
📹What's Hidden in a Randomly Weighted Neural Network?
Amazingly this paper finds a subnetwork with random weights in a Wide ResNet-50 that outperforms optimized weights in a ResNet-34 for ImageNet!
On the last ICLR article by Lottery Ticket Hypothesis — the authors showed that it is possible to take a trained big net, and throw out at 95% of the scales so that the rest can be learned on the same quality, starting with the same initialization.
In the follow-up Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask found out that, it is possible to leave the weight with the initialization and learn only the mask, throwing unnecessary connections from the network - so it was possible to get under 40% of the quality on the Cifar, teaching not the weight of the model, but only its structure. Similar observations were made for simple RL tasks, see Weight-Agnostic Neural Network.
However, it was not clear how much structure-only training works on normal datasets and large nets, or without the right weights.
In the article the authors for the first time start struture-only on Imagenet. For this purpose:
- It takes a bold grid aka DenseNet, weights are initialized from the "binaryized" kaiming normal (either +std, or -std instead of normal).
- For each weight, an additional scalar - score s, showing how important it is for a good prediction. On the inference we take the top-k% weights and zero out the rest.
- With fixed weights, we train the scores. The main trick is that although in the forward pass we, like in the inference, take only top-k weights, in the backward pass the gradient flows through all the scores. It is ambiguous LRD where all weights are used in the forward, and in the backward - only a small subset.
Thus we can to prune a random WideResnet50 and get 73.3% accuracy on imagenet and there will be less active weights than in Resnet34. Magic.
ArXiV: https://arxiv.org/pdf/1911.13299.pdf
YouTube explanation: https://www.youtube.com/watch?v=C6Tj8anJO-Q
via @JanRocketMan
#ImageNet #ResNet
Amazingly this paper finds a subnetwork with random weights in a Wide ResNet-50 that outperforms optimized weights in a ResNet-34 for ImageNet!
On the last ICLR article by Lottery Ticket Hypothesis — the authors showed that it is possible to take a trained big net, and throw out at 95% of the scales so that the rest can be learned on the same quality, starting with the same initialization.
In the follow-up Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask found out that, it is possible to leave the weight with the initialization and learn only the mask, throwing unnecessary connections from the network - so it was possible to get under 40% of the quality on the Cifar, teaching not the weight of the model, but only its structure. Similar observations were made for simple RL tasks, see Weight-Agnostic Neural Network.
However, it was not clear how much structure-only training works on normal datasets and large nets, or without the right weights.
In the article the authors for the first time start struture-only on Imagenet. For this purpose:
- It takes a bold grid aka DenseNet, weights are initialized from the "binaryized" kaiming normal (either +std, or -std instead of normal).
- For each weight, an additional scalar - score s, showing how important it is for a good prediction. On the inference we take the top-k% weights and zero out the rest.
- With fixed weights, we train the scores. The main trick is that although in the forward pass we, like in the inference, take only top-k weights, in the backward pass the gradient flows through all the scores. It is ambiguous LRD where all weights are used in the forward, and in the backward - only a small subset.
Thus we can to prune a random WideResnet50 and get 73.3% accuracy on imagenet and there will be less active weights than in Resnet34. Magic.
ArXiV: https://arxiv.org/pdf/1911.13299.pdf
YouTube explanation: https://www.youtube.com/watch?v=C6Tj8anJO-Q
via @JanRocketMan
#ImageNet #ResNet
arXiv.org
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Neural network pruning techniques can reduce the parameter counts of trained networks by over 90%, decreasing storage requirements and improving computational performance of inference without...
