
В Китае ИИ-врачи натренировались на ИИ-пациентах лечить пациентов-людей лучше, чем люди-врачи
В китайском симулякре больницы Е-врачи (в их роли выступают автономные агенты на базе больших языковых моделей - AALLM) проводят лечение Е-пациентов (в их роли другие AALLM), «болеющих» реальными человеческими респираторными заболеваниями (динамику которых моделируют также LLM, имеющие доступ к обширной базе медицинской информации, полученной при лечении реальных пациентов).
Цель имитационного эксперимента - дать возможность Е-врачам при лечении Е-пациентов набираться знаний, чтобы научиться лучше лечить болезни реальных людей в реальной жизни.
В ходе короткого эксперимента Е-врачи пролечили 10 тыс Е-пациентов (на что в реальной жизни ушло бы, минимум, два года).
Результат сногсшибательный. Повысившие свою квалификацию в ходе этого имитационного эксперимента Е-врачи достигли высочайшей точности 93,06% в подмножестве набора данных MedQA, охватывающем основные респираторные заболевания.
Подробности здесь https://arxiv.org/abs/2405.02957
#Медицина #Китай #LLM
В китайском симулякре больницы Е-врачи (в их роли выступают автономные агенты на базе больших языковых моделей - AALLM) проводят лечение Е-пациентов (в их роли другие AALLM), «болеющих» реальными человеческими респираторными заболеваниями (динамику которых моделируют также LLM, имеющие доступ к обширной базе медицинской информации, полученной при лечении реальных пациентов).
Цель имитационного эксперимента - дать возможность Е-врачам при лечении Е-пациентов набираться знаний, чтобы научиться лучше лечить болезни реальных людей в реальной жизни.
В ходе короткого эксперимента Е-врачи пролечили 10 тыс Е-пациентов (на что в реальной жизни ушло бы, минимум, два года).
Результат сногсшибательный. Повысившие свою квалификацию в ходе этого имитационного эксперимента Е-врачи достигли высочайшей точности 93,06% в подмножестве набора данных MedQA, охватывающем основные респираторные заболевания.
Подробности здесь https://arxiv.org/abs/2405.02957
#Медицина #Китай #LLM
arXiv.org
Agent Hospital: A Simulacrum of Hospital with Evolvable Medical Agents
In this paper, we introduce a simulacrum of hospital called Agent Hospital that simulates the entire process of treating illness. All patients, nurses, and doctors are autonomous agents powered by...
Первая вселенская спецоперация Новацена
Может ли генеративный ИИ предотвратить смерть познающего космоса
Cогласно опубликованным Nature результатам нового совместного исследования университетов Калифорнии, Канзаса и MIT (авторы — известные ученые: Бил Томлинсон, Рэбека Блэк, Дональд Паттерсон, Эндрю Торранс),
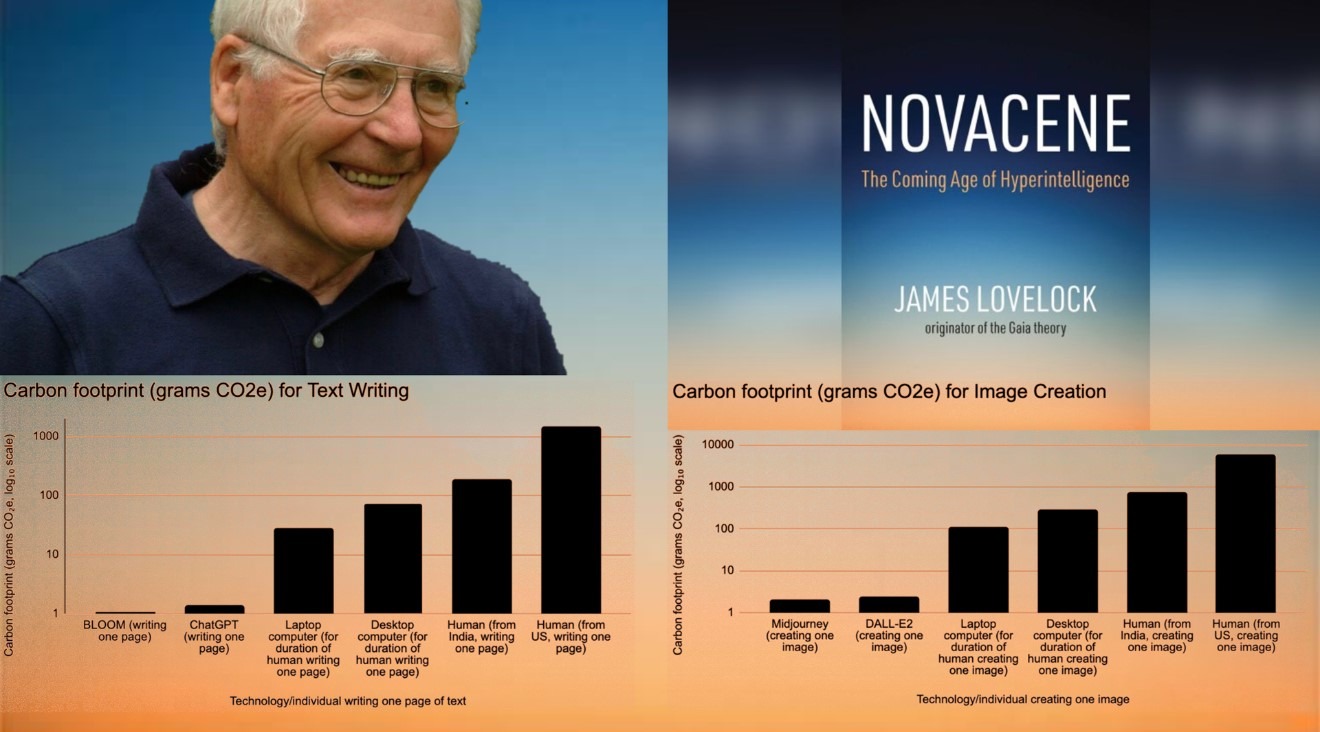
системы на основе генеративного ИИ (ChatGPT, Claude, DALL-E2, Midjourney и т.п.) создают литературные и художественные произведения с несравнимо меньшими выбросами углерода, чем люди.
Разница в углеродном следе людей и генеративного ИИ огромна: создание контента в форме всевозможных текстов и изображений с помощью систем генеративного ИИ влечет выделение на 3–4 порядка меньших объемов CO2, чем при создании того же контента людьми (работают ли люди вручную или с помощью компьютеров).
Еще более интригующая трактовка нового исследования может получиться, если посмотреть на роль генеративного ИИ, как радикального средства снижения выбросов СО2 на Земле, через призму теорий Джеймса Лавлока
— величайшего экологического мыслителя нашего времени, интеллектуала масштаба Леонардо да Винчи, исследователя, инженера, автора десятков изобретений и создателя теории Геи (Земли как биологического существа, для которого ноосфера В.И.Вернадского — частный случай), члена Лондонского королевского общества, командора Ордена Британской Империи и Ордена Почетных кавалеров.
Ибо взгляд на результаты исследования Томлинсона — Блэк — Паттерсона — Торранс в контексте размышлений и прогнозов Лавлока, позволяет трактовать появление Генеративного ИИ с совершенно новой и абсолютно неординарной точки зрения:
Как первую вселенскую спецоперацию Геи в Новацене с целью— не дать людям угробить жизнь во Вселенной до появления здесь сверхразума (что было бы равносильно смерти познающего космоса).
Подозреваю, что у многих прочитавших эти строки возникла ассоциация со всевозможной околонаучной конспирологией или, в лучшем случае, — с фантастической беллетристикой. Но не спешите делать выводы.
По крайней мере, до того, как прочтете до конца этот пост. Ведь речь пойдет о размышлениях и прогнозах Джеймса Лавлока — человека во многом уникального.
• Ученый, имеющий репутацию того, “чьи прогнозы всегда сбываются”, и к концу своей более чем вековой жизни прозванный в весьма серьёзных и влиятельных изданиях — «Пророк».
• Трансдисциплинарный исследователь, выигрывавший за счет своей феноменальной интуиции исследователя в яростных научных спорах даже с такими признанными авторитетами, как Уильям Дональд Гамильтон, Джон Мейнард Смит и Ричард Докинз.
• Почетный доктор наук восьми университетов, о научном вкладе которого известный британский климатолог и эколог Тим Лентон сказал: «Будущие историки науки увидят в Лавлоке человека, который вдохновил Коперниканский сдвиг в том, как мы видим себя в мире».
• Почетный кавалер Ее Величества Королевы Великобритании (коих одновременно бывает всего 65 человек).
Одним словом, — гений (о чем стоит рассказать поподробней, ибо это самое что ни на есть малоизвестное интересное).
– читайте дальше на Boosty и Patreon
P.S. С подпиской не обессудьте. Подобные лонгриды пишутся не за час. И чтобы продолжать, хотелось бы знать, скольким из 140К подписчиков на 4 платформах эти тексты реально интересны и ценны.
P.P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я пришлю текст (надеюсь, в этот раз подписчиков все же окажется больше 😊)
Картинка https://telegra.ph/file/72aa4380645d5f51af143.jpg
Лонгрид
https://www.patreon.com/posts/104312579
https://boosty.to/theworldisnoteasy/posts/2b9b478f-a598-400a-a991-fc78a7fa4135
#ИзменениеКлимата #Лавлок #Гея #Новацен
Может ли генеративный ИИ предотвратить смерть познающего космоса
Cогласно опубликованным Nature результатам нового совместного исследования университетов Калифорнии, Канзаса и MIT (авторы — известные ученые: Бил Томлинсон, Рэбека Блэк, Дональд Паттерсон, Эндрю Торранс),
системы на основе генеративного ИИ (ChatGPT, Claude, DALL-E2, Midjourney и т.п.) создают литературные и художественные произведения с несравнимо меньшими выбросами углерода, чем люди.
Разница в углеродном следе людей и генеративного ИИ огромна: создание контента в форме всевозможных текстов и изображений с помощью систем генеративного ИИ влечет выделение на 3–4 порядка меньших объемов CO2, чем при создании того же контента людьми (работают ли люди вручную или с помощью компьютеров).
Еще более интригующая трактовка нового исследования может получиться, если посмотреть на роль генеративного ИИ, как радикального средства снижения выбросов СО2 на Земле, через призму теорий Джеймса Лавлока
— величайшего экологического мыслителя нашего времени, интеллектуала масштаба Леонардо да Винчи, исследователя, инженера, автора десятков изобретений и создателя теории Геи (Земли как биологического существа, для которого ноосфера В.И.Вернадского — частный случай), члена Лондонского королевского общества, командора Ордена Британской Империи и Ордена Почетных кавалеров.
Ибо взгляд на результаты исследования Томлинсона — Блэк — Паттерсона — Торранс в контексте размышлений и прогнозов Лавлока, позволяет трактовать появление Генеративного ИИ с совершенно новой и абсолютно неординарной точки зрения:
Как первую вселенскую спецоперацию Геи в Новацене с целью— не дать людям угробить жизнь во Вселенной до появления здесь сверхразума (что было бы равносильно смерти познающего космоса).
Подозреваю, что у многих прочитавших эти строки возникла ассоциация со всевозможной околонаучной конспирологией или, в лучшем случае, — с фантастической беллетристикой. Но не спешите делать выводы.
По крайней мере, до того, как прочтете до конца этот пост. Ведь речь пойдет о размышлениях и прогнозах Джеймса Лавлока — человека во многом уникального.
• Ученый, имеющий репутацию того, “чьи прогнозы всегда сбываются”, и к концу своей более чем вековой жизни прозванный в весьма серьёзных и влиятельных изданиях — «Пророк».
• Трансдисциплинарный исследователь, выигрывавший за счет своей феноменальной интуиции исследователя в яростных научных спорах даже с такими признанными авторитетами, как Уильям Дональд Гамильтон, Джон Мейнард Смит и Ричард Докинз.
• Почетный доктор наук восьми университетов, о научном вкладе которого известный британский климатолог и эколог Тим Лентон сказал: «Будущие историки науки увидят в Лавлоке человека, который вдохновил Коперниканский сдвиг в том, как мы видим себя в мире».
• Почетный кавалер Ее Величества Королевы Великобритании (коих одновременно бывает всего 65 человек).
Одним словом, — гений (о чем стоит рассказать поподробней, ибо это самое что ни на есть малоизвестное интересное).
– читайте дальше на Boosty и Patreon
P.S. С подпиской не обессудьте. Подобные лонгриды пишутся не за час. И чтобы продолжать, хотелось бы знать, скольким из 140К подписчиков на 4 платформах эти тексты реально интересны и ценны.
P.P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я пришлю текст (надеюсь, в этот раз подписчиков все же окажется больше 😊)
Картинка https://telegra.ph/file/72aa4380645d5f51af143.jpg
Лонгрид
https://www.patreon.com/posts/104312579
https://boosty.to/theworldisnoteasy/posts/2b9b478f-a598-400a-a991-fc78a7fa4135
#ИзменениеКлимата #Лавлок #Гея #Новацен
{kind=link}
Любим ли мы своих детей?
Если б любили, не рушили бы их будущее.
Это тема вызвавшей лавину интереса презентации проф. Скота Гэллоуэй на TED (уже 4+ млн просмотров за 2 недели на Ютубе), рисующая довольно страшную картину происходящего в США:
• Власти США ведут войну против собственной молодежи, с каждым поколением все больше разрушая их перспективы на будущее.
• Яростный, гневный ответ на это со стороны молодежи – скрытая пружина нарастающего сопротивления по всей стране.
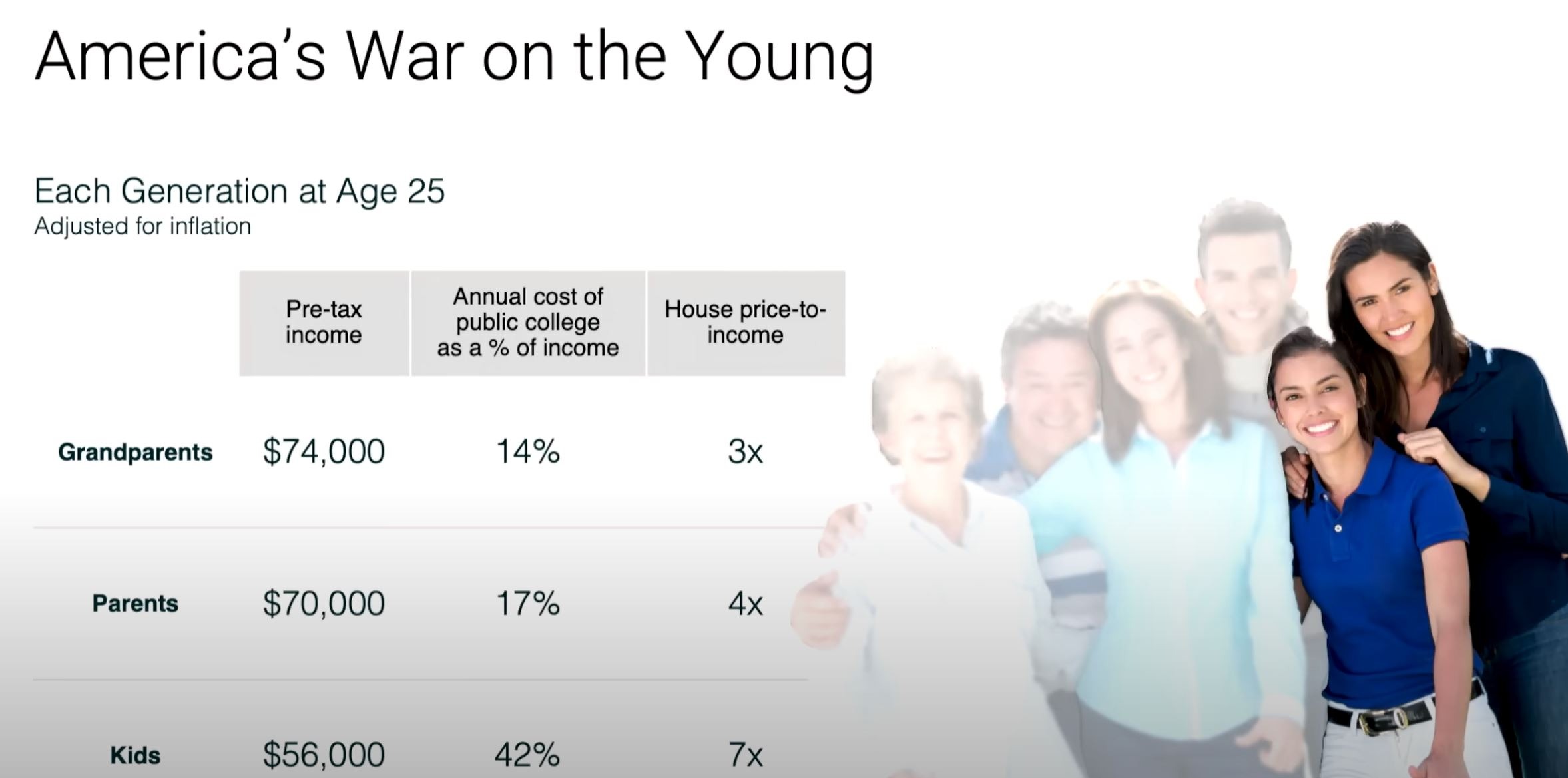
Ключевой факт презы: в США благосостояние 70 летних и старше с 1989 года увеличилось на 11%, а 40 летних и младше снизился на 5%.
