
Королевство пустых зеркал
В рамках нашей рубрики #историянаукометрии мы уже не раз показывали, что наука о науке не сразу обрела собственный предмет.
В дискуссии, получившей название «Как перестать беспокоиться и полюбить реферируемые журналы», А. Космарский отметил, что наукометрия как способ изучения работы научных практик может быть интересна в двух перспективах. С одной стороны, интерес к изучению науки как самостоятельного предмета может быть внутренней практикой самой науки, ее саморефлексией над происходящими внутри науки процессами. С другой стороны, в ней заинтересованы внешние по отношению к науке лица, например, государство, которое может прибегать к использованию продуктов наукометрии для (не-)эффективного администрирования процессов самой науки.
Т. Франссен и П. Воутерс в своем исследовании об изменениях использования библиометрии подчеркивают, что две эти перспективы в отношении гуманитарных наук последовательно сменяют друг друга: с 1960-х по 1980-е годы библиометрия является частью социологической оптики для изучения внутринаучных процессов, в то время как с 1980-х годов библиометрия начинает в большей степени рассматриваться как эмпирический материал для формирования научных политик и оценки исследований.
Учитывая наш личный интерес к теме, мы не могли пройти мимо анонса нашего коллеги Андрея Герасимова, который приглашает принять участие в конференции «Королевство пустых зеркал: социальные исследования социальных наук». Конференция, которая пройдет в Шанинке и онлайн, будет посвящена как эмпирическим исследованиям, реконструирующим путь становления наук и изменения их формы, так и теоретическим подходам к научной самообъективации. Направления конференции затронут в первую очередь разные социологические подходы, будь то исследования социо-гуманитарного знания в СССР, интеллектуалов, подходов к социальным наукам или социология социологии. Кроме того, одним из заявленных направлений, которое может особенно заинтересовать наших постоянных читателей, выступит наукометрическая перпектива (а также ее враги!): как цифры характеризуют нынешнее положение социальной науки, а также при помощи каких практик наука изучает эти цифры?
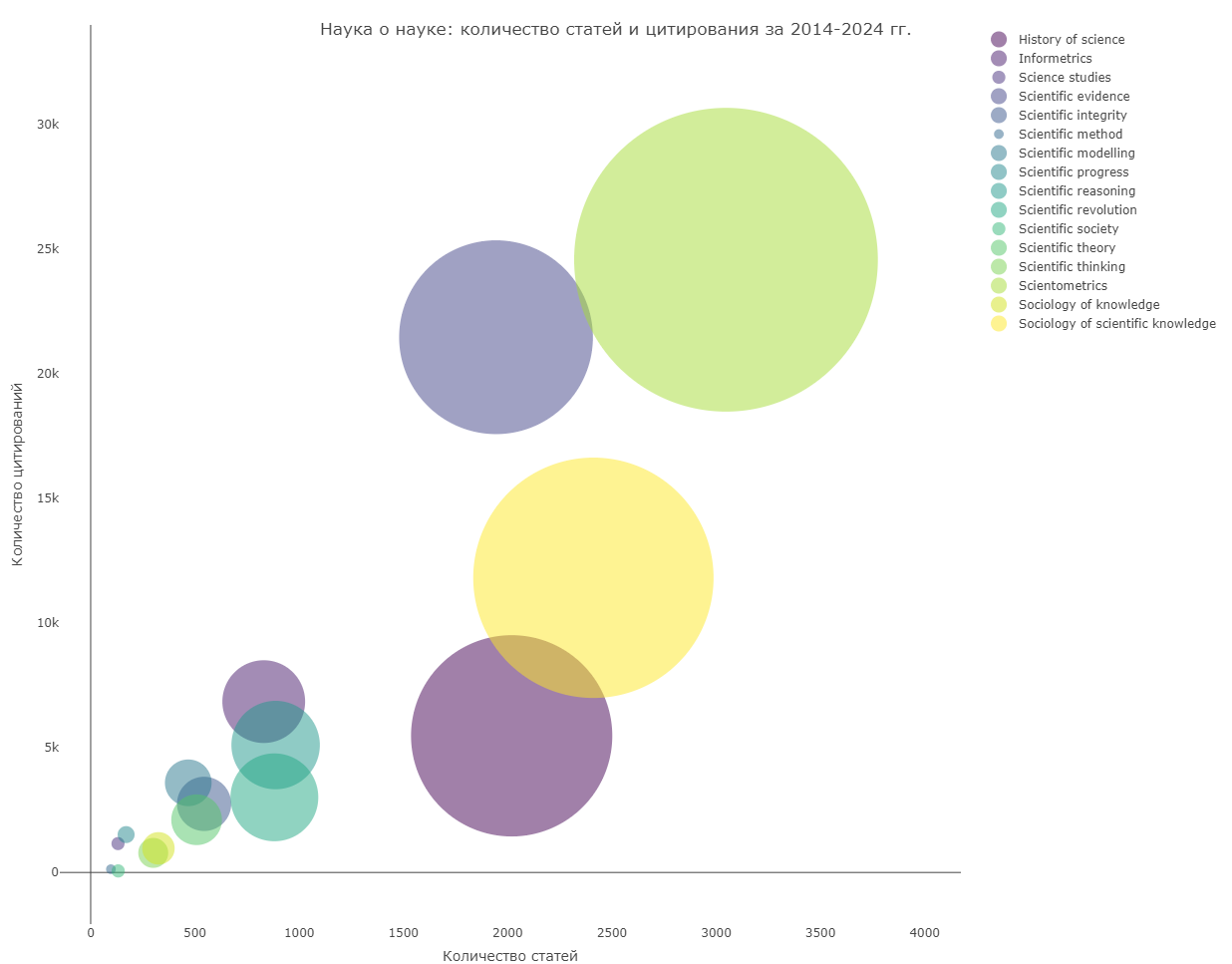
Мы же, по обыкновению, решили посмотреть, как схожие темы представлены в OpenAlex. Выборку было решено делать по концепциям, а не по недавно появившимся тематикам, поскольку только среди концепций удалось найти соответствующие пункты. Для анализа мы выбрали следующие концепции: Scientific integrity, Scientific thinking, Scientific evidence, Sociology of knowledge, Scientific modelling, Scientific reasoning, History of science, Scientific society, Scientific revolution, Scientific method, Scientometrics, Scientific progress, Science studies, Sociology of scientific knowledge, Scientific theory, Informetrics, порог балла связи (score) 0,5, временной период — с 2014 по 2024 гг. Результаты представлены на диаграмме (есть и интерактивная версия). Больше всего как цитирований, так и публикаций насчитывает наукометрия — более 3 тысяч статей были процитированы почти 25 тысяч раз. Сразу обращают на себя внимание концепции «научное доказательство» (scientific evidence) и история науки — публикаций по каждой из концепций около 2 тысяч, но при этом цитирований у первой более 20 тысяч, а у второй — всего 5479.
#конференция #OpenAlex #аналитика
В рамках нашей рубрики #историянаукометрии мы уже не раз показывали, что наука о науке не сразу обрела собственный предмет.
В дискуссии, получившей название «Как перестать беспокоиться и полюбить реферируемые журналы», А. Космарский отметил, что наукометрия как способ изучения работы научных практик может быть интересна в двух перспективах. С одной стороны, интерес к изучению науки как самостоятельного предмета может быть внутренней практикой самой науки, ее саморефлексией над происходящими внутри науки процессами. С другой стороны, в ней заинтересованы внешние по отношению к науке лица, например, государство, которое может прибегать к использованию продуктов наукометрии для (не-)эффективного администрирования процессов самой науки.
Т. Франссен и П. Воутерс в своем исследовании об изменениях использования библиометрии подчеркивают, что две эти перспективы в отношении гуманитарных наук последовательно сменяют друг друга: с 1960-х по 1980-е годы библиометрия является частью социологической оптики для изучения внутринаучных процессов, в то время как с 1980-х годов библиометрия начинает в большей степени рассматриваться как эмпирический материал для формирования научных политик и оценки исследований.
