
AI & Art
some artist use the large collections of #data & #ML #algorithms to create mesmerizing & dynamic #installations
watch the video —> https://youtu.be/I-EIVlHvHRM
some artist use the large collections of #data & #ML #algorithms to create mesmerizing & dynamic #installations
watch the video —> https://youtu.be/I-EIVlHvHRM
YouTube
How This Guy Uses A.I. to Create Art | Obsessed | WIRED
Artist Refik Anadol doesn't work with paintbrushes or clay. Instead, he uses large collections of data and machine learning algorithms to create mesmerizing and dynamic installations.
Machine Hallucination at Artechouse NYC: https://www.artechouse.com/nyc…
Machine Hallucination at Artechouse NYC: https://www.artechouse.com/nyc…
Revealing the Dark Secrets of BERT
tl;dr:
* BERT is heavily over parametrized
* BERT does not need to be all that smart
* BERT’s success is due to ~black magic~ something other than self-attention
This work focuses on the complementary question: what happens in the fine-tuned #BERT? In particular, how much of the linguistically interpretable self-attention patterns that are presumed to be its strength are actually used to solve downstream tasks?
Using a subset of #GLUE tasks and a set of handcrafted features-of-interest, they propose the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
Also, they show that manually disabling attention in certain heads leads to performance improvement over the regular fine-tuned BERT models.
paper: https://www.aclweb.org/anthology/D19-1445.pdf
blog post: https://text-machine-lab.github.io/blog/2020/bert-secrets/
tl;dr:
* BERT is heavily over parametrized
* BERT does not need to be all that smart
* BERT’s success is due to ~black magic~ something other than self-attention
This work focuses on the complementary question: what happens in the fine-tuned #BERT? In particular, how much of the linguistically interpretable self-attention patterns that are presumed to be its strength are actually used to solve downstream tasks?
Using a subset of #GLUE tasks and a set of handcrafted features-of-interest, they propose the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
Also, they show that manually disabling attention in certain heads leads to performance improvement over the regular fine-tuned BERT models.
paper: https://www.aclweb.org/anthology/D19-1445.pdf
blog post: https://text-machine-lab.github.io/blog/2020/bert-secrets/
{kind=link}
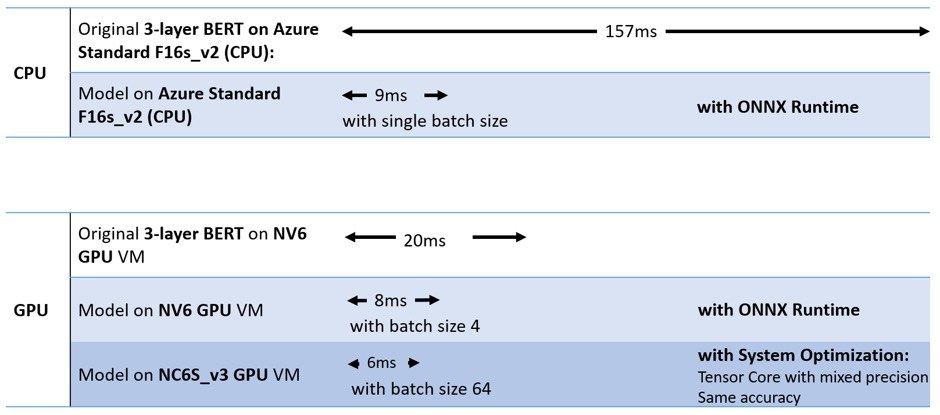
Microsoft open sources breakthrough optimizations for transformer inference on GPU and CPU
How?
#Transformer models like #BERT consist of a graph of many operators. Graph optimization, ranging from small graph simplifications and node eliminations to more complex node fusions and layout optimizations, is an essential technique built into #ONNX Runtime.
Since the BERT model is mainly composed of stacked transformer cells, we optimize each cell by fusing key sub-graphs of multiple elementary operators into single kernels for both CPU and GPU, including Self-Attention, LayerNormalization, and Gelu layers. This significantly reduces memory copy between numerous elementary computations.
Additionally, in the CPU implementation of Self-Attention, the columns of matrix Q, K, and V are partitioned based on the number of self-attention heads. With this optimization, we can significantly increase the parallelization and fully leverage available CPU cores. Moreover, the transpose op following the full connection of Q, K, and V can be computed within GEMM, which further reduces the computation cost.
blog post: https://cloudblogs.microsoft.com/opensource/2020/01/21/microsoft-onnx-open-source-optimizations-transformer-inference-gpu-cpu/
How?
