
Movement Pruning: Adaptive Sparsity by Fine-Tuning
Victor Sanh, Thomas Wolf, Alexander M. Rush
Hugging Face, Cornell University
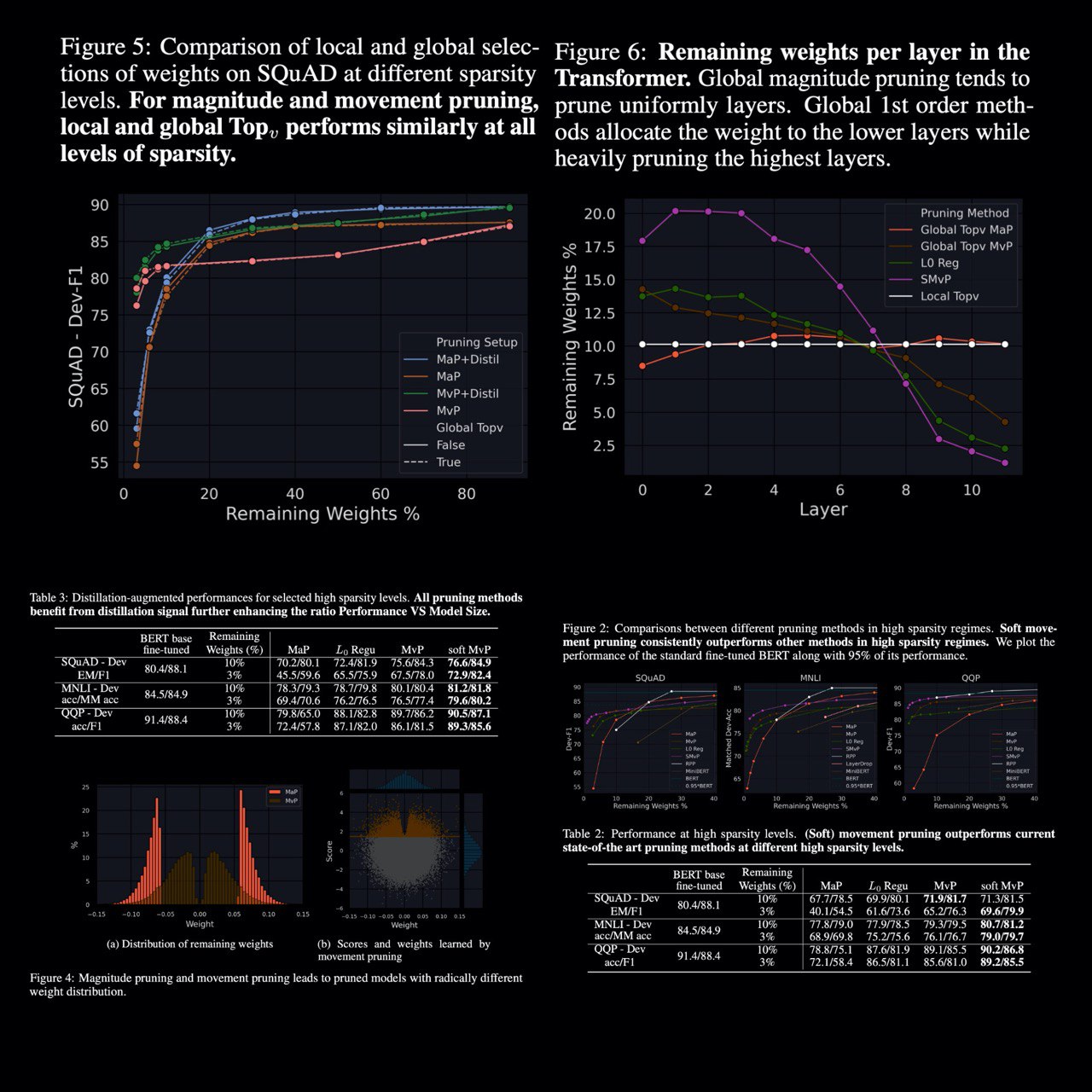
The authors consider the case of pruning of pretrained models for task-specific fine-tuning and compare zeroth- and first-order pruning methods. They show that a simple method for weight pruning based on straight-through gradients is effective for this task and that it adapts using a first-order importance score.
They apply this movement pruning to a transformer-based architecture and empirically show that their method consistently yields strong improvements over existing methods in high-sparsity regimes. The analysis demonstrates how this approach adapts to the fine-tuning regime in a way that magnitude pruning cannot.
In future work, it would also be interesting to leverage group-sparsity inducing penalties to remove entire columns or filters. In this setup, they would associate a score to a group of weights (a column or a row for instance). In the transformer architecture, it would give a systematic way to perform feature selection and remove entire columns of the embedding matrix.
paper: https://arxiv.org/abs/2005.07683
#nlp #pruning #sparsity #transfer #learning
Victor Sanh, Thomas Wolf, Alexander M. Rush
Hugging Face, Cornell University
The authors consider the case of pruning of pretrained models for task-specific fine-tuning and compare zeroth- and first-order pruning methods. They show that a simple method for weight pruning based on straight-through gradients is effective for this task and that it adapts using a first-order importance score.
They apply this movement pruning to a transformer-based architecture and empirically show that their method consistently yields strong improvements over existing methods in high-sparsity regimes. The analysis demonstrates how this approach adapts to the fine-tuning regime in a way that magnitude pruning cannot.
