
Fast Segment Anything
The Segment Anything Model (SAM), a revolutionary tool in computer vision tasks, has significantly impacted various high-level tasks like image segmentation, image captioning, and image editing. However, its application has been restricted in industry scenarios due to its enormous computational demand, largely attributed to the Transformer architecture handling high-resolution inputs.
The authors of this paper have proposed a speedier alternative method that accomplishes this foundational task with performance on par with SAM, but at a staggering 50 times faster! By ingeniously reformulating the task as segments-generation and prompting and employing a regular CNN detector with an instance segmentation branch, they've converted this task into the well-established instance segmentation task. The magic touch? They've trained the existing instance segmentation method using just 1/50 of the SA-1B dataset, a stroke of brilliance that led to a solution marrying performance and efficiency.
Paper link: https://huggingface.co/papers/2306.12156
Code link: https://github.com/CASIA-IVA-Lab/FastSAM
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-fastsam
#deeplearning #cv #segmentanythingmodel #efficiency
The Segment Anything Model (SAM), a revolutionary tool in computer vision tasks, has significantly impacted various high-level tasks like image segmentation, image captioning, and image editing. However, its application has been restricted in industry scenarios due to its enormous computational demand, largely attributed to the Transformer architecture handling high-resolution inputs.
The authors of this paper have proposed a speedier alternative method that accomplishes this foundational task with performance on par with SAM, but at a staggering 50 times faster! By ingeniously reformulating the task as segments-generation and prompting and employing a regular CNN detector with an instance segmentation branch, they've converted this task into the well-established instance segmentation task. The magic touch? They've trained the existing instance segmentation method using just 1/50 of the SA-1B dataset, a stroke of brilliance that led to a solution marrying performance and efficiency.
Paper link: https://huggingface.co/papers/2306.12156
Code link: https://github.com/CASIA-IVA-Lab/FastSAM
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-fastsam
#deeplearning #cv #segmentanythingmodel #efficiency
{kind=link}
❤16👍6🔥3
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
In the rapidly evolving landscape of artificial intelligence, a groundbreaking approach to supervised classification performance has been born. Modern hierarchical vision transformers have been known to incorporate various vision-specific components, aiming to enhance accuracies and produce desirable FLOP counts. However, these augmentations have led to slower processing times compared to their vanilla ViT counterparts. In this exciting research, we challenge the necessity of such additional complexities.
Enter Hiera, an innovative and significantly simplified hierarchical vision transformer that champions efficiency without compromising accuracy. By deploying a potent visual pretext task, MAE, we're able to eliminate the bells-and-whistles from a state-of-the-art multi-stage vision transformer. The result? A lean, mean machine learning model that not only outperforms its predecessors in terms of accuracy but also achieves superior speed, both during inference and training. Tested across a diverse array of image and video recognition tasks, Hiera stands as a beacon of progress in the field of computer vision.
Paper link: https://arxiv.org/abs/2306.00989
Code link: https://github.com/facebookresearch/hiera
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hiera
#deeplearning #cv #transformer #sota
In the rapidly evolving landscape of artificial intelligence, a groundbreaking approach to supervised classification performance has been born. Modern hierarchical vision transformers have been known to incorporate various vision-specific components, aiming to enhance accuracies and produce desirable FLOP counts. However, these augmentations have led to slower processing times compared to their vanilla ViT counterparts. In this exciting research, we challenge the necessity of such additional complexities.
Enter Hiera, an innovative and significantly simplified hierarchical vision transformer that champions efficiency without compromising accuracy. By deploying a potent visual pretext task, MAE, we're able to eliminate the bells-and-whistles from a state-of-the-art multi-stage vision transformer. The result? A lean, mean machine learning model that not only outperforms its predecessors in terms of accuracy but also achieves superior speed, both during inference and training. Tested across a diverse array of image and video recognition tasks, Hiera stands as a beacon of progress in the field of computer vision.
Paper link: https://arxiv.org/abs/2306.00989
Code link: https://github.com/facebookresearch/hiera
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hiera
#deeplearning #cv #transformer #sota
{kind=link}
👍11❤3👀3🔥2🥰1
Recognize Anything: A Strong Image Tagging Model
Get ready for a breakthrough in the realm of AI: introducing the Recognize Anything Model (RAM), a powerful new model that is set to revolutionize image tagging. RAM, a titan in the world of large computer vision models, astoundingly exhibits the zero-shot ability to recognize any common category with an impressive level of accuracy. Shattering traditional approaches, RAM employs a unique paradigm for image tagging, utilizing large-scale image-text pairs for training instead of relying on tedious manual annotations.