#Transformer models like #BERT consist of a graph of many operators. Graph optimization, ranging from small graph simplifications and node eliminations to more complex node fusions and layout optimizations, is an essential technique built into #ONNX Runtime.
Since the BERT model is mainly composed of stacked transformer cells, we optimize each cell by fusing key sub-graphs of multiple elementary operators into single kernels for both CPU and GPU, including Self-Attention, LayerNormalization, and Gelu layers. This significantly reduces memory copy between numerous elementary computations.
Additionally, in the CPU implementation of Self-Attention, the columns of matrix Q, K, and V are partitioned based on the number of self-attention heads. With this optimization, we can significantly increase the parallelization and fully leverage available CPU cores. Moreover, the transpose op following the full connection of Q, K, and V can be computed within GEMM, which further reduces the computation cost.
blog post: https://cloudblogs.microsoft.com/opensource/2020/01/21/microsoft-onnx-open-source-optimizations-transformer-inference-gpu-cpu/
{kind=link}
AI Career Pathways: Put Yourself on the Right Track
by deeplearning.ai (founder Andrew Ng)
tl;dr: at the picture
This report aims to clarify what #AI organizations are, what tasks you will work on, and the existing career tracks. It can help learners around the world choose a career track that matches their skills, background, and aspirations.
report: https://www.workera.ai/candidates/report/
by deeplearning.ai (founder Andrew Ng)
tl;dr: at the picture
This report aims to clarify what #AI organizations are, what tasks you will work on, and the existing career tracks. It can help learners around the world choose a career track that matches their skills, background, and aspirations.
report: https://www.workera.ai/candidates/report/
{kind=link}
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 5 to 14 people.
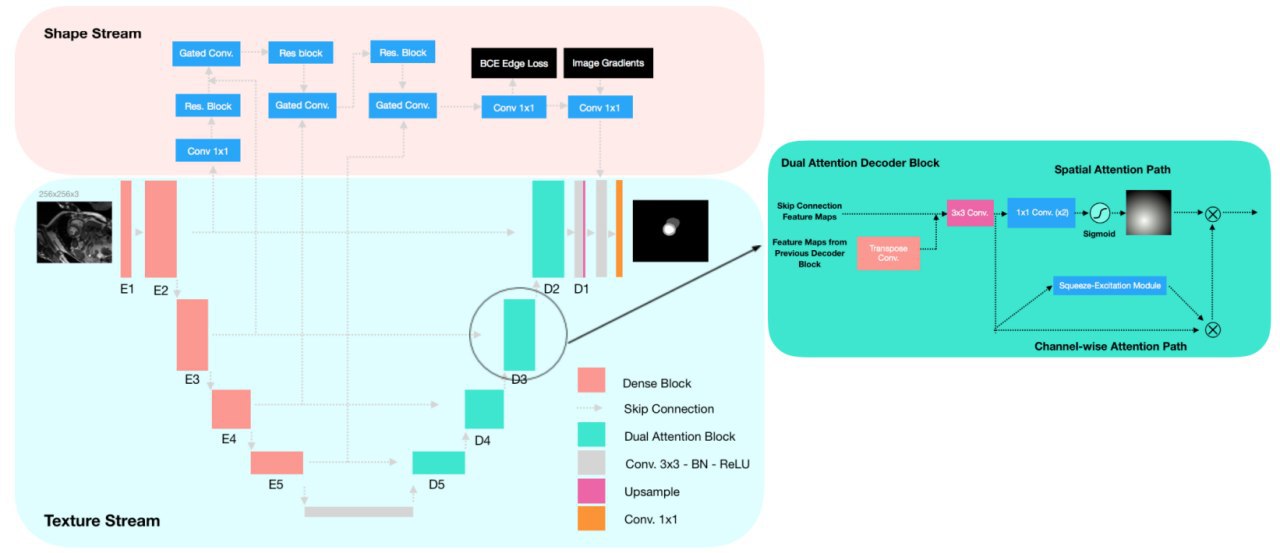
SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation
New approach for interpreting medical image segmentation models.
