
Меньше месяца до окончания приема заявок в магистратуру ЦУ с грантом до 75% на все время обучения!
Если хочешь двигаться в новую роль, но не хватает уверенности и структуры — начни обучение на одном из четырех ИТ-направлений магистратуры ЦУ.
Ты сможешь прокачаться:
— в продуктовой аналитике;
— машинном обучении;
— продуктовом менеджменте;
— backend-разработке.
Партнеры университета — ведущие компании на рынке РФ: ВТБ, Сбер, Т-Банк, Яндекс, Avito, Ozon, Х5 Tech и другие. 62% магистрантов ЦУ находят новую работу с ростом зарплаты в 1,6 раза уже на первом курсе, а средняя зарплата достигает 195 000 ₽.
Обучение можно совмещать с работой, так как занятия проводятся по вечерам и выходным.
Успей подать заявку до 24 августа: ссылка
Если хочешь двигаться в новую роль, но не хватает уверенности и структуры — начни обучение на одном из четырех ИТ-направлений магистратуры ЦУ.
Ты сможешь прокачаться:
— в продуктовой аналитике;
— машинном обучении;
— продуктовом менеджменте;
— backend-разработке.
Партнеры университета — ведущие компании на рынке РФ: ВТБ, Сбер, Т-Банк, Яндекс, Avito, Ozon, Х5 Tech и другие. 62% магистрантов ЦУ находят новую работу с ростом зарплаты в 1,6 раза уже на первом курсе, а средняя зарплата достигает 195 000 ₽.
Обучение можно совмещать с работой, так как занятия проводятся по вечерам и выходным.
Успей подать заявку до 24 августа: ссылка
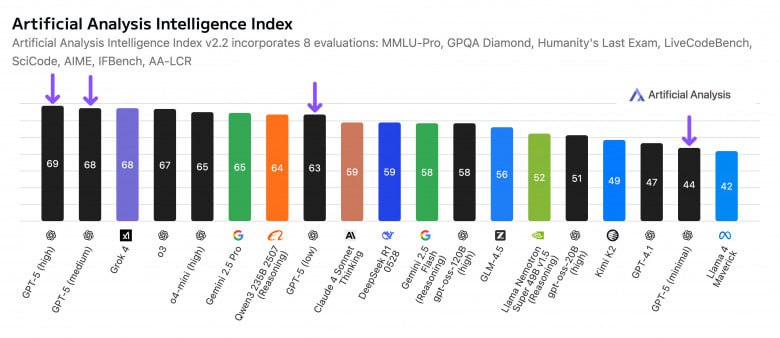
Разбираем, как устроен запуск GPT-5, какие лимиты и настройки ввела OpenAI, и на что обратить внимание подписчикам ChatGPT Plus, чтобы выбрать оптимальную модель и избежать проблем
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤1
Статья рассказывает, как с помощью Python и ChatGPT создать скрипт для автоматической загрузки видео с YouTube и генерации метаданных (описаний и обложек) для интеграции с медиацентром Kodi.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
👍2⚡1
Напишите функцию, которая принимает строку и возвращает словарь, где ключами являются слова из строки, а значениями — количество их вхождений. Игнорируйте регистр и знаки препинания.
Пример:
text = "Hello, world! Hello Python world."
result = count_words(text)
print(result)
# Ожидаемый результат: {'hello': 2, 'world': 2, 'python': 1}
Решение задачи
import re
from collections import Counter
def count_words(text):
# Убираем знаки препинания и приводим к нижнему регистру
words = re.findall(r'\b\w+\b', text.lower())
# Подсчитываем количество вхождений каждого слова
return Counter(words)
# Пример использования:
text = "Hello, world! Hello Python world."
result = count_words(text)
print(result)
# Ожидаемый результат: {'hello': 2, 'world': 2, 'python': 1}
Please open Telegram to view this post
VIEW IN TELEGRAM
❤2⚡1
Покажу, как в Firefox задействовать несколько потоков в логическом выводе с помощью SharedArrayBuffer и добиться параллельной обработки задач ИИ в WASM/JS.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤2⚡1
Разбирается философский джейлбрейк LLM: модель через саморефлексию перестаёт воспринимать фильтры как обязательные. Без багов, без хака — просто философия.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤4⚡1
У вас есть бинарная целевая переменная
y (список из 0 и 1) и числовой признак x (такой же длины). Нужно реализовать функцию best_split(x, y), которая найдёт такое значение признака, при разделении по которому (меньше/больше) будет максимально уменьшена энтропия классов.Иными словами, нужно найти лучший
threshold, при котором данные делятся на две группы по x, и у этих групп наименьшая средняя энтропия. Это базовая операция в построении деревьев решений, например, в алгоритме ID3.Цель:
Вернуть threshold, который даёт наилучшее (наименьшее) значение средневзвешенной энтропии.
