
Семантические сдвиги и предсказание военных конфликтов — в интервью с Андреем Кутузовым
Значение слов постоянно меняется, отражаясь в контекстах. Следом меняются и типичные ассоциации, связанные со словами.
Цифровые методы позволяют отследить эти изменения. Классический пример — слово «cell», которое сначала означало только «тюремную камеру», потом постепенно начало появляться в значении «биологическая клетка», а вот в конце 90-х — начале 2000-х письменные тексты захлестнула волна использования слова «cell» в значении «сотовый телефон».
Системный Блокъ взял интервью у Андрея Кутузова, создателя сайта RusVectōrēs, постдока и сотрудника группы языковых технологий в университете Осло.
О чем мы поговорили в интервью с Андреем:
● о диахронических семантических сдвигах — как изучать изменения значений слов с течением времени.
● о том, как даже простые дистрибутивные модели выявляют тонкие семантические отношения.
● о предсказании вооруженных конфликтов. Оказывается, что семантические сдвиги предшествуют вооруженным конфликтам, а значит, теоретически могут их предсказывать.
https://sysblok.ru/interviews/oblast-v-kotoroj-ja-rabotaju-rozhdaetsja-prjamo-na-glazah/
Значение слов постоянно меняется, отражаясь в контекстах. Следом меняются и типичные ассоциации, связанные со словами.
Цифровые методы позволяют отследить эти изменения. Классический пример — слово «cell», которое сначала означало только «тюремную камеру», потом постепенно начало появляться в значении «биологическая клетка», а вот в конце 90-х — начале 2000-х письменные тексты захлестнула волна использования слова «cell» в значении «сотовый телефон».
Системный Блокъ взял интервью у Андрея Кутузова, создателя сайта RusVectōrēs, постдока и сотрудника группы языковых технологий в университете Осло.
О чем мы поговорили в интервью с Андреем:
● о диахронических семантических сдвигах — как изучать изменения значений слов с течением времени.
● о том, как даже простые дистрибутивные модели выявляют тонкие семантические отношения.
● о предсказании вооруженных конфликтов. Оказывается, что семантические сдвиги предшествуют вооруженным конфликтам, а значит, теоретически могут их предсказывать.
https://sysblok.ru/interviews/oblast-v-kotoroj-ja-rabotaju-rozhdaetsja-prjamo-na-glazah/
{kind=link}
5 российских библиотек с богатыми цифровыми коллекциями
Оцифровка культурных данных — необходимая база для цифровых гуманитарных исследований. Делимся списком крупных коллекций, созданных российскими библиотеками.
1. Национальная электронная библиотека
В разделе «Коллекции» размещены тематические подборки самых разнообразных изданий и документов. Например: «Русская классика», «Редкие и ценные издания», «Московская электронная нотная библиотека», «Собрание картографических материалов» и др.
Для книг, находящихся в общественном достоянии, доступна опция «скачать» (в формате pdf или epub). Книги, находящиеся в ограниченном доступе, можно изучать в читальных залах библиотек, подключенных к НЭБ (спросите в библиотеке по соседству — скорее всего, она подключена). С лета этого года из библиотек открылся доступ и к коллекции диссертаций.
2. Российская национальная библиотека
В разделе «Электронные коллекции» множество подборок, в том числе с редкими историческими источниками. Тут есть коллекции «Епархиальных ведомостей» и «Памятных книжек губерний Российской империи», «Аудиозаписи российского музыкального фольклора», коллекция материалов о Санкт-Петербурге, огромный массив художественной литературы.
Документы доступны для просмотра онлайн в приложении Vivaldi. Чтобы выбрать только те документы, которые можно просмотреть на сайте, отметьте в фильтре «Отображать только электронные копии».
3. Президентская библиотека
Библиотека специализируется на книгах и документах по истории российской государственности и русского языка. Среди онлайн-коллекций этой библиотеки — собрания книг, периодических изданий и архивных документов, связанные с жизнью и деятельностью крупнейших российских писателей, ученых, художников, музыкантов, государственных деятелей и многих других.
Например, в коллекции, посвященной А.П. Чехову, есть подборка его портретов и фотографий, исторические публикации, посвященные юбилейным датам, открытки с изображением памятников Чехову и т.д. А в разделе «Аудиовизуальные материалы» можно, например, посмотреть старую кинохронику или редкие документальные фильмы.
Книги и материалы доступны лишь для онлайн-просмотра на сайте, возможности скачивания нет.
4. Государственная публичная историческая библиотека
Историческая библиотека предлагает электронное собрание документов и материалов по отечественной и всеобщей истории, генеалогии, геральдике, истории военного дела, этнографии и географии России.
В разделе «Коллекции» есть подборки материалов по истории Первой мировой войны, русских революций, генеалогические и биографические справочники, коллекции листовок, иллюстрированные периодические издания, газеты.
Например, коллекция газет русского зарубежья включает издания из множества стран мира на русском языке.Коллекция библиотеки доступна для онлайн-просмотра на сайте. Скачивание возможно лишь постранично в формате jpeg.
5. Электронекрасовка
Среди книг и документов, оцифрованных московской Библиотекой им. Н.А. Некрасова — издания 1610–1961 годов, уникальные коллекции книг, журналов и газет. Здесь есть подборки «О театре», «История одежды», «Детская полка», «Фотокниги», «Шрифты и типографика», «Московское метро» и множество других.
Особенно выделяется коллекция периодики: многие из этих изданий впервые стали доступны в электронном виде именно благодаря «Электронекрасовке». Все электронные документы можно и просматривать на сайте, и скачать в формате pdf.
Оцифровка культурных данных — необходимая база для цифровых гуманитарных исследований. Делимся списком крупных коллекций, созданных российскими библиотеками.
1. Национальная электронная библиотека
В разделе «Коллекции» размещены тематические подборки самых разнообразных изданий и документов. Например: «Русская классика», «Редкие и ценные издания», «Московская электронная нотная библиотека», «Собрание картографических материалов» и др.
Для книг, находящихся в общественном достоянии, доступна опция «скачать» (в формате pdf или epub). Книги, находящиеся в ограниченном доступе, можно изучать в читальных залах библиотек, подключенных к НЭБ (спросите в библиотеке по соседству — скорее всего, она подключена). С лета этого года из библиотек открылся доступ и к коллекции диссертаций.
2. Российская национальная библиотека
В разделе «Электронные коллекции» множество подборок, в том числе с редкими историческими источниками. Тут есть коллекции «Епархиальных ведомостей» и «Памятных книжек губерний Российской империи», «Аудиозаписи российского музыкального фольклора», коллекция материалов о Санкт-Петербурге, огромный массив художественной литературы.
Документы доступны для просмотра онлайн в приложении Vivaldi. Чтобы выбрать только те документы, которые можно просмотреть на сайте, отметьте в фильтре «Отображать только электронные копии».
3. Президентская библиотека
Библиотека специализируется на книгах и документах по истории российской государственности и русского языка. Среди онлайн-коллекций этой библиотеки — собрания книг, периодических изданий и архивных документов, связанные с жизнью и деятельностью крупнейших российских писателей, ученых, художников, музыкантов, государственных деятелей и многих других.
Например, в коллекции, посвященной А.П. Чехову, есть подборка его портретов и фотографий, исторические публикации, посвященные юбилейным датам, открытки с изображением памятников Чехову и т.д. А в разделе «Аудиовизуальные материалы» можно, например, посмотреть старую кинохронику или редкие документальные фильмы.
Книги и материалы доступны лишь для онлайн-просмотра на сайте, возможности скачивания нет.
4. Государственная публичная историческая библиотека
Историческая библиотека предлагает электронное собрание документов и материалов по отечественной и всеобщей истории, генеалогии, геральдике, истории военного дела, этнографии и географии России.
В разделе «Коллекции» есть подборки материалов по истории Первой мировой войны, русских революций, генеалогические и биографические справочники, коллекции листовок, иллюстрированные периодические издания, газеты.
Например, коллекция газет русского зарубежья включает издания из множества стран мира на русском языке.Коллекция библиотеки доступна для онлайн-просмотра на сайте. Скачивание возможно лишь постранично в формате jpeg.
5. Электронекрасовка
Среди книг и документов, оцифрованных московской Библиотекой им. Н.А. Некрасова — издания 1610–1961 годов, уникальные коллекции книг, журналов и газет. Здесь есть подборки «О театре», «История одежды», «Детская полка», «Фотокниги», «Шрифты и типографика», «Московское метро» и множество других.
Особенно выделяется коллекция периодики: многие из этих изданий впервые стали доступны в электронном виде именно благодаря «Электронекрасовке». Все электронные документы можно и просматривать на сайте, и скачать в формате pdf.
{kind=link}
Шпионаж и слежка 400 лет назад
Спецслужбы собирают данные огромного количества людей и делают выводы на основе не только содержания, но и метаданных. А как найти шпиона по метаданным среди 20000 корреспондентов архива писем эпохи Тюдоров, если вам лень читать архив вручную?
Письма в архиве структурированы в xml формате. Учёные отделили только те, у которых заполнены метаданные «автор» и «получатель». Многие адресаты появлялись под несколькими именами, в течение жизни накапливая титулы. Потребовалась восемнадцать месяцев, чтобы разобрать, кто есть кто. Изначальный архив содержал 37101 уникальное имя корреспондентов, в процессе выяснилось, что на самом деле переписывалось только 20656 человек.
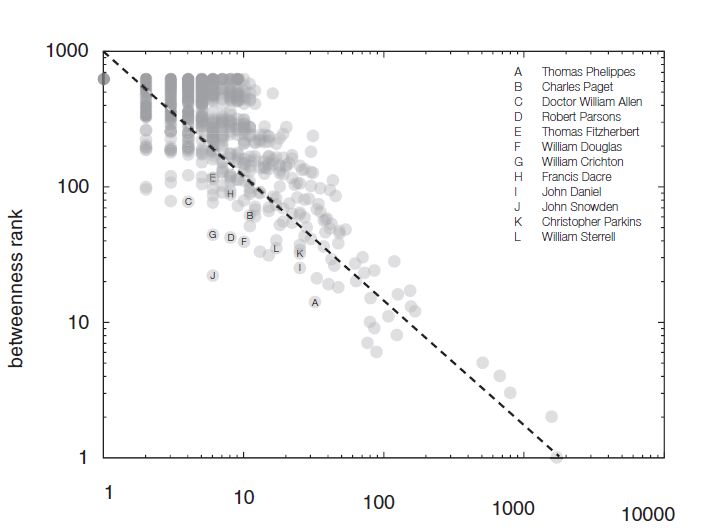
Для поиска аномалий среди корреспондентов использовался сетевой анализ. Наиболее полезными оказались метрики степень (то есть количество людей, которые получали или отправляли письма данному человеку) и промежуточность (сколько кратчайших путей от узла к узлу проходит через данный узел). О метриках сетевого анализа мы подробно писали тут.
Наиболее интересным для исследователей оказался график, где степень узла ставится в зависимость от его промежуточности. То есть шпионов выдаёт то, что через них курсировала информация от слишком большого числа людей. Среди попавших в список лиц — миссионеры, священники, дипломаты и послы.
https://sysblok.ru/history/shpionazh-i-slezhka-400-let-nazad-i-pochemu-jeto-vazhno-znat-segodnja/
Спецслужбы собирают данные огромного количества людей и делают выводы на основе не только содержания, но и метаданных. А как найти шпиона по метаданным среди 20000 корреспондентов архива писем эпохи Тюдоров, если вам лень читать архив вручную?
Письма в архиве структурированы в xml формате. Учёные отделили только те, у которых заполнены метаданные «автор» и «получатель». Многие адресаты появлялись под несколькими именами, в течение жизни накапливая титулы. Потребовалась восемнадцать месяцев, чтобы разобрать, кто есть кто. Изначальный архив содержал 37101 уникальное имя корреспондентов, в процессе выяснилось, что на самом деле переписывалось только 20656 человек.
Для поиска аномалий среди корреспондентов использовался сетевой анализ. Наиболее полезными оказались метрики степень (то есть количество людей, которые получали или отправляли письма данному человеку) и промежуточность (сколько кратчайших путей от узла к узлу проходит через данный узел). О метриках сетевого анализа мы подробно писали тут.
Наиболее интересным для исследователей оказался график, где степень узла ставится в зависимость от его промежуточности. То есть шпионов выдаёт то, что через них курсировала информация от слишком большого числа людей. Среди попавших в список лиц — миссионеры, священники, дипломаты и послы.
https://sysblok.ru/history/shpionazh-i-slezhka-400-let-nazad-i-pochemu-jeto-vazhno-znat-segodnja/
{kind=link}
«Особый праздник для бритья»: из чего сделаны поздравления с 23 февраля
В прошлом году мы анализировали поздравления с 8 марта — и подтвердили свои подозрения: «женский» праздник давно превратился из дня борьбы за равные права в день приторных восхищений женственностью и сексистских пожеланий «рожать детей» и «украшать» собой жизнь.
Теперь настала очередь поздравлений с 23 февраля. Стихотворные поздравления с Днем защитника Отечества — не менее одиозный жанр, чем сексистские вирши на 8 марта или слащавые стишки на День святого Валентина. Что можно сказать о пожеланиях на 23 февраля на основе данных и количественного анализа?
Что мы исследовали
Мы собрали тексты с сайта, который выпал первым в выдаче Google по запросу «поздравление с 23 февраля». Коллекция текстов, которую мы исследовали, состоит из 903 поздравлений. Всего в них 39 518 слов — 7 196 уникальных словоформ. Мы решили изучить её традиционным для корпусных исследований способом — посчитали частотности слов.
Мы привели все слова в нашем корпусе к начальной форме. Служебные слова вроде союзов, предлогов, частиц и местоимений мы отфильтровали. Еще убрали некоторые типовые поздравительные слова (поздравлять, желать, день, праздник и т.п.).
Сильный и крепкий защитник: пожелания в цифрах
Дальше мы исследовали частотности для отдельных частей речи. Начали с прилагательных. Как помнят читатели нашего прошлогоднего 8-мартовского исследования, там лидировали прекрасный, нежный и красивый, а слова, характеризующие силу, ум и успех, оказались гораздо ниже.
С поздравлениями на 23 февраля ситуация иная — здесь доминирует именно сила. Прилагательное сильный лидирует с большим отрывом. Также в топ-5 хороший, смелый, любимый и крепкий. Кажется, это неудивительно, учитывая военное происхождение праздника и невытравимую идею разделения полов на «сильный» и «слабый».
В списке частотных глаголов лидер тоже предсказуем — это глагол защищать. За ним с большим отрывом следуют жить, любить, ждать и хранить. В общем, День защитника Отечества — это про защиту и силу, и только потом — про любовь. «Военно-патриотическую» тематику отражают и другие глаголы в этом топе: служить, хранить. Симптоматично появление глагола ждать: идея ожидания человека, призванного на службу/войну, безусловно, одна из стержневых в русской околовоенной лирике («Жди меня», «Темная ночь» и мн. др.) и литературе в целом.
