
NeuralCam Live release on the #ProductHunt
App turns iPhone into the better camera for Zoom calls with auto bluring in case of unwanted gestures.
It was clear that global pandemic and pressure on the remote culture will be foundation for new ideas and solutions, such as this.
There is nothing groundbraking about technology, but execution and market is what matters. Apple or Google might even buy this startup instead of simply copying the features and making default cameras more smart.
ProductHunt: https://www.producthunt.com/posts/neuralcam-live
#aiproduct #dataproduct #camera #aicamera #cv #DL
App turns iPhone into the better camera for Zoom calls with auto bluring in case of unwanted gestures.
It was clear that global pandemic and pressure on the remote culture will be foundation for new ideas and solutions, such as this.
There is nothing groundbraking about technology, but execution and market is what matters. Apple or Google might even buy this startup instead of simply copying the features and making default cameras more smart.
ProductHunt: https://www.producthunt.com/posts/neuralcam-live
#aiproduct #dataproduct #camera #aicamera #cv #DL
Dont hesitate to click «Comment» button and share your ideas or links to other pandemic solutions
Anonymous Poll
49%
Will share
51%
Not today
Forwarded from Recent AI News
Google AI Blog: On-device Supermarket Product Recognition http://feedproxy.google.com/~r/blogspot/gJZg/~3/uEq7NDB-AgY/on-device-supermarket-product.html
📝 Post "Google AI Blog: On-device Supermarket Product…" published, discuss!
nlp newsletter 14: nlp beyond english, big bird, monitoring ml models, breaking into nlp, arxiv dataset,…
by elvis saravia @dair.ai
in our point of view in this newsletter showcase the next interesting links
* demos and applications gpt3
* monitoring ml models
* Big Bird: Transformers for Longer Sequences by reducing the complexity of the attention mechanism to linear complexity in the number of tokens
* competition contradictory, my dear watson: detecting contradiction and entailment in multilingual text using tpus
* competition hate speech and offensive content identification in indo-european languages
* why u should do nlp beyond :en: by sebastian ruder
* covost v2: expanding the largest, most diverse multilingual speech-to-text translation data set
* panel discussion about the future of conversational ai systems
* …
blog post: https://dair.ai/NLP_Newsletter_14-en/
#nlp #news
by elvis saravia @dair.ai
in our point of view in this newsletter showcase the next interesting links
* demos and applications gpt3
* monitoring ml models
* Big Bird: Transformers for Longer Sequences by reducing the complexity of the attention mechanism to linear complexity in the number of tokens
* competition contradictory, my dear watson: detecting contradiction and entailment in multilingual text using tpus
* competition hate speech and offensive content identification in indo-european languages
* why u should do nlp beyond :en: by sebastian ruder
* covost v2: expanding the largest, most diverse multilingual speech-to-text translation data set
* panel discussion about the future of conversational ai systems
* …
blog post: https://dair.ai/NLP_Newsletter_14-en/
#nlp #news
REALM: Integrating Retrieval into Language Representation Models
by google research
A new paper from google with a novel approach for language model pre-training, which augments a language representation model with a knowledge retriever.
The idea is the following: we take a sentence or a piece of text and augment it with additional knowledge (pass original text and additional texts to the model).
An example:
The masked text is:
Knowledge retriever could add the following information to it:
blog post: https://ai.googleblog.com/2020/08/realm-integrating-retrieval-into.html
paper: https://arxiv.org/abs/2002.08909
github: https://github.com/google-research/language/tree/master/language/realm
#nlp #languagemodel #knowledgeretriever #icml2020
by google research
A new paper from google with a novel approach for language model pre-training, which augments a language representation model with a knowledge retriever.
The idea is the following: we take a sentence or a piece of text and augment it with additional knowledge (pass original text and additional texts to the model).
An example:
The masked text is:
We paid twenty __ at the Buckingham Palace gift shop.