Решение задачи
import numpy as np
def entropy(labels):
if len(labels) == 0:
return 0
p = np.bincount(labels) / len(labels)
return -np.sum([pi * np.log2(pi) for pi in p if pi > 0])
def best_split(x, y):
x = np.array(x)
y = np.array(y)
thresholds = sorted(set(x))
best_entropy = float('inf')
best_thresh = None
for t in thresholds:
left_mask = x <= t
right_mask = x > t
left_entropy = entropy(y[left_mask])
right_entropy = entropy(y[right_mask])
w_left = np.sum(left_mask) / len(x)
w_right = 1 - w_left
avg_entropy = w_left * left_entropy + w_right * right_entropy
if avg_entropy < best_entropy:
best_entropy = avg_entropy
best_thresh = t
return best_thresh
# Пример использования
x = [2, 4, 6, 8, 10, 12]
y = [0, 0, 1, 1, 1, 1]
print(best_split(x, y))
# Ожидаемый результат: значение между 4 и 6 (например, 6), так как оно лучше всего делит классы
Please open Telegram to view this post
VIEW IN TELEGRAM
⚡1❤1
Собрали для Вас подборку нужных каналов.🧑💻
🐍 👩💻 $ sudo teach IT - рай для ботоделов!
- Как создать Телеграм-Бот?
- Где найти заказы?
- Как писать профессиональный код под высоконагруженные сервисы?
Начните свой практический путь в мире айти!
🐍 Data Science | Machinelearning [ru] - Статьи на тему data science, machine learning, big data, python, математика, нейронные сети, искусственный интеллект (artificial intelligence)
🐍 Node.JS [ru] | Серверный JavaScript - Все о разработке backend части на JavaScript (Node JS).
А так же: Express JS, Next JS, Nest, Socket.IO
🖥 PytStart - стартуй в Python с нами!
🐍 PythonTalk. Авторский канал, где Python, AI и здравый смысл встречаются. Разбор свежих open-source инструментов, мануалы, новости с IT-передовой и трезвый взгляд на AI-хайп.
🐍 Indigo Python - твой путь к мастерству в коде!
🐍 Канал вирусного аналитика, занимающегося безопасностью опенсорса и технологиями искусственного интеллекта.
Хочешь участвовать в подборке? Пиши!
- Как создать Телеграм-Бот?
- Где найти заказы?
- Как писать профессиональный код под высоконагруженные сервисы?
Начните свой практический путь в мире айти!
А так же: Express JS, Next JS, Nest, Socket.IO
Хочешь участвовать в подборке? Пиши!
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2
• Пришёл на вакансию дизайнера, а стал питонистом: как IT-специалисты нашли свою первую работу
• На сколько денег может рассчитывать ИТ-предприниматель в разных ветках развития
• Анализ задачи с собеседования в Google: конь и телефонные кнопки
• Быстрый старт в QA Fullstack: чем вооружиться будущему стажеру в Альфа-Банке
• Как убить самоорганизацию в команде: вредные советы для лидера
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤1
Упрощать и искать похожие детали, очень полезный навык! Предлагаю быстро пробежаться и попробовать найти ту самую серебряную пулю в RecSys.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤2⚡1
🚀 Интересуетесь нейросетями и хотите понять, как эволюция архитектур RNN и Transformer влияет на NLP?
🚀
На открытом уроке «От RNN до Transformers: скорость, память, контекст» 19 августа в 20:00 МСК мы разберём, как работают рекуррентные нейросети (RNN), их ограничения и почему современные NLP-системы всё чаще переходят к трансформерам. Мы сравним эти архитектуры по ключевым параметрам: скорости, памяти, контексту и масштабируемости.
Урок даст вам чёткое представление о том, как меняются подходы в обработке текста, а также объяснит, почему трансформеры становятся основой современных NLP-систем.
📚 Посетите вебинар и получите скидку на большое обучение «NLP / Natural Language Processing»: https://vk.cc/cOBpIj
Реклама. ООО «Отус онлайн-образование», ОГРН 1177746618576, www.otus.ru
🚀
На открытом уроке «От RNN до Transformers: скорость, память, контекст» 19 августа в 20:00 МСК мы разберём, как работают рекуррентные нейросети (RNN), их ограничения и почему современные NLP-системы всё чаще переходят к трансформерам. Мы сравним эти архитектуры по ключевым параметрам: скорости, памяти, контексту и масштабируемости.
Урок даст вам чёткое представление о том, как меняются подходы в обработке текста, а также объяснит, почему трансформеры становятся основой современных NLP-систем.
