
Ruslan Salakhutdinov, Apple AI leader, thoughts on deep learning:
https://www.technologyreview.com/s/603912/apples-ai-director-heres-how-to-supercharge-deep-learning/
#apple #deeplearning #theory
https://www.technologyreview.com/s/603912/apples-ai-director-heres-how-to-supercharge-deep-learning/
#apple #deeplearning #theory
MIT Technology Review
Apple’s AI Director: Here’s How to Supercharge Deep Learning
Apple’s director of artificial intelligence, Ruslan Salakhutdinov, believes that the deep neural networks that have produced spectacular results in recent years could be supercharged in coming years by the addition of memory, attention, and general knowledge.…
Can Global Semantic Context Improve Neural Language Models?
New article by #Apple Frameworks Natural Language Processing Team
https://machinelearning.apple.com/2018/09/27/can-global-semantic-context-improve-neural-language-models.html
#nlp
New article by #Apple Frameworks Natural Language Processing Team
https://machinelearning.apple.com/2018/09/27/can-global-semantic-context-improve-neural-language-models.html
#nlp
Apple Machine Learning Research
Can Global Semantic Context Improve Neural Language Models?
Entering text on your iPhone, discovering news articles you might enjoy, finding out answers to questions you may have, and many other…
Optimizing Siri on HomePod in Far‑Field Settings
New post by #Apple ML team
https://machinelearning.apple.com/2018/12/03/optimizing-siri-on-homepod-in-far-field-settings.html
#Siri #DL #homeassistant
New post by #Apple ML team
https://machinelearning.apple.com/2018/12/03/optimizing-siri-on-homepod-in-far-field-settings.html
#Siri #DL #homeassistant
Apple Machine Learning Research
Optimizing Siri on HomePod in Far‑Field Settings
The typical audio environment for HomePod has many challenges — echo, reverberation, and noise. Unlike Siri on iPhone, which operates close…
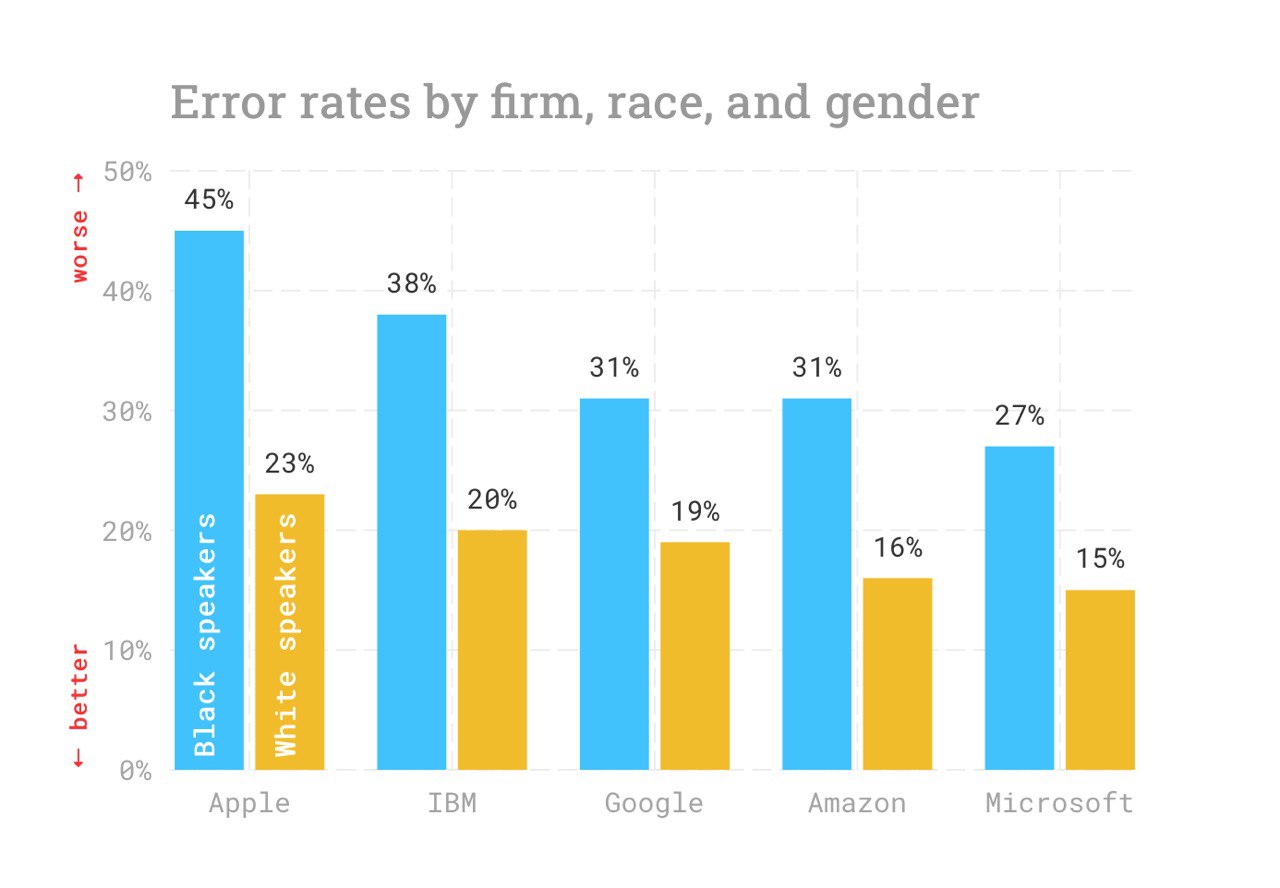
Racial Disparities in Automated Speech Recognition
To no surprise, speech recognition tools have #bias due to the lack of diversity in the datasets. Group of explorers addressed that issue and provided their’s research results as a paper and #reproducible research repo.
Project link: https://fairspeech.stanford.edu
Paper: https://www.pnas.org/cgi/doi/10.1073/pnas.1915768117
Github: https://github.com/stanford-policylab/asr-disparities
#speechrecognition #voice #audiolearning #dl #microsoft #google #apple #ibm #amazon
To no surprise, speech recognition tools have #bias due to the lack of diversity in the datasets. Group of explorers addressed that issue and provided their’s research results as a paper and #reproducible research repo.