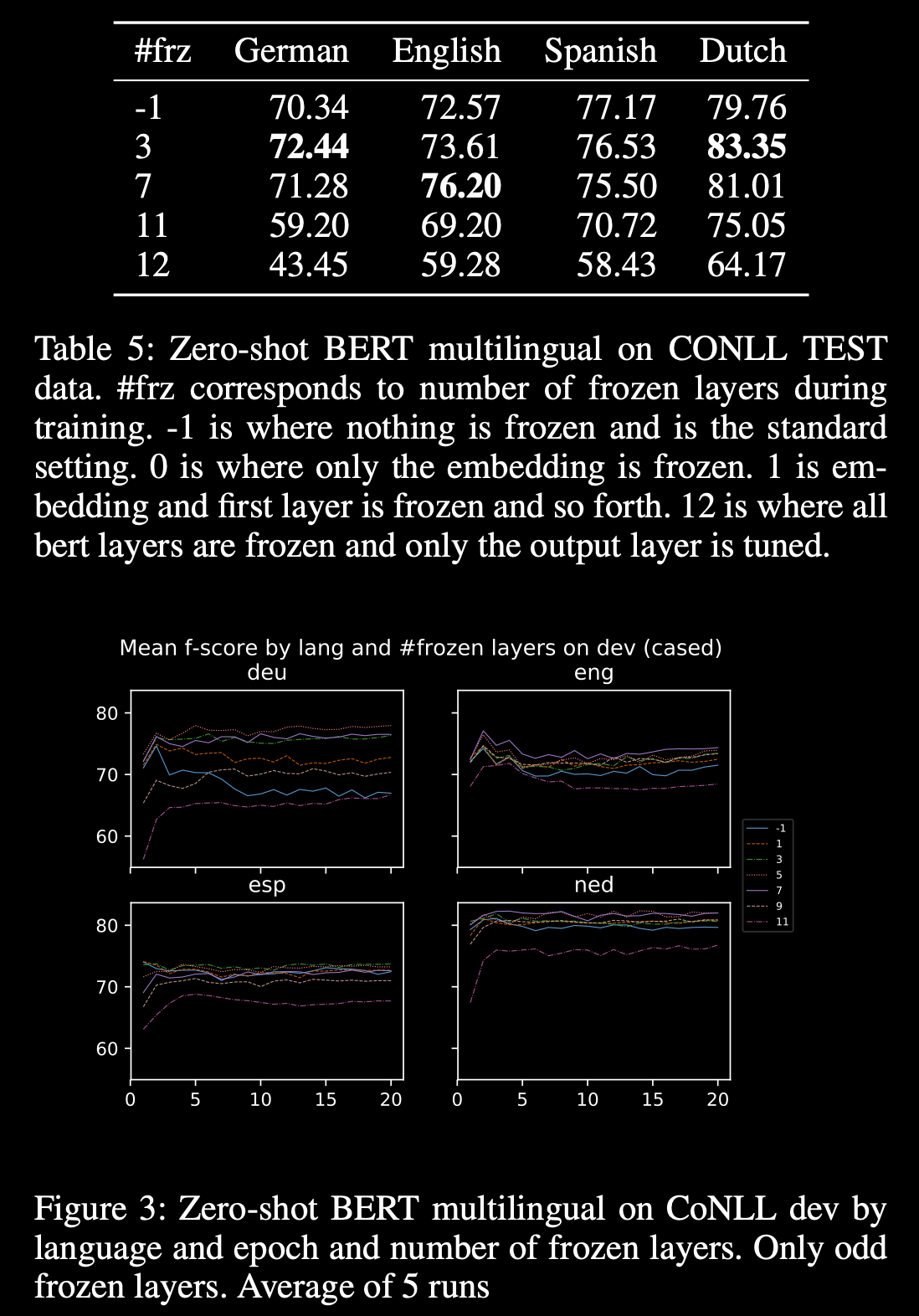
Towards Lingua Franca Named Entity Recognition with BERT
The authors present a simple and effective recipe for building #multilingual #NER systems with #BERT.
By utilizing a multilingual BERT framework, they were able to not only train a system that can perform inference on English, German, Spanish, and Dutch languages, but it performs better than the same model trained only on one language at a time, and also is able to perform 0-shot inference.
The resulting model yields #SotA results on CoNLL Spanish and Dutch, and on OntoNotes Chinese and Arabic datasets.
Also, the English trained model yields SotA results for 0-shot languages for Spanish, Dutch, and German NER, improving it by a range of 2.4F to 17.8F.
Furthermore, the runtime signature (memory/CPU/GPU) of the model is the same as the models built on single languages, significantly simplifying its life- cycle maintenance.
paper: https://arxiv.org/abs/1912.01389
The authors present a simple and effective recipe for building #multilingual #NER systems with #BERT.
By utilizing a multilingual BERT framework, they were able to not only train a system that can perform inference on English, German, Spanish, and Dutch languages, but it performs better than the same model trained only on one language at a time, and also is able to perform 0-shot inference.