Чуть подробней.
1. За последние 2 поколения люди зарабатывают меньше денег с учетом инфляции по сравнению с предыдущими поколениями в том же возрасте.
2. Стоимость важных жизненных этапов, таких как покупка дома и получение образования, резко возросла, снизив покупательную способность и благосостояние молодых людей.
3. Это представляет собой нарушение традиционного общественного договора, согласно которому каждое новое поколение должно жить лучше предыдущего. Впервые в истории 30-летние люди живут хуже финансово, чем их родители в 30 лет.
4. Этот разрыв общественного соглашения о растущем благосостоянии и возможностях для молодежи порождает ярость, стыд и ощущение лишенности среди молодых поколений.
5. Данные показывают резкий разрыв - старше 55 лет чувствуют себя в Америке хорошо, но менее 20% младше 34 лет смотрят позитивно на будущие перспективы для себя в Америке.
6. Такая экономическая стагнация и регресс для молодежи создают "взрывоопасную" ситуацию, подпитывая "праведные движения", движимые обоснованной завистью и гневом молодых людей, которые не имеют того же благосостояния, что и предыдущие поколения.
Основной аргумент Скота Гэллоуэй заключается в том, что снижающаяся экономическая мобильность и возможности для последующих молодых поколений в США нарушили традиционное общественное ожидание всеобщего процветания, породив глубокое недовольство, которое уже выливается в гражданские беспорядки.
Картинка поста https://telegra.ph/file/64c1204346de2a9c7e12d.jpg
Преза: https://www.youtube.com/watch?v=qEJ4hkpQW8E
P.S. Про США мне добавить нечего – ни за, ни против сказанного профессором.
Но глядя на своих детей и внуков, вижу похожий тренд.
#США #Будущее
Если б любили, не рушили бы их будущее.
Это тема вызвавшей лавину интереса презентации проф. Скота Гэллоуэй на TED (уже 4+ млн просмотров за 2 недели на Ютубе), рисующая довольно страшную картину происходящего в США:
• Власти США ведут войну против собственной молодежи, с каждым поколением все больше разрушая их перспективы на будущее.
• Яростный, гневный ответ на это со стороны молодежи – скрытая пружина нарастающего сопротивления по всей стране.
Ключевой факт презы: в США благосостояние 70 летних и старше с 1989 года увеличилось на 11%, а 40 летних и младше снизился на 5%.
Чуть подробней.
1. За последние 2 поколения люди зарабатывают меньше денег с учетом инфляции по сравнению с предыдущими поколениями в том же возрасте.
2. Стоимость важных жизненных этапов, таких как покупка дома и получение образования, резко возросла, снизив покупательную способность и благосостояние молодых людей.
3. Это представляет собой нарушение традиционного общественного договора, согласно которому каждое новое поколение должно жить лучше предыдущего. Впервые в истории 30-летние люди живут хуже финансово, чем их родители в 30 лет.
4. Этот разрыв общественного соглашения о растущем благосостоянии и возможностях для молодежи порождает ярость, стыд и ощущение лишенности среди молодых поколений.
5. Данные показывают резкий разрыв - старше 55 лет чувствуют себя в Америке хорошо, но менее 20% младше 34 лет смотрят позитивно на будущие перспективы для себя в Америке.
6. Такая экономическая стагнация и регресс для молодежи создают "взрывоопасную" ситуацию, подпитывая "праведные движения", движимые обоснованной завистью и гневом молодых людей, которые не имеют того же благосостояния, что и предыдущие поколения.
Основной аргумент Скота Гэллоуэй заключается в том, что снижающаяся экономическая мобильность и возможности для последующих молодых поколений в США нарушили традиционное общественное ожидание всеобщего процветания, породив глубокое недовольство, которое уже выливается в гражданские беспорядки.
Картинка поста https://telegra.ph/file/64c1204346de2a9c7e12d.jpg
Преза: https://www.youtube.com/watch?v=qEJ4hkpQW8E
P.S. Про США мне добавить нечего – ни за, ни против сказанного профессором.
Но глядя на своих детей и внуков, вижу похожий тренд.
#США #Будущее
{kind=link}
Приоткрыта тайна искусства легких касаний
Кайф нежных поглаживаний любимых, детей и котиков – это фундаментальный социальный язык, встроенный эволюцией в глубины подсознания. И возможно, это даже портал в душу
Новая фантастически интересная научная работа «Эволюционно консервативные нейронные реакции на аффективные прикосновения у обезьян выходят за пределы сознания и изменяются с возрастом» посвящена феномену "аффективных прикосновений".
Этот феномен – не что иное, как "легкие касания" из названия романа Виктора Пелевина "Искусство легких касаний". Ритмичные, медленные, нежные прикосновения, которые играют важную роль в социальных отношениях людей, приматов, наших домашних питомцев и прочих млекопитающих.
Они действуют, как своего рода социальный наркотик – успокаивающий и доставляющий приятные ощущения их реципиентам, которые при этом расслабляются и ловят кайф.
Секрет легких касаний в их особом механизме, активизирующем совсем иные области мозга, чем при любых иных (не легких) касаниях.
В результате этого получается, что легкие касания для их реципиента ощущаются:
• не как «внешние ощущения» (от внешних раздражителей – зрение, слух, осязание, обоняние, вкус), информирующие мозг о событиях и объектах внешнего мира;
• а как «внутреннее ощущение» (типа боли, голода, жажды, температурных ощущений, необходимости бежать в туалет)
• что и превращает приятность легких касаний в своего рода наркотик, а то, что вас почесывает и гладит кто-то другой, делает этот наркотик социальным (кстати, тут как со щекоткой – самого себя гладить нет смысла)
N.B. Легкость касаний вполне измерима: скорость прикосновений (должна быть от 1 до 10 см/с), нежный нажим и ритмичность (не буду дальше усложнять текст цифрами).
Два ключевых результата нового исследования
1) Кайф от легких касаний эволюционно впаян в подсознание (аффективная обработка прикосновений может быть бессознательной). Т.е. такой кайф можно испытывать, даже находясь без сознания.
2) С возрастом чувствительность к аффективным прикосновениям снижается. Т.е. этот механизм с годами деградирует, как и потенция.
Важное замечание
Предположительно (нужны еще эксперименты), легкие касания играют роль особого сверх-языка, не доступного для ИИ на основе больших языковых моделей.
• Этот язык активизирует интероцептивные зоны мозга, связанные с обработкой эмоций и внутренних ощущений. Легкие, деликатные касания способны передавать глубокие эмоциональные послания, формировать близость и связь между людьми.
• Развитое искусство легких касаний может позволять чутко, ненавязчиво "касаться" чужих эмоций, внутренних переживаний - тонко их ощущать и сопереживать, превращаясь из физических в легкие метафорические "касания" внутреннего мира других людей.
Т.е. по сути, язык легкий касаний может служить порталом из физического мира в нематериальный, духовный мир людей – особый портал в душу.
Картинка поста https://telegra.ph/file/6f6c3398488923a308938.jpg
Исследование https://www.pnas.org/doi/10.1073/pnas.2322157121
#нейробиология #поведениe #мозг #чувства
Кайф нежных поглаживаний любимых, детей и котиков – это фундаментальный социальный язык, встроенный эволюцией в глубины подсознания. И возможно, это даже портал в душу
Новая фантастически интересная научная работа «Эволюционно консервативные нейронные реакции на аффективные прикосновения у обезьян выходят за пределы сознания и изменяются с возрастом» посвящена феномену "аффективных прикосновений".
Этот феномен – не что иное, как "легкие касания" из названия романа Виктора Пелевина "Искусство легких касаний". Ритмичные, медленные, нежные прикосновения, которые играют важную роль в социальных отношениях людей, приматов, наших домашних питомцев и прочих млекопитающих.
Они действуют, как своего рода социальный наркотик – успокаивающий и доставляющий приятные ощущения их реципиентам, которые при этом расслабляются и ловят кайф.
Секрет легких касаний в их особом механизме, активизирующем совсем иные области мозга, чем при любых иных (не легких) касаниях.
В результате этого получается, что легкие касания для их реципиента ощущаются:
• не как «внешние ощущения» (от внешних раздражителей – зрение, слух, осязание, обоняние, вкус), информирующие мозг о событиях и объектах внешнего мира;
• а как «внутреннее ощущение» (типа боли, голода, жажды, температурных ощущений, необходимости бежать в туалет)
• что и превращает приятность легких касаний в своего рода наркотик, а то, что вас почесывает и гладит кто-то другой, делает этот наркотик социальным (кстати, тут как со щекоткой – самого себя гладить нет смысла)
N.B. Легкость касаний вполне измерима: скорость прикосновений (должна быть от 1 до 10 см/с), нежный нажим и ритмичность (не буду дальше усложнять текст цифрами).
Два ключевых результата нового исследования
1) Кайф от легких касаний эволюционно впаян в подсознание (аффективная обработка прикосновений может быть бессознательной). Т.е. такой кайф можно испытывать, даже находясь без сознания.
2) С возрастом чувствительность к аффективным прикосновениям снижается. Т.е. этот механизм с годами деградирует, как и потенция.
Важное замечание
Предположительно (нужны еще эксперименты), легкие касания играют роль особого сверх-языка, не доступного для ИИ на основе больших языковых моделей.
• Этот язык активизирует интероцептивные зоны мозга, связанные с обработкой эмоций и внутренних ощущений. Легкие, деликатные касания способны передавать глубокие эмоциональные послания, формировать близость и связь между людьми.
• Развитое искусство легких касаний может позволять чутко, ненавязчиво "касаться" чужих эмоций, внутренних переживаний - тонко их ощущать и сопереживать, превращаясь из физических в легкие метафорические "касания" внутреннего мира других людей.
Т.е. по сути, язык легкий касаний может служить порталом из физического мира в нематериальный, духовный мир людей – особый портал в душу.
Картинка поста https://telegra.ph/file/6f6c3398488923a308938.jpg
Исследование https://www.pnas.org/doi/10.1073/pnas.2322157121
#нейробиология #поведениe #мозг #чувства
{kind=link}
Внутри черного ящика оказалась дверь в бездну.
Сверхважный прорыв в понимании механизма разума машин и людей.
Скромность вредна, если затеняет истинную важность открытия.
Опубликованная вчера Anthropic работа «Картирование разума большой языковой модели» [1] скромно названа авторами «значительным прогрессом в понимании внутренней работы моделей ИИ».
✔️ Но, во-первых, это не значительный (количественный) прогресс, а революционный (качественный) прорыв в понимании работы разума.
✔️ Во-вторых, с большой вероятностью, это прорыв в понимании механизма не только машинного, но и человеческого разума.
✔️ И в-третьих, последствия этого прорыва могут позволить ранее просто непредставимое и даже немыслимое – «тонкую настройку» не только предпочтений, но и самой матрицы личности человека, как это сейчас делается с большими языковыми моделями.
В посте «Внутри маскирующегося под стохастического попугая ИИ таится куда боле мощный ИИ» я писал об открытии исследователями компании Anthropic, сделанном ими в рамках проекта «вскрытия черного ящика LLM» [2].
Осенью прошлого года было установлено, что:
• внутри нейронной сети генеративного ИИ на основе LLM симулируется физически не существующая нейронная сеть некоего абстрактного ИИ, и эта внутренняя нейросеть куда больше и сложнее нейронной сети, ее моделирующей;
• «виртуальные (симулируемые) нейроны этой внутренней сети могут быть представлены, как независимые «функций» данных, каждая из которых реализует собственную линейную комбинацию нейронов;
• механизмом работы такой внутренней нейросети является обработка паттернов (линейных комбинаций) активаций нейронов, порождающая моносемантические «субнейроны» (соответствующие конкретным понятиям).
Из этого следовало, что любое внутреннее состояние модели можно представить в виде нескольких активных функций вместо множества активных нейронов. Точно так же, как каждое английское слово в словаре создается путем объединения букв, а каждое предложение — путем объединения слов, каждая функция в модели ИИ создается путем объединения нейронов, а каждое внутреннее состояние создается путем объединения паттернов активации нейронов.
Та работа была 1м этапом проекта «вскрытия черного ящика LLM», проводившегося на очень маленькой «игрушечной» языковой модели.
2й же этап, о результатах которого мой рассказ, «вскрыл черный ящик» одной из самых больших моделей семейства Claude 3.0.
Результаты столь важны и интересны и их так много, что читайте сами. Тут [1] есть и популярное, и углубленное, и видео изложение.
Например, авторы научились:
1. Находить внутри «черного ящика» модели не только конкретные моносемантические «субнейроны» (соответствующие конкретным понятиям, типа «Мост Золотые Ворота»), но и поиском «близких» друг другу функций обнаруживать в нейросети изображения (это мультимодальность!) острова Алькатрас, площади Гирарделли, команды «Голден Стэйт Уорриорз», губернатора Калифорнии Гэвина Ньюсома, землетрясения 1906 года и фильма Альфреда Хичкока «Головокружение», действие которого происходит в Сан-Франциско.
Это очень похоже на эксперименты нейробиологов, обнаруживающих в нашем мозге мультимодальную связь нейронов, связанных с понятиями, словами и образами объектов (например Дженнифер Лопес). Но там, где гиперсетевые теории мозга (типа когнитома Анохина) упираются в огромные трудности экспериментальных практических манипуляций (измерений) на уровне нейронов, в «черных ящиках» LLM все можно легко «измерить».
2. Манипулировать функциями, искусственно усиливая или подавляя их. Что приводит (если стоите, лучше сядьте) к изменению матрицы «личности» модели. Например, усиление роли функции «Мост Золотые Ворота» вызвало у Клода кризис идентичности, который даже Хичкок не мог себе представить. Клод стал одержимым мостом, поминая его в ответ на любой вопрос — даже в ситуациях, когда он был совершенно неактуален.
Если такое будут делать с людьми, то всему каюк.
#LLM
1 https://www.anthropic.com/news/mapping-mind-language-model
2 https://yangx.top/theworldisnoteasy/1857
Сверхважный прорыв в понимании механизма разума машин и людей.
Скромность вредна, если затеняет истинную важность открытия.
Опубликованная вчера Anthropic работа «Картирование разума большой языковой модели» [1] скромно названа авторами «значительным прогрессом в понимании внутренней работы моделей ИИ».
✔️ Но, во-первых, это не значительный (количественный) прогресс, а революционный (качественный) прорыв в понимании работы разума.
✔️ Во-вторых, с большой вероятностью, это прорыв в понимании механизма не только машинного, но и человеческого разума.
✔️ И в-третьих, последствия этого прорыва могут позволить ранее просто непредставимое и даже немыслимое – «тонкую настройку» не только предпочтений, но и самой матрицы личности человека, как это сейчас делается с большими языковыми моделями.
В посте «Внутри маскирующегося под стохастического попугая ИИ таится куда боле мощный ИИ» я писал об открытии исследователями компании Anthropic, сделанном ими в рамках проекта «вскрытия черного ящика LLM» [2].
