
@Machine_learn
Deep Learning For Real Time Streaming Data With Kafka And Tensorflow
#ODSC #DeepLearning #Tensorflow
https://www.youtube.com/watch?v=HenBuC4ATb0
Deep Learning For Real Time Streaming Data With Kafka And Tensorflow
#ODSC #DeepLearning #Tensorflow
https://www.youtube.com/watch?v=HenBuC4ATb0
Implementing original #UNet paper using #PyTorch
Video tutorial on how to code your own neural network from scratch.
Link: https://www.youtube.com/watch?v=u1loyDCoGbE&t=1s
Paper: https://arxiv.org/abs/1505.04597
@Machine_learn
Video tutorial on how to code your own neural network from scratch.
Link: https://www.youtube.com/watch?v=u1loyDCoGbE&t=1s
Paper: https://arxiv.org/abs/1505.04597
@Machine_learn
YouTube
Implementing original U-Net from scratch using PyTorch
In this video, I show you how to implement original UNet paper using PyTorch. UNet paper can be found here: https://arxiv.org/abs/1505.04597
Please subscribe and like the video to help me keep motivated to make awesome videos like this one. :)
To buy my…
Please subscribe and like the video to help me keep motivated to make awesome videos like this one. :)
To buy my…
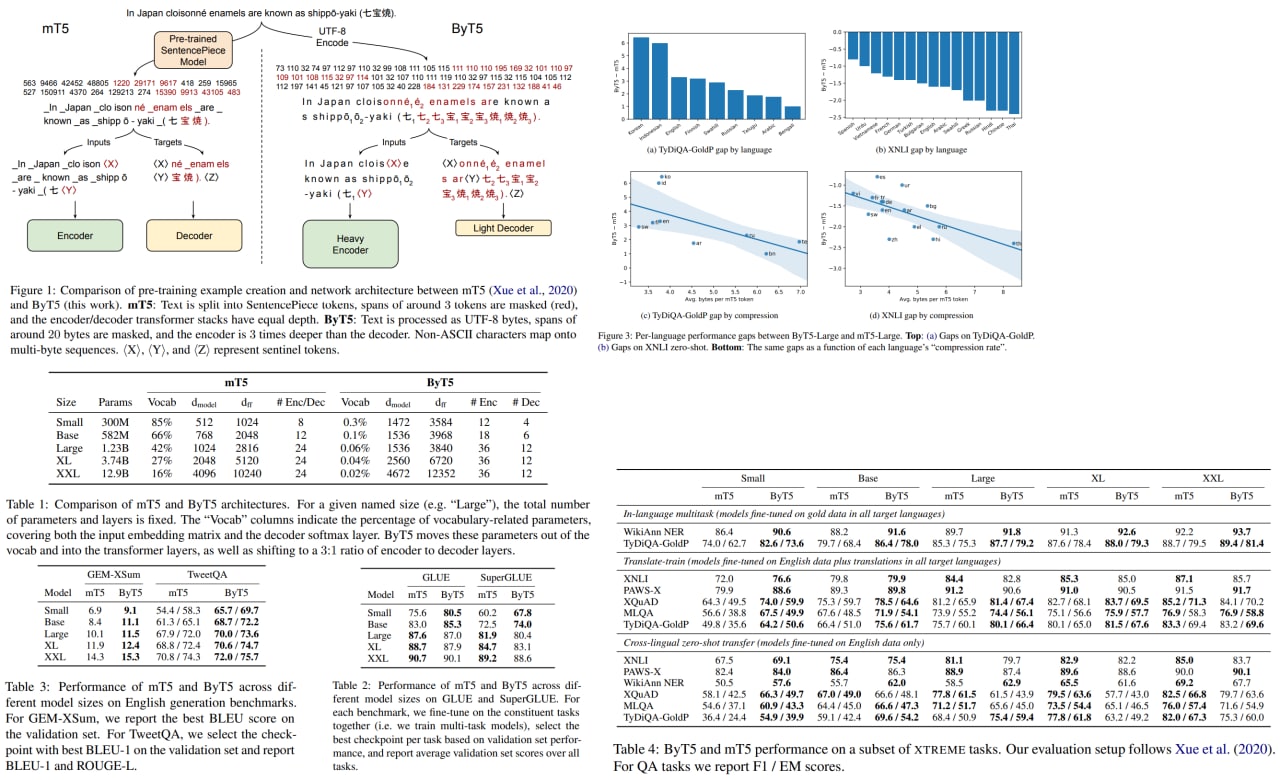
ByT5: Towards a token-free future with pre-trained byte-to-byte models
Pre-trained language models usually operate on the sequences of tokens, which are based on words or subword units.