RAM's development comprises a strategic, four-step process. Initially, annotation-free image tags are obtained on a large scale via an automated text semantic parsing. This is followed by training a preliminary model for automatic annotation, fusing caption and tagging tasks under the supervision of original texts and parsed tags. Then, RAM utilizes a data engine to generate extra annotations and eliminate incorrect ones, refining the input. Finally, the model is meticulously retrained with the cleaned data and fine-tuned using a smaller, higher-quality dataset. Extensive evaluations of RAM have revealed stunning results: it outshines its counterparts like CLIP and BLIP in zero-shot performance, even surpassing fully supervised models, exhibiting a competitive edge akin to Google's tagging API!
Paper link: https://arxiv.org/abs/2306.03514
Code link: https://github.com/xinyu1205/recognize-anything
Project link: https://recognize-anything.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ram
#deeplearning #cv #imagecaptioning
Get ready for a breakthrough in the realm of AI: introducing the Recognize Anything Model (RAM), a powerful new model that is set to revolutionize image tagging. RAM, a titan in the world of large computer vision models, astoundingly exhibits the zero-shot ability to recognize any common category with an impressive level of accuracy. Shattering traditional approaches, RAM employs a unique paradigm for image tagging, utilizing large-scale image-text pairs for training instead of relying on tedious manual annotations.
RAM's development comprises a strategic, four-step process. Initially, annotation-free image tags are obtained on a large scale via an automated text semantic parsing. This is followed by training a preliminary model for automatic annotation, fusing caption and tagging tasks under the supervision of original texts and parsed tags. Then, RAM utilizes a data engine to generate extra annotations and eliminate incorrect ones, refining the input. Finally, the model is meticulously retrained with the cleaned data and fine-tuned using a smaller, higher-quality dataset. Extensive evaluations of RAM have revealed stunning results: it outshines its counterparts like CLIP and BLIP in zero-shot performance, even surpassing fully supervised models, exhibiting a competitive edge akin to Google's tagging API!
Paper link: https://arxiv.org/abs/2306.03514
Code link: https://github.com/xinyu1205/recognize-anything
Project link: https://recognize-anything.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ram
#deeplearning #cv #imagecaptioning
{kind=link}
👍9🔥3❤2
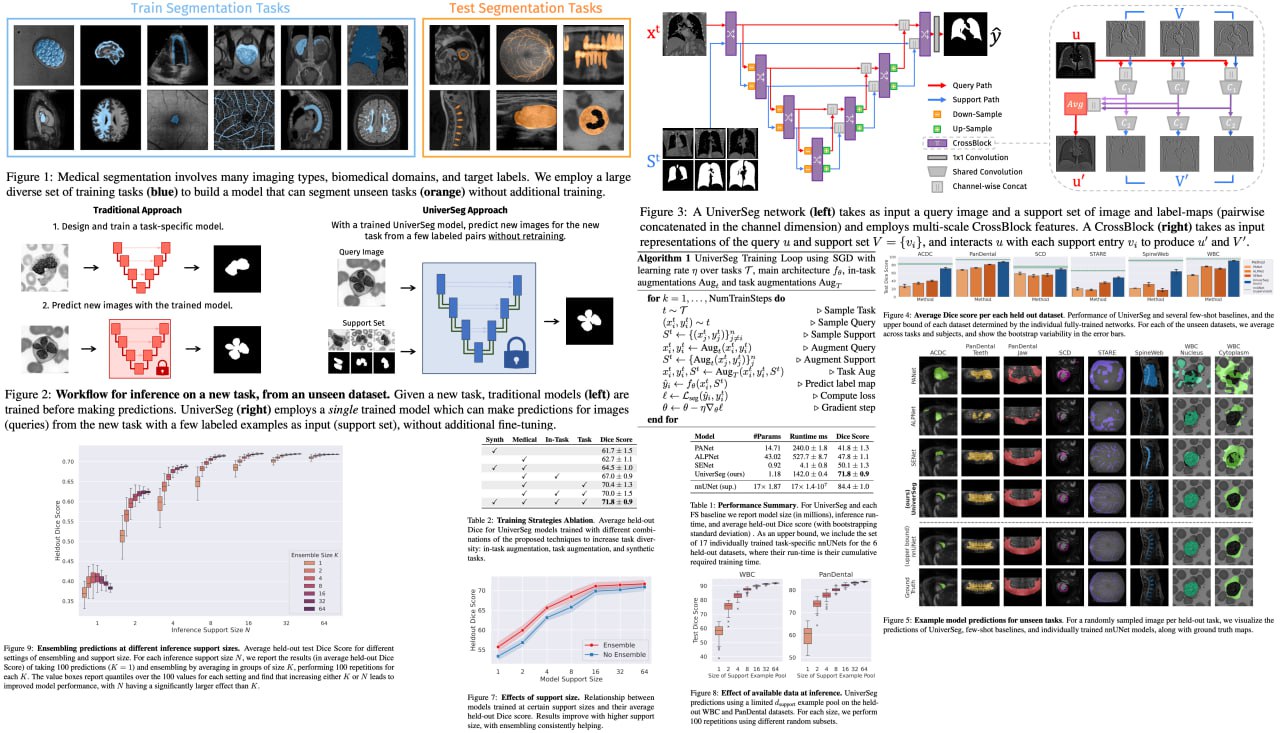
UniverSeg: Universal Medical Image Segmentation
Get ready for a major breakthrough in the field of medical image segmentation! Deep learning models, despite being the primary tool for medical image segmentation, have always struggled to generalize to new, unseen segmentation tasks involving different anatomies, image modalities, or labels. This has typically required researchers to spend significant time and resources on training or fine-tuning models for each new task, a process often out of reach for many clinical researchers. Enter UniverSeg, a trailblazing solution that simplifies this process by tackling unseen medical segmentation tasks without any need for additional training. Its revolutionary Cross-Block mechanism delivers accurate segmentation maps from a query image and a set of example image-label pairs, completely eliminating the need for retraining.