The resulting model yields #SotA results on CoNLL Spanish and Dutch, and on OntoNotes Chinese and Arabic datasets.
Also, the English trained model yields SotA results for 0-shot languages for Spanish, Dutch, and German NER, improving it by a range of 2.4F to 17.8F.
Furthermore, the runtime signature (memory/CPU/GPU) of the model is the same as the models built on single languages, significantly simplifying its life- cycle maintenance.
paper: https://arxiv.org/abs/1912.01389
{kind=link}
Dream to Control: Learning Behaviors by Latent Imagination
Abstract: Learned world models summarize an agent's experience to facilitate learning complex behaviors. While learning world models from high-dimensional sensory inputs are becoming feasible through deep learning, there are many potential ways for deriving behaviors from them. We present Dreamer, a reinforcement learning agent that solves long-horizon tasks from images purely by latent imagination. We efficiently learn behaviors by propagating analytic gradients of learned state values back through trajectories imagined in the compact state space of a learned world model. On 20 challenging visual control tasks, Dreamer exceeds existing approaches in data-efficiency, computation time, and final performance.
Dreamer learns long-horizon behaviors from images purely by latent imagination. For this, it backpropagates value estimates through trajectories imagined in the compact latent space of a learned world model. Dreamer solves visual control tasks using substantially fewer episodes than strong model-free agents.
Dreamer learns a world model from past experiences that can predict the future. It then learns action and value models in its compact latent space. The value model optimizes Bellman's consistency of imagined trajectories. The action model maximizes value estimates by propagating their analytic gradients back through imagined trajectories. When interacting with the environment, it simply executes the action model.
paper: https://arxiv.org/abs/1912.01603
github: https://github.com/google-research/dreamer
site: https://danijar.com/dreamer
#RL #Dreams #Imagination #DL #GoogleBrain #DeepMind
Abstract: Learned world models summarize an agent's experience to facilitate learning complex behaviors. While learning world models from high-dimensional sensory inputs are becoming feasible through deep learning, there are many potential ways for deriving behaviors from them. We present Dreamer, a reinforcement learning agent that solves long-horizon tasks from images purely by latent imagination. We efficiently learn behaviors by propagating analytic gradients of learned state values back through trajectories imagined in the compact state space of a learned world model. On 20 challenging visual control tasks, Dreamer exceeds existing approaches in data-efficiency, computation time, and final performance.
Dreamer learns long-horizon behaviors from images purely by latent imagination. For this, it backpropagates value estimates through trajectories imagined in the compact latent space of a learned world model. Dreamer solves visual control tasks using substantially fewer episodes than strong model-free agents.
Dreamer learns a world model from past experiences that can predict the future. It then learns action and value models in its compact latent space. The value model optimizes Bellman's consistency of imagined trajectories. The action model maximizes value estimates by propagating their analytic gradients back through imagined trajectories. When interacting with the environment, it simply executes the action model.
paper: https://arxiv.org/abs/1912.01603
github: https://github.com/google-research/dreamer
site: https://danijar.com/dreamer
#RL #Dreams #Imagination #DL #GoogleBrain #DeepMind
👍1
Encoder-decoders in Transformers: a hybrid pre-trained architecture for seq2seq
by huggingface
In this post briefly goes through the (modern) history of #transformers and the comeback of the encoder-decoder architecture.
The author walk through the implementation of encoder-decoders in the transformers library, show you can use them for your projects, and give you a taste of what is coming in the next releases.
Blog: https://medium.com/huggingface/encoder-decoders-in-transformers-a-hybrid-pre-trained-architecture-for-seq2seq-af4d7bf14bb8
by huggingface
In this post briefly goes through the (modern) history of #transformers and the comeback of the encoder-decoder architecture.
The author walk through the implementation of encoder-decoders in the transformers library, show you can use them for your projects, and give you a taste of what is coming in the next releases.
Blog: https://medium.com/huggingface/encoder-decoders-in-transformers-a-hybrid-pre-trained-architecture-for-seq2seq-af4d7bf14bb8
👍1
Very cool application of GPT-2
It is a game endless generating by large GPT-2 depends of your actions which litterally anything with just words. Without any gamemaster or gamedisigner limitations) GPT-2 was fine-tuned on collection of adventures texts.