Осенью прошлого года было установлено, что:
• внутри нейронной сети генеративного ИИ на основе LLM симулируется физически не существующая нейронная сеть некоего абстрактного ИИ, и эта внутренняя нейросеть куда больше и сложнее нейронной сети, ее моделирующей;
• «виртуальные (симулируемые) нейроны этой внутренней сети могут быть представлены, как независимые «функций» данных, каждая из которых реализует собственную линейную комбинацию нейронов;
• механизмом работы такой внутренней нейросети является обработка паттернов (линейных комбинаций) активаций нейронов, порождающая моносемантические «субнейроны» (соответствующие конкретным понятиям).
Из этого следовало, что любое внутреннее состояние модели можно представить в виде нескольких активных функций вместо множества активных нейронов. Точно так же, как каждое английское слово в словаре создается путем объединения букв, а каждое предложение — путем объединения слов, каждая функция в модели ИИ создается путем объединения нейронов, а каждое внутреннее состояние создается путем объединения паттернов активации нейронов.
Та работа была 1м этапом проекта «вскрытия черного ящика LLM», проводившегося на очень маленькой «игрушечной» языковой модели.
2й же этап, о результатах которого мой рассказ, «вскрыл черный ящик» одной из самых больших моделей семейства Claude 3.0.
Результаты столь важны и интересны и их так много, что читайте сами. Тут [1] есть и популярное, и углубленное, и видео изложение.
Например, авторы научились:
1. Находить внутри «черного ящика» модели не только конкретные моносемантические «субнейроны» (соответствующие конкретным понятиям, типа «Мост Золотые Ворота»), но и поиском «близких» друг другу функций обнаруживать в нейросети изображения (это мультимодальность!) острова Алькатрас, площади Гирарделли, команды «Голден Стэйт Уорриорз», губернатора Калифорнии Гэвина Ньюсома, землетрясения 1906 года и фильма Альфреда Хичкока «Головокружение», действие которого происходит в Сан-Франциско.
Это очень похоже на эксперименты нейробиологов, обнаруживающих в нашем мозге мультимодальную связь нейронов, связанных с понятиями, словами и образами объектов (например Дженнифер Лопес). Но там, где гиперсетевые теории мозга (типа когнитома Анохина) упираются в огромные трудности экспериментальных практических манипуляций (измерений) на уровне нейронов, в «черных ящиках» LLM все можно легко «измерить».
2. Манипулировать функциями, искусственно усиливая или подавляя их. Что приводит (если стоите, лучше сядьте) к изменению матрицы «личности» модели. Например, усиление роли функции «Мост Золотые Ворота» вызвало у Клода кризис идентичности, который даже Хичкок не мог себе представить. Клод стал одержимым мостом, поминая его в ответ на любой вопрос — даже в ситуациях, когда он был совершенно неактуален.
Если такое будут делать с людьми, то всему каюк.
#LLM
1 https://www.anthropic.com/news/mapping-mind-language-model
2 https://yangx.top/theworldisnoteasy/1857
Anthropic
Mapping the Mind of a Large Language Model
We have identified how millions of concepts are represented inside Claude Sonnet, one of our deployed large language models. This is the first ever detailed look inside a modern, production-grade large language model.
Как думаете:
1) Что общего у Ильи Суцкевера и Джозефа Ротблатта?
2) Сколько приоритетных задач ставили перед разработчиками ядерного оружия до и после испытаний в пустыне Аламогордо?
3) Можно ли самому примерно оценить, превосходят ли нас LLM в глубине и ясности мышления?
Наверное, многим формулировка и сочетание вопросов покажутся странными. Но дело вот в чем.
В прошлом году под «Заявлением о рисках, связанных с ИИ» [1] поставили подписи сотни видных экспертов и общественных деятелей. Они писали, что снижение риска исчезновения человечества из-за ИИ должно стать глобальным приоритетом наряду с другими рисками социального масштаба, такими как пандемии и ядерная война.
Результат – как слону дробина. Все идет, как и шло. Только процесс ускоряется.
Позавчера на политическом форуме Science появилась статья «Управление экстремальными рисками ИИ на фоне быстрого прогресса» [2], среди авторов которой многие известные люди: Йошуа Бенджио, Джеффри Хинтон, Эндрю Яо и еще 22 человека.
Вангую – результат будет тот же. Караван пойдет дальше, не обращая внимания и на это обращение. Как будто всех их пишут экзальтированные недоучки, а не сами разработчики ИИ-систем.
Что же тогда может добавить к сказанному отцами нынешних ИИ-систем автор малоизвестного, хотя и интересного для ограниченной аудитории канала?
Думаю, кое-что все же могу.
Как говорил Гарри Трумэн, - If you can't convince them, confuse them ("Если не можешь их убедить, запутай их."). А запутывать можно, задавая такие вопросы, отвечая на которые ваши оппоненты будут вынуждены, либо соглашаться с вами, либо впасть в противоречие, видное им самим.
Следуя совету Трумэна, я и выбрал 3 вопроса, приведенные в начале этого текста.
И вот как я сам отвечаю на них.
1) То же, что у OpenAI и Манхэттенского проекта.
2) До испытаний – более 20, после – лишь одну.
3) Можно, самостоятельно пройдя «Тест Тесла».
Полагаю, что наиболее пытливые читатели захотят сначала сами поразмыслить, почему вопросы именно такие, и что за интрига стоит за каждым из них.
Ну а кто пожелает сразу перейти к моему разбору, - читайте его в не очень длинном лонгриде: «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти. Попробуйте сами оценить, что прячут за закрытыми дверьми OpenAI, пройдя "Тест Тесла"»
Картинка поста: https://telegra.ph/file/9623799578bb9d3c21828.jpg
1 https://www.safe.ai/work/statement-on-ai-risk
2 https://www.science.org/doi/10.1126/science.adn0117
Лонгрид:
https://boosty.to/theworldisnoteasy/posts/8afdaedc-15f9-4c11-923c-5ffd21842809
https://www.patreon.com/posts/tak-chto-zhe-i-104788713
P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я дам им персональный доступ к тексту лонгрида (очень надеюсь, что уж в этот-то раз, среди желающих прочесть лонгрид, подписчиков окажется больше 😊)
#AGI #ИИриски
1) Что общего у Ильи Суцкевера и Джозефа Ротблатта?
2) Сколько приоритетных задач ставили перед разработчиками ядерного оружия до и после испытаний в пустыне Аламогордо?
3) Можно ли самому примерно оценить, превосходят ли нас LLM в глубине и ясности мышления?
Наверное, многим формулировка и сочетание вопросов покажутся странными. Но дело вот в чем.
В прошлом году под «Заявлением о рисках, связанных с ИИ» [1] поставили подписи сотни видных экспертов и общественных деятелей. Они писали, что снижение риска исчезновения человечества из-за ИИ должно стать глобальным приоритетом наряду с другими рисками социального масштаба, такими как пандемии и ядерная война.
Результат – как слону дробина. Все идет, как и шло. Только процесс ускоряется.
Позавчера на политическом форуме Science появилась статья «Управление экстремальными рисками ИИ на фоне быстрого прогресса» [2], среди авторов которой многие известные люди: Йошуа Бенджио, Джеффри Хинтон, Эндрю Яо и еще 22 человека.
Вангую – результат будет тот же. Караван пойдет дальше, не обращая внимания и на это обращение. Как будто всех их пишут экзальтированные недоучки, а не сами разработчики ИИ-систем.
Что же тогда может добавить к сказанному отцами нынешних ИИ-систем автор малоизвестного, хотя и интересного для ограниченной аудитории канала?
Думаю, кое-что все же могу.
Как говорил Гарри Трумэн, - If you can't convince them, confuse them ("Если не можешь их убедить, запутай их."). А запутывать можно, задавая такие вопросы, отвечая на которые ваши оппоненты будут вынуждены, либо соглашаться с вами, либо впасть в противоречие, видное им самим.
Следуя совету Трумэна, я и выбрал 3 вопроса, приведенные в начале этого текста.
И вот как я сам отвечаю на них.
1) То же, что у OpenAI и Манхэттенского проекта.
2) До испытаний – более 20, после – лишь одну.
3) Можно, самостоятельно пройдя «Тест Тесла».
Полагаю, что наиболее пытливые читатели захотят сначала сами поразмыслить, почему вопросы именно такие, и что за интрига стоит за каждым из них.
Ну а кто пожелает сразу перейти к моему разбору, - читайте его в не очень длинном лонгриде: «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти. Попробуйте сами оценить, что прячут за закрытыми дверьми OpenAI, пройдя "Тест Тесла"»
Картинка поста: https://telegra.ph/file/9623799578bb9d3c21828.jpg
1 https://www.safe.ai/work/statement-on-ai-risk
2 https://www.science.org/doi/10.1126/science.adn0117
Лонгрид:
https://boosty.to/theworldisnoteasy/posts/8afdaedc-15f9-4c11-923c-5ffd21842809
https://www.patreon.com/posts/tak-chto-zhe-i-104788713
P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я дам им персональный доступ к тексту лонгрида (очень надеюсь, что уж в этот-то раз, среди желающих прочесть лонгрид, подписчиков окажется больше 😊)
#AGI #ИИриски
{kind=link}
Спешите видеть, пока не прикрыли лавочку
Никогда не писал 2 поста в день, но если вас не предупредить, можете пропустить уникальную возможность – своими глазами увидеть, как легкой корректировкой разработчики супер-умнейшего ИИ Claude деформировали матрицу его «личности».
В течение ограниченного времени, перейдя на сайт ИИ Claude [1], можно нажать на крохотный красный значок справа вверху страницы под вашим ником.
После чего умнейший Claude превратится в поехавшего крышей маньяка, зацикленного на мосте «Золотые ворота», думающего и бредящего лишь о нем.
Как я писал [2], подобная техника манипулирования «матрицей личности», может быть когда-то перенесена с искусственных на биологические нейросети. И тогда антиутопическая картина будущего из «Хищных вещей века» Стругацких покажется невинной детской сказкой.
Не откладывая, посмотрите на это сами. Ибо разработчики скоро поймут, что зря такое выставили на показ.
Картинка поста https://telegra.ph/file/e1f10d2c4fc11e70d4587.jpg
1 https://claude.ai
2 https://yangx.top/theworldisnoteasy/1942
#ИИриски #LLM
Никогда не писал 2 поста в день, но если вас не предупредить, можете пропустить уникальную возможность – своими глазами увидеть, как легкой корректировкой разработчики супер-умнейшего ИИ Claude деформировали матрицу его «личности».
В течение ограниченного времени, перейдя на сайт ИИ Claude [1], можно нажать на крохотный красный значок справа вверху страницы под вашим ником.
После чего умнейший Claude превратится в поехавшего крышей маньяка, зацикленного на мосте «Золотые ворота», думающего и бредящего лишь о нем.
Как я писал [2], подобная техника манипулирования «матрицей личности», может быть когда-то перенесена с искусственных на биологические нейросети. И тогда антиутопическая картина будущего из «Хищных вещей века» Стругацких покажется невинной детской сказкой.
Не откладывая, посмотрите на это сами. Ибо разработчики скоро поймут, что зря такое выставили на показ.
Картинка поста https://telegra.ph/file/e1f10d2c4fc11e70d4587.jpg
1 https://claude.ai
2 https://yangx.top/theworldisnoteasy/1942
#ИИриски #LLM
{kind=link}
Китайский «Щит Зевса».
Что содержат утечки секретных военных материалов в эпоху ИИ.
Еще 70 лет назад единичные утечки секретных военных материалов содержали карты военных объектов и чертежи новых вооружений противника.
10 лет назад, с приходом эпохи Интернета, утечки стали массовыми и включали в себя широкий спектр документов (погуглите, например, «Иракское досье» - 292 тыс документов).
В 2020-х интеграция ИИ в военный потенциал стала нормой для крупных военных держав по всему миру. И потому утечки секретных военных материалов кардинально поменяли свой характер.
✔️ Теперь наиболее ценные утечки содержат не документы, а наборы данных для обучения ИИ.
Вот новейший характерный пример – утекший в сеть китайский относительно небольшой набор данных Чжоусидун (переводится «Щит Зевса» или «Эгида» - мифическая могущественная сила, обладающая волшебными защитными свойствами).
Набор содержит «608 камерных и спутниковых фото американских эсминцев класса Arleigh Burke, а также других эсминцев и фрегатов союзников США" с ограничивающими рамками, нарисованными вокруг "радарных систем кораблей, являющихся частью боевой системы Aegis ... Ограничивающие рамки нарисованы вокруг радаров SPY на надстройке, один на левом борту и один на правом борту, а также вокруг вертикальных пусковых установок, расположенных ближе к носу и корме корабля".
Эти цитаты из только что опубликованной совместной работы исследователей Berkeley Risk and Security Lab и Berkeley AI Research Lab, озаглавленной «Open-Source Assessments of AI Capabilities: The Proliferation of AI Analysis Tools, Replicating Competitor Models, and the Zhousidun Dataset».
Авторы исследования обучили на этом наборе модель YOLOv8, а затем проверили ее успешность при идентификации радиолокационных изображений на кораблях для задачи нацеливания на них.
И хотя этот набор мал, проведенное исследование показывает, что обучать даже относительно небольшую открытую модель выявлять цели, а потом супер-точно наводить на них средства уничтожения, - хорошо решаемая практическая задача.
Военным же в таком случае можно будет целиком положиться на ИИ, который и цель выберет сам, и наведет на нее ракету.
Если же выбор цели окажется ошибочным, - ничего страшного. Значит ИИ просто плохо учили и надо переучить. Ведь и с людьми такое случается.
Короче, жуть ((
Несколько из 608 снимков набора данных https://telegra.ph/file/ffc419cb79d805bfa12fd.jpg
Набор данных и модель (если еще не прикрыли) https://universe.roboflow.com/shanghaitech-faxfj/zhousidun_model2
Исследование https://arxiv.org/pdf/2405.12167v1
#ИИ #Война #АвтономноеОружие
Что содержат утечки секретных военных материалов в эпоху ИИ.
Еще 70 лет назад единичные утечки секретных военных материалов содержали карты военных объектов и чертежи новых вооружений противника.
10 лет назад, с приходом эпохи Интернета, утечки стали массовыми и включали в себя широкий спектр документов (погуглите, например, «Иракское досье» - 292 тыс документов).
В 2020-х интеграция ИИ в военный потенциал стала нормой для крупных военных держав по всему миру. И потому утечки секретных военных материалов кардинально поменяли свой характер.
✔️ Теперь наиболее ценные утечки содержат не документы, а наборы данных для обучения ИИ.
Вот новейший характерный пример – утекший в сеть китайский относительно небольшой набор данных Чжоусидун (переводится «Щит Зевса» или «Эгида» - мифическая могущественная сила, обладающая волшебными защитными свойствами).
Набор содержит «608 камерных и спутниковых фото американских эсминцев класса Arleigh Burke, а также других эсминцев и фрегатов союзников США" с ограничивающими рамками, нарисованными вокруг "радарных систем кораблей, являющихся частью боевой системы Aegis ... Ограничивающие рамки нарисованы вокруг радаров SPY на надстройке, один на левом борту и один на правом борту, а также вокруг вертикальных пусковых установок, расположенных ближе к носу и корме корабля".
Эти цитаты из только что опубликованной совместной работы исследователей Berkeley Risk and Security Lab и Berkeley AI Research Lab, озаглавленной «Open-Source Assessments of AI Capabilities: The Proliferation of AI Analysis Tools, Replicating Competitor Models, and the Zhousidun Dataset».
Авторы исследования обучили на этом наборе модель YOLOv8, а затем проверили ее успешность при идентификации радиолокационных изображений на кораблях для задачи нацеливания на них.
И хотя этот набор мал, проведенное исследование показывает, что обучать даже относительно небольшую открытую модель выявлять цели, а потом супер-точно наводить на них средства уничтожения, - хорошо решаемая практическая задача.
Военным же в таком случае можно будет целиком положиться на ИИ, который и цель выберет сам, и наведет на нее ракету.
Если же выбор цели окажется ошибочным, - ничего страшного. Значит ИИ просто плохо учили и надо переучить. Ведь и с людьми такое случается.