Knowledge retriever could add the following information to it:
Buckingham Palace is the London residence of the British monarchy.The official currency of the United Kingdom is the Pound.blog post: https://ai.googleblog.com/2020/08/realm-integrating-retrieval-into.html
paper: https://arxiv.org/abs/2002.08909
github: https://github.com/google-research/language/tree/master/language/realm
#nlp #languagemodel #knowledgeretriever #icml2020
{kind=link}
Forwarded from Находки в опенсорсе
A utility tool powered by fzf for using git interactively.
This tool is designed to help you use git more efficiently. It's lightweight and easy to use.
Also integrates with: diff-so-fancy, delta, bat, emoji-cli.
https://github.com/wfxr/forgit
#shell #git
This tool is designed to help you use git more efficiently. It's lightweight and easy to use.
Also integrates with: diff-so-fancy, delta, bat, emoji-cli.
https://github.com/wfxr/forgit
#shell #git
{kind=link}
Forwarded from Graph Machine Learning
The Quantum Graph Recurrent Neural Network
This demonstration by pennylane investigates quantum graph recurrent neural networks (QGRNN), which are the quantum analogue of a classical graph recurrent neural network, and a subclass of the more general quantum graph neural network ansatz. Both the QGNN and QGRNN were introduced in this paper (2019) by Google X.
This demonstration by pennylane investigates quantum graph recurrent neural networks (QGRNN), which are the quantum analogue of a classical graph recurrent neural network, and a subclass of the more general quantum graph neural network ansatz. Both the QGNN and QGRNN were introduced in this paper (2019) by Google X.
Clothing Dataset: Call for Action
Help to collect a public-domain dataset with images of clothes
Medium post: https://medium.com/data-science-insider/clothing-dataset-call-for-action-3cad023246c1
#dataset #clothing #cv #calltoarms
Help to collect a public-domain dataset with images of clothes
Medium post: https://medium.com/data-science-insider/clothing-dataset-call-for-action-3cad023246c1
#dataset #clothing #cv #calltoarms
{kind=link}
GANs used to create photorealistic images of Roman Emperors
Project post: https://voshart.com/ROMAN-EMPEROR-PROJECT
Medium: https://medium.com/@voshart/photoreal-roman-emperor-project-236be7f06c8f
#GAN #Art #history #DL
Project post: https://voshart.com/ROMAN-EMPEROR-PROJECT
Medium: https://medium.com/@voshart/photoreal-roman-emperor-project-236be7f06c8f
#GAN #Art #history #DL
{kind=link}
mingpt – a minimal pytorch re-implementation of the openai generative pretrained transformer training
by karpathy
small, clean, interpretable and educational, as most of the currently available ones are a bit sprawling. this implementation is appropriately about 300 lines of code, including boilerplate and a totally unnecessary custom causal self-attention module. all that's going on is that a sequence of indices goes into a sequence of transformer blocks, and a probability distribution of the next index comes out.
with a bpe encoder, distributed training and maybe fp16 this implementation may be able to reproduce gpt-1/gpt-2 results, though they haven't tried $$$. gpt-3 is likely out of reach as his understanding is that it does not fit into gpu memory and requires a more careful model-parallel treatment.
https://twitter.com/karpathy/status/1295410274095095810?s=20
#nlp #karpathy #gpt #torch
by karpathy
small, clean, interpretable and educational, as most of the currently available ones are a bit sprawling. this implementation is appropriately about 300 lines of code, including boilerplate and a totally unnecessary custom causal self-attention module. all that's going on is that a sequence of indices goes into a sequence of transformer blocks, and a probability distribution of the next index comes out.
with a bpe encoder, distributed training and maybe fp16 this implementation may be able to reproduce gpt-1/gpt-2 results, though they haven't tried $$$. gpt-3 is likely out of reach as his understanding is that it does not fit into gpu memory and requires a more careful model-parallel treatment.
https://twitter.com/karpathy/status/1295410274095095810?s=20
#nlp #karpathy #gpt #torch
Twitter
Andrej Karpathy
I wrote a minimal/educational GPT training library in PyTorch, am calling it minGPT as it is only around ~300 lines of code: https://t.co/79S9lShJRN +demos for addition and character-level language model. (quick weekend project, may contain sharp edges)
Language-agnostic BERT Sentence Embedding
Authors adopt multilingual BERT to produce language-agnostic sentence embeddings for 109 languages.
