
Hello!
Gentle reminder in regards of second but not less historical Munich Data Science #meetup on Dec 5th jointly with BMW Welt. 160 RSVPed already, don’t miss opportunity
Evgenii +4916091541827
https://www.meetup.com/Munich-Data-Science/events/266659553
Gentle reminder in regards of second but not less historical Munich Data Science #meetup on Dec 5th jointly with BMW Welt. 160 RSVPed already, don’t miss opportunity
Evgenii +4916091541827
https://www.meetup.com/Munich-Data-Science/events/266659553
Meetup
Login to Meetup | Meetup
Find groups that host online or in person events and meet people in your local community who share your interests.
MMM: Multi-stage Multi-task Learning for Multi-choice Reading Comprehension
This method involves two sequential stages:
* coarse-tuning stage using out-of-domain datasets
* multitask learning stage using a larger in-domain dataset to help model generalize better with limited data.
Also, they propose a novel multi-step attention network (MAN) as the top-level classifier for the above task.
MMM demonstrate significantly advances the SOTA on four representative
Dialogue Multiple-Choice QA datasets
paper: https://arxiv.org/abs/1910.00458
#nlp #dialog #qa
This method involves two sequential stages:
* coarse-tuning stage using out-of-domain datasets
* multitask learning stage using a larger in-domain dataset to help model generalize better with limited data.
Also, they propose a novel multi-step attention network (MAN) as the top-level classifier for the above task.
MMM demonstrate significantly advances the SOTA on four representative
Dialogue Multiple-Choice QA datasets
paper: https://arxiv.org/abs/1910.00458
#nlp #dialog #qa
{kind=link}
What GPT-2 thinks of the future
Link: https://worldin.economist.com/article/17521/edition2020artificial-intelligence-predicts-future
#NLU #NLP #NLG #GPT2
Link: https://worldin.economist.com/article/17521/edition2020artificial-intelligence-predicts-future
#NLU #NLP #NLG #GPT2
Free eBook from Stanford: Introduction to Applied Linear Algebra – Vectors, Matrices, and Least Squares
Base material you need to understand how neural networks and other #ML algorithms work.
Link: https://web.stanford.edu/~boyd/vmls/
#Stanford #MOOC #WhereToStart #free #ebook #algebra #linalg #NN
Base material you need to understand how neural networks and other #ML algorithms work.
Link: https://web.stanford.edu/~boyd/vmls/
#Stanford #MOOC #WhereToStart #free #ebook #algebra #linalg #NN
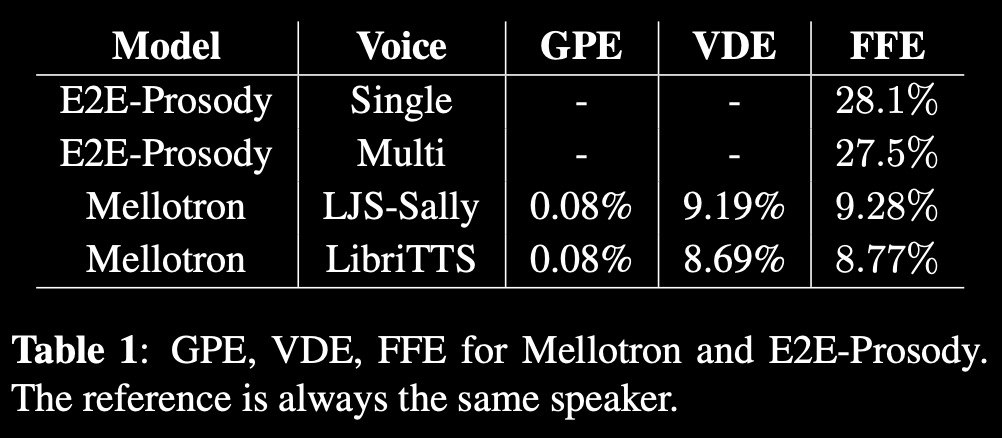
mellotron by #NVIDIA
It's a multispeaker #voice synthesis model based on #Tacotron 2 GST that can make a voice emote and sing without emotive or singing training data.
