
ODS breakfast in Paris! 🇫🇷 As an exception, because of the manifestations, this Saturday, we meet at 9:45 at Malongo Café, 50 Rue Saint-André des Arts. We can have lunch after that as well. See you tomorrow.
New tutorial on QA task
The T5 team competed against T5 in a "pub quiz" on (context-free) questions from the TriviaQA/NQ validation sets.
Result: team got 20% right; T5 got 35%.
Colab link: https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb
Source: twitter
#NLU #NLP #Colab #Tutorial #QA
The T5 team competed against T5 in a "pub quiz" on (context-free) questions from the TriviaQA/NQ validation sets.
Result: team got 20% right; T5 got 35%.
Colab link: https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb
Source: twitter
#NLU #NLP #Colab #Tutorial #QA
Your Classifier is Secretly an Energy-Based Model and You Should Treat it Like One
Classifiers are secretly energy-based models! Every softmax giving
The authors did math tricks to the joint Energy-Based Model (EBM) to a usual #classifier with #softmax. So it turns that in this usual classifier hiding the EBM.
Our key observation in this work is that one can slightly re-interpret the logits obtained from
In their result, they show that approach gives more adversarial robustness and for generated images maximize class confidence than its classified. It also gives more unify the density of confidence classes of all data. And of course, it can generate pictures. Interesting result by math trick!
paper: http://arxiv.org/abs/1912.03263
tweet: http://twitter.com/DavidDuvenaud/status/1204143678865866752
github: https://github.com/wgrathwohl/JEM
Classifiers are secretly energy-based models! Every softmax giving
p(c|x) has an unused degree of freedom, which we use to compute the input density p(x). This makes classifiers into #generative models without changing the architecture.The authors did math tricks to the joint Energy-Based Model (EBM) to a usual #classifier with #softmax. So it turns that in this usual classifier hiding the EBM.
Our key observation in this work is that one can slightly re-interpret the logits obtained from
fθ to define p(x, y) and p(x) as well. Without changing fθ, one can re-use the logits to define an energy-based model of the joint distribution of data point x and labels y. The normalizing constant cancels out, yielding the standard Softmax parameterization. Thus, we have found a generative model hidden within every standard discriminative model!In their result, they show that approach gives more adversarial robustness and for generated images maximize class confidence than its classified. It also gives more unify the density of confidence classes of all data. And of course, it can generate pictures. Interesting result by math trick!
paper: http://arxiv.org/abs/1912.03263
tweet: http://twitter.com/DavidDuvenaud/status/1204143678865866752
github: https://github.com/wgrathwohl/JEM
{kind=link}
Story of Parisian ODS Breakfasts (and tips for setting up one at your city)
ODS breakfasts are informal regular meetings of data science enthusiasts to discuss professional themes as long with personal ones. It is like coffee break after a conference but without any conference.
Link: https://medium.com/@isprokin/ods-breakfast-is-coming-to-your-city-paris-and-562b1244febd
P.S. please press the clap button in the bottom of medium article to give the article 50 claps, to help promoting data breakfasts.
ODS breakfasts are informal regular meetings of data science enthusiasts to discuss professional themes as long with personal ones. It is like coffee break after a conference but without any conference.
Link: https://medium.com/@isprokin/ods-breakfast-is-coming-to-your-city-paris-and-562b1244febd
P.S. please press the clap button in the bottom of medium article to give the article 50 claps, to help promoting data breakfasts.
Medium
ODS breakfast is coming to your city! Paris, and…
…it depends on you!
#NLP #News (by Sebastian Ruder):
* 2020 NLP wish lists
* #HuggingFace + #fastai
* #NeurIPS 2019
* #GPT2 things
* #ML Interviews
blog post: http://newsletter.ruder.io/archive/211277
* 2020 NLP wish lists
* #HuggingFace + #fastai
* #NeurIPS 2019
* #GPT2 things
* #ML Interviews
blog post: http://newsletter.ruder.io/archive/211277
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (many people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts.
BETO: Spanish BERT
#BETO trained on a big Spanish corpus (3B number of tokens).
Similar to a BERT-Base & was trained with the Whole Word Masking technique.
Weight available for tensorflow & pytorch (cased & uncased versions)
blog post: https://medium.com/dair-ai/beto-spanish-bert-420e4860d2c6
github: https://github.com/dccuchile/beto
#BETO trained on a big Spanish corpus (3B number of tokens).
Similar to a BERT-Base & was trained with the Whole Word Masking technique.
Weight available for tensorflow & pytorch (cased & uncased versions)
blog post: https://medium.com/dair-ai/beto-spanish-bert-420e4860d2c6
github: https://github.com/dccuchile/beto
{kind=link}
Driverless DeLorean drifting
#Stanford researchers taught autonomous car driving AI to drift to handle hazardous conditions better.