Project link: https://fairspeech.stanford.edu
Paper: https://www.pnas.org/cgi/doi/10.1073/pnas.1915768117
Github: https://github.com/stanford-policylab/asr-disparities
#speechrecognition #voice #audiolearning #dl #microsoft #google #apple #ibm #amazon
{kind=link}
News on new Macbook Pro 13:
* M1 Apple chip with built in stuff for ML — but anyway you won't build models on the laptop
* Max 16 Gb RAM — so you won't be able to open more tabs in Chrome / Safari
* 100% recycled alluminium — good for nature
* Improved microphones and camera — collegues will see better picture of you and listen to your cats meowing clearer
And still no reasons to update if you are doing any DS.
#Apple
* M1 Apple chip with built in stuff for ML — but anyway you won't build models on the laptop
* Max 16 Gb RAM — so you won't be able to open more tabs in Chrome / Safari
* 100% recycled alluminium — good for nature
* Improved microphones and camera — collegues will see better picture of you and listen to your cats meowing clearer
And still no reasons to update if you are doing any DS.
#Apple
Forwarded from Machinelearning
Matrix3D — модель, предлагающая решение сразу нескольких задач в рамках единой архитектуры: оценку положения камер, предсказание глубины и генерацию новых ракурсов.
Всю эту красоту обеспечивает модифицированный диффузионный трансформер, который обрабатывает изображения, параметры камер и карты глубины как взаимосвязанные модальности. Он не только упрощает традиционный пайплайн (нет зависимостей от отдельных алгоритмов SfM или MVS), но и повышает точность за счет уникальной оптимизации.
Ключевая особенность Matrix3D — маскированное обучение, позаимствованное из методов MAE. Модель тренируется на частично заполненных данных: парах «изображение-поза» или «изображение-глубина». При этом модель учится «достраивать» недостающие модальности, что позволяет комбинировать входы и выходы во время инференса. Например, можно добавить карту глубины с физического датчика или сгенерировать новые ракурсы на основе всего двух изображений.
Результаты тестов с задачей оценки поз на датасете CO3D Matrix3D обходят специализированные методы (RayDiffusion): точность определения положения камеры достигает 96,3% против 92,4% у конкурентов.
В синтезе видов модель демонстрирует PSNR 20,45 против 19,22 у SyncDreamer, а в оценке глубины — AbsRel 0,036 против 0,064 у Metric3D. При этом Matrix3D не требует отдельных моделей для каждой задачи, все решается в рамках одной модели.