By explicitly conditioning on rhythm and continuous pitch contours from an audio signal or music score, Mellotron is able to generate #speech in a variety of styles ranging from reading speech to expressive speech, from slow drawls to rap and from monotonous voice to singing voice.
Unlike other methods, Mellotron trains using only read speech data without alignments between text and audio.
Site: https://nv-adlr.github.io/Mellotron
Paper: https://arxiv.org/abs/1910.11997
Git: https://github.com/NVIDIA/mellotron
It's a multispeaker #voice synthesis model based on #Tacotron 2 GST that can make a voice emote and sing without emotive or singing training data.
By explicitly conditioning on rhythm and continuous pitch contours from an audio signal or music score, Mellotron is able to generate #speech in a variety of styles ranging from reading speech to expressive speech, from slow drawls to rap and from monotonous voice to singing voice.
Unlike other methods, Mellotron trains using only read speech data without alignments between text and audio.
Site: https://nv-adlr.github.io/Mellotron
Paper: https://arxiv.org/abs/1910.11997
Git: https://github.com/NVIDIA/mellotron
{kind=link}
New RL competition from Codeforces & collaborators
Competition involves developing a strategy / agent to win in platformer game.
Provided baseline solution contains a simple strategy — running towards nearest weapon, then to the nearest enemy, constantly shooting.
Link: competition site.
Competition involves developing a strategy / agent to win in platformer game.
Provided baseline solution contains a simple strategy — running towards nearest weapon, then to the nearest enemy, constantly shooting.
Link: competition site.
russianaicup.ru
Russian AI Cup
Привет! Теперь Russian AI Cup будет проходить на платформе All Cups от VK! Твой аккаунт и результаты предыдущих чемпионатов уже перенесены. Так что переходи по ссылке, и вперед — открывать новые горизонты!
Great community event by OpenDataScience in Dubai 🏝🏙
The first Data Fest in Dubai.
Check the agenda and don't miss the event!
- Top talks from renowned experts in their fields
- Lots of new insights, skills and know-how
- Best networking with the professional community
Location: Hult International Business School
Link: https://fest.ai/dubai/
#event #dubai #ml #meta #dl
The first Data Fest in Dubai.
Check the agenda and don't miss the event!
- Top talks from renowned experts in their fields
- Lots of new insights, skills and know-how
- Best networking with the professional community
Location: Hult International Business School
Link: https://fest.ai/dubai/
#event #dubai #ml #meta #dl
fest.ai
December 7, Data Fest Dubai
Community Data Science Conference in Dubai, Hult IBS
Forwarded from Machinelearning
nbdev: use Jupyter Notebooks for everything
https://www.fast.ai//2019/12/02/nbdev/
github: https://github.com/fastai/nbdev/
https://www.fast.ai//2019/12/02/nbdev/
github: https://github.com/fastai/nbdev/
Machinelearning
nbdev: use Jupyter Notebooks for everything https://www.fast.ai//2019/12/02/nbdev/ github: https://github.com/fastai/nbdev/
This is a forward from an independent channel run by our fellow engineers.
@ai_machinelearning_big_data
@ai_machinelearning_big_data
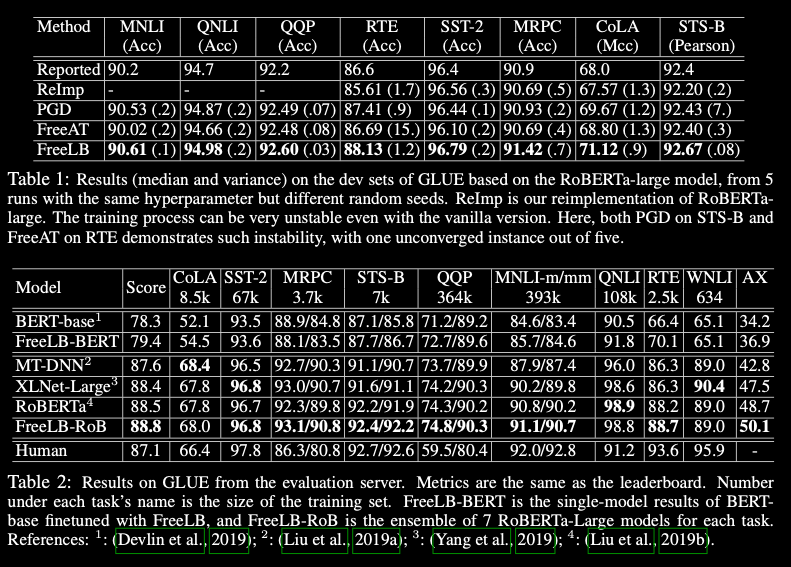
FreeLB: Enhanced Adversarial Training for Language Understanding
The authors propose a novel adversarial training algorithm – FreeLB, that promotes higher robustness and invariance in the embedding space, by adding adversarial perturbations to word embeddings and minimizing the resultant adversarial risk inside different regions around input samples, applied to Transformer-based models for NLU & commonsense reasoning tasks.