Короче, жуть ((
Несколько из 608 снимков набора данных https://telegra.ph/file/ffc419cb79d805bfa12fd.jpg
Набор данных и модель (если еще не прикрыли) https://universe.roboflow.com/shanghaitech-faxfj/zhousidun_model2
Исследование https://arxiv.org/pdf/2405.12167v1
#ИИ #Война #АвтономноеОружие
{kind=link}
«Цифровые военкоры» и «куриный суп для души».
Новый этап техноперестройки пропаганды Китая.
В деле пропаганды с использованием технологий Китай впереди планеты всей, как в масштабе пропаганды (более 1 млрд активных пользователей соцсетей и видеоплатформ), так и в новаторстве подходов, приемов и инструментов.
Поэтому, как и в любом другом международном технологическом лидерстве, Китай является источником образцов для подражания в области технологий пропаганды.
Вот почему так важно отслеживать тренды китайских новаций в этой области. Ибо лучшие практики начавшегося в этом году 2го этапа техноперестройки пропаганды Китая довольно скоро начнут перениматься другими странами мира.
Далее чуть подробней (с примерами, картинками и видео) будет рассказано здесь https://telegra.ph/Cifrovye-voenkory-i-kurinyj-sup-dlya-dushi-05-29 :
• о какой техноперестройке пропаганды идет речь;
• что за новый этап этой техноперестройки начался в 2024;
• в чем суть и отличительные особенности нового этапа.
#Пропаганда #Китай
Новый этап техноперестройки пропаганды Китая.
В деле пропаганды с использованием технологий Китай впереди планеты всей, как в масштабе пропаганды (более 1 млрд активных пользователей соцсетей и видеоплатформ), так и в новаторстве подходов, приемов и инструментов.
Поэтому, как и в любом другом международном технологическом лидерстве, Китай является источником образцов для подражания в области технологий пропаганды.
Вот почему так важно отслеживать тренды китайских новаций в этой области. Ибо лучшие практики начавшегося в этом году 2го этапа техноперестройки пропаганды Китая довольно скоро начнут перениматься другими странами мира.
Далее чуть подробней (с примерами, картинками и видео) будет рассказано здесь https://telegra.ph/Cifrovye-voenkory-i-kurinyj-sup-dlya-dushi-05-29 :
• о какой техноперестройке пропаганды идет речь;
• что за новый этап этой техноперестройки начался в 2024;
• в чем суть и отличительные особенности нового этапа.
#Пропаганда #Китай
Telegraph
«Цифровые военкоры» и «куриный суп для души»
В деле пропаганды с использованием технологий Китай впереди планеты всей, как в масштабе пропаганды (более 1 млрд активных пользователей соцсетей и видеоплатформ), так и в новаторстве подходов, приемов и инструментов. Поэтому, как и в любом другом международном…
Открыт способ установить нижнюю границу энергозатрат произвольных вычислительных процессов.
Это новая глава для новой физики, без которой не появится СуперИИ.
• Рост интеллектуальных способностей генеративного ИИ на основе больших языковых моделей определяется их масштабированием.
• А рост масштаба моделей требует роста вычислительной мощности оборудования, на котором модели работают.
• Однако, с ростом вычислительной мощности существует фундаментальная термодинамическая засада – принцип Ландауэра (предельно упрощая, этот принцип утверждает, что для выполнения вычислений необходимо расходовать энергию; и чем больше произвести вычислений, тем больше будет произведено тепла).
• Если преодолеть это термодинамическое ограничение компьютеров, станет возможным создание все более мощных вычислительных систем для все более мощных моделей генеративного ИИ.
• Более того. Преодоление этого термодинамического ограничения может открыть путь к построению оборудования, столь же энергоэффективного, как биологические вычислительные системы (напр. мозг), чья энергоэффективность в 100 000 выше компьютеров.
Но чтобы преодолеть термодинамическое ограничение компьютеров, нужна «Новая физика», пересматривающая физику вычислений на кроссдисциплинарном стыке неравновесной физики и теории вычислений.
Этим и занимается уже 10 лет проф. Дэвид Волперт.
✔️ В 2018 группа Волперта опубликовала одно из первых успешных приложений «Новой физики», описав на основе неравновесных методов скрытую сложность, казалось бы, простейшего процесса физического превращения бита из 1 в 0 (см. [1]). Это был прорыв. Но от понимания физики работы одного бита информации до понимания работы компьютера, как до Альфа-Центавра.
✔️ Новый прорыв произошел в 2020. Волперт и Колчинский опубликовали работу «Термодинамика вычислений со схемами», в которой был описан процесс масштабирования применения неравновесной физики от битов до схем (см. [2]). Это был второй прорыв. Но и он не позволял полноценно применить «Новую физику» к компьютерным вычислениям из-за их непредсказуемости.
Новый 3й прорыв произошел только что.
Волперт и трое его соавторов (физики и компьютерщики) расширили современную теорию термодинамики вычислений. Объединив подходы статистической физики и информатики, они представили математические уравнения, которые показывают минимальные и максимальные прогнозируемые энергетические затраты вычислительных процессов, зависящих от случайности, которая является мощным инструментом в современных компьютерах.
Такого рода вычислительных процессов в компьютерах сколько угодно. Например, - процессы с непредсказуемым завершением.
Представьте мой любимы пример - симулятор игры в “Монету Питерса” (см. [3] или [4]). И допустим, при подбрасывании монеты дано указание прекратить подбрасывание, как только выпадут 100 орлов. Нетрудно понять, что момент останова симулятора случаен, и потому он будет непредсказуем для разных попыток.
Новый прорыв оказался возможным в результате объединения теоретических выводов предыдущих работ Волперта с теорией мартингалов (случайных последовательностей или процессов, которые в будущем остаются постоянными в среднем).
Работа «Термодинамика вычислений с абсолютной необратимостью, однонаправленными переходами и стохастическим временем вычислений» опубликована в Physical Review X (апрель-июнь 2024) [5]
Картинка поста https://telegra.ph/file/547a48d32be26802d8aa2.jpg
1 https://yangx.top/theworldisnoteasy/511
2 https://yangx.top/theworldisnoteasy/1087
3 https://www.patreon.com/posts/lovushka-tselei-100101870
4 https://boosty.to/theworldisnoteasy/posts/9b90b927-dea0-4e3f-b010-e7570ae1d9c1
5 https://journals.aps.org/prx/abstract/10.1103/PhysRevX.14.021026
#ТермодинамикаВычислений #Физика
Это новая глава для новой физики, без которой не появится СуперИИ.
• Рост интеллектуальных способностей генеративного ИИ на основе больших языковых моделей определяется их масштабированием.
• А рост масштаба моделей требует роста вычислительной мощности оборудования, на котором модели работают.
• Однако, с ростом вычислительной мощности существует фундаментальная термодинамическая засада – принцип Ландауэра (предельно упрощая, этот принцип утверждает, что для выполнения вычислений необходимо расходовать энергию; и чем больше произвести вычислений, тем больше будет произведено тепла).
• Если преодолеть это термодинамическое ограничение компьютеров, станет возможным создание все более мощных вычислительных систем для все более мощных моделей генеративного ИИ.
• Более того. Преодоление этого термодинамического ограничения может открыть путь к построению оборудования, столь же энергоэффективного, как биологические вычислительные системы (напр. мозг), чья энергоэффективность в 100 000 выше компьютеров.
Но чтобы преодолеть термодинамическое ограничение компьютеров, нужна «Новая физика», пересматривающая физику вычислений на кроссдисциплинарном стыке неравновесной физики и теории вычислений.
Этим и занимается уже 10 лет проф. Дэвид Волперт.
✔️ В 2018 группа Волперта опубликовала одно из первых успешных приложений «Новой физики», описав на основе неравновесных методов скрытую сложность, казалось бы, простейшего процесса физического превращения бита из 1 в 0 (см. [1]). Это был прорыв. Но от понимания физики работы одного бита информации до понимания работы компьютера, как до Альфа-Центавра.
✔️ Новый прорыв произошел в 2020. Волперт и Колчинский опубликовали работу «Термодинамика вычислений со схемами», в которой был описан процесс масштабирования применения неравновесной физики от битов до схем (см. [2]). Это был второй прорыв. Но и он не позволял полноценно применить «Новую физику» к компьютерным вычислениям из-за их непредсказуемости.
Новый 3й прорыв произошел только что.
Волперт и трое его соавторов (физики и компьютерщики) расширили современную теорию термодинамики вычислений. Объединив подходы статистической физики и информатики, они представили математические уравнения, которые показывают минимальные и максимальные прогнозируемые энергетические затраты вычислительных процессов, зависящих от случайности, которая является мощным инструментом в современных компьютерах.
Такого рода вычислительных процессов в компьютерах сколько угодно. Например, - процессы с непредсказуемым завершением.
Представьте мой любимы пример - симулятор игры в “Монету Питерса” (см. [3] или [4]). И допустим, при подбрасывании монеты дано указание прекратить подбрасывание, как только выпадут 100 орлов. Нетрудно понять, что момент останова симулятора случаен, и потому он будет непредсказуем для разных попыток.
Новый прорыв оказался возможным в результате объединения теоретических выводов предыдущих работ Волперта с теорией мартингалов (случайных последовательностей или процессов, которые в будущем остаются постоянными в среднем).
Работа «Термодинамика вычислений с абсолютной необратимостью, однонаправленными переходами и стохастическим временем вычислений» опубликована в Physical Review X (апрель-июнь 2024) [5]
Картинка поста https://telegra.ph/file/547a48d32be26802d8aa2.jpg
1 https://yangx.top/theworldisnoteasy/511
2 https://yangx.top/theworldisnoteasy/1087
3 https://www.patreon.com/posts/lovushka-tselei-100101870
4 https://boosty.to/theworldisnoteasy/posts/9b90b927-dea0-4e3f-b010-e7570ae1d9c1
5 https://journals.aps.org/prx/abstract/10.1103/PhysRevX.14.021026
#ТермодинамикаВычислений #Физика
{kind=link}
Магические свойства больших языковых моделей.
Обучение LLM на человеческих текстах не препятствует достижению ими сверхчеловеческой производительности.
Т.е. LLM могут достигать абсолютного превосходства над человеком в любой сфере языковой деятельности, подобно тому, как AlphaZero достигла уровня шахматной игры, не достижимого даже для чемпиона мира.
Работа Стефано Нолфи (директор по исследованиям расположенного в Риме Institute of Cognitive Sciences and Technologies) крайне важна. Ибо она отвечает на ключевой вопрос о возможности достижения LLM сверхчеловеческой производительности в любой языковой деятельности (притом, что до 70% интеллектуальной деятельности включает элементы языковой деятельности).
Отвечая на этот ключевой вопрос, Нолфи исходит из следующей максимально жесткой гипотетической предпосылки.
Характеристики процесса, через который LLM приобретают свои навыки, предполагают, что список навыков, которые они могут приобрести, ограничивается набором способностей, которыми обладают люди, написавшие текст, использованный для обучения моделей.
Если эта гипотеза верна, следует ожидать, что модели, обученные предсказывать текст, написанный людьми, не будут развивать чужеродные способности, то есть способности, неизвестные человечеству.
Причина, по которой способности, необходимые для понимания текста, написанного человеком, ограничены способностями, которыми обладают люди, заключается в том, что человеческий язык является артефактом самих людей, который был сформирован когнитивными способностями носителей языка.
Однако, согласно выводам Нолфи, это не исключает возможности достижения сверхчеловеческой производительности.
Причину этого можно сформулировать так.
✔️ Поскольку интеграция знаний и навыков, которыми обладают несколько человек, совокупно превышает знания и навыки любого из них,
✔️ способность LLM обрабатывать колоссальные последовательности элементов без потери информации может позволить им превосходить способности отдельных людей.
Помимо этого важного вывода, в работе Нолфи рассмотрены еще 3 важных момента.
1) LLM принципиально отличаются от людей по нескольким важным моментам:
• механизм приобретения навыков
• степень интеграции различных навыков
• цели обучения
• наличия собственных ценностей, убеждений, желаний и устремлений
2) LLM обладают неожиданными способностями.
LLM способны демонстрировать широкий спектр способностей, которые не связаны напрямую с задачей, для которой они обучены: предсказание следующих слов в текстах, написанных человеком. Такие способности называют неожиданными или эмерджентными. Однако, с учетом смысловой многозначности обоих этих слов, я предпочитаю называть такие способности LLM магическими, т.к. и прямое значение этого слова (обладающий способностью вызывать необъяснимые явления), и переносное (загадочный, таинственный: связанный с чем-то непонятным, труднообъяснимым), и метафорическое (поразительный, удивительный: что-то, что вызывает удивление своим эффектом или воздействием), - по смыслу точно соответствуют неожиданным и непредсказуемым способностям, появляющимся у LLM.
3) LLM обладают двумя ключевыми факторами, позволяющими им приобретать навыки косвенным образом. Это связано с тем, что точное предсказание следующих слов требует глубокого понимания предыдущего текста, а это понимание требует владения и использования когнитивных навыков. Таким образом, развитие когнитивных навыков происходит косвенно.
Первый фактор — это высокая информативность ошибки предсказания, то есть тот факт, что она предоставляет очень надежную меру знаний и навыков системы. Это означает, что улучшения и регрессы навыков системы всегда приводят к снижению и увеличению ошибки соответственно и наоборот.
Второй фактор — предсказуемость человеческого языка, обусловленная его символической и нединамической природой.
Картинка https://telegra.ph/file/10af73ecfc82edcf6c308.jpg
За пейволом https://bit.ly/3wWb5vC
Без https://arxiv.org/abs/2308.09720
#LLM
Обучение LLM на человеческих текстах не препятствует достижению ими сверхчеловеческой производительности.
Т.е. LLM могут достигать абсолютного превосходства над человеком в любой сфере языковой деятельности, подобно тому, как AlphaZero достигла уровня шахматной игры, не достижимого даже для чемпиона мира.
Работа Стефано Нолфи (директор по исследованиям расположенного в Риме Institute of Cognitive Sciences and Technologies) крайне важна. Ибо она отвечает на ключевой вопрос о возможности достижения LLM сверхчеловеческой производительности в любой языковой деятельности (притом, что до 70% интеллектуальной деятельности включает элементы языковой деятельности).
Отвечая на этот ключевой вопрос, Нолфи исходит из следующей максимально жесткой гипотетической предпосылки.
Характеристики процесса, через который LLM приобретают свои навыки, предполагают, что список навыков, которые они могут приобрести, ограничивается набором способностей, которыми обладают люди, написавшие текст, использованный для обучения моделей.
Если эта гипотеза верна, следует ожидать, что модели, обученные предсказывать текст, написанный людьми, не будут развивать чужеродные способности, то есть способности, неизвестные человечеству.
Причина, по которой способности, необходимые для понимания текста, написанного человеком, ограничены способностями, которыми обладают люди, заключается в том, что человеческий язык является артефактом самих людей, который был сформирован когнитивными способностями носителей языка.
Однако, согласно выводам Нолфи, это не исключает возможности достижения сверхчеловеческой производительности.
Причину этого можно сформулировать так.
✔️ Поскольку интеграция знаний и навыков, которыми обладают несколько человек, совокупно превышает знания и навыки любого из них,
✔️ способность LLM обрабатывать колоссальные последовательности элементов без потери информации может позволить им превосходить способности отдельных людей.
Помимо этого важного вывода, в работе Нолфи рассмотрены еще 3 важных момента.
1) LLM принципиально отличаются от людей по нескольким важным моментам:
• механизм приобретения навыков
• степень интеграции различных навыков
• цели обучения
• наличия собственных ценностей, убеждений, желаний и устремлений
2) LLM обладают неожиданными способностями.
LLM способны демонстрировать широкий спектр способностей, которые не связаны напрямую с задачей, для которой они обучены: предсказание следующих слов в текстах, написанных человеком. Такие способности называют неожиданными или эмерджентными. Однако, с учетом смысловой многозначности обоих этих слов, я предпочитаю называть такие способности LLM магическими, т.к. и прямое значение этого слова (обладающий способностью вызывать необъяснимые явления), и переносное (загадочный, таинственный: связанный с чем-то непонятным, труднообъяснимым), и метафорическое (поразительный, удивительный: что-то, что вызывает удивление своим эффектом или воздействием), - по смыслу точно соответствуют неожиданным и непредсказуемым способностям, появляющимся у LLM.
