
Интеллектуальная вычислительная мощь Китая в 4 тыс раз больше России.
К 2030 отставание России может сократиться … до 3,5 тыс раз.
Эти кажущиеся бредом цифры следуют из сопоставления двух авторитетных источников.
1. Материалы стратегической сессии «Развитие искусственного интеллекта», проведенной правительством России 26 сентября 2023.
2. Совместный отчет International Data Corporation (IDC), китайского производителя серверов Inspur и Института глобальной промышленности Университета Цинхуа «2022-2023 Оценка развития вычислительной мощности искусственного интеллекта в Китае».
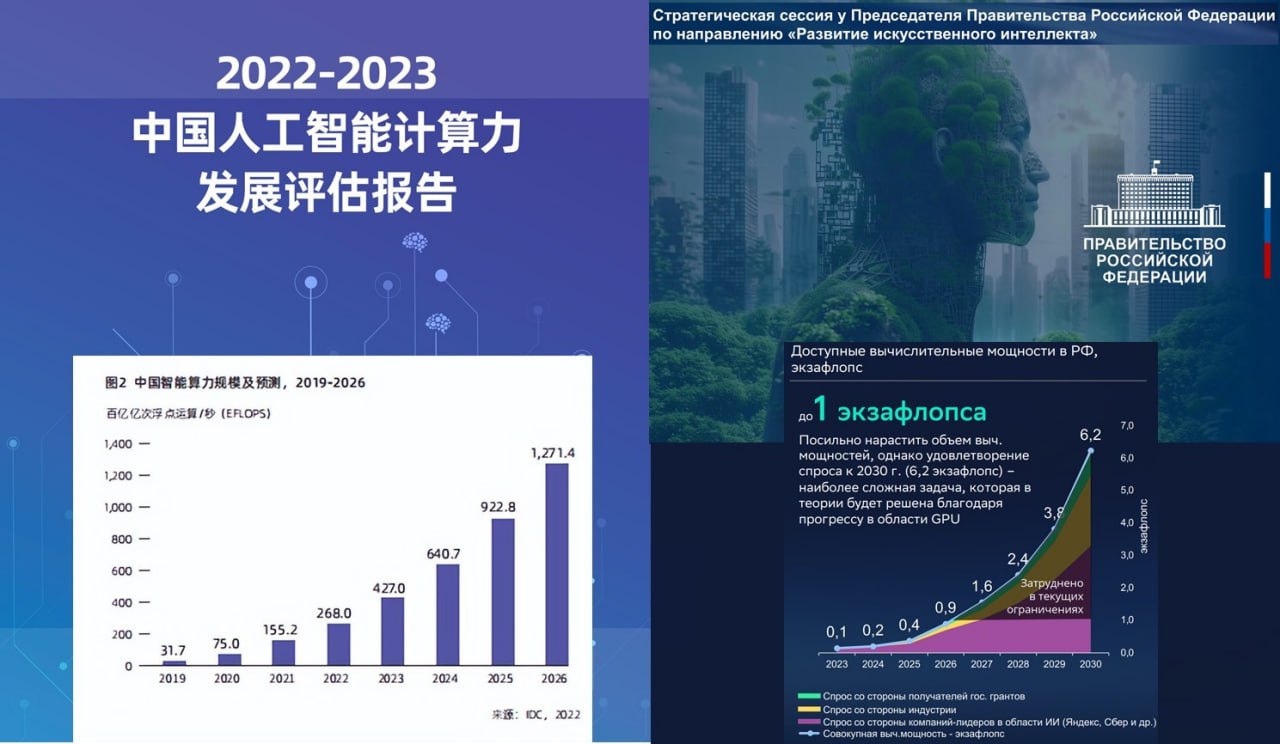
Первый из названных документов предполагает следующее:
• В России вычислительная мощность инфраструктуры исследований, разработок и применения ИИ вырастет с нынешних примерно 0.1 экзафлопса до 1 экзафлопса в 2027.
• Увеличение этого показателя к 2030 возможно лишь теоретически, «благодаря прогрессу в области GPU» (что это за прогресс, чей прогресс и за счет чего, - в материалах не указано).