But it is work not very well, esspecially on custom setting (I try to setup cyberpunk, but it is wa a fantasy anyway sometimes))
But it is fun and very cool applications of this type of nets. And it is really awesome to be suprised each time by power of this model esspecialy in this task.
Site: http://www.aidungeon.io/
Post: https://pcc.cs.byu.edu/2019/11/21/ai-dungeon-2-creating-infinitely-generated-text-adventures-with-deep-learning-language-models/
Github: https://github.com/nickwalton/AIDungeon/
Play in colab: https://colab.research.google.com/drive/1u7flclharvMchwWHY7Ya41NKjX3dkslu#forceEdit=true&sandboxMode=true&scrollTo=FKqlSCrpS9dH
#GPT2 #NLP #NLU
It is a game endless generating by large GPT-2 depends of your actions which litterally anything with just words. Without any gamemaster or gamedisigner limitations) GPT-2 was fine-tuned on collection of adventures texts.
But it is work not very well, esspecially on custom setting (I try to setup cyberpunk, but it is wa a fantasy anyway sometimes))
But it is fun and very cool applications of this type of nets. And it is really awesome to be suprised each time by power of this model esspecialy in this task.
Site: http://www.aidungeon.io/
Post: https://pcc.cs.byu.edu/2019/11/21/ai-dungeon-2-creating-infinitely-generated-text-adventures-with-deep-learning-language-models/
Github: https://github.com/nickwalton/AIDungeon/
Play in colab: https://colab.research.google.com/drive/1u7flclharvMchwWHY7Ya41NKjX3dkslu#forceEdit=true&sandboxMode=true&scrollTo=FKqlSCrpS9dH
#GPT2 #NLP #NLU
Guide to reading articles in 202x:
1. Accept cookies
2. Block notifications
3. Deny location to website
4. Decline invitation to subscribe
5. Stop auto-playing video ads/mute sound
6. Dismiss reminder of free articles remaining
7. Shrink drop down banner
8. Click "read more"
9. Give up
1. Accept cookies
2. Block notifications
3. Deny location to website
4. Decline invitation to subscribe
5. Stop auto-playing video ads/mute sound
6. Dismiss reminder of free articles remaining
7. Shrink drop down banner
8. Click "read more"
9. Give up
Improving Transformer Models by Reordering their Sublayers
tl;dr – improve transformers by reordering their sublayers like the sandwich transformer
The authors trained random #transformer models with reordered sublayers, and find that some perform better than the baseline interleaved trans former in #language #modeling.
They observed that, on average, better models contain more self-attention #sublayers at the bottom and more feedforward sublayer at the top.
This leads them to design a new transformer stack, the sandwich transformer, which consistently improves performance over the baseline at no cost.
paper: https://ofir.io/sandwich_transformer.pdf
tl;dr – improve transformers by reordering their sublayers like the sandwich transformer
The authors trained random #transformer models with reordered sublayers, and find that some perform better than the baseline interleaved trans former in #language #modeling.
They observed that, on average, better models contain more self-attention #sublayers at the bottom and more feedforward sublayer at the top.
This leads them to design a new transformer stack, the sandwich transformer, which consistently improves performance over the baseline at no cost.
paper: https://ofir.io/sandwich_transformer.pdf
{kind=link}
Episodic Memory in Lifelong Language Learning
tl;dr – the model needs to learn from a stream of text examples without any dataset identifier.
The authors propose an episodic memory model that performs sparse experience replay and local adaptation to mitigate catastrophic forgetting in this setup. Experiments on text classification and question answering demonstrate the complementary benefits of sparse experience replay & local adaptation to allow the model to continuously learn from new datasets.
Also, they show that the space complexity of the episodic memory module can be reduced significantly (∼50-90%) by randomly choosing which examples to store in memory with a minimal decrease in performance. They consider an episodic memory component as a crucial building block of general linguistic intelligence and see the model as the first step in that direction.
paper: https://arxiv.org/abs/1906.01076
#nlp #bert #NeurIPSConf19
tl;dr – the model needs to learn from a stream of text examples without any dataset identifier.
The authors propose an episodic memory model that performs sparse experience replay and local adaptation to mitigate catastrophic forgetting in this setup. Experiments on text classification and question answering demonstrate the complementary benefits of sparse experience replay & local adaptation to allow the model to continuously learn from new datasets.