«Воевать за монитором желаю счастья»
Мы решили посмотреть, возможно ли получить по-настоящему душевные пожелания на такой коллекции слов, и сгенерировали свой текст на основе исходных данных. Для генерации мы использовали самый простой способ — цепи Маркова.
Из результатов генерации мы собрали свою подборку поздравлений с 23 февраля. Ведь, в конце концов, люди ищут «оригинальные» поздравления — а что может быть оригинальнее, чем текст, синтезированный только что на наших глазах? Вот несколько примеров:
Поздравляю тебя через край.
Будь отважным героем для успеха, любви и взаимной любви.
Воевать за монитором, желаю счастья.
Пусть ВБР будет полна любовью!
В феврале особый праздник для бритья,
Февральский ветер лишь преследует тебя.
Познакомиться с остальными результатами генерации, изучить графики частотностей слов, а также посмотреть на любопытные примеры народной поздравительной поэзии вы можете по ссылке:
https://sysblok.ru/society/eshhe-muzhchinestee-byt-iz-chego-sdelany-pozdravlenija-s-23-fevralja/
В прошлом году мы анализировали поздравления с 8 марта — и подтвердили свои подозрения: «женский» праздник давно превратился из дня борьбы за равные права в день приторных восхищений женственностью и сексистских пожеланий «рожать детей» и «украшать» собой жизнь.
Теперь настала очередь поздравлений с 23 февраля. Стихотворные поздравления с Днем защитника Отечества — не менее одиозный жанр, чем сексистские вирши на 8 марта или слащавые стишки на День святого Валентина. Что можно сказать о пожеланиях на 23 февраля на основе данных и количественного анализа?
Что мы исследовали
Мы собрали тексты с сайта, который выпал первым в выдаче Google по запросу «поздравление с 23 февраля». Коллекция текстов, которую мы исследовали, состоит из 903 поздравлений. Всего в них 39 518 слов — 7 196 уникальных словоформ. Мы решили изучить её традиционным для корпусных исследований способом — посчитали частотности слов.
Мы привели все слова в нашем корпусе к начальной форме. Служебные слова вроде союзов, предлогов, частиц и местоимений мы отфильтровали. Еще убрали некоторые типовые поздравительные слова (поздравлять, желать, день, праздник и т.п.).
Сильный и крепкий защитник: пожелания в цифрах
Дальше мы исследовали частотности для отдельных частей речи. Начали с прилагательных. Как помнят читатели нашего прошлогоднего 8-мартовского исследования, там лидировали прекрасный, нежный и красивый, а слова, характеризующие силу, ум и успех, оказались гораздо ниже.
С поздравлениями на 23 февраля ситуация иная — здесь доминирует именно сила. Прилагательное сильный лидирует с большим отрывом. Также в топ-5 хороший, смелый, любимый и крепкий. Кажется, это неудивительно, учитывая военное происхождение праздника и невытравимую идею разделения полов на «сильный» и «слабый».
В списке частотных глаголов лидер тоже предсказуем — это глагол защищать. За ним с большим отрывом следуют жить, любить, ждать и хранить. В общем, День защитника Отечества — это про защиту и силу, и только потом — про любовь. «Военно-патриотическую» тематику отражают и другие глаголы в этом топе: служить, хранить. Симптоматично появление глагола ждать: идея ожидания человека, призванного на службу/войну, безусловно, одна из стержневых в русской околовоенной лирике («Жди меня», «Темная ночь» и мн. др.) и литературе в целом.
«Воевать за монитором желаю счастья»
Мы решили посмотреть, возможно ли получить по-настоящему душевные пожелания на такой коллекции слов, и сгенерировали свой текст на основе исходных данных. Для генерации мы использовали самый простой способ — цепи Маркова.
Из результатов генерации мы собрали свою подборку поздравлений с 23 февраля. Ведь, в конце концов, люди ищут «оригинальные» поздравления — а что может быть оригинальнее, чем текст, синтезированный только что на наших глазах? Вот несколько примеров:
Поздравляю тебя через край.
Будь отважным героем для успеха, любви и взаимной любви.
Воевать за монитором, желаю счастья.
Пусть ВБР будет полна любовью!
В феврале особый праздник для бритья,
Февральский ветер лишь преследует тебя.
Познакомиться с остальными результатами генерации, изучить графики частотностей слов, а также посмотреть на любопытные примеры народной поздравительной поэзии вы можете по ссылке:
https://sysblok.ru/society/eshhe-muzhchinestee-byt-iz-chego-sdelany-pozdravlenija-s-23-fevralja/
{kind=link}
Берлинале-2020 глазами российских и американских критиков
#arts #visualisation
29 февраля завершился 70-й Берлинский кинофестиваль. Программа вышла разнообразная — здесь и вызвавший этические споры в Берлине «Дау. Наташа», и новое переложение культового немецкого романа «Берлин, Александерплац» из 1920-х в контекст современной Европы, и многое другое. Иранская лента об ужасах тоталитарного режима «Зла не существует» получила в этом году главный приз — Золотого Медведя.
Вместе с журналом «Искусство Кино» @kinoartru «Системный Блокъ» подготовил инфографику с оценками фильмов конкурсной программы фестиваля. Мы использовали оценки российских критиков, собранные на сайте Искусства Кино, и Tomatometer — совокупный рейтинг сайта Rotten Tomatoes, составленный на основе отзывов американских критиков. Российские критики оценивали ленты по пятибалльной шкале, далее считалась средняя оценка для каждого фильма. Tomatometer представлен в виде оценки по стобалльной шкале, поэтому мы перевели её в пятибалльную шкалу для более удобного сравнения: например, у фильма «Первая корова» Tomatometer равен 91 из 100, т.е. (91/100) * 5 = 4,6 из 5.
Интересно, что российские критики оценили фильм-победитель Берлинале довольно сдержанно — на 3 балла. Американские критики и вовсе не уделяют ему должного внимания — рейтинг для этого фильма пока не доступен, как и ещё для пяти фильмов-участников (он становится видимым только после того, как ленту оценят хотя бы 5 экспертов).
Наибольший разрыв между оценками российских и американских критиков наблюдается у фильма «Чужак» («The Intruder») — средняя оценка российских кинокритиков составила всего 2,2 балла, в то время как рейтинг их американских коллег составил 3,8 балла (75 из 100). А вот оценка фильма «DAU. Наташа» Ильи Хржановского от российских критиков оказалась на полбалла выше, чем оценка американских — и это наибольший разрыв в обратную сторону.
Данные
1. Оценки фильмов, данные российскими критиками
2. Рейтинг фильмов с сайта Rotten Tomatoes
#arts #visualisation
29 февраля завершился 70-й Берлинский кинофестиваль. Программа вышла разнообразная — здесь и вызвавший этические споры в Берлине «Дау. Наташа», и новое переложение культового немецкого романа «Берлин, Александерплац» из 1920-х в контекст современной Европы, и многое другое. Иранская лента об ужасах тоталитарного режима «Зла не существует» получила в этом году главный приз — Золотого Медведя.
Вместе с журналом «Искусство Кино» @kinoartru «Системный Блокъ» подготовил инфографику с оценками фильмов конкурсной программы фестиваля. Мы использовали оценки российских критиков, собранные на сайте Искусства Кино, и Tomatometer — совокупный рейтинг сайта Rotten Tomatoes, составленный на основе отзывов американских критиков. Российские критики оценивали ленты по пятибалльной шкале, далее считалась средняя оценка для каждого фильма. Tomatometer представлен в виде оценки по стобалльной шкале, поэтому мы перевели её в пятибалльную шкалу для более удобного сравнения: например, у фильма «Первая корова» Tomatometer равен 91 из 100, т.е. (91/100) * 5 = 4,6 из 5.
Интересно, что российские критики оценили фильм-победитель Берлинале довольно сдержанно — на 3 балла. Американские критики и вовсе не уделяют ему должного внимания — рейтинг для этого фильма пока не доступен, как и ещё для пяти фильмов-участников (он становится видимым только после того, как ленту оценят хотя бы 5 экспертов).
Наибольший разрыв между оценками российских и американских критиков наблюдается у фильма «Чужак» («The Intruder») — средняя оценка российских кинокритиков составила всего 2,2 балла, в то время как рейтинг их американских коллег составил 3,8 балла (75 из 100). А вот оценка фильма «DAU. Наташа» Ильи Хржановского от российских критиков оказалась на полбалла выше, чем оценка американских — и это наибольший разрыв в обратную сторону.
Данные
1. Оценки фильмов, данные российскими критиками
2. Рейтинг фильмов с сайта Rotten Tomatoes
{kind=link}
Отставной козы продюсер: как сделать генератор заголовков для Дарьи Донцовой
У компьютерной лингвистики много применений: от поисковиков до банков, от права до филологии. А еще ее можно использовать для бесполезных, но смешных задач. Например, мы сделали генератор названий книг Дарьи Донцовой. Местами программа справляется не хуже человека. А все потому, что алгоритм не просто порождает случайные комбинации — он воспроизводит творческий процесс.
Как устроены названия книг Донцовой?
Посмотрите на этот список:
— Дьявол носит лапти
— Депутат кислых щей
— Мопс в мешке
— Чудеса в кастрюльке
— Дискета всё стерпит
Здесь есть настоящие книги Донцовой, а есть — выдуманные алгоритмом (угадаете, где какие?). Все они устроены похоже. Это устойчивые выражения, в которых одно слово заменено на близкое по смыслу: был профессор кислых щей — стал депутат. Часто так же делают заголовки в газетах.
Как устроен алгоритм?
Новые слова появляются в названиях не случайно: они связаны с сюжетом книг. Поэтому логично сделать так: на вход программе будет приходить то слово, которое мы хотим увидеть в сгенерированном названии. А дальше пусть алгоритм подбирает под это слово какую-нибудь поговорку или фразеологизм, где есть что-то похожее по смыслу. Например, написали сникерс — получили «кнут и сникерс» (вместо «кнута и пряника»).
Как мы делали генератор?
1. Мы взяли список фразеологизмов русского языка, а также заглавия ста классических книг (у Донцовой бывают названия с отсылками к классике: «Лягушка Баскервилей», «Пролетая над гнездом Индюшки»...). Из наших списков мы отобрали строчки длиной в 3-5 слов: они больше подходят под формат названий.
2. Для определения семантической близости слов использовали векторную модель (подробнее о векторных моделях) от команды @RusVectores. Мы взяли модель, обученную на Википедии и Национальном корпусе русского языка. Она умеет понимать, что сникерс и пряник ближе, чем сникерс и помидор, а кукушка похожа на индюшку.
3. Чтобы названия были грамматически согласованы, мы применили морфологический анализатор pymorphy2. В программе мы задали условие: ищем только слова в именительном падеже и с тем же родом, что у предложенного нами слова. Это помогло нам избавиться от случаев типа «моя коттедж с краю».
Что получилось?
Во-первых, раскроем интригу. Не Донцовой, а бездушным алгоритмом порождены три из пяти названий, которые мы показывали в начале: «Депутат кислых щей», «Мопс в мешке» и «Дискета всё стерпит». А вот еще несколько примеров работы генератора (ввод => выдача):
мартышка => где мартышка зарыта
телепузик => телепузик на побегушках
продюсер => отставной козы продюсер
Радует, что «Продюсер козьей морды» — это самое что ни на есть настоящее название книги Донцовой. Так что машина отлично проникла в логику человека.
Подробнее об устройстве алгоритма, а также ошибках, которые он допускает, и возможных доработках читайте тут:
https://sysblok.ru/philology/otstavnoj-kozy-prodjuser-generiruem-nazvanija-knig-dari-doncovoj/
Мария Подрядчикова
У компьютерной лингвистики много применений: от поисковиков до банков, от права до филологии. А еще ее можно использовать для бесполезных, но смешных задач. Например, мы сделали генератор названий книг Дарьи Донцовой. Местами программа справляется не хуже человека. А все потому, что алгоритм не просто порождает случайные комбинации — он воспроизводит творческий процесс.
Как устроены названия книг Донцовой?
Посмотрите на этот список:
— Дьявол носит лапти
— Депутат кислых щей
— Мопс в мешке
— Чудеса в кастрюльке
— Дискета всё стерпит
Здесь есть настоящие книги Донцовой, а есть — выдуманные алгоритмом (угадаете, где какие?). Все они устроены похоже. Это устойчивые выражения, в которых одно слово заменено на близкое по смыслу: был профессор кислых щей — стал депутат. Часто так же делают заголовки в газетах.
Как устроен алгоритм?
Новые слова появляются в названиях не случайно: они связаны с сюжетом книг. Поэтому логично сделать так: на вход программе будет приходить то слово, которое мы хотим увидеть в сгенерированном названии. А дальше пусть алгоритм подбирает под это слово какую-нибудь поговорку или фразеологизм, где есть что-то похожее по смыслу. Например, написали сникерс — получили «кнут и сникерс» (вместо «кнута и пряника»).
Как мы делали генератор?
1. Мы взяли список фразеологизмов русского языка, а также заглавия ста классических книг (у Донцовой бывают названия с отсылками к классике: «Лягушка Баскервилей», «Пролетая над гнездом Индюшки»...). Из наших списков мы отобрали строчки длиной в 3-5 слов: они больше подходят под формат названий.
2. Для определения семантической близости слов использовали векторную модель (подробнее о векторных моделях) от команды @RusVectores. Мы взяли модель, обученную на Википедии и Национальном корпусе русского языка. Она умеет понимать, что сникерс и пряник ближе, чем сникерс и помидор, а кукушка похожа на индюшку.
3. Чтобы названия были грамматически согласованы, мы применили морфологический анализатор pymorphy2. В программе мы задали условие: ищем только слова в именительном падеже и с тем же родом, что у предложенного нами слова. Это помогло нам избавиться от случаев типа «моя коттедж с краю».
Что получилось?
Во-первых, раскроем интригу. Не Донцовой, а бездушным алгоритмом порождены три из пяти названий, которые мы показывали в начале: «Депутат кислых щей», «Мопс в мешке» и «Дискета всё стерпит». А вот еще несколько примеров работы генератора (ввод => выдача):
мартышка => где мартышка зарыта
телепузик => телепузик на побегушках
продюсер => отставной козы продюсер
Радует, что «Продюсер козьей морды» — это самое что ни на есть настоящее название книги Донцовой. Так что машина отлично проникла в логику человека.
