
ProteinNet: a standardized data set for machine learning of protein structure
Link: https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-019-2932-0
Github: https://github.com/aqlaboratory/proteinnet
#biolearning #medical #dl
Link: https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-019-2932-0
Github: https://github.com/aqlaboratory/proteinnet
#biolearning #medical #dl
BioMed Central
ProteinNet: a standardized data set for machine learning of protein structure - BMC Bioinformatics
Background Rapid progress in deep learning has spurred its application to bioinformatics problems including protein structure prediction and design. In classic machine learning problems like computer vision, progress has been driven by standardized data sets…
The 2019 AI Index report!
Stanford University Human-Centered Artificial Intelligence released an annual report about the state of #AI this year. 160 pages of text with various metrics and measurements. Good to read with a cup of coffee ;)
TL;DR by TheVerge in the picture but inside report more interesting!
site of the report: https://hai.stanford.edu/ai-index/2019
Stanford University Human-Centered Artificial Intelligence released an annual report about the state of #AI this year. 160 pages of text with various metrics and measurements. Good to read with a cup of coffee ;)
TL;DR by TheVerge in the picture but inside report more interesting!
site of the report: https://hai.stanford.edu/ai-index/2019
{kind=link}
A Deep Neural Network's Loss Surface Contains Every Low-dimensional Pattern
New work from #DeepMind built in top of Loss Landscape Sightseeing with Multi-Point Optimization
ArXiV: https://arxiv.org/abs/1912.07559
Predecessor’s github: https://github.com/universome/loss-patterns
New work from #DeepMind built in top of Loss Landscape Sightseeing with Multi-Point Optimization
ArXiV: https://arxiv.org/abs/1912.07559
