
This media is not supported in your browser
VIEW IN TELEGRAM
Nvidia AI Noise Reduction
#Nvidia launches #KrispAI competitor Noise Reduction by AI on RTX Videocards.
Seems it works significantly better then other that kind of tools. But it needs to have Nvidia RTX officially.
But it possible to run it on older cards. The instruction is below. Or you can just download already hacked executable (also, below)
Setup Guide: https://www.nvidia.com/en-us/geforce/guides/nvidia-rtx-voice-setup-guide/
The instruction: https://forums.guru3d.com/threads/nvidia-rtx-voice-works-without-rtx-gpu-heres-how.431781/
Executable (use it on your own risk): https://mega.nz/file/CJ0xDYTB#LPorY_aPVqVKfHqWVV7zxK8fNfRmxt6iw6KdkHodz1M
#noisereduction #soundlearning #dl #noise #sound #speech #nvidia
#Nvidia launches #KrispAI competitor Noise Reduction by AI on RTX Videocards.
Seems it works significantly better then other that kind of tools. But it needs to have Nvidia RTX officially.
But it possible to run it on older cards. The instruction is below. Or you can just download already hacked executable (also, below)
Setup Guide: https://www.nvidia.com/en-us/geforce/guides/nvidia-rtx-voice-setup-guide/
The instruction: https://forums.guru3d.com/threads/nvidia-rtx-voice-works-without-rtx-gpu-heres-how.431781/
Executable (use it on your own risk): https://mega.nz/file/CJ0xDYTB#LPorY_aPVqVKfHqWVV7zxK8fNfRmxt6iw6KdkHodz1M
#noisereduction #soundlearning #dl #noise #sound #speech #nvidia
Training with quantization noise for extreme model compression
It is a new technique to enable extreme compression of models that still deliver high performance when deployed in practical applications mimics the effect of quantization during training time.
This method delivers performance that nearly matches that of the original uncompressed models while reducing the memory footprint by 10x to 20x. This significantly exceeds the 4x compression with int8 currently available in both PyTorch and Tensorflow. Quant-Noise can be used to shrink models even further – by more than 50x – in use cases where greater performance trade-offs are acceptable. Quant-Noise changes model training only by adding a regularization noise similar to dropout, with no impact on either the convergence rate or training speed.
At training time during the forward pass, it takes a subset of the weights and then randomly applies simulated quantization noise. This makes the model resilient to quantization and enables large compression ratios without much loss in accuracy.
Quant-Noise is applied to only a subset of the weights. This method has the advantage that the unbiased gradients still flow from the weights that are unaffected by the noise.
The authors demonstrated that their framework compresses the SOTA EfficientNet-B3 model from ~50 MB to 3.3 MB while achieving 80% top-1 accuracy on ImageNet, compared with 81.7% for the uncompressed model. Compress RoBERTa Base model from 480 MB to 14 MB while achieving 82.5% on MNLI, compared with 84.8% for the original model.
blogpost: https://ai.facebook.com/blog/training-with-quantization-noise-for-extreme-model-compression/
paper: https://arxiv.org/abs/2004.07320
github: https://github.com/pytorch/fairseq/tree/master/examples/quant_noise
#quantization #compression #shrinking
It is a new technique to enable extreme compression of models that still deliver high performance when deployed in practical applications mimics the effect of quantization during training time.
This method delivers performance that nearly matches that of the original uncompressed models while reducing the memory footprint by 10x to 20x. This significantly exceeds the 4x compression with int8 currently available in both PyTorch and Tensorflow. Quant-Noise can be used to shrink models even further – by more than 50x – in use cases where greater performance trade-offs are acceptable. Quant-Noise changes model training only by adding a regularization noise similar to dropout, with no impact on either the convergence rate or training speed.
At training time during the forward pass, it takes a subset of the weights and then randomly applies simulated quantization noise. This makes the model resilient to quantization and enables large compression ratios without much loss in accuracy.
Quant-Noise is applied to only a subset of the weights. This method has the advantage that the unbiased gradients still flow from the weights that are unaffected by the noise.