The model combines a masked language model (MLM) and a translation language model (TLM) pretraining with a translation ranking task using bi-directional dual encoders.
The resulting multilingual sentence embeddings improve average bi-text retrieval accuracy over 112 languages to 83.7% on Tatoeba (previous state-of-the-art was 65.5%)
blogpost: https://ai.googleblog.com/2020/08/language-agnostic-bert-sentence.html
paper: https://arxiv.org/abs/2007.01852
bodel on tf hub: https://tfhub.dev/google/LaBSE/1
#deeplearning #transformers #nlp #tensorflow #sentenceembeddings
Authors adopt multilingual BERT to produce language-agnostic sentence embeddings for 109 languages.
The model combines a masked language model (MLM) and a translation language model (TLM) pretraining with a translation ranking task using bi-directional dual encoders.
The resulting multilingual sentence embeddings improve average bi-text retrieval accuracy over 112 languages to 83.7% on Tatoeba (previous state-of-the-art was 65.5%)
blogpost: https://ai.googleblog.com/2020/08/language-agnostic-bert-sentence.html
paper: https://arxiv.org/abs/2007.01852
bodel on tf hub: https://tfhub.dev/google/LaBSE/1
#deeplearning #transformers #nlp #tensorflow #sentenceembeddings
{kind=link}
Philosopher AI — website to generate text with #GPT3
Tool to generate text on different topics. Sensible topics such as sex, religion or even nationality are blocked.
Great way to spread the awareness on #ai and to show nontechnical friends that #Skynet is not a problem to be concerned with yet.
Website: https://philosopherai.com/philosopher/humanity-on-mars-73ac00
#nlu #nlp
Tool to generate text on different topics. Sensible topics such as sex, religion or even nationality are blocked.
Great way to spread the awareness on #ai and to show nontechnical friends that #Skynet is not a problem to be concerned with yet.
Website: https://philosopherai.com/philosopher/humanity-on-mars-73ac00
#nlu #nlp
{kind=link}
Forwarded from Находки в опенсорсе
A terminal-based presentation tool with colors and effects.
Present your stuff without leaving your terminal!
Personal opinion: this might be a really cool thing for live-coding sessions for people using vim/emacs. The context switch would be minimal.
https://github.com/vinayak-mehta/present
#python
Present your stuff without leaving your terminal!
Personal opinion: this might be a really cool thing for live-coding sessions for people using vim/emacs. The context switch would be minimal.
https://github.com/vinayak-mehta/present
#python
Most of the Scots NLP models used Wikipedia for training are wrong
One person who had done 200,000 edits and written 20,000 articles of Scots Wikipedia was not using Scots language but rather faking it. Since Wikipedia texts are often used as a dataset for #NLU / #NLP / #NMT neural nets training, those models using it as an input had a flaw.
Reddit thread: https://www.reddit.com/r/Scotland/comments/ig9jia/ive_discovered_that_almost_every_single_article/
#datasets #translation #scots #wikipedia
One person who had done 200,000 edits and written 20,000 articles of Scots Wikipedia was not using Scots language but rather faking it. Since Wikipedia texts are often used as a dataset for #NLU / #NLP / #NMT neural nets training, those models using it as an input had a flaw.
Reddit thread: https://www.reddit.com/r/Scotland/comments/ig9jia/ive_discovered_that_almost_every_single_article/
#datasets #translation #scots #wikipedia
Reddit
From the Scotland community on Reddit: I’ve discovered that almost every single article on the Scots version of Wikipedia is written…
Explore this post and more from the Scotland community
Forwarded from PDP-11🚀
The latest paper by David Patterson & Google TPU team reveals details of the world most efficient and one of the most powerful supercomputers for DNN Acceleration - TPU v3. The one which was used to train BERT.
We recommend that you definitely read the full text, but here are insights and tldr highlights
Key Insight:
The co-design of an ML-specific programming system (TensorFlow), compiler (XLA), architecture (TPU), floating-point arithmetic (Brain float16), interconnect (ICI), and chip (TPUv2/v3) let production ML applications scale at 96%–99% of perfect linear speedup and 10x gains in performance/ Watt over the most efficient general-purpose supercomputers.