Учитывая наш личный интерес к теме, мы не могли пройти мимо анонса нашего коллеги Андрея Герасимова, который приглашает принять участие в конференции «Королевство пустых зеркал: социальные исследования социальных наук». Конференция, которая пройдет в Шанинке и онлайн, будет посвящена как эмпирическим исследованиям, реконструирующим путь становления наук и изменения их формы, так и теоретическим подходам к научной самообъективации. Направления конференции затронут в первую очередь разные социологические подходы, будь то исследования социо-гуманитарного знания в СССР, интеллектуалов, подходов к социальным наукам или социология социологии. Кроме того, одним из заявленных направлений, которое может особенно заинтересовать наших постоянных читателей, выступит наукометрическая перпектива (а также ее враги!): как цифры характеризуют нынешнее положение социальной науки, а также при помощи каких практик наука изучает эти цифры?
Мы же, по обыкновению, решили посмотреть, как схожие темы представлены в OpenAlex. Выборку было решено делать по концепциям, а не по недавно появившимся тематикам, поскольку только среди концепций удалось найти соответствующие пункты. Для анализа мы выбрали следующие концепции: Scientific integrity, Scientific thinking, Scientific evidence, Sociology of knowledge, Scientific modelling, Scientific reasoning, History of science, Scientific society, Scientific revolution, Scientific method, Scientometrics, Scientific progress, Science studies, Sociology of scientific knowledge, Scientific theory, Informetrics, порог балла связи (score) 0,5, временной период — с 2014 по 2024 гг. Результаты представлены на диаграмме (есть и интерактивная версия). Больше всего как цитирований, так и публикаций насчитывает наукометрия — более 3 тысяч статей были процитированы почти 25 тысяч раз. Сразу обращают на себя внимание концепции «научное доказательство» (scientific evidence) и история науки — публикаций по каждой из концепций около 2 тысяч, но при этом цитирований у первой более 20 тысяч, а у второй — всего 5479.
#конференция #OpenAlex #аналитика
{kind=link}
Data paper как самостоятельная наукометрическая единица
Не так давно Иван Бегтин, которого мы регулярно читаем, опубликовал пост о том, что следует считать наборами данных. Это могут быть как стандартные датасеты, так и другие типы данных: data paper, data report, data article и data note. В такие публикации входит не только текст статьи, но и ссылки на исходные данные или данные, полученные в результате работы.
Пока нет общего мнения, можно ли считать наборы данных отдельным типом данных и следует ли в принципе индексировать их в библиометрических системах, но, как минимум, Scopus добавил к параметру DOCTYPE допустимое значение “dp” (data paper) (правда, в справке пока что этой информации не содержится), в Web of Science data paper индексируются с 2016 года, причем им присваивается двойное значение — data paper и article, а в OpenAlex есть тип “dataset”.
Наборы данных пока не везде считаются отдельным типом данных, поэтому не во всех библиометрических базах можно выделить их однозначно, но мы сделали несколько разрезов, чтобы внимательнее рассмотреть, как распределяются публикации по годам и областям, а также — какие издательства уже публикуют работы с подобными ссылками.
В Web of Science за все годы было 15 677 публикаций с типом data paper, в Scopus немного больше — 16 146. В OpenAlex же хранится информация о более чем 7 миллионах датасетов, из которых более 4 — в открытом доступе, однако данных о data paper как о полноценных статьях, описывающих содержание датасета, пока нет.
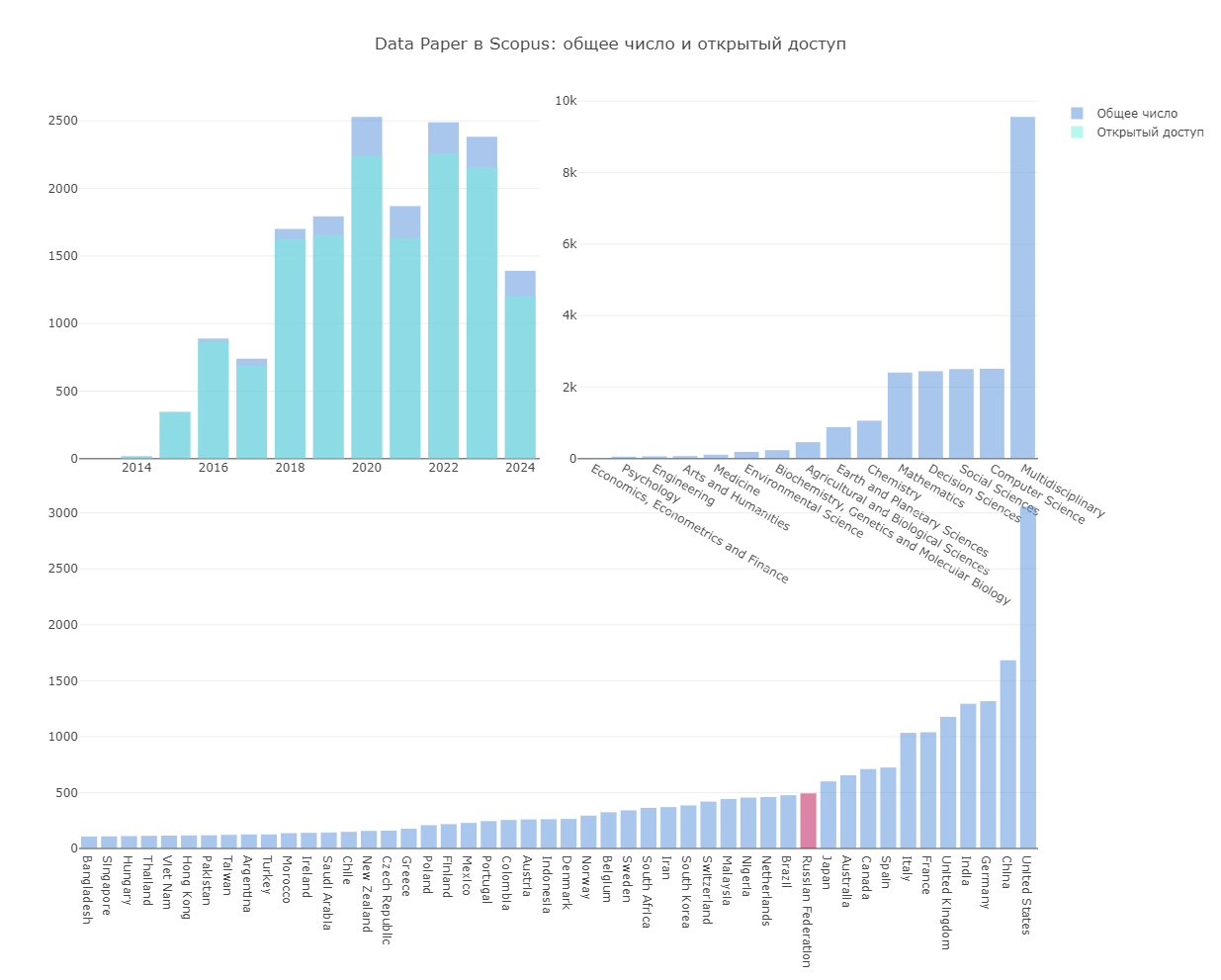
Мы проанализировали data paper, индексируемые в Scopus, по нескольким разрезам, чтобы понять, насколько распространены подобные публикации в различных странах и областях знаний. Среди государств ожидаемо лидируют США и КНР (при этом в США было опубликовано более 3000 data paper, что почти вдвое больше, чем в Китае). Россия на 12 месте (493 data paper) и опережает, например, Нидерланды, Швейцарию и Бельгию.
По областям (если не считать ожидаемого пика у Multidisciplinary) почти наравне держатся компьютерные и социальные науки — 2516 и 2507 публикаций соответственно. За ними с незначительной разницей идут науки о принятии решений и математика — 2447 и 2410. А вот биохимия, генетика и молекулярная биология, которые часто приходят на ум при словосочетании «набор данных», имеет всего 239 data papers.
Важно отметить, что большая часть data papers размещена в открытом доступе: 14 676 публикаций из 16 146 имеют различный статус Open Access, от Gold до Hybrid.
#Scopus #openaccess #datapaper #аналитика
Не так давно Иван Бегтин, которого мы регулярно читаем, опубликовал пост о том, что следует считать наборами данных. Это могут быть как стандартные датасеты, так и другие типы данных: data paper, data report, data article и data note. В такие публикации входит не только текст статьи, но и ссылки на исходные данные или данные, полученные в результате работы.