• Рассуждая же практически, 1 экзафлопс вычислительной мощности может так и остаться непревзойденным максимумом вычислительной мощности российской ИИ инфраструктуры вплоть до 2030 (хотя потребности вычислительной мощности инфраструктуры ИИ к тому времени составят 6,2 экзафлопса).
Второй из вышеназванных документов сообщает и предполагает абсолютно несравнимые по масштабу цифры:
• Сейчас (в 2023) вычислительная мощность инфраструктуры исследований, разработок и применения ИИ в Китае составляет около 427 экзафлопсов.
• Планируется, что к 2026 эта величина вырастет до 1271 экзафлопса.
• К 2030 году, как легко подсчитать самостоятельно на основе приведенных в отчете данных, вычислительная мощность инфраструктуры исследований, разработок и применения ИИ может составить в Китае примерно 3550 экзафлопса (или 3,55 зетафлопса).
Также напомню, что в США вычислительная мощность инфраструктуры исследований, разработок и применения ИИ сейчас, где-то на 30-40% больше, чем у Китая (а к 2030 США планируют оторваться примерно в 2 раза за счет экспортных ограничений на микроэлектронику).
В заключение, мне остается лишь с сожалением заметить вот что.
Зря глава Сбера Герман Греф не начал свой 1й доклад на стратегической сессию с уже цитировавшегося им ранее анекдота про снаряды:
«Здесь как в том анекдоте: назовите три причины, почему следует отступить? Причина первая: у нас нет снарядов. Вот так же и здесь: у нас нет такого количества снарядов».
Ведь и с развитием ИИ то же самое: если нет и не планируется в России обретение ИИ инфраструктуры, обладающей хоть как-то сопоставимой вычислительной мощностью, обсуждать пути преодоления остальных шести вызовов (что обсуждались на сессии) нет смысла.
Об этом я предупреждаю уже не один год в своих постах под грифом «Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке»
#ИИ #Компьютинг #Россия #Китай
К 2030 отставание России может сократиться … до 3,5 тыс раз.
Эти кажущиеся бредом цифры следуют из сопоставления двух авторитетных источников.
1. Материалы стратегической сессии «Развитие искусственного интеллекта», проведенной правительством России 26 сентября 2023.
2. Совместный отчет International Data Corporation (IDC), китайского производителя серверов Inspur и Института глобальной промышленности Университета Цинхуа «2022-2023 Оценка развития вычислительной мощности искусственного интеллекта в Китае».
Первый из названных документов предполагает следующее:
• В России вычислительная мощность инфраструктуры исследований, разработок и применения ИИ вырастет с нынешних примерно 0.1 экзафлопса до 1 экзафлопса в 2027.
• Увеличение этого показателя к 2030 возможно лишь теоретически, «благодаря прогрессу в области GPU» (что это за прогресс, чей прогресс и за счет чего, - в материалах не указано).
• Рассуждая же практически, 1 экзафлопс вычислительной мощности может так и остаться непревзойденным максимумом вычислительной мощности российской ИИ инфраструктуры вплоть до 2030 (хотя потребности вычислительной мощности инфраструктуры ИИ к тому времени составят 6,2 экзафлопса).
Второй из вышеназванных документов сообщает и предполагает абсолютно несравнимые по масштабу цифры:
• Сейчас (в 2023) вычислительная мощность инфраструктуры исследований, разработок и применения ИИ в Китае составляет около 427 экзафлопсов.
• Планируется, что к 2026 эта величина вырастет до 1271 экзафлопса.
• К 2030 году, как легко подсчитать самостоятельно на основе приведенных в отчете данных, вычислительная мощность инфраструктуры исследований, разработок и применения ИИ может составить в Китае примерно 3550 экзафлопса (или 3,55 зетафлопса).
Также напомню, что в США вычислительная мощность инфраструктуры исследований, разработок и применения ИИ сейчас, где-то на 30-40% больше, чем у Китая (а к 2030 США планируют оторваться примерно в 2 раза за счет экспортных ограничений на микроэлектронику).
В заключение, мне остается лишь с сожалением заметить вот что.