In future work, it would also be interesting to leverage group-sparsity inducing penalties to remove entire columns or filters. In this setup, they would associate a score to a group of weights (a column or a row for instance). In the transformer architecture, it would give a systematic way to perform feature selection and remove entire columns of the embedding matrix.
paper: https://arxiv.org/abs/2005.07683
#nlp #pruning #sparsity #transfer #learning
{kind=link}
Do Adversarially Robust ImageNet Models Transfer Better?
TLDR - Yes.
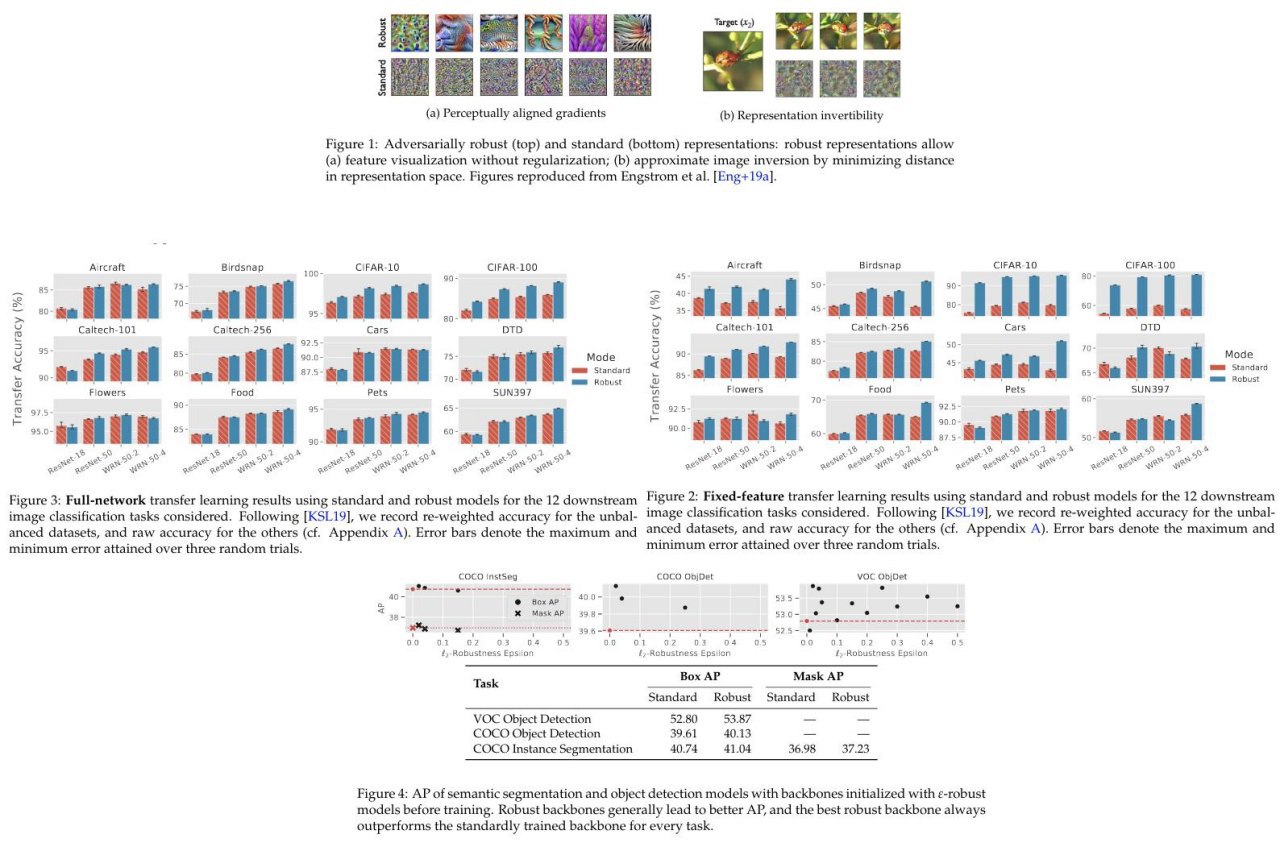
Authors decide to check will adversarial trained network performed better on transfer learning tasks despite on worst accuracy on the trained dataset (ImageNet of course). And it is true.
They tested this idea on a frozen pre-trained feature extractor and trained only linear classifier that outperformed classic counterpart. And they tested on a full unfrozen fine-tuned network, that outperformed too on transfer learning tasks.
On pre-train task they use the adversarial robustness prior, that refers to a model’s invariance to small (often imperceptible) perturbations of its inputs.
They show also that such an approach gives better future representation properties of the networks.
They did many experiments (14 pages of graphics) and an ablation study.
paper: https://arxiv.org/abs/2007.08489
code: https://github.com/Microsoft/robust-models-transfer
#transfer_learning #SOTA #adversarial
TLDR - Yes.
Authors decide to check will adversarial trained network performed better on transfer learning tasks despite on worst accuracy on the trained dataset (ImageNet of course). And it is true.
They tested this idea on a frozen pre-trained feature extractor and trained only linear classifier that outperformed classic counterpart. And they tested on a full unfrozen fine-tuned network, that outperformed too on transfer learning tasks.
On pre-train task they use the adversarial robustness prior, that refers to a model’s invariance to small (often imperceptible) perturbations of its inputs.
They show also that such an approach gives better future representation properties of the networks.
They did many experiments (14 pages of graphics) and an ablation study.
paper: https://arxiv.org/abs/2007.08489
code: https://github.com/Microsoft/robust-models-transfer
#transfer_learning #SOTA #adversarial
{kind=link}