To make this leap, the team behind UniverSeg went the extra mile and assembled MegaMedical, an expansive collection of over 22,000 scans from 53 diverse open-access medical segmentation datasets. This wide variety of anatomies and imaging modalities provided a comprehensive training ground for UniverSeg, priming it to excel in a multitude of scenarios. The results are nothing short of phenomenal - UniverSeg substantially outperforms several related methods on unseen tasks, bringing a new era of efficiency and accessibility to medical imaging.
Paper link: https://arxiv.org/abs/2304.06131
Project link: https://universeg.csail.mit.edu/
Code link: https://github.com/JJGO/UniverSeg
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universeg-med
#deeplearning #cv #imagesegmentation
Get ready for a major breakthrough in the field of medical image segmentation! Deep learning models, despite being the primary tool for medical image segmentation, have always struggled to generalize to new, unseen segmentation tasks involving different anatomies, image modalities, or labels. This has typically required researchers to spend significant time and resources on training or fine-tuning models for each new task, a process often out of reach for many clinical researchers. Enter UniverSeg, a trailblazing solution that simplifies this process by tackling unseen medical segmentation tasks without any need for additional training. Its revolutionary Cross-Block mechanism delivers accurate segmentation maps from a query image and a set of example image-label pairs, completely eliminating the need for retraining.
To make this leap, the team behind UniverSeg went the extra mile and assembled MegaMedical, an expansive collection of over 22,000 scans from 53 diverse open-access medical segmentation datasets. This wide variety of anatomies and imaging modalities provided a comprehensive training ground for UniverSeg, priming it to excel in a multitude of scenarios. The results are nothing short of phenomenal - UniverSeg substantially outperforms several related methods on unseen tasks, bringing a new era of efficiency and accessibility to medical imaging.
Paper link: https://arxiv.org/abs/2304.06131
Project link: https://universeg.csail.mit.edu/
Code link: https://github.com/JJGO/UniverSeg
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universeg-med
#deeplearning #cv #imagesegmentation
{kind=link}
👍17❤6🔥3
Practical ML Conf - The biggest offline ML conference of the year in Moscow.
- https://pmlconf.yandex.ru
- September 7, Moscow
- For speakers: offline
- For participants: offline and online (youtube)
- The conference language is Russian.
Call for propose is open https://pmlconf.yandex.ru/call_for_papers
#conference #nlp #cv #genAI #recsys #mlops #ecomm #hardware #research #offline #online
- https://pmlconf.yandex.ru
- September 7, Moscow
- For speakers: offline
- For participants: offline and online (youtube)
- The conference language is Russian.