Predecessor’s github: https://github.com/universome/loss-patterns
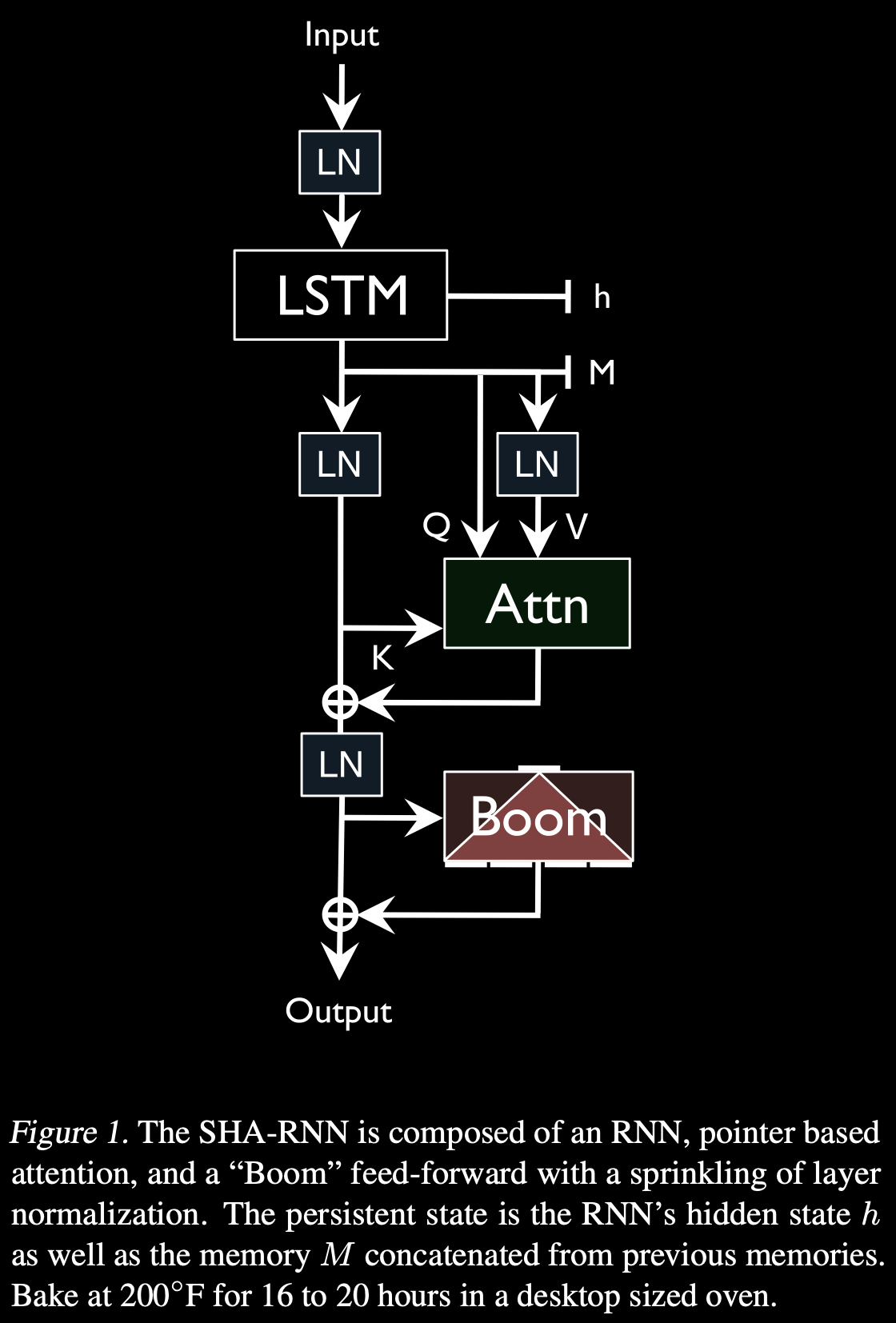
Single Headed Attention RNN
tl;dr: stop thinking with your (#attention) head :kekeke:
* obtain strong results on a byte level #languageModeling dataset (enwik8) in under 24 hours on a single GPU (12GB Titan V)
* support long-range dependencies (up to 5000 tokens) without increasing compute time or memory usage substantially by using a simpler attention mechanism
* avoid the fragile training process required by standard #Transformer models such as a long warmup
* back off toward a standard #LSTM allowing you to drop retained memory states (needed for a Transformer model) if memory becomes a major constraint
* provide a smaller model that features only standard components such as the LSTM, single-headed attention, and feed-forward modules such that they can easily be productionized using existing optimized tools and exported to various formats (i.e. ONNX)
paper: https://arxiv.org/abs/1911.11423
code: https://github.com/Smerity/sha-rnn
tweet: https://twitter.com/Smerity/status/1199529360954257408?s=20
tl;dr: stop thinking with your (#attention) head :kekeke:
* obtain strong results on a byte level #languageModeling dataset (enwik8) in under 24 hours on a single GPU (12GB Titan V)
* support long-range dependencies (up to 5000 tokens) without increasing compute time or memory usage substantially by using a simpler attention mechanism
* avoid the fragile training process required by standard #Transformer models such as a long warmup
* back off toward a standard #LSTM allowing you to drop retained memory states (needed for a Transformer model) if memory becomes a major constraint
* provide a smaller model that features only standard components such as the LSTM, single-headed attention, and feed-forward modules such that they can easily be productionized using existing optimized tools and exported to various formats (i.e. ONNX)
