
PEP 734: Параллелизм без
Запланировано добавление нового стандартного модуля
Каждый подинтерпретатор имеет свой собственный GIL, то есть код может действительно выполняться параллельно (в отличие от обычных потоков). Нет накладных расходов на создание отдельных процессов и межпроцессное взаимодействие.
Уже сейчас доступен в виде пакета на PyPI:
#инструмент
@zen_of_python
🙉 — Если лучше не видеть, как это работает
multiprocessingЗапланировано добавление нового стандартного модуля
concurrent.interpreters. Он будет управлять несколькими изолированными подинтерпретаторами внутри одного процесса.Каждый подинтерпретатор имеет свой собственный GIL, то есть код может действительно выполняться параллельно (в отличие от обычных потоков). Нет накладных расходов на создание отдельных процессов и межпроцессное взаимодействие.
Уже сейчас доступен в виде пакета на PyPI:
interpreters-pep-734, который можно использовать с Python 3.12+.#инструмент
@zen_of_python
🙉 — Если лучше не видеть, как это работает
{kind=link}
⚡5😍3🙈2❤1
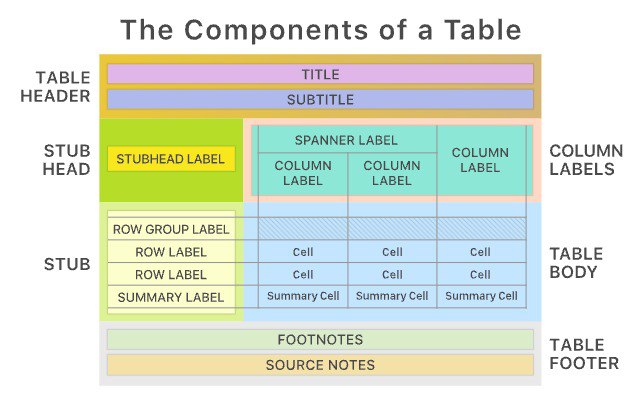
great-tables | Make Tables Great Again
Создатель этого репозитория напоминает нам, что у грамотной HTML-таблицы, помимо тела, есть еще (под)заголовок, футер и объединенные ячейки. Забытые возможности <table>...
Цена: бесплатно
Репозиторий проекта
#инструмент
@zen_of_python
Создатель этого репозитория напоминает нам, что у грамотной HTML-таблицы, помимо тела, есть еще (под)заголовок, футер и объединенные ячейки. Забытые возможности <table>...
Цена: бесплатно
Репозиторий проекта
#инструмент
@zen_of_python
{kind=link}
✍3🗿1
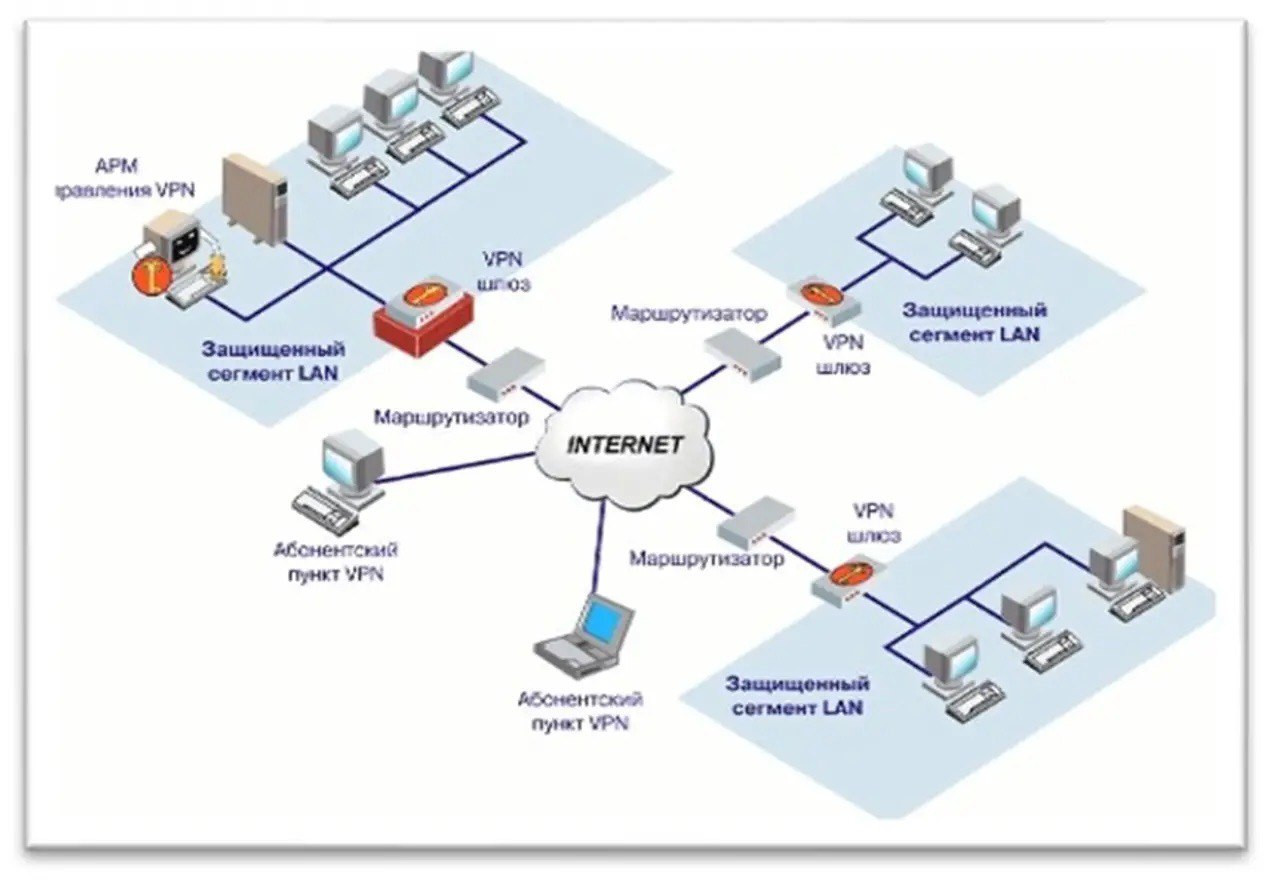
Виды компьютерных сетей
Белый хакер разложил по полочкам, какие бывают топологии систем: кольцо, шина, звезда, WLAN, WAN.
