
The effectiveness of MAE pre-pretraining for billion-scale pretraining
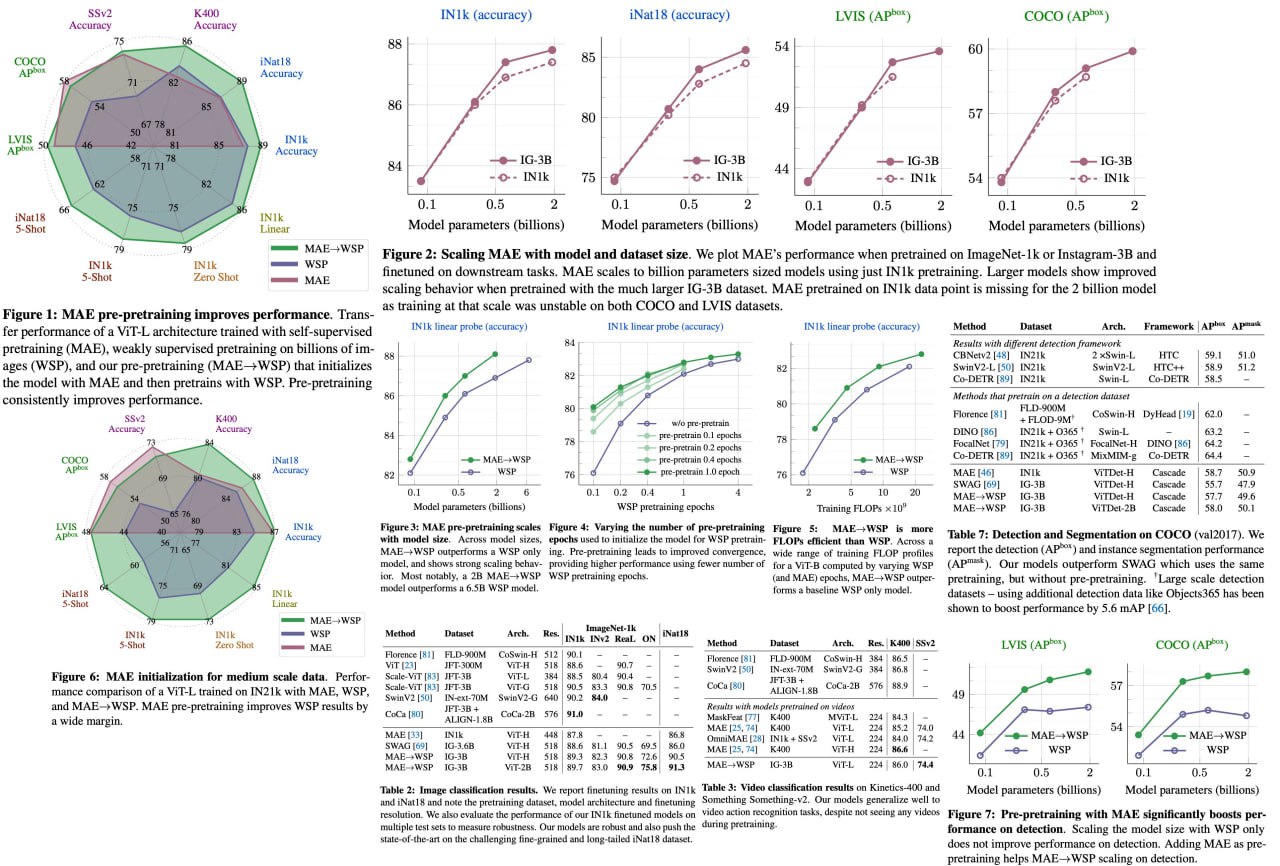
Revolutionizing the current pretrain-then-finetune paradigm of computer vision, this research has introduced an innovative pre-pretraining stage. Utilizing the Masked Autoencoder (MAE) technique for model initialization, this pre-pretraining strategy scales with the size of both the model and the data. This makes it an ideal tool for training next-generation foundation models, even on the grandest scales.