Пока нет общего мнения, можно ли считать наборы данных отдельным типом данных и следует ли в принципе индексировать их в библиометрических системах, но, как минимум, Scopus добавил к параметру DOCTYPE допустимое значение “dp” (data paper) (правда, в справке пока что этой информации не содержится), в Web of Science data paper индексируются с 2016 года, причем им присваивается двойное значение — data paper и article, а в OpenAlex есть тип “dataset”.
Наборы данных пока не везде считаются отдельным типом данных, поэтому не во всех библиометрических базах можно выделить их однозначно, но мы сделали несколько разрезов, чтобы внимательнее рассмотреть, как распределяются публикации по годам и областям, а также — какие издательства уже публикуют работы с подобными ссылками.
В Web of Science за все годы было 15 677 публикаций с типом data paper, в Scopus немного больше — 16 146. В OpenAlex же хранится информация о более чем 7 миллионах датасетов, из которых более 4 — в открытом доступе, однако данных о data paper как о полноценных статьях, описывающих содержание датасета, пока нет.
Мы проанализировали data paper, индексируемые в Scopus, по нескольким разрезам, чтобы понять, насколько распространены подобные публикации в различных странах и областях знаний. Среди государств ожидаемо лидируют США и КНР (при этом в США было опубликовано более 3000 data paper, что почти вдвое больше, чем в Китае). Россия на 12 месте (493 data paper) и опережает, например, Нидерланды, Швейцарию и Бельгию.
По областям (если не считать ожидаемого пика у Multidisciplinary) почти наравне держатся компьютерные и социальные науки — 2516 и 2507 публикаций соответственно. За ними с незначительной разницей идут науки о принятии решений и математика — 2447 и 2410. А вот биохимия, генетика и молекулярная биология, которые часто приходят на ум при словосочетании «набор данных», имеет всего 239 data papers.
Важно отметить, что большая часть data papers размещена в открытом доступе: 14 676 публикаций из 16 146 имеют различный статус Open Access, от Gold до Hybrid.
#Scopus #openaccess #datapaper #аналитика
{kind=link}
Что с сайтами журналов в Elibrary?
В нашем канале мы уже неоднократно упоминали о феномене «похищенных» (hijacked) журналов (некоторые мошеннические издательства создают копии сайтов научных журналов, которые тяжело отличить от официальных страниц). В комментариях к апрельскому посту наш коллега отметил неактуальность некоторых доменов университетов из 1-Мониторинга, что навело нас на мысль: сколько неактуальных сайтов журналов сейчас присутствует в российском сегменте?
Для исследования мы выбрали рейтинг Science Index 2022, размещенный на Elibrary. В него входят 4044 журнала, в том числе 3058 журналов из списка ВАК. В Elibrary домашняя страница указана у 3786 (93,6%) из них. Для проверки ответов сервера мы использовали сервис https://coolakov.ru/tools/ping/, позволяющий отследить редиректы и получить итоговый адрес страницы (или 404, если страница не найдена).
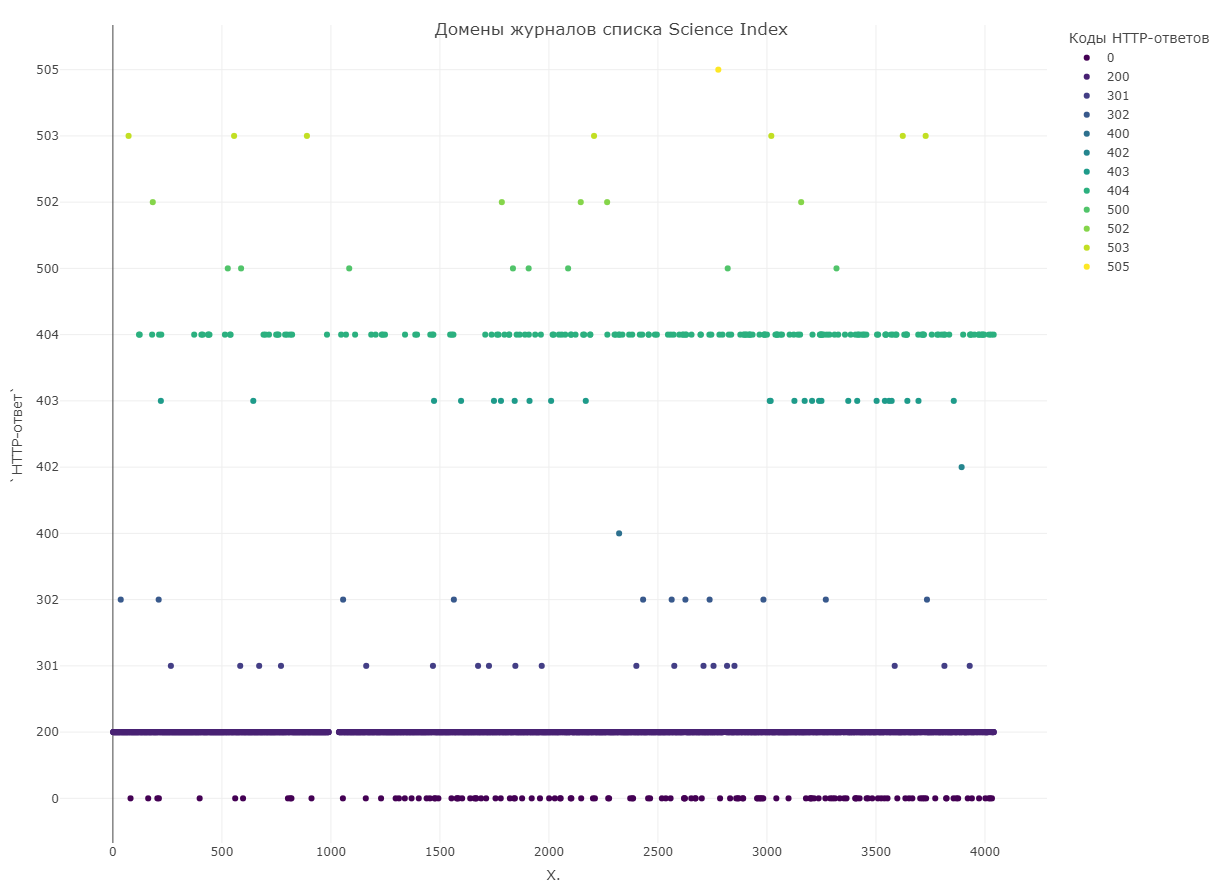
Полученные данные мы разместили на диаграмме. По оси X указывается место журнала в рейтинге, а на оси Y — код ответа сервера. Распределение по ответам серверов следующее:
3397 журналов — код 2ХХ (успешная обработка запроса)
30 журналов — коды 3ХХ (редирект и после этого успешная обработка запроса)
209 журналов — коды 4ХХ (ошибка на стороне клиента — нет доступа или ошибочный адрес сайта)
21 журнал — коды 5ХХ (ошибка на стороне сервера — например, сайт временно недоступен)
129 журналов — код 0 (такой код сервис возвращал, если сайта просто не существует).
Итак, для 359 журналов (почти 9%) журналов из Science Index указаны некорректные адреса веб-страниц (при этом редиректов на подозрительные ресурсы мы не обнаружили). 209 журналов, сайты которых возвращают коды 4XX, как правило, поменяли адрес или архитектуру сайта — нужно только обновить данные. А вот 129 журналов с несуществующими сайтами вызывают больше беспокойства.
#аналитика #Elibrary #сайты
В нашем канале мы уже неоднократно упоминали о феномене «похищенных» (hijacked) журналов (некоторые мошеннические издательства создают копии сайтов научных журналов, которые тяжело отличить от официальных страниц). В комментариях к апрельскому посту наш коллега отметил неактуальность некоторых доменов университетов из 1-Мониторинга, что навело нас на мысль: сколько неактуальных сайтов журналов сейчас присутствует в российском сегменте?
Для исследования мы выбрали рейтинг Science Index 2022, размещенный на Elibrary. В него входят 4044 журнала, в том числе 3058 журналов из списка ВАК. В Elibrary домашняя страница указана у 3786 (93,6%) из них. Для проверки ответов сервера мы использовали сервис https://coolakov.ru/tools/ping/, позволяющий отследить редиректы и получить итоговый адрес страницы (или 404, если страница не найдена).