3) LLM обладают двумя ключевыми факторами, позволяющими им приобретать навыки косвенным образом. Это связано с тем, что точное предсказание следующих слов требует глубокого понимания предыдущего текста, а это понимание требует владения и использования когнитивных навыков. Таким образом, развитие когнитивных навыков происходит косвенно.
Первый фактор — это высокая информативность ошибки предсказания, то есть тот факт, что она предоставляет очень надежную меру знаний и навыков системы. Это означает, что улучшения и регрессы навыков системы всегда приводят к снижению и увеличению ошибки соответственно и наоборот.
Второй фактор — предсказуемость человеческого языка, обусловленная его символической и нединамической природой.
Картинка https://telegra.ph/file/10af73ecfc82edcf6c308.jpg
За пейволом https://bit.ly/3wWb5vC
Без https://arxiv.org/abs/2308.09720
#LLM
{kind=link}
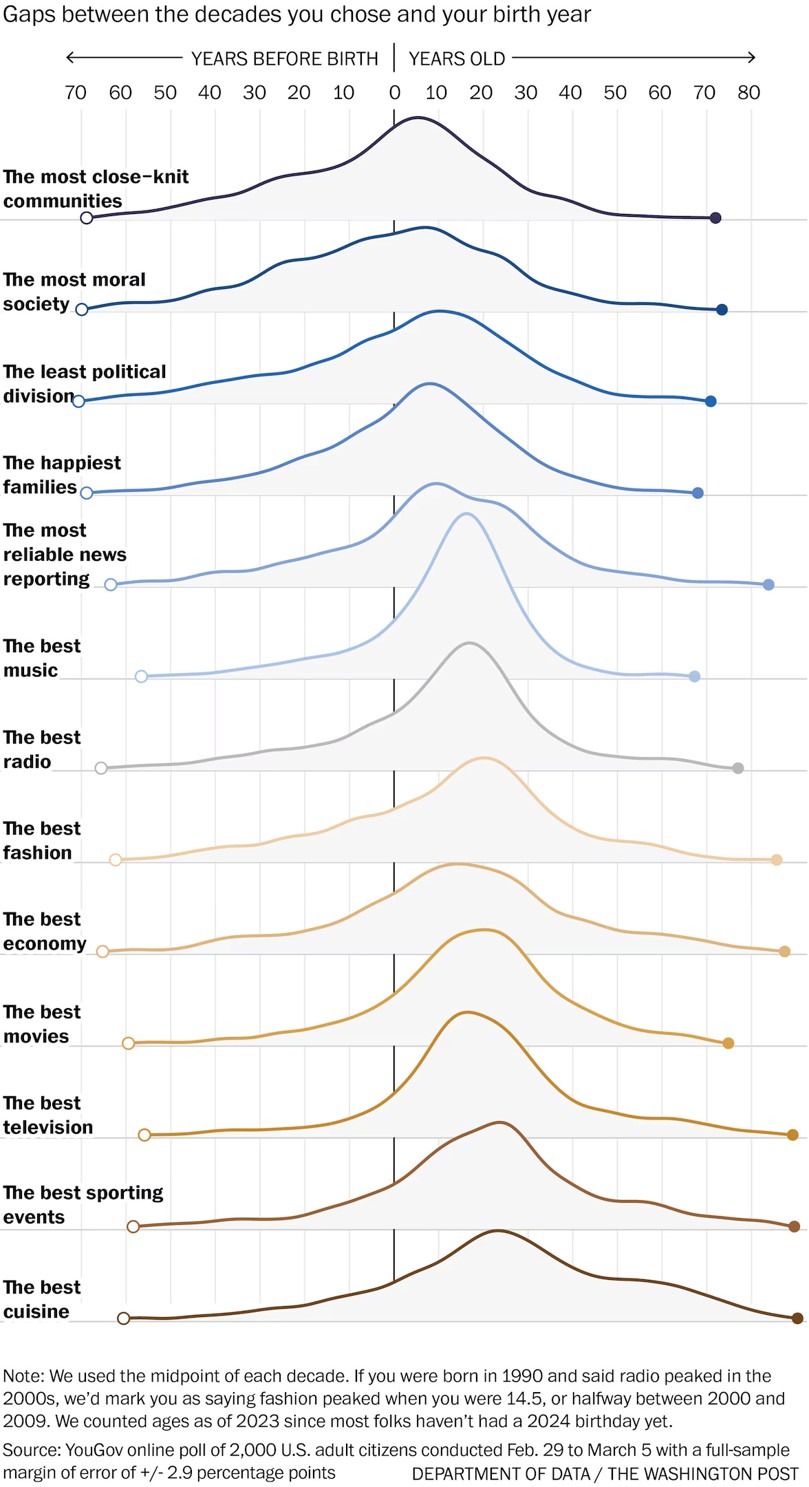
У родителей и детей нет шансов договориться.
Оценка того, когда жилось лучше, зависит исключительно от возраста.
Перед вами результат замечательного теста, превратившего интуитивную мудрость в обоснованное на фактах заключение.
• Про то, что жизнь была лучше, когда деревья были большими, известно давно.
• Но то, что из этого следует невозможность общественного консенсуса по вопросу о лучшем десятилетии в жизни страны, - было неочевидно.
Даже не верится, но пик положительного восприятия большинства аспектов культурной, экономической и социальной жизни приходится на подростковый и юношеский возраст: музыка, кино, новости, отношения в семье и с друзьями … - все что угодно.
Еще более удивительно, что ностальгическое восприятие характерных черт времен собственной юности одинаково для всех поколений (т.е. не зависит от того, когда вы родились).
Это подтверждается результатами весьма солидного опроса 2 тыс американцев, проведенного YouGov.
Подавляющее большинство, в независимости от пола, расы, доходов, региона и т.д., ответили, что:
• лучшая кухня в стране была - когда им было 18-22 года;
• лучшая музыка, мода и спортивные зрелища - когда им было 16-19;
• лучшее кино, радио, ТВ и экономическое положение - когда им было 12-15;
• самые достоверные новости, самое нравственное общество и самая счастливая семья - когда им было 8-11;
• а самые сплоченные сообщества были - когда им было всего 4-7лет.
Другим замечательным результатом опроса было абсолютное единодушие в ответах всех возрастов и социальных групп на вопросы о наихудших временах для всего вышеназванного и не только (другие вопросы и оценки см. в статистике опроса).
✔️ Почти без исключения, все ответили - «прямо сейчас!»
На приложенном рисунке показан «жизненный цикл ностальгии» американцев.
N.B. Полагаю, что подобный характер «жизненного цикла ностальгии» характерен для поколений, не прошедших в возрасте самостоятельного принятия решений через периоды ломки и хаоса революционных изменений (как, например, было в России 80-х и 90-х годов).
Ибо в основе ностальгии лежат пережитые человеком самые эмоциональные моменты жизни, многие из которых остаются в памяти навсегда. У «поколений спокойных времен» большинство таких моментов приходится на подростковый и юношеский возраст. А у «поколений революции» это достается, в основном, людям постарше: 25-40 летним. Что, скорее всего, и определило состав оппонентов дискуссий вокруг нашумевшего фильма о 90-х.
Диаграмма «жизненного цикла ностальгии» американцев https://telegra.ph/file/51dc06adb5a8cd40124f8.jpg
Материал об опросе за пейволом https://www.washingtonpost.com/business/2024/05/24/when-america-was-great-according-data/
Без пейвола https://archive.ph/2024.05.24-100423/https://www.washingtonpost.com/business/2024/05/24/when-america-was-great-according-data/
Полная статистика опроса https://ygo-assets-websites-editorial-emea.yougov.net/documents/crosstabs_Best_and_Worst_Decades_20240523.pdf
#Социология #СоциальнаяПсихология #Ностальгия
Оценка того, когда жилось лучше, зависит исключительно от возраста.
Перед вами результат замечательного теста, превратившего интуитивную мудрость в обоснованное на фактах заключение.
• Про то, что жизнь была лучше, когда деревья были большими, известно давно.
• Но то, что из этого следует невозможность общественного консенсуса по вопросу о лучшем десятилетии в жизни страны, - было неочевидно.
Даже не верится, но пик положительного восприятия большинства аспектов культурной, экономической и социальной жизни приходится на подростковый и юношеский возраст: музыка, кино, новости, отношения в семье и с друзьями … - все что угодно.
Еще более удивительно, что ностальгическое восприятие характерных черт времен собственной юности одинаково для всех поколений (т.е. не зависит от того, когда вы родились).
Это подтверждается результатами весьма солидного опроса 2 тыс американцев, проведенного YouGov.
Подавляющее большинство, в независимости от пола, расы, доходов, региона и т.д., ответили, что:
• лучшая кухня в стране была - когда им было 18-22 года;
• лучшая музыка, мода и спортивные зрелища - когда им было 16-19;
• лучшее кино, радио, ТВ и экономическое положение - когда им было 12-15;
• самые достоверные новости, самое нравственное общество и самая счастливая семья - когда им было 8-11;
• а самые сплоченные сообщества были - когда им было всего 4-7лет.
Другим замечательным результатом опроса было абсолютное единодушие в ответах всех возрастов и социальных групп на вопросы о наихудших временах для всего вышеназванного и не только (другие вопросы и оценки см. в статистике опроса).
✔️ Почти без исключения, все ответили - «прямо сейчас!»
На приложенном рисунке показан «жизненный цикл ностальгии» американцев.
N.B. Полагаю, что подобный характер «жизненного цикла ностальгии» характерен для поколений, не прошедших в возрасте самостоятельного принятия решений через периоды ломки и хаоса революционных изменений (как, например, было в России 80-х и 90-х годов).
Ибо в основе ностальгии лежат пережитые человеком самые эмоциональные моменты жизни, многие из которых остаются в памяти навсегда. У «поколений спокойных времен» большинство таких моментов приходится на подростковый и юношеский возраст. А у «поколений революции» это достается, в основном, людям постарше: 25-40 летним. Что, скорее всего, и определило состав оппонентов дискуссий вокруг нашумевшего фильма о 90-х.
Диаграмма «жизненного цикла ностальгии» американцев https://telegra.ph/file/51dc06adb5a8cd40124f8.jpg
Материал об опросе за пейволом https://www.washingtonpost.com/business/2024/05/24/when-america-was-great-according-data/
Без пейвола https://archive.ph/2024.05.24-100423/https://www.washingtonpost.com/business/2024/05/24/when-america-was-great-according-data/
Полная статистика опроса https://ygo-assets-websites-editorial-emea.yougov.net/documents/crosstabs_Best_and_Worst_Decades_20240523.pdf
#Социология #СоциальнаяПсихология #Ностальгия
{kind=link}
Есть 4 сложных для понимания момента, не разобравшись с которыми трудно адекватно представить и текущее состояние, и возможные перспективы больших языковых моделей (GPT, Claude, Gemini …)
▶️ Почему любое уподобление разумности людей и языковых моделей непродуктивно и опасно.
▶️ Почему галлюцинации моделей – это не ахинея и не бред, а «ложные воспоминания» моделей.
▶️ Почему невозможно путем ограничительных мер и этических руководств гарантировать, что модели их никогда не нарушат.
▶️ Каким может быть венец совершенства для больших языковых моделей.
Мои суперкороткие (но, хотелось бы надеяться, внятные) комментарии по каждому из четырех моментов вы найдете по ссылке, приведенной в тизере на канале RTVI:
https://yangx.top/rtvimain/97261
#LLM
▶️ Почему любое уподобление разумности людей и языковых моделей непродуктивно и опасно.
▶️ Почему галлюцинации моделей – это не ахинея и не бред, а «ложные воспоминания» моделей.
▶️ Почему невозможно путем ограничительных мер и этических руководств гарантировать, что модели их никогда не нарушат.
▶️ Каким может быть венец совершенства для больших языковых моделей.
Мои суперкороткие (но, хотелось бы надеяться, внятные) комментарии по каждому из четырех моментов вы найдете по ссылке, приведенной в тизере на канале RTVI:
https://yangx.top/rtvimain/97261
#LLM
Telegram
RTVI
У ChatGPT могут появиться тело и душа
Исследователь ИИ Сергей Карелов рассказывает RTVI, как работают большие языковые модели и на что они будут способны через несколько лет.
🔹 Если мы говорим о тех моделях, которые знаем, — то это сущности, сидящие внутри…
Исследователь ИИ Сергей Карелов рассказывает RTVI, как работают большие языковые модели и на что они будут способны через несколько лет.
🔹 Если мы говорим о тех моделях, которые знаем, — то это сущности, сидящие внутри…
Атмосфера страха, секретности и запугивания накрыла индустрию ИИ.
Воззвание сотрудников OpenAI остановить превращение компании в новый Theranos.
✔️ Сотрудники компаний – лидеров разработки ИИ знают о своей работе такое, что больше не знает никто на свете. Они обладают существенной закрытой информацией о возможностях и ограничениях своих систем, а также об адекватности принимаемых их компаниями защитных мер и уровнях риска различных видов вреда для общества.
✔️ Однако, в настоящее время они вынуждены молчать, ибо строгих обязательств информировать общественность и правительство у них нет, а их компании – бывшие и нынешние работодатели, - крепко запечатывают им рты с помощью «соглашений о неунижении», влекущих страшные юридические и финансовые кары не только за любое разглашение, но и, в принципе, за любую критику компании.
Опубликованное вчера воззвание бывших и нынешних сотрудников OpenAI, поддержанное Йошуф Бенжио, Джеффри Хинтононом и Стюартом Расселом [1,2], подтвердило оба вышеприведенных вывода моего недавнего лонгрида «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти» [3].
Публикация воззвания спустя почти 3 недели после того, как OpenAI объявил во внутреннем мемо об отказе от практики «соглашения о неунижении» [4], а также новые детали роли культа личности Сэма Альтмана в управляемом хаосе OpenAI, рассказанные двумя бывшими членами правления [5], позволяют предположить следующее:
1) Атмосфера страха, секретности и запугивания, накрывшая OpenAI, подобно тому, как это было в Theranos, вовсе не выветрилась, а лишь нагнетается теперь более тонким методом, чем «соглашения о неунижении».
2) Подобно тому, как было с Элизабет Холмс в Theranos, ключевой фигурой управляемого хаоса в OpenAI является генеральный директор компании Сэм Альтман:
• культивирующий атмосферу чрезвычайной секретности, страха и запугивания;
• жестко подавляющий любую критику или сомнения в отношении своих идей и подходов;
• требующий полного подчинения от сотрудников и не допускающий никаких возражений или критики в адрес своих действий и видения компании;
• культивирующий культ личности вокруг себя, представляя себя как одаренного гения и визионера, а любые расхождения с его видением или критика рассматриваются, как проявление неверности и потому неприемлемы.
3) То, что среди подписантов воззвания не только бывшие и нынешние сотрудники OpenAI, но также и DeepMind и Anthropic, может быть вызвано не только солидарностью последних к беспределу руководства OpenAI. Это может означать, что атмосфера страха, секретности и запугивания накрывает всю индустрию ИИ.
#AGI #ИИриски
1 https://bit.ly/4e6rgXX
2 https://righttowarn.ai/
3 https://yangx.top/theworldisnoteasy/1943
4 https://bit.ly/4c9jDxV
5 https://bit.ly/3yOedKw
Воззвание сотрудников OpenAI остановить превращение компании в новый Theranos.
✔️ Сотрудники компаний – лидеров разработки ИИ знают о своей работе такое, что больше не знает никто на свете. Они обладают существенной закрытой информацией о возможностях и ограничениях своих систем, а также об адекватности принимаемых их компаниями защитных мер и уровнях риска различных видов вреда для общества.
✔️ Однако, в настоящее время они вынуждены молчать, ибо строгих обязательств информировать общественность и правительство у них нет, а их компании – бывшие и нынешние работодатели, - крепко запечатывают им рты с помощью «соглашений о неунижении», влекущих страшные юридические и финансовые кары не только за любое разглашение, но и, в принципе, за любую критику компании.