Подробнее об устройстве алгоритма, а также ошибках, которые он допускает, и возможных доработках читайте тут:
https://sysblok.ru/philology/otstavnoj-kozy-prodjuser-generiruem-nazvanija-knig-dari-doncovoj/
Мария Подрядчикова
{kind=link}
Краудсорсинг в Digital Humanities: опыт Латвийского фольклорного архива
#nlp #philology
Из фольклорных и диалектологических экспедиций ученые привозят множество материалов — тетрадей и аудиозаписей — и передают их в научные институты и университеты. Сейчас записи расшифровываются и классифицируются в цифровом виде, а в доцифровую эпоху — выписывались на карточки. Поэтому большинство материалов существует в виде специализированных изданий, формат которых не позволяет ничего посмотреть или посчитать в текстах автоматически. Только некоторые из таких изданий были оцифрованы и стали доступны для широкой публики.
Волонтеры помогают расшифровывать оцифрованные тексты
В Латвии предложили масштабное и современное решение этой проблемы. В декабре 2014 года Фольклорный архив Латвии к своему 90-летию запустил портал garamantas.lv (garamantas означает духовное наследие или фольклор).
Оцифрованные сканы рукописных листов загружаются в специально разработанную систему, где указаны необходимые метаданные: номер коллекции в архиве, описание коллекции, номера соответствующих архивных единиц и др. Для волонтеров-расшифровщиков разработали подробную инструкцию, а интерфейс доступен на разных языках.
В архиве есть не только латышские материалы, но и ливские песни, русский и белорусский фольклор, тексты на идише и латышском цыганском. Поэтому для участия в расшифровке необязательно знать латышский: в объемной коллекции русского фольклора, собранной Иваном Фридрихом в Латгалии (восточной Латвии), еще достаточно нерасшифрованных текстов. Также, «переписывать» слова со сканов можно и вообще без знания языка.
В 2016 году запустили отдельные «дочерние» ресурсы проекта — «Кудесники столетия» и «Языковая толока» (Valodas talka). «Языковая толока» была направлена на школьников: в течение двух с половиной месяцев им предлагалось поучаствовать в расшифровке рукописей. К окончанию акции собрали статистику об участниках, и наградили самых активных призами. Таким образом удалось привлечь много новых участников и расшифровать более десяти тысяч отсканированных изображений.
Другие проекты фольклорного архива: читаем стихи и поём
В 2017 году, к 150-летию поэта Эдуарда Вейденбаума, запустили акцию «Читай вслух!». Суть акции такова: люди выбирали любое стихотворение из представленных на портале и читали его под запись. Получилась своеобразная база данных с записями латышской речи, хоть и ограниченная конечным списком стихотворных текстов: можно послушать один и тот же текст, зачитанный людьми разных возрастов и из разных мест.
Затем прошли еще две похожие акции: со стихами для детей латышских поэтов-классиков и со стихами столетней давности (написанными или опубликованными в 1919 году).
В начале 2019 года запустили проект «Пой с архивом»: теперь можно не только послушать отдельные музыкальные записи из коллекций архива, но и загрузить свою версию. Пока что на странице этого проекта доступно не очень много записей, но даже в них представлены записи, собранные не только в Латвии, и не только на латышском.
Вот, например, песня, записанная в сибирской латышской деревне Нижняя Буланка в 1991 году (ноты здесь). А вот версия известной латышской народной песни «Kur tu teci, gailīti mans» (Куда бежишь, мой петушок?) на латышском цыганском. Среди выложенных записей есть также песни на ливском, русском и белорусском.
Опыт Латвийского фольклорного архива в некоторой степени уникален — прежде всего благодаря материалу, который представлен в его коллекциях. В то же время он универсален как пример успешного привлечения обычных людей к работе с культурным наследием страны.
Наталья Перкова
#nlp #philology
Из фольклорных и диалектологических экспедиций ученые привозят множество материалов — тетрадей и аудиозаписей — и передают их в научные институты и университеты. Сейчас записи расшифровываются и классифицируются в цифровом виде, а в доцифровую эпоху — выписывались на карточки. Поэтому большинство материалов существует в виде специализированных изданий, формат которых не позволяет ничего посмотреть или посчитать в текстах автоматически. Только некоторые из таких изданий были оцифрованы и стали доступны для широкой публики.
Волонтеры помогают расшифровывать оцифрованные тексты
В Латвии предложили масштабное и современное решение этой проблемы. В декабре 2014 года Фольклорный архив Латвии к своему 90-летию запустил портал garamantas.lv (garamantas означает духовное наследие или фольклор).
Оцифрованные сканы рукописных листов загружаются в специально разработанную систему, где указаны необходимые метаданные: номер коллекции в архиве, описание коллекции, номера соответствующих архивных единиц и др. Для волонтеров-расшифровщиков разработали подробную инструкцию, а интерфейс доступен на разных языках.
В архиве есть не только латышские материалы, но и ливские песни, русский и белорусский фольклор, тексты на идише и латышском цыганском. Поэтому для участия в расшифровке необязательно знать латышский: в объемной коллекции русского фольклора, собранной Иваном Фридрихом в Латгалии (восточной Латвии), еще достаточно нерасшифрованных текстов. Также, «переписывать» слова со сканов можно и вообще без знания языка.
В 2016 году запустили отдельные «дочерние» ресурсы проекта — «Кудесники столетия» и «Языковая толока» (Valodas talka). «Языковая толока» была направлена на школьников: в течение двух с половиной месяцев им предлагалось поучаствовать в расшифровке рукописей. К окончанию акции собрали статистику об участниках, и наградили самых активных призами. Таким образом удалось привлечь много новых участников и расшифровать более десяти тысяч отсканированных изображений.
Другие проекты фольклорного архива: читаем стихи и поём
В 2017 году, к 150-летию поэта Эдуарда Вейденбаума, запустили акцию «Читай вслух!». Суть акции такова: люди выбирали любое стихотворение из представленных на портале и читали его под запись. Получилась своеобразная база данных с записями латышской речи, хоть и ограниченная конечным списком стихотворных текстов: можно послушать один и тот же текст, зачитанный людьми разных возрастов и из разных мест.
Затем прошли еще две похожие акции: со стихами для детей латышских поэтов-классиков и со стихами столетней давности (написанными или опубликованными в 1919 году).
В начале 2019 года запустили проект «Пой с архивом»: теперь можно не только послушать отдельные музыкальные записи из коллекций архива, но и загрузить свою версию. Пока что на странице этого проекта доступно не очень много записей, но даже в них представлены записи, собранные не только в Латвии, и не только на латышском.
Вот, например, песня, записанная в сибирской латышской деревне Нижняя Буланка в 1991 году (ноты здесь). А вот версия известной латышской народной песни «Kur tu teci, gailīti mans» (Куда бежишь, мой петушок?) на латышском цыганском. Среди выложенных записей есть также песни на ливском, русском и белорусском.
Опыт Латвийского фольклорного архива в некоторой степени уникален — прежде всего благодаря материалу, который представлен в его коллекциях. В то же время он универсален как пример успешного привлечения обычных людей к работе с культурным наследием страны.
Наталья Перкова
{kind=link}
Как AI помогает журналистам и почему профессия журналист умрет не скоро
#nlp
Профессию журналиста начали хоронить еще в 2015 году. Тогда в Америке говорили, что компьютер получит Пулитцеровскую премию в течение пяти лет, а к 2030 году 90% журналистских материалов будут создавать роботы.
Сегодня специалисты говорят скорее о новых возможностях использования ИИ в журналистике. Поэтому мы сделали подборку журналистских AI-проектов последних лет.
ИИ сообщает итоги выборов
В ночь после последних всеобщих выборов в Великобритании BBC News опубликовали около 700 новостей о результатах голосования. Так жители 650 избирательных округов Соединенного Королевства узнали о результатах голосования на своей территории в режиме реального времени. Это стало возможным благодаря компьютерной модели, обученной на шаблонах, созданных журналистами-людьми.
ИИ определяет, кто пришел на вечеринку
Британский канал Sky News впервые опробовал возможности AI в 2018 году во время скандальной свадьбы принца Гарри и Меган Маркл. С помощью технологии распознавания лиц они определяли, кто пришел на королевское торжество. Результатом стал проект «Кто есть кто» на сайте телеканала.
ИИ определяет, что пользователи хотели бы прочесть в СМИ
Новинка 2020 года — сервис, отслеживающий темы, которые вызывают интерес у читателей, но недостаточно освещены в СМИ. Сервис собирает данные об эффективности контента более чем 600 тысяч статей, публикуемых на 3000 сайтах, в день.
ИИ пишет шаблонные новости для регионов
С 2018 года в Великобритании работает автоматизированная редакция RADAR. Журналист-человек пишет шаблон новости для каждого из возможных сценариев — например, бум, скромный рост или резкое падение преступлений. Затем на основе открытых данных программа создает версии для каждой из 391 областей Великобритании на основе статистики этого региона.
ИИ на спортивных трибунах
Летом 2019 года на Уимблдоне компания IBM представила технологию искусственного интеллекта, которая отслеживает эмоции и характерные жесты спортсменов и зрителей во время матчей. Затем программа выделяет самые захватывающие моменты и создает яркие видео.
В конце 2019 года они представили похожую технологию, но уже обученную комментировать футбольные матчи.
ИИ обрабатывает документы
Летом 2019 года журналистам слили архив, раскрывающий схемы ухода от налогов транснациональных компаний, а модель машинного обучения, созданная в Quartz AI Studio, помогла обработать 200 тысяч документов. Результатом работы 54 журналистов стал интернациональный проект Mauritius Leaks, а создатели модели поделились кодом на GitHub.
ИИ модерирует комментарии
В The New York Times для модерирования комментариев стали использовать бесплатный инструмент Perspective, разработанный Jigsaw и Google с помощью машинного обучения. Модератор-код находит ненормативную лексику, буллинг в комментариях и оценивает их токсичность. Модератор-человек использует эту информацию для сортировки записей и для обратной связи с комментаторами в режиме реального времени.
ИИ оценивает лояльность пользователей
Дата-отдел South China Morning Post создал алгоритм для прогнозирования лояльности читателей и оптимизации маркетинговых кампаний за счет этих данных.
ИИ решает, кому продавать подписку
В редакции швейцарской немецкоязычной газеты Neue Zürcher Zeitung используют искусственный интеллект, чтобы предсказать, кто из читателей и в какой момент готов оформить платную подписку. Использование этого алгоритма повысило коэффициент конверсии на 82%, утверждают представители Neue Zürcher Zeitung.
https://sysblok.ru/linguistics/zhurnalisty-vs-roboty-neravnyj-boj/
#nlp
Профессию журналиста начали хоронить еще в 2015 году. Тогда в Америке говорили, что компьютер получит Пулитцеровскую премию в течение пяти лет, а к 2030 году 90% журналистских материалов будут создавать роботы.
Сегодня специалисты говорят скорее о новых возможностях использования ИИ в журналистике. Поэтому мы сделали подборку журналистских AI-проектов последних лет.
ИИ сообщает итоги выборов
В ночь после последних всеобщих выборов в Великобритании BBC News опубликовали около 700 новостей о результатах голосования. Так жители 650 избирательных округов Соединенного Королевства узнали о результатах голосования на своей территории в режиме реального времени. Это стало возможным благодаря компьютерной модели, обученной на шаблонах, созданных журналистами-людьми.
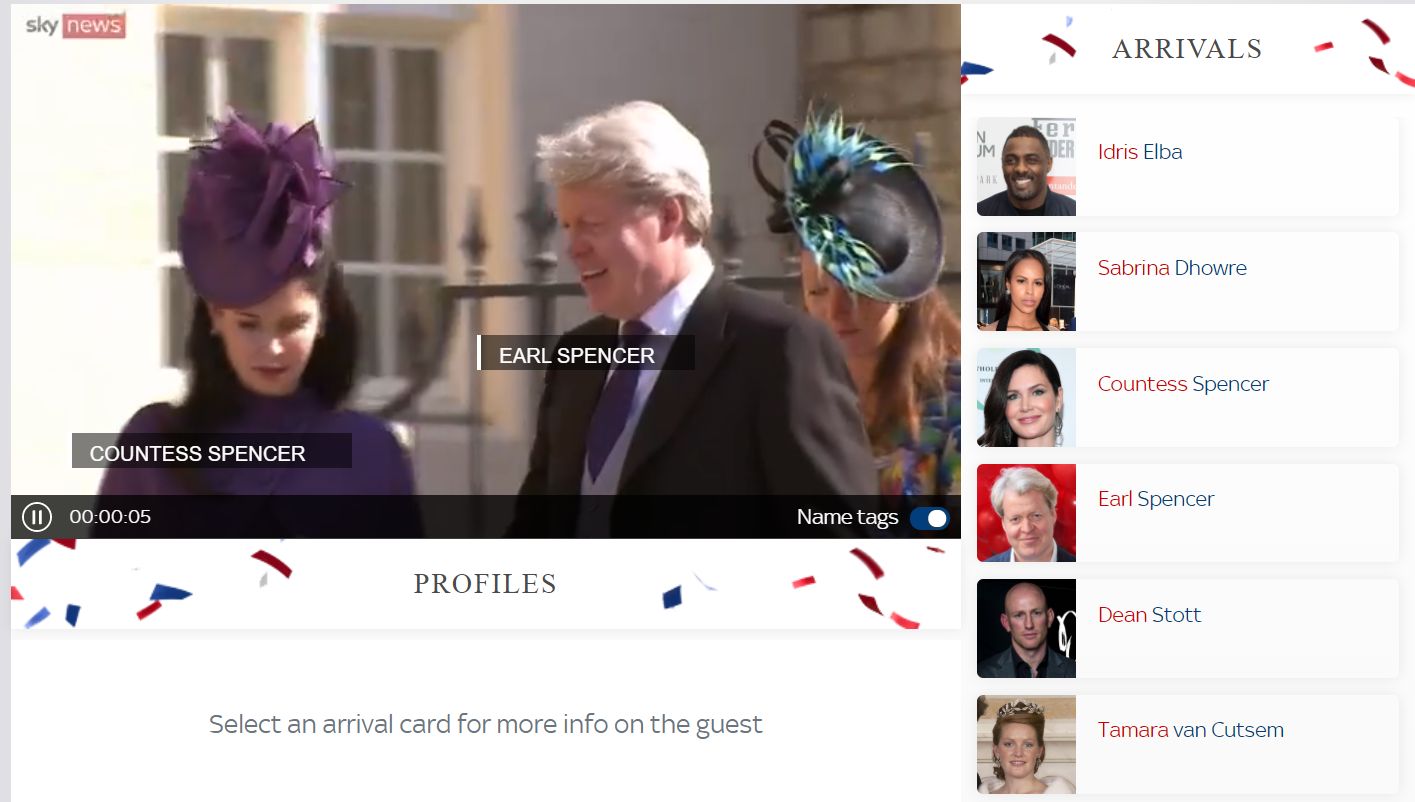
ИИ определяет, кто пришел на вечеринку
Британский канал Sky News впервые опробовал возможности AI в 2018 году во время скандальной свадьбы принца Гарри и Меган Маркл. С помощью технологии распознавания лиц они определяли, кто пришел на королевское торжество. Результатом стал проект «Кто есть кто» на сайте телеканала.