Полученные данные мы разместили на диаграмме. По оси X указывается место журнала в рейтинге, а на оси Y — код ответа сервера. Распределение по ответам серверов следующее:
3397 журналов — код 2ХХ (успешная обработка запроса)
30 журналов — коды 3ХХ (редирект и после этого успешная обработка запроса)
209 журналов — коды 4ХХ (ошибка на стороне клиента — нет доступа или ошибочный адрес сайта)
21 журнал — коды 5ХХ (ошибка на стороне сервера — например, сайт временно недоступен)
129 журналов — код 0 (такой код сервис возвращал, если сайта просто не существует).
Итак, для 359 журналов (почти 9%) журналов из Science Index указаны некорректные адреса веб-страниц (при этом редиректов на подозрительные ресурсы мы не обнаружили). 209 журналов, сайты которых возвращают коды 4XX, как правило, поменяли адрес или архитектуру сайта — нужно только обновить данные. А вот 129 журналов с несуществующими сайтами вызывают больше беспокойства.
#аналитика #Elibrary #сайты
{kind=link}
Самоцитирования журналов: тематический, страновой и квартильный разрезы
Постепенно возвращаясь к академическому ритму после летних каникул, мы решили обратить внимание наших подписчиков на динамику самоцитирований журналов, индексирующихся в Web of Science.
В онлайн-руководстве вопрос самоцитирований рассматривается как с точки зрения отдельного автора, так и с позиции журнального самоцитирования. Основная проблема самоцитирований в последнем случае — это искажение информации об истинной видимости журнальных статей академическим сообществом, что снижает надежность метрик, рассчитываемых на основе цитируемости (в том числе и широко используемых квартилей, являющихся побочным продуктом статистического подхода). Последние работы в области наукометрии (Bennett H., Singh B. & Slattery F.: 2024; Fiorillo. L.: 2024) показывают, что интерес к оценке самоцитирований не только сохраняется, но и является драйвером для описания тех изменений, которые претерпевают отдельные научные области.
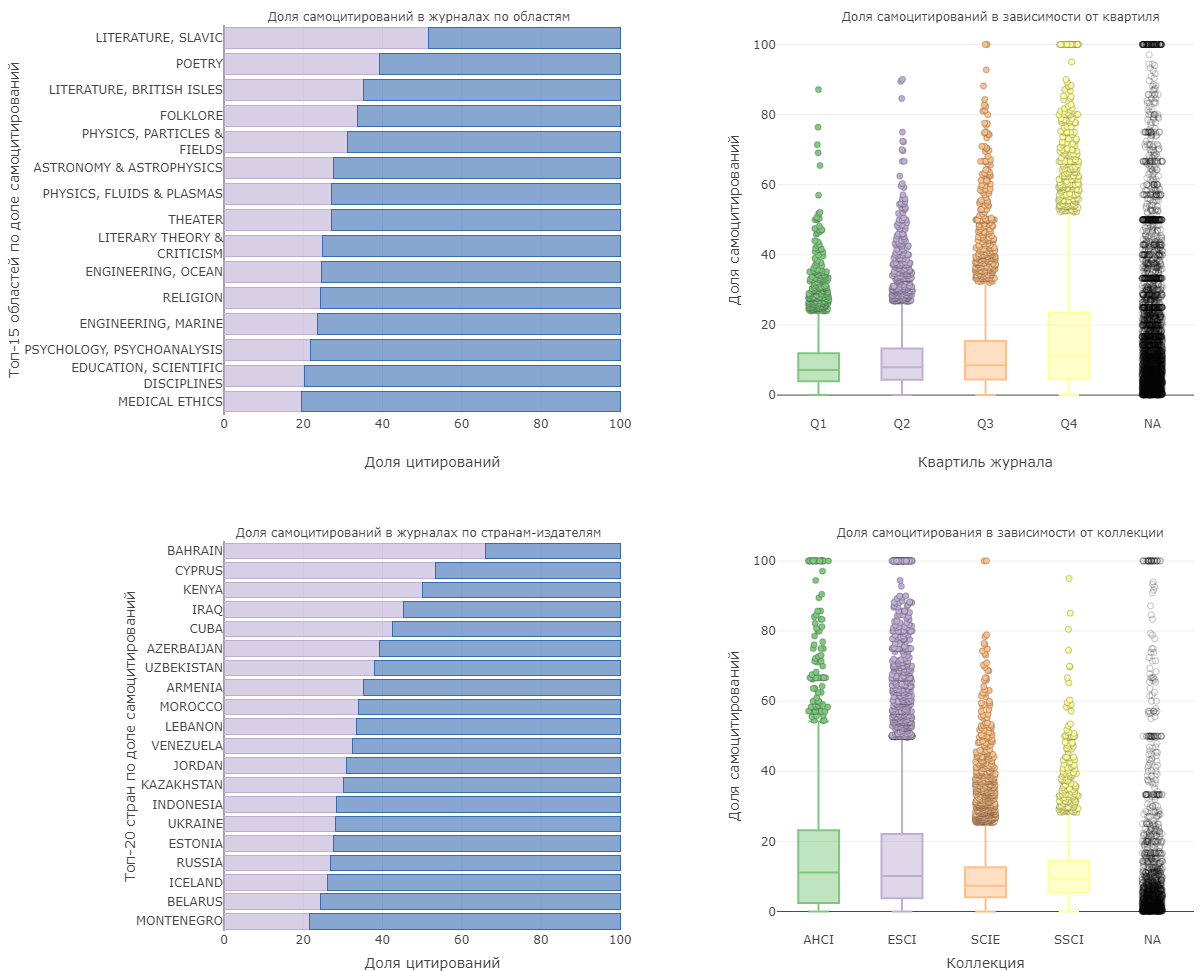
Наша сегодняшняя аналитика продолжает заданное направление и построена на данных по источникам WoS за 2021-2023 гг. На диаграмме можно увидеть области, в которых наиболее часто встречается самоцитирование: в основном это узкие специфические области литературы (в частности, славянская литература — в среднем более 50% самоцитирований) и физики (физика полей и частиц, астрофизика, физика плазмы — 25-30%) Если говорить о странах-издателях журналов, то наибольшее количество самоцитирований встречается в журналах стран Африки и СНГ.
С квартилем журнала доля самоцитирований коррелирует слабо, но устойчиво — медианное значение составляет от 7,2% в журналах Q1 до 11,3% в Q4. Наблюдается и зависимость от коллекции, в которую входит журнал: меньше всего прибегают к самоцитированию авторы журналов из коллекции SCIE (Science Citation Index Expanded, 7,3%), за ней следует SSCI (Social Sciences Citation Index, 9,3%). У коллекций ESCI (Emerging Sources Citation Index) и AHCI (Arts & Humanities Citation Index) показатели самоцитирования выше — 10,2% и 11,1% соответственно.
#аналитика #самоцитирование #webofscience #руководство
Постепенно возвращаясь к академическому ритму после летних каникул, мы решили обратить внимание наших подписчиков на динамику самоцитирований журналов, индексирующихся в Web of Science.
В онлайн-руководстве вопрос самоцитирований рассматривается как с точки зрения отдельного автора, так и с позиции журнального самоцитирования. Основная проблема самоцитирований в последнем случае — это искажение информации об истинной видимости журнальных статей академическим сообществом, что снижает надежность метрик, рассчитываемых на основе цитируемости (в том числе и широко используемых квартилей, являющихся побочным продуктом статистического подхода). Последние работы в области наукометрии (Bennett H., Singh B. & Slattery F.: 2024; Fiorillo. L.: 2024) показывают, что интерес к оценке самоцитирований не только сохраняется, но и является драйвером для описания тех изменений, которые претерпевают отдельные научные области.
Наша сегодняшняя аналитика продолжает заданное направление и построена на данных по источникам WoS за 2021-2023 гг. На диаграмме можно увидеть области, в которых наиболее часто встречается самоцитирование: в основном это узкие специфические области литературы (в частности, славянская литература — в среднем более 50% самоцитирований) и физики (физика полей и частиц, астрофизика, физика плазмы — 25-30%) Если говорить о странах-издателях журналов, то наибольшее количество самоцитирований встречается в журналах стран Африки и СНГ.
