
Popular example of application AI to fashion
Ai can be used for chair design. Some generative models can definately be used in the fashion industry.
Link: https://qz.com/1770508/an-emerging-japanese-startup-is-mining-tradition-to-create-a-more-sustainable-fashion-future/
#aiapplication #generativedesign #meta
Ai can be used for chair design. Some generative models can definately be used in the fashion industry.
Link: https://qz.com/1770508/an-emerging-japanese-startup-is-mining-tradition-to-create-a-more-sustainable-fashion-future/
#aiapplication #generativedesign #meta
Extending relational query processing with ML inference
In some way, it may sound like something strange, but in a close view, it is a brilliant idea in our opinion.
Microsoft develops SQL DB with an inference ML model inside them. So you can do SQL query with a model like usual query alongside good optimization and runtimes as part of the builtin functionality of SQL engine. Data scientists develop an ML model with a pipeline and just put it inside the database. A stored model with the pipeline can then be invoked a bit like a stored procedure by issuing SQL commands.
So:
0. A statement adds the source code for the model pipeline (Python in the example) to the database.
1. At some later point, a SQL query is issued which a model and then uses the function to generate a prediction from the model given some input data (which is itself, of course, the result of a query).
2. The combined model and query undergo static analysis to produce an intermediate representation (IR) of the prediction computation as a DAG.
3. A cross-optimizer then looks for opportunities to optimize the data operator parts of the query given the ML model, and vice-versa (e.g., pruning).
4. A runtime code generator creates a SQL query incorporating all of these optimizations.
5. An extended version of SQL Server, with an integrated ONNX Runtime engine, executes the query.
Neural network translation optimizations replace classical ML operators and data features with NN that can be executed directly in e.g. ONNX Runtime, PyTorch, or TensorFlow.
paper (.pdf): http://cidrdb.org/cidr2020/papers/p24-karanasos-cidr20.pdf
blogpost: https://blog.acolyer.org/2020/02/21/extending-relational-query-processing/
software: https://azure.microsoft.com/en-gb/services/sql-database-edge/
#ml #db #sql
In some way, it may sound like something strange, but in a close view, it is a brilliant idea in our opinion.
Microsoft develops SQL DB with an inference ML model inside them. So you can do SQL query with a model like usual query alongside good optimization and runtimes as part of the builtin functionality of SQL engine. Data scientists develop an ML model with a pipeline and just put it inside the database. A stored model with the pipeline can then be invoked a bit like a stored procedure by issuing SQL commands.
So:
0. A statement adds the source code for the model pipeline (Python in the example) to the database.
1. At some later point, a SQL query is issued which a model and then uses the function to generate a prediction from the model given some input data (which is itself, of course, the result of a query).
2. The combined model and query undergo static analysis to produce an intermediate representation (IR) of the prediction computation as a DAG.
3. A cross-optimizer then looks for opportunities to optimize the data operator parts of the query given the ML model, and vice-versa (e.g., pruning).
4. A runtime code generator creates a SQL query incorporating all of these optimizations.
5. An extended version of SQL Server, with an integrated ONNX Runtime engine, executes the query.
Neural network translation optimizations replace classical ML operators and data features with NN that can be executed directly in e.g. ONNX Runtime, PyTorch, or TensorFlow.
paper (.pdf): http://cidrdb.org/cidr2020/papers/p24-karanasos-cidr20.pdf
blogpost: https://blog.acolyer.org/2020/02/21/extending-relational-query-processing/
software: https://azure.microsoft.com/en-gb/services/sql-database-edge/
#ml #db #sql
{kind=link}
How climate change, air pollution, and provider shortages are making things worse for allergy-sufferers
Analytical research (including #interactive maps) of connection of air pollution to allergy reactions in the U.S.
Link: https://medium.com/ro-co/how-climate-change-air-pollution-and-provider-shortages-are-making-things-worse-for-90e0f8d4a36b
#eda #explorative #healthcare #medical
Analytical research (including #interactive maps) of connection of air pollution to allergy reactions in the U.S.
