
«Efficient Neural Architecture Search via Parameters Sharing»
Authors reduced the computational requirement (GPU-hrs) of standard Neural Architecture Search by 1000x via parameter sharing between models that are subgraphs within a large computational graph. ENAS achieves SOTA on PTB language modeling among all methods without post-training processing and strong performance on CIFAR-10.
Link: https://arxiv.org/pdf/1802.03268.pdf
#arxiv #optimization #neuralnetworks
Authors reduced the computational requirement (GPU-hrs) of standard Neural Architecture Search by 1000x via parameter sharing between models that are subgraphs within a large computational graph. ENAS achieves SOTA on PTB language modeling among all methods without post-training processing and strong performance on CIFAR-10.
Link: https://arxiv.org/pdf/1802.03268.pdf
#arxiv #optimization #neuralnetworks
🥇Parameter optimization in neural networks.
Play with three interactive visualizations and develop your intuition for optimizing model parameters.
Link: https://www.deeplearning.ai/ai-notes/optimization/
#interactive #demo #optimization #parameteroptimization #novice #entrylevel #beginner #goldcontent #nn #neuralnetwork
Play with three interactive visualizations and develop your intuition for optimizing model parameters.
Link: https://www.deeplearning.ai/ai-notes/optimization/
#interactive #demo #optimization #parameteroptimization #novice #entrylevel #beginner #goldcontent #nn #neuralnetwork
Great artilce on pandas optimization
Link: https://medium.com/bigdatarepublic/advanced-pandas-optimize-speed-and-memory-a654b53be6c2
#pandas #optimization
Link: https://medium.com/bigdatarepublic/advanced-pandas-optimize-speed-and-memory-a654b53be6c2
#pandas #optimization
Medium
Advanced Pandas: Optimize speed and memory
Nowadays the Python data analysis library Pandas is widely used across the world. It started mostly as a data exploration and…
👍1
ZeRO, DeepSpeed & Turing-NLG
ZeRO: Memory Optimization Towards Training A Trillion Parameter Models
Turing-NLG: A 17-billion-parameter language model by Microsoft
Microsoft is releasing an open-source library called DeepSpeed, which vastly advances large model training by improving scale, speed, cost, and usability, unlocking the ability to train 100-billion-parameter models; compatible with PyTorch.
ZeRO – is a new parallelized optimizer that greatly reduces the resources needed for model and data parallelism while massively increasing the number of parameters that can be trained.
ZeRO has three main optimization stages, which correspond to the partitioning of optimizer states, gradients, and parameters. When enabled cumulatively:
0. Optimizer State Partitioning (
1. Add Gradient Partitioning (
2. Add Parameter Partitioning (
They have used these breakthroughs to create Turing Natural Language Generation (Turing-NLG), the largest publicly known language model at 17 billion parameters, which you can learn more about in this accompanying blog post. Also, the abstract for Turing-NLG had been written by their own model
ZeRO & DeepSpeed: https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
paper: https://arxiv.org/abs/1910.02054
github: https://github.com/microsoft/DeepSpeed
Turing-NLG: https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
#nlp #dl #ml #microsoft #deepspeed #optimization
ZeRO: Memory Optimization Towards Training A Trillion Parameter Models
Turing-NLG: A 17-billion-parameter language model by Microsoft
Microsoft is releasing an open-source library called DeepSpeed, which vastly advances large model training by improving scale, speed, cost, and usability, unlocking the ability to train 100-billion-parameter models; compatible with PyTorch.
ZeRO – is a new parallelized optimizer that greatly reduces the resources needed for model and data parallelism while massively increasing the number of parameters that can be trained.
ZeRO has three main optimization stages, which correspond to the partitioning of optimizer states, gradients, and parameters. When enabled cumulatively:
0. Optimizer State Partitioning (
P_os_) – 4x memory reduction, same communication volume as data parallelism1. Add Gradient Partitioning (
P_os+g_) – 8x memory reduction, same communication volume as data parallelism2. Add Parameter Partitioning (
P_os+g+p_) – memory reduction is linear with data parallelism degree N_d_They have used these breakthroughs to create Turing Natural Language Generation (Turing-NLG), the largest publicly known language model at 17 billion parameters, which you can learn more about in this accompanying blog post. Also, the abstract for Turing-NLG had been written by their own model
ZeRO & DeepSpeed: https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
paper: https://arxiv.org/abs/1910.02054
github: https://github.com/microsoft/DeepSpeed
Turing-NLG: https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
#nlp #dl #ml #microsoft #deepspeed #optimization
{kind=link}
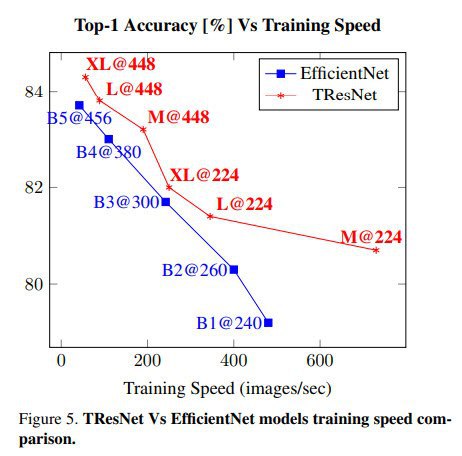
TResNet: High Performance GPU-Dedicated Architecture
An alternative design of ResNet Architecture to better utilize GPU structure and assets.
Modern neural net architectures provide high accuracy but often at the expense of FLOPS count.
The authors of this paper suggest various design and optimization improvements achieve both higher accuracy and efficiency.
There are three variants of architecture: TResNet-M, TResNet-L, and TResNet-XL. These three models vary only in-depth and the number of channels.
The refinements of the architecture:
– SpaceToDepth stem
– Anti-Alias downsampling
– In-Place Activated BatchNorm
– Blocks selection
– SE layers
They also use Jit Compilation for layers without learnable parameters and a custom implementation of Average pooling with up to 5 times speed increase.
Paper: https://arxiv.org/abs/2003.13630
Github: https://github.com/mrT23/TResNet
#deeplearning #architecture #optimization
An alternative design of ResNet Architecture to better utilize GPU structure and assets.
Modern neural net architectures provide high accuracy but often at the expense of FLOPS count.
The authors of this paper suggest various design and optimization improvements achieve both higher accuracy and efficiency.
There are three variants of architecture: TResNet-M, TResNet-L, and TResNet-XL. These three models vary only in-depth and the number of channels.
The refinements of the architecture:
– SpaceToDepth stem
– Anti-Alias downsampling
– In-Place Activated BatchNorm
– Blocks selection
– SE layers
They also use Jit Compilation for layers without learnable parameters and a custom implementation of Average pooling with up to 5 times speed increase.
Paper: https://arxiv.org/abs/2003.13630
Github: https://github.com/mrT23/TResNet
#deeplearning #architecture #optimization
{kind=link}