С квартилем журнала доля самоцитирований коррелирует слабо, но устойчиво — медианное значение составляет от 7,2% в журналах Q1 до 11,3% в Q4. Наблюдается и зависимость от коллекции, в которую входит журнал: меньше всего прибегают к самоцитированию авторы журналов из коллекции SCIE (Science Citation Index Expanded, 7,3%), за ней следует SSCI (Social Sciences Citation Index, 9,3%). У коллекций ESCI (Emerging Sources Citation Index) и AHCI (Arts & Humanities Citation Index) показатели самоцитирования выше — 10,2% и 11,1% соответственно.
#аналитика #самоцитирование #webofscience #руководство
{kind=link}
Гендерная гомофилия — исследование RSCI
Недавно мы писали об исследовании гендерной гомофилии, опубликованном в PLoS ONE. Нас заинтересовало более актуальное положение в различных научных областях, прежде всего по российским источникам. Мы решили проанализировать публикации 2023 года на предмет гендерного распределения исследователей, основываясь на данных OpenAlex. Выборка состояла из журналов RSCI (включая их переводные версии).
Наш исходный датасет включал 42 353 публикации со следующими параметрами: тип публикации "article"; не менее двух авторов, год публикации = 2023. Для определения предполагаемого пола авторов использовался пакет gender в R, который рассчитывает вероятность того, является ли имя мужским или женским, основываясь на данных за 1932-2012 гг. Для имен, которые не удалось распознать, дополнительно анализировалось родовое окончание фамилии. Всего в рассматриваемом датасете оказалось 187 303 автора, из которых 60 802 — женщины, 66 233 — мужчины, у 60 268 пол не был распознан. Последний результат частично связан с несовершенством метаданных в OpenAlex, но в большой степени со страновыми особенностями. Во-первых, пакет gender довольно часто не распознает азиатские и ближневосточные имена; во-вторых, в ряде стран (например, в Индии) принято указывать только инициалы и фамилию, что делает распознавание имени невозможным.
Итоговый массив составляет 18 238 публикаций, для которых распознан пол всех авторов. В нем мы выявили 3 079 публикаций, написанных чисто женскими коллективами, 3 940 — чисто мужскими. В 3 494 случаях число мужчин и женщин среди авторов было одинаковым. Также выяснилось, что чисто мужские коллективы обычно незначительно крупнее, чем чисто женские — 2,29 авторов-мужчин и 2,27 авторов-женщин в среднем.
Показательным также оказалось распределение по предметным областям. Наибольший разрыв по-прежнему сохраняется в инженерных дисциплинах — мужских коллективов более чем в два раза больше, чем женских, тогда как во всех науках о здоровье, включая общую медицину, число авторских женских коллективов значительно превосходит число мужских (причем это характерно только для нашей выборки по журналам RSCI — на общемировой выборке женщины имеют преимущество только в сестринском деле, общих науках о здоровье и нейронауках, причем перевес незначителен).
#аналитика #гомофилия #соавторство #OpenAlex
Недавно мы писали об исследовании гендерной гомофилии, опубликованном в PLoS ONE. Нас заинтересовало более актуальное положение в различных научных областях, прежде всего по российским источникам. Мы решили проанализировать публикации 2023 года на предмет гендерного распределения исследователей, основываясь на данных OpenAlex. Выборка состояла из журналов RSCI (включая их переводные версии).
Наш исходный датасет включал 42 353 публикации со следующими параметрами: тип публикации "article"; не менее двух авторов, год публикации = 2023. Для определения предполагаемого пола авторов использовался пакет gender в R, который рассчитывает вероятность того, является ли имя мужским или женским, основываясь на данных за 1932-2012 гг. Для имен, которые не удалось распознать, дополнительно анализировалось родовое окончание фамилии. Всего в рассматриваемом датасете оказалось 187 303 автора, из которых 60 802 — женщины, 66 233 — мужчины, у 60 268 пол не был распознан. Последний результат частично связан с несовершенством метаданных в OpenAlex, но в большой степени со страновыми особенностями. Во-первых, пакет gender довольно часто не распознает азиатские и ближневосточные имена; во-вторых, в ряде стран (например, в Индии) принято указывать только инициалы и фамилию, что делает распознавание имени невозможным.
Итоговый массив составляет 18 238 публикаций, для которых распознан пол всех авторов. В нем мы выявили 3 079 публикаций, написанных чисто женскими коллективами, 3 940 — чисто мужскими. В 3 494 случаях число мужчин и женщин среди авторов было одинаковым. Также выяснилось, что чисто мужские коллективы обычно незначительно крупнее, чем чисто женские — 2,29 авторов-мужчин и 2,27 авторов-женщин в среднем.
Показательным также оказалось распределение по предметным областям. Наибольший разрыв по-прежнему сохраняется в инженерных дисциплинах — мужских коллективов более чем в два раза больше, чем женских, тогда как во всех науках о здоровье, включая общую медицину, число авторских женских коллективов значительно превосходит число мужских (причем это характерно только для нашей выборки по журналам RSCI — на общемировой выборке женщины имеют преимущество только в сестринском деле, общих науках о здоровье и нейронауках, причем перевес незначителен).
#аналитика #гомофилия #соавторство #OpenAlex
{kind=link}
Три года «Выше квартилей» 🗓 🎆
Дорогие подписчики! Сегодня наш канал празднует свой третий день рождения. Мы традиционно составили подборку из десяти наиболее просматриваемых постов за прошедший год:
1️⃣ Академический угон: обзор публикаций о hijacked журналах
2️⃣ United2Act и борьба с paper mills
3️⃣ Чат-боты: цитировать или не цитировать?
4️⃣ Dark side of publishing
5️⃣ Королевство пустых зеркал
6️⃣ Retracted Articles: от репутационных проблем к аналитике по областям
7️⃣ Репозиторий НЦ на GitHub
8️⃣ Лейденский рейтинг: открытая версия
9️⃣ Les grands embrasements naissent de petites étincelles
1️⃣ 0️⃣ Обновление квартилей JCR
Уже второй год у нас активно выходила тематическая аналитика о нобелевских лауреатах под тегом #нобелевскаянеделя, практически каждую неделю — #обзор на одну из наиболее интересных свежих статей в нашей области и авторская #аналитика по различным библиометрическим базам и инструментам, а ежемесячно — #дайджест самых важных новостей в сфере науки и наукометрии со всего мира. Мы сделали цикл публикаций о недобросовестных исследовательских практиках, вели рубрику #историянаукометрии и неоднократно касались темы этичного использования #ИИ-инструментов в научной работе, а также во второй раз поучаствовали в фестивале науки «Республика ученых» ВШЭ.
Те из наших читателей, кто посещал фестиваль в прошлом году, возможно, помнят нашу наукометрическую викторину. И сегодня, в честь годовщины, мы хотим представить ее всем подписчикам нашего канала. Переходите по ссылке, играйте (с коллегами или друзьями) и делитесь впечатлениями!
Остаемся выше квартилей!
Дорогие подписчики! Сегодня наш канал празднует свой третий день рождения. Мы традиционно составили подборку из десяти наиболее просматриваемых постов за прошедший год:
Уже второй год у нас активно выходила тематическая аналитика о нобелевских лауреатах под тегом #нобелевскаянеделя, практически каждую неделю — #обзор на одну из наиболее интересных свежих статей в нашей области и авторская #аналитика по различным библиометрическим базам и инструментам, а ежемесячно — #дайджест самых важных новостей в сфере науки и наукометрии со всего мира. Мы сделали цикл публикаций о недобросовестных исследовательских практиках, вели рубрику #историянаукометрии и неоднократно касались темы этичного использования #ИИ-инструментов в научной работе, а также во второй раз поучаствовали в фестивале науки «Республика ученых» ВШЭ.
Те из наших читателей, кто посещал фестиваль в прошлом году, возможно, помнят нашу наукометрическую викторину. И сегодня, в честь годовщины, мы хотим представить ее всем подписчикам нашего канала. Переходите по ссылке, играйте (с коллегами или друзьями) и делитесь впечатлениями!
Остаемся выше квартилей!