Link: https://news.stanford.edu/2019/12/20/autonomous-delorean-drives-sideways-move-forward/
#Autonomous #selfdriving #RL #CV #DL #DeLorean
#Stanford researchers taught autonomous car driving AI to drift to handle hazardous conditions better.
Link: https://news.stanford.edu/2019/12/20/autonomous-delorean-drives-sideways-move-forward/
#Autonomous #selfdriving #RL #CV #DL #DeLorean
Becoming an Independent Researcher and getting published in ICLR with spotlight
* It is possible to get published as an independent researcher, but it is really HARD.
* Now you need a top tier publication (ACL/EMNLP/CVPR/ICCV/ICLR/NeurIPS or ICML paper) to get accepted into PhD program.
* Mind acceptance rate of 20% and keep on grinding.
Link: https://medium.com/@andreas_madsen/becoming-an-independent-researcher-and-getting-published-in-iclr-with-spotlight-c93ef0b39b8b
#Academia #PhD #conference #learning
* It is possible to get published as an independent researcher, but it is really HARD.
* Now you need a top tier publication (ACL/EMNLP/CVPR/ICCV/ICLR/NeurIPS or ICML paper) to get accepted into PhD program.
* Mind acceptance rate of 20% and keep on grinding.
Link: https://medium.com/@andreas_madsen/becoming-an-independent-researcher-and-getting-published-in-iclr-with-spotlight-c93ef0b39b8b
#Academia #PhD #conference #learning
Medium
Becoming an Independent Researcher and getting published in ICLR with spotlight
Why I became an Independent Researcher, why you should avoid it, and advice for those who make the difficult choice anyway.
top podcast episodes from 2k19 by @lexfridman:
⚫️ on nature:
Glenn Villeneuve on @joerogan #1395 | link
⚫️ on perception:
Donald Hoffman on @SamHarrisOrg's Making Sense #178 | link
⚫️ on physics:
Garrett Lisi on @EricRWeinstein's The Portal #15 | link
⚫️ on consciousness:
Philip Goff on @seanmcarroll's Mindscape #71 | link
⚫️ on nature:
Glenn Villeneuve on @joerogan #1395 | link
⚫️ on perception:
Donald Hoffman on @SamHarrisOrg's Making Sense #178 | link
⚫️ on physics:
Garrett Lisi on @EricRWeinstein's The Portal #15 | link
⚫️ on consciousness:
Philip Goff on @seanmcarroll's Mindscape #71 | link
{kind=link}
SberQuAD – Russian Reading Comprehension Dataset: Description and Analysis
#SberQuAD – a large scale analog of #Stanford #SQuAD in the Russian language – is a valuable resource that has not been properly presented to the scientific community.
SberQuAD creators generally followed a procedure described by the SQuAD authors, which resulted in the similarly high lexical overlap between questions and sentences with answers.
paper: https://arxiv.org/abs/1912.09723
link to SDSJ Task B dataset: http://files.deeppavlov.ai/datasets/sber_squad-v1.1.tar.gz
#SberQuAD – a large scale analog of #Stanford #SQuAD in the Russian language – is a valuable resource that has not been properly presented to the scientific community.
SberQuAD creators generally followed a procedure described by the SQuAD authors, which resulted in the similarly high lexical overlap between questions and sentences with answers.
paper: https://arxiv.org/abs/1912.09723
link to SDSJ Task B dataset: http://files.deeppavlov.ai/datasets/sber_squad-v1.1.tar.gz
{kind=link}
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday (tomorrow) at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 3 to 7 people.