paper: https://arxiv.org/abs/1911.11423
code: https://github.com/Smerity/sha-rnn
tweet: https://twitter.com/Smerity/status/1199529360954257408?s=20
{kind=link}
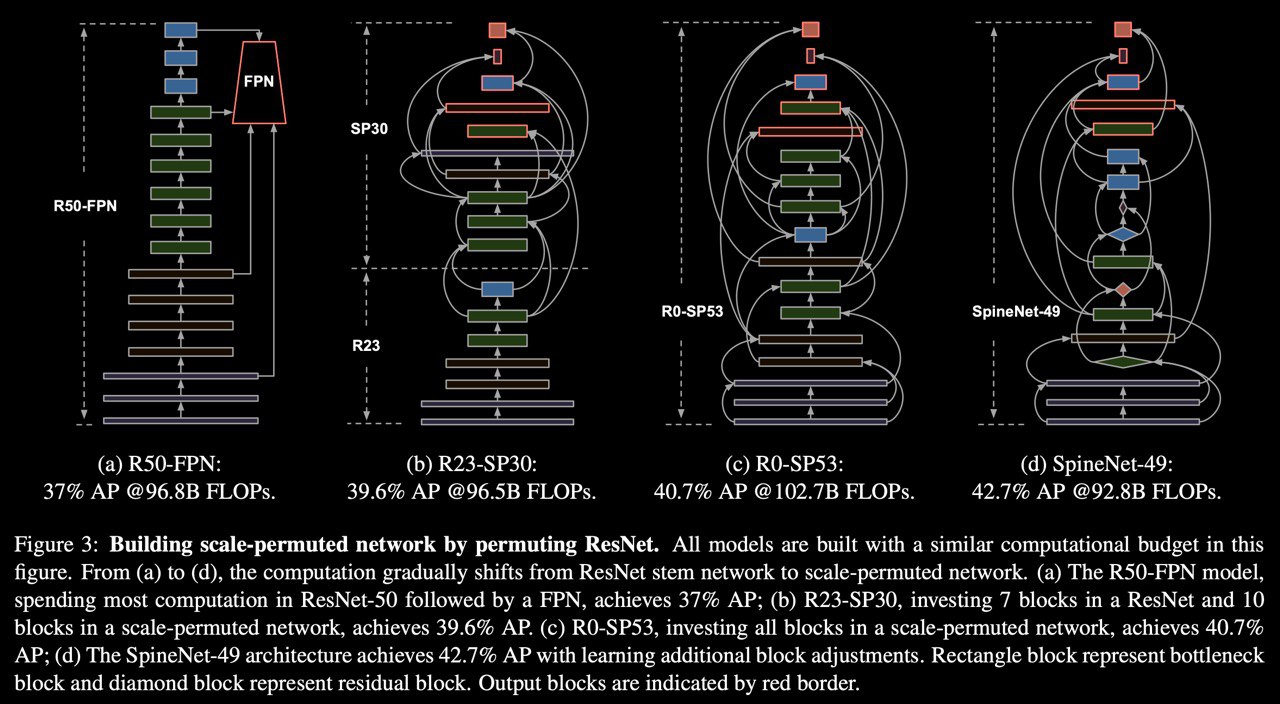
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
Abstract: CNN typically encodes an input image into a series of intermediate features with decreasing resolutions. While this structure is suited to classification tasks, it does not perform well for tasks requiring simultaneous recognition and localization (e.g., object detection). The encoder-decoder architectures are proposed to resolve this by applying a decoder network onto a backbone model designed for classification tasks. In this paper, we argue that encoder-decoder architecture is ineffective in generating strong multi-scale features because of the scale-decreased backbone. We propose SpineNet, a backbone with scale-permuted intermediate features and cross-scale connections that are learned on an object detection task by Neural Architecture Search. SpineNet achieves the SOTA performance of a one-stage object detector on COCO with 60% less computation and outperforms ResNet-FPN counterparts by 6% AP. SpineNet architecture can transfer to classification tasks, achieving 6% top-1 accuracy improvement on a challenging iNaturalist fine-grained dataset.
So, by Google's beloved method of creating a new SOTA, there is a new one! They just permute ResNet layers by NAS with adding resample cross-scale connections for correct connection scales output between layers. It seems that no need FPN cause the whole backbone is FPN. They train from scratch on RetinaNet just replace ResNet backbone with SpineNet and get SOTA. On two-stage detectors, there is the same result by replacing the backbone with SpineNet. If you want just classify something with that backbone it is performed very well too. So new architecture for any application!