Please open Telegram to view this post
VIEW IN TELEGRAM
Genially
HSE SCIENTOMETRICS BOARD
«Вероятно, да»: неопределенность в русскоязычных статьях
Задумывались ли вы о когда-нибудь о том, есть ли баланс в отношении использования выражений неопределенности в академическом письме? «Возможно», «вероятно», «гипотетически» — такие слова, с одной стороны, могут свидетельствовать об осторожности и педантичности ученого, пишущего статью, но с другой — демонстрировать (или казаться) признаком неуверенности. Стремясь избежать последнего, в ряде случаев исследователи могут намеренно или неосознанно начать использовать более «позитивный» язык, в котором меньше места отводится выражению сомнений, что, безусловно, влияет на восприятие исследовательских выводов.
В прошлом году китайские ученые провели масштабный анализ текстов статей в журнале "Science" за 1997-2021 гг., чтобы определить частоту использования выражений неопределенности (которые исследователи довольно метко назвали «хедж-словами») и возможные закономерности их изменения. Корпус состоял из 2600 статей, содержащих в общей сложности более 11 млн слов. Авторы провели детальный статистический анализ, в том числе по отдельными частям речи, и выяснили, что за 25 лет частота использования хедж-слов упала более чем на 40% — с 115.8 до 67.42 на 10 тысяч слов.
Мы решили проверить, подтверждаются ли эти наблюдения для работ на русском языке на основе данных OpenAlex c 2001 по 2024 г. и составили список слов, выражающих неопределенность, включая наречия, прилагательные, местоимения и частицы. При этом мы рассчитали отношение количества публикаций, содержащих каждое из хедж-слов, к общему числу публикаций на русском языке, так как полные тексты анализировались через n-граммы. Поскольку в OpenAlex реализована возможность полнотекстового поиска, мы ввели в качестве фильтра API-запроса наличие полнотекстовой версии (всего таких работ 241 615 из 2 138 926 за указанный период времени). Ограничением API OpenAlex и нашего анализа стала невозможность использования метасимволов (wildcards) в поиске, поэтому все леммы прописывались вручную.
Сгруппировав информацию о доле статей, содержащих хедж-слова, по годам и по укрупненным научным областям, мы получили график, приведенный по ссылке и на диаграмме, приложенной к посту. При таком методе анализа для русскоязычного сегмента, выводы китайских ученых подтверждаются лишь частично. В медицине и науках о жизни процентное соотношение хедж-слов стабильно низкое — не более 10 % за весь рассматриваемый период с незначительными колебаниями.
Для физических наук наблюдается резкий рост доли хедж-слов с 2005 по 2006 г., далее рост замедляется, а после 2008 года начинается постепенное неравномерное снижение, с локальными максимумами в 2012 и 2015 гг. В социальных науках постепенный рост использования выражений неопределенности начинается с 2013 года, в 2019-2020 показатель выходит на плато, а затем снижается, причем довольно стремительно.
Не вполне очевидно (присоединяемся к неуверенной когорте), говорит ли это о том, что российские ученые выбирают более аккуратные выражения, даже если текст выглядит от этого менее точным, или результаты продиктованы особенностями академического письма на русском языке.
В случае такого авторитетного журнала, как Science, использование хедж-слов может быть неявной стратегией продвижения своего исследования одновременно со снижением риска встретиться с критикой, спорами и сомнениями. Вместе с тем природа академического знания зачастую действительно неопределенна, поэтому поиск баланса (особенно в отдельных дисциплинах) продолжает оставаться нетривиальной задачей.
#аналитика #неопределенность #OpenAlex
Задумывались ли вы о когда-нибудь о том, есть ли баланс в отношении использования выражений неопределенности в академическом письме? «Возможно», «вероятно», «гипотетически» — такие слова, с одной стороны, могут свидетельствовать об осторожности и педантичности ученого, пишущего статью, но с другой — демонстрировать (или казаться) признаком неуверенности. Стремясь избежать последнего, в ряде случаев исследователи могут намеренно или неосознанно начать использовать более «позитивный» язык, в котором меньше места отводится выражению сомнений, что, безусловно, влияет на восприятие исследовательских выводов.
В прошлом году китайские ученые провели масштабный анализ текстов статей в журнале "Science" за 1997-2021 гг., чтобы определить частоту использования выражений неопределенности (которые исследователи довольно метко назвали «хедж-словами») и возможные закономерности их изменения. Корпус состоял из 2600 статей, содержащих в общей сложности более 11 млн слов. Авторы провели детальный статистический анализ, в том числе по отдельными частям речи, и выяснили, что за 25 лет частота использования хедж-слов упала более чем на 40% — с 115.8 до 67.42 на 10 тысяч слов.
Мы решили проверить, подтверждаются ли эти наблюдения для работ на русском языке на основе данных OpenAlex c 2001 по 2024 г. и составили список слов, выражающих неопределенность, включая наречия, прилагательные, местоимения и частицы. При этом мы рассчитали отношение количества публикаций, содержащих каждое из хедж-слов, к общему числу публикаций на русском языке, так как полные тексты анализировались через n-граммы. Поскольку в OpenAlex реализована возможность полнотекстового поиска, мы ввели в качестве фильтра API-запроса наличие полнотекстовой версии (всего таких работ 241 615 из 2 138 926 за указанный период времени). Ограничением API OpenAlex и нашего анализа стала невозможность использования метасимволов (wildcards) в поиске, поэтому все леммы прописывались вручную.
Сгруппировав информацию о доле статей, содержащих хедж-слова, по годам и по укрупненным научным областям, мы получили график, приведенный по ссылке и на диаграмме, приложенной к посту. При таком методе анализа для русскоязычного сегмента, выводы китайских ученых подтверждаются лишь частично. В медицине и науках о жизни процентное соотношение хедж-слов стабильно низкое — не более 10 % за весь рассматриваемый период с незначительными колебаниями.
Для физических наук наблюдается резкий рост доли хедж-слов с 2005 по 2006 г., далее рост замедляется, а после 2008 года начинается постепенное неравномерное снижение, с локальными максимумами в 2012 и 2015 гг. В социальных науках постепенный рост использования выражений неопределенности начинается с 2013 года, в 2019-2020 показатель выходит на плато, а затем снижается, причем довольно стремительно.
Не вполне очевидно (присоединяемся к неуверенной когорте), говорит ли это о том, что российские ученые выбирают более аккуратные выражения, даже если текст выглядит от этого менее точным, или результаты продиктованы особенностями академического письма на русском языке.
В случае такого авторитетного журнала, как Science, использование хедж-слов может быть неявной стратегией продвижения своего исследования одновременно со снижением риска встретиться с критикой, спорами и сомнениями. Вместе с тем природа академического знания зачастую действительно неопределенна, поэтому поиск баланса (особенно в отдельных дисциплинах) продолжает оставаться нетривиальной задачей.
#аналитика #неопределенность #OpenAlex
{kind=link}
Специальные выпуски: анализ уровней Белого списка
Сегодня мы хотим вернуться к теме специальных выпусков, которая продолжает оставаться весьма дискуссионной. Мы решили проанализировать публикации в специальных выпусках российских журналов, чтобы определить, есть ли взаимосвязь между количеством спецвыпусков и уровнем журнала.
Для анализа мы выбрали российские журналы, входящие в RSCI. Временной промежуток выборки — с 2021 по 2023 год. Данные были получены из БД OpenAlex, которая по-прежнему не полностью индексирует некоторые журналы, из-за чего в массиве встречались пропуски. Полученная выборка составила 956 журналов и 203 тысячи статей. Мы определили список различных вариантов названия спецвыпусков (например, Suppl.1, Special Issue, S1 и др.), хранящиеся в поле 'biblio.issue' в OpenAlex. Всего мы получили 35 вариаций обозначений, хотя и ожидаем, что в действительности их намного больше.
Согласно нашим данным, около 10 % (2043) статей из выборки относятся к специальным выпускам. Для дальнейшего анализа мы отобрали только те журналы, которые хотя бы один раз за рассматриваемый период времени публиковали спецвыпуски (всего их 46, а число публикаций в них — 13 402).
Первое, что обращает на себя внимание, — это средняя цитируемость, которая для общего массива составляет 1,259 цитат на материал, для статей из сквозных выпусков — 1,365, а для статей из спецвыпусков — 0,674, что вдвое ниже, чем общее среднее.
Опираясь на уровни журналов из Белого списка, мы проанализировали цитируемость и число публикаций для каждого из четырех уровней. Наиболее интересные результаты получены для последнего: в процентном соотношении статьи из спецвыпусков составляют 29% от общего числа публикаций в журналах 4 уровня со спецвыпусками, однако они получают всего 7,2% от общего числа цитат, а средняя цитируемость для них составляет 0,14.