Link: https://medium.com/ro-co/how-climate-change-air-pollution-and-provider-shortages-are-making-things-worse-for-90e0f8d4a36b
#eda #explorative #healthcare #medical
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 6 to 18 people.
ODS dinner in Munich! See you this Friday at 20:00 at
Opatija Easy im Tal
Hochbrückenstraße 3, 80331 München
089 268353
https://goo.gl/maps/iNMcNmzmvKbcxnqk7
Table is booked for Evgenii/Eugene/Ivgenii - try your best to identify :)
Opatija Easy im Tal
Hochbrückenstraße 3, 80331 München
089 268353
https://goo.gl/maps/iNMcNmzmvKbcxnqk7
Table is booked for Evgenii/Eugene/Ivgenii - try your best to identify :)
The Open Images Dataset V4 by GoogleAI
#GoogleAI present #OpenImagesV4, a #dataset of 9.2M images with unified annotations for:
– image #classification
– object #detection
– visual relationship detection
30.1M image-level labels for 19.8k concepts, 15.4M bounding boxes for 600 object classes
paper: https://arxiv.org/abs/1811.00982v2
#GoogleAI present #OpenImagesV4, a #dataset of 9.2M images with unified annotations for:
– image #classification
– object #detection
– visual relationship detection
30.1M image-level labels for 19.8k concepts, 15.4M bounding boxes for 600 object classes
paper: https://arxiv.org/abs/1811.00982v2
{kind=link}
Albumentation – fast & flexible image augmentations
Image Augmentations is a powerful technique to improve model robustness and performance. There are many image augmentations libraries on the market: torchvision, imgaug, DALI, Augmentor, SOLT, etc.
In all of them, authors focussed on variety at the cost of speed, or the speed at the cost of flexibility.
Requirements for augmentations:
* Variety: they want to have a large set of standard and exotic augmentation for image classification, segmentation, and detection in one place.
* Performance: transforms should be as fast as possible.
* Flexibility: it should be easy to add new transforms or new types of transforms.
* Conciseness: all complexity of implementation should be hidden behind the API.
To date
The library was adopted by academics, Kaggle, and other communities.
ODS: #tool_albumentations
Link: https://albumentations.ai/
Github: https://github.com/albumentations-team/albumentations
Paper: https://www.mdpi.com/2078-2489/11/2/125
P.S. Following trend setup by #Catalyst team, we provide extensive description of project with the help of its creators.
#guestpost #augmentation #CV #DL #imageprocessing #ods #objectdetection #imageclassification #tool
Image Augmentations is a powerful technique to improve model robustness and performance. There are many image augmentations libraries on the market: torchvision, imgaug, DALI, Augmentor, SOLT, etc.
In all of them, authors focussed on variety at the cost of speed, or the speed at the cost of flexibility.
Requirements for augmentations:
* Variety: they want to have a large set of standard and exotic augmentation for image classification, segmentation, and detection in one place.
* Performance: transforms should be as fast as possible.
* Flexibility: it should be easy to add new transforms or new types of transforms.
* Conciseness: all complexity of implementation should be hidden behind the API.
Albumentations were born out of necessity. The authors were actively participating in various Deep Learning competitions. To get to the top they needed something better than what was already available. All of them, independently, started working on more powerful augmentation pipelines. Later they merged their efforts and released the code in the form of the library.To date
Albumentations has more than 70 transforms and supports image classification, #segmentation, object and keypoint detection tasks.The library was adopted by academics, Kaggle, and other communities.
ODS: #tool_albumentations
Link: https://albumentations.ai/
Github: https://github.com/albumentations-team/albumentations
Paper: https://www.mdpi.com/2078-2489/11/2/125
P.S. Following trend setup by #Catalyst team, we provide extensive description of project with the help of its creators.