Call for propose is open https://pmlconf.yandex.ru/call_for_papers
#conference #nlp #cv #genAI #recsys #mlops #ecomm #hardware #research #offline #online
Practical ML Conf 2025
Конференция про практический ML от Яндекса
👍23👎13🔥6👏2
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
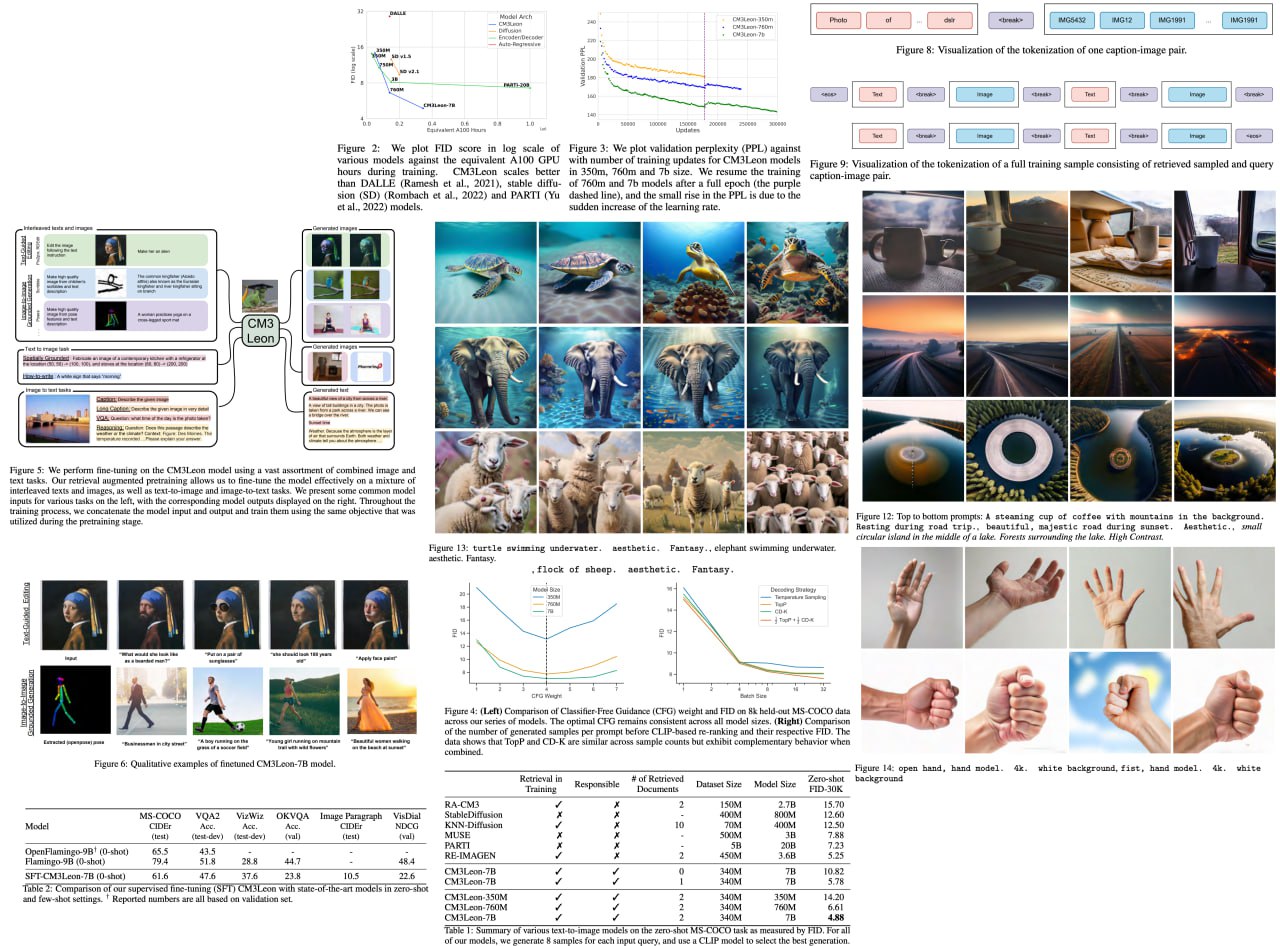
Introducing CM3Leon (pronounced “Chameleon”), a multi-modal language model that's revolutionizing the realms of text and image generation. This model, designed with a decoder-only, retrieval-augmented, and token-based structure, expands on the established CM3 multi-modal architecture. It showcases the striking benefits of scaling and diversification in instruction-style data. The most impressive part? It's the first of its kind, trained with a recipe inspired by text-only language models, including a substantial retrieval-augmented pretraining phase and a secondary multi-task supervised fine-tuning (SFT) stage. It exemplifies the power of general-purpose models, capable of both text-to-image and image-to-text generation.
CM3Leon isn't just a theoretical model, but a proven performer. Through extensive experiments, it demonstrates the effectiveness of this new approach for multi-modal models. Remarkably, it achieves state-of-the-art performance in text-to-image generation, requiring 5x less training compute than comparable methods, and achieving a zero-shot MS-COCO FID of 4.88. Post-SFT, CM3Leon exhibits an unmatched level of controllability across various tasks, ranging from language-guided image editing to image-controlled generation and segmentation.