The authors demonstrated that their framework compresses the SOTA EfficientNet-B3 model from ~50 MB to 3.3 MB while achieving 80% top-1 accuracy on ImageNet, compared with 81.7% for the uncompressed model. Compress RoBERTa Base model from 480 MB to 14 MB while achieving 82.5% on MNLI, compared with 84.8% for the original model.
blogpost: https://ai.facebook.com/blog/training-with-quantization-noise-for-extreme-model-compression/
paper: https://arxiv.org/abs/2004.07320
github: https://github.com/pytorch/fairseq/tree/master/examples/quant_noise
#quantization #compression #shrinking
{kind=link}
StarGAN v2 code release on GitHub
The better news is if you put a human into the animal model you do in fact get out a feline version of the human, and it's even wearing a suit.
GitHub: https://github.com/clovaai/stargan-v2
ArXiV: https://arxiv.org/abs/1912.01865
YouTube: https://www.youtube.com/watch?v=0EVh5Ki4dIY&feature=youtu.be
#GAN #StarGAN #PyTorch
The better news is if you put a human into the animal model you do in fact get out a feline version of the human, and it's even wearing a suit.
GitHub: https://github.com/clovaai/stargan-v2
ArXiV: https://arxiv.org/abs/1912.01865
YouTube: https://www.youtube.com/watch?v=0EVh5Ki4dIY&feature=youtu.be
#GAN #StarGAN #PyTorch
{kind=link}
👍1
Two more samples for dog-lovers. And it also seems that dog-transition works better.
The Ingredients of Real World Robotic Reinforcement Learning
Blog post describing experiments on applying #RL in real world.
Blog post: https://bair.berkeley.edu/blog/2020/04/27/ingredients/
Paper: https://openreview.net/forum?id=rJe2syrtvS
#DL #robotics
Blog post describing experiments on applying #RL in real world.
Blog post: https://bair.berkeley.edu/blog/2020/04/27/ingredients/
Paper: https://openreview.net/forum?id=rJe2syrtvS
#DL #robotics
ICASSP 2020 – FREE
45th International Conference on Acoustics, Speech, and Signal Processing
Registration includes full access to the virtual conference and all sessions, virtual patron and exhibitor experiences, as well as the conference app and any live and asynchronous discussion forums, and an electronic download of the conference proceedings.
link: https://cmsworkshops.com/ICASSP2020/Registration.asp
#icassp #conference
45th International Conference on Acoustics, Speech, and Signal Processing
Registration includes full access to the virtual conference and all sessions, virtual patron and exhibitor experiences, as well as the conference app and any live and asynchronous discussion forums, and an electronic download of the conference proceedings.
link: https://cmsworkshops.com/ICASSP2020/Registration.asp
#icassp #conference
{kind=link}
Scheduled DropHead: A Regularization Method for Transformer Models
In this paper introduced DropHead, a structured dropout method specifically designed for regularizing the multi-head attention mechanism, which is a key component of the transformer, a SOTA model for various NLP tasks.
In contrast to the conventional dropout mechanisms which randomly drop units or connections, the proposed DropHead is a structured dropout method. It drops entire attention heads during training and It prevents the multi-head attention model from being dominated by a small portion of attention heads while also reduces the risk of overfitting the training data, thus making use of the multi-head attention mechanism more efficiently.
paper: https://arxiv.org/abs/2004.13342
#nlp #regularization #transformer
In this paper introduced DropHead, a structured dropout method specifically designed for regularizing the multi-head attention mechanism, which is a key component of the transformer, a SOTA model for various NLP tasks.
In contrast to the conventional dropout mechanisms which randomly drop units or connections, the proposed DropHead is a structured dropout method. It drops entire attention heads during training and It prevents the multi-head attention model from being dominated by a small portion of attention heads while also reduces the risk of overfitting the training data, thus making use of the multi-head attention mechanism more efficiently.
paper: https://arxiv.org/abs/2004.13342
#nlp #regularization #transformer
{kind=link}
🎙🎶Improved audio generative model from OpenAI
Wow! OpenAI just released Jukebox – neural net and service that generates music from genre, artist name, and some lyrics that you can supply. It is can generate even some singing like from corrupted magnet compact cassette.