📚 Посетите вебинар и получите скидку на большое обучение «NLP / Natural Language Processing»: https://vk.cc/cOBpIj
Реклама. ООО «Отус онлайн-образование», ОГРН 1177746618576, www.otus.ru
logging в Python?logging — это встроенный модуль Python для создания логов, которые помогают отлаживать и мониторить работу приложений.import logging
# Настройка базового уровня логирования
logging.basicConfig(level=logging.INFO)
# Создание лога
logging.info("Приложение запущено")
logging.warning("Это предупреждение!")
logging.error("Произошла ошибка")
🗣️ В этом примере модуль logging создаёт сообщения разного уровня важности. Логирование позволяет отслеживать работу приложений и находить проблемы в коде.
Please open Telegram to view this post
VIEW IN TELEGRAM
👍3🔥1
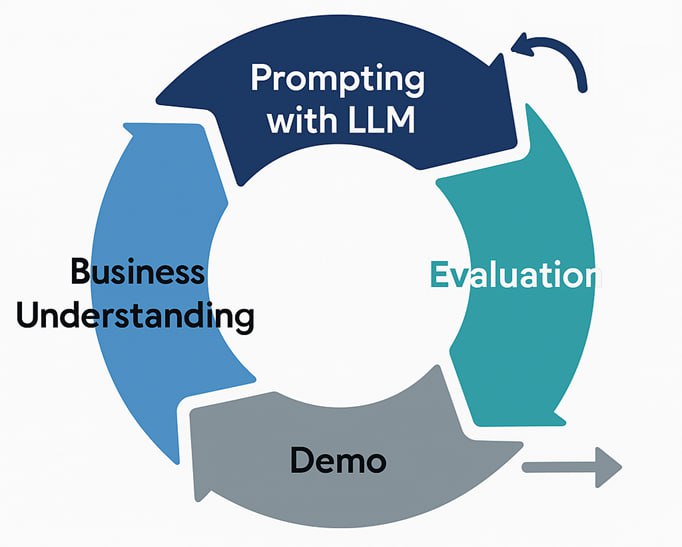
Рассказывается про CRISP-DM Light — фреймворк, который помогает быстро проверять ML-гипотезы и не сливать бюджеты впустую. Меньше бюрократии, больше пользы — и шанс дойти до прода.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
⚡1
Интересуешься анализом данных и хочешь развивать карьеру в финтехе? Участвуй в бесплатной программе университета «Сириус» и Газпромбанк.Тех.
Что тебя ждет?
– Изучение Python, ML, pandas и streamlit
– Работа с реальными бизнес-сценариями и разработка MVP
– Поддержка ведущих экспертов на протяжении всего обучения
Старт обучения в декабре, по итогам программы каждый участник получит возможность стать частью команды Газпромбанка.
В карточках отвечаем на главные вопросы о программе. Подай заявку до 10 сентября по ссылке.
Реклама, Банк ГПБ (АО), ИНН: 7744001497, erid: 2Vtzqw8AzKb
Что тебя ждет?
– Изучение Python, ML, pandas и streamlit
– Работа с реальными бизнес-сценариями и разработка MVP
– Поддержка ведущих экспертов на протяжении всего обучения
Старт обучения в декабре, по итогам программы каждый участник получит возможность стать частью команды Газпромбанка.
В карточках отвечаем на главные вопросы о программе. Подай заявку до 10 сентября по ссылке.
Реклама, Банк ГПБ (АО), ИНН: 7744001497, erid: 2Vtzqw8AzKb
👎2
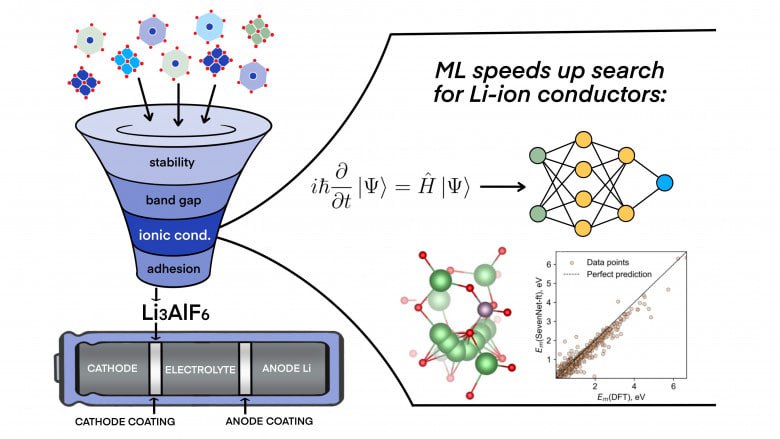
Рассказываю, как мы с помощью ML искали литий-ионные проводники и покрытия для катодов. Материалы, потенциалы, немного науки и много практики — без занудства.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
🐳1
Самая большая проблема больших проектов — то, что картину целиком никто не держит в голове.
👉 Совет: регулярно обновляй схемы, диаграммы или хотя бы заметки по архитектуре. Пусть у каждого будет карта системы. Без карты любой проект превращается в джунгли, даже если код отличный.
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2