поиска словоформ по базе была адаптирована поисковая система Восточноармянского национального корпуса, созданная компанией Corpus Technologies.
Тексты в корпусе снабжены морфологической разметкой и стиховедческой разметкой, которая позволяет осуществлять поиск в строках, написанных определенным метром, в зоне рифмовки и т. д. Корпус поддерживает два вида поиска — лексический и грамматический, можно искать как само слово, так и формы по определенным грамматическим признакам. Также есть возможность задавать корпус отдельного автора.
Чешский поэтический корпус
На данный момент в корпусе чешского стиха собраны тексты чешских поэтов XIX — начала XX веков, и его объем более 14,6 млн слов. Каждой словоформе в корпусе присвоена начальная форма данного слова, фонетическая транскрипция и грамматические категории; для каждого стиха определены метр, число стоп, тип клаузулы и метрическая схема.
На основе корпуса создано приложение «Эвфонометр». Эвфония — это учение о благозвучии, раздел поэтики, изучающий в стихе качественную сторону речевых звуков, накладывающих известную эмоциональную окраску на художественное произведение. С помощью Эвфонометра можно вычислить степень благозвучия любого поэтического текста в корпусе.
Персидский поэтический корпус
Персидский поэтический корпус был опубликован весной 2020 года и строился по той же модели, что и все предыдущие. Он содержит тексты классической персидской поэзии IX–XVII веков в объеме 4,3 млн словоупотреблений. Это 16 842 произведения или 330 723 бейта — так называется минимальная строфическая единица тюркской и персидской поэзии. Тексты морфологически размечены, доступен поиск по словам в позиции редифа и рифмы, часть текстов размечена метрически.
Больше подробностей — в нашей статье: https://sysblok.ru/philology/resursy-dlja-cifrovyh-stihovedov-pojeticheskie-korpusa/
Ольга Лисицкая
{kind=link}
Джеймс против Джойса: можно ли измерить сложность художественной литературы
#philology
Художественный текст сложный по определению, так как авторы используют средства художественной выразительности — метафоры, эксперименты с синтаксисом и лексической многозначностью, аллюзии и др. Кроме того, понимание сложности текста меняется. То, что было ново и непривычно для читателя начала XX века, читателя XXI века не удивит и покажется простым в восприятии.
В этой статье рассказываем, как исследователи из Кембриджского университета измеряли сложность разнообразных по жанру и стилю произведений английской литературы XIX–XX веков.
Индекс Флеша
Чтобы найти индекс Флеша, вычисляют среднюю длину предложений в тексте, а также количество слогов в словах. Подробнее об индексе Флеша мы уже рассказывали в другой нашей статье.
Выяснилось, что многие тексты первой половины XIX века, например, «Чувство и чувствительность» Остин, имеют по этому критерию показатели выше, чем у авангардных романов Джойса «Улисс» и «Поминки по Финнегану».
Поэтому меры удобочитаемости (readability) не дают объективной картины для художественной литературы.
Абстрактность используемых слов
Существует словарь, в котором слова размечены носителями языка по степени абстрактности-конкретности: испытуемые оценивали слова, ставя баллы от 1 до 5 напротив каждого слова. Каждый текст из выборки был оценен по среднему значению конкретности тех слов, которые есть и в словаре, и в самом тексте.
Вестерн Кормака Маккарни «Кровавый меридиан» предсказуемо оказался в самом верху шкалы конкретности. Однако авангардный «Улисс» соседствует с приключенческим романом «Остров сокровищ» Стивенсона, а степень конкретности Джойса остается одинаковой, несмотря на значительную эволюцию его стиля от реалистических «Дублинцев» до экспериментального романа «Поминки по Финнегану».
Этот факт ставит под сомнение тезис, что по лексической абстрактности можно судить о сложности текста.
Измерение культурного контекста
Исследователи Ewan Jones и Paul Nulty предлагают новую методику определения сложности художественного текста: они измеряют сложность текста в сравнении с окружающим его контекстом — большим текстовым корпусом. Для своей задачи исследователи использовали Google Books Fiction — раздел с английской художественной литературой с 1800 по 1915 год, который состоит из примерно 7.1 миллиардов токенов.
Ключевой параметр — относительная частота употребления слов: чем больше в тексте знакомых слов, тем текст для нас «предсказуемее», легче. Для каждого слова в датасете и в «испытуемых» произведениях из первых экспериментов вычисляется мера Ципфа: насколько часто встречается слово в конкретном произведении и насколько часто встречается оно же во всем корпусе. При этом учитываются только те слова, которые встречаются и там, и там.