U-Net and other image segmentation models work quite well on medical data, but still aren't widely adopted. One of the reasons is the lack of reproducibility as well as robustness issues.
The key idea of the paper is using the additional stream in U-Net with shape features to increase robustness and use the output of this stream (attention map) that can be used or interpretability.
Modifications to the basic U-Net architecture:
- use dense blocks from DenseNet-121 as the encoder.
- use dual attention decoder block (with spatial and channel-wise attention paths)
- make the second stream using object shape (contour)
- dual-task loss function: cross-entropy + dice + edge loss (bce loss of the predicted shape boundaries)
Shape and spatial attention maps can be used for interpretation.
Paper: https://arxiv.org/abs/2001.07645
Code: https://github.com/sunjesse/shape-attentive-unet
#unet #imagesegmentation #interpretability #segmentation
New approach for interpreting medical image segmentation models.
U-Net and other image segmentation models work quite well on medical data, but still aren't widely adopted. One of the reasons is the lack of reproducibility as well as robustness issues.
The key idea of the paper is using the additional stream in U-Net with shape features to increase robustness and use the output of this stream (attention map) that can be used or interpretability.
Modifications to the basic U-Net architecture:
- use dense blocks from DenseNet-121 as the encoder.
- use dual attention decoder block (with spatial and channel-wise attention paths)
- make the second stream using object shape (contour)
- dual-task loss function: cross-entropy + dice + edge loss (bce loss of the predicted shape boundaries)
Shape and spatial attention maps can be used for interpretation.
Paper: https://arxiv.org/abs/2001.07645
Code: https://github.com/sunjesse/shape-attentive-unet
#unet #imagesegmentation #interpretability #segmentation
{kind=link}
Natural Language Processing News
by Sebastian Ruder
* NLP progress
* Retrospectives and look ahead
* New NLP courses
* Independent research initiatives
* Interviews
* Resources
* Tools
* Articles and blog posts
* Papers + blog post
* Paper picks
blog post: http://newsletter.ruder.io/issues/nlp-progress-restrospectives-and-look-ahead-new-nlp-courses-independent-research-initiatives-interviews-lots-of-resources-217744
#nlp #progress #news #ruder
by Sebastian Ruder
* NLP progress
* Retrospectives and look ahead
* New NLP courses
* Independent research initiatives
* Interviews
* Resources
* Tools
* Articles and blog posts
* Papers + blog post
* Paper picks
blog post: http://newsletter.ruder.io/issues/nlp-progress-restrospectives-and-look-ahead-new-nlp-courses-independent-research-initiatives-interviews-lots-of-resources-217744
#nlp #progress #news #ruder
{kind=link}
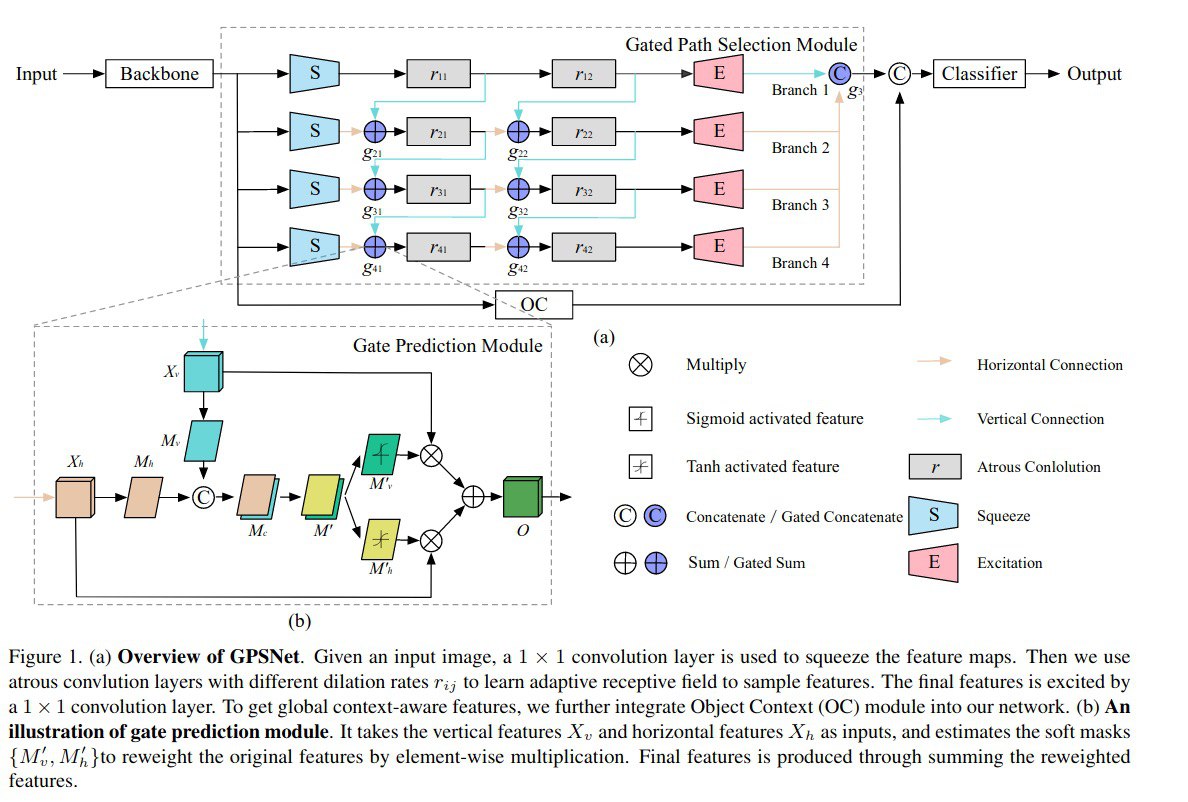
Gated Path Selection Network for Semantic Segmentation
A new approach for improving APSS-like networks for image segmentation.
Atrous Spatial Pyramid Pooling (ASPP) is an architecture that concatenates multiple atrous-convolved features using different dilution rates.