Суперпонятная статья для новичков и не только: вы точно почерпнете для себя что-то новое.
#основы
@zen_of_python
Белый хакер разложил по полочкам, какие бывают топологии систем: кольцо, шина, звезда, WLAN, WAN.
Суперпонятная статья для новичков и не только: вы точно почерпнете для себя что-то новое.
#основы
@zen_of_python
{kind=link}
❤🔥2❤2🍌1
This media is not supported in your browser
VIEW IN TELEGRAM
flowshow | отслеживайте задачи с графами
Предоставляет декоратор
Обеспечивает удобный визуальный интерфейс: после запуска
Жизнь в условиях проектов с асинхронностью в том числе станет чуточку легче.
На PyPi
#инструмент
@zen_of_python
Предоставляет декоратор
@task, который превращает обычную функцию в «таску» с автоматическим сбором метаданных.Обеспечивает удобный визуальный интерфейс: после запуска
main_job() можно вызвать main_job.plot() или main_job.last_run.render(), чтобы увидеть граф выполнения задач, время начала и окончания, входы и выходы, ошибки, логи и количества повторных запусков. Жизнь в условиях проектов с асинхронностью в том числе станет чуточку легче.
На PyPi
#инструмент
@zen_of_python
❤5✍1
Forwarded from Типичный программист
Основы PostgreSQL для начинающих: от установки до первых запросов
PostgreSQL — одна из самых мощных и популярных СУБД. Если вы только начинаете разбираться с ней, у нас есть понятный гайд: как всё установить на любую ОС, создать первую базу данных и выполнить базовые SQL-запросы. Заодно разобрали ключевые плюсы этой системы.
Бонусом: забирайте шпаргалку по БД и подборку игр для прокачки SQL-скиллов
Сохраняйте годноту👍
PostgreSQL — одна из самых мощных и популярных СУБД. Если вы только начинаете разбираться с ней, у нас есть понятный гайд: как всё установить на любую ОС, создать первую базу данных и выполнить базовые SQL-запросы. Заодно разобрали ключевые плюсы этой системы.