Also, they show that the space complexity of the episodic memory module can be reduced significantly (∼50-90%) by randomly choosing which examples to store in memory with a minimal decrease in performance. They consider an episodic memory component as a crucial building block of general linguistic intelligence and see the model as the first step in that direction.
paper: https://arxiv.org/abs/1906.01076
#nlp #bert #NeurIPSConf19
{kind=link}
Open invitation to student Olympiad
IT students from all over the world are invited to participate in Digital Economy International Olympiad held in Russia from January to March 2020. First two stages will held online via Stepik platform and finalists will go to Moscow at the expense of organizers to participate in the final stage and award ceremony!
Winners will be preferentially enrolled in the top Russian Universities and get job-offers from the best IT-companies.
Nominations include:
- Neurotechnology and artificial intelligence
- Data science
- Big data
- Parts of robotics and sensors
Link: https://olymp.digitaleconomy.world/index_en.html
IT students from all over the world are invited to participate in Digital Economy International Olympiad held in Russia from January to March 2020. First two stages will held online via Stepik platform and finalists will go to Moscow at the expense of organizers to participate in the final stage and award ceremony!
Winners will be preferentially enrolled in the top Russian Universities and get job-offers from the best IT-companies.
Nominations include:
- Neurotechnology and artificial intelligence
- Data science
- Big data
- Parts of robotics and sensors
Link: https://olymp.digitaleconomy.world/index_en.html
What we learned from NeurIPS 2019 data
x4 growth since 2014
21.6% acceptance rate
Takeaways:
1. No free-loader problem: Relatively few papers are submitted where none of the authors invited to participate in the review process accepted the invitation
2. Unclear how to rapidly filter papers prior to full review: Allowing for early desk rejects by ACs is unlikely to have a significant impact on reviewer load without producing inappropriate decisions. Likewise, the eagerness of reviewers to review a particular paper is not a strong signal, either.
3. No clear evidence that review quality as measured by length is lower for NeurIPS: NeurIPS is surprisingly not much different from other conferences of smaller sizes when it comes to review length.
4. Impact of engagement in rebuttal/discussion period: Overall engagement seemed to be higher than in 2018.
#Nips #NeurIPS #NIPS2019 #conference #meta
x4 growth since 2014
21.6% acceptance rate
Takeaways:
1. No free-loader problem: Relatively few papers are submitted where none of the authors invited to participate in the review process accepted the invitation
2. Unclear how to rapidly filter papers prior to full review: Allowing for early desk rejects by ACs is unlikely to have a significant impact on reviewer load without producing inappropriate decisions. Likewise, the eagerness of reviewers to review a particular paper is not a strong signal, either.
3. No clear evidence that review quality as measured by length is lower for NeurIPS: NeurIPS is surprisingly not much different from other conferences of smaller sizes when it comes to review length.
4. Impact of engagement in rebuttal/discussion period: Overall engagement seemed to be higher than in 2018.
#Nips #NeurIPS #NIPS2019 #conference #meta
{kind=link}
Low-variance Black-box Gradient Estimates for the Plackett-Luce Distribution
The authors consider models with #latent #permutations and propose control variates for the #PlackettLuce distribution. In particular, the control variates allow them to optimize #blackBox functions over permutations using stochastic gradient descent. To illustrate the approach, they consider a variety of causal structure learning tasks for continuous and discrete data.
They show that the method outperforms competitive relaxation-based optimization methods and is also applicable to non-differentiable score functions.
paper: https://arxiv.org/abs/1911.10036
tweet: https://twitter.com/bayesgroup/status/1199023536653950976?s=20
The authors consider models with #latent #permutations and propose control variates for the #PlackettLuce distribution. In particular, the control variates allow them to optimize #blackBox functions over permutations using stochastic gradient descent. To illustrate the approach, they consider a variety of causal structure learning tasks for continuous and discrete data.
They show that the method outperforms competitive relaxation-based optimization methods and is also applicable to non-differentiable score functions.
paper: https://arxiv.org/abs/1911.10036
tweet: https://twitter.com/bayesgroup/status/1199023536653950976?s=20
{kind=link}
Football performance modelling in python
An article with football game outcome analysis in #jupyter.
