
MaxUp: A Simple Way to Improve Generalization of Neural Network Training
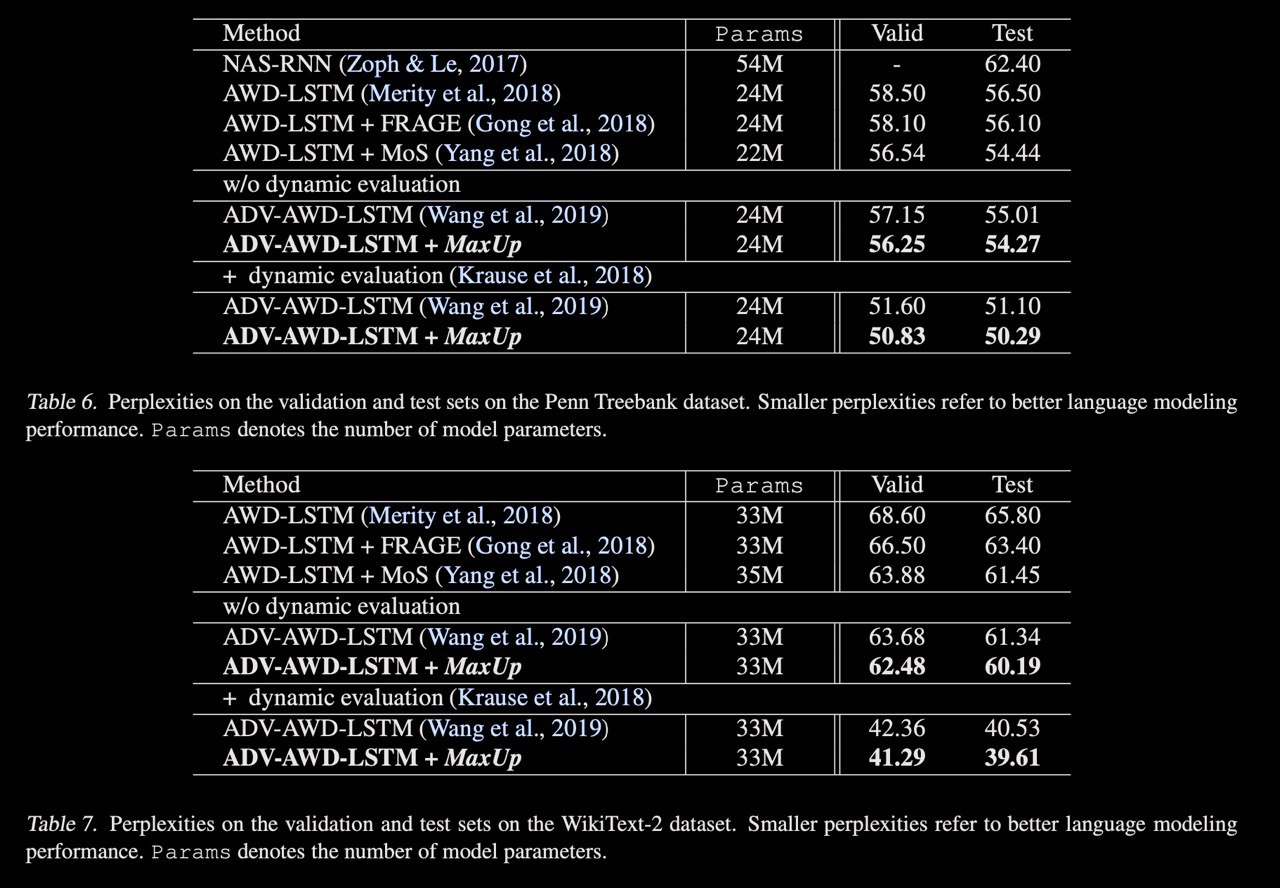
A new approach to augmentation both images and text. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, the authors implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. Testing MaxUp on a range of tasks, including image classification, language modeling, and adversarial certification, it is consistently outperforming the existing best baseline methods, without introducing substantial computational overhead.
Each sample in the batch is augmented
There is some proof of the theorem that MaxUp is gradient-norm regularization if minimizing loss through all batch. Also, It can be viewed as an adversarial variant of data augmentation, in that it minimizes the worse case loss on the perturbed data, instead of an average loss like typical data augmentation methods.
MaxUp easy to mix with other
paper: https://arxiv.org/abs/2002.09024
#augmentations #SOTA #ml
A new approach to augmentation both images and text. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, the authors implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. Testing MaxUp on a range of tasks, including image classification, language modeling, and adversarial certification, it is consistently outperforming the existing best baseline methods, without introducing substantial computational overhead.
Each sample in the batch is augmented
m times and then found aug with maximum loss and does backprop only through that. i.e. minimizing max loss.There is some proof of the theorem that MaxUp is gradient-norm regularization if minimizing loss through all batch. Also, It can be viewed as an adversarial variant of data augmentation, in that it minimizes the worse case loss on the perturbed data, instead of an average loss like typical data augmentation methods.
MaxUp easy to mix with other
augs without the overhead. Only m times to forward pass on the sample but one time to backprop. paper: https://arxiv.org/abs/2002.09024
#augmentations #SOTA #ml
{kind=link}