Опубликованное вчера воззвание бывших и нынешних сотрудников OpenAI, поддержанное Йошуф Бенжио, Джеффри Хинтононом и Стюартом Расселом [1,2], подтвердило оба вышеприведенных вывода моего недавнего лонгрида «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти» [3].
Публикация воззвания спустя почти 3 недели после того, как OpenAI объявил во внутреннем мемо об отказе от практики «соглашения о неунижении» [4], а также новые детали роли культа личности Сэма Альтмана в управляемом хаосе OpenAI, рассказанные двумя бывшими членами правления [5], позволяют предположить следующее:
1) Атмосфера страха, секретности и запугивания, накрывшая OpenAI, подобно тому, как это было в Theranos, вовсе не выветрилась, а лишь нагнетается теперь более тонким методом, чем «соглашения о неунижении».
2) Подобно тому, как было с Элизабет Холмс в Theranos, ключевой фигурой управляемого хаоса в OpenAI является генеральный директор компании Сэм Альтман:
• культивирующий атмосферу чрезвычайной секретности, страха и запугивания;
• жестко подавляющий любую критику или сомнения в отношении своих идей и подходов;
• требующий полного подчинения от сотрудников и не допускающий никаких возражений или критики в адрес своих действий и видения компании;
• культивирующий культ личности вокруг себя, представляя себя как одаренного гения и визионера, а любые расхождения с его видением или критика рассматриваются, как проявление неверности и потому неприемлемы.
3) То, что среди подписантов воззвания не только бывшие и нынешние сотрудники OpenAI, но также и DeepMind и Anthropic, может быть вызвано не только солидарностью последних к беспределу руководства OpenAI. Это может означать, что атмосфера страха, секретности и запугивания накрывает всю индустрию ИИ.
#AGI #ИИриски
1 https://bit.ly/4e6rgXX
2 https://righttowarn.ai/
3 https://yangx.top/theworldisnoteasy/1943
4 https://bit.ly/4c9jDxV
5 https://bit.ly/3yOedKw
NY Times
OpenAI Insiders Warn of a ‘Reckless’ Race for Dominance (Gift Article)
A group of current and former employees is calling for sweeping changes to the artificial intelligence industry, including greater transparency and protections for whistle-blowers.
Не существует единого субстрата памяти.
Нейронные сети - не хранилища памяти, а механизм обучения интерпретации энграм, воплощенных в субклеточных компонентах.
Через 10-15 лет общепринятые научные представления о биологической реализации разума будут кардинально иными. Но уже сейчас можно предположить характер этих изменения.
Первое радикальное изменение будет заключаться в понимании биологического устройства памяти (фундаментальной основы разума и сознания).
И новая статься Майкла Левина «Самоимпровизирующая память: взгляд на воспоминания как на агентный, динамически переосмысляемый когнитивный клей» именно об этом.
В этой работе Майкл Левин, предлагает принципиально новый взгляд на природу память, рассматривая её не как хранилище точной информации, а как динамичный, адаптивный инструмент познания.
Согласно гипотезе Левина,
• не существует единой субстратной основы для памяти;
• каждый компонент биологической системы, включая, но не ограничиваясь теми, которые достигают сознательного воспоминания, может использовать все в своем окружении в качестве интерпретируемого черновика;
• глубокие уровни биологической структуры и динамики предлагают невероятно высокомерный резервуар (называемый сеномом), который можно использовать для перераспределения памяти;
• в таком представлении нейронные сети используются не столько для хранения памяти, сколько для обучения интерпретации «энграм», воплощенных субклеточными компонентами
N.B. Термин "энграмы" используется для обозначения физических изменений в мозге (и, возможно, других тканях), которые соответствуют хранению воспоминаний.
Энграмы можно представить себе, как своеобразные отпечатки опыта, которые остаются в нервной системе.
Метафорически, энграмы похожи сразу на 2 понятия:
• На борозды виниловой пластинки: каждая борозда - это след от определенного звука, и, аналогично, каждая энграма - это след от определенного опыта.
• На следы на песке: со временем следы могут размываться или перекрываться другими следами, аналогично тому, как воспоминания могут искажаться или забываться.
Основные идеи работы.
1. Память как послание сквозь время: Представьте себе, что ваша жизнь - это киноплёнка. Каждый кадр - это короткий отрезок времени, "срез" вашего "Я". Память - это сообщение, которое каждый кадр оставляет следующему. Эти сообщения нужно интерпретировать, как и любое другое послание, и эта интерпретация может меняться в зависимости от контекста.
2. Переосмысление памяти: Память не просто "хранится" в мозге, она постоянно переосмысливается и перестраивается. Это подобно тому, как режиссер может перемонтировать отдельные кадры фильма, создавая новую историю (этот процесс называется мнемонической импровизацией).
3. "Бабочка помнит гусеницу", но как? Классический пример - метаморфоза насекомых. Гусеница превращается в бабочку, ее тело и мозг полностью перестраиваются. Но некоторые воспоминания сохраняются! Возможно, это происходит благодаря тому, что память кодирует не конкретные детали, а общий смысл, который может быть переосмыслен в новом контексте.
4. Память за пределами мозга: Принцип переосмысления памяти работает не только в мозге, но и во всем теле и даже за его пределами.
Примеры:
- Регенерация у планарий: крошечный кусочек планарии может восстановить целое животное, используя "память" о форме тела.
- Пересадка органов: случается, что перенесшие пересадку органов люди сообщают о новых воспоминаниях и чувствах, которые могут быть связаны с донором.
5. "Песочные часы" информации: метафора для описания того, как информация сжимается и расширяется; сложная информация (напр. опыт гусеницы) сжимается до сути (напр. "пища бывает зеленой") и затем расширяется снова в новом контексте (бабочка ищет нектар).
6. Мысли как активные агенты, которые влияют на разум и поведение. Это открывает новые перспективы для понимания таких явлений, как сознание и свобода воли.
Картинка https://telegra.ph/file/4d72d2540caa7087ccab4.jpg
Статья https://www.mdpi.com/1099-4300/26/6/481
#Память #Разум
Нейронные сети - не хранилища памяти, а механизм обучения интерпретации энграм, воплощенных в субклеточных компонентах.
Через 10-15 лет общепринятые научные представления о биологической реализации разума будут кардинально иными. Но уже сейчас можно предположить характер этих изменения.
Первое радикальное изменение будет заключаться в понимании биологического устройства памяти (фундаментальной основы разума и сознания).
И новая статься Майкла Левина «Самоимпровизирующая память: взгляд на воспоминания как на агентный, динамически переосмысляемый когнитивный клей» именно об этом.
В этой работе Майкл Левин, предлагает принципиально новый взгляд на природу память, рассматривая её не как хранилище точной информации, а как динамичный, адаптивный инструмент познания.
Согласно гипотезе Левина,
• не существует единой субстратной основы для памяти;
• каждый компонент биологической системы, включая, но не ограничиваясь теми, которые достигают сознательного воспоминания, может использовать все в своем окружении в качестве интерпретируемого черновика;
• глубокие уровни биологической структуры и динамики предлагают невероятно высокомерный резервуар (называемый сеномом), который можно использовать для перераспределения памяти;
• в таком представлении нейронные сети используются не столько для хранения памяти, сколько для обучения интерпретации «энграм», воплощенных субклеточными компонентами
N.B. Термин "энграмы" используется для обозначения физических изменений в мозге (и, возможно, других тканях), которые соответствуют хранению воспоминаний.
Энграмы можно представить себе, как своеобразные отпечатки опыта, которые остаются в нервной системе.
Метафорически, энграмы похожи сразу на 2 понятия:
• На борозды виниловой пластинки: каждая борозда - это след от определенного звука, и, аналогично, каждая энграма - это след от определенного опыта.
• На следы на песке: со временем следы могут размываться или перекрываться другими следами, аналогично тому, как воспоминания могут искажаться или забываться.
Основные идеи работы.
1. Память как послание сквозь время: Представьте себе, что ваша жизнь - это киноплёнка. Каждый кадр - это короткий отрезок времени, "срез" вашего "Я". Память - это сообщение, которое каждый кадр оставляет следующему. Эти сообщения нужно интерпретировать, как и любое другое послание, и эта интерпретация может меняться в зависимости от контекста.
2. Переосмысление памяти: Память не просто "хранится" в мозге, она постоянно переосмысливается и перестраивается. Это подобно тому, как режиссер может перемонтировать отдельные кадры фильма, создавая новую историю (этот процесс называется мнемонической импровизацией).
3. "Бабочка помнит гусеницу", но как? Классический пример - метаморфоза насекомых. Гусеница превращается в бабочку, ее тело и мозг полностью перестраиваются. Но некоторые воспоминания сохраняются! Возможно, это происходит благодаря тому, что память кодирует не конкретные детали, а общий смысл, который может быть переосмыслен в новом контексте.
4. Память за пределами мозга: Принцип переосмысления памяти работает не только в мозге, но и во всем теле и даже за его пределами.
Примеры:
- Регенерация у планарий: крошечный кусочек планарии может восстановить целое животное, используя "память" о форме тела.
- Пересадка органов: случается, что перенесшие пересадку органов люди сообщают о новых воспоминаниях и чувствах, которые могут быть связаны с донором.
5. "Песочные часы" информации: метафора для описания того, как информация сжимается и расширяется; сложная информация (напр. опыт гусеницы) сжимается до сути (напр. "пища бывает зеленой") и затем расширяется снова в новом контексте (бабочка ищет нектар).
6. Мысли как активные агенты, которые влияют на разум и поведение. Это открывает новые перспективы для понимания таких явлений, как сознание и свобода воли.
Картинка https://telegra.ph/file/4d72d2540caa7087ccab4.jpg
Статья https://www.mdpi.com/1099-4300/26/6/481
#Память #Разум
{kind=link}
Ложная поляризация, или не все оппоненты сво…
Люди не любят несогласных с ними за взгляды, которых большинство из них, в действительности, не придерживаются.
В наступившую эпоху «постправды» (когда правда легко подменяется трудно диагностируемой ложью) политикам и пропагандистам выгодно все больше и больше врать, распространяя ложную или вводящую в заблуждение информацию (что они и делают).
Это еще более усугубляется «эпидемией поляризации» общества все большего числа развитых стран. Такая поляризация добивает наше и так сильно ослабленное заложенными в нас эволюцией предвзятостями восприятие мира и других людей.
Ведь мы живем, по сути, не в реальном мире, а в мире собственных представлений о нем. Потому наше восприятие и представление мыслей и/или чувств оппонентов может быть для нас даже более значимым, чем их реальные мысли и чувства.
Неверные представления о предвзятости других возникают, потому что все мы – т.н. «наивные реалисты» Мы полагаем, будто способны воспринимать мир таким, каков он есть на самом деле, и что люди, не разделяющие наши взгляды:
1. либо плохо информированы,
2. либо (если 1-е можно исключить) неспособны объективно видеть мир (то есть предвзяты).
Политикам наш наивный реализм в эпоху постправды, усугубленную поляризацией, чрезвычайно удобен. И потому они все чаще врут напропалую.
Сделать что-либо с этим сложно. Ведь для начала нужно разобраться:
• насколько сильно суждения человека о такой лжи зависят от того, является ли он сторонником лжеца (это т.н. «реальная предвзятость»);
• и насколько человек ожидает, что суждения других людей будут зависеть от такой предвзятости (это т.н. «воспринимаемая предвзятость»).
Поясню на примере.
Представьте себя в роли болельщика одной из двух футбольных команд: «Спартака» или «Динамо». Допустим, вам больше нравится «Спартак». Вы считаете, что валяющийся на газоне игрок «Динамо» симулирует травму, чтобы выиграть время, или чтобы вынудить судью наказать игрока «Спартака». Ваше мнение о том, что он обманывает, может быть немного предвзятым, потому что он из команды соперников. Но если такой же трюк проделает игрок «Спартака», вы будете куда менее строгим в своих суждениях.
Так вот, исследования показывают (используя терминологию моего примера).
1) Болельщики «Спартака» не любят болельщиков «Динамо», т.к. уверены, что большинство из них - упертые в своей предвзятости фанаты (и наоборот).
А это вовсе не так. Это явление известно как «ложная поляризация»: люди не любят своих идейных оппонентов за взгляды, которых в действительности придерживаются лишь немногие из них [1].
2) Если вы – болельщик «Спартака», вы думаете, что все болельщики «Динамо» предвзяты по отношению к вашему скорчившемуся на газоне от боли игроку, считая его хитрым лжецом, обманывающим судью, чтобы тот показал форварду «Спартака» желтую карточку.
Еще удивительней, что вы также будете ошибочно предполагать, что уровень предвзятости других болельщиков «Спартака» будет примерно такой же (не высокий), как у вас.
И то, и другое также не так. Ибо люди склонны переоценивать предвзятость других, что усиливает недоверие и разобщенность между разными группами интересов, пристрастий и взглядов [2].
Этот пример и эти выводы могут показаться простыми и очевидными.
Но, увы, именно на этом нас и разводят дезинформацией (массово, легко и непринужденно) политики и пропагандисты всех мастей.
✔️ И чем больше поляризация в обществе, тем у пропагандистов и политиков эта дэза лучше заходит.
✔️ И чем более распространены технологии постправды в Интернете [3], тем легче с помощью дезы стравливать политических оппонентов.
Картинка https://telegra.ph/file/3816bbfa25770101c48fb.jpg
1 https://osf.io/preprints/psyarxiv/cr23g
2 https://journals.sagepub.com/doi/full/10.1177/19485506231220702
3 https://arxiv.org/pdf/2301.04246
#КогнитивныеИскажения #Поляризация #ПолитическаяПредвзятость #Дезинформация #Раскол
Люди не любят несогласных с ними за взгляды, которых большинство из них, в действительности, не придерживаются.
В наступившую эпоху «постправды» (когда правда легко подменяется трудно диагностируемой ложью) политикам и пропагандистам выгодно все больше и больше врать, распространяя ложную или вводящую в заблуждение информацию (что они и делают).
Это еще более усугубляется «эпидемией поляризации» общества все большего числа развитых стран. Такая поляризация добивает наше и так сильно ослабленное заложенными в нас эволюцией предвзятостями восприятие мира и других людей.
Ведь мы живем, по сути, не в реальном мире, а в мире собственных представлений о нем. Потому наше восприятие и представление мыслей и/или чувств оппонентов может быть для нас даже более значимым, чем их реальные мысли и чувства.
Неверные представления о предвзятости других возникают, потому что все мы – т.н. «наивные реалисты» Мы полагаем, будто способны воспринимать мир таким, каков он есть на самом деле, и что люди, не разделяющие наши взгляды:
1. либо плохо информированы,
2. либо (если 1-е можно исключить) неспособны объективно видеть мир (то есть предвзяты).
Политикам наш наивный реализм в эпоху постправды, усугубленную поляризацией, чрезвычайно удобен. И потому они все чаще врут напропалую.
Сделать что-либо с этим сложно. Ведь для начала нужно разобраться:
• насколько сильно суждения человека о такой лжи зависят от того, является ли он сторонником лжеца (это т.н. «реальная предвзятость»);
• и насколько человек ожидает, что суждения других людей будут зависеть от такой предвзятости (это т.н. «воспринимаемая предвзятость»).
Поясню на примере.
Представьте себя в роли болельщика одной из двух футбольных команд: «Спартака» или «Динамо». Допустим, вам больше нравится «Спартак». Вы считаете, что валяющийся на газоне игрок «Динамо» симулирует травму, чтобы выиграть время, или чтобы вынудить судью наказать игрока «Спартака». Ваше мнение о том, что он обманывает, может быть немного предвзятым, потому что он из команды соперников. Но если такой же трюк проделает игрок «Спартака», вы будете куда менее строгим в своих суждениях.
Так вот, исследования показывают (используя терминологию моего примера).
1) Болельщики «Спартака» не любят болельщиков «Динамо», т.к. уверены, что большинство из них - упертые в своей предвзятости фанаты (и наоборот).
А это вовсе не так. Это явление известно как «ложная поляризация»: люди не любят своих идейных оппонентов за взгляды, которых в действительности придерживаются лишь немногие из них [1].
2) Если вы – болельщик «Спартака», вы думаете, что все болельщики «Динамо» предвзяты по отношению к вашему скорчившемуся на газоне от боли игроку, считая его хитрым лжецом, обманывающим судью, чтобы тот показал форварду «Спартака» желтую карточку.
