
Do Better ImageNet Models Transfer Better?
Finding: better ImageNet architectures tend to work better on other datasets too. Surprise: pretraining on ImageNet dataset sometimes doesn't help very much.
ArXiV: https://arxiv.org/abs/1805.08974
#ImageNet #finetuning #transferlearning
Finding: better ImageNet architectures tend to work better on other datasets too. Surprise: pretraining on ImageNet dataset sometimes doesn't help very much.
ArXiV: https://arxiv.org/abs/1805.08974
#ImageNet #finetuning #transferlearning
Really short and brief, yet useful #tutorial on #PyTorch #transferlearning
Transfer learning is a concept of using network trained for a certain task for another one.
Link: https://medium.com/@iamHarin17/transfer-learning-in-pytorch-f7736598b1ed
#DL #novice #entrylevel #beginner
Transfer learning is a concept of using network trained for a certain task for another one.
Link: https://medium.com/@iamHarin17/transfer-learning-in-pytorch-f7736598b1ed
#DL #novice #entrylevel #beginner
Medium
Implementing Transfer Learning in PyTorch
Transfer Learning is a technique where a model trained for a certain task is used for another similar task.
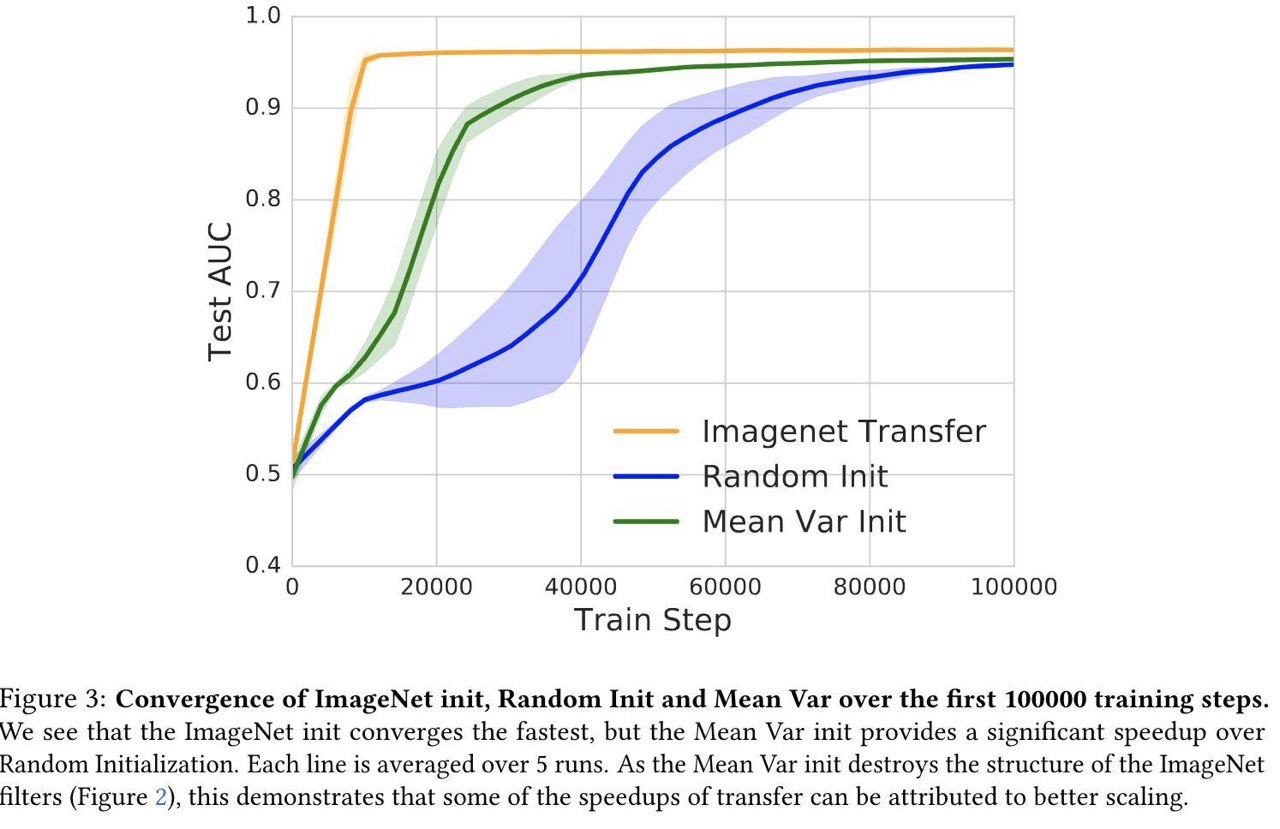
Understanding Transfer Learning for Medical Imaging
ArXiV: https://arxiv.org/abs/1902.07208
#biolearning #dl #transferlearning
ArXiV: https://arxiv.org/abs/1902.07208
#biolearning #dl #transferlearning
{kind=link}
VirTex: Learning Visual Representations from Textual Annotations
The authors offer an alternative approach to pre-training backbones for CV tasks – using semantically dense captions to learn visual representations.
Recent methods have explored unsupervised pretraining to scale to vast quantities of unlabeled images. In contrast, the authors aim to learn high-quality visual representations from fewer images. They revisit supervised pretraining and seek data-efficient alternatives to classification-based pretraining.