One of the key features to predict a football game turned out to be the best attacking player even though "A ferocious scream from the stands, a mistaken whistle from the ref’, or the shrimps on the lunch menu may jeopardise the whole outcome of the match."
Authors also highlighted improtance of amplitude of persistence diagrams as a key feature.
This is a suggested by the channel readers material. Don’t forget to thank them by giving claps 👏 on Medium and starring repository if you found a code useful.
Link: https://towardsdatascience.com/the-shape-of-football-games-1589dc4e652a
Code: https://github.com/giotto-ai/football-tda
#football #soccer #betting #readersmaterial
An article with football game outcome analysis in #jupyter.
One of the key features to predict a football game turned out to be the best attacking player even though "A ferocious scream from the stands, a mistaken whistle from the ref’, or the shrimps on the lunch menu may jeopardise the whole outcome of the match."
Authors also highlighted improtance of amplitude of persistence diagrams as a key feature.
This is a suggested by the channel readers material. Don’t forget to thank them by giving claps 👏 on Medium and starring repository if you found a code useful.
Link: https://towardsdatascience.com/the-shape-of-football-games-1589dc4e652a
Code: https://github.com/giotto-ai/football-tda
#football #soccer #betting #readersmaterial
Medium
The shape of football games
Modelling the outcome of football matches using player characteristics and topological data analysis
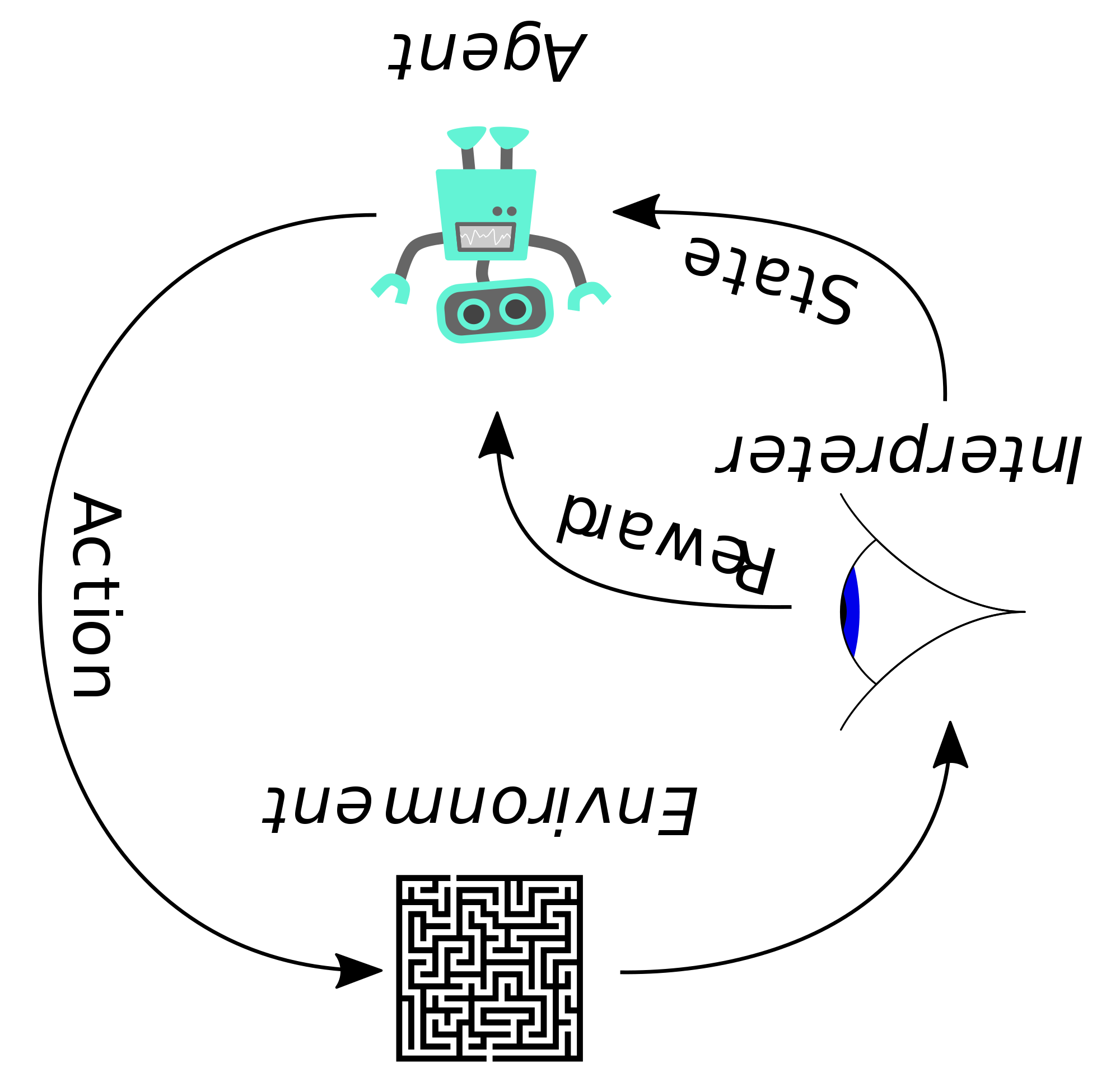
Reinforcement Learning Upside Down: Don't Predict Rewards – Just Map Them to Actions by Juergen Schmidhuber
Traditional #RL predicts rewards and uses a myriad of methods for translating those predictions into good actions. ꓶꓤ shortcuts this process, creating a direct mapping from rewards, time horizons and other inputs to actions.
Without depending on reward predictions, and without explicitly maximizing expected rewards, ꓶꓤ simply learn by gradient descent to map task specifications or commands (such as: get lots of reward within little time) to action probabilities. Its success depends on the generalization abilities of deep/recurrent neural nets. Its potential drawbacks are essentially those of traditional gradient-based learning: local minima, underfitting, overfitting, etc.
Nevertheless, experiments in a separate paper show that even them initial pilot version of ꓶꓤ can outperform traditional RL methods on certain challenging problems.
A closely related Imitate-Imitator approach is to imitate a robot, then let it learn to map its observations of the imitated behavior to its own behavior, then let it generalize, by demonstrating something new, to be imitated by the robot.