Good job.
paper: https://arxiv.org/abs/1912.05027
code: Very wanted, but not release yet
#CV #ObjectDetection #GoogleResearch #NAS #SOTA
Abstract: CNN typically encodes an input image into a series of intermediate features with decreasing resolutions. While this structure is suited to classification tasks, it does not perform well for tasks requiring simultaneous recognition and localization (e.g., object detection). The encoder-decoder architectures are proposed to resolve this by applying a decoder network onto a backbone model designed for classification tasks. In this paper, we argue that encoder-decoder architecture is ineffective in generating strong multi-scale features because of the scale-decreased backbone. We propose SpineNet, a backbone with scale-permuted intermediate features and cross-scale connections that are learned on an object detection task by Neural Architecture Search. SpineNet achieves the SOTA performance of a one-stage object detector on COCO with 60% less computation and outperforms ResNet-FPN counterparts by 6% AP. SpineNet architecture can transfer to classification tasks, achieving 6% top-1 accuracy improvement on a challenging iNaturalist fine-grained dataset.
So, by Google's beloved method of creating a new SOTA, there is a new one! They just permute ResNet layers by NAS with adding resample cross-scale connections for correct connection scales output between layers. It seems that no need FPN cause the whole backbone is FPN. They train from scratch on RetinaNet just replace ResNet backbone with SpineNet and get SOTA. On two-stage detectors, there is the same result by replacing the backbone with SpineNet. If you want just classify something with that backbone it is performed very well too. So new architecture for any application!
Good job.
paper: https://arxiv.org/abs/1912.05027
code: Very wanted, but not release yet
#CV #ObjectDetection #GoogleResearch #NAS #SOTA
{kind=link}
ODS breakfast in Paris! 🇫🇷 As an exception, because of the manifestations, this Saturday, we meet at 9:45 at Malongo Café, 50 Rue Saint-André des Arts. We can have lunch after that as well. See you tomorrow.
New tutorial on QA task
The T5 team competed against T5 in a "pub quiz" on (context-free) questions from the TriviaQA/NQ validation sets.
Result: team got 20% right; T5 got 35%.
Colab link: https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb
Source: twitter
#NLU #NLP #Colab #Tutorial #QA
The T5 team competed against T5 in a "pub quiz" on (context-free) questions from the TriviaQA/NQ validation sets.
Result: team got 20% right; T5 got 35%.
Colab link: https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb
Source: twitter
#NLU #NLP #Colab #Tutorial #QA
Your Classifier is Secretly an Energy-Based Model and You Should Treat it Like One
Classifiers are secretly energy-based models! Every softmax giving
The authors did math tricks to the joint Energy-Based Model (EBM) to a usual #classifier with #softmax. So it turns that in this usual classifier hiding the EBM.
Our key observation in this work is that one can slightly re-interpret the logits obtained from
In their result, they show that approach gives more adversarial robustness and for generated images maximize class confidence than its classified. It also gives more unify the density of confidence classes of all data. And of course, it can generate pictures. Interesting result by math trick!
paper: http://arxiv.org/abs/1912.03263
tweet: http://twitter.com/DavidDuvenaud/status/1204143678865866752
github: https://github.com/wgrathwohl/JEM
Classifiers are secretly energy-based models! Every softmax giving
p(c|x) has an unused degree of freedom, which we use to compute the input density p(x). This makes classifiers into #generative models without changing the architecture.The authors did math tricks to the joint Energy-Based Model (EBM) to a usual #classifier with #softmax. So it turns that in this usual classifier hiding the EBM.
Our key observation in this work is that one can slightly re-interpret the logits obtained from
fθ to define p(x, y) and p(x) as well. Without changing fθ, one can re-use the logits to define an energy-based model of the joint distribution of data point x and labels y. The normalizing constant cancels out, yielding the standard Softmax parameterization. Thus, we have found a generative model hidden within every standard discriminative model!In their result, they show that approach gives more adversarial robustness and for generated images maximize class confidence than its classified. It also gives more unify the density of confidence classes of all data. And of course, it can generate pictures. Interesting result by math trick!
paper: http://arxiv.org/abs/1912.03263
tweet: http://twitter.com/DavidDuvenaud/status/1204143678865866752
github: https://github.com/wgrathwohl/JEM
{kind=link}
Story of Parisian ODS Breakfasts (and tips for setting up one at your city)
ODS breakfasts are informal regular meetings of data science enthusiasts to discuss professional themes as long with personal ones. It is like coffee break after a conference but without any conference.