The robustness of our pre-pretraining technique is demonstrated by consistent improvement in model convergence and downstream transfer performance across diverse model scales and dataset sizes. The authors measured the effectiveness of pre-pretraining on a wide array of visual recognition tasks, and the results have been promising. The ielargest model achieved unprecedented results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%), underlining the tremendous potential of proper model initialization, even when handling web-scale pretraining with billions of images.
Paper link: https://arxiv.org/abs/2303.13496
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mae-pretrain
#deeplearning #cv #pretraining #selfsupervisedlearning
Revolutionizing the current pretrain-then-finetune paradigm of computer vision, this research has introduced an innovative pre-pretraining stage. Utilizing the Masked Autoencoder (MAE) technique for model initialization, this pre-pretraining strategy scales with the size of both the model and the data. This makes it an ideal tool for training next-generation foundation models, even on the grandest scales.
The robustness of our pre-pretraining technique is demonstrated by consistent improvement in model convergence and downstream transfer performance across diverse model scales and dataset sizes. The authors measured the effectiveness of pre-pretraining on a wide array of visual recognition tasks, and the results have been promising. The ielargest model achieved unprecedented results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%), underlining the tremendous potential of proper model initialization, even when handling web-scale pretraining with billions of images.
Paper link: https://arxiv.org/abs/2303.13496
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mae-pretrain
#deeplearning #cv #pretraining #selfsupervisedlearning
{kind=link}
👍7❤🔥3🔥2
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
In a recent breakthrough, a novel approach for learning highly semantic image representations has been introduced that eschews the need for hand-crafted data augmentations. The strategy, known as Image-based Joint-Embedding Predictive Architecture (I-JEPA), offers a refreshing, non-generative pathway to self-supervised learning from images. The concept underpinning I-JEPA is deceptively simple, yet incredibly powerful: it takes a single context block from an image and predicts the representations of various target blocks within the same image.
I-JEPA's core design principle - its masking strategy - plays a pivotal role in shaping the system's semantic prowess. The key is to sample target blocks at a sufficiently large, semantic scale while using a context block that provides ample, spatially distributed information. When integrated with Vision Transformers, I-JEPA exhibits impressive scalability. To illustrate, a ViT-Huge/14 model was trained on ImageNet using just 16 A100 GPUs in under 72 hours, delivering robust performance across a wide spectrum of tasks, including linear classification, object counting, and depth prediction.
Paper link: https://arxiv.org/abs/2301.08243
Code link: https://github.com/facebookresearch/ijepa
Blogpost link: https://ai.facebook.com/blog/yann-lecun-ai-model-i-jepa/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ijepa
#deeplearning #cv #selfsupervisedlearning
In a recent breakthrough, a novel approach for learning highly semantic image representations has been introduced that eschews the need for hand-crafted data augmentations. The strategy, known as Image-based Joint-Embedding Predictive Architecture (I-JEPA), offers a refreshing, non-generative pathway to self-supervised learning from images. The concept underpinning I-JEPA is deceptively simple, yet incredibly powerful: it takes a single context block from an image and predicts the representations of various target blocks within the same image.
I-JEPA's core design principle - its masking strategy - plays a pivotal role in shaping the system's semantic prowess. The key is to sample target blocks at a sufficiently large, semantic scale while using a context block that provides ample, spatially distributed information. When integrated with Vision Transformers, I-JEPA exhibits impressive scalability. To illustrate, a ViT-Huge/14 model was trained on ImageNet using just 16 A100 GPUs in under 72 hours, delivering robust performance across a wide spectrum of tasks, including linear classification, object counting, and depth prediction.
Paper link: https://arxiv.org/abs/2301.08243
Code link: https://github.com/facebookresearch/ijepa
Blogpost link: https://ai.facebook.com/blog/yann-lecun-ai-model-i-jepa/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ijepa
#deeplearning #cv #selfsupervisedlearning
{kind=link}
👍9🔥4❤3😁3