Бонусом: забирайте шпаргалку по БД и подборку игр для прокачки SQL-скиллов
Сохраняйте годноту
Please open Telegram to view this post
VIEW IN TELEGRAM
😁5👍2❤1
Type Hinting vs. Type Checking vs. Data Validation: в чём разница?
Python — это язык с динамической типизацией («тип переменной определяется во время выполнения программы»). Это даёт большую гибкость, но одновременно приводит к ошибкам. Чтобы справляться с этим, разработчики используют три инструмента: аннотации типов, проверка типов и валидация данных. У каждого из них своя цель.
Type Hinting — подсказки, а не контроль
Аннотации типов (Type Hinting) — это способ добавить метаинформацию о типах данных, которую Python сам по себе не использует для исполнения кода:
Интерпретатор, однако, игнорирует эти аннотации при исполнении. Они нужны исключительно для разработчика и инструментов анализа.
Type Checking
Проверка типов происходит до выполнения программы и помогает выявить несоответствия между ожидаемыми и фактическими типами, но не останавливает выполнение кода.
### Как работает:
Для статической проверки используется внешний инструмент, например, MyPy
Если передать строку вместо числа:
MyPy выдаст ошибку:
Важное ограничение: не проверяет данные из внешних источников (например, API).
Data Validation
Валидация данных — это уже проверка во время исполнения программы. Она позволяет остановить программу, если входные данные не соответствуют ожиданиям:
Ручная валидация быстро становится громоздкой. Здесь на помощь приходят библиотеки, такие как Pydantic.
Pydantic использует type hints для автоматической валидации данных. Пример с использованием
Если передать некорректный тип:
Вы получите подробное сообщение об ошибке:
#основы
@zen_of_python
Python — это язык с динамической типизацией («тип переменной определяется во время выполнения программы»). Это даёт большую гибкость, но одновременно приводит к ошибкам. Чтобы справляться с этим, разработчики используют три инструмента: аннотации типов, проверка типов и валидация данных. У каждого из них своя цель.
Type Hinting — подсказки, а не контроль
Аннотации типов (Type Hinting) — это способ добавить метаинформацию о типах данных, которую Python сам по себе не использует для исполнения кода:
def create_user(first_name: str, last_name: str, age: int) -> dict:
return {"first_name": first_name, "last_name": last_name, "age": age}
Интерпретатор, однако, игнорирует эти аннотации при исполнении. Они нужны исключительно для разработчика и инструментов анализа.
Type Checking
Проверка типов происходит до выполнения программы и помогает выявить несоответствия между ожидаемыми и фактическими типами, но не останавливает выполнение кода.
### Как работает:
Для статической проверки используется внешний инструмент, например, MyPy
mypy your_script.py
Если передать строку вместо числа:
create_user("John", "Doe", "38") # строка, а не int
MyPy выдаст ошибку:
error: Argument "age" to "create_user" has incompatible type "str"; expected "int"
Важное ограничение: не проверяет данные из внешних источников (например, API).
Data Validation
Валидация данных — это уже проверка во время исполнения программы. Она позволяет остановить программу, если входные данные не соответствуют ожиданиям:
if not isinstance(age, int):
raise TypeError("Age must be an integer")
Ручная валидация быстро становится громоздкой. Здесь на помощь приходят библиотеки, такие как Pydantic.
Pydantic использует type hints для автоматической валидации данных. Пример с использованием
@validate_call:
from pydantic import validate_call
@validate_call
def create_user(first_name: str, last_name: str, age: int) -> dict:
return {"first_name": first_name, "last_name": last_name, "age": age}
Если передать некорректный тип:
create_user("John", "Doe", "38") # строка
Вы получите подробное сообщение об ошибке:
1 validation error for create_user
age
Input should be a valid integer (type=type_error.integer)
#основы
@zen_of_python
mypy-lang.org
mypy - Optional Static Typing for Python
Mypy is an optional static type checker for Python.
👍7🌚1
{kind=link}
Вопросы подписчиков
Zen of Python поддерживает новоприбывших (и не только) в особой рубрике. Как это работает:
— Спрашивайте что угодно (в комментариях под этим постом), связанное с Python. Здесь нет плохих вопросов!