Зря глава Сбера Герман Греф не начал свой 1й доклад на стратегической сессию с уже цитировавшегося им ранее анекдота про снаряды:
«Здесь как в том анекдоте: назовите три причины, почему следует отступить? Причина первая: у нас нет снарядов. Вот так же и здесь: у нас нет такого количества снарядов».
Ведь и с развитием ИИ то же самое: если нет и не планируется в России обретение ИИ инфраструктуры, обладающей хоть как-то сопоставимой вычислительной мощностью, обсуждать пути преодоления остальных шести вызовов (что обсуждались на сессии) нет смысла.
Об этом я предупреждаю уже не один год в своих постах под грифом «Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке»
#ИИ #Компьютинг #Россия #Китай
{kind=link}
Скрытый потенциал русского ИИ для преодоления отставания от США и Китая.
Что если разрешить русским LLM материться без ограничений?
«Русский мат — … это не просто скабрезные ругательства. Это еще и эмоциональная беседа мужчин в критических ситуациях. Исконной матерной речью пользовались в мужских компаниях, и не для того, чтобы обругать друг друга, а чтобы весело, быстро, понятно и эмоционально объясниться друг с другом в экстремальных условиях, в опасных ситуациях. Такая речь обладает мощным не только психологическим, но, как показано выше, и физиологическим действием.»
Доктор психологических наук Леонид Александрович Китаев-Смык
Сразу предупрежу: это не шутка, не ирония и уж тем более не издевка.
На современном этапе развития ИИ все упирается в наличие огромных вычислительных мощностей, требуемых для обучения гигантских нейросетей-трансформеров. Об этом я талдычу уже несколько лет в постах под грифом «Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке» [1, 2, 3]
Но экспортные ограничения крепчают. Их преодоление становится все накладней, и требуемый массовый характер таких поставок в Россию уже не видится реальным.
Разработка своего железа на горизонте достижимости в несколько лет тоже нереальна, т.к. на это требуются десятки миллиардов долларов и десятки лет. А для создания стратегической системы поставок, подобной китайской, среди российских госчиновников маловато китайцев.
В этой тупиковой ситуации остается надеяться либо на чудо, либо на какой-то уж совсем немыслимый творческий кульбит – некую фантастически перспективную идею.
Как у нас водится, примеров предложений таких, якобы, перспективных идей хватает во всех сегментах разработок российского ИИ: от, будто бы, небывало эффективных новых архитектур, до хитрейших и гениальных (по мнению их авторов) новых алгоритмов.
Но все они, в моем представлении, уступают по шедевриальности вот этой идее, недавно прозвучавшей в кулуарах крупной тусовки российских ИИ-разработчиков – новый класс матерящихся языковых моделей.
Речь об использовании уникального ресурсного языкового богатства русского языка (русского мата), потенциально способного стать ключевым конкурентным преимуществом больших языковых моделей, обучающихся на нерецензируемом корпусе русский текстов и не имеющих никаких ограничений на использование нецензурной лексики.
Эта довольно дикая на первый взгляд идея, по мысли ее сторонников, стоит на трёх слонах и черепахе по имени «аффорданс» (описание которых не умещается в ограниченный размер Телеграм поста и потому вынесено в лонгрид для подписчиков на Patreon, Boosty, VK и Дзен – подписывайтесь, ибо текст весьма интересный 😊).
Здесь же, из-за недостатка места, я лишь назову три связанных друг с другом следствия этой идеи.
1) Новейшее метаисследование пяти солидных академических центров показывает, что с точки зрения практического применения, «ругань представляет собой малорискованное, эффективное и недорогое вмешательство, которое может существенно улучшить физическую работоспособность» людей (см. рисунок).
2) Резонно предположить, что, будучи частью языка, ругань может быть использована языковыми моделями с большей лингвистической, семантической и эмоциональной эффективностью, чем это достижимо для людей.
3) При снятии цензурных ограничений при обучении и использовании LLM, уникальное преимущество русского мата могло бы стать малорискованным, эффективным и недорогим вмешательством, способным существенно улучшить интеллектуальную работоспособность не только языковых моделей, но и работающих с ними в гибридном режиме людей.