Paper link: https://ai.meta.com/research/publications/scaling-autoregressive-multi-modal-models-pretraining-and-instruction-tuning/
Blogpost link: https://ai.meta.com/blog/generative-ai-text-images-cm3leon/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cm3leon
#deeplearning #cv #nlp #imagegeneration #sota #multimodal
Introducing CM3Leon (pronounced “Chameleon”), a multi-modal language model that's revolutionizing the realms of text and image generation. This model, designed with a decoder-only, retrieval-augmented, and token-based structure, expands on the established CM3 multi-modal architecture. It showcases the striking benefits of scaling and diversification in instruction-style data. The most impressive part? It's the first of its kind, trained with a recipe inspired by text-only language models, including a substantial retrieval-augmented pretraining phase and a secondary multi-task supervised fine-tuning (SFT) stage. It exemplifies the power of general-purpose models, capable of both text-to-image and image-to-text generation.
CM3Leon isn't just a theoretical model, but a proven performer. Through extensive experiments, it demonstrates the effectiveness of this new approach for multi-modal models. Remarkably, it achieves state-of-the-art performance in text-to-image generation, requiring 5x less training compute than comparable methods, and achieving a zero-shot MS-COCO FID of 4.88. Post-SFT, CM3Leon exhibits an unmatched level of controllability across various tasks, ranging from language-guided image editing to image-controlled generation and segmentation.
Paper link: https://ai.meta.com/research/publications/scaling-autoregressive-multi-modal-models-pretraining-and-instruction-tuning/
Blogpost link: https://ai.meta.com/blog/generative-ai-text-images-cm3leon/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cm3leon
#deeplearning #cv #nlp #imagegeneration #sota #multimodal
{kind=link}
👍12❤2🔥1
Meta-Transformer: A Unified Framework for Multimodal Learning
The landscape of multimodal learning is about to witness a remarkable transformation with the introduction of Meta-Transformer, a state-of-the-art framework that's poised to overcome long-standing challenges in the field. The beauty of Meta-Transformer lies in its unique ability to process and understand information from a diverse range of modalities - from natural language, 2D images, 3D point clouds, to audio, video, time series, and tabular data. This ability stems from its innovative design that leverages a frozen encoder to map raw input data from these diverse modalities into a shared token space, eliminating the need for paired multimodal training data.
More than just a theoretical achievement, the Meta-Transformer has proven its practical application across various benchmarks, handling an impressive range of tasks from fundamental perception such as text, image, and audio processing, to more complex applications like X-Ray, infrared, and hyperspectral data interpretation, as well as data mining tasks involving graph, tabular, and time-series data.
Code link: https://github.com/invictus717/MetaTransformer
Paper link: https://arxiv.org/abs/2307.10802
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-meta-transformer
#deeplearning #nlp #transformer #cv
The landscape of multimodal learning is about to witness a remarkable transformation with the introduction of Meta-Transformer, a state-of-the-art framework that's poised to overcome long-standing challenges in the field. The beauty of Meta-Transformer lies in its unique ability to process and understand information from a diverse range of modalities - from natural language, 2D images, 3D point clouds, to audio, video, time series, and tabular data. This ability stems from its innovative design that leverages a frozen encoder to map raw input data from these diverse modalities into a shared token space, eliminating the need for paired multimodal training data.
More than just a theoretical achievement, the Meta-Transformer has proven its practical application across various benchmarks, handling an impressive range of tasks from fundamental perception such as text, image, and audio processing, to more complex applications like X-Ray, infrared, and hyperspectral data interpretation, as well as data mining tasks involving graph, tabular, and time-series data.
Code link: https://github.com/invictus717/MetaTransformer
Paper link: https://arxiv.org/abs/2307.10802
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-meta-transformer
#deeplearning #nlp #transformer #cv
{kind=link}
👍8👨💻6🔥3❤2
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
The fusion of transformer and convolutional architectures has ushered in a new era of enhanced model accuracy and efficiency, and FastViT is at the forefront of this revolution. This novel hybrid vision transformer architecture boasts an impressive latency-accuracy trade-off, setting new benchmarks in the field. Key to its success is the RepMixer, an innovative token mixing operator that utilizes structural reparameterization to slash memory access costs by doing away with traditional skip-connections.
In practical terms, FastViT's prowess is undeniable. Not only is it a staggering 3.5x faster than CMT on mobile devices for ImageNet accuracy, but it also leaves EfficientNet and ConvNeXt trailing in its wake, being 4.9x and 1.9x faster respectively. Additionally, when pitted against MobileOne at a similar latency, FastViT emerges triumphant with a 4.2% superior Top-1 accuracy. Across a spectrum of tasks, from image classification and detection to segmentation and 3D mesh regression, FastViT consistently outshines its competitors, showcasing both remarkable speed and robustness against out-of-distribution samples and corruptions.