Experiments on the GLUE benchmark show that when applied only to the finetuning stage, it is able to improve the overall test scores:
* of BERT-based model from 78.3 -> 79.4
* RoBERTa-large model from 88.5 -> 88.8
The proposed approach achieves SOTA single-model test accuracies of 85.44% and 67.75% on ARC-Easy and ARC-Challenge.
paper: https://arxiv.org/abs/1909.11764
#nlp #nlu #bert #adversarial #ICLR
The authors propose a novel adversarial training algorithm – FreeLB, that promotes higher robustness and invariance in the embedding space, by adding adversarial perturbations to word embeddings and minimizing the resultant adversarial risk inside different regions around input samples, applied to Transformer-based models for NLU & commonsense reasoning tasks.
Experiments on the GLUE benchmark show that when applied only to the finetuning stage, it is able to improve the overall test scores:
* of BERT-based model from 78.3 -> 79.4
* RoBERTa-large model from 88.5 -> 88.8
The proposed approach achieves SOTA single-model test accuracies of 85.44% and 67.75% on ARC-Easy and ARC-Challenge.
paper: https://arxiv.org/abs/1909.11764
#nlp #nlu #bert #adversarial #ICLR
{kind=link}
With new TensorBoard.dev you can share your DL/ML experiments result at tensorBoard
Link: https://blog.tensorflow.org/2019/12/introducing-tensorboarddev-new-way-to.html
#DL #ML #tensorflow #tf
Link: https://blog.tensorflow.org/2019/12/introducing-tensorboarddev-new-way-to.html
#DL #ML #tensorflow #tf
blog.tensorflow.org
Introducing TensorBoard.dev: a new way to share your ML experiment results
The TensorFlow blog contains regular news from the TensorFlow team and the community, with articles on Python, TensorFlow.js, TF Lite, TFX, and more.
How Much Over-parameterization Is Sufficient to Learn Deep ReLU Networks?
Chen et al., 2019 UCLA
arxiv.org/abs/1911.12360
The theory of deep learning is a new and fast-developing field. Recent studies suggest that huge over-parametrization of neural networks is not a bug, but a feature that allows deep NNs both to generalize and to be optimizable using simple (first-order gradient) optimization.
Chen et al. make another step into solving mysteries of deep learning, and their main results are:
1. Sharp optimization and generalization guarantees for deep ReLU networks
1. Better asymptotics that allows applying the theory to smaller networks (polylogarithmic instead of polynomial hidden size)
As authors say, "Our results push the study of over-parameterized deep neural networks towards more practical settings."
For a deep dive to a theory of deep learning, I suggest
iPavlov: github.com/deepmipt/tdl (Russian and English)
Stanford: stats385.github.io (English)
Chen et al., 2019 UCLA
arxiv.org/abs/1911.12360
The theory of deep learning is a new and fast-developing field. Recent studies suggest that huge over-parametrization of neural networks is not a bug, but a feature that allows deep NNs both to generalize and to be optimizable using simple (first-order gradient) optimization.
Chen et al. make another step into solving mysteries of deep learning, and their main results are:
1. Sharp optimization and generalization guarantees for deep ReLU networks
1. Better asymptotics that allows applying the theory to smaller networks (polylogarithmic instead of polynomial hidden size)
As authors say, "Our results push the study of over-parameterized deep neural networks towards more practical settings."