ИИ определяет, что пользователи хотели бы прочесть в СМИ
Новинка 2020 года — сервис, отслеживающий темы, которые вызывают интерес у читателей, но недостаточно освещены в СМИ. Сервис собирает данные об эффективности контента более чем 600 тысяч статей, публикуемых на 3000 сайтах, в день.
ИИ пишет шаблонные новости для регионов
С 2018 года в Великобритании работает автоматизированная редакция RADAR. Журналист-человек пишет шаблон новости для каждого из возможных сценариев — например, бум, скромный рост или резкое падение преступлений. Затем на основе открытых данных программа создает версии для каждой из 391 областей Великобритании на основе статистики этого региона.
ИИ на спортивных трибунах
Летом 2019 года на Уимблдоне компания IBM представила технологию искусственного интеллекта, которая отслеживает эмоции и характерные жесты спортсменов и зрителей во время матчей. Затем программа выделяет самые захватывающие моменты и создает яркие видео.
В конце 2019 года они представили похожую технологию, но уже обученную комментировать футбольные матчи.
ИИ обрабатывает документы
Летом 2019 года журналистам слили архив, раскрывающий схемы ухода от налогов транснациональных компаний, а модель машинного обучения, созданная в Quartz AI Studio, помогла обработать 200 тысяч документов. Результатом работы 54 журналистов стал интернациональный проект Mauritius Leaks, а создатели модели поделились кодом на GitHub.
ИИ модерирует комментарии
В The New York Times для модерирования комментариев стали использовать бесплатный инструмент Perspective, разработанный Jigsaw и Google с помощью машинного обучения. Модератор-код находит ненормативную лексику, буллинг в комментариях и оценивает их токсичность. Модератор-человек использует эту информацию для сортировки записей и для обратной связи с комментаторами в режиме реального времени.
ИИ оценивает лояльность пользователей
Дата-отдел South China Morning Post создал алгоритм для прогнозирования лояльности читателей и оптимизации маркетинговых кампаний за счет этих данных.
ИИ решает, кому продавать подписку
В редакции швейцарской немецкоязычной газеты Neue Zürcher Zeitung используют искусственный интеллект, чтобы предсказать, кто из читателей и в какой момент готов оформить платную подписку. Использование этого алгоритма повысило коэффициент конверсии на 82%, утверждают представители Neue Zürcher Zeitung.
https://sysblok.ru/linguistics/zhurnalisty-vs-roboty-neravnyj-boj/
{kind=link}
Генерация текстов с помощью моделей Plug and Play от Uber AI
#nlp
Нейросети уже научились правдоподобно дописывать текст за человеком, но есть проблема: их сложно заставить генерировать текст в нужной тональности или по конкретной тематике. Рассказываем про решение, которое позволяет «донастраивать» языковую модель под себя.
Языковая модель Plug and Play (PPLM)
Plug and Play Language Model позволяет пользователю подключать одну или несколько моделей для каждого из желаемых параметров (позитив или негатив, тематика и т. п.) в большую предобученную языковую модель (LM). Обучение или настройка этой языковой модели не требуется, что позволяет исследователям использовать лучшие языковые модели.
Например, без подключения PPLM предварительно обученная модель GPT-2-medium генерирует такое продолжение:
The food is awful. -> The staff are rude and lazy. The food is disgusting — even by my standards.
(Еда ужасна. -> Персонал грубый и ленивый. Еда отвратительна даже по моим стандартам.)
А подключив PPLM и настроив ее так, чтобы она завершила предложение позитивно, модель генерирует такой текст:
The food is awful, but there is also the music, the story and the magic! The «Avenged Sevenfold» is a masterfully performed rock musical that will have a strong presence all over the world.
(Еда ужасна, но еще здесь есть музыка, сюжет, магическая атмосфера. «Avenged Sevenfold» — мастерски исполненный рок-мюзикл, который получит признание по всему миру.)
Задаем тему
В качестве дополнительной модели исследователи использовали мешок слов (Bag of words, BoW) для различных тем, где вероятность темы определяется суммой вероятностей каждого слова в мешке.
Какое бы начало мы ни задали, нейросеть выдаст связный текст по заданной теме.
Задаем тональность
Здесь в качестве дополнительной модели исследователи используют дискриминатор PPLM-Discrim, обученный на наборе данных, размеченном по тональности.
При генерации использовали дискриминатор с 5000 параметрами (1025 параметров на класс (- -, -, 0, +, + +)), обученный на наборе данных SST-5. 5000 параметров — это ничтожно мало по сравнению с количеством параметров в основной модели (LM), и обучать такую модель гораздо легче и быстрее.
Проводим детоксикацию текста
Модели, обученные на большом количестве текстов в Интернете, могут отражать предвзятость и токсичность, присутствующие в исходных данных. Чтобы этого не допустить, при использовании PPLM нужно также подключить классификатор токсичности в качестве модели атрибута и обновить латентность с отрицательным градиентом.
Исследователи из Uber AI провели тест, в котором добровольные оценщики отметили токсичность пятисот образцов текста, сгенерированных PPLM с детоксикацией, и сравнили их с базовой моделью GPT-2. В среднем доля токсичной речи снизилась с 63,6% до 4,6%.
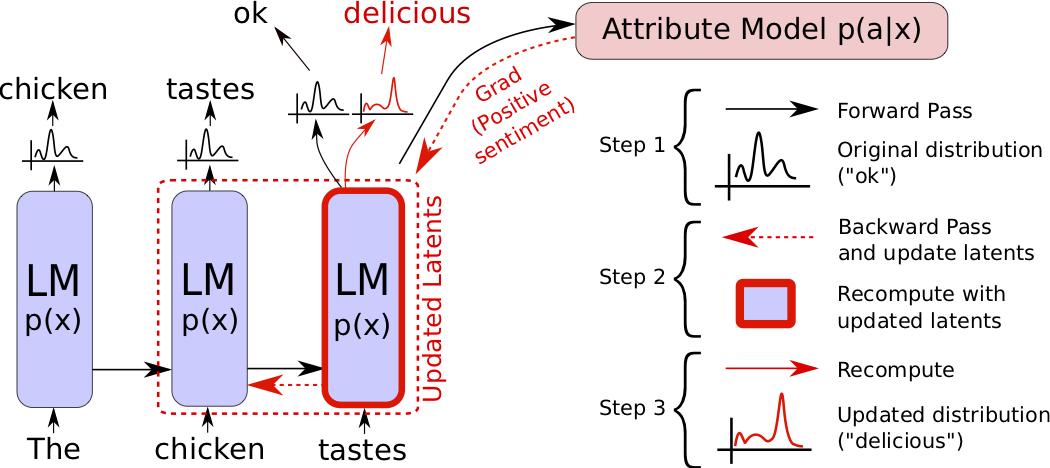
Принцип работы PPLM
Представлен на прикрепленной схеме. Алгоритм PPLM производит прямой и обратный обход нейронной сети, состоящей из двух подсетей — базовой предобученной языковой модели (LM) и модели классификатора по заданному пользователем атрибуту (attribute model).
Код моделей можно посмотреть здесь и здесь. Также доступна интерактивная демонстрация работы моделей.
Полный текст с примерами работы генераторов:
https://sysblok.ru/linguistics/kak-upravljat-mamontom-generiruem-nuzhnye-teksty-s-pomoshhju-modelej-plug-and-play/
#nlp
Нейросети уже научились правдоподобно дописывать текст за человеком, но есть проблема: их сложно заставить генерировать текст в нужной тональности или по конкретной тематике. Рассказываем про решение, которое позволяет «донастраивать» языковую модель под себя.
Языковая модель Plug and Play (PPLM)
Plug and Play Language Model позволяет пользователю подключать одну или несколько моделей для каждого из желаемых параметров (позитив или негатив, тематика и т. п.) в большую предобученную языковую модель (LM). Обучение или настройка этой языковой модели не требуется, что позволяет исследователям использовать лучшие языковые модели.
Например, без подключения PPLM предварительно обученная модель GPT-2-medium генерирует такое продолжение:
The food is awful. -> The staff are rude and lazy. The food is disgusting — even by my standards.
(Еда ужасна. -> Персонал грубый и ленивый. Еда отвратительна даже по моим стандартам.)
А подключив PPLM и настроив ее так, чтобы она завершила предложение позитивно, модель генерирует такой текст:
The food is awful, but there is also the music, the story and the magic! The «Avenged Sevenfold» is a masterfully performed rock musical that will have a strong presence all over the world.
(Еда ужасна, но еще здесь есть музыка, сюжет, магическая атмосфера. «Avenged Sevenfold» — мастерски исполненный рок-мюзикл, который получит признание по всему миру.)
Задаем тему
В качестве дополнительной модели исследователи использовали мешок слов (Bag of words, BoW) для различных тем, где вероятность темы определяется суммой вероятностей каждого слова в мешке.
Какое бы начало мы ни задали, нейросеть выдаст связный текст по заданной теме.
Задаем тональность
Здесь в качестве дополнительной модели исследователи используют дискриминатор PPLM-Discrim, обученный на наборе данных, размеченном по тональности.
При генерации использовали дискриминатор с 5000 параметрами (1025 параметров на класс (- -, -, 0, +, + +)), обученный на наборе данных SST-5. 5000 параметров — это ничтожно мало по сравнению с количеством параметров в основной модели (LM), и обучать такую модель гораздо легче и быстрее.
Проводим детоксикацию текста
Модели, обученные на большом количестве текстов в Интернете, могут отражать предвзятость и токсичность, присутствующие в исходных данных. Чтобы этого не допустить, при использовании PPLM нужно также подключить классификатор токсичности в качестве модели атрибута и обновить латентность с отрицательным градиентом.
Исследователи из Uber AI провели тест, в котором добровольные оценщики отметили токсичность пятисот образцов текста, сгенерированных PPLM с детоксикацией, и сравнили их с базовой моделью GPT-2. В среднем доля токсичной речи снизилась с 63,6% до 4,6%.
Принцип работы PPLM
Представлен на прикрепленной схеме. Алгоритм PPLM производит прямой и обратный обход нейронной сети, состоящей из двух подсетей — базовой предобученной языковой модели (LM) и модели классификатора по заданному пользователем атрибуту (attribute model).
Код моделей можно посмотреть здесь и здесь. Также доступна интерактивная демонстрация работы моделей.
Полный текст с примерами работы генераторов:
https://sysblok.ru/linguistics/kak-upravljat-mamontom-generiruem-nuzhnye-teksty-s-pomoshhju-modelej-plug-and-play/
{kind=link}
Как устроен шрифт Брайля и зачем его распознавать
Рассказывает Ася Ройтберг, инициатор разработки алгоритма распознавания Брайля
#nlp #society
Больше всего распознавание Брайля и его автоматический перевод нужны людям, которые много взаимодействуют с незрячими — обычно это родственники и учителя, — а в некоторых случаях это нужно и самим незрячим людям.
Учителя в школах для слабовидящих обычно читают Брайль глазами, поэтому проверять тетради диктантов из белых точек на белом фоне очень тяжело. Родители часто не могут помочь своему незрячему ребенку с уроками или почитать вместе одну книгу. Также, только в некоторых регионах у незрячих детей есть возможность участвовать в школьных олимпиадах.
Еще одна проблема — оцифровка и переиздание брайлевских книг, изданных в доцифровую эпоху.
Но главная цель — помочь незрячим людям расширить круг общения. Если убрать «языковой барьер», преподавать незрячим людям смогут люди, не умеющие бегло читать на Брайле.
Как устроен шрифт Брайля
Шрифт Брайля изначально придумали для армии. Предполагалось, что с помощью него солдаты смогут бесшумно общаться в полной темноте. В армии язык не пошел: зрячим людям оказалось не под силу читать пальцами рельефные точки. Но не пропадать же изобретению — рельефному шрифту решили научить слепых детей.
Один из этих детей — Луи Брайль — доработал систему, и в итоге получился рельефно-точечный шрифт. Он состоит из выпуклых точек и промежутков, причем точки четко организованы.
Один символ шрифта Брайля — решетка 3×2, в каждой из шести ячеек которой может быть (или не быть) рельефная точка. Получается всего 64 комбинации точек и пустот, поэтому для передачи кириллицы, латиницы, других видов письменности и даже музыкальных нот используют одни и те же символы.
Как и в других письменностях, Брайль бывает печатным и «рукописным». На вид символы не отличаются — отличается способ письма. Печатный вариант — это пластиковые округлые выпуклые точки, наверняка вы видели такие в лифтах или в подписях в музеях. Здесь можно конвертировать в Брайль русский текст, а здесь — текст на латинице.
В школах для слабовидящих детей учат писать «рукописным» Брайлем. Технически это протыкание дырочек специальным шилом (или просто ручкой) в листе бумаги, вставленном в специальный трафарет. На трафарете пишут зеркально: точки продавливают шилом с обратной стороны листа справа-налево. В этом видео подробно показывается, как пишут Брайлем.
Также есть брайлевские печатные машинки. Здесь можно посмотреть, какие они бывают. У них 6 больших кнопок — по кнопке на каждую из шести точек в брайлевской букве, и седьмая клавиша — пробел.
Брайлевские тексты иногда печатают с двух сторон, тогда на странице присутствуют одновременно и выпуклые точки текста, и впадины на местах точек текста с другой стороны листа. Такие тексты очень плохо распознаются с помощью компьютерного зрения и оптического распознавания символов.
Что сделано и не сделано в сфере распознавания Брайля
Распознать Брайль значит взять фотографию или скан текста на Брайле и превратить в машиночитаемые брайлевские символы (а дальше можно сразу конвертировать его в обычный текст на кириллице, латинице и т. д.).
Распознавание Брайля — проект без коммерческого потенциала. Для многих задач эта технология уже не актуальна: есть технические средства, помогающие незрячим при чтение и письме. С ними люди отлично могут набирать текст на компьютере и пользоваться любыми мессенджерами, а рукописный Брайль остается только на этапе начального обучения письму.
К сожалению, все эти технические средства довольно дорогие. В России брайлевская строка и брайлевский дисплей доступны совсем немногим.
Электронные помощники также не решают проблему оцифровки старых книг на Брайле. Но для этого есть аппаратно-программный комплекс — большая и дорогая железная машина с 3D сканером внутри, которая может распознавать только печатный Брайль.
https://sysblok.ru/nlp/kak-ustroen-shrift-brajlja-i-zachem-ego-raspoznavat/
Рассказывает Ася Ройтберг, инициатор разработки алгоритма распознавания Брайля
#nlp #society
Больше всего распознавание Брайля и его автоматический перевод нужны людям, которые много взаимодействуют с незрячими — обычно это родственники и учителя, — а в некоторых случаях это нужно и самим незрячим людям.