More highlights:
🐣🐤🐔 Three generations
There are 3 generations of TPU now released, TPU v1 used fixpoint arithmetic and was used for inference only. TPU v2 and v3 operate in floating-point and used for training. TPU v4 results were presented in MLPerf summer release, but there is no public information available. The TPU architecture differs from CPU with
▪️ Two Dimensional array processing units (instead of 1D vector SIMDs in CPU)
▪️Narrower data (8-16 bits)
▪️ Drop complex CPU features - caches and branch prediction
🐮🤜🐤 Fewer cores per chip (two oxen vs 1024 chickens)
NVidia put thousands of CUDA cores inside their chip. TPU v3 has only 2 TensorCores per chip. It's way easier to generate a program for 2 beefier cores than to swarm of wimpier cores.
Each TensorCore includes the following units:-
▪️
▪️
▪️
▪️
▪️
🐱🐶❓ From inference to training chip
Key challenges on the way from inference chip V1 to training hardware V2
▪️ Harder parallelization
▪️ More computation
▪️ More memory
▪️ More programmability
▪️ Wider dynamic range of data
✂️🧮✂️ Brain Float
The compromised
🍩🧬⚡️ Torus topology and ICI
TPU v1 was an accelerator card for CPU 'based computer. TPUv2 and v3 are building blocks of the supercomputer. Chips connected with ICI interface, each running at ~500Gbits/s. ICU enables direct connection between chips, so no need of any extra interfaces. GPU/CPU based supercomputers have to apply NVLink and PCI-E inside computer chase and InfiniBand network and switches to connect them.
Chips in TPUv2 and v3 clusters are connected in 2D Torus topology (doughnut ) and achieve an unbelievable linear scale of performance growth with increasing of chips number.
🛠⚙️🖥 XLA compiler (to orchestrate them all)
TF programs are graphs of operations, where tensor-arrays are first-class citizens. XLA compiler front-end transforms the TF graph into an intermediate representation, which is then efficiently mapped into selected TPU (or CPU/GPU) architectures. XLA maps TF graph parallelism across hundreds of chips, TensorCores per chip, multiple units per core. XLA provides precise reasoning about memory use at every point in the program.
Young XLA compiler has more opportunities to improve than a more mature CUDA stack.
🌲🐰🦊 Green Power (Forest animals approves)
TPU v3 supercomputer already climbed on the 4th row of TOP500 ranking, but what is remarkable - it demonstrates an overwhelming 146.3 GFLops/Watt performance. The nearest competitor has 10 times and lower number.
Original Paper
A Domain Specific Computer for training DNN
We recommend that you definitely read the full text, but here are insights and tldr highlights
Key Insight:
The co-design of an ML-specific programming system (TensorFlow), compiler (XLA), architecture (TPU), floating-point arithmetic (Brain float16), interconnect (ICI), and chip (TPUv2/v3) let production ML applications scale at 96%–99% of perfect linear speedup and 10x gains in performance/ Watt over the most efficient general-purpose supercomputers.
More highlights:
🐣🐤🐔 Three generations
There are 3 generations of TPU now released, TPU v1 used fixpoint arithmetic and was used for inference only. TPU v2 and v3 operate in floating-point and used for training. TPU v4 results were presented in MLPerf summer release, but there is no public information available. The TPU architecture differs from CPU with
▪️ Two Dimensional array processing units (instead of 1D vector SIMDs in CPU)
▪️Narrower data (8-16 bits)
▪️ Drop complex CPU features - caches and branch prediction
🐮🤜🐤 Fewer cores per chip (two oxen vs 1024 chickens)
NVidia put thousands of CUDA cores inside their chip. TPU v3 has only 2 TensorCores per chip. It's way easier to generate a program for 2 beefier cores than to swarm of wimpier cores.