Token-free models operate directly on the raw text (characters or bytes) instead. They can work with any language, are more robust to the noise, and don’t require preprocessing.
The authors use a modified mT5 architecture and show that their approach is competitive with token-level models.
Paper: https://arxiv.org/abs/2105.13626
Code: https://github.com/google-research/byt5
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-byt5
#nlp #deeplearning #transformer #pretraining
@Machine_learn
Pre-trained language models usually operate on the sequences of tokens, which are based on words or subword units.
Token-free models operate directly on the raw text (characters or bytes) instead. They can work with any language, are more robust to the noise, and don’t require preprocessing.
The authors use a modified mT5 architecture and show that their approach is competitive with token-level models.
Paper: https://arxiv.org/abs/2105.13626
Code: https://github.com/google-research/byt5
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-byt5
#nlp #deeplearning #transformer #pretraining
@Machine_learn
{kind=link}
Forwarded from Omid
I gladly announce my first online course on #Statistics and #Mathematics for #MachineLearning and #DeepLearning.
The course will be in English, QA sessions with instructor will be in Turkish, Azerbaijani , or English. TA sessions will be in English.
This is the first course of tribology courses to help attendees to capture foundations and mathematics behind ML,DL models.
The courses are listed as follow:
1. Statistics Foundation for ML
2. Introduction to Statistical Learning for ML
3. Advanced Statistical Learning for DL
The course starts on 15 Jan 2022, at 13:00 to 15:00 (Istanbul time):
Course Fee:
Free for unemployed attendees. :)
200 USD for employed candidates :).
Course contents:
https://lnkd.in/dcXKxUjE
Course Registration:
https://lnkd.in/dMpzMfMG
Please kindly share with the ones who are interested.
The course will be in English, QA sessions with instructor will be in Turkish, Azerbaijani , or English. TA sessions will be in English.
This is the first course of tribology courses to help attendees to capture foundations and mathematics behind ML,DL models.
The courses are listed as follow:
1. Statistics Foundation for ML
2. Introduction to Statistical Learning for ML
3. Advanced Statistical Learning for DL
The course starts on 15 Jan 2022, at 13:00 to 15:00 (Istanbul time):
Course Fee:
Free for unemployed attendees. :)
200 USD for employed candidates :).
Course contents:
https://lnkd.in/dcXKxUjE
Course Registration:
https://lnkd.in/dMpzMfMG
Please kindly share with the ones who are interested.
lnkd.in
LinkedIn
This link will take you to a page that’s not on LinkedIn
👍1
https://web.njit.edu/~ym329/dlg_book/dlg_book.pdf
Deep Learning on Graphs
📖 Book
#deeplearning #DL
@Machine_learn
Deep Learning on Graphs
📖 Book
#deeplearning #DL
@Machine_learn
Recognize Anything: A Strong Image Tagging Model
Get ready for a breakthrough in the realm of AI: introducing the Recognize Anything Model (RAM), a powerful new model that is set to revolutionize image tagging. RAM, a titan in the world of large computer vision models, astoundingly exhibits the zero-shot ability to recognize any common category with an impressive level of accuracy. Shattering traditional approaches, RAM employs a unique paradigm for image tagging, utilizing large-scale image-text pairs for training instead of relying on tedious manual annotations.
Paper link: https://arxiv.org/abs/2306.03514
Code link: https://github.com/xinyu1205/recognize-anything
Project link: https://recognize-anything.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ram
#deeplearning #cv #imagecaptioning
@Machine_lean
Recognize Anything: A Strong Image Tagging Model
Get ready for a breakthrough in the realm of AI: introducing the Recognize Anything Model (RAM), a powerful new model that is set to revolutionize image tagging. RAM, a titan in the world of large computer vision models, astoundingly exhibits the zero-shot ability to recognize any common category with an impressive level of accuracy. Shattering traditional approaches, RAM employs a unique paradigm for image tagging, utilizing large-scale image-text pairs for training instead of relying on tedious manual annotations.
Paper link: https://arxiv.org/abs/2306.03514
Code link: https://github.com/xinyu1205/recognize-anything
Project link: https://recognize-anything.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ram
#deeplearning #cv #imagecaptioning
@Machine_lean
🔥5👍2❤1
Please open Telegram to view this post
VIEW IN TELEGRAM
👍7🔥1