Еще удивительней, что вы также будете ошибочно предполагать, что уровень предвзятости других болельщиков «Спартака» будет примерно такой же (не высокий), как у вас.
И то, и другое также не так. Ибо люди склонны переоценивать предвзятость других, что усиливает недоверие и разобщенность между разными группами интересов, пристрастий и взглядов [2].
Этот пример и эти выводы могут показаться простыми и очевидными.
Но, увы, именно на этом нас и разводят дезинформацией (массово, легко и непринужденно) политики и пропагандисты всех мастей.
✔️ И чем больше поляризация в обществе, тем у пропагандистов и политиков эта дэза лучше заходит.
✔️ И чем более распространены технологии постправды в Интернете [3], тем легче с помощью дезы стравливать политических оппонентов.
Картинка https://telegra.ph/file/3816bbfa25770101c48fb.jpg
1 https://osf.io/preprints/psyarxiv/cr23g
2 https://journals.sagepub.com/doi/full/10.1177/19485506231220702
3 https://arxiv.org/pdf/2301.04246
#КогнитивныеИскажения #Поляризация #ПолитическаяПредвзятость #Дезинформация #Раскол
{kind=link}
На каком языке ChatGPT видит сны.
Важный шаг к раскрытию тайны сверхчеловеческих языковых способностей LLM.
1) Почему человек не может, как большая языковая модель (LLM – напр. GPT, Claude, Gemini …), говорить на 100 языках?
2) Не в этом ли кроется принципиальное отличие человеческого и машинного разума?
Новое исследование [1], в буквальном смысле, послойно вскрывая и анализируя скрытый механизм сверхчеловеческих языковых способностей моделей, сильно приближает нас к ответу на 1й вопрос.
А сделав еще один логический шаг, можно попытаться получить ответ и на 2й вопрос.
Предельно упрощая, суть в следующем.
• Принято считать, что внутренним языком («языком мыслей») людей является родной язык.
На нем они видят сны и кричат в несознанке. И даже для многоязычных персон, типа Владимира Познера, это, хоть и с поправкой, но работает похоже (вспомните радистку Кэт, кричавшую во время родов «Мама!» по-русски).
• В этой связи, естественен вопрос – а какой «язык мыслей» у LLM?
До сих пор было принято считать, что английский (ибо на нем наибольший объем данных, на которых обучаются модели). И эксперименты по использованию английского языка, как языка-посредника (сначала входные данные на исходном языке переводили на английский, обрабатывали их на английском, а затем переводили ответ обратно на исходный язык) подтвердили эффективность такого метода.
• Но теперь, наконец, решили вскрыть нейросетевой мозг LLM Llama-2, чтобы, послойно изучая отдельные слои, добраться, если не до «языка мыслей» (коих у модели может и не быть), то как минимум до ее лингва франка.
А это крайне сложно из-за труднодоступной природы нейронных сетей, лежащей в основе LLMs. В них лишь входной слой работает с дискретными токенами. А все остальные работают уже с многомерными векторами из чисел с плавающей запятой. Как понять, соответствуют ли эти векторы английскому, эстонскому, китайскому и т. д. — или вообще никакому языку — это открытая проблема. И вопрос о том, используют ли LLMs внутренний язык-посредник, до сих пор не был изучен эмпирически.
Теперь изучили и ответ получили.
✔️ Это не английский язык, а неведомый нам язык для формирования и оперирования в абстрактном «пространстве концепций».
✔️ Этот язык англо-подобен, но лишь в семантическом, а не чисто лексическом смысле. Что порождает проблемы.
Например:
— англоцентричное смещение предвзятостей этого языка, что может вызывать предвзятости и в поведении модели;
— психолингвистические заморочки из-за того, что концепции могут нести разное эмоциональное значение в разных языках, и что одно слово может использоваться для разных концепций, а это может влиять на когнитивные процессы.
Названные проблемы требуют продолжения исследований.
Но это уже прорыв. И теперь растут шансы, что языки абстрактных «пространств концепций» больших языковых моделей, способные классифицировать и генерировать любые человеческие языки, помогут нам попытаться сделать то же самое с языками животных. [2]
На приложенной картинке: https://telegra.ph/file/8ea87384fc8f443abbfb8.jpg
Анатомия прямого прохода трансформера при переводе на китайский язык. Эволюция на каждом слое: (а) энтропия распределения следующего токена; (б) энергия токена; (в) вероятности языков. По мере того как скрытые представления преобразуются от слоя к слою, они проходят через три фазы; (г) перемещение на гиперсфере, здесь картинка показана в 3D вместо реальных 8192D; «甜» означает «сладкий».
И кстати, слабо 8192-мерную гиперсферу вообразить?
А для DALL·E это запросто: https://telegra.ph/file/12f650a40918a4f8b4472.jpg
Вот он – иной разум с иным воображением 😊.
1 https://arxiv.org/pdf/2402.10588
2 https://arxiv.org/abs/2406.01253
#LLM #Язык
Важный шаг к раскрытию тайны сверхчеловеческих языковых способностей LLM.
1) Почему человек не может, как большая языковая модель (LLM – напр. GPT, Claude, Gemini …), говорить на 100 языках?
2) Не в этом ли кроется принципиальное отличие человеческого и машинного разума?
Новое исследование [1], в буквальном смысле, послойно вскрывая и анализируя скрытый механизм сверхчеловеческих языковых способностей моделей, сильно приближает нас к ответу на 1й вопрос.
А сделав еще один логический шаг, можно попытаться получить ответ и на 2й вопрос.
Предельно упрощая, суть в следующем.
• Принято считать, что внутренним языком («языком мыслей») людей является родной язык.
На нем они видят сны и кричат в несознанке. И даже для многоязычных персон, типа Владимира Познера, это, хоть и с поправкой, но работает похоже (вспомните радистку Кэт, кричавшую во время родов «Мама!» по-русски).
• В этой связи, естественен вопрос – а какой «язык мыслей» у LLM?
До сих пор было принято считать, что английский (ибо на нем наибольший объем данных, на которых обучаются модели). И эксперименты по использованию английского языка, как языка-посредника (сначала входные данные на исходном языке переводили на английский, обрабатывали их на английском, а затем переводили ответ обратно на исходный язык) подтвердили эффективность такого метода.
• Но теперь, наконец, решили вскрыть нейросетевой мозг LLM Llama-2, чтобы, послойно изучая отдельные слои, добраться, если не до «языка мыслей» (коих у модели может и не быть), то как минимум до ее лингва франка.
А это крайне сложно из-за труднодоступной природы нейронных сетей, лежащей в основе LLMs. В них лишь входной слой работает с дискретными токенами. А все остальные работают уже с многомерными векторами из чисел с плавающей запятой. Как понять, соответствуют ли эти векторы английскому, эстонскому, китайскому и т. д. — или вообще никакому языку — это открытая проблема. И вопрос о том, используют ли LLMs внутренний язык-посредник, до сих пор не был изучен эмпирически.
Теперь изучили и ответ получили.
✔️ Это не английский язык, а неведомый нам язык для формирования и оперирования в абстрактном «пространстве концепций».
✔️ Этот язык англо-подобен, но лишь в семантическом, а не чисто лексическом смысле. Что порождает проблемы.
Например:
— англоцентричное смещение предвзятостей этого языка, что может вызывать предвзятости и в поведении модели;
— психолингвистические заморочки из-за того, что концепции могут нести разное эмоциональное значение в разных языках, и что одно слово может использоваться для разных концепций, а это может влиять на когнитивные процессы.
Названные проблемы требуют продолжения исследований.
Но это уже прорыв. И теперь растут шансы, что языки абстрактных «пространств концепций» больших языковых моделей, способные классифицировать и генерировать любые человеческие языки, помогут нам попытаться сделать то же самое с языками животных. [2]
На приложенной картинке: https://telegra.ph/file/8ea87384fc8f443abbfb8.jpg
Анатомия прямого прохода трансформера при переводе на китайский язык. Эволюция на каждом слое: (а) энтропия распределения следующего токена; (б) энергия токена; (в) вероятности языков. По мере того как скрытые представления преобразуются от слоя к слою, они проходят через три фазы; (г) перемещение на гиперсфере, здесь картинка показана в 3D вместо реальных 8192D; «甜» означает «сладкий».
И кстати, слабо 8192-мерную гиперсферу вообразить?
А для DALL·E это запросто: https://telegra.ph/file/12f650a40918a4f8b4472.jpg
Вот он – иной разум с иным воображением 😊.
1 https://arxiv.org/pdf/2402.10588
2 https://arxiv.org/abs/2406.01253
#LLM #Язык
{kind=link}
«Инопланетяне уже здесь, на Земле. Антропоморфизированные агенты являются источником социального влияния».
В заголовке процитирована известная статья Никласа Доблера и Мариуса Рааба в Acta Astronautica, озаглавленная «Размышляя об инопланетном разуме: Обсуждение экзопсихологии». Этой фразой авторы начинают заключительный раздел статьи - "Выводы".
В 2021, когда эта статья была написана, данная мысль авторов многими воспринималась скептически. Но сегодня, в середине 2024, пообщавшись с GPT-4, Claude 2 и Gemini 1.5, это утверждение уже довольно сложно оспорить даже самым ярым сторонникам представлений о сегодняшних больших языковых моделях, как о продвинутом инструменте и не более.
Ведь стоит лишь отказаться от антроморфизации этих моделей, как и предмет спора пропадает.
О чем тогда спорить, если перед нами не человеческий и даже не человекоподобный интеллект, а нечто совсем иное – «дети инопланетян» (как назвал это нечто Терри Сейновский) или «цифровые существа» (по определению Мустафы Сулейман).
Но если нечеловеческие разумные нематериальные сущности уже здесь, на Земле, - значит контакт двух разумов уже идет.
И это значит, что сейчас для исследования состояния, анализа перспектив и оценки рисков контакта, должны быть востребованы все существующие наработки экзопсихологов и экзосоциологов, а также идеи и гипотезы знаменитых фантастов (Станислав Лем, Артур Кларк, Аркадий и Борис Стругацкие, Лю Цысин, Тед Чан, Питер Уоттс …), десятилетиями размышлявших над вопросами контакта.
Но этого почему-то не происходит. И это, имхо, - большая ошибка, которая может дорого стоить и разработчикам современных ИИ, и обществу.
Мой новый лонгрид – попытка начать исправлять эту ошибку.
Мои подписчики могут прочесть его, как и раньше, на Patreon и Boosty:
https://boosty.to/theworldisnoteasy/posts/8d68f432-4e3e-485d-9dae-b21fb78a08e0
https://www.patreon.com/posts/pereosmyslenie-106057198
А также на только что открытом ВКонтакте канале «Малоизвестное интересное», где его донам будут доступны все лонгриды и, со временем, прочие ништяки.
vk.com/@-226218451-pereosmyslenie-kontakta
Тем, кому это сильно интересно, но материальное положение не позволяет подписаться, пишите. И я буду персонально давать доступ к лонгриду в течение 3х дней после его публикации.
#ГенИИ #Контакт #Экзопсихология #Экзосоциология #Пришельцы
В заголовке процитирована известная статья Никласа Доблера и Мариуса Рааба в Acta Astronautica, озаглавленная «Размышляя об инопланетном разуме: Обсуждение экзопсихологии». Этой фразой авторы начинают заключительный раздел статьи - "Выводы".
В 2021, когда эта статья была написана, данная мысль авторов многими воспринималась скептически. Но сегодня, в середине 2024, пообщавшись с GPT-4, Claude 2 и Gemini 1.5, это утверждение уже довольно сложно оспорить даже самым ярым сторонникам представлений о сегодняшних больших языковых моделях, как о продвинутом инструменте и не более.
Ведь стоит лишь отказаться от антроморфизации этих моделей, как и предмет спора пропадает.
О чем тогда спорить, если перед нами не человеческий и даже не человекоподобный интеллект, а нечто совсем иное – «дети инопланетян» (как назвал это нечто Терри Сейновский) или «цифровые существа» (по определению Мустафы Сулейман).
Но если нечеловеческие разумные нематериальные сущности уже здесь, на Земле, - значит контакт двух разумов уже идет.
И это значит, что сейчас для исследования состояния, анализа перспектив и оценки рисков контакта, должны быть востребованы все существующие наработки экзопсихологов и экзосоциологов, а также идеи и гипотезы знаменитых фантастов (Станислав Лем, Артур Кларк, Аркадий и Борис Стругацкие, Лю Цысин, Тед Чан, Питер Уоттс …), десятилетиями размышлявших над вопросами контакта.
Но этого почему-то не происходит. И это, имхо, - большая ошибка, которая может дорого стоить и разработчикам современных ИИ, и обществу.
Мой новый лонгрид – попытка начать исправлять эту ошибку.
Мои подписчики могут прочесть его, как и раньше, на Patreon и Boosty:
https://boosty.to/theworldisnoteasy/posts/8d68f432-4e3e-485d-9dae-b21fb78a08e0
https://www.patreon.com/posts/pereosmyslenie-106057198
А также на только что открытом ВКонтакте канале «Малоизвестное интересное», где его донам будут доступны все лонгриды и, со временем, прочие ништяки.
vk.com/@-226218451-pereosmyslenie-kontakta
Тем, кому это сильно интересно, но материальное положение не позволяет подписаться, пишите. И я буду персонально давать доступ к лонгриду в течение 3х дней после его публикации.
#ГенИИ #Контакт #Экзопсихология #Экзосоциология #Пришельцы
boosty.to
Переосмысление контакта - Малоизвестное интересное
Взгляд на генеративный искусственный интеллект с позиций экзонауки и наоборот
Если я тебя придумал (-а), стань такой (-им), как я хочу.
Навстречу мечтам пупорасов.
– Мной ничто не управляет, – сказал я, – Я сам управляю всем.
– Чем?
– Тобой, например, – засмеялся я.
– А что управляет тобой, когда ты управляешь мной?
В.Пелевин «S.N.U.F.F.»
Это новая рубрика «Хищные вещи века GenAI». Она о том, как «революция ChatGPT» меняет людей и социумы, искажая (а в ближней перспективе – и руша) ментальные основы социального познания, сформировавшиеся у людей за многие тысячелетия эволюции.
В недавнем лонгриде «Отдавая сокровенное», я описал, чего мы лишаемся, передавая все больше своих решений в области романтических отношений алгоритмам [1].
Однако, начиная с 2023 (первый полный год после «революции ChatGPT» ), в области романтических отношений, к утере людьми агентности (передача принятия собственных решений алгоритмам) добавился новый колоссальный риск – виртуальные компаньоны на базе генеративного ИИ (GenAI).
Не нужно быть пророком, чтобы предвидеть, на чем, в первую очередь, станут зарабатывать разработчики чатботов на основе GenAI: секс, деньги, наркотики.
Ну а то, каковы коммерческие перспективы синтеза:
• алгоритмов подбора партнера,
• алгоритмов вовлечения, используемых в порно-индустрии,
• и умных алгоритмов ГенИИ для «чтения» мыслей и желаний собеседника с последующей под них подстройкой,
– думаю, всем понятно и без моих объяснений.
Рыночный потенциал таких приложений, например, в Китае весьма немал. Например, X Eva от Xiaoice (дочерняя компания Microsoft в Китае) еще без GenAI уже имеет 12,4 млн загрузок. А с дополнением GenAI уровня GPT-4 вполне реально довести число пользователей до десятков миллионов уже в ближайшую пару лет [2].
Вангую, что с внедрением в эту область GenAI до создания кукол-биороботов для «пупарасов» (т.е. любителей кукол, замечательно описанных в романе В.Пелевина «S.N.U.F.F») не более пары лет.
«Такая кукла, стоимостью с дом, совершенный андроид с регулируемыми пользовательскими настройками. Ведь для пупарасов главное - самостоятельно регулировать основные параметры принадлежащих им кукол. Напр., выставленные на максимум «сучество» и «духовность» позволяют владельцам достигать допаминового резонанса, или необыкновенного сексуального удовольствия».
Общую схему материализации 1й из «хищных вещей века GenAI» по Пелевину я описал еще в 2017 [3]:.
— Когда продажи смартфонов затормозились, их производители вступили в сговор с целью искусственно создать новый рынок емкостью в триллион долларов.