Link: https://medium.com/@isprokin/ods-breakfast-is-coming-to-your-city-paris-and-562b1244febd
P.S. please press the clap button in the bottom of medium article to give the article 50 claps, to help promoting data breakfasts.
ODS breakfasts are informal regular meetings of data science enthusiasts to discuss professional themes as long with personal ones. It is like coffee break after a conference but without any conference.
Link: https://medium.com/@isprokin/ods-breakfast-is-coming-to-your-city-paris-and-562b1244febd
P.S. please press the clap button in the bottom of medium article to give the article 50 claps, to help promoting data breakfasts.
Medium
ODS breakfast is coming to your city! Paris, and…
…it depends on you!
#NLP #News (by Sebastian Ruder):
* 2020 NLP wish lists
* #HuggingFace + #fastai
* #NeurIPS 2019
* #GPT2 things
* #ML Interviews
blog post: http://newsletter.ruder.io/archive/211277
* 2020 NLP wish lists
* #HuggingFace + #fastai
* #NeurIPS 2019
* #GPT2 things
* #ML Interviews
blog post: http://newsletter.ruder.io/archive/211277
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (many people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts.
BETO: Spanish BERT
#BETO trained on a big Spanish corpus (3B number of tokens).
Similar to a BERT-Base & was trained with the Whole Word Masking technique.
Weight available for tensorflow & pytorch (cased & uncased versions)
blog post: https://medium.com/dair-ai/beto-spanish-bert-420e4860d2c6
github: https://github.com/dccuchile/beto
#BETO trained on a big Spanish corpus (3B number of tokens).
Similar to a BERT-Base & was trained with the Whole Word Masking technique.
Weight available for tensorflow & pytorch (cased & uncased versions)
blog post: https://medium.com/dair-ai/beto-spanish-bert-420e4860d2c6
github: https://github.com/dccuchile/beto
{kind=link}
Driverless DeLorean drifting
#Stanford researchers taught autonomous car driving AI to drift to handle hazardous conditions better.
Link: https://news.stanford.edu/2019/12/20/autonomous-delorean-drives-sideways-move-forward/
#Autonomous #selfdriving #RL #CV #DL #DeLorean
#Stanford researchers taught autonomous car driving AI to drift to handle hazardous conditions better.
Link: https://news.stanford.edu/2019/12/20/autonomous-delorean-drives-sideways-move-forward/
#Autonomous #selfdriving #RL #CV #DL #DeLorean
Becoming an Independent Researcher and getting published in ICLR with spotlight
* It is possible to get published as an independent researcher, but it is really HARD.
* Now you need a top tier publication (ACL/EMNLP/CVPR/ICCV/ICLR/NeurIPS or ICML paper) to get accepted into PhD program.
* Mind acceptance rate of 20% and keep on grinding.
Link: https://medium.com/@andreas_madsen/becoming-an-independent-researcher-and-getting-published-in-iclr-with-spotlight-c93ef0b39b8b
#Academia #PhD #conference #learning
* It is possible to get published as an independent researcher, but it is really HARD.
* Now you need a top tier publication (ACL/EMNLP/CVPR/ICCV/ICLR/NeurIPS or ICML paper) to get accepted into PhD program.
* Mind acceptance rate of 20% and keep on grinding.
Link: https://medium.com/@andreas_madsen/becoming-an-independent-researcher-and-getting-published-in-iclr-with-spotlight-c93ef0b39b8b
#Academia #PhD #conference #learning
Medium
Becoming an Independent Researcher and getting published in ICLR with spotlight
Why I became an Independent Researcher, why you should avoid it, and advice for those who make the difficult choice anyway.