Some of the sounds seem it is from hell. Agonizing Michel Jakson for example or Creepy Eminiem or Celien Dion
#OpenAI 's approach is to use 3 levels of quantized variational autoencoders VQVAE-2 to learn discrete representations of audio and compress audio by 8x, 32x, and 128x and use the spectral loss to reconstruct spectrograms. And after that, they use sparse transformers conditioned on lyrics to generate new patterns and upsample it to higher discrete samples and decode it to the song.
The net can even learn and generates some solo parts during the track.
explore some creepy songs: https://jukebox.openai.com/
code: https://github.com/openai/jukebox/
paper: https://cdn.openai.com/papers/jukebox.pdf
blog: https://openai.com/blog/jukebox/
#openAI #music #sound #cool #fan #creepy #vae #audiolearning #soundlearning
Wow! OpenAI just released Jukebox – neural net and service that generates music from genre, artist name, and some lyrics that you can supply. It is can generate even some singing like from corrupted magnet compact cassette.
Some of the sounds seem it is from hell. Agonizing Michel Jakson for example or Creepy Eminiem or Celien Dion
#OpenAI 's approach is to use 3 levels of quantized variational autoencoders VQVAE-2 to learn discrete representations of audio and compress audio by 8x, 32x, and 128x and use the spectral loss to reconstruct spectrograms. And after that, they use sparse transformers conditioned on lyrics to generate new patterns and upsample it to higher discrete samples and decode it to the song.
The net can even learn and generates some solo parts during the track.
explore some creepy songs: https://jukebox.openai.com/
code: https://github.com/openai/jukebox/
paper: https://cdn.openai.com/papers/jukebox.pdf
blog: https://openai.com/blog/jukebox/
#openAI #music #sound #cool #fan #creepy #vae #audiolearning #soundlearning
🔥Consistent Video Depth Estimation
New algorithm for reconstructing dense, geometrically consistent depth for all pixels in a monocular video.
Obviously, later there will be various VR/AR effects based on this research. Looking forward to it.
Paper: https://arxiv.org/abs/2004.15021
Project site: https://roxanneluo.github.io/Consistent-Video-Depth-Estimation/
Video: https://www.youtube.com/watch?v=5Tia2oblJAg
New algorithm for reconstructing dense, geometrically consistent depth for all pixels in a monocular video.
Obviously, later there will be various VR/AR effects based on this research. Looking forward to it.
Paper: https://arxiv.org/abs/2004.15021
Project site: https://roxanneluo.github.io/Consistent-Video-Depth-Estimation/
Video: https://www.youtube.com/watch?v=5Tia2oblJAg
Video lecture on geodesics
Geodesics generalize the idea of "straight lines" to curved spaces—like the circular arc an airplane takes across the globe. This video gives a crash course on geodesics, using geometric algorithms to help tell the story.
Video: https://youtu.be/uojNGbVtlsQ
#closeenough #othermath
Geodesics generalize the idea of "straight lines" to curved spaces—like the circular arc an airplane takes across the globe. This video gives a crash course on geodesics, using geometric algorithms to help tell the story.