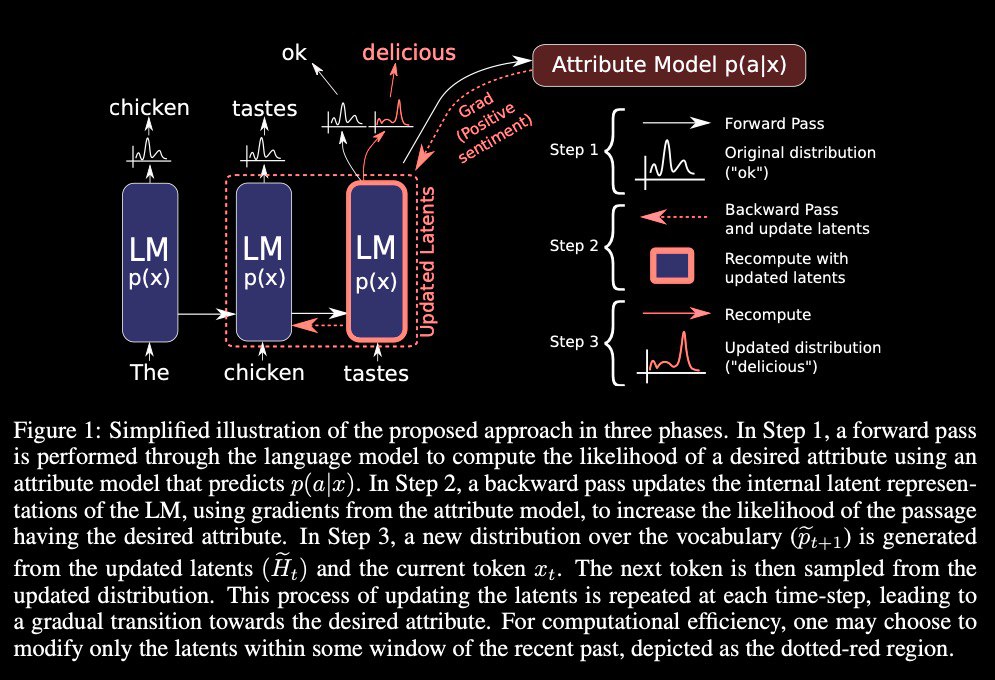
Uber AI Plug and Play Language Model (PPLM)
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
#nlp #lm #languagemodeling #uber #pplm
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
#nlp #lm #languagemodeling #uber #pplm
{kind=link}
10 ML & NLP Research Highlights of 2019
by Sebastian Ruder @ huggingface
The full list of highlights:
* Universal unsupervised pretraining
* Lottery tickets
* The Neural Tangent Kernel
* Unsupervised multilingual learning
* More robust benchmarks
* ML and NLP for science
* Fixing decoding errors in NLG
* Augmenting pretrained models
* Efficient and long-range Transformers
* More reliable analysis methods
blogpost: https://ruder.io/research-highlights-2019/
by Sebastian Ruder @ huggingface
The full list of highlights:
* Universal unsupervised pretraining
* Lottery tickets
* The Neural Tangent Kernel
* Unsupervised multilingual learning
* More robust benchmarks
* ML and NLP for science
* Fixing decoding errors in NLG
* Augmenting pretrained models
* Efficient and long-range Transformers
* More reliable analysis methods
blogpost: https://ruder.io/research-highlights-2019/
{kind=link}
📚Guest post on great example of book abandonment at GoodReads
An excellent new article from Gwern on analyzing abandoned (hard to finish, hard to read) books on Goodreads. This write up includes step by step instructions with source code, even the way he parsed the data from the website without an API.
It’s a shame analysis like this does not come from an online book subscription service like Bookmate or MyBook. They have vastly superior datasets and many able data scientists. I am quite sure amazon kindle team does prepare internal reports like that for some evil business purposes, but that’s a whole different story.
During my time at video game database company RAWG.io we’ve compiled ‘most abandoned’ and ‘most addictive’ reports for video games.
Do you make a popular service with valuable user behavior data? Funny data analysis reports are a good way to get some attention to your product. Take a lead from Pornhub, they are great at publicizing their data.
Link: https://www.gwern.net/GoodReads
Pornhub Insights: https://www.pornhub.com/insights/
—
This is a guest post by Samat Galimov, who writes about technology, programming and management in Russian on @ctodaily.
#DataAnalysis #GoodReads #statistics #greatstats #talkingnumbers
An excellent new article from Gwern on analyzing abandoned (hard to finish, hard to read) books on Goodreads. This write up includes step by step instructions with source code, even the way he parsed the data from the website without an API.
It’s a shame analysis like this does not come from an online book subscription service like Bookmate or MyBook. They have vastly superior datasets and many able data scientists. I am quite sure amazon kindle team does prepare internal reports like that for some evil business purposes, but that’s a whole different story.
During my time at video game database company RAWG.io we’ve compiled ‘most abandoned’ and ‘most addictive’ reports for video games.
Do you make a popular service with valuable user behavior data? Funny data analysis reports are a good way to get some attention to your product. Take a lead from Pornhub, they are great at publicizing their data.
Link: https://www.gwern.net/GoodReads
Pornhub Insights: https://www.pornhub.com/insights/
—
This is a guest post by Samat Galimov, who writes about technology, programming and management in Russian on @ctodaily.
#DataAnalysis #GoodReads #statistics #greatstats #talkingnumbers
gwern.net
The Most ‘Abandoned’ Books on GoodReads
Which books on GoodReads are most difficult to finish? Estimating
proportions in December 2019 gives an entirely different result than
absolute counts.
proportions in December 2019 gives an entirely different result than
absolute counts.
Robust breast cancer detection in mammography and digital breast tomosynthesis using annotation-efficient deep learning approach
ArXiV: https://arxiv.org/abs/1912.11027
#Cancer #BreastCancer #DL #CV #biolearning
ArXiV: https://arxiv.org/abs/1912.11027
#Cancer #BreastCancer #DL #CV #biolearning
{kind=link}
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday (tomorrow) at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 7 to 11 people.
👍1