#guestpost #augmentation #CV #DL #imageprocessing #ods #objectdetection #imageclassification #tool
GitHub
GitHub - albumentations-team/albumentations: Fast and flexible image augmentation library. Paper about the library: https://www.mdpi.com/2078…
Fast and flexible image augmentation library. Paper about the library: https://www.mdpi.com/2078-2489/11/2/125 - albumentations-team/albumentations
Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer
tl;dr:
- 11 billion parameters
- encoder-decoder models generally outperformed “decoder-only” language models
- fill-in-the-blank-style denoising objectives worked best;
- the most important factor was the computational cost;
- training on in-domain data can be beneficial but that pre-training on smaller datasets can lead to detrimental overfitting;
- multitask learning could be close to competitive with a pre-train-then-fine-tune approach but requires carefully choosing how often the model is trained on each task
The model can be fine-tuned on smaller labeled datasets, often resulting in (far) better performance than training on the labeled data alone.
Present a large-scale empirical survey to determine which transfer learning techniques work best and apply these insights at scale to create a new model that we call the T5. Also, introduce a new open-source pre-training dataset, called the Colossal Clean Crawled Corpus (C4).
The T5 model, pre-trained on C4, achieves SOTA results on many NLP benchmarks while being flexible enough to be fine-tuned to a variety of important downstream tasks.
blog post: https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
paper: https://arxiv.org/abs/1910.10683
github (with pre-trained models): https://github.com/google-research/text-to-text-transfer-transformer
colab notebook: https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb
#nlp #transformer #t5
tl;dr:
- 11 billion parameters
- encoder-decoder models generally outperformed “decoder-only” language models
- fill-in-the-blank-style denoising objectives worked best;
- the most important factor was the computational cost;
- training on in-domain data can be beneficial but that pre-training on smaller datasets can lead to detrimental overfitting;
- multitask learning could be close to competitive with a pre-train-then-fine-tune approach but requires carefully choosing how often the model is trained on each task
The model can be fine-tuned on smaller labeled datasets, often resulting in (far) better performance than training on the labeled data alone.
Present a large-scale empirical survey to determine which transfer learning techniques work best and apply these insights at scale to create a new model that we call the T5. Also, introduce a new open-source pre-training dataset, called the Colossal Clean Crawled Corpus (C4).
The T5 model, pre-trained on C4, achieves SOTA results on many NLP benchmarks while being flexible enough to be fine-tuned to a variety of important downstream tasks.
blog post: https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
paper: https://arxiv.org/abs/1910.10683
github (with pre-trained models): https://github.com/google-research/text-to-text-transfer-transformer
colab notebook: https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb
#nlp #transformer #t5
{kind=link}
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 4 to 16 people.
🔥AI Meme Generator: This Meme Does Not Exist
Imgflip created an “AI meme generator”. Meme captions are generated by neural network.
Link: https://imgflip.com/ai-meme
#NLP #NLU #meme #generation #imgflip
Imgflip created an “AI meme generator”. Meme captions are generated by neural network.
Link: https://imgflip.com/ai-meme
#NLP #NLU #meme #generation #imgflip
{kind=link}
#DeepPavlov & #transformers
and now at 🤗 you can also use the next models:
-
-
-
-
-
-
page: https://huggingface.co/DeepPavlov
colab tutorial: here
and now at 🤗 you can also use the next models:
-
DeepPavlov/bert-base-bg-cs-pl-ru-cased-
DeepPavlov/bert-base-cased-conversational-
DeepPavlov/bert-base-multilingual-cased-sentence-
DeepPavlov/rubert-base-cased-conversational-
DeepPavlov/rubert-base-cased-sentence-
DeepPavlov/rubert-base-casedpage: https://huggingface.co/DeepPavlov
colab tutorial: here
{kind=link}
👍1
Data Science interview questions list
List, compiled from medium article and peer-provided contributions.
Github (questions and answers): https://github.com/alexeygrigorev/data-science-interviews/blob/master/theory.md
#interview #questions #meta
List, compiled from medium article and peer-provided contributions.