Если же анализировать сами выпуски, то мы видим, что для журналов 1-3 уровней среднее число публикаций в спецвыпусках, как правило, вдвое меньше, чем число публикаций в выпусках сквозной нумерации. Для 4 уровня справедливо обратное — в спецвыпуске в среднем публикуется почти вдвое больше работ, чем в обычном. Мы проверили эту информацию в Elibrary, и обнаружили, что в качестве спецвыпусков нередко маркируются сборники докладов с форумов и конференций. С одной стороны, строго говоря, такие выпуски не являются специальными в узком понимании этого термина; с другой — они выходят за рамки сквозной нумерации, при этом публикуются нерегулярно и содержат значительное число работ (до 350).
Таким образом, наш базовый анализ показывает, что разница между спецвыпусками и регулярными выпусками журналов, с одной стороны, а также между журналами различных уровней Белого списка — с другой, несомненно, присутствует. На следующих этапах планируем глубже погрузиться в тему спецвыпусков с учетом сквозной нумерации.
#OpenAlex #специальныевыпуски #specialissues #БелыйСписок #аналитика
Сегодня мы хотим вернуться к теме специальных выпусков, которая продолжает оставаться весьма дискуссионной. Мы решили проанализировать публикации в специальных выпусках российских журналов, чтобы определить, есть ли взаимосвязь между количеством спецвыпусков и уровнем журнала.
Для анализа мы выбрали российские журналы, входящие в RSCI. Временной промежуток выборки — с 2021 по 2023 год. Данные были получены из БД OpenAlex, которая по-прежнему не полностью индексирует некоторые журналы, из-за чего в массиве встречались пропуски. Полученная выборка составила 956 журналов и 203 тысячи статей. Мы определили список различных вариантов названия спецвыпусков (например, Suppl.1, Special Issue, S1 и др.), хранящиеся в поле 'biblio.issue' в OpenAlex. Всего мы получили 35 вариаций обозначений, хотя и ожидаем, что в действительности их намного больше.
Согласно нашим данным, около 10 % (2043) статей из выборки относятся к специальным выпускам. Для дальнейшего анализа мы отобрали только те журналы, которые хотя бы один раз за рассматриваемый период времени публиковали спецвыпуски (всего их 46, а число публикаций в них — 13 402).
Первое, что обращает на себя внимание, — это средняя цитируемость, которая для общего массива составляет 1,259 цитат на материал, для статей из сквозных выпусков — 1,365, а для статей из спецвыпусков — 0,674, что вдвое ниже, чем общее среднее.
Опираясь на уровни журналов из Белого списка, мы проанализировали цитируемость и число публикаций для каждого из четырех уровней. Наиболее интересные результаты получены для последнего: в процентном соотношении статьи из спецвыпусков составляют 29% от общего числа публикаций в журналах 4 уровня со спецвыпусками, однако они получают всего 7,2% от общего числа цитат, а средняя цитируемость для них составляет 0,14.
Если же анализировать сами выпуски, то мы видим, что для журналов 1-3 уровней среднее число публикаций в спецвыпусках, как правило, вдвое меньше, чем число публикаций в выпусках сквозной нумерации. Для 4 уровня справедливо обратное — в спецвыпуске в среднем публикуется почти вдвое больше работ, чем в обычном. Мы проверили эту информацию в Elibrary, и обнаружили, что в качестве спецвыпусков нередко маркируются сборники докладов с форумов и конференций. С одной стороны, строго говоря, такие выпуски не являются специальными в узком понимании этого термина; с другой — они выходят за рамки сквозной нумерации, при этом публикуются нерегулярно и содержат значительное число работ (до 350).
Таким образом, наш базовый анализ показывает, что разница между спецвыпусками и регулярными выпусками журналов, с одной стороны, а также между журналами различных уровней Белого списка — с другой, несомненно, присутствует. На следующих этапах планируем глубже погрузиться в тему спецвыпусков с учетом сквозной нумерации.
#OpenAlex #специальныевыпуски #specialissues #БелыйСписок #аналитика
{kind=link}
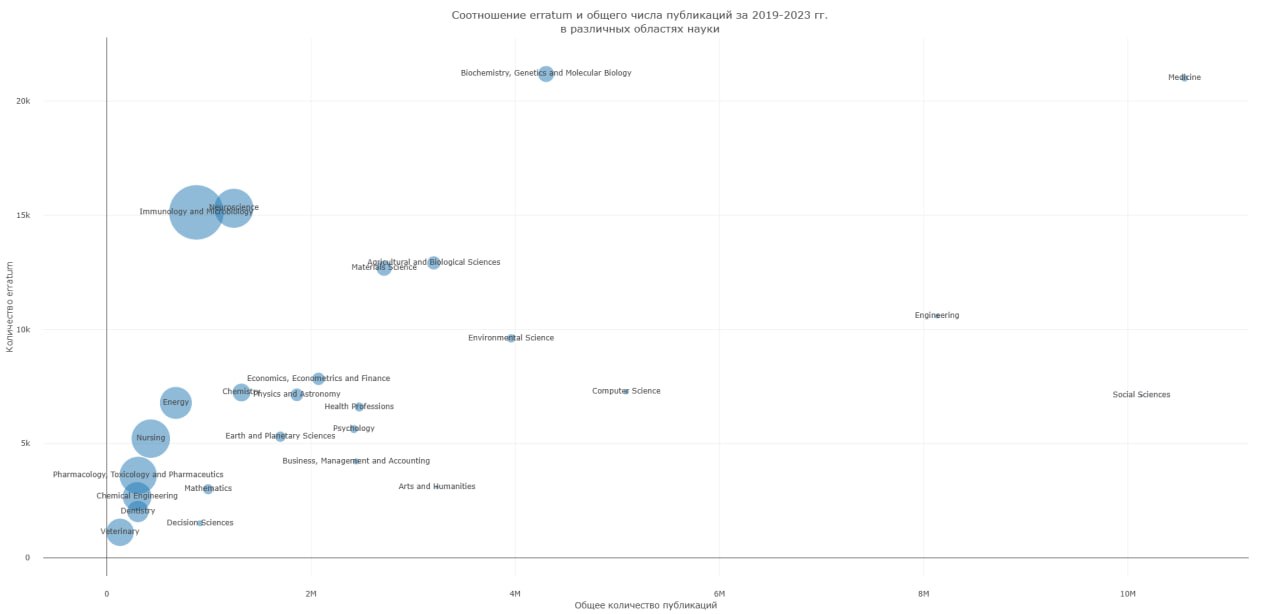
Публикационные и тематические паттерны публикаций erratum
В этом году мы неоднократно поднимали тему ретракции (отзыва) опубликованных статей в случае обнаружения грубых ошибок в методологии исследования или откровенной фальсификации данных. Однако нередко возникает ситуация, когда ошибка, обнаруженная в статье уже после публикации, является не слишком серьезной, но всё же влияет на смысл, и автор по собственной инициативе хочет внести исправления или дополнения, чтобы читатель верно понял содержание. В таких случаях журнал выпускает специальные типы публикаций: erratum (в случае, если ошибка была допущена издательством при обработке рукописи) или corrigendum (если ошибку допустил сам автор).
Такие публикации могут иметь разное название и тип в различных библиометрических базах: Correction, Addendum, Erratum и другие. Разумеется, такая практика является хорошим тоном в академической среде и служит доказательством серьезного и ответственного отношения к научной работе. Мы решили посмотреть, насколько характерна публикация erratum для различных издательств, и есть ли у них закономерности.
Для анализа мы загрузили из OpenAlex массив из 107 тыс. публикаций типа erratum за 2019-2023 гг. и дополнили датасет данными об общем количестве публикаций всех упомянутых издательств за тот же временной период. Из анализа исключены издательства, у которых было менее 1000 erratum за период, а также журналы, для которых не указаны издательства. По оси X отмечается общее количество публикаций, по оси Y - количество публикаций типа erratum, а размер точки отражает их соотношение.
Первое, что обращает на себя внимание — это экстремальный выброс, который представляет собой Elsevier BV. Более 4 млн. публикаций и более 23 тыс. статей-исправлений смещают график далеко вправо, при этом соотношение между этими двумя числами остается относительно невысоким. Если же убрать выброс, то картина получается следующей: общее число исправлений не превышает 10 тыс., а наиболее высокое соотношение наблюдается у American Medical Association (4,5%) и Nature Portfolio (2,8%).