Each TensorCore includes the following units:-
▪️
ICI(Inter Core Interconnects) - connect core across different chips- ▪️
HBM, stacked DRAM on the same interposes substrate- ▪️
Core Sequencer - manages instructions and performs scalar operations- ▪️
Vector Processing Unit, performs vectors operation for 1D and 2D vectors- ▪️
Matrix Multiply Unit (MXU) 🐱🐶❓ From inference to training chip
Key challenges on the way from inference chip V1 to training hardware V2
▪️ Harder parallelization
▪️ More computation
▪️ More memory
▪️ More programmability
▪️ Wider dynamic range of data
✂️🧮✂️ Brain Float
IEEE FP16 and FP32 use (1+8+23) and (1+5+7) bits for the sign, exponent, and mantissa values respectively. In practice, DNN doesn't need mantissa precision of FP32, but the dynamic range of FP16 is not enough. Using of FP16 also requires loss scaling.The compromised
bf16 keeps the same 8 bits for exponent, as FP32, but reduced mantissa - only 7 bits instead of 23. BF16 delivers reducing space usage and power consumption with no loss scaling in software required. 🍩🧬⚡️ Torus topology and ICI
TPU v1 was an accelerator card for CPU 'based computer. TPUv2 and v3 are building blocks of the supercomputer. Chips connected with ICI interface, each running at ~500Gbits/s. ICU enables direct connection between chips, so no need of any extra interfaces. GPU/CPU based supercomputers have to apply NVLink and PCI-E inside computer chase and InfiniBand network and switches to connect them.
Chips in TPUv2 and v3 clusters are connected in 2D Torus topology (doughnut ) and achieve an unbelievable linear scale of performance growth with increasing of chips number.
🛠⚙️🖥 XLA compiler (to orchestrate them all)
TF programs are graphs of operations, where tensor-arrays are first-class citizens. XLA compiler front-end transforms the TF graph into an intermediate representation, which is then efficiently mapped into selected TPU (or CPU/GPU) architectures. XLA maps TF graph parallelism across hundreds of chips, TensorCores per chip, multiple units per core. XLA provides precise reasoning about memory use at every point in the program.
Young XLA compiler has more opportunities to improve than a more mature CUDA stack.
🌲🐰🦊 Green Power (Forest animals approves)
TPU v3 supercomputer already climbed on the 4th row of TOP500 ranking, but what is remarkable - it demonstrates an overwhelming 146.3 GFLops/Watt performance. The nearest competitor has 10 times and lower number.
Original Paper
A Domain Specific Computer for training DNN
Open Data Science Online Event Announce & Call for speakers!
Data Fest 2020 - Online & Global, September 19-20
Data Fest is global free conference series where we unite all researchers, engineers, and developers around Data Science and related areas. Most of the tracks (sections) will be in English, some of them in Russian.
It was tricky to promise an increase in geography in 2020, but we’ve managed. We've completely reimagined what an online conference can be and invite you to try:
• Youtube Livestream on September 19-20 from 11:00 to 19:00 Moscow time.
• Networking in spatial.chat - the closest you can get to an online festival with a great number of rooms with topics of interest.
• All materials will be hosted on the ODS.ai platform in our new format - online tracks.
All materials will be open, however, to participate in networking you will have to register with your profile on ODS.AI website: https://datafest.ru/2020/ (English version coming soon on Thursday)
After the Data Fest is over, all the valuable information and insights gathered in the preparation and the event will be published on the ODS.ai platform as tracks:
• The tracks are united by topics - there are ML, Graph ML, Big Data, from pet-project to startup, Career, and many more. We already have 35+ announced tracks, and the list is not yet final - everyone should find something of their interest.
• Data Fest is literally the premier event, and some tracks’ organisers will host their regular events in the weeks following the Fest. So stay tuned.
• Some tracks will be in English - remember we told that ODS.AI goes global?
If you want to become a part of a great story that is about to begin, the call for speakers is publicly open!
To become a part of the program just write to the track organizers directly, you can find a list of them on the website.
Or if you feel shy, you can simply submit your talks ideas via this form: https://forms.gle/8qPMu2pndHZcNxvL9
If you are willing to give a talk on «DS without ML» topic: from Excel Data Science to any Heuristics and cases of applying Algorithms for solving business tasks, reach out directly to @malev.
