
🛢️Кто публикует данные по запасам нефти в США и кому верить? Во вторник вечером API (American Petroleum Institute - американский институт нефти) или объединение американских компаний нефтегазового сектора, а в среду вечером EIA или подразделение Минэнерго США. Оба агентства собирают точные данные по 90% всех компаний и прогнозируют оставшиеся 10%. Исторически их прогнозы по запасам отличаются не более, чем на 1% в 75% случаев. Поэтому их можно считать равнозначными источниками информации.
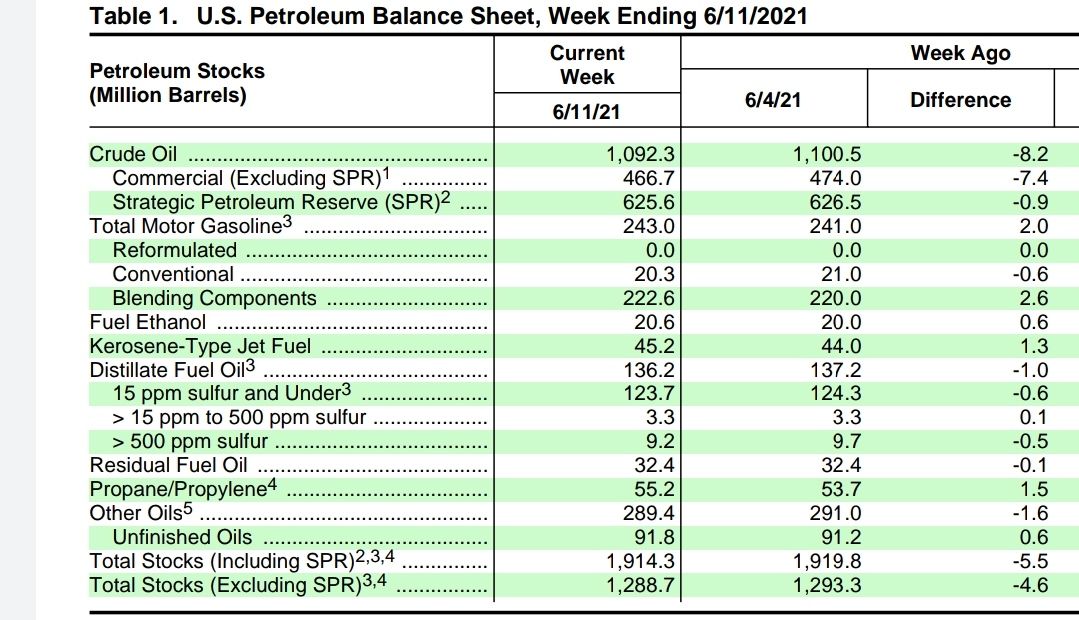
По вышедшим данным API, которые не доступны в открытом доступе, а известны только по сообщениям СМИ, запасы нефти упали на 8 млн барр., запасы нефтепродуктов выросли на 5 млн барр. По данным EIA запасы нефти упали также на 8 млн барр., а нефтепродуктов выросли на 3 млн барр., см. таблицу, что очень похоже на данные API и подтверждает нашу гипотезу о равнозначности этих источников.
Данные позитивны для рынка нефти, т.к. на прошлой неделе запасы нефтепродуктов от EIA выросли на 20 млн барр., что породило сомнение в восстановлении спроса. Но на этой неделе потребление нефтепродуктов увеличилось на 3 млн барр. в сутки.
#статистика #образование #нефть #нефтепродукты
По вышедшим данным API, которые не доступны в открытом доступе, а известны только по сообщениям СМИ, запасы нефти упали на 8 млн барр., запасы нефтепродуктов выросли на 5 млн барр. По данным EIA запасы нефти упали также на 8 млн барр., а нефтепродуктов выросли на 3 млн барр., см. таблицу, что очень похоже на данные API и подтверждает нашу гипотезу о равнозначности этих источников.
Данные позитивны для рынка нефти, т.к. на прошлой неделе запасы нефтепродуктов от EIA выросли на 20 млн барр., что породило сомнение в восстановлении спроса. Но на этой неделе потребление нефтепродуктов увеличилось на 3 млн барр. в сутки.
#статистика #образование #нефть #нефтепродукты
{kind=link}
Forwarded from Душа Питона
Богиню обучили школьной математике
Появившиеся за последние годы крупномасштабные модели обработки естественного языка оказались исключительно универсальны. Обученные на больших массивах разнообразных данных, они отлично проявляют себя и в анализе текстов, и в генерации программного кода, и в ответах на вопросы при ведении свободного диалога с пользователем. Однако стоит сочетать обычный текст с математическим, — и они уже не справляются. Задачка по геометрии школьного уровня ставит в тупик все эти сложные системы.