In this paper, authors develop a novel architecture named GPSNet, which aims to densely capture semantic context and to learn adaptive receptive fields, which are flexible to model various geometric deformations.
They designed architecture with multiple branches called SuperNet. The main characteristics are the following:
- it stacks a series of bottlenecked branches which consist of differently tuned dilation convolutions;
- multiple dense connections;
- a new module - Gate Prediction, which produces soft masks;
- improved sampling.
This approach was tested on Cityscapes и ADE20K datasets and showed better quality than other ASPP architectures, but still not as good as the current SOTA.
An ablation study shows that all changes introduced in this paper improve the score.
GPS module is lightweight and can be easily used in other models with ASPP architecture.
paper: https://deepai.org/publication/gated-path-selection-network-for-semantic-segmentation
#cv #semantic #segmentation #ASPP
A new approach for improving APSS-like networks for image segmentation.
Atrous Spatial Pyramid Pooling (ASPP) is an architecture that concatenates multiple atrous-convolved features using different dilution rates.
In this paper, authors develop a novel architecture named GPSNet, which aims to densely capture semantic context and to learn adaptive receptive fields, which are flexible to model various geometric deformations.
They designed architecture with multiple branches called SuperNet. The main characteristics are the following:
- it stacks a series of bottlenecked branches which consist of differently tuned dilation convolutions;
- multiple dense connections;
- a new module - Gate Prediction, which produces soft masks;
- improved sampling.
This approach was tested on Cityscapes и ADE20K datasets and showed better quality than other ASPP architectures, but still not as good as the current SOTA.
An ablation study shows that all changes introduced in this paper improve the score.
GPS module is lightweight and can be easily used in other models with ASPP architecture.
paper: https://deepai.org/publication/gated-path-selection-network-for-semantic-segmentation
#cv #semantic #segmentation #ASPP
{kind=link}
🔝Great OpenDataScience Channel Audience Research
The first audience research was done on 25.06.18 and it is time to update our knowledge on what are we.
Please fill in this form: https://forms.gle/GGNgukYNQbAZPtmk8 all the collected data will be used to benefit and it will dramatically help us to improve quality of content we share!
Google form link: https://forms.gle/GGNgukYNQbAZPtmk8
The first audience research was done on 25.06.18 and it is time to update our knowledge on what are we.
Please fill in this form: https://forms.gle/GGNgukYNQbAZPtmk8 all the collected data will be used to benefit and it will dramatically help us to improve quality of content we share!
Google form link: https://forms.gle/GGNgukYNQbAZPtmk8
Google Docs
@opendatascience audience research 2020
Hey, this is a form to study the audience of our channel to post more relevant and interesting content for you. Please fill in.
