
Few-shot Video-to-Video Synthesis
it's the pytorch implementation for few-shot photorealistic video-to-video (vid2vid) translation.
it can be used for generating human motions from poses, synthesizing people talking from edge maps, or turning semantic label maps into photo-realistic videos.
the core of vid2vid translation is image-to-image translation.
blog post: https://nvlabs.github.io/few-shot-vid2vid/
paper: https://arxiv.org/abs/1910.12713
youtube: https://youtu.be/8AZBuyEuDqc
github: https://github.com/NVlabs/few-shot-vid2vid
#cv #nips #neurIPS #pattern #recognition #vid2vid #synthesis
it's the pytorch implementation for few-shot photorealistic video-to-video (vid2vid) translation.
it can be used for generating human motions from poses, synthesizing people talking from edge maps, or turning semantic label maps into photo-realistic videos.
the core of vid2vid translation is image-to-image translation.
blog post: https://nvlabs.github.io/few-shot-vid2vid/
paper: https://arxiv.org/abs/1910.12713
youtube: https://youtu.be/8AZBuyEuDqc
github: https://github.com/NVlabs/few-shot-vid2vid
#cv #nips #neurIPS #pattern #recognition #vid2vid #synthesis
❤1
Scene Text Recognition via Transformer
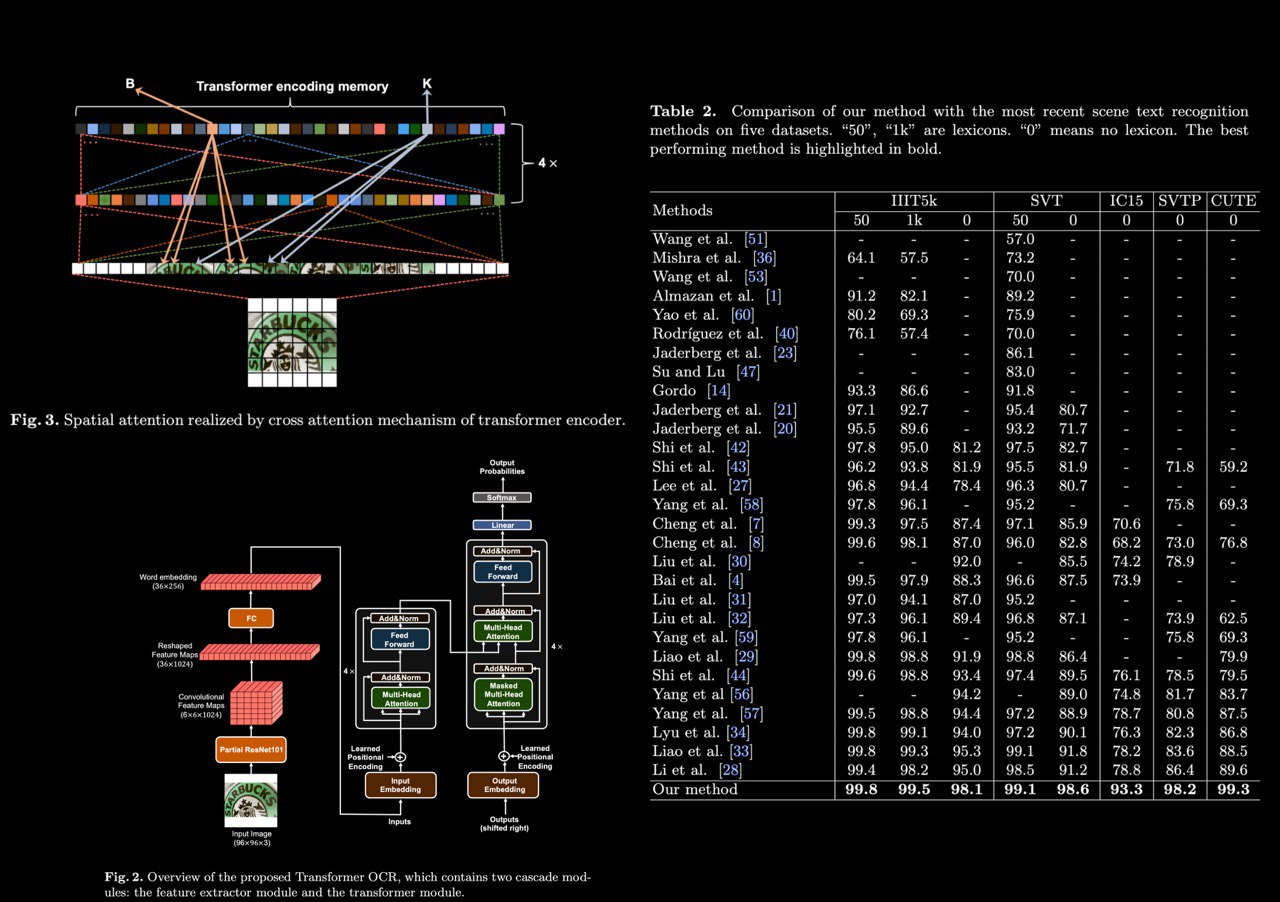
The authors propose a simple but extremely effective scene text recognition method based on the transformer. The proposed method uses convolutional feature maps as word embedding input into the transformer. In such a way, their method is able to make full use of the powerful attention mechanism of the transformer.
Extensive experimental results show that the proposed method significantly outperforms SOTA methods by a very large margin on both regular and irregular text datasets. In particular, the proposed method performs the best on two regular text benchmarks. On irregular text benchmarks, the proposed method shows its powerful ability to recognize irregular texts. Surprisingly, the proposed method outperforms the second best by very large margins, 14.5%, 11.8%, and 9.7%, on the IC15, SVTP, and CUTE, respectively.
paper: https://arxiv.org/abs/2003.08077
github: https://github.com/fengxinjie/Transformer-OCR
#ocr #scene #text #recognition #cv #nlp #resNet #Transformer
The authors propose a simple but extremely effective scene text recognition method based on the transformer. The proposed method uses convolutional feature maps as word embedding input into the transformer. In such a way, their method is able to make full use of the powerful attention mechanism of the transformer.
Extensive experimental results show that the proposed method significantly outperforms SOTA methods by a very large margin on both regular and irregular text datasets. In particular, the proposed method performs the best on two regular text benchmarks. On irregular text benchmarks, the proposed method shows its powerful ability to recognize irregular texts. Surprisingly, the proposed method outperforms the second best by very large margins, 14.5%, 11.8%, and 9.7%, on the IC15, SVTP, and CUTE, respectively.
paper: https://arxiv.org/abs/2003.08077
github: https://github.com/fengxinjie/Transformer-OCR
#ocr #scene #text #recognition #cv #nlp #resNet #Transformer
{kind=link}