Paper link: https://huggingface.co/papers/2303.14189
Code link: https://github.com/apple/ml-fastvit
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-fastvit
#deeplearning #cv
The fusion of transformer and convolutional architectures has ushered in a new era of enhanced model accuracy and efficiency, and FastViT is at the forefront of this revolution. This novel hybrid vision transformer architecture boasts an impressive latency-accuracy trade-off, setting new benchmarks in the field. Key to its success is the RepMixer, an innovative token mixing operator that utilizes structural reparameterization to slash memory access costs by doing away with traditional skip-connections.
In practical terms, FastViT's prowess is undeniable. Not only is it a staggering 3.5x faster than CMT on mobile devices for ImageNet accuracy, but it also leaves EfficientNet and ConvNeXt trailing in its wake, being 4.9x and 1.9x faster respectively. Additionally, when pitted against MobileOne at a similar latency, FastViT emerges triumphant with a 4.2% superior Top-1 accuracy. Across a spectrum of tasks, from image classification and detection to segmentation and 3D mesh regression, FastViT consistently outshines its competitors, showcasing both remarkable speed and robustness against out-of-distribution samples and corruptions.
Paper link: https://huggingface.co/papers/2303.14189
Code link: https://github.com/apple/ml-fastvit
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-fastvit
#deeplearning #cv
{kind=link}
👍7🔥4❤1👏1
LISA: Reasoning Segmentation via Large Language Model
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
{kind=link}
🔥11👍7
OBELISC: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
The OBELICS dataset is a game-changer in the world of machine learning and AI! Unlike existing closed-source datasets, OBELICS is a vast, open-source, web-scale dataset specially curated for training large multimodal models. Boasting 141 million web pages from Common Crawl, 353 million high-quality images, and an impressive 115 billion text tokens, OBELICS sets a new standard in the richness and diversity of training data.
But it's not just about the numbers; it's about results. To prove its mettle, models with 9 and 80 billion parameters were trained on OBELICS, showcasing competitive performance across various multimodal benchmarks. Named IDEFICS, these models outperformed or matched their closed-source counterparts, proving that OBELICS isn't just a theoretical concept—it's a practical, high-impact alternative.
Paper link: https://huggingface.co/papers/2306.16527
Model card link: https://huggingface.co/HuggingFaceM4/idefics-80b-instruct
Blogpost link: https://huggingface.co/blog/idefics
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-obelisc
#deeplearning #cv #nlp #largelanguagemodel #opensource
The OBELICS dataset is a game-changer in the world of machine learning and AI! Unlike existing closed-source datasets, OBELICS is a vast, open-source, web-scale dataset specially curated for training large multimodal models. Boasting 141 million web pages from Common Crawl, 353 million high-quality images, and an impressive 115 billion text tokens, OBELICS sets a new standard in the richness and diversity of training data.
But it's not just about the numbers; it's about results. To prove its mettle, models with 9 and 80 billion parameters were trained on OBELICS, showcasing competitive performance across various multimodal benchmarks. Named IDEFICS, these models outperformed or matched their closed-source counterparts, proving that OBELICS isn't just a theoretical concept—it's a practical, high-impact alternative.