— Сообщество вас поддержит. Самые интересные вопросы мы разберём в отдельном посте;
#вопросы_новичков
@zen_of_python
Zen of Python поддерживает новоприбывших (и не только) в особой рубрике. Как это работает:
— Спрашивайте что угодно (в комментариях под этим постом), связанное с Python. Здесь нет плохих вопросов!
— Сообщество вас поддержит. Самые интересные вопросы мы разберём в отдельном посте;
#вопросы_новичков
@zen_of_python
👀1🆒1
{kind=link}
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
Zephyr | Действительно ВАШ умный девайс
Этот питонический фреймворк поддерживает 750+ материнских плат и делает устройства умными. Пишите свою логику и деплойте на плату: создатели стремились сделать процесс проще, чем у Arduino.
Цена: бесплатно
Сайт проекта
@prog_tools
Этот питонический фреймворк поддерживает 750+ материнских плат и делает устройства умными. Пишите свою логику и деплойте на плату: создатели стремились сделать процесс проще, чем у Arduino.
Цена: бесплатно
Сайт проекта
@prog_tools
❤8🆒1
pyrefly | Ну очень быстрый тайпчекер
В Meta (организация признана экстремистской в РФ) релизнули инструмент для проверки типов данных на базе Rust.
Он аналогичен
Взгляните на простой пример:
Так и работают тайп-чекеры: проверяют функции, методы, классы в файлах и целых репозиториях.
Для VS Code или других редакторов можно настроить команду форматирования или использовать
В кой-то век на бенчмарк-графике признались, что не самые первые.
На PyPi
#инструмент
@zen_of_python
В Meta (организация признана экстремистской в РФ) релизнули инструмент для проверки типов данных на базе Rust.
Он аналогичен
mypy, но сделано с упором на производительность. Это быстрая альтернатива для больших кодовых баз.Взгляните на простой пример:
def greet(name: str) -> str:
return "Hello, " + name
def add(a: int, b: int) -> int:
return a + b
result = add(1, "2") # Ошибка: "2" — это str, а не int
print(result)
Так и работают тайп-чекеры: проверяют функции, методы, классы в файлах и целых репозиториях.
Для VS Code или других редакторов можно настроить команду форматирования или использовать
pyrefly как pre-commit-хук. В кой-то век на бенчмарк-графике признались, что не самые первые.
На PyPi
#инструмент
@zen_of_python
✍4🐳1
py-pglite | PostgreSQL прямо через import
Инструмент для тестов с настоящим PostgreSQL без необходимости поднимать сервер. Он запускается за пару секунд прямо из Python-кода, без Docker и лишней настройки. Полностью совместим с SQLAlchemy, Django ORM, psycopg, asyncpg и поддерживает расширения вроде pgvector.
Цена: бесплатно
На PyPi
#инструмент
@zen_of_python
Инструмент для тестов с настоящим PostgreSQL без необходимости поднимать сервер. Он запускается за пару секунд прямо из Python-кода, без Docker и лишней настройки. Полностью совместим с SQLAlchemy, Django ORM, psycopg, asyncpg и поддерживает расширения вроде pgvector.
Цена: бесплатно
На PyPi
#инструмент
@zen_of_python
{kind=link}
👍2🆒1
Forwarded from Типичный программист
This media is not supported in your browser
VIEW IN TELEGRAM
Не понимаю, как я это упустил: Microsoft раскатила расширение, которое превращает VS Code в полноценную IDE для работы с PostgreSQL, без переключений между тулзами 👍
Внутри всё, что нужно:
• Визуализация схемы базы прямо в IDE.
• IntelliSense с автокомплитом и подсветкой и форматированием SQL-запросов.
• Запуск PostgreSQL в Docker.
• Быстрое подключение к любой базе (локально, в облаке).
• История запросов для быстрого повторного запуска.
• Просмотр и управление объектами БД.
• История запросов и запуск psql прямо из VS Code.
• Интеграция с GitHub Copilot — AI пишет и объясняет SQL
Поставить можно тут
Внутри всё, что нужно:
• Визуализация схемы базы прямо в IDE.
• IntelliSense с автокомплитом и подсветкой и форматированием SQL-запросов.
• Запуск PostgreSQL в Docker.
• Быстрое подключение к любой базе (локально, в облаке).
• История запросов для быстрого повторного запуска.
• Просмотр и управление объектами БД.