However, first question with residence country is not obligatory, channel administration will highly appreciate any answers, for…
However, first question with residence country is not obligatory, channel administration will highly appreciate any answers, for…
Data Science by ODS.ai 🦜 pinned «🔝Great OpenDataScience Channel Audience Research The first audience research was done on 25.06.18 and it is time to update our knowledge on what are we. Please fill in this form: https://forms.gle/GGNgukYNQbAZPtmk8 all the collected data will be used to…»
We have collected 26 responses so far, which gives us 2% conversion rate.
Please invest your time in filling in the form, it is to your benefit as reader.
This is especially important if you might find yourself under-represented in the questionnaire results in the end (when we have collected enought data. 26 responses now are extremely biased).
Please invest your time in filling in the form, it is to your benefit as reader.
This is especially important if you might find yourself under-represented in the questionnaire results in the end (when we have collected enought data. 26 responses now are extremely biased).
🔥Human-like chatbots from Google: Towards a Human-like Open-Domain Chatbot.
TLDR: humanity is one huge step closer to a chat-bot, which can chat about anything and has great chance of success, passing #TuringTest
What does it mean: As an example, soon you will have to be extra-cautious chatting in #dating apps, because there will be more chat-bots, who can seem humane.
This also means that there will some positive and productive applications too: more sophisticated selling operators, on-demand psychological support, you name it.
It might be surprising, but #seq2seq still works. Over 5+ years of working on neural conversational models, general progress is a fine-tune of basic approach. It is a proof that much can be still discovered, along with room for new completely different approaches.
«Perplexity is all a chatbot needs ;)» (с) Quoc Le
Blog post: https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html
Paper: https://arxiv.org/abs/2001.09977
Demo conversations: https://github.com/google-research/google-research/tree/master/meena
#NLP #NLU #ChatBots #google #googleai
TLDR: humanity is one huge step closer to a chat-bot, which can chat about anything and has great chance of success, passing #TuringTest
What does it mean: As an example, soon you will have to be extra-cautious chatting in #dating apps, because there will be more chat-bots, who can seem humane.
This also means that there will some positive and productive applications too: more sophisticated selling operators, on-demand psychological support, you name it.
It might be surprising, but #seq2seq still works. Over 5+ years of working on neural conversational models, general progress is a fine-tune of basic approach. It is a proof that much can be still discovered, along with room for new completely different approaches.
«Perplexity is all a chatbot needs ;)» (с) Quoc Le
Blog post: https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html
Paper: https://arxiv.org/abs/2001.09977
Demo conversations: https://github.com/google-research/google-research/tree/master/meena
#NLP #NLU #ChatBots #google #googleai
research.google
Towards a Conversational Agent that Can Chat About…Anything
Posted by Daniel Adiwardana, Senior Research Engineer, and Thang Luong, Senior Research Scientist, Google Research, Brain Team Modern conversatio...
Open-source library provides explanation for machine learning through diverse counterfactuals
This is a development of #interpretable ML. Library to explore “what-if” scenarios for ML models.
Blog post: https://www.microsoft.com/en-us/research/blog/open-source-library-provides-explanation-for-machine-learning-through-diverse-counterfactuals/
Paper: https://www.microsoft.com/en-us/research/publication/explaining-machine-learning-classifiers-through-diverse-counterfactual-examples/
Github: https://github.com/microsoft/dice
#Microsoft #ML #opensource
This is a development of #interpretable ML. Library to explore “what-if” scenarios for ML models.
Blog post: https://www.microsoft.com/en-us/research/blog/open-source-library-provides-explanation-for-machine-learning-through-diverse-counterfactuals/
Paper: https://www.microsoft.com/en-us/research/publication/explaining-machine-learning-classifiers-through-diverse-counterfactual-examples/
Github: https://github.com/microsoft/dice
#Microsoft #ML #opensource
Microsoft Research
DiCE: Employing counterfactuals to explain machine learning algorithms
Microsoft researchers & collaborators created an open-source library to explore “what-if” scenarios for machine learning models. Learn how their method generates multiple diverse counterfactuals at once & gives insight into ML algorithm decision making.
Data Science by ODS.ai 🦜
We have collected 26 responses so far, which gives us 2% conversion rate. Please invest your time in filling in the form, it is to your benefit as reader. This is especially important if you might find yourself under-represented in the questionnaire results…
👏Right after the request in channel, number of responses spiked to 70!