Затем меру Ципфа в корпусе для каждого слова сравнили с мерой Ципфа каждого конкретного произведения. Наименьшее значение получил роман «Поминки по Финнегану» (Finnegan’s Wake) Джойса, а наибольшее — «Крылья голубки» (Wings of the dove) Джеймса.
Кажется, это значит, что Джойс максимально отличается от литературного контекста, а Джеймс максимально на него похож. Но это не так: близость к контексту определяется близостью к среднему значению, т. к. сравнивается относительная сложность произведений.
Наиболее близкий к контексту текст — это «Записки Пиквикского клуба» Диккенса: именно его показатель ближе всего к общему среднему по корпусу. А экстремумы — это непохожесть на контекст, причем эта непохожесть может быть как простотой, так и сложностью.
https://sysblok.ru/philology/dzhejms-protiv-dzhojsa-o-slozhnosti-v-hudozhestvennoj-literature/
Мария Захарова
#philology
Художественный текст сложный по определению, так как авторы используют средства художественной выразительности — метафоры, эксперименты с синтаксисом и лексической многозначностью, аллюзии и др. Кроме того, понимание сложности текста меняется. То, что было ново и непривычно для читателя начала XX века, читателя XXI века не удивит и покажется простым в восприятии.
В этой статье рассказываем, как исследователи из Кембриджского университета измеряли сложность разнообразных по жанру и стилю произведений английской литературы XIX–XX веков.
Индекс Флеша
Чтобы найти индекс Флеша, вычисляют среднюю длину предложений в тексте, а также количество слогов в словах. Подробнее об индексе Флеша мы уже рассказывали в другой нашей статье.
Выяснилось, что многие тексты первой половины XIX века, например, «Чувство и чувствительность» Остин, имеют по этому критерию показатели выше, чем у авангардных романов Джойса «Улисс» и «Поминки по Финнегану».
Поэтому меры удобочитаемости (readability) не дают объективной картины для художественной литературы.
Абстрактность используемых слов
Существует словарь, в котором слова размечены носителями языка по степени абстрактности-конкретности: испытуемые оценивали слова, ставя баллы от 1 до 5 напротив каждого слова. Каждый текст из выборки был оценен по среднему значению конкретности тех слов, которые есть и в словаре, и в самом тексте.
Вестерн Кормака Маккарни «Кровавый меридиан» предсказуемо оказался в самом верху шкалы конкретности. Однако авангардный «Улисс» соседствует с приключенческим романом «Остров сокровищ» Стивенсона, а степень конкретности Джойса остается одинаковой, несмотря на значительную эволюцию его стиля от реалистических «Дублинцев» до экспериментального романа «Поминки по Финнегану».
Этот факт ставит под сомнение тезис, что по лексической абстрактности можно судить о сложности текста.
Измерение культурного контекста
Исследователи Ewan Jones и Paul Nulty предлагают новую методику определения сложности художественного текста: они измеряют сложность текста в сравнении с окружающим его контекстом — большим текстовым корпусом. Для своей задачи исследователи использовали Google Books Fiction — раздел с английской художественной литературой с 1800 по 1915 год, который состоит из примерно 7.1 миллиардов токенов.
Ключевой параметр — относительная частота употребления слов: чем больше в тексте знакомых слов, тем текст для нас «предсказуемее», легче. Для каждого слова в датасете и в «испытуемых» произведениях из первых экспериментов вычисляется мера Ципфа: насколько часто встречается слово в конкретном произведении и насколько часто встречается оно же во всем корпусе. При этом учитываются только те слова, которые встречаются и там, и там.
Затем меру Ципфа в корпусе для каждого слова сравнили с мерой Ципфа каждого конкретного произведения. Наименьшее значение получил роман «Поминки по Финнегану» (Finnegan’s Wake) Джойса, а наибольшее — «Крылья голубки» (Wings of the dove) Джеймса.
Кажется, это значит, что Джойс максимально отличается от литературного контекста, а Джеймс максимально на него похож. Но это не так: близость к контексту определяется близостью к среднему значению, т. к. сравнивается относительная сложность произведений.
Наиболее близкий к контексту текст — это «Записки Пиквикского клуба» Диккенса: именно его показатель ближе всего к общему среднему по корпусу. А экстремумы — это непохожесть на контекст, причем эта непохожесть может быть как простотой, так и сложностью.
https://sysblok.ru/philology/dzhejms-protiv-dzhojsa-o-slozhnosti-v-hudozhestvennoj-literature/
Мария Захарова
{kind=link}