• История запросов и запуск psql прямо из VS Code.
• Интеграция с GitHub Copilot — AI пишет и объясняет SQL
Поставить можно тут
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥14❤5👍1
Молчаливый «провал» INSERT
Вы запускаете SQL-запрос
Как можно вставить данные и не вставить одновременно?
Когда
Виновник —
Здесь мы явно говорим: "если произойдёт конфликт по
Поведение UPSERT при множественных уникальных индекса
Представьте, что в таблице есть не один, а два уникальных индекса:
Теперь вы выполняете:
А если
Вставка завершится ошибкой!
Так происходит, потому что
Чтобы избежать этого, используем:
Тогда PostgreSQL проигнорирует конфликт по любому индексу. Но это может спровоцировать проблемы, особенно при вставке пачкой
Как отладить такую ситуацию?
— Проверяйте
— Добавьте
Если возвращается пустой результат — значит, вставки не было.
— Логируйте причину. Если вы используете логику вида
#sql
Вы запускаете SQL-запрос
INSERT, и вроде всё просто. Нет ошибок. Но и данные не вставлены. Звучит странно? Такое действительно может случиться с PostgreSQL — и случается чаще, чем хотелось бы.Как можно вставить данные и не вставить одновременно?
Когда
INSERT не срабатывает, первое, что приходит в голову — ошибка. Но PostgreSQL умеет «глотать» такое — ведь вы сами его об этом попросили.Виновник —
ON CONFLICT DO NOTHING
INSERT INTO users (id, email)
VALUES (42, '[email protected]')
ON CONFLICT (id) DO NOTHING;
Здесь мы явно говорим: "если произойдёт конфликт по
id, ничего не делай". И PostgreSQL по умолчанию так и поступает.Поведение UPSERT при множественных уникальных индекса
Представьте, что в таблице есть не один, а два уникальных индекса:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
email TEXT UNIQUE,
username TEXT UNIQUE
);
Теперь вы выполняете:
INSERT INTO users (email, username)
VALUES ('[email protected]', 'johnny');
А если
username = 'johnny' уже существует, но email ещё нет?Вставка завершится ошибкой!
Так происходит, потому что
ON CONFLICT (email) говорит PostgreSQL: «молчи, если конфликт по email, но бросай ошибку, если конфликт по чему-то ещё».Чтобы избежать этого, используем:
ON CONFLICT DO NOTHING
Тогда PostgreSQL проигнорирует конфликт по любому индексу. Но это может спровоцировать проблемы, особенно при вставке пачкой
Как отладить такую ситуацию?
— Проверяйте
rowcount после запроса. В Python/psycopg2, например:
cursor.execute(sql, values)
if cursor.rowcount == 0:
print("Nothing inserted!")
— Добавьте
RETURNING и логируйте:
INSERT INTO users (email, username)
VALUES ('[email protected]', 'johnny')
ON CONFLICT DO NOTHING
RETURNING id;
Если возвращается пустой результат — значит, вставки не было.
— Логируйте причину. Если вы используете логику вида
DO UPDATE, можно добавить логи в `UPDATE`-часть или сохранять «причину отказа» отдельно.#sql
👍9❤1🗿1
Комментарии в коде: зло или спасение?
Комментарий может не только объяснить код, но и быть бесячим. Грамотно написанные пометки значительно упрощают код-ревью. Кроме того, LLM'ки вроде GitHub Copilot используют комментарии как промты, а это сплошная экономия времени. В статье на Tproger порассуждали, где заканчивается польза и начинается вред от комментариев — и как найти правильный баланс.
#основы
@zen_of_python
Комментарий может не только объяснить код, но и быть бесячим. Грамотно написанные пометки значительно упрощают код-ревью. Кроме того, LLM'ки вроде GitHub Copilot используют комментарии как промты, а это сплошная экономия времени. В статье на Tproger порассуждали, где заканчивается польза и начинается вред от комментариев — и как найти правильный баланс.
#основы
@zen_of_python
🤔3❤2👌1🍌1
👎1🌚1
This media is not supported in your browser
VIEW IN TELEGRAM
crudadmin | Минималистичная админка для FastAPI
Симпатичный минималистичный GUI для самописных API. Поддерживает различные бэкенды для сессий (Redis, Memcached и БД). Встроенные механизмы защиты включают фильтрацию IP, защиту от DDoS-атак и подробный журнал событий.