Video: https://youtu.be/uojNGbVtlsQ
#closeenough #othermath
Forwarded from Graph Machine Learning
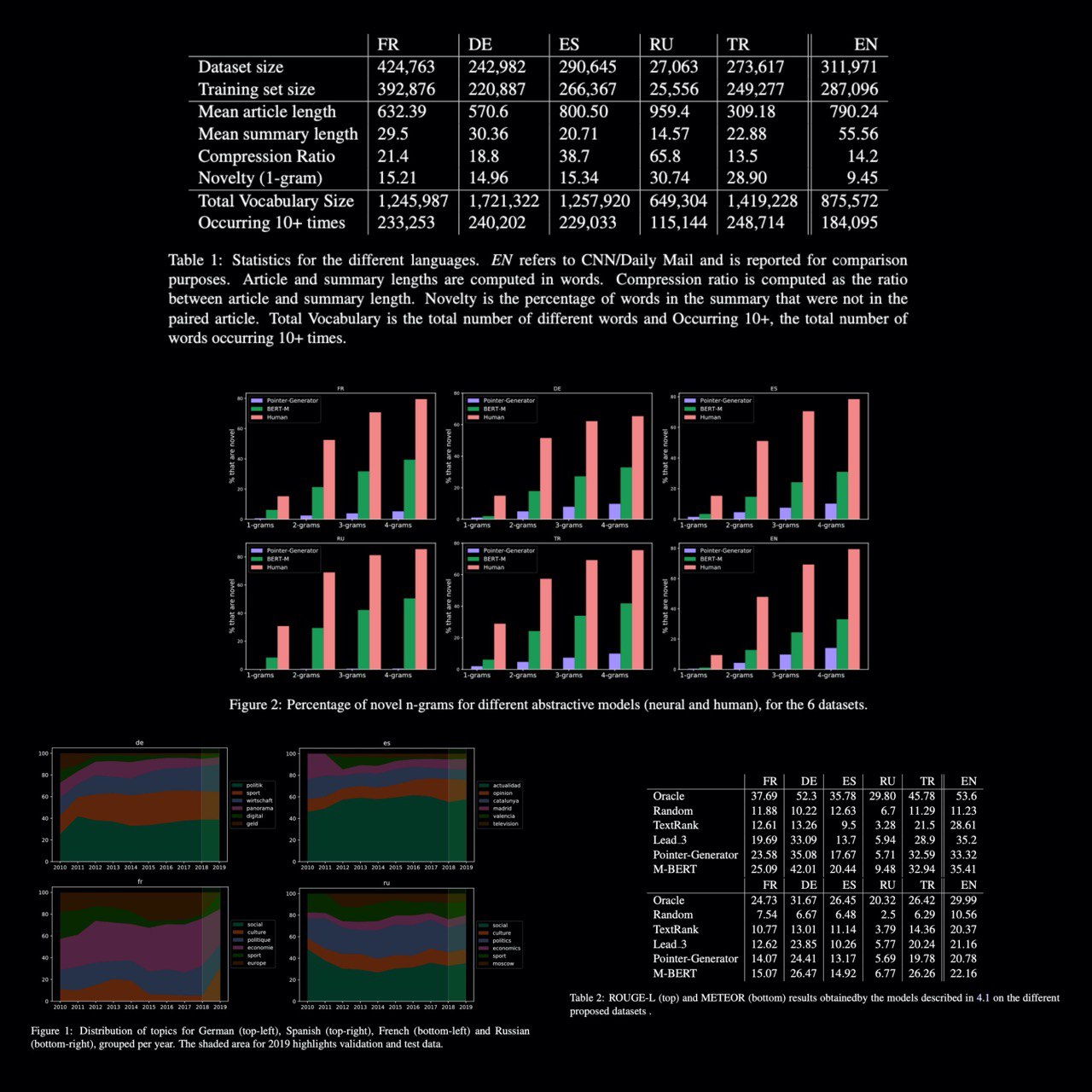
MLSUM: The Multilingual Summarization Corpus
The first large-scale MultiLingual SUMmarization dataset, comprising over 1.5M article/summary pairs in French, German, Russian, Spanish, and Turkish. Its complementary nature to the CNN/DM summarization dataset for English.
For each language, they selected an online newspaper from 2010 to 2019 which met the following requirements:
0 being a generalist newspaper: ensuring that a broad range of topics is represented for each language allows minimizing the risk of training topic-specific models, a fact which would hinder comparative cross-lingual analyses of the models.
1 having a large number of articles in their public online archive.
2 Providing human written highlights/summaries for the articles that can be extracted from the HTML code of the web page.
Also, in this paper, you can remember about similar other datasets
paper: https://arxiv.org/abs/2004.14900
github: https://github.com/recitalAI/MLSUM
Instructions and code will soon.
#nlp #corpus #dataset #multilingual
The first large-scale MultiLingual SUMmarization dataset, comprising over 1.5M article/summary pairs in French, German, Russian, Spanish, and Turkish. Its complementary nature to the CNN/DM summarization dataset for English.
