
Reformer: The Efficient Transformer to #ICLR2020
tl;dr: #Reformer is a technical optimization of the original #Transformer, takes up less memory & reads more quickly
propose 3 improvements:
* reversible layers enable storing only a single copy of activations in the whole model, so the N factor disappears (where n – count of layers)
* splitting activations inside feed-forward layers & processing them in chunks removes the dff factor & saves memory inside feed-forward layers
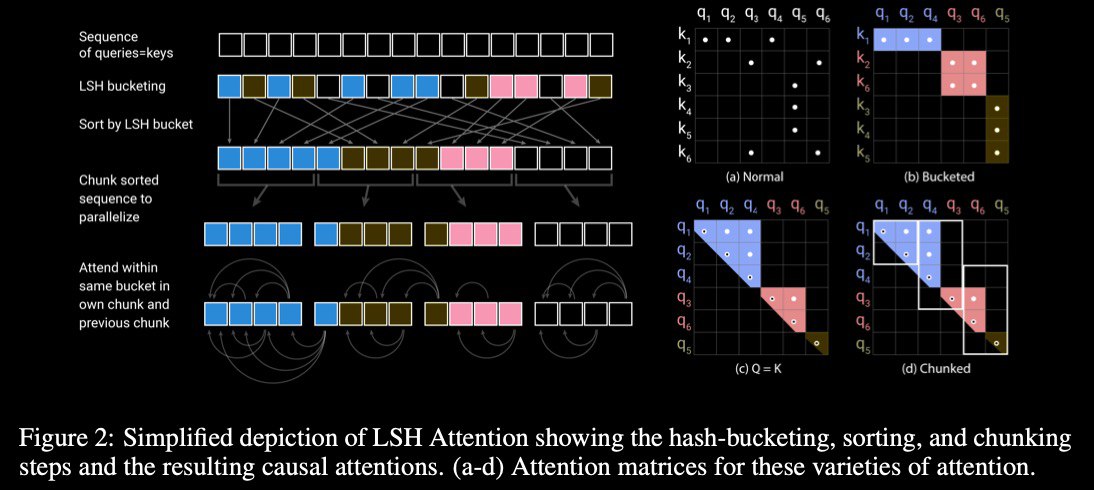
* approximate attention computation based on locality-sensitive hashing (#LSH) replaces the O(L**2) factor in attention layers with O(L*log(L)) & so allows operating on long sequences (where L – sequence size)
Query and Keys in the Transformer can be considered one matrix, not separate.
paper: https://arxiv.org/abs/2001.04451
github: https://github.com/google/trax/tree/master/trax/models/reformer
blog post: https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
tl;dr: #Reformer is a technical optimization of the original #Transformer, takes up less memory & reads more quickly
propose 3 improvements:
* reversible layers enable storing only a single copy of activations in the whole model, so the N factor disappears (where n – count of layers)
* splitting activations inside feed-forward layers & processing them in chunks removes the dff factor & saves memory inside feed-forward layers
* approximate attention computation based on locality-sensitive hashing (#LSH) replaces the O(L**2) factor in attention layers with O(L*log(L)) & so allows operating on long sequences (where L – sequence size)
Query and Keys in the Transformer can be considered one matrix, not separate.
paper: https://arxiv.org/abs/2001.04451
github: https://github.com/google/trax/tree/master/trax/models/reformer
blog post: https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
{kind=link}