Учителя в школах для слабовидящих обычно читают Брайль глазами, поэтому проверять тетради диктантов из белых точек на белом фоне очень тяжело. Родители часто не могут помочь своему незрячему ребенку с уроками или почитать вместе одну книгу. Также, только в некоторых регионах у незрячих детей есть возможность участвовать в школьных олимпиадах.
Еще одна проблема — оцифровка и переиздание брайлевских книг, изданных в доцифровую эпоху.
Но главная цель — помочь незрячим людям расширить круг общения. Если убрать «языковой барьер», преподавать незрячим людям смогут люди, не умеющие бегло читать на Брайле.
Как устроен шрифт Брайля
Шрифт Брайля изначально придумали для армии. Предполагалось, что с помощью него солдаты смогут бесшумно общаться в полной темноте. В армии язык не пошел: зрячим людям оказалось не под силу читать пальцами рельефные точки. Но не пропадать же изобретению — рельефному шрифту решили научить слепых детей.
Один из этих детей — Луи Брайль — доработал систему, и в итоге получился рельефно-точечный шрифт. Он состоит из выпуклых точек и промежутков, причем точки четко организованы.
Один символ шрифта Брайля — решетка 3×2, в каждой из шести ячеек которой может быть (или не быть) рельефная точка. Получается всего 64 комбинации точек и пустот, поэтому для передачи кириллицы, латиницы, других видов письменности и даже музыкальных нот используют одни и те же символы.
Как и в других письменностях, Брайль бывает печатным и «рукописным». На вид символы не отличаются — отличается способ письма. Печатный вариант — это пластиковые округлые выпуклые точки, наверняка вы видели такие в лифтах или в подписях в музеях. Здесь можно конвертировать в Брайль русский текст, а здесь — текст на латинице.
В школах для слабовидящих детей учат писать «рукописным» Брайлем. Технически это протыкание дырочек специальным шилом (или просто ручкой) в листе бумаги, вставленном в специальный трафарет. На трафарете пишут зеркально: точки продавливают шилом с обратной стороны листа справа-налево. В этом видео подробно показывается, как пишут Брайлем.
Также есть брайлевские печатные машинки. Здесь можно посмотреть, какие они бывают. У них 6 больших кнопок — по кнопке на каждую из шести точек в брайлевской букве, и седьмая клавиша — пробел.
Брайлевские тексты иногда печатают с двух сторон, тогда на странице присутствуют одновременно и выпуклые точки текста, и впадины на местах точек текста с другой стороны листа. Такие тексты очень плохо распознаются с помощью компьютерного зрения и оптического распознавания символов.
Что сделано и не сделано в сфере распознавания Брайля
Распознать Брайль значит взять фотографию или скан текста на Брайле и превратить в машиночитаемые брайлевские символы (а дальше можно сразу конвертировать его в обычный текст на кириллице, латинице и т. д.).
Распознавание Брайля — проект без коммерческого потенциала. Для многих задач эта технология уже не актуальна: есть технические средства, помогающие незрячим при чтение и письме. С ними люди отлично могут набирать текст на компьютере и пользоваться любыми мессенджерами, а рукописный Брайль остается только на этапе начального обучения письму.
К сожалению, все эти технические средства довольно дорогие. В России брайлевская строка и брайлевский дисплей доступны совсем немногим.
Электронные помощники также не решают проблему оцифровки старых книг на Брайле. Но для этого есть аппаратно-программный комплекс — большая и дорогая железная машина с 3D сканером внутри, которая может распознавать только печатный Брайль.
https://sysblok.ru/nlp/kak-ustroen-shrift-brajlja-i-zachem-ego-raspoznavat/
{kind=link}
Обзор сервиса Talk To Books от Google
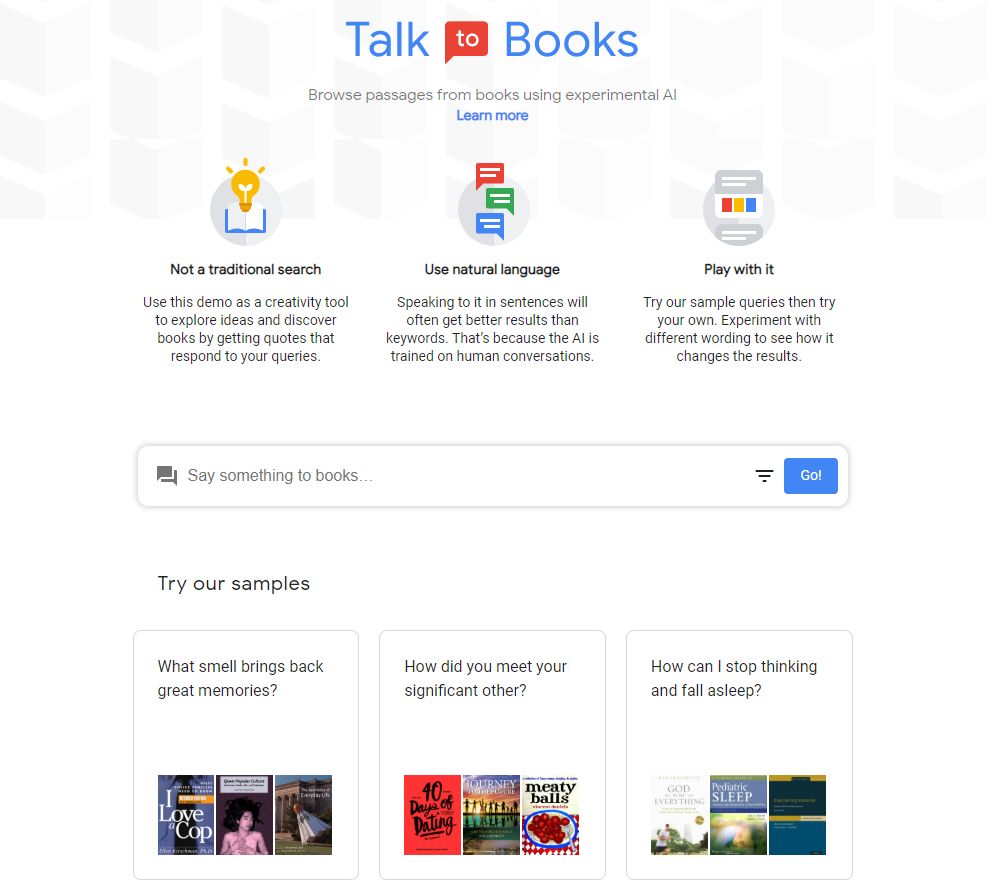
#nlp
Talk To Books — поисковой сервис, который ответит на любой вопрос не набором ссылок на статьи или сайты, а цитатами из книг, которых в базе сервиса более 100 тысяч. Это экспериментальный сервис от Google из серии Semantic Experiences. В этой серии Google разрабатывает инструменты, которые учат искусственный интеллект понимать естественный язык не по ключевым словам, а используя семантику.
Talk to Books ищет ответы, основываясь на семантике предложений. Нейронную сеть сервиса обучали на реальных диалогах между людьми. В качестве входных данных взяли миллиард пар высказываний по схеме вопрос — ответ или высказывание — реакция на него. Затем в систему загрузили тексты книг, и искусственный интеллект стал искать в них строчки, которые вероятнее всего могли бы стать ответом на запрос.
Ответ на запрос — это не просто вырванная цитата из книги. Пользователь видит целый абзац, в котором предполагаемый ответ выделен жирным шрифтом. После цитаты дана ссылка на конкретную страницу книги и на саму книгу. Книги также разделены на категории, по которым можно настроить фильтр для поиска ответов.
Talk to Books доступен только на английском языке и пока что работает не идеально, однако ему уже можно найти практическое применение. Например, его можно использовать для поиска книг для чтения. Также, преподаватели английского предлагают ученикам тренироваться в нем составлять вопросительные предложения.
Полный обзор сервиса со скриншотами по ссылке: https://sysblok.ru/nlp/kak-pogovorit-so-100-000-knig-talk-to-books/
#nlp
Talk To Books — поисковой сервис, который ответит на любой вопрос не набором ссылок на статьи или сайты, а цитатами из книг, которых в базе сервиса более 100 тысяч. Это экспериментальный сервис от Google из серии Semantic Experiences. В этой серии Google разрабатывает инструменты, которые учат искусственный интеллект понимать естественный язык не по ключевым словам, а используя семантику.
Talk to Books ищет ответы, основываясь на семантике предложений. Нейронную сеть сервиса обучали на реальных диалогах между людьми. В качестве входных данных взяли миллиард пар высказываний по схеме вопрос — ответ или высказывание — реакция на него. Затем в систему загрузили тексты книг, и искусственный интеллект стал искать в них строчки, которые вероятнее всего могли бы стать ответом на запрос.
Ответ на запрос — это не просто вырванная цитата из книги. Пользователь видит целый абзац, в котором предполагаемый ответ выделен жирным шрифтом. После цитаты дана ссылка на конкретную страницу книги и на саму книгу. Книги также разделены на категории, по которым можно настроить фильтр для поиска ответов.
Talk to Books доступен только на английском языке и пока что работает не идеально, однако ему уже можно найти практическое применение. Например, его можно использовать для поиска книг для чтения. Также, преподаватели английского предлагают ученикам тренироваться в нем составлять вопросительные предложения.
Полный обзор сервиса со скриншотами по ссылке: https://sysblok.ru/nlp/kak-pogovorit-so-100-000-knig-talk-to-books/
{kind=link}
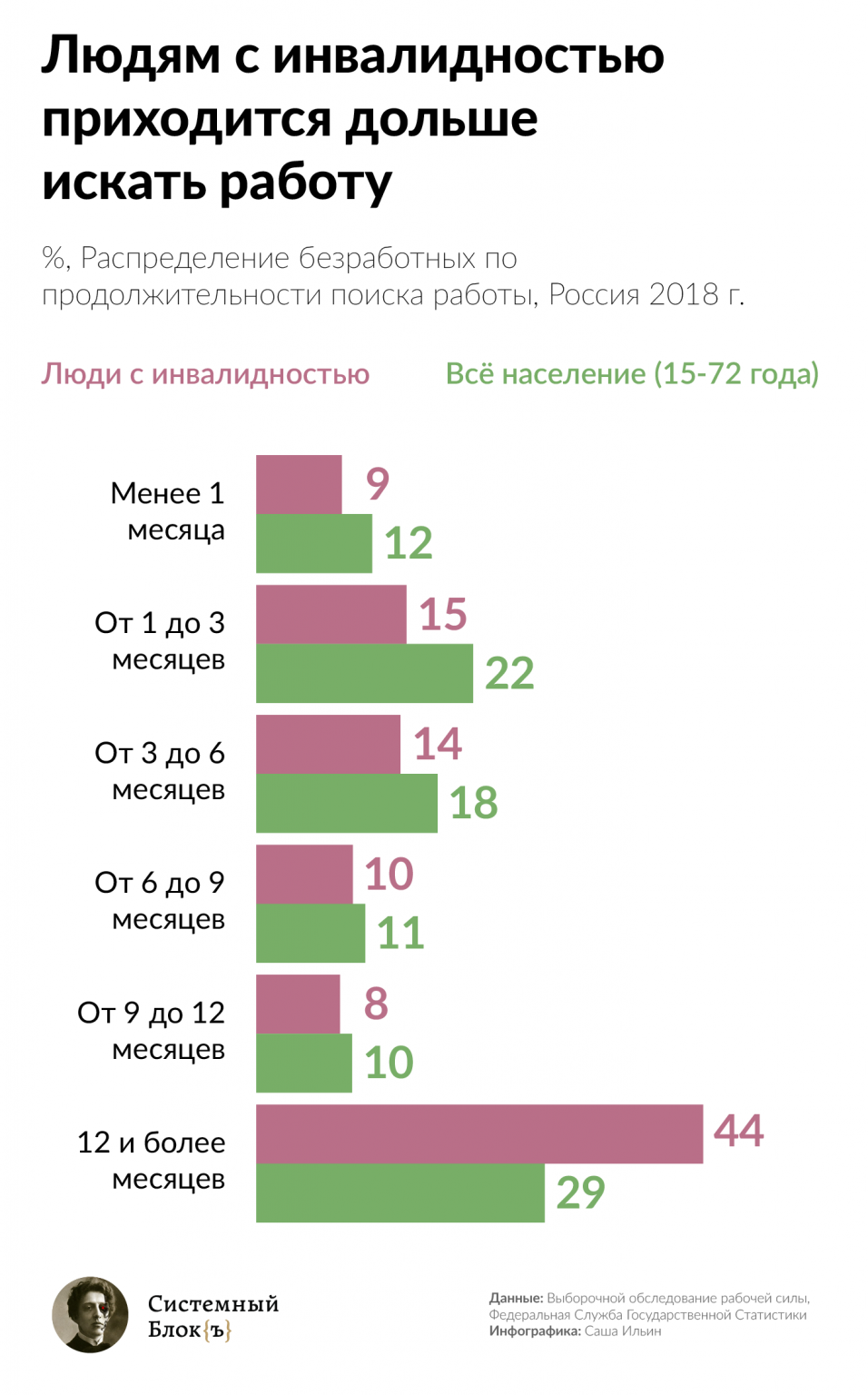
Доступность работы для людей с инвалидностью в России: инфографика
#открытыеданные #opendata
Сейчас в России живет почти 12 миллионов людей с инвалидностью. Когда говорят о проблемах доступной среды, чаще всего имеют в виду колясочников и невозможность добраться до магазина. Но даже если дойти до магазина получится, нужны еще деньги, чтобы что-то купить.
По данным Росстата на 2018 год уровень безработицы среди людей с инвалидностью трудоспособного возраста составляет 21,3%, хотя в целом по России он составляет 5%.
Люди с инвалидностью не только чаще остаются без работы, но и больше времени проводят в поиске вакансии — 44% ищут работу 12 месяцев или дольше.
Ссылка на данные: п. 4.15
#открытыеданные #opendata
Сейчас в России живет почти 12 миллионов людей с инвалидностью. Когда говорят о проблемах доступной среды, чаще всего имеют в виду колясочников и невозможность добраться до магазина. Но даже если дойти до магазина получится, нужны еще деньги, чтобы что-то купить.
По данным Росстата на 2018 год уровень безработицы среди людей с инвалидностью трудоспособного возраста составляет 21,3%, хотя в целом по России он составляет 5%.
Люди с инвалидностью не только чаще остаются без работы, но и больше времени проводят в поиске вакансии — 44% ищут работу 12 месяцев или дольше.