For each language, they selected an online newspaper from 2010 to 2019 which met the following requirements:
0 being a generalist newspaper: ensuring that a broad range of topics is represented for each language allows minimizing the risk of training topic-specific models, a fact which would hinder comparative cross-lingual analyses of the models.
1 having a large number of articles in their public online archive.
2 Providing human written highlights/summaries for the articles that can be extracted from the HTML code of the web page.
Also, in this paper, you can remember about similar other datasets
paper: https://arxiv.org/abs/2004.14900
github: https://github.com/recitalAI/MLSUM
Instructions and code will soon.
#nlp #corpus #dataset #multilingual
{kind=link}
Shear, Torsion and Pressure Tactile Sensor via Plastic Optofiber Guided Imaging
CNN applied to tactile sensing
YouTube: https://youtu.be/7wsURXJrq7U
Paper: https://ieeexplore.ieee.org/abstract/document/8990014
CNN applied to tactile sensing
YouTube: https://youtu.be/7wsURXJrq7U
Paper: https://ieeexplore.ieee.org/abstract/document/8990014
YouTube
ICRA2020 Baimukashev Optical Tactile Sensor
Submitted to RA-L with ICRA2020 option
Martin Calvino's AI-inspired art is such an evoking meta-narrative of "art imitating tech imitating art"
https://www.martincalvino.co/paintings
#ai #art #abstract
https://www.martincalvino.co/paintings
#ai #art #abstract
{kind=link}
🤖 The NetHack Learning Environment
#Facebook launched new Reinforcement Learning environment for training agents based on #NetHack game. Nethack has nothing to do with what is considered common cybersecurity now, but it is an early terminal-based Minecraft (as a matter of fact one might say «console NetHack game» to go ‘all in’ in a word pun game).
NetHack is a wonderful RPG adventure game, happening in dungeon. Players control
#NLE uses python and ZeroMQ and we are looking forward to interesting applications or showcases to arise from this release.
Github: https://github.com/facebookresearch/nle
NetHack official page: http://nethack.org
#RL
#Facebook launched new Reinforcement Learning environment for training agents based on #NetHack game. Nethack has nothing to do with what is considered common cybersecurity now, but it is an early terminal-based Minecraft (as a matter of fact one might say «console NetHack game» to go ‘all in’ in a word pun game).
NetHack is a wonderful RPG adventure game, happening in dungeon. Players control
@ sign moving in ASCII-based environment, fighting enemies and doing quests. If you haven’t played it you are missing a whole piece of gaming culture and our editorial team kindly cheers you on at least trying to play it. Though now there lots of wikis and playing guides, canonicial way to play it is to dive into source code for looking up the keys and getting the whole idea of what to expect from different situations.#NLE uses python and ZeroMQ and we are looking forward to interesting applications or showcases to arise from this release.
Github: https://github.com/facebookresearch/nle
NetHack official page: http://nethack.org
#RL
👍1
The Cost of Training NLP Models: A Concise Overview
The authors review the cost of training large-scale language models, and the drivers of these costs.
More at the paper: https://arxiv.org/abs/2004.08900
#nlp #language
The authors review the cost of training large-scale language models, and the drivers of these costs.
More at the paper: https://arxiv.org/abs/2004.08900
#nlp #language
{kind=link}
By the coincedence we received a couple of help requests with trivial questions.
Thank you for using @opendatasciencebot and we will address the issue in our upcoming Ultimate Post on Where To Start with Data Science.
Our channel doesn’t advertise or spam, so our editorial team runs only on enthuasism (and because we want to give back to the community and spread worthy information). Therefore we do not have enough resources to provide response on technical questions regarding syntax and other errors and we can not help with your requests.
We can only advice to try stackoverflow for getting down to the source of your problems.
Thank you for using @opendatasciencebot and we will address the issue in our upcoming Ultimate Post on Where To Start with Data Science.
Our channel doesn’t advertise or spam, so our editorial team runs only on enthuasism (and because we want to give back to the community and spread worthy information). Therefore we do not have enough resources to provide response on technical questions regarding syntax and other errors and we can not help with your requests.
We can only advice to try stackoverflow for getting down to the source of your problems.