For a deep dive to a theory of deep learning, I suggest
iPavlov: github.com/deepmipt/tdl (Russian and English)
Stanford: stats385.github.io (English)
GitHub
GitHub - deeppavlov/tdl: Course "Theories of Deep Learning"
Course "Theories of Deep Learning". Contribute to deeppavlov/tdl development by creating an account on GitHub.
Forwarded from ML Trainings
Artur Kuzin tells about his participation in Kaggle Open Images 2019 in English. He got a gold medal in each of the three competitions.
In this video you will find out:
🔹Description of the dataset and its markup procedures, as well as a description of the metric and its features
🔹Architecture overview of the best models
🔹Overview of tricks and hacks from the top3 of each competition
🔹Approach for quick model training
https://youtu.be/NGnOY-AzDBg
In this video you will find out:
🔹Description of the dataset and its markup procedures, as well as a description of the metric and its features
🔹Architecture overview of the best models
🔹Overview of tricks and hacks from the top3 of each competition
🔹Approach for quick model training
https://youtu.be/NGnOY-AzDBg
YouTube
Kaggle Open Images 2019 — Artur Kuzin
Artur Kuzin tells about his participation in Kaggle Open Images 2019 in English. He got a gold medal in each of the three competitions.
In this video you will find out:
- Description of the dataset and its markup procedures, as well as a description of…
In this video you will find out:
- Description of the dataset and its markup procedures, as well as a description of…
🇳🇱We received a request to setup weekly data breakfasts at Eindhoven (Holland).
Please pm @malev if you are resident or live nearby and up for joining weekly breakfasts.
Please pm @malev if you are resident or live nearby and up for joining weekly breakfasts.
Data Science by ODS.ai 🦜 pinned «🇳🇱We received a request to setup weekly data breakfasts at Eindhoven (Holland). Please pm @malev if you are resident or live nearby and up for joining weekly breakfasts.»
Great artilce on pandas optimization
Link: https://medium.com/bigdatarepublic/advanced-pandas-optimize-speed-and-memory-a654b53be6c2
#pandas #optimization
Link: https://medium.com/bigdatarepublic/advanced-pandas-optimize-speed-and-memory-a654b53be6c2
#pandas #optimization
Medium
Advanced Pandas: Optimize speed and memory
Nowadays the Python data analysis library Pandas is widely used across the world. It started mostly as a data exploration and…
👍1
Deep Learning for Symbolic Mathematics
Abstract: Neural networks have a reputation for being better at solving statistical or approximate problems than at performing calculations or working with symbolic data. In this paper, we show that they can be surprisingly good at more elaborated tasks in mathematics, such as symbolic integration and solving differential equations. We propose a syntax for representing mathematical problems and methods for generating large datasets that can be used to train sequence-to-sequence models. We achieve results that outperform commercial Computer Algebra Systems such as Matlab or Mathematica.
They show that transformers cope surprisingly well with complex mathematical problems such as function integration and differential equations.
They adapt seq2seq models to these mathematical problems.
So they use a general transformer with 8 heads and 6 layers and Adam for the optimizer. But they present a framework to generate correct math problems to use in the dataset. Interestingly, beam search selects the right solutions for one task at high scores, which are simply alternatives to each other.
For integration, the model achieves close to 100% performance on a held-out test set, even with greedy decoding (beam size 1). This performance is consistent over the three integration datasets (FWD, BWD, and IBP). Greedy decoding (beam size 1) does not work as well for differential equations. In particular, we observe an improvement in accuracy of almost 40% when using a large beam size of 50 for second-order differential equations. Unlike in machine translation, where increasing the beam size does not necessarily increase the performance (Ott et al., 2018), we always observe significant improvements with wider beams. Typically, using a beam size of 50 provides an improvement of 8% accuracy compared to a beam size of 10. This makes sense, as increasing the beam size will provide more hypotheses, although a wider beam may displace a valid hypothesis to consider invalid ones with better log-probabilities.
The model also generalizes to integrate problems that SymPy cannot solve but has trained on problems that SymPy can.