Github (questions and answers): https://github.com/alexeygrigorev/data-science-interviews/blob/master/theory.md
#interview #questions #meta
GitHub
data-science-interviews/theory.md at master · alexeygrigorev/data-science-interviews
Data science interview questions and answers. Contribute to alexeygrigorev/data-science-interviews development by creating an account on GitHub.
Forwarded from Spark in me (Alexander)
Russian Text Normalization for Speech Recognition
Usually no one talks about this, but STT / TTS technologies contain many "small" tasks that have to be solved, to make your STT / TTS pipeline work in real life.
For example:
- Speech recognition / dataset itself;
- Post-processing - beam-search / decoding;
- Domain customizations;
- Normalization (5 =>
- De-Normalization (
We want the Imagenet moment to arrive sooner in Speech in general.
So we released the Open STT dataset.
This time we have decided to share our text normalization to support STT research in Russian.
Please like / share / repost:
- Original publication
- Habr.com article
- GitHub repository
- Medium (coming soon!)
- Support dataset on Open Collective
#stt
#deep_learning
#nlp
Usually no one talks about this, but STT / TTS technologies contain many "small" tasks that have to be solved, to make your STT / TTS pipeline work in real life.
For example:
- Speech recognition / dataset itself;
- Post-processing - beam-search / decoding;
- Domain customizations;
- Normalization (5 =>
пять);- De-Normalization (
пять => 5);We want the Imagenet moment to arrive sooner in Speech in general.
So we released the Open STT dataset.
This time we have decided to share our text normalization to support STT research in Russian.
Please like / share / repost:
- Original publication
- Habr.com article
- GitHub repository
- Medium (coming soon!)
- Support dataset on Open Collective
#stt
#deep_learning
#nlp
GitHub
GitHub - snakers4/open_stt: Open STT
Open STT. Contribute to snakers4/open_stt development by creating an account on GitHub.
TensorFlow Quantum
A Software Framework for Quantum Machine Learning
Introduce TensorFlow Quantum (TFQ), an open source library for the rapid prototyping of hybrid quantum-classical models for classical or quantum data.
TFQ provides the tools necessary for bringing the quantum computing and ML research communities together to control and model natural or artificial quantum systems; e.g. Noisy Intermediate Scale Quantum (NISQ) processors with ~50-100 qubits.
A quantum model has the ability to represent and generalize data with a quantum mechanical origin. However, to understand quantum models, two concepts must be introduced – quantum data and hybrid quantum-classical models.
Quantum data exhibits superposition and entanglement, leading to joint probability distributions that could require an exponential amount of classical computational resources to represent or store. Quantum data, which can be generated/simulated on quantum processors/sensors/networks include the simulation of chemicals and quantum matter, quantum control, quantum communication networks, quantum metrology, and much more.
Quantum models cannot use quantum processors alone – NISQ processors will need to work in concert with classical processors to become effective. As TensorFlow already supports heterogeneous computing across CPUs, GPUs, and TPUs, it is a natural platform for experimenting with hybrid quantum-classical algorithms.
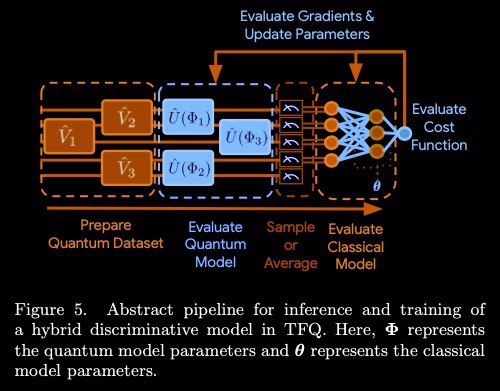
To build and train such a model, the researcher can do the following:
– prepare a quantum dataset
– evaluate a quantum NN model
- sample or Average
– evaluate a classical NN model
– evaluate сost function
– evaluate gradients & update parameters
blog post: https://ai.googleblog.com/2020/03/announcing-tensorflow-quantum-open.html
paper: https://arxiv.org/abs/2003.02989
#tfq #tensorflow #quantum #physics #ml
A Software Framework for Quantum Machine Learning
Introduce TensorFlow Quantum (TFQ), an open source library for the rapid prototyping of hybrid quantum-classical models for classical or quantum data.