VirTex (CNN + Transformer) is pre-trained on COCO captions. On downstream tasks it can reach performance similar to pre-training on ImageNet, but with 10x less images!
Paper: https://arxiv.org/abs/2006.06666
Code: https://github.com/kdexd/virtex
Site: https://kdexd.github.io/virtex/
#imagecaptioning #cv #visual #annotation #transformer #pretraining #transferlearning #deeplearning #paper
The authors offer an alternative approach to pre-training backbones for CV tasks – using semantically dense captions to learn visual representations.
Recent methods have explored unsupervised pretraining to scale to vast quantities of unlabeled images. In contrast, the authors aim to learn high-quality visual representations from fewer images. They revisit supervised pretraining and seek data-efficient alternatives to classification-based pretraining.
VirTex (CNN + Transformer) is pre-trained on COCO captions. On downstream tasks it can reach performance similar to pre-training on ImageNet, but with 10x less images!
Paper: https://arxiv.org/abs/2006.06666
Code: https://github.com/kdexd/virtex
Site: https://kdexd.github.io/virtex/
#imagecaptioning #cv #visual #annotation #transformer #pretraining #transferlearning #deeplearning #paper
{kind=link}
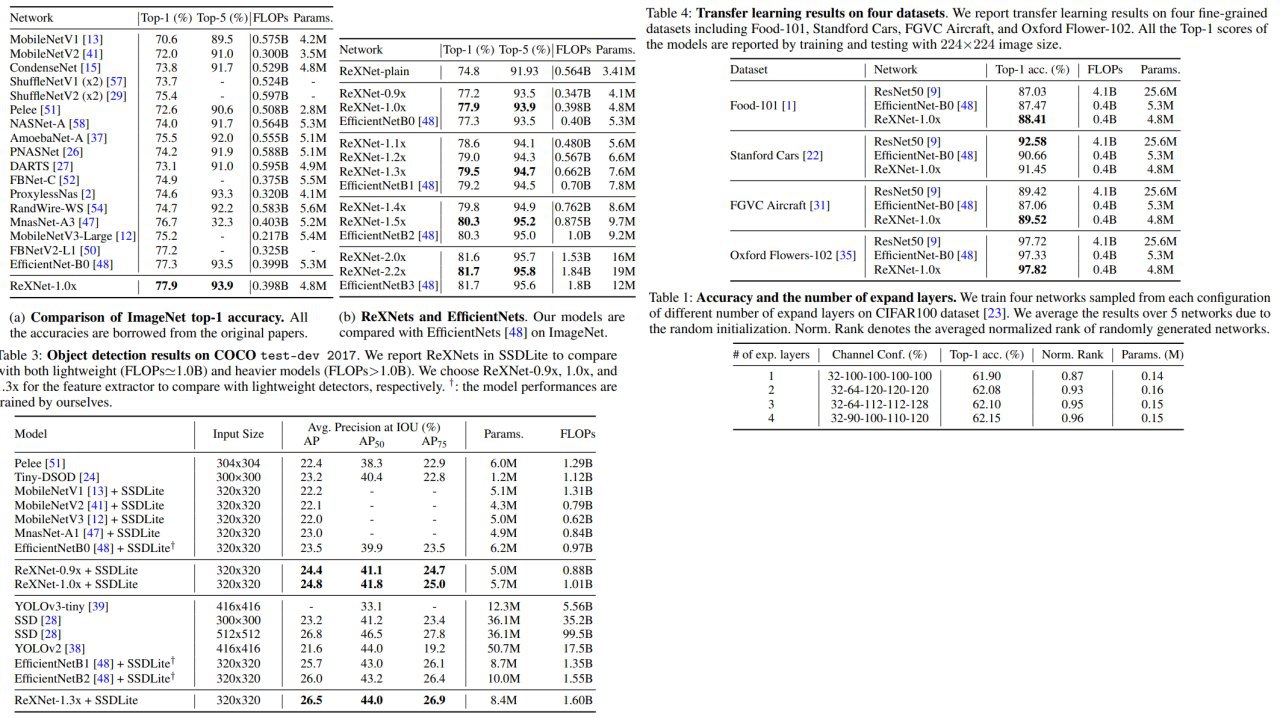
ReXNet: Diminishing Representational Bottleneck on Convolutional Neural Network
The authors propose a set of design principles that improves model performance significantly based on the analysis of representation bottlenecks.
Authors think that commonly used architectures have a representation bottleneck and try to fix it by expanding channel size, using more expand layers, and better activation functions. This also improves the performance of models on ImageNet and good results on transfer learning on classification and object detection.
Authors hope that their design ideas could be used by NAS to create even better models.
Paper: https://arxiv.org/abs/2007.00992
Code: https://github.com/clovaai/rexnet
#deeplearning #pretraining #transferlearning #computervision #pytorch
The authors propose a set of design principles that improves model performance significantly based on the analysis of representation bottlenecks.
Authors think that commonly used architectures have a representation bottleneck and try to fix it by expanding channel size, using more expand layers, and better activation functions. This also improves the performance of models on ImageNet and good results on transfer learning on classification and object detection.
Authors hope that their design ideas could be used by NAS to create even better models.
Paper: https://arxiv.org/abs/2007.00992
Code: https://github.com/clovaai/rexnet
#deeplearning #pretraining #transferlearning #computervision #pytorch
{kind=link}
👍1