Практическая ценность модели — в ее адаптивности. Например, для 3D-реконструкции из одного кадра Matrix3D сначала генерирует недостающие ракурсы, оценивает их позы и глубину, а затем оптимизирует сцену через 3D Gaussian Splatting.
Для работы с несколькими кадрами без известных поз модель сама восстанавливает параметры камер, что раньше требовало отдельного этапа с COLMAP. Все это реализовано в репозитории с готовыми скриптами — от синтеза видов до полной реконструкции.
Конечно, есть нюансы: качество облаков точек пока уступает другим методам (GeoMVSNet). Но даже имеющиеся результаты достаточны для инициализации 3DGS, а главное — весь процесс занимает несколько минут на одной RTX 3090. Для сравнения: CAT3D, хотя и точнее в синтезе, требует 16х A100 и оптимизации под каждую сцену.
@ai_machinelearning_big_data
#AI #ML #Photogrammetry #Matrix3D #Apple
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍4🔥4❤1
Forwarded from Анализ данных (Data analysis)
Apple внезапно опубликовала исследование, которое разоблачает популярные LLM с "цепочкой размышлений" (Chain-of-Thought) — такие как Gemini 2.5 Pro, OpenAI o3 и DeepSeek R1.
📌 Что тестировали?
Логические задачи:
• башни Ханоя (100+ шагов!)
• загадка про волка, козу и капусту
• головоломки с правилами и условиями
И всё это — с усложнением.
💥 Результаты:
— 🔁 Модели не думают, а вспоминают
Они не решают задачу шаг за шагом, а ищут похожие примеры в своей базе знаний. Это имитация мышления, а не само мышление.
— 🤯 "Переосмысление" вредит
Если задача простая, модель находит верный ответ — и… продолжает «думать» дальше, усложняя всё и случайно портя решение.
— 🧠 Больше размышлений ≠ лучше результат
Дать больше токенов и времени на размышления не помогает. На сложных задачах модели просто сдаются быстрее. Даже "бесконечный" бюджет не спасает.
— 🧪 Few-shot примеры не работают
Даже если расписать пошаговое решение и дать примеры — модель всё равно ломается, если задача ей незнакома.
— 🏗 Модели обожают Ханой, но ненавидят загадки
Башни Ханоя решаются идеально даже на 100+ шагов.
А вот в простой задаче с козой и капустой — модели сдаются на 4-м шаге. Почему? Ханой — в датасетах, загадки про реку — нет.
🧠 Почему LLM не справляются с Ханойскими башнаями при большом числе дисков
Модели вроде Sonnet 3.7, DeepSeek R1 и o3-mini не могут правильно решать башни Ханоя, если дисков больше 13 — и вот почему:
📏 Немного математики:
• Чтобы решить башни Ханоя, нужно минимум 2ⁿ − 1 ходов
• Один ход — это примерно 10 токенов (формат: «переместить диск X с A на B»)
• А значит, для 15 дисков нужно ~**327,670 токенов** только на вывод шагов
🧱 Лимиты моделей:
| Модель | Лимит токенов | Макс. число дисков (без размышлений) |
|--------------|----------------|---------------------------------------|
| DeepSeek R1 | 64k | 12
| o3-mini | 100k | 13
| Sonnet 3.7 | 128k | 13
И это без учёта reasoning (внутренних размышлений), которые модель делает перед финальным ответом.
🔍 Что реально происходит:
• Модели не могут вывести все шаги, если дисков слишком много
• При >13 дисках они просто пишут что-то вроде:
> *"Из-за большого количества шагов я опишу метод, а не приведу все 32 767 действий..."*
• Некоторые модели (например, Sonnet) перестают "думать" уже после 7 дисков — они просто описывают алгоритм и переходят к финальному ответу без вычислений
🎲 А теперь представим, что модель угадывает каждый шаг с точностью 99.99%
На задаче с 15 дисками (32767 ходов) ошибка почти неизбежна — чистая математика:
даже 0.01% ошибок на токенах *экспоненциально* накапливаются
🍏 Интересно, что Apple выпустила это исследование за день до WWDC 2025.
Подколка конкурентам? А завтра, может, и своё покажут. 🤔
📎 Исследование: https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf
@data_analysis_ml
#AI #LLM #AGI #Apple #WWDC2025 #PromptEngineering #NeuralNetworks
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
❤5🔥5👍4