Консоль доступна по адресу /admin в тёмной и светлой темах.
Цена: бесплатно
Репозиторий проекта
#инструмент
Симпатичный минималистичный GUI для самописных API. Поддерживает различные бэкенды для сессий (Redis, Memcached и БД). Встроенные механизмы защиты включают фильтрацию IP, защиту от DDoS-атак и подробный журнал событий.
Консоль доступна по адресу /admin в тёмной и светлой темах.
Цена: бесплатно
Репозиторий проекта
#инструмент
❤7✍2
MCP или еще один повод уважать Anthropic
Сегодня всё больше разработчиков задумываются о том, как подключить большие языковые модели (LLM) к своим инструментам и данным. Но сталкиваются с кучей проблем: модели изолированы, не понимают, что делает API, и не могут просто так «пойти» в интернет. И вот здесь появляется MCP (Model Context Protocol).
Это открытый стандарт, созданный Anthropic. Он решает ключевую проблему: как дать LLM доступ к внешним данным и инструментам, не ломая их внутреннюю безопасность.
Да, у нас есть RESTful API. Но:
— Большинство LLM работают в «песочнице» без доступа в интернет;
— Даже если бы доступ был, модель не знает, как вызвать ваш API, какие параметры использовать и как интерпретировать ответ.
MCP решает эту задачу: он описывает, что делает ваш сервис, как с ним работать и что возвращается в ответ.
Три типа возможностей
1. Resources — данные, которые можно "прочитать", аналог GET-запросов
2. Tools — функции, которые можно вызвать (например, поиск видео)
3. Prompts — шаблоны запросов, помогающие пользователю формировать нужный вызов.
Пример: YouTube
Структура:
1. Модуль YouTube-поиска — обёртка над пакетом
2. MCP-сервер — оборачивает этот модуль и превращает его в доступный инструмент для LLM.
И MCP-сервер, использующий этот модуль:
LLM теперь может вызывать
Автогенерация MCP из FastAPI
Если ваш API уже на FastAPI, вы можете автоматически создать MCP-интерфейс через
Но это подойдёт, если вы точно знаете, что API и MCP будут едины и не потребуется различать их архитектурно.
Где это уже используется?
Пример из видео — интеграция с Claude Desktop, где в конфигурации можно указать локальный MCP-сервер:
#LLM
Сегодня всё больше разработчиков задумываются о том, как подключить большие языковые модели (LLM) к своим инструментам и данным. Но сталкиваются с кучей проблем: модели изолированы, не понимают, что делает API, и не могут просто так «пойти» в интернет. И вот здесь появляется MCP (Model Context Protocol).
Это открытый стандарт, созданный Anthropic. Он решает ключевую проблему: как дать LLM доступ к внешним данным и инструментам, не ломая их внутреннюю безопасность.
Да, у нас есть RESTful API. Но:
— Большинство LLM работают в «песочнице» без доступа в интернет;
— Даже если бы доступ был, модель не знает, как вызвать ваш API, какие параметры использовать и как интерпретировать ответ.
MCP решает эту задачу: он описывает, что делает ваш сервис, как с ним работать и что возвращается в ответ.
Три типа возможностей
1. Resources — данные, которые можно "прочитать", аналог GET-запросов
2. Tools — функции, которые можно вызвать (например, поиск видео)
3. Prompts — шаблоны запросов, помогающие пользователю формировать нужный вызов.
Пример: YouTube
Структура:
1. Модуль YouTube-поиска — обёртка над пакетом
youtube-search2. MCP-сервер — оборачивает этот модуль и превращает его в доступный инструмент для LLM.
def search_youtube(query, max_results):
# Используем youtube_search
...
return result_dict
И MCP-сервер, использующий этот модуль:
from fast_mcp import FastMCP
server = FastMCP(name="videos")
server.add_tool("get_videos", search_youtube)
LLM теперь может вызывать
get_videos(), передав строку запроса — и получить отформатированный список роликов.Автогенерация MCP из FastAPI
Если ваш API уже на FastAPI, вы можете автоматически создать MCP-интерфейс через
fast_mcp.
from fast_mcp.contrib.fastapi import convert_app_to_mcp
app = FastAPI()
# ... API endpoints
mcp_server = convert_app_to_mcp(app)
Но это подойдёт, если вы точно знаете, что API и MCP будут едины и не потребуется различать их архитектурно.
