
REST: Robust and Efficient Neural Networks for Sleep Monitoring in the Wild
New approach for sleep monitoring.
Nowadays a lot of people suffer from sleep disorders thataffects their daily functioning, long-term health and longevity. Thelong-term effects of sleep deprivation and sleep disorders includean increased risk of hypertension, diabetes, obesity, depression, heart attack, and stroke. As a result sleep monitoring is a very important topic.
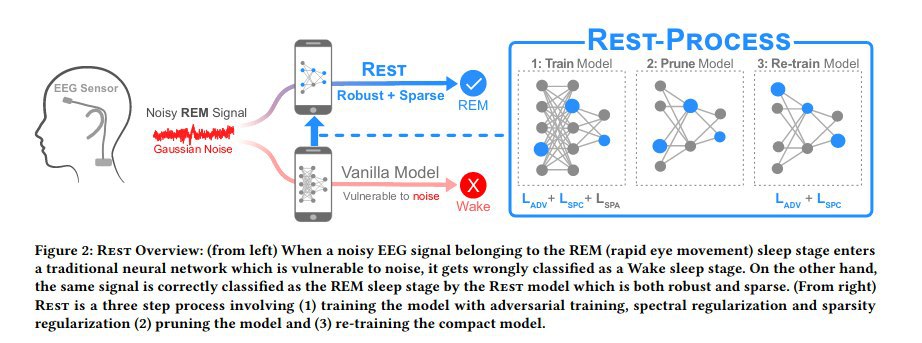
Currently automatical documentation of sleep stages isn't robust against noises (which can be introduced by electrical interferences (e.g., power-line) and user motions (e.g., muscle contraction, respiration)) and isn't computationaly efficient enough for fast calculations on user devices.
The authors offer the following improvenents:
- adversarial training and spectral regularization to improve robustness to noise
- sparsity regularization to improve energy and computational efficiency
Rest models achieves a macro-F1 score of 0.67 vs. 0.39 for the state-of-the-art model in the presence of Gaussian noise, with 19×parameter and 15×MFLOPS reduction.
The model is also deployed onto a Pixel 2 smartphone. It achieves 17x energy reduction and 9x faster inference compared to uncompressed models.
Paper: https://arxiv.org/abs/2001.11363
Code: https://github.com/duggalrahul/REST
#deeplearning #compression #adversarial #sleepstaging
New approach for sleep monitoring.
Nowadays a lot of people suffer from sleep disorders thataffects their daily functioning, long-term health and longevity. Thelong-term effects of sleep deprivation and sleep disorders includean increased risk of hypertension, diabetes, obesity, depression, heart attack, and stroke. As a result sleep monitoring is a very important topic.
Currently automatical documentation of sleep stages isn't robust against noises (which can be introduced by electrical interferences (e.g., power-line) and user motions (e.g., muscle contraction, respiration)) and isn't computationaly efficient enough for fast calculations on user devices.
The authors offer the following improvenents:
- adversarial training and spectral regularization to improve robustness to noise
- sparsity regularization to improve energy and computational efficiency
Rest models achieves a macro-F1 score of 0.67 vs. 0.39 for the state-of-the-art model in the presence of Gaussian noise, with 19×parameter and 15×MFLOPS reduction.
The model is also deployed onto a Pixel 2 smartphone. It achieves 17x energy reduction and 9x faster inference compared to uncompressed models.
Paper: https://arxiv.org/abs/2001.11363
Code: https://github.com/duggalrahul/REST
#deeplearning #compression #adversarial #sleepstaging
{kind=link}
❤1
Training with quantization noise for extreme model compression
It is a new technique to enable extreme compression of models that still deliver high performance when deployed in practical applications mimics the effect of quantization during training time.
This method delivers performance that nearly matches that of the original uncompressed models while reducing the memory footprint by 10x to 20x. This significantly exceeds the 4x compression with int8 currently available in both PyTorch and Tensorflow. Quant-Noise can be used to shrink models even further – by more than 50x – in use cases where greater performance trade-offs are acceptable. Quant-Noise changes model training only by adding a regularization noise similar to dropout, with no impact on either the convergence rate or training speed.
At training time during the forward pass, it takes a subset of the weights and then randomly applies simulated quantization noise. This makes the model resilient to quantization and enables large compression ratios without much loss in accuracy.
Quant-Noise is applied to only a subset of the weights. This method has the advantage that the unbiased gradients still flow from the weights that are unaffected by the noise.
The authors demonstrated that their framework compresses the SOTA EfficientNet-B3 model from ~50 MB to 3.3 MB while achieving 80% top-1 accuracy on ImageNet, compared with 81.7% for the uncompressed model. Compress RoBERTa Base model from 480 MB to 14 MB while achieving 82.5% on MNLI, compared with 84.8% for the original model.
blogpost: https://ai.facebook.com/blog/training-with-quantization-noise-for-extreme-model-compression/
paper: https://arxiv.org/abs/2004.07320
github: https://github.com/pytorch/fairseq/tree/master/examples/quant_noise
#quantization #compression #shrinking
It is a new technique to enable extreme compression of models that still deliver high performance when deployed in practical applications mimics the effect of quantization during training time.
This method delivers performance that nearly matches that of the original uncompressed models while reducing the memory footprint by 10x to 20x. This significantly exceeds the 4x compression with int8 currently available in both PyTorch and Tensorflow. Quant-Noise can be used to shrink models even further – by more than 50x – in use cases where greater performance trade-offs are acceptable. Quant-Noise changes model training only by adding a regularization noise similar to dropout, with no impact on either the convergence rate or training speed.
At training time during the forward pass, it takes a subset of the weights and then randomly applies simulated quantization noise. This makes the model resilient to quantization and enables large compression ratios without much loss in accuracy.
Quant-Noise is applied to only a subset of the weights. This method has the advantage that the unbiased gradients still flow from the weights that are unaffected by the noise.
The authors demonstrated that their framework compresses the SOTA EfficientNet-B3 model from ~50 MB to 3.3 MB while achieving 80% top-1 accuracy on ImageNet, compared with 81.7% for the uncompressed model. Compress RoBERTa Base model from 480 MB to 14 MB while achieving 82.5% on MNLI, compared with 84.8% for the original model.
blogpost: https://ai.facebook.com/blog/training-with-quantization-noise-for-extreme-model-compression/
paper: https://arxiv.org/abs/2004.07320
github: https://github.com/pytorch/fairseq/tree/master/examples/quant_noise
#quantization #compression #shrinking