🔢 Количественные рассуждения (Quantitative Reasoning) требуют понимания математических символов, формул и констант, а также реальных отношений физического мира и хотя бы простейших вычислений. Всё это лежит за пределами возможностей даже таких мощных моделей как BERT или GPT-3. Многие специалисты полагали, что языковым моделям математика в принципе недоступна, или же потребует существенных изменений в их архитектуре, например, внедрения отдельных модулей для вычислений.
🧖🏼♀️ Однако на днях Google Research представили новый алгоритм Minerva (
📄 Дело в том, что в отличие от обычного текста, для математического крайне важно форматирование (в частности, взаимное расположение знаков и чисел), которое обычно стирается при подготовке данных для обучения. Создатели же Minerva, наоборот, максимально старались сохранить его.
Кроме того, для выбора правильного решения в модели используется новый метод «самосогласованности» (Self-consistency method). Он включает три шага:
1️⃣ В качестве затравки (prompt) используется цепочка размышлений. Например, вопрос:
2️⃣ В ответ на затравку модель генерирует множество альтернативных цепочек рассуждений. Среди них могут быть как имеющие «неправильные» ответы (4 или 6). Так и «правильный» — 5.
3️⃣ В конце включается специальный механизм «большинства голосов». Обычно языковые модели генерируют набор ответов на запрос и выбирают тот, который считают наиболее вероятным. Однако Minerva действует чуть иначе — она отбирает цепочку рассуждений с ответом, который появлялся чаще других.
🧾 Дообученная модель испытывалась на нескольких специализированных бенчмарках с задачами из области науки, технологий, инженерии и математики (Science, Technology, Engineering, and Mathematics, STEM). Например, бенчмарке MATH, который содержит задания по математике уровня старшей школы. С ними Minerva успешно справлялась в 50% случаев, тогда как прежние SOTA-модели оставались в пределах нескольких процентов.
Почитать подробнее: препринт в arXiv.
Пограться: демо на GitHub.
#Машинное_обучение, #Обработка_естественного_языка, #Образование
Появившиеся за последние годы крупномасштабные модели обработки естественного языка оказались исключительно универсальны. Обученные на больших массивах разнообразных данных, они отлично проявляют себя и в анализе текстов, и в генерации программного кода, и в ответах на вопросы при ведении свободного диалога с пользователем. Однако стоит сочетать обычный текст с математическим, — и они уже не справляются. Задачка по геометрии школьного уровня ставит в тупик все эти сложные системы.
🔢 Количественные рассуждения (Quantitative Reasoning) требуют понимания математических символов, формул и констант, а также реальных отношений физического мира и хотя бы простейших вычислений. Всё это лежит за пределами возможностей даже таких мощных моделей как BERT или GPT-3. Многие специалисты полагали, что языковым моделям математика в принципе недоступна, или же потребует существенных изменений в их архитектуре, например, внедрения отдельных модулей для вычислений.
🧖🏼♀️ Однако на днях Google Research представили новый алгоритм Minerva (
Минерва — римский вариант богини мудрости Афины). В его основе лежит языковая модель PaLM, в вариантах на 62 и 530 миллиардов параметров. Для понимания «языка» математики её дополнительно обучали на специально составленном датасете из 118 Гб академических статей, в которых используется математическая нотация в популярных форматах LaTeX, MathJax и др.📄 Дело в том, что в отличие от обычного текста, для математического крайне важно форматирование (в частности, взаимное расположение знаков и чисел), которое обычно стирается при подготовке данных для обучения. Создатели же Minerva, наоборот, максимально старались сохранить его.
Кроме того, для выбора правильного решения в модели используется новый метод «самосогласованности» (Self-consistency method). Он включает три шага:
1️⃣ В качестве затравки (prompt) используется цепочка размышлений. Например, вопрос:
«Три машины стояли на стоянке. Две приехали. Стало ли их больше?». И рассуждение-ответ: «Так как три машины было и две добавилось, значит 3 + 2 = 5. Следовательно, машин стало больше».2️⃣ В ответ на затравку модель генерирует множество альтернативных цепочек рассуждений. Среди них могут быть как имеющие «неправильные» ответы (4 или 6). Так и «правильный» — 5.
3️⃣ В конце включается специальный механизм «большинства голосов». Обычно языковые модели генерируют набор ответов на запрос и выбирают тот, который считают наиболее вероятным. Однако Minerva действует чуть иначе — она отбирает цепочку рассуждений с ответом, который появлялся чаще других.
🧾 Дообученная модель испытывалась на нескольких специализированных бенчмарках с задачами из области науки, технологий, инженерии и математики (Science, Technology, Engineering, and Mathematics, STEM). Например, бенчмарке MATH, который содержит задания по математике уровня старшей школы. С ними Minerva успешно справлялась в 50% случаев, тогда как прежние SOTA-модели оставались в пределах нескольких процентов.
Почитать подробнее: препринт в arXiv.
Пограться: демо на GitHub.
#Машинное_обучение, #Обработка_естественного_языка, #Образование
minerva-demo.github.io
Minerva sample explorer
Explore samples from a large language model trained on technical content