Stay safe, stay sane, and see you on Data Fest Online! 🎉
https://datafest.ru/2020/
You can ask you questions in the comments below ⬇️
Data Fest 2020 - Online & Global, September 19-20
Data Fest is global free conference series where we unite all researchers, engineers, and developers around Data Science and related areas. Most of the tracks (sections) will be in English, some of them in Russian.
It was tricky to promise an increase in geography in 2020, but we’ve managed. We've completely reimagined what an online conference can be and invite you to try:
• Youtube Livestream on September 19-20 from 11:00 to 19:00 Moscow time.
• Networking in spatial.chat - the closest you can get to an online festival with a great number of rooms with topics of interest.
• All materials will be hosted on the ODS.ai platform in our new format - online tracks.
All materials will be open, however, to participate in networking you will have to register with your profile on ODS.AI website: https://datafest.ru/2020/ (English version coming soon on Thursday)
After the Data Fest is over, all the valuable information and insights gathered in the preparation and the event will be published on the ODS.ai platform as tracks:
• The tracks are united by topics - there are ML, Graph ML, Big Data, from pet-project to startup, Career, and many more. We already have 35+ announced tracks, and the list is not yet final - everyone should find something of their interest.
• Data Fest is literally the premier event, and some tracks’ organisers will host their regular events in the weeks following the Fest. So stay tuned.
• Some tracks will be in English - remember we told that ODS.AI goes global?
If you want to become a part of a great story that is about to begin, the call for speakers is publicly open!
To become a part of the program just write to the track organizers directly, you can find a list of them on the website.
Or if you feel shy, you can simply submit your talks ideas via this form: https://forms.gle/8qPMu2pndHZcNxvL9
If you are willing to give a talk on «DS without ML» topic: from Excel Data Science to any Heuristics and cases of applying Algorithms for solving business tasks, reach out directly to @malev.
Stay safe, stay sane, and see you on Data Fest Online! 🎉
https://datafest.ru/2020/
You can ask you questions in the comments below ⬇️
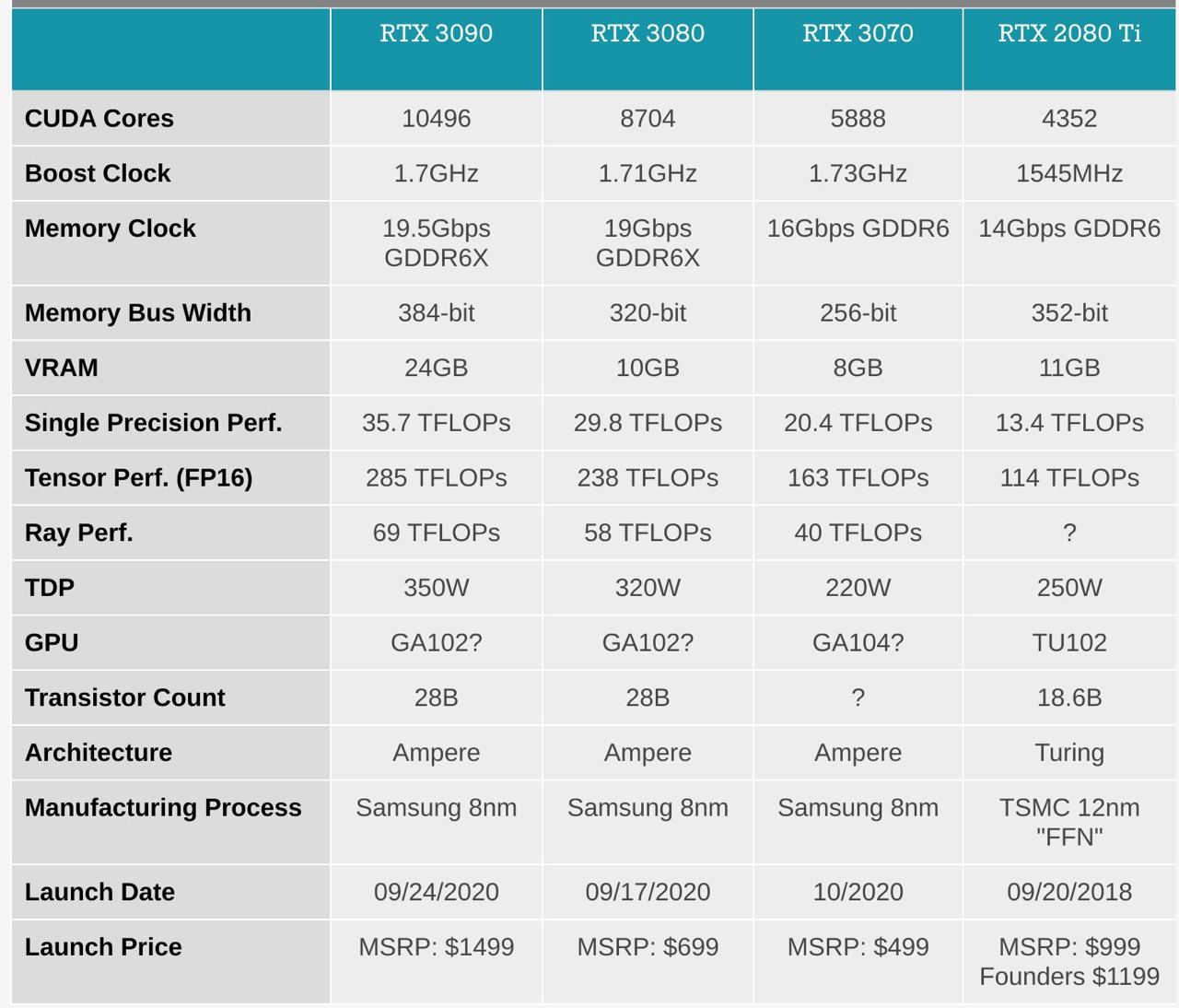
Nvidia announced new card RTX 3090
RTX 3090 is roughly 2 times more powerful than 2080.
There is probably no point in getting 3080 because RAM volume is only 10G.