more at paper: https://arxiv.org/abs/1912.02875
Traditional #RL predicts rewards and uses a myriad of methods for translating those predictions into good actions. ꓶꓤ shortcuts this process, creating a direct mapping from rewards, time horizons and other inputs to actions.
Without depending on reward predictions, and without explicitly maximizing expected rewards, ꓶꓤ simply learn by gradient descent to map task specifications or commands (such as: get lots of reward within little time) to action probabilities. Its success depends on the generalization abilities of deep/recurrent neural nets. Its potential drawbacks are essentially those of traditional gradient-based learning: local minima, underfitting, overfitting, etc.
Nevertheless, experiments in a separate paper show that even them initial pilot version of ꓶꓤ can outperform traditional RL methods on certain challenging problems.
A closely related Imitate-Imitator approach is to imitate a robot, then let it learn to map its observations of the imitated behavior to its own behavior, then let it generalize, by demonstrating something new, to be imitated by the robot.
more at paper: https://arxiv.org/abs/1912.02875
{kind=link}
NeurIPS slides and presentations link
Link: https://slideslive.com/neurips/
Brief paper overview videos: https://nips.cc/Conferences/2019/Videos
#NeurIPS #NIPS #NIPS2019
Link: https://slideslive.com/neurips/
Brief paper overview videos: https://nips.cc/Conferences/2019/Videos
#NeurIPS #NIPS #NIPS2019
SlidesLive
NeurIPS
Neural Information Processing Systems (NeurIPS) is a multi-track machine learning and computational neuroscience conference that includes invited talks, demonstrations, symposia and oral and poster presentations of refereed papers. Following the conference…
🏆 Moscow ML Trainings meetup on the 14th of December
ML Trainings are based on Kaggle and other platform competitions and are held regularly with free attendance. Winners and top-performing participants discuss competition tasks, share their solutions, and results.
Program and the registration link - https://pao-megafon--org.timepad.ru/event/1137770/
* Note: the first talk will be in English and the rest will be in Russian
ML Trainings are based on Kaggle and other platform competitions and are held regularly with free attendance. Winners and top-performing participants discuss competition tasks, share their solutions, and results.
Program and the registration link - https://pao-megafon--org.timepad.ru/event/1137770/
* Note: the first talk will be in English and the rest will be in Russian