Thank you for all your time, but to-date 150 responses are not enough to be statistically correct representation of our audience.
Please, fill in the questionnaire form. Please, invest some of your time into the filling the form, because it will be very benefitial to the channel and audience.
Especially, if you are not that often reader, because you can be under-represented in this poll!
This is you chance to influence channel policy, don’t lose it, vote:
https://forms.gle/BzueRFAw3WFS8uk67
Thank you for all your time, but to-date 150 responses are not enough to be statistically correct representation of our audience.
Please, fill in the questionnaire form. Please, invest some of your time into the filling the form, because it will be very benefitial to the channel and audience.
Especially, if you are not that often reader, because you can be under-represented in this poll!
This is you chance to influence channel policy, don’t lose it, vote:
https://forms.gle/BzueRFAw3WFS8uk67
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 8 to 14 people.
An autonomous AI racecar using NVIDIA Jetson Nano
Usually DS means some blue collar work. Rare cases suggest physical interactions. This set by #NVidia allows to build $400/$600 toy car capable of #selfdriving.
#JetRacer comes with a couple examples to get you up and running. The examples are in the format of Jupyter Notebooks, which are interactive documents which combine text, code, and visualization. Once you've completed the notebooks, start tweaking them to create your own racing software!
Github: https://github.com/NVIDIA-AI-IOT/jetracer
#autonomousvehicle #rl #jupyter #physical
Usually DS means some blue collar work. Rare cases suggest physical interactions. This set by #NVidia allows to build $400/$600 toy car capable of #selfdriving.
#JetRacer comes with a couple examples to get you up and running. The examples are in the format of Jupyter Notebooks, which are interactive documents which combine text, code, and visualization. Once you've completed the notebooks, start tweaking them to create your own racing software!
Github: https://github.com/NVIDIA-AI-IOT/jetracer
#autonomousvehicle #rl #jupyter #physical
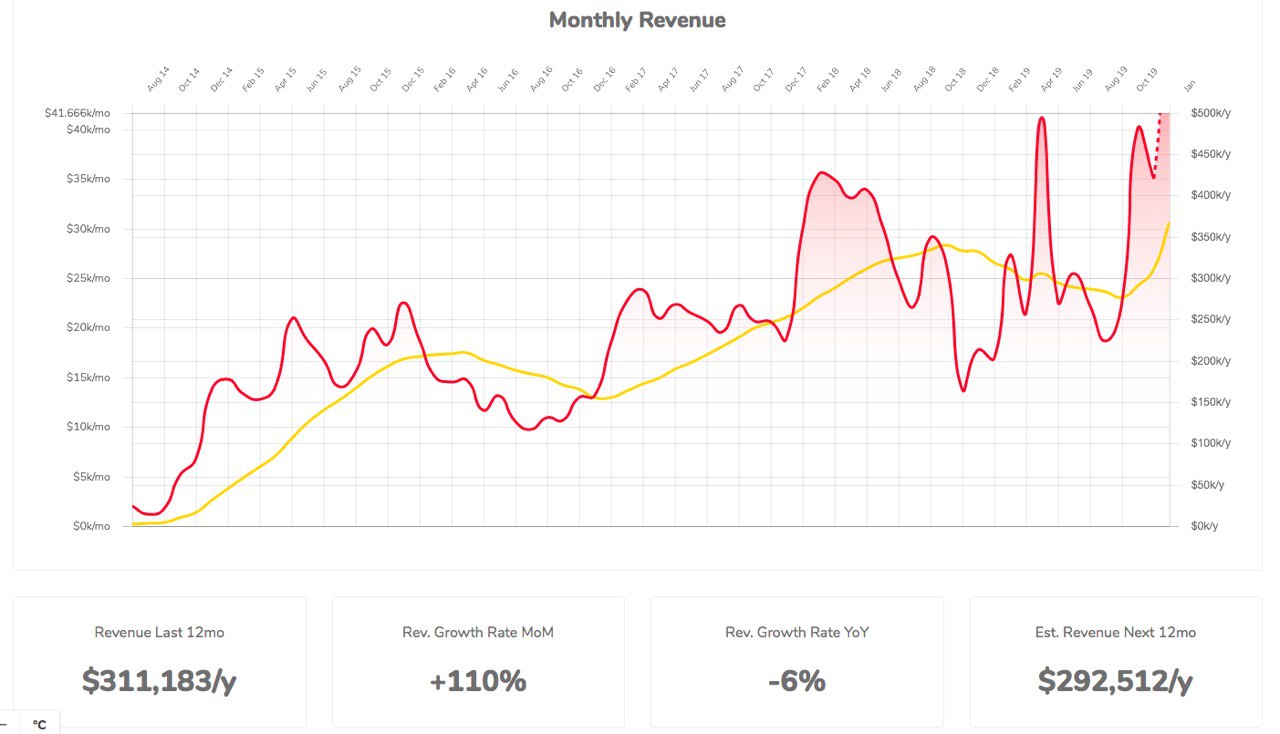
Nomadlist Open Data portal
#OpenStartup is a concept of sharing usually private business data and KPIs. Nomadlist is a great example of this concept, sharing yearly revenue, and most importantly, valuable insights, like the auto-refund data.