TFQ provides the tools necessary for bringing the quantum computing and ML research communities together to control and model natural or artificial quantum systems; e.g. Noisy Intermediate Scale Quantum (NISQ) processors with ~50-100 qubits.
A quantum model has the ability to represent and generalize data with a quantum mechanical origin. However, to understand quantum models, two concepts must be introduced – quantum data and hybrid quantum-classical models.
Quantum data exhibits superposition and entanglement, leading to joint probability distributions that could require an exponential amount of classical computational resources to represent or store. Quantum data, which can be generated/simulated on quantum processors/sensors/networks include the simulation of chemicals and quantum matter, quantum control, quantum communication networks, quantum metrology, and much more.
Quantum models cannot use quantum processors alone – NISQ processors will need to work in concert with classical processors to become effective. As TensorFlow already supports heterogeneous computing across CPUs, GPUs, and TPUs, it is a natural platform for experimenting with hybrid quantum-classical algorithms.
To build and train such a model, the researcher can do the following:
– prepare a quantum dataset
– evaluate a quantum NN model
- sample or Average
– evaluate a classical NN model
– evaluate сost function
– evaluate gradients & update parameters
blog post: https://ai.googleblog.com/2020/03/announcing-tensorflow-quantum-open.html
paper: https://arxiv.org/abs/2003.02989
#tfq #tensorflow #quantum #physics #ml
{kind=link}
Survey of machine-learning experimental methods at NeurIPS2019 and ICLR2020
Good thread about what ML scientists do experiments on their papers
twitter: https://twitter.com/deliprao/status/1235697595919421440
report: https://hal.archives-ouvertes.fr/hal-02447823/document
#Survey #NeurIPS #ICLR #Experiments #ml
Good thread about what ML scientists do experiments on their papers
twitter: https://twitter.com/deliprao/status/1235697595919421440
report: https://hal.archives-ouvertes.fr/hal-02447823/document
#Survey #NeurIPS #ICLR #Experiments #ml
Twitter
Delip Rao
Survey of #MachineLearning experimental methods (aka "how do ML folks do their experiments") at #NeurIPS2019 and #ICLR2020, a thread of results:
{kind=link}
Can evolution be the Master Algorithm?
Fun AutoML-Zero experiments: Evolutionary search discovers fundamental ML algorithms from scratch, e.g., small neural nets with backprop.
Genetic programming learned operations reminiscent of dropout, normalized gradients, and weight averaging when trying to evolve better learning algorithms.
Paper: https://arxiv.org/abs/2003.03384
Code: https://git.io/JvKrZ
#automl #genetic
Fun AutoML-Zero experiments: Evolutionary search discovers fundamental ML algorithms from scratch, e.g., small neural nets with backprop.
Genetic programming learned operations reminiscent of dropout, normalized gradients, and weight averaging when trying to evolve better learning algorithms.
Paper: https://arxiv.org/abs/2003.03384
Code: https://git.io/JvKrZ
#automl #genetic
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 6 to 12 coronafearless people.
Forwarded from Karim Iskakov - канал (Vladimir Ivashkin)
New paper by Yandex.MILAB 🎉
Tired of waiting for backprop to project your face into StyleGAN latent space to use some funny vector on it? Just distilate this tranformation by pix2pixHD!
📝 arxiv.org/abs/2003.03581
👤 @iviazovetskyi, @vlivashkin, @digitman
📉 @loss_function_porn
Tired of waiting for backprop to project your face into StyleGAN latent space to use some funny vector on it? Just distilate this tranformation by pix2pixHD!
📝 arxiv.org/abs/2003.03581
👤 @iviazovetskyi, @vlivashkin, @digitman
📉 @loss_function_porn