Если же говорить об областях науки, то выбросом является медицина — на ее долю приходится 21 тыс. исправлений на 10,5 млн. публикаций, а в биохимии, генетике и молекулярной биологии — более 21 тыс. исправлений на 4 млн. публикаций. Довольно высокое соотношение исправлений в смежных областях — фармакологии, нейронауках, сестринском деле; максимума же соотношение достигает в иммунологии: 1,7%, или 15 тыс. исправлений на 878 тыс. публикаций.
Очевидно, что в науках о здоровье, где данные постоянно уточняются и корректируются после проведения дополнительных исследований и экспериментов, соотношение исправлений к общему числу статей велико. Но каковы же паттерны в других областях наук? На этот вопрос попробуем ответить уже в следующем году.
Поздравляем подписчиков с наступающими праздниками, и пусть ни одна ваша статья не нуждается в erratum!
#erratum #OpenAlex #аналитика #поздравление
В этом году мы неоднократно поднимали тему ретракции (отзыва) опубликованных статей в случае обнаружения грубых ошибок в методологии исследования или откровенной фальсификации данных. Однако нередко возникает ситуация, когда ошибка, обнаруженная в статье уже после публикации, является не слишком серьезной, но всё же влияет на смысл, и автор по собственной инициативе хочет внести исправления или дополнения, чтобы читатель верно понял содержание. В таких случаях журнал выпускает специальные типы публикаций: erratum (в случае, если ошибка была допущена издательством при обработке рукописи) или corrigendum (если ошибку допустил сам автор).
Такие публикации могут иметь разное название и тип в различных библиометрических базах: Correction, Addendum, Erratum и другие. Разумеется, такая практика является хорошим тоном в академической среде и служит доказательством серьезного и ответственного отношения к научной работе. Мы решили посмотреть, насколько характерна публикация erratum для различных издательств, и есть ли у них закономерности.
Для анализа мы загрузили из OpenAlex массив из 107 тыс. публикаций типа erratum за 2019-2023 гг. и дополнили датасет данными об общем количестве публикаций всех упомянутых издательств за тот же временной период. Из анализа исключены издательства, у которых было менее 1000 erratum за период, а также журналы, для которых не указаны издательства. По оси X отмечается общее количество публикаций, по оси Y - количество публикаций типа erratum, а размер точки отражает их соотношение.
Первое, что обращает на себя внимание — это экстремальный выброс, который представляет собой Elsevier BV. Более 4 млн. публикаций и более 23 тыс. статей-исправлений смещают график далеко вправо, при этом соотношение между этими двумя числами остается относительно невысоким. Если же убрать выброс, то картина получается следующей: общее число исправлений не превышает 10 тыс., а наиболее высокое соотношение наблюдается у American Medical Association (4,5%) и Nature Portfolio (2,8%).
Если же говорить об областях науки, то выбросом является медицина — на ее долю приходится 21 тыс. исправлений на 10,5 млн. публикаций, а в биохимии, генетике и молекулярной биологии — более 21 тыс. исправлений на 4 млн. публикаций. Довольно высокое соотношение исправлений в смежных областях — фармакологии, нейронауках, сестринском деле; максимума же соотношение достигает в иммунологии: 1,7%, или 15 тыс. исправлений на 878 тыс. публикаций.
Очевидно, что в науках о здоровье, где данные постоянно уточняются и корректируются после проведения дополнительных исследований и экспериментов, соотношение исправлений к общему числу статей велико. Но каковы же паттерны в других областях наук? На этот вопрос попробуем ответить уже в следующем году.
Поздравляем подписчиков с наступающими праздниками, и пусть ни одна ваша статья не нуждается в erratum!
#erratum #OpenAlex #аналитика #поздравление
{kind=link}
Как публикуются журналы РАН на платформе eLibrary?
В прошлом году многие телеграм-каналы и другие источники обратили внимание на то, что выпуски журналов РАН начали выходить с запозданием. В ноябре об этом написали даже «Ведомости». Мы со своей стороны обещали вернуться к рассмотрению темы в одном из наших прошлых дайджестов, и сейчас решили посмотреть, насколько заметным было отставание по данным eLibrary в сравнении с прошлыми годами.
Для анализа мы взяли список из 141 журнала РАН, опубликованный на сайте РЦНИ, сопоставили их с ID на eLibrary и добавили данные о дате выпусков по следующему принципу:
🔹 датой выпуска считается дата размещения первой статьи в каждом выпуске на сайте eLibrary,
🔹 числом выпусков в год считается максимальное число выпусков в год за последние 5 полных лет (2020-2024).
Таким образом, мы получили данные о 4934 выпусках. Сгруппировав их по годам и по числу выпусков в год, мы построили интерактивный график публикации по месяцам. По вертикальной оси откладывается общее число выпусков всех журналов, которые выходили в указанном месяце и относятся к конкретной категории по периодичности выпусков. На этом графике видны явные отклонения. Так, для всех журналов, выходящих с периодичностью 1-2 и 4-5 выпусков в год (всего их 19), в 2024 г. первые публикации были размещены не раньше июня, а для журналов, выходящих 8 раз в год (их всего 2), — не раньше июля.
Большинство журналов РАН выходят 6-7 либо 12 раз в год. Видно, что на графике присутствуют выпуски, выходившие в первой половине года, однако по факту это номера, которые формально относятся к 2024 г., но были размещены на eLibrary только в январе 2025.
Мысль о том, что в задержке публикаций виноваты не платформы, на которых они размещаются (ни РЦНИ, ни eLibrary) кажется достаточно тривиальной, однако мы считаем важным вновь ее подчеркнуть. Кроме того, сложившаяся картина интересует нас, прежде всего, с наукометрической точки зрения. Именно поэтому мы планируем продолжить тему, сравнив даты выхода выпусков на двух платформах, последствия задержек для видимости и цитируемости статей, размещенных в них.
#аналитика #диаграммы #РАН #РЦНИ #eLibrary
В прошлом году многие телеграм-каналы и другие источники обратили внимание на то, что выпуски журналов РАН начали выходить с запозданием. В ноябре об этом написали даже «Ведомости». Мы со своей стороны обещали вернуться к рассмотрению темы в одном из наших прошлых дайджестов, и сейчас решили посмотреть, насколько заметным было отставание по данным eLibrary в сравнении с прошлыми годами.
Для анализа мы взяли список из 141 журнала РАН, опубликованный на сайте РЦНИ, сопоставили их с ID на eLibrary и добавили данные о дате выпусков по следующему принципу:
🔹 датой выпуска считается дата размещения первой статьи в каждом выпуске на сайте eLibrary,
🔹 числом выпусков в год считается максимальное число выпусков в год за последние 5 полных лет (2020-2024).
Таким образом, мы получили данные о 4934 выпусках. Сгруппировав их по годам и по числу выпусков в год, мы построили интерактивный график публикации по месяцам. По вертикальной оси откладывается общее число выпусков всех журналов, которые выходили в указанном месяце и относятся к конкретной категории по периодичности выпусков. На этом графике видны явные отклонения. Так, для всех журналов, выходящих с периодичностью 1-2 и 4-5 выпусков в год (всего их 19), в 2024 г. первые публикации были размещены не раньше июня, а для журналов, выходящих 8 раз в год (их всего 2), — не раньше июля.
Большинство журналов РАН выходят 6-7 либо 12 раз в год. Видно, что на графике присутствуют выпуски, выходившие в первой половине года, однако по факту это номера, которые формально относятся к 2024 г., но были размещены на eLibrary только в январе 2025.
Мысль о том, что в задержке публикаций виноваты не платформы, на которых они размещаются (ни РЦНИ, ни eLibrary) кажется достаточно тривиальной, однако мы считаем важным вновь ее подчеркнуть. Кроме того, сложившаяся картина интересует нас, прежде всего, с наукометрической точки зрения. Именно поэтому мы планируем продолжить тему, сравнив даты выхода выпусков на двух платформах, последствия задержек для видимости и цитируемости статей, размещенных в них.
#аналитика #диаграммы #РАН #РЦНИ #eLibrary
{kind=link}