#OpenData Portal: https://nomadlist.com/open
Auto-refund thread: https://twitter.com/levelsio/status/1222444905244479489
Nomadlist URL: https://nomadlist.com
#OpenStartup is a concept of sharing usually private business data and KPIs. Nomadlist is a great example of this concept, sharing yearly revenue, and most importantly, valuable insights, like the auto-refund data.
#OpenData Portal: https://nomadlist.com/open
Auto-refund thread: https://twitter.com/levelsio/status/1222444905244479489
Nomadlist URL: https://nomadlist.com
{kind=link}
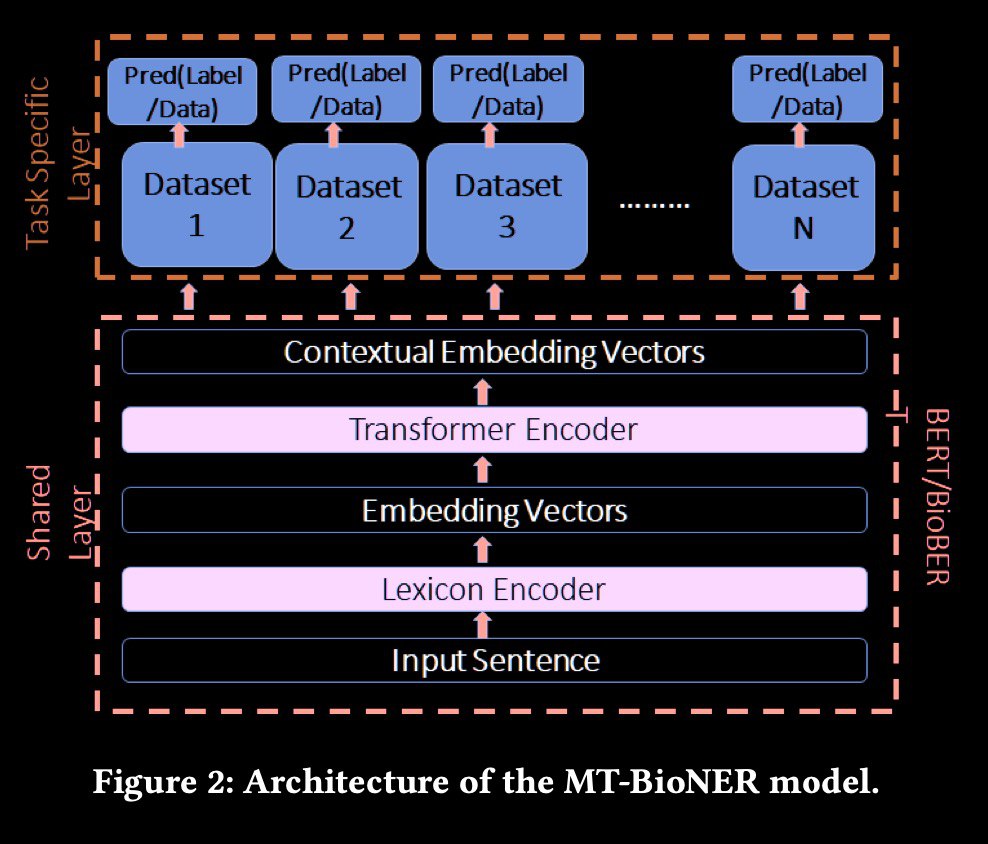
A new approach for NER on partially labeled datasets.