Ссылка на данные: п. 4.15
{kind=link}
Большие данные в биологии: как вы можете помочь науке
#biology
С появлением смартфона и интернета в классической биологии произошла революция, и от нее отделилась новая область знаний — информатика разнообразия. Теперь каждый человек может фотографировать природу и участвовать в развитии науки.
iNaturalist
Когда вы фотографируете, в exif-файл фотографии автоматически записываются координаты, дата и время съемки. Чтобы ваши фото помогали биологам, загружайте их на сайт iNaturalist. Движок сайта считывает все данные из exif-файла, а искусственный интеллект называет сфотографированный организм. Если он ошибся, неравнодушные пользователи поправят машину, и ее нейронная сеть станет компетентнее.
В итоге массив больших данных формируется в режиме реального времени. В библиотеке изображений уже 250 тысяч видов, снятых в своей среде обитания. В базе данных уже 32 миллиона наблюдений — серий из фотографий организма с разных ракурсов. Также у каждого наблюдения есть метаданные — метка на карте, дата и время съемки.
City Nature Challenge
Каждый апрель число наблюдений на в iNaturalist увеличивается на сотни тысяч, или даже на миллионы. Это происходит в ходе всемирных соревнований City Nature Challenge — чемпионата мира по документации городского биоразнообразия.
Соревнования проходят в течении четырех суток в режиме реального времени. Участники фотографируют на свои смартфоны и фотоаппараты растения, грибы и животных и загружают изображения на портал соревнований. В России для этого используются приложения iNaturalist и Seek или сайт inaturalist.org.
City Nature Challenge 2020 пройдет с 24 по 27 апреля. Обычно каждый участник соревнований видит рейтинг своего города, а также личный зачет в своем городе, стране и мировом табеле. В этом году мировой зачет отменен, так как велика вероятность, что некоторые города еще будут на карантине.
Подробности рассказывает доктор биологических наук Алексей Петрович Серегин: https://sysblok.ru/biologija/v-les-za-bolshimi-dannymi-kak-vashi-fotki-belok-i-gribov-pomogut-nauke/
#biology
С появлением смартфона и интернета в классической биологии произошла революция, и от нее отделилась новая область знаний — информатика разнообразия. Теперь каждый человек может фотографировать природу и участвовать в развитии науки.
iNaturalist
Когда вы фотографируете, в exif-файл фотографии автоматически записываются координаты, дата и время съемки. Чтобы ваши фото помогали биологам, загружайте их на сайт iNaturalist. Движок сайта считывает все данные из exif-файла, а искусственный интеллект называет сфотографированный организм. Если он ошибся, неравнодушные пользователи поправят машину, и ее нейронная сеть станет компетентнее.
В итоге массив больших данных формируется в режиме реального времени. В библиотеке изображений уже 250 тысяч видов, снятых в своей среде обитания. В базе данных уже 32 миллиона наблюдений — серий из фотографий организма с разных ракурсов. Также у каждого наблюдения есть метаданные — метка на карте, дата и время съемки.
City Nature Challenge
Каждый апрель число наблюдений на в iNaturalist увеличивается на сотни тысяч, или даже на миллионы. Это происходит в ходе всемирных соревнований City Nature Challenge — чемпионата мира по документации городского биоразнообразия.
Соревнования проходят в течении четырех суток в режиме реального времени. Участники фотографируют на свои смартфоны и фотоаппараты растения, грибы и животных и загружают изображения на портал соревнований. В России для этого используются приложения iNaturalist и Seek или сайт inaturalist.org.
City Nature Challenge 2020 пройдет с 24 по 27 апреля. Обычно каждый участник соревнований видит рейтинг своего города, а также личный зачет в своем городе, стране и мировом табеле. В этом году мировой зачет отменен, так как велика вероятность, что некоторые города еще будут на карантине.
Подробности рассказывает доктор биологических наук Алексей Петрович Серегин: https://sysblok.ru/biologija/v-les-za-bolshimi-dannymi-kak-vashi-fotki-belok-i-gribov-pomogut-nauke/
{kind=link}
Индивидуальный стиль переводчика: как определить автора перевода
#philology
В задаче определения авторства хорошие результаты показывает метод Дельта, опубликованный в 2002 году. Теперь мы точно знаем, что Роберт Гэлбрейт — псевдоним Джоан Роулинг, а уверенность в том, что «Тихий Дон» написал Шолохов, а не Федор Крюков, сильно возросла. Вы и сами можете в этом убедиться: Дельту интегрировали в функции Stylo — библиотеку для языка R.
Сейчас ученые ищут способ точно определять автора перевода. В этой статье разбираемся:
1. Можно ли использовать метод Дельта для определения переводчика?
2. Какие еще инструменты могут помочь для решения этой задачи?
Метод Дельта
Возможности применения этого метода изучает филолог и стилометрист Дэвид Хувер в своем исследовании The Invisible Translator Revisited.
Он использует функцию classify — инструмент, который при помощи машинного обучения определяет, насколько точно он может угадать «класс» документа на основе стилометрических признаков. Классом может быть автор, переводчик, жанр, временной период, и т. д. Также классификатор нужно обучать — на тренировочной и тестовой выборках.
Ученый выяснил, что авторский сигнал сильнее сигнала переводчика, который «пробивается» из-под стиля автора только в определенных ситуациях.
Чтобы уловить именно отпечаток переводчика, нужно ослабить значимость автора. Для этого Дэвид Хувер создал выборки так, чтобы в тренировочной и тестовой выборках авторы произведений были разные, а переводчики — одинаковые.
В итоге две разные модели машинного обучения угадали переводчика в 81.2% и 93.9% случаев.
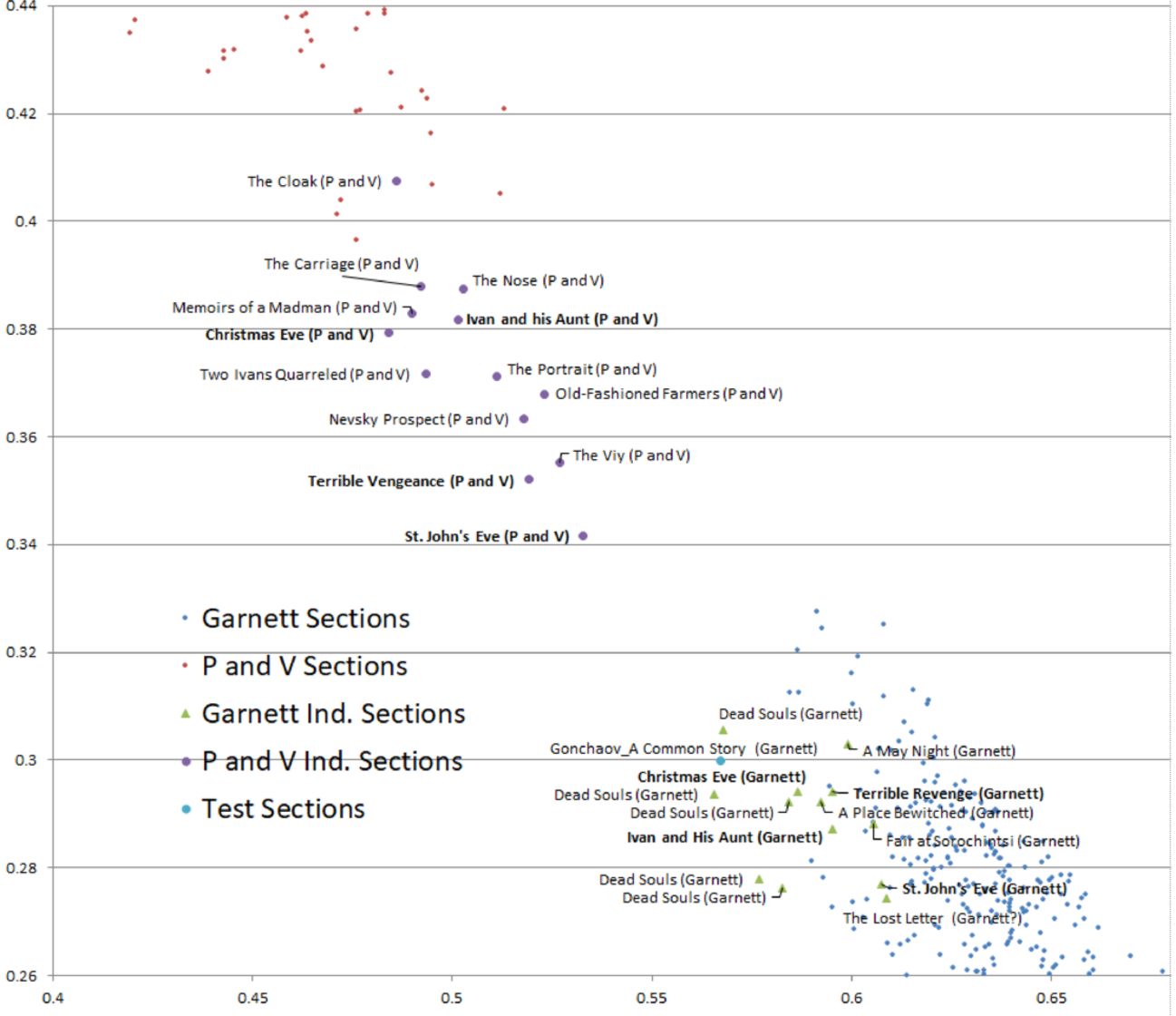
Метод Зета
У переводных текстов есть одна особенность: многие слова, которые часто встречаются у одного переводчика, избегаются другими, и то же верно наоборот. Такие слова называются отличительными словами.
Зета-анализ для нашей задачи работает так: он сравнивает, насколько постоянны включение и исключение набора отличительных слов в равных по размеру сегментах текста, на которые разделены произведения.
Если изобразить результат работы этого метода на графике (прикреплен ниже), то даже два перевода одного и того же текста разными переводчиками не будут находится рядом. Чем больше частотность отличительных слов, тем дальше их «разведет» по разным сторонам.
Полный рассказ с примерами и скриншотами по ссылке: https://sysblok.ru/philology/est-li-stil-u-perevodchika-a-esli-najdem/
#philology
В задаче определения авторства хорошие результаты показывает метод Дельта, опубликованный в 2002 году. Теперь мы точно знаем, что Роберт Гэлбрейт — псевдоним Джоан Роулинг, а уверенность в том, что «Тихий Дон» написал Шолохов, а не Федор Крюков, сильно возросла. Вы и сами можете в этом убедиться: Дельту интегрировали в функции Stylo — библиотеку для языка R.
Сейчас ученые ищут способ точно определять автора перевода. В этой статье разбираемся:
1. Можно ли использовать метод Дельта для определения переводчика?
2. Какие еще инструменты могут помочь для решения этой задачи?
Метод Дельта
Возможности применения этого метода изучает филолог и стилометрист Дэвид Хувер в своем исследовании The Invisible Translator Revisited.
Он использует функцию classify — инструмент, который при помощи машинного обучения определяет, насколько точно он может угадать «класс» документа на основе стилометрических признаков. Классом может быть автор, переводчик, жанр, временной период, и т. д. Также классификатор нужно обучать — на тренировочной и тестовой выборках.
Ученый выяснил, что авторский сигнал сильнее сигнала переводчика, который «пробивается» из-под стиля автора только в определенных ситуациях.
Чтобы уловить именно отпечаток переводчика, нужно ослабить значимость автора. Для этого Дэвид Хувер создал выборки так, чтобы в тренировочной и тестовой выборках авторы произведений были разные, а переводчики — одинаковые.
В итоге две разные модели машинного обучения угадали переводчика в 81.2% и 93.9% случаев.
Метод Зета
У переводных текстов есть одна особенность: многие слова, которые часто встречаются у одного переводчика, избегаются другими, и то же верно наоборот. Такие слова называются отличительными словами.
Зета-анализ для нашей задачи работает так: он сравнивает, насколько постоянны включение и исключение набора отличительных слов в равных по размеру сегментах текста, на которые разделены произведения.
Если изобразить результат работы этого метода на графике (прикреплен ниже), то даже два перевода одного и того же текста разными переводчиками не будут находится рядом. Чем больше частотность отличительных слов, тем дальше их «разведет» по разным сторонам.
Полный рассказ с примерами и скриншотами по ссылке: https://sysblok.ru/philology/est-li-stil-u-perevodchika-a-esli-najdem/
{kind=link}
«Прямо как в Plague. Inc!» Что объединяет игры и фильмы про эпидемии
#society
В связи с коронавирусом резко выросла популярность не самой новой (2012) игры Plague Inc. Цель игры — истребить или поработить человечество, используя смертельный патоген. Игрок управляет патогеном, наделяет его новыми симптомами и способами передачи. Обычные сюжетные роли перевернуты: злодей является протагонистом.
В последнее время стало появляться много шуток, связывающих игру и пандемию коронавируса. Люди начинают думать в терминах игры и используют игровые тропы для описания реального мира.
Тропы — повествовательные схемы, ментальные конструкции, которые обнаруживаются в разных видах творческих произведений (игры, фильмы, сериалы и прочее) — простой способ описания узнаваемых ситуаций, «кирпичики», составляющие повествование.
Мы решили узнать, какие тропы объединяют Plague Inc. и другие произведения, сюжет которых построен вокруг эпидемий. Для сравнения мы выбрали настольную игру Pandemic, фильмы Contagion и 28 Days Later и видео игру Left 4 Dead.
Мы использовали сетевой анализ. Анализируя тропы сетевым методом, можно быстро получить достаточно полное представление о самом произведении и понять, что его объединяет с другими: сразу видно общие детали сюжета или сеттинга.
Примеры тропов, которые встретились в нескольких произведениях:
Zombie Apocalypse (Зомби-апокалипсис)
Где встречается: Plague Inc., Pandemic, Left 4 Dead.
По-разному реализуется в каждой игре.
Patient Zero (Нулевой пациент)
Где встречается: Plague Inc., Contagion, Pandemic.
Первый зараженный может быть ключом к вакцине.
Ripped From The Headlines («Сюжет стащили из новостей») .
Где встречается: Contagion, Plague Inc., 28 Days Later
Здесь довольно любопытно то, что описание тропа несколько уже его фактического применения. Название и примеры передают больше информации, чем описание. Вкратце: общая канва истории основана на реальных событиях с некоторыми изменениями. Кроме того в Plague Inc. регулярно добавляют новые новости с отсылками, что делает структуру сложнее.
Spreading Disaster Map Graphic (Карта распространения вируса)
Где встречается: Plague Inc., Contagion, Pandemic
Карта с распространением вируса — прямо как в новостях
Oh, Crap! («О, чёрт!»)
Где присутствует: Plague Inc., Contagion, 28 Days Later, Left 4 Dead.
Момент осознания всего ужаса ситуации. Как говорится, «вы находитесь здесь».
Обо всех результатах и о том, как проводится сетевой анализ, читайте по ссылке: https://sysblok.ru/society/prjamo-kak-v-plague-inc-chto-obedinjaet-igry-i-filmy-pro-jepidemii/
#society
В связи с коронавирусом резко выросла популярность не самой новой (2012) игры Plague Inc. Цель игры — истребить или поработить человечество, используя смертельный патоген. Игрок управляет патогеном, наделяет его новыми симптомами и способами передачи. Обычные сюжетные роли перевернуты: злодей является протагонистом.