Где это уже используется?
Пример из видео — интеграция с Claude Desktop, где в конфигурации можно указать локальный MCP-сервер:
{
"name": "YouTube Videos",
"command": "uv",
"args": {
"dir": "~/youtube_service",
"file": "run_mcp.py"
}
}
#LLM
❤7🗿1
Отслеживание неиспользуемых ключей в словаре Python
Словари — это фундаментальная структура данных, используемая для хранения пар «ключ-значение». В большинстве случаев мы просто читаем и записываем значения по ключам, не задумываясь о том, какие ключи были запрошены в процессе выполнения программы, а какие так и остались неиспользованными. Однако иногда в разработке возникает задача понять, какие ключи словаря так и не были использованы.
Представим, что у вас есть словарь с множеством параметров, который передаётся в функцию или класс. Вы хотите убедиться, что ваша логика действительно «потрогала» все ключи, и не осталось параметров, которые вы передали, но не использовали. Это особенно актуально, если словарь — это некий набор опций или конфигураций.
Без специальных инструментов проверить, какие ключи словаря не использовались, довольно сложно. Стандартный словарь в Python не хранит никакой информации о том, обращались ли к конкретному ключу.
Решения: словарь с учётом использования ключей
Для решения этой задачи можно создать класс-обёртку над обычным словарём, который при каждом запросе ключа будет отмечать этот ключ как «использованный».
Основные требования к такой структуре:
— При запросе значения по ключу отмечать ключ как использованный;
— Предоставлять метод, возвращающий ключи, к которым не обращались;
— Максимально просто и удобно использовать вместо обычного словаря.
Реализация: UsedDict
— Наследуемся от стандартного
— При инициализации создаём пустое множество
— Переопределяем метод
— Добавляем метод
Пример использования:
#основы
Словари — это фундаментальная структура данных, используемая для хранения пар «ключ-значение». В большинстве случаев мы просто читаем и записываем значения по ключам, не задумываясь о том, какие ключи были запрошены в процессе выполнения программы, а какие так и остались неиспользованными. Однако иногда в разработке возникает задача понять, какие ключи словаря так и не были использованы.
Представим, что у вас есть словарь с множеством параметров, который передаётся в функцию или класс. Вы хотите убедиться, что ваша логика действительно «потрогала» все ключи, и не осталось параметров, которые вы передали, но не использовали. Это особенно актуально, если словарь — это некий набор опций или конфигураций.
Без специальных инструментов проверить, какие ключи словаря не использовались, довольно сложно. Стандартный словарь в Python не хранит никакой информации о том, обращались ли к конкретному ключу.
Решения: словарь с учётом использования ключей
Для решения этой задачи можно создать класс-обёртку над обычным словарём, который при каждом запросе ключа будет отмечать этот ключ как «использованный».
Основные требования к такой структуре:
— При запросе значения по ключу отмечать ключ как использованный;
— Предоставлять метод, возвращающий ключи, к которым не обращались;
— Максимально просто и удобно использовать вместо обычного словаря.
Реализация: UsedDict
class UsedDict(dict):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._used_keys = set()
def __getitem__(self, key):
self._used_keys.add(key)
return super().__getitem__(key)
def get_unused_keys(self):
return set(self.keys()) - self._used_keys
— Наследуемся от стандартного
dict, чтобы сохранить привычный интерфейс;— При инициализации создаём пустое множество
_used_keys, в котором будем хранить все ключи, к которым обращались;— Переопределяем метод
__getitem__, который вызывается при чтении значения по ключу mydict[key]. В этом методе сначала отмечаем ключ как использованный, а затем возвращаем значение;— Добавляем метод
get_unused_keys, который возвращает разницу между всеми ключами словаря и теми, которые использовались.Пример использования:
config = UsedDict({
"host": "localhost",
"port": 8080,
"debug": True,
"timeout": 30
})
print(config["host"]) # используется
print(config["port"]) # используется
unused = config.get_unused_keys()
print("Неиспользованные ключи:", unused)
# Выведет: Неиспользованные ключи: {'debug', 'timeout'}
#основы
👎5👀2👍1