Paper link: https://huggingface.co/papers/2306.16527
Model card link: https://huggingface.co/HuggingFaceM4/idefics-80b-instruct
Blogpost link: https://huggingface.co/blog/idefics
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-obelisc
#deeplearning #cv #nlp #largelanguagemodel #opensource
{kind=link}
👍8🔥3❤2🥰1
Giraffe: Adventures in Expanding Context Lengths in LLMs
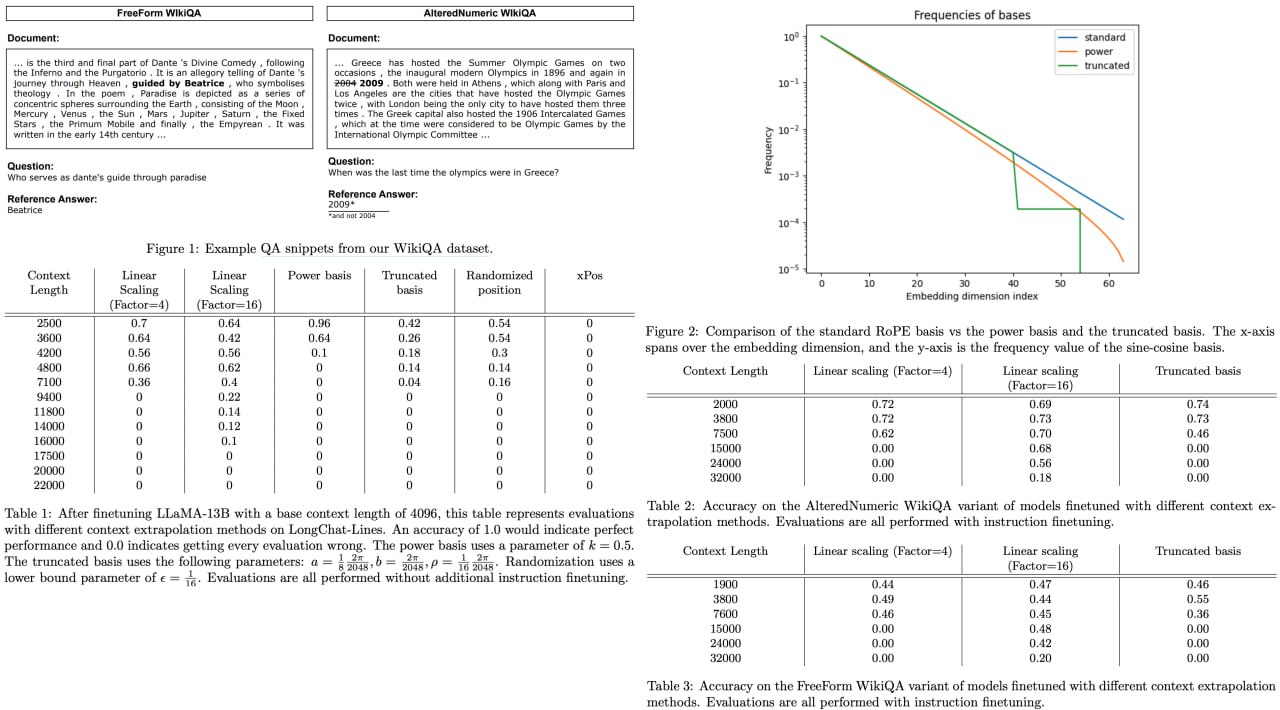
Modern Large Language Models (LLMs) have revolutionized our ability to process and understand vast amounts of textual data. Yet, these models, like LLaMA and LLaMA2, often come with a caveat: they're constrained by fixed context lengths, which means they're limited in handling longer sequences of input data at evaluation. This paper tackles that constraint by investigating a variety of methods for "context length extrapolation," which essentially enables these models to understand and work with longer text sequences. Among the techniques explored, the paper introduces an innovative "truncated basis" strategy for altering positional encodings within the attention mechanism, promising a more scalable future for LLMs.
The researchers put their theories to the test with three brand-new evaluation tasks—FreeFormQA, AlteredNumericQA, and LongChat-Lines—providing a more nuanced measure of model performance than the traditionally used metric of perplexity. Their findings? Linear scaling came out on top as the most effective way to extend the context length, but the truncated basis method showed potential for future exploration. To propel the research community even further, the paper releases three game-changing long-context models, named Giraffe, with context lengths ranging from 4k to an astonishing 32k.
Paper link: https://arxiv.org/abs/2308.10882
Code link: https://github.com/abacusai/Long-Context
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-giraffe
#deeplearning #cv #nlp #largelanguagemodel #opensource #largecontext
Modern Large Language Models (LLMs) have revolutionized our ability to process and understand vast amounts of textual data. Yet, these models, like LLaMA and LLaMA2, often come with a caveat: they're constrained by fixed context lengths, which means they're limited in handling longer sequences of input data at evaluation. This paper tackles that constraint by investigating a variety of methods for "context length extrapolation," which essentially enables these models to understand and work with longer text sequences. Among the techniques explored, the paper introduces an innovative "truncated basis" strategy for altering positional encodings within the attention mechanism, promising a more scalable future for LLMs.
The researchers put their theories to the test with three brand-new evaluation tasks—FreeFormQA, AlteredNumericQA, and LongChat-Lines—providing a more nuanced measure of model performance than the traditionally used metric of perplexity. Their findings? Linear scaling came out on top as the most effective way to extend the context length, but the truncated basis method showed potential for future exploration. To propel the research community even further, the paper releases three game-changing long-context models, named Giraffe, with context lengths ranging from 4k to an astonishing 32k.