В последнее время стало появляться много шуток, связывающих игру и пандемию коронавируса. Люди начинают думать в терминах игры и используют игровые тропы для описания реального мира.
Тропы — повествовательные схемы, ментальные конструкции, которые обнаруживаются в разных видах творческих произведений (игры, фильмы, сериалы и прочее) — простой способ описания узнаваемых ситуаций, «кирпичики», составляющие повествование.
Мы решили узнать, какие тропы объединяют Plague Inc. и другие произведения, сюжет которых построен вокруг эпидемий. Для сравнения мы выбрали настольную игру Pandemic, фильмы Contagion и 28 Days Later и видео игру Left 4 Dead.
Мы использовали сетевой анализ. Анализируя тропы сетевым методом, можно быстро получить достаточно полное представление о самом произведении и понять, что его объединяет с другими: сразу видно общие детали сюжета или сеттинга.
Примеры тропов, которые встретились в нескольких произведениях:
Zombie Apocalypse (Зомби-апокалипсис)
Где встречается: Plague Inc., Pandemic, Left 4 Dead.
По-разному реализуется в каждой игре.
Patient Zero (Нулевой пациент)
Где встречается: Plague Inc., Contagion, Pandemic.
Первый зараженный может быть ключом к вакцине.
Ripped From The Headlines («Сюжет стащили из новостей») .
Где встречается: Contagion, Plague Inc., 28 Days Later
Здесь довольно любопытно то, что описание тропа несколько уже его фактического применения. Название и примеры передают больше информации, чем описание. Вкратце: общая канва истории основана на реальных событиях с некоторыми изменениями. Кроме того в Plague Inc. регулярно добавляют новые новости с отсылками, что делает структуру сложнее.
Spreading Disaster Map Graphic (Карта распространения вируса)
Где встречается: Plague Inc., Contagion, Pandemic
Карта с распространением вируса — прямо как в новостях
Oh, Crap! («О, чёрт!»)
Где присутствует: Plague Inc., Contagion, 28 Days Later, Left 4 Dead.
Момент осознания всего ужаса ситуации. Как говорится, «вы находитесь здесь».
Обо всех результатах и о том, как проводится сетевой анализ, читайте по ссылке: https://sysblok.ru/society/prjamo-kak-v-plague-inc-chto-obedinjaet-igry-i-filmy-pro-jepidemii/
{kind=link}
Музыка нас связала: универсалии в музыке мира
#musicology #news
Есть ли что-то общее у горлового пения эскимосов, традиционного аккомпанемента японского драматического театра, но и мелодий, сыгранных австралийскими аборигенами на диджериду?
Различия в музыкальных традициях мира убедили некоторых музыковедов-фольклористов в том, что идея об универсальности мировой музыки не состоятельна. Однако, музыковед Самуил Мэр и другие исследователи Гарвардского университета нашли доказательства тому, что мировую музыку объединяют общие акустические признаки.
Исследование
Самуил Мэр с командой исследователей записал множество песен, типичных для разных культур. В выборку вошли только песни с вокальным элементом. Из собранных песен исследователей привлекли четыре типа: колыбельные, плясовые, любовные песни и песни-заговоры. Ученые их транскрибировали и проанализировали с помощью программ для обработки звучащей речи.
Также провели онлайн-эксперимент, цель которого — узнать, смогут ли слушатели разделить песни на категории, анализируя исключительно акустические признаки мелодий. Участники слушали песни, информация о содержании которых была скрыта, и распределяли их по четырем категориям.
Еще исследовали, во всех ли песнях есть лад, то есть системная организация тонов и отношений между ними. Для этого 30 музыковедов прослушали отрывки из песен и ответили, звучит ли в них хоть одна тоника (трезвучие, построенное на первой ступени ладового звукоряда).
Результаты
Предварительный анализ показал, что у песен каждого типа есть сходные элементы. Некоторые сходства очевидны: например, у плясовых песен более энергичный темп, по сравнению с колыбельными. Также выяснили, что в любовных песнях тональный диапазон шире, чем в колыбельных; плясовые песни более мелодически разнородны, в сравнении с заговорами; а в заговорах используется небольшое количество близких по звучанию нот.
Исследование выделило три измерения, которыми можно объяснить основные различия между четырьмя типами песен: церемониальность, возбуждение и религиозность. Так, плясовые песни отличает высокая церемониальность и возбуждение, но низкая религиозность. У заговоров все три аспекта ярко выражены, а у колыбельных, наоборот, менее всего.
Участники онлайн-эксперимента правильно угадали тип песни в 42% случаев, что гораздо выше 25% случайного распределения.
При исследовании лада 90% музыковедов выявили тонику в 113 из 118 песен, что указывает на универсальную природу лада.
Выводы исследователей
Полученные результаты указывают на то, что в акустических свойствах песен закодирован поведенческий контекст, общий для мировых культур. Принципиальное различие между песнями разных культур значительно ниже, чем разнообразие контекстов внутри отдельно взятой культуры. Значит, несмотря на вариации в манере исполнения и инструментах, по всему миру сходные песни используются в сходных контекстах.
Пока не до конца ясно, чем можно объяснить несоответствие социальных контекстов и акустических свойств песен. Кроме того, в исследовании пока представлены не все мировые культуры. В будущем можно создать обширную базу данных, аннотированную текстом и видео, в которую войдут аудиозаписи песен разных культур и стилей.
О зарождении музыки
Недавнее исследование ископаемых останков выявило, что гейдельбергский человек — общий предок человека разумного и неандертальца — мог менять высоту своего голоса , то есть «петь», уже более миллиона лет назад.
В ходе другого археологического исследования обнаружили дудки, выточенные из костей лебедей и ястребов, возраст которых составляет около 40 тысяч лет. Можно представить, что эти изделия — результат долгой эволюции музыкальных инструментов, а более ранние образцы были сделаны из травы, тростника и дерева — тех материалов, которые не так часто встречаются в ископаемых находках.
Есть мнение, что музыка — эволюционное приспособление, финальное или — как результат другого приспособления — побочное.
Вера Шимко
https://sysblok.ru/news/muzyka-nas-svjazala-universalii-v-muzyke-mira/
#musicology #news
Есть ли что-то общее у горлового пения эскимосов, традиционного аккомпанемента японского драматического театра, но и мелодий, сыгранных австралийскими аборигенами на диджериду?
Различия в музыкальных традициях мира убедили некоторых музыковедов-фольклористов в том, что идея об универсальности мировой музыки не состоятельна. Однако, музыковед Самуил Мэр и другие исследователи Гарвардского университета нашли доказательства тому, что мировую музыку объединяют общие акустические признаки.
Исследование
Самуил Мэр с командой исследователей записал множество песен, типичных для разных культур. В выборку вошли только песни с вокальным элементом. Из собранных песен исследователей привлекли четыре типа: колыбельные, плясовые, любовные песни и песни-заговоры. Ученые их транскрибировали и проанализировали с помощью программ для обработки звучащей речи.
Также провели онлайн-эксперимент, цель которого — узнать, смогут ли слушатели разделить песни на категории, анализируя исключительно акустические признаки мелодий. Участники слушали песни, информация о содержании которых была скрыта, и распределяли их по четырем категориям.
Еще исследовали, во всех ли песнях есть лад, то есть системная организация тонов и отношений между ними. Для этого 30 музыковедов прослушали отрывки из песен и ответили, звучит ли в них хоть одна тоника (трезвучие, построенное на первой ступени ладового звукоряда).
Результаты
Предварительный анализ показал, что у песен каждого типа есть сходные элементы. Некоторые сходства очевидны: например, у плясовых песен более энергичный темп, по сравнению с колыбельными. Также выяснили, что в любовных песнях тональный диапазон шире, чем в колыбельных; плясовые песни более мелодически разнородны, в сравнении с заговорами; а в заговорах используется небольшое количество близких по звучанию нот.
Исследование выделило три измерения, которыми можно объяснить основные различия между четырьмя типами песен: церемониальность, возбуждение и религиозность. Так, плясовые песни отличает высокая церемониальность и возбуждение, но низкая религиозность. У заговоров все три аспекта ярко выражены, а у колыбельных, наоборот, менее всего.
Участники онлайн-эксперимента правильно угадали тип песни в 42% случаев, что гораздо выше 25% случайного распределения.
При исследовании лада 90% музыковедов выявили тонику в 113 из 118 песен, что указывает на универсальную природу лада.
Выводы исследователей
Полученные результаты указывают на то, что в акустических свойствах песен закодирован поведенческий контекст, общий для мировых культур. Принципиальное различие между песнями разных культур значительно ниже, чем разнообразие контекстов внутри отдельно взятой культуры. Значит, несмотря на вариации в манере исполнения и инструментах, по всему миру сходные песни используются в сходных контекстах.
Пока не до конца ясно, чем можно объяснить несоответствие социальных контекстов и акустических свойств песен. Кроме того, в исследовании пока представлены не все мировые культуры. В будущем можно создать обширную базу данных, аннотированную текстом и видео, в которую войдут аудиозаписи песен разных культур и стилей.
О зарождении музыки
Недавнее исследование ископаемых останков выявило, что гейдельбергский человек — общий предок человека разумного и неандертальца — мог менять высоту своего голоса , то есть «петь», уже более миллиона лет назад.
В ходе другого археологического исследования обнаружили дудки, выточенные из костей лебедей и ястребов, возраст которых составляет около 40 тысяч лет. Можно представить, что эти изделия — результат долгой эволюции музыкальных инструментов, а более ранние образцы были сделаны из травы, тростника и дерева — тех материалов, которые не так часто встречаются в ископаемых находках.
Есть мнение, что музыка — эволюционное приспособление, финальное или — как результат другого приспособления — побочное.
Вера Шимко
https://sysblok.ru/news/muzyka-nas-svjazala-universalii-v-muzyke-mira/
{kind=link}
Как 3D-технологии воскресили Страстной монастырь
#history
Страстной монастырь основали в середине 17-го века. Со временем его облик и значение менялись: его перестраивали, восстанавливали после пожаров, добавляли функциональные постройки. А в 1937 году монастырь был полностью уничтожен. Сейчас на месте, где стоял монастырь, находится Пушкинская площадь и стоит памятник А. С. Пушкину.
Активисты выдвигали предложения о переносе памятника и восстановлении Страстного монастыря, но проект не был поддержан. Однако, в 2016 году монастырь восстановили в виртуальном городе: был организован масштабный проект по 3D-реконструкции облика Страстного монастыря в разные эпохи.
Реконструкция выполнена для трех отрезков времени: рубеж 17-го и 18-го веков, 1830-ые годы и начало 20-го века. 3D-модели монастырского комплекса, а также отдельных его зданий и сооружений можно посмотреть здесь. Теперь любой человек может «погулять» по Страстному монастырю и площади вокруг него.
О том, как велась работа над проектом, читайте в нашей статье: https://sysblok.ru/history/kak-3d-tehnologii-voskresili-strastnoj-monastyr/
#history
Страстной монастырь основали в середине 17-го века. Со временем его облик и значение менялись: его перестраивали, восстанавливали после пожаров, добавляли функциональные постройки. А в 1937 году монастырь был полностью уничтожен. Сейчас на месте, где стоял монастырь, находится Пушкинская площадь и стоит памятник А. С. Пушкину.
Активисты выдвигали предложения о переносе памятника и восстановлении Страстного монастыря, но проект не был поддержан. Однако, в 2016 году монастырь восстановили в виртуальном городе: был организован масштабный проект по 3D-реконструкции облика Страстного монастыря в разные эпохи.
Реконструкция выполнена для трех отрезков времени: рубеж 17-го и 18-го веков, 1830-ые годы и начало 20-го века. 3D-модели монастырского комплекса, а также отдельных его зданий и сооружений можно посмотреть здесь. Теперь любой человек может «погулять» по Страстному монастырю и площади вокруг него.
О том, как велась работа над проектом, читайте в нашей статье: https://sysblok.ru/history/kak-3d-tehnologii-voskresili-strastnoj-monastyr/
YouTube
Виртуальная реконструкция Страстного монастыря нач. XX века
Проект "Виртуальная реконструкция московского Страстного монастыря (середина XVII - начало XX вв.): анализ эволюции пространственной инфраструктуры на основе методов 3D моделирования" поддержан грантом Российского научного Фонда (РНФ) № 14-18-03473. Проект…
Европейское культурное наследие онлайн
#arts
Пока границы закрыты, изучим возможности, которые предоставляют крупнейшие онлайн-коллекции объектов культурного наследия.
Europeana
Общеевропейская база. Архивы, музеи и библиотеки разных стран (включая Россию) выкладывают сюда свои электронные коллекции. Здесь можно найти произведения изобразительного искусства, старинные книги, газеты, географические карты, нотные издания и рукописи, звукозаписи и многое другое.
Условия использования прописаны для каждого объекта. Материалы могут быть как общедоступными, так и платными, либо вообще запрещенными для воспроизведения.
Google Arts And Culture
Онлайн-платформа от Google, посвященная культурному наследию. Здесь есть три основных раздела: коллекция изображений произведений искусства (в высоком разрешении, доступны для свободного скачивания), панорамные видео и виртуальные экскурсии по достопримечательностям (на основе технологии Street View).
На платформе представлены экспонаты из более чем 1200 музеев и архивов со всего мира.
Gallica
Проект Национальной библиотеки Франции. На портале есть следующие разделы: печатные книги, рукописи, карты, изображения, звукозаписи, ноты и видео. По документам доступен полнотекстовый поиск.
Большинство объектов находятся в публичном доступе, т. е. разрешено их использование в некоммерческих целях. Однако это относится не ко всей коллекции, поэтому в каждом конкретном случае необходимо уточнять условия копирайта.
Коллекции музеев Парижа
Портал, объединяющий онлайн-коллекции 14 муниципальных парижских музеев, среди которых есть художественные, исторические, дома художников и писателей. В их числе Карнавале (музей истории Парижа), Катакомбы (сеть подземных тоннелей на месте древних римских каменоломен), Крипта паперти Нотр-Дама (здесь выставлены археологические находки), Музей современного искусства, дома-музеи Оноре де Бальзака и Виктора Гюго.
На портале доступны более 150 тысяч цифровых репродукций произведений из коллекций музеев Парижа. Изображения находятся в свободном доступе, их можно скачать (в разрешении 300 dpi).
#arts
Пока границы закрыты, изучим возможности, которые предоставляют крупнейшие онлайн-коллекции объектов культурного наследия.
Europeana
Общеевропейская база. Архивы, музеи и библиотеки разных стран (включая Россию) выкладывают сюда свои электронные коллекции. Здесь можно найти произведения изобразительного искусства, старинные книги, газеты, географические карты, нотные издания и рукописи, звукозаписи и многое другое.