In particular, we found that the accuracy of SymPy on the BWD test set is only 30%. Our FWD-trained model only obtains an accuracy of 17.2% on BWD. However, we observed that the FWD-trained model is sometimes able to compute the integral of functions that SymPy cannot compute. This means that by only training on functions that SymPy can integrate, the model was able to generalize to functions that SymPy cannot integrate. Table 7 presents examples of such functions with their integrals.
But the final solution to the problem is not pure end2end. Each hypothesis should be checked against the symbolic framework.
paper: https://arxiv.org/abs/1912.01412
tweet: http://twitter.com/GuillaumeLample/status/1202178956063064064
Abstract: Neural networks have a reputation for being better at solving statistical or approximate problems than at performing calculations or working with symbolic data. In this paper, we show that they can be surprisingly good at more elaborated tasks in mathematics, such as symbolic integration and solving differential equations. We propose a syntax for representing mathematical problems and methods for generating large datasets that can be used to train sequence-to-sequence models. We achieve results that outperform commercial Computer Algebra Systems such as Matlab or Mathematica.
They show that transformers cope surprisingly well with complex mathematical problems such as function integration and differential equations.
They adapt seq2seq models to these mathematical problems.
So they use a general transformer with 8 heads and 6 layers and Adam for the optimizer. But they present a framework to generate correct math problems to use in the dataset. Interestingly, beam search selects the right solutions for one task at high scores, which are simply alternatives to each other.
For integration, the model achieves close to 100% performance on a held-out test set, even with greedy decoding (beam size 1). This performance is consistent over the three integration datasets (FWD, BWD, and IBP). Greedy decoding (beam size 1) does not work as well for differential equations. In particular, we observe an improvement in accuracy of almost 40% when using a large beam size of 50 for second-order differential equations. Unlike in machine translation, where increasing the beam size does not necessarily increase the performance (Ott et al., 2018), we always observe significant improvements with wider beams. Typically, using a beam size of 50 provides an improvement of 8% accuracy compared to a beam size of 10. This makes sense, as increasing the beam size will provide more hypotheses, although a wider beam may displace a valid hypothesis to consider invalid ones with better log-probabilities.
The model also generalizes to integrate problems that SymPy cannot solve but has trained on problems that SymPy can.
In particular, we found that the accuracy of SymPy on the BWD test set is only 30%. Our FWD-trained model only obtains an accuracy of 17.2% on BWD. However, we observed that the FWD-trained model is sometimes able to compute the integral of functions that SymPy cannot compute. This means that by only training on functions that SymPy can integrate, the model was able to generalize to functions that SymPy cannot integrate. Table 7 presents examples of such functions with their integrals.
But the final solution to the problem is not pure end2end. Each hypothesis should be checked against the symbolic framework.
paper: https://arxiv.org/abs/1912.01412
tweet: http://twitter.com/GuillaumeLample/status/1202178956063064064
Twitter
Guillaume Lample
Our new paper, Deep Learning for Symbolic Mathematics, is now on arXiv arxiv.org/abs/1912.01412 We added *a lot* of new results compared to the original submission. With @f_charton (1/7)
ODS breakfast in Paris! 🇫🇷 See you this Saturday at 10:30 (many people come around 11:00, and this time because of greve, it can be more) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 4 to 10 people.
Yet another article about adversarial prints to fool face recognition
With progress on facial recognition, such prints will become more popular.
Link: https://medium.com/syncedreview/personal-invisibility-cloak-stymies-people-detectors-15bebdcc7943
#facerecognition #adversarial
With progress on facial recognition, such prints will become more popular.
Link: https://medium.com/syncedreview/personal-invisibility-cloak-stymies-people-detectors-15bebdcc7943
#facerecognition #adversarial
{kind=link}
LOGAN: Latent Optimisation for Generative Adversarial Networks
Game-theory motivated algorithm from #DeepMind improves the state-of-the-art in #GAN image generation by over 30% measured in FID.
ArXiV: https://arxiv.org/abs/1912.00953
Game-theory motivated algorithm from #DeepMind improves the state-of-the-art in #GAN image generation by over 30% measured in FID.
ArXiV: https://arxiv.org/abs/1912.00953
{kind=link}