Paper link: https://arxiv.org/abs/2308.10882
Code link: https://github.com/abacusai/Long-Context
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-giraffe
#deeplearning #cv #nlp #largelanguagemodel #opensource #largecontext
{kind=link}
👍13❤3🔥3
CoTracker: It is Better to Track Together
The CoTracker paper proposes a groundbreaking approach that takes video motion prediction to the next level. Traditional methods have often been limited, either tracking the motion of all points in a frame collectively using optical flow, or tracking individual points through a video. These approaches tend to overlook the crucial interrelationships between multiple points, especially when they're part of the same physical object. CoTracker flips the script by employing a transformer-based architecture to jointly track multiple points throughout a video, effectively modeling the correlations between different points in time.
What really sets CoTracker apart is its versatility and adaptability. It's engineered to handle extremely long videos through a unique sliding-window mechanism, and iteratively updates estimates for multiple trajectories. The system even allows for the addition of new tracking points on-the-fly, offering unmatched flexibility. CoTracker outshines state-of-the-art methods in nearly all benchmark tests.
Paper link: https://arxiv.org/abs/2307.07635
Code link: https://github.com/facebookresearch/co-tracker
Project link: https://co-tracker.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cotracker
#deeplearning #cv #objecttracking
The CoTracker paper proposes a groundbreaking approach that takes video motion prediction to the next level. Traditional methods have often been limited, either tracking the motion of all points in a frame collectively using optical flow, or tracking individual points through a video. These approaches tend to overlook the crucial interrelationships between multiple points, especially when they're part of the same physical object. CoTracker flips the script by employing a transformer-based architecture to jointly track multiple points throughout a video, effectively modeling the correlations between different points in time.
What really sets CoTracker apart is its versatility and adaptability. It's engineered to handle extremely long videos through a unique sliding-window mechanism, and iteratively updates estimates for multiple trajectories. The system even allows for the addition of new tracking points on-the-fly, offering unmatched flexibility. CoTracker outshines state-of-the-art methods in nearly all benchmark tests.
Paper link: https://arxiv.org/abs/2307.07635
Code link: https://github.com/facebookresearch/co-tracker
Project link: https://co-tracker.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cotracker
#deeplearning #cv #objecttracking
{kind=link}
👍7🔥7❤5😁1
Forwarded from Machinelearning
Команда Fundamental AI Research (FAIR) компании Марка Цукерберга представила серию новых разработок: методики и модели, улучшающие компьютерное зрение, 3D-локализацию объектов и совместное обучение языковых агентов. Все модели, техотчеты, датасеты и код этих проектов уже доступны на платформах Hugging Face и GitHub.
Perception Encoder - новый виток развития в сфере обработки визуальной информации. Модель, обученная с помощью этой методики на масштабных данных, превосходит аналоги в задачах классификации изображений и видео, включая сложные сценарии — распознавание ската, зарывшегося в морское дно, или крошечной птицы на заднем плане снимка. Благодаря интеграции с LLM, Encoder улучшает ответы на визуальные вопросы, описание сцен и понимание пространственных отношений между объектами.
Для задач, требующих анализа видео и текста, Meta выпустила Perception Language Model (PLM). Ее обучали на 2,5 млн. новых аннотированных видеозаписей — это крупнейший датасет для понимания действий и контекста в динамике. PLM доступна в трёх вариантах (1, 3 и 8 млрд параметров). Дополнительный бонус — PLM-VideoBench, бенчмарк для оценки тонкого понимания сцен, который заполняет пробелы существующих тестов.
Как заставить робот найти красную чашку на столе или вазу возле телевизора? Locate 3D решает эту задачу через анализ 3D-точечных облаков и текстовых подсказок. Модель учитывает пространственные связи и контекст, отличая «вазу у TV» от «вазы на столе». В основе — трехэтапный пайплайн: предобработка данных, кодирование 3D-сцены и декодирование запроса. Для обучения использовали 130 тыс. аннотаций из ARKitScenes и ScanNet, что вдвое увеличило объём доступных данных для локализации объектов.
Dynamic Byte Latent Transformer - архитектура, которая работает на уровне байтов, а не токенов, что повышает устойчивость к ошибкам, ускоряет обработку и "отменяет" необходимость токенизации для масштабирования. На тесте CUTE модель показывает преимущество в +55 пунктов против традиционных подходов.
Совместное решение задач — следующий этап развития ИИ. Collaborative Reasoner — это фреймворк, где два агента ведут диалог, чтобы прийти к общему решению. Они могут спорить, аргументировать и согласовывать ответы на сложные вопросы. Для обучения используют синтетические диалоги, которые генерирует сама модель. Результаты впечатляют: на некоторых задачах совместная работа даёт прирост эффективности до 29% по сравнению с одиночным агентом.
@ai_machinelearning_big_data
#AI #ML #LLM #CV #NLP #FAIR
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
❤6👍4🔥2