Условия использования прописаны для каждого объекта. Материалы могут быть как общедоступными, так и платными, либо вообще запрещенными для воспроизведения.
Google Arts And Culture
Онлайн-платформа от Google, посвященная культурному наследию. Здесь есть три основных раздела: коллекция изображений произведений искусства (в высоком разрешении, доступны для свободного скачивания), панорамные видео и виртуальные экскурсии по достопримечательностям (на основе технологии Street View).
На платформе представлены экспонаты из более чем 1200 музеев и архивов со всего мира.
Gallica
Проект Национальной библиотеки Франции. На портале есть следующие разделы: печатные книги, рукописи, карты, изображения, звукозаписи, ноты и видео. По документам доступен полнотекстовый поиск.
Большинство объектов находятся в публичном доступе, т. е. разрешено их использование в некоммерческих целях. Однако это относится не ко всей коллекции, поэтому в каждом конкретном случае необходимо уточнять условия копирайта.
Коллекции музеев Парижа
Портал, объединяющий онлайн-коллекции 14 муниципальных парижских музеев, среди которых есть художественные, исторические, дома художников и писателей. В их числе Карнавале (музей истории Парижа), Катакомбы (сеть подземных тоннелей на месте древних римских каменоломен), Крипта паперти Нотр-Дама (здесь выставлены археологические находки), Музей современного искусства, дома-музеи Оноре де Бальзака и Виктора Гюго.
На портале доступны более 150 тысяч цифровых репродукций произведений из коллекций музеев Парижа. Изображения находятся в свободном доступе, их можно скачать (в разрешении 300 dpi).
{kind=link}
Кэти Перри невиновна: цифровые музыковеды опровергают плагиат в песне Dark Horse
#musicology #news
В прошлом году певицу Кэти Перри обвинили в плагиате песни «Joyful Noise» рэпера Флейма (Flame). Суд обязал Кэти Перри выплатить 2,8 миллионов долларов за использованное в ее композиции «Dark Horse» остинато, которое якобы было заимствовано.
Остинато — это многократное повторение мелодической фразы, ритмической фигуры или гармонического оборота. Группа музыковедов, называющая себя Amici, доказывает, что остинато вовсе не является объектом авторского права, т. к. лишено оригинальности. Поэтому они категорически не согласны с решением суда Калифорнии, который присудил Кэти Перри штраф.
Исследование
Сначала выявили последовательность нот, которую содержат обе композиции: она состоит из нот CCCCBB (в буквенной нотации). Затем ввели эту последовательность в базу данных RISM, которая содержит более 1,4 миллиона музыкальных инципитов (вступлений).
Музыкальный инципит — это поле, в котором закодированы несколько первых нот или тактов музыкального источника. Поиск по инципиту выполняется только с помощью расширенного поиска RISM. Предлагается использовать либо экранную клавиатуру пианино, либо поле Music incipit (с транспозицией): введите CCCCBB и нажмите Search.
Дополнительно музыковеды задействовали корпус Themefinder.org. Это некоммерческий проект поиска музыкальных фрагментов, созданный Центром компьютерных гуманитарных исследований (CCARH) и Лабораторией когнитивного и систематического музыковедения в Университете штата Огайо.
Результаты
Результаты поиска в RISM представляют собой те композиции, где эта последовательность нот (в этой или в другой тональности) встречается в начале произведения, и включают музыкальные источники, найденные по всей Европе. Музыковеды обнаружили около 2300 (по состоянию на январь 2020 года) песен по заданным параметрам, причем, большинство из них были написаны в 18-ом и 19-ом веках.
Результаты поиска в корпусе Themefinder также подтвердили широкое распространение последовательности нот, за которую судили Кэти Перри.
Ольга Чхотуа
https://sysblok.ru/musicology/kjeti-pjerri-nevinovna-cifrovye-muzykovedy-oprovergajut-plagiat-v-dark-horse/
#musicology #news
В прошлом году певицу Кэти Перри обвинили в плагиате песни «Joyful Noise» рэпера Флейма (Flame). Суд обязал Кэти Перри выплатить 2,8 миллионов долларов за использованное в ее композиции «Dark Horse» остинато, которое якобы было заимствовано.
Остинато — это многократное повторение мелодической фразы, ритмической фигуры или гармонического оборота. Группа музыковедов, называющая себя Amici, доказывает, что остинато вовсе не является объектом авторского права, т. к. лишено оригинальности. Поэтому они категорически не согласны с решением суда Калифорнии, который присудил Кэти Перри штраф.
Исследование
Сначала выявили последовательность нот, которую содержат обе композиции: она состоит из нот CCCCBB (в буквенной нотации). Затем ввели эту последовательность в базу данных RISM, которая содержит более 1,4 миллиона музыкальных инципитов (вступлений).
Музыкальный инципит — это поле, в котором закодированы несколько первых нот или тактов музыкального источника. Поиск по инципиту выполняется только с помощью расширенного поиска RISM. Предлагается использовать либо экранную клавиатуру пианино, либо поле Music incipit (с транспозицией): введите CCCCBB и нажмите Search.
Дополнительно музыковеды задействовали корпус Themefinder.org. Это некоммерческий проект поиска музыкальных фрагментов, созданный Центром компьютерных гуманитарных исследований (CCARH) и Лабораторией когнитивного и систематического музыковедения в Университете штата Огайо.
Результаты
Результаты поиска в RISM представляют собой те композиции, где эта последовательность нот (в этой или в другой тональности) встречается в начале произведения, и включают музыкальные источники, найденные по всей Европе. Музыковеды обнаружили около 2300 (по состоянию на январь 2020 года) песен по заданным параметрам, причем, большинство из них были написаны в 18-ом и 19-ом веках.
Результаты поиска в корпусе Themefinder также подтвердили широкое распространение последовательности нот, за которую судили Кэти Перри.
Ольга Чхотуа
https://sysblok.ru/musicology/kjeti-pjerri-nevinovna-cifrovye-muzykovedy-oprovergajut-plagiat-v-dark-horse/
{kind=link}
Компьютерный анализ Сезанна: что объединяет серию Купальщиков
#arts
Поль Сезанн был воспитан культурой Ренессанса и воспевал неоплатонические идеи. В мировой культуре он остался художником, для которого искусство было самоцелью. «Купальщики» — самая длительная и монументальная серия его творчества: к этому сюжету он возвращался на протяжении всей жизни. Полотно «Большие купальщицы» стало последней работой, поставленной Сезанном на мольберт перед смертью.
Возможности компьютерного анализа произведений искусства
Сегодня для анализа произведений искусства применяются разнообразные технологии. Сравнительный анализ и основы классификации произведений искусства, которыми пользуются по сей день, открыл миру Генрих Вельфлин.
Методы анализа полотен с помощью рентгеновских и ультрафиолетовых лучей могут выявить нижние слои картин, идентифицировать свойства пигментов и связующих веществ, подтвердить подлинность произведений искусства и обнаружить подделки. Полученные сведения помогают составить оптимальные проекты для музея.
Компьютерные алгоритмы используются для измерения и подсчета мазков кисти, классификации картин по стилю, выявления их характерных черт и создания трехмерных моделей, которые иллюстрируют методы работы художника. Программы способны одновременно перерабатывать большой объем данных, не опираясь при этом на прошлый опыт исследователей, подвергать сомнению уже имеющиеся категории и выявлять ошибки в нашем понимании и оценке живописи.
Таким образом, компьютеры способны создать уникальные культурные карты, которые оригинальным образом свяжут исторические артефакты.
Применение программ DIAS и DENDRON
В медицине программы DIAS и DENDRON (сокращ. DDA) используют для изучения микозов и раковых клеток. DIAS отвечает за анализ морфологии клеток, изучает их движения и динамику популяции, а DENDRON — сортирует и сравнивает генетические отпечатки инфекционных организмов, формируя их в древообразные дендрограммы.
Группа исследователей из Массачусетса стала первой, кто использовал DDA в искусстве. Метод кластерного анализа или построения дендрограмм был применен к 55 оцифрованным картинам. Программа DDA позволила перенести все оцифрованные картины в единую базу.
С помощью сравнительного анализа полотна удалось автоматически распределить по девяти разным параметрам: яркости, насыщенности, сложности, красного, оранжевого, желтого, зеленого, голубого и пурпурного оттенков. Каждая пара или группа картин была отсортирована, исходя из соответствия единому признаку, и распределена в порядке растущей прогрессии. Далее коэффициент прогрессии генерировал матрицы, на основе которых были сформированы дендрограммы.
Результаты исследования
Результаты исследования подтвердили художественную связь Веронезе и Сезанна: в своей работе «Стоящая купальщица моет волосы» Сезанн использует паттерны картины «Брак в Кане Галилейской», написанной Паоло Веронезе в 16-ом веке.
Анализ работ также выявил скрытую единую композиционную структуру, отмеченную во всех полотнах Сезанна. Удалось установить, что, вероятнее всего, Сезанн в своем творчестве руководствовался математическими расчетами, а не интуитивными мотивами. Это изменило сложившиеся в искусствоведении представление о неуклюжести и дисбалансе форм Сезанна, на идею о точной выверенной им композиции, соответствующей правилам «золотого сечения».
Благодаря программе DDA можно предположить, что Сезанн закладывал в свои работы не только игру цвета и формы, но и особую головоломку — главную идею своего творчества.
Дара Марич
https://sysblok.ru/arts/kompjuternyj-analiz-sezanna-chto-obedinjaet-seriju-kupalshhikov/
#arts
Поль Сезанн был воспитан культурой Ренессанса и воспевал неоплатонические идеи. В мировой культуре он остался художником, для которого искусство было самоцелью. «Купальщики» — самая длительная и монументальная серия его творчества: к этому сюжету он возвращался на протяжении всей жизни. Полотно «Большие купальщицы» стало последней работой, поставленной Сезанном на мольберт перед смертью.
Возможности компьютерного анализа произведений искусства
Сегодня для анализа произведений искусства применяются разнообразные технологии. Сравнительный анализ и основы классификации произведений искусства, которыми пользуются по сей день, открыл миру Генрих Вельфлин.
Методы анализа полотен с помощью рентгеновских и ультрафиолетовых лучей могут выявить нижние слои картин, идентифицировать свойства пигментов и связующих веществ, подтвердить подлинность произведений искусства и обнаружить подделки. Полученные сведения помогают составить оптимальные проекты для музея.
Компьютерные алгоритмы используются для измерения и подсчета мазков кисти, классификации картин по стилю, выявления их характерных черт и создания трехмерных моделей, которые иллюстрируют методы работы художника. Программы способны одновременно перерабатывать большой объем данных, не опираясь при этом на прошлый опыт исследователей, подвергать сомнению уже имеющиеся категории и выявлять ошибки в нашем понимании и оценке живописи.
Таким образом, компьютеры способны создать уникальные культурные карты, которые оригинальным образом свяжут исторические артефакты.
Применение программ DIAS и DENDRON
В медицине программы DIAS и DENDRON (сокращ. DDA) используют для изучения микозов и раковых клеток. DIAS отвечает за анализ морфологии клеток, изучает их движения и динамику популяции, а DENDRON — сортирует и сравнивает генетические отпечатки инфекционных организмов, формируя их в древообразные дендрограммы.
Группа исследователей из Массачусетса стала первой, кто использовал DDA в искусстве. Метод кластерного анализа или построения дендрограмм был применен к 55 оцифрованным картинам. Программа DDA позволила перенести все оцифрованные картины в единую базу.
С помощью сравнительного анализа полотна удалось автоматически распределить по девяти разным параметрам: яркости, насыщенности, сложности, красного, оранжевого, желтого, зеленого, голубого и пурпурного оттенков. Каждая пара или группа картин была отсортирована, исходя из соответствия единому признаку, и распределена в порядке растущей прогрессии. Далее коэффициент прогрессии генерировал матрицы, на основе которых были сформированы дендрограммы.
Результаты исследования
Результаты исследования подтвердили художественную связь Веронезе и Сезанна: в своей работе «Стоящая купальщица моет волосы» Сезанн использует паттерны картины «Брак в Кане Галилейской», написанной Паоло Веронезе в 16-ом веке.
Анализ работ также выявил скрытую единую композиционную структуру, отмеченную во всех полотнах Сезанна. Удалось установить, что, вероятнее всего, Сезанн в своем творчестве руководствовался математическими расчетами, а не интуитивными мотивами. Это изменило сложившиеся в искусствоведении представление о неуклюжести и дисбалансе форм Сезанна, на идею о точной выверенной им композиции, соответствующей правилам «золотого сечения».
Благодаря программе DDA можно предположить, что Сезанн закладывал в свои работы не только игру цвета и формы, но и особую головоломку — главную идею своего творчества.
Дара Марич
https://sysblok.ru/arts/kompjuternyj-analiz-sezanna-chto-obedinjaet-seriju-kupalshhikov/
{kind=link}
Перенос стиля рукописей Леонардо да Винчи
#arts
Обычно все показывают перенос стиля на «Звездной ночи» Ван Гога. Но вообще-то технология переноса стиля универсальна и дает возможность проявить немного фантазии.
Идея совместить да Винчи и Data Science пришла в голову исследователю из Вышки Борису Орехову, который и поделился с Системным Блоком этими картинками.
На современные научные статьи о нейросетях наложен визуальный стиль трактатов да Винчи. Посмотрите сами: слева — статья про нейронные сети, справа — рукопись да Винчи, а посередине — результат переноса стиля рукописи на статью.
Как это сделано? C помощью предобученной сверточной нейросети VGG-19, которая способна извлекать признаки из изображений. Из сети нужно удалить все полносвязные слои, чтобы можно было работать со своим входным изображением.
А по ссылке вы найдете еще примеры и сможете проследить стадии переноса стиля на разном числе итераций работы нейросети: https://sysblok.ru/arts/nejronnye-seti-pridumal-leonardo-da-vinchi/
#arts
Обычно все показывают перенос стиля на «Звездной ночи» Ван Гога. Но вообще-то технология переноса стиля универсальна и дает возможность проявить немного фантазии.
Идея совместить да Винчи и Data Science пришла в голову исследователю из Вышки Борису Орехову, который и поделился с Системным Блоком этими картинками.
На современные научные статьи о нейросетях наложен визуальный стиль трактатов да Винчи. Посмотрите сами: слева — статья про нейронные сети, справа — рукопись да Винчи, а посередине — результат переноса стиля рукописи на статью.
Как это сделано? C помощью предобученной сверточной нейросети VGG-19, которая способна извлекать признаки из изображений. Из сети нужно удалить все полносвязные слои, чтобы можно было работать со своим входным изображением.
А по ссылке вы найдете еще примеры и сможете проследить стадии переноса стиля на разном числе итераций работы нейросети: https://sysblok.ru/arts/nejronnye-seti-pridumal-leonardo-da-vinchi/
{kind=link}