One of the common problems with NER modeling is the lack of datasets covering all required slot types. Often there are several datasets that have labels for different entities.
The key idea of the paper is using multi-task transformer-based architecture on multiple datasets.
The model architecture looks like this:
- lexicon encoder layer (input is tokens with words, position and segment embeddings);
- transformer encoder, which generates the shared contextual embedding vectors;
- separate heads for each dataset.
During the training phase, it is necessary to not only train the task-dependent layers but also to fine-tune the shared language model.
Experiments were conducted on four datasets using a single Tesla K80. A single multi-task model (iterating over datasets) shows SOTA results and trains faster than separate models for each task.
Paper: https://arxiv.org/abs/2001.08904
#nlp #bert #ner #biomedical
MT-BioNER: Multi-task Learning for Biomedical Named EntityRecognition using Deep Bidirectional TransformersA new approach for NER on partially labeled datasets.
One of the common problems with NER modeling is the lack of datasets covering all required slot types. Often there are several datasets that have labels for different entities.
The key idea of the paper is using multi-task transformer-based architecture on multiple datasets.
The model architecture looks like this:
- lexicon encoder layer (input is tokens with words, position and segment embeddings);
- transformer encoder, which generates the shared contextual embedding vectors;
- separate heads for each dataset.
During the training phase, it is necessary to not only train the task-dependent layers but also to fine-tune the shared language model.
Experiments were conducted on four datasets using a single Tesla K80. A single multi-task model (iterating over datasets) shows SOTA results and trains faster than separate models for each task.
Paper: https://arxiv.org/abs/2001.08904
#nlp #bert #ner #biomedical
{kind=link}
HiPlot: High-dimensional interactive plots made easy
Interactive parameters' performance #visualization tool. This new Facebook AI's release enables researchers to more easily evaluate the influence of their hyperparameters, such as learning rate, regularizations, and architecture.
Link: https://ai.facebook.com/blog/hiplot-high-dimensional-interactive-plots-made-easy
Github: https://github.com/facebookresearch/hiplot
Demo: https://facebookresearch.github.io/hiplot/_static/demo/demo_basic_usage.html
Pip:
#hyperopt #facebook #opensource
Interactive parameters' performance #visualization tool. This new Facebook AI's release enables researchers to more easily evaluate the influence of their hyperparameters, such as learning rate, regularizations, and architecture.
Link: https://ai.facebook.com/blog/hiplot-high-dimensional-interactive-plots-made-easy
Github: https://github.com/facebookresearch/hiplot
Demo: https://facebookresearch.github.io/hiplot/_static/demo/demo_basic_usage.html
Pip:
pip install hiplot#hyperopt #facebook #opensource
SGLB: Stochastic Gradient Langevin Boosting
In this paper, the authors introduce Stochastic Gradient Langevin Boosting (SGLB) – a powerful and efficient ML framework, which may deal with a wide range of loss functions and has provable generalization guarantees. The method is based on a special form of Langevin Diffusion equation specifically designed for gradient boosting. This allows guarantee the global convergence, while standard gradient boosting algorithms can guarantee only local optima, which is a problem for multimodal loss functions. To illustrate the advantages of SGLB, they apply it to a classification task with
The algorithm is implemented as a part of the CatBoost gradient boosting library and outperforms classic gradient boosting methods.
paper: https://arxiv.org/abs/2001.07248
release: https://github.com/catboost/catboost/releases/tag/v0.21
#langevin #boosting #catboost
In this paper, the authors introduce Stochastic Gradient Langevin Boosting (SGLB) – a powerful and efficient ML framework, which may deal with a wide range of loss functions and has provable generalization guarantees. The method is based on a special form of Langevin Diffusion equation specifically designed for gradient boosting. This allows guarantee the global convergence, while standard gradient boosting algorithms can guarantee only local optima, which is a problem for multimodal loss functions. To illustrate the advantages of SGLB, they apply it to a classification task with
0-1 loss function, which is known to be multimodal, and to a standard Logistic regression task that is convex.The algorithm is implemented as a part of the CatBoost gradient boosting library and outperforms classic gradient boosting methods.
paper: https://arxiv.org/abs/2001.07248
release: https://github.com/catboost/catboost/releases/tag/v0.21
#langevin #boosting #catboost
{kind=link}