top podcast episodes from 2k19 by @lexfridman:
⚫️ on nature:
Glenn Villeneuve on @joerogan #1395 | link
⚫️ on perception:
Donald Hoffman on @SamHarrisOrg's Making Sense #178 | link
⚫️ on physics:
Garrett Lisi on @EricRWeinstein's The Portal #15 | link
⚫️ on consciousness:
Philip Goff on @seanmcarroll's Mindscape #71 | link
⚫️ on nature:
Glenn Villeneuve on @joerogan #1395 | link
⚫️ on perception:
Donald Hoffman on @SamHarrisOrg's Making Sense #178 | link
⚫️ on physics:
Garrett Lisi on @EricRWeinstein's The Portal #15 | link
⚫️ on consciousness:
Philip Goff on @seanmcarroll's Mindscape #71 | link
{kind=link}
SberQuAD – Russian Reading Comprehension Dataset: Description and Analysis
#SberQuAD – a large scale analog of #Stanford #SQuAD in the Russian language – is a valuable resource that has not been properly presented to the scientific community.
SberQuAD creators generally followed a procedure described by the SQuAD authors, which resulted in the similarly high lexical overlap between questions and sentences with answers.
paper: https://arxiv.org/abs/1912.09723
link to SDSJ Task B dataset: http://files.deeppavlov.ai/datasets/sber_squad-v1.1.tar.gz
#SberQuAD – a large scale analog of #Stanford #SQuAD in the Russian language – is a valuable resource that has not been properly presented to the scientific community.
SberQuAD creators generally followed a procedure described by the SQuAD authors, which resulted in the similarly high lexical overlap between questions and sentences with answers.
paper: https://arxiv.org/abs/1912.09723
link to SDSJ Task B dataset: http://files.deeppavlov.ai/datasets/sber_squad-v1.1.tar.gz
{kind=link}
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday (tomorrow) at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 3 to 7 people.
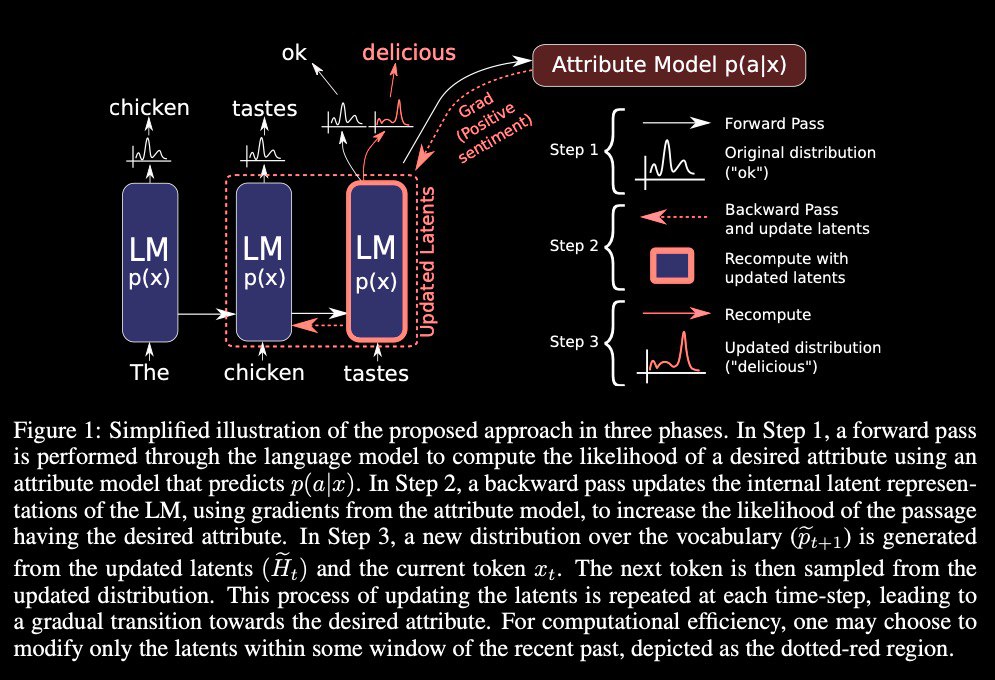
Uber AI Plug and Play Language Model (PPLM)
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
#nlp #lm #languagemodeling #uber #pplm
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
#nlp #lm #languagemodeling #uber #pplm
{kind=link}