Своих комментариев на эту офигительную идею я давать не буду, дабы не портить одним читателям возможность ее уничижительной критики, а другим - ее восторженной поддержки.
Скажу лишь, что мое подробное обсуждение с пятью LLM (четырьмя американскими и одной китайской) показало их весьма позитивное отношение к этой «плодотворной дебютной идее».
#ИИгонка #Россия #Аффорданс
Что если разрешить русским LLM материться без ограничений?
«Русский мат — … это не просто скабрезные ругательства. Это еще и эмоциональная беседа мужчин в критических ситуациях. Исконной матерной речью пользовались в мужских компаниях, и не для того, чтобы обругать друг друга, а чтобы весело, быстро, понятно и эмоционально объясниться друг с другом в экстремальных условиях, в опасных ситуациях. Такая речь обладает мощным не только психологическим, но, как показано выше, и физиологическим действием.»
Доктор психологических наук Леонид Александрович Китаев-Смык
Сразу предупрежу: это не шутка, не ирония и уж тем более не издевка.
На современном этапе развития ИИ все упирается в наличие огромных вычислительных мощностей, требуемых для обучения гигантских нейросетей-трансформеров. Об этом я талдычу уже несколько лет в постах под грифом «Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке» [1, 2, 3]
Но экспортные ограничения крепчают. Их преодоление становится все накладней, и требуемый массовый характер таких поставок в Россию уже не видится реальным.
Разработка своего железа на горизонте достижимости в несколько лет тоже нереальна, т.к. на это требуются десятки миллиардов долларов и десятки лет. А для создания стратегической системы поставок, подобной китайской, среди российских госчиновников маловато китайцев.
В этой тупиковой ситуации остается надеяться либо на чудо, либо на какой-то уж совсем немыслимый творческий кульбит – некую фантастически перспективную идею.
Как у нас водится, примеров предложений таких, якобы, перспективных идей хватает во всех сегментах разработок российского ИИ: от, будто бы, небывало эффективных новых архитектур, до хитрейших и гениальных (по мнению их авторов) новых алгоритмов.
Но все они, в моем представлении, уступают по шедевриальности вот этой идее, недавно прозвучавшей в кулуарах крупной тусовки российских ИИ-разработчиков – новый класс матерящихся языковых моделей.
Речь об использовании уникального ресурсного языкового богатства русского языка (русского мата), потенциально способного стать ключевым конкурентным преимуществом больших языковых моделей, обучающихся на нерецензируемом корпусе русский текстов и не имеющих никаких ограничений на использование нецензурной лексики.
Эта довольно дикая на первый взгляд идея, по мысли ее сторонников, стоит на трёх слонах и черепахе по имени «аффорданс» (описание которых не умещается в ограниченный размер Телеграм поста и потому вынесено в лонгрид для подписчиков на Patreon, Boosty, VK и Дзен – подписывайтесь, ибо текст весьма интересный 😊).
Здесь же, из-за недостатка места, я лишь назову три связанных друг с другом следствия этой идеи.
1) Новейшее метаисследование пяти солидных академических центров показывает, что с точки зрения практического применения, «ругань представляет собой малорискованное, эффективное и недорогое вмешательство, которое может существенно улучшить физическую работоспособность» людей (см. рисунок).
2) Резонно предположить, что, будучи частью языка, ругань может быть использована языковыми моделями с большей лингвистической, семантической и эмоциональной эффективностью, чем это достижимо для людей.
3) При снятии цензурных ограничений при обучении и использовании LLM, уникальное преимущество русского мата могло бы стать малорискованным, эффективным и недорогим вмешательством, способным существенно улучшить интеллектуальную работоспособность не только языковых моделей, но и работающих с ними в гибридном режиме людей.
Своих комментариев на эту офигительную идею я давать не буду, дабы не портить одним читателям возможность ее уничижительной критики, а другим - ее восторженной поддержки.
Скажу лишь, что мое подробное обсуждение с пятью LLM (четырьмя американскими и одной китайской) показало их весьма позитивное отношение к этой «плодотворной дебютной идее».
#ИИгонка #Россия #Аффорданс