But what really matters, is how it was presented. Purely technological product for mostly proffesionals, techheads and gamers was presented with absolute brialliancy. That is much more exciting then the release itself.
YouTube: https://www.youtube.com/watch?v=E98hC9e__Xs
#Nvidia #GPU #techstack
RTX 3090 is roughly 2 times more powerful than 2080.
There is probably no point in getting 3080 because RAM volume is only 10G.
But what really matters, is how it was presented. Purely technological product for mostly proffesionals, techheads and gamers was presented with absolute brialliancy. That is much more exciting then the release itself.
YouTube: https://www.youtube.com/watch?v=E98hC9e__Xs
#Nvidia #GPU #techstack
{kind=link}
Lo-Fi Player
The team from the magenta project, that does research about deep learning and music powered by TensorFlow in Google, obviously, release a new fun project lofi-player powered by their open-source library magenta.js.
So it's basically a lo-fi music generator which popular genre on youtube streams and other kinds of stuff. You can customize the vibe on your manner and wish from sad to moody, slow to fast, etc.
It is based on their earlier work MusicVae to sample latent space of music and MelodyRNN to generate music sequences from different instruments. The project is not about new research, but to show what can do with an already done library in a creative way.
They also create a stream on youtube to listen lo-fi generated by that application and users in chat can together tune lo-fi player in stream :)
#magenta #lo-fi #music #google #tensorflow #fun
The team from the magenta project, that does research about deep learning and music powered by TensorFlow in Google, obviously, release a new fun project lofi-player powered by their open-source library magenta.js.
So it's basically a lo-fi music generator which popular genre on youtube streams and other kinds of stuff. You can customize the vibe on your manner and wish from sad to moody, slow to fast, etc.
It is based on their earlier work MusicVae to sample latent space of music and MelodyRNN to generate music sequences from different instruments. The project is not about new research, but to show what can do with an already done library in a creative way.
They also create a stream on youtube to listen lo-fi generated by that application and users in chat can together tune lo-fi player in stream :)
#magenta #lo-fi #music #google #tensorflow #fun
Lo-Fi Player
Interactive lofi beat player.