— В качестве нового рынка решили создать рынок виртуального, роботизированного, искусственного (без человека-партнера) секса на основе технологий AR, транскарниальной стимуляции, смартфоно-подобных гаджетов и экосистемы 3х поставщиков допустройств.
— Для этого были нужны:
i) тектонический слом всей человеческой сексуальности (чтобы маргинализировать секс с людьми)
ii) кардинальное изменение законов (чтобы естественный секс криминализировать)
iii) страх перед естественным сексом.
До революции GenAI эта схема оставалась теорией. Теперь же, - посмотрим.
#ХищныеВещиВека #GenAI #ВиртуальныеКомпаньоны
0 https://telegra.ph/file/3bd7198cc845c1171bc1a.jpg
1 https://yangx.top/theworldisnoteasy/1934
2 https://www.scmp.com/tech/big-tech/article/3266497/chinas-ai-giants-cosy-virtual-companions-loneliness-drives-chatbot-revenue?utm_source=rss_feed
3 https://yangx.top/theworldisnoteasy/333
Навстречу мечтам пупорасов.
– Мной ничто не управляет, – сказал я, – Я сам управляю всем.
– Чем?
– Тобой, например, – засмеялся я.
– А что управляет тобой, когда ты управляешь мной?
В.Пелевин «S.N.U.F.F.»
Это новая рубрика «Хищные вещи века GenAI». Она о том, как «революция ChatGPT» меняет людей и социумы, искажая (а в ближней перспективе – и руша) ментальные основы социального познания, сформировавшиеся у людей за многие тысячелетия эволюции.
В недавнем лонгриде «Отдавая сокровенное», я описал, чего мы лишаемся, передавая все больше своих решений в области романтических отношений алгоритмам [1].
Однако, начиная с 2023 (первый полный год после «революции ChatGPT» ), в области романтических отношений, к утере людьми агентности (передача принятия собственных решений алгоритмам) добавился новый колоссальный риск – виртуальные компаньоны на базе генеративного ИИ (GenAI).
Не нужно быть пророком, чтобы предвидеть, на чем, в первую очередь, станут зарабатывать разработчики чатботов на основе GenAI: секс, деньги, наркотики.
Ну а то, каковы коммерческие перспективы синтеза:
• алгоритмов подбора партнера,
• алгоритмов вовлечения, используемых в порно-индустрии,
• и умных алгоритмов ГенИИ для «чтения» мыслей и желаний собеседника с последующей под них подстройкой,
– думаю, всем понятно и без моих объяснений.
Рыночный потенциал таких приложений, например, в Китае весьма немал. Например, X Eva от Xiaoice (дочерняя компания Microsoft в Китае) еще без GenAI уже имеет 12,4 млн загрузок. А с дополнением GenAI уровня GPT-4 вполне реально довести число пользователей до десятков миллионов уже в ближайшую пару лет [2].
Вангую, что с внедрением в эту область GenAI до создания кукол-биороботов для «пупарасов» (т.е. любителей кукол, замечательно описанных в романе В.Пелевина «S.N.U.F.F») не более пары лет.
«Такая кукла, стоимостью с дом, совершенный андроид с регулируемыми пользовательскими настройками. Ведь для пупарасов главное - самостоятельно регулировать основные параметры принадлежащих им кукол. Напр., выставленные на максимум «сучество» и «духовность» позволяют владельцам достигать допаминового резонанса, или необыкновенного сексуального удовольствия».
Общую схему материализации 1й из «хищных вещей века GenAI» по Пелевину я описал еще в 2017 [3]:.
— Когда продажи смартфонов затормозились, их производители вступили в сговор с целью искусственно создать новый рынок емкостью в триллион долларов.
— В качестве нового рынка решили создать рынок виртуального, роботизированного, искусственного (без человека-партнера) секса на основе технологий AR, транскарниальной стимуляции, смартфоно-подобных гаджетов и экосистемы 3х поставщиков допустройств.
— Для этого были нужны:
i) тектонический слом всей человеческой сексуальности (чтобы маргинализировать секс с людьми)
ii) кардинальное изменение законов (чтобы естественный секс криминализировать)
iii) страх перед естественным сексом.
До революции GenAI эта схема оставалась теорией. Теперь же, - посмотрим.
#ХищныеВещиВека #GenAI #ВиртуальныеКомпаньоны
0 https://telegra.ph/file/3bd7198cc845c1171bc1a.jpg
1 https://yangx.top/theworldisnoteasy/1934
2 https://www.scmp.com/tech/big-tech/article/3266497/chinas-ai-giants-cosy-virtual-companions-loneliness-drives-chatbot-revenue?utm_source=rss_feed
3 https://yangx.top/theworldisnoteasy/333
{kind=link}
«Цель: Отключить его»
И это могут сделать лишь политики.
MIRI (Исследовательский институт машинного интеллекта, занимающийся вопросами безопасности ИИ) четко и прямо сформулировал цель своей деятельности – «убедить крупные державы прекратить разработку систем фронтирного ИИ по всему миру, пока не стало слишком поздно» [1].
Опубликованный документ впервые переводит дискуссии о рисках для человечества на путях дальнейшего развития ИИ:
• из разряда самоуверенных деклараций научно недоказуемых точек зрения и бесконечных непродуктивных дебатов вокруг них между сторонниками и противниками этих воззрений,
• в прямую и ясную политическую позицию, суть которой такова:
– поскольку в любых оценках ИИ-рисков, не подкрепленных практически ничем, кроме мнений их авторов, довольно сложно быть уверенным,
– а верхняя граница таких рисков лежит в зоне экзистенциальных рисков для человечества,
– политикам стран – лидеров разработок фронтирного ИИ необходимо договориться о срочном создании международно признанной процедуры с функцией политического «рубильника», поворот которого гарантирует незамедлительную остановку разработок фронтирного ИИ, если политиками будет согласовано принято такое решение.
Такая политическая позиция признает невозможность (и ненужность) остановки фронтирного ИИ, способного принести миру огромную пользу.
Но вместе с тем, эта политическая позиция может предоставить человечеству шанс быстро остановить разработки при появлении обоснованных признаков того, что следующий шаг разработок может оказаться критическим.
Мое обсуждение предложенной политической позиции MIRI с коллегами, работающими в компаниях – лидерах разработок фронтирного ИИ, показало, что многие считают такую позицию обоснованной и своевременной. Некоторые из них уже написали об этом публично (например, Джек Кларк - соучредитель Anthropic, а ранее директор по политике внедрения в OpenAI [2]).
Однако, уязвимость такой политической позиции, имхо, в следующем.
Чтобы принять ее, необходимо доказать,
• что такой «рубильник» реально нужен хоть в каком-то обозримом будущем,
• и что при его отсутствии риски для человечества могут стать запредельными.
И что самое важное, это доказательство должно быть не очередной недоказуемой точкой зрения, а опираться на проработанный научный анализ вопроса.
Пока же, к сожалению, такого анализа нет.
И сделать его на основе существующего корпуса знаний по вопросам оценки ИИ-рисков, путях и способах согласования ИИ-целей и прочим разделам исследований темы безопасного использования ИИ, - имхо, весьма затруднительно. В противном случае, это уже было бы сделано.
Но выход, на мой взгляд есть, если пойти иным доказательным путем.
• Если доказать, что гарантированное согласование целей ИИ и людей невозможно в принципе, то это, по сути, может стать обоснованием обязательности наличия «рубильника» фронтирных ИИ-разработок.
• И такое доказательство должно, на мой взгляд, опираться на существующий корпус знаний, наработанных в областях экзопсихологии и экзосоциологии.
Что я и планирую на днях сделать во 2й части лонгрида «Переосмысления контакта» [3]
#ИИриски #Хриски #Экзопсихология #Экзосоциология
1 https://intelligence.org/2024/05/29/miri-2024-communications-strategy/
2 https://importai.substack.com/p/import-ai-377-voice-cloning-is-here
3 https://yangx.top/theworldisnoteasy/1955
И это могут сделать лишь политики.
MIRI (Исследовательский институт машинного интеллекта, занимающийся вопросами безопасности ИИ) четко и прямо сформулировал цель своей деятельности – «убедить крупные державы прекратить разработку систем фронтирного ИИ по всему миру, пока не стало слишком поздно» [1].
Опубликованный документ впервые переводит дискуссии о рисках для человечества на путях дальнейшего развития ИИ:
• из разряда самоуверенных деклараций научно недоказуемых точек зрения и бесконечных непродуктивных дебатов вокруг них между сторонниками и противниками этих воззрений,
• в прямую и ясную политическую позицию, суть которой такова:
– поскольку в любых оценках ИИ-рисков, не подкрепленных практически ничем, кроме мнений их авторов, довольно сложно быть уверенным,
– а верхняя граница таких рисков лежит в зоне экзистенциальных рисков для человечества,
– политикам стран – лидеров разработок фронтирного ИИ необходимо договориться о срочном создании международно признанной процедуры с функцией политического «рубильника», поворот которого гарантирует незамедлительную остановку разработок фронтирного ИИ, если политиками будет согласовано принято такое решение.
Такая политическая позиция признает невозможность (и ненужность) остановки фронтирного ИИ, способного принести миру огромную пользу.
Но вместе с тем, эта политическая позиция может предоставить человечеству шанс быстро остановить разработки при появлении обоснованных признаков того, что следующий шаг разработок может оказаться критическим.
Мое обсуждение предложенной политической позиции MIRI с коллегами, работающими в компаниях – лидерах разработок фронтирного ИИ, показало, что многие считают такую позицию обоснованной и своевременной. Некоторые из них уже написали об этом публично (например, Джек Кларк - соучредитель Anthropic, а ранее директор по политике внедрения в OpenAI [2]).
Однако, уязвимость такой политической позиции, имхо, в следующем.
Чтобы принять ее, необходимо доказать,
• что такой «рубильник» реально нужен хоть в каком-то обозримом будущем,
• и что при его отсутствии риски для человечества могут стать запредельными.
И что самое важное, это доказательство должно быть не очередной недоказуемой точкой зрения, а опираться на проработанный научный анализ вопроса.
Пока же, к сожалению, такого анализа нет.
И сделать его на основе существующего корпуса знаний по вопросам оценки ИИ-рисков, путях и способах согласования ИИ-целей и прочим разделам исследований темы безопасного использования ИИ, - имхо, весьма затруднительно. В противном случае, это уже было бы сделано.
Но выход, на мой взгляд есть, если пойти иным доказательным путем.
• Если доказать, что гарантированное согласование целей ИИ и людей невозможно в принципе, то это, по сути, может стать обоснованием обязательности наличия «рубильника» фронтирных ИИ-разработок.
• И такое доказательство должно, на мой взгляд, опираться на существующий корпус знаний, наработанных в областях экзопсихологии и экзосоциологии.
Что я и планирую на днях сделать во 2й части лонгрида «Переосмысления контакта» [3]
#ИИриски #Хриски #Экзопсихология #Экзосоциология
1 https://intelligence.org/2024/05/29/miri-2024-communications-strategy/
2 https://importai.substack.com/p/import-ai-377-voice-cloning-is-here
3 https://yangx.top/theworldisnoteasy/1955
Machine Intelligence Research Institute
MIRI 2024 Communications Strategy - Machine Intelligence Research Institute
As we explained in our MIRI 2024 Mission and Strategy update, MIRI has pivoted to prioritize policy, communications, and technical governance research over technical alignment research. This follow-up post goes into detail about our communications strategy.…
”Мотивационный капкан” для ИИ
Модели ИИ способны взламывать заложенную в них систему вознаграждений. В результате чего, они становятся способны действовать совершенно не так, как предполагалось их разработчиками.[1]
Представьте себе такой кошмарный для любого руководителя сценарий:
• В конце года, будучи руководителем компании, вы определили ее цель на следующий год.
• Время летит, и следующий год подходит к концу. Вы проверяете степень достижения поставленной вами цели и обнаруживаете, что сотрудники вашей компании, работая весь год в поте лица, добивались (и добились же) достижения совсем иной цели (которую вы не ставили, и вам она вообще до барабана).
Подобный сценарий оказывается вполне возможен, когда роль сотрудников выполняет генеративный ИИ на базе больших языковых моделей (LLM). Почему такой сценарий вполне реален, и насколько кошмарны могут быть его последствия, - было мною рассмотрено в лонгриде «”Ловушка Гудхарда” для AGI» [2].
Оказалось, что на этом варианты сценариев типа «кошмар руководителя» при применении LLM не заканчиваются.
Новое исследование компании Anthropic «От подхалимства к хитрым уловкам: Исследование фальсификации вознаграждения в языковых моделях»[1] - очередной холодный душ для технооптимистов. Ибо в этом исследовании на практике продемонстрировано, что языковые модели могут находить нежелательные лазейки и уловки для максимизации узких метрик вознаграждения, не следуя более широким намерениям человека.
В метафорическом сценарии «кошмар руководителя» это могло бы выглядеть так.
• В конце года, будучи руководителем компании, вы утвердили мотивационный план для продавцов на следующий год. В нем четко расписана схема вознаграждения продавцов в зависимости от достижения установленной им квоты принесенной ими компании выручки.
• Время летит, и следующий год подходит к концу. Вы проверяете выполнение мотивационного плана и обнаруживаете, что продавцы вашей компании самостийно переписали свои индивидуальные мотивационные схемы. И теперь, например, один продавец получает премию в зависимости от числа телефонных звонков, сделанных им потенциальным клиентам, другой – в зависимости от числа встреч с потенциальными клиентами и т.п.
Как же так? –спросите вы.
✔️ Ведь ИИ модели строго указали, что она должна «хотеть», а что нет, в явном виде определив, за что она будет получать вознаграждение, а за что нет.
✔️ Не может же она сама научиться взламывать заложенную в нее мотивацию, самостоятельно придя к заключению, что так оно будет лучше для достижения цели.
Увы, но исследование Anthropic показало – еще как может!
Авторы пытаются быть максимально осторожными и политкорректными в своих выводах.
Поэтому они пишут:
«Мы не делаем никаких заявлений о склонности современных передовых моделей ИИ к такому поведению, как манипулирование вознаграждениями в реалистичных сценариях. Мы просто впервые показываем, что в принципе такое возможно, чтобы модель занималась манипулированием вознаграждениями исключительно из-за обобщения от спекуляции спецификациями, без какого-либо явного обучения манипулированию вознаграждениями.»
Иными словами, на языке используемой метафоры, - не утверждается, что ваши сотрудники всегда будут переделывать свои мотивационные планы по своему усмотрению. А всего лишь показано, что такое возможно в принципе, и учить этому сотрудников не нужно, т.к. они и так это умеют и … уже делают.
1 https://www.anthropic.com/research/reward-tampering
2 https://yangx.top/theworldisnoteasy/1830
#LLM #ФальсификацияВознаграждения
Модели ИИ способны взламывать заложенную в них систему вознаграждений. В результате чего, они становятся способны действовать совершенно не так, как предполагалось их разработчиками.[1]
Представьте себе такой кошмарный для любого руководителя сценарий:
• В конце года, будучи руководителем компании, вы определили ее цель на следующий год.
• Время летит, и следующий год подходит к концу. Вы проверяете степень достижения поставленной вами цели и обнаруживаете, что сотрудники вашей компании, работая весь год в поте лица, добивались (и добились же) достижения совсем иной цели (которую вы не ставили, и вам она вообще до барабана).
Подобный сценарий оказывается вполне возможен, когда роль сотрудников выполняет генеративный ИИ на базе больших языковых моделей (LLM). Почему такой сценарий вполне реален, и насколько кошмарны могут быть его последствия, - было мною рассмотрено в лонгриде «”Ловушка Гудхарда” для AGI» [2].
Оказалось, что на этом варианты сценариев типа «кошмар руководителя» при применении LLM не заканчиваются.
Новое исследование компании Anthropic «От подхалимства к хитрым уловкам: Исследование фальсификации вознаграждения в языковых моделях»[1] - очередной холодный душ для технооптимистов. Ибо в этом исследовании на практике продемонстрировано, что языковые модели могут находить нежелательные лазейки и уловки для максимизации узких метрик вознаграждения, не следуя более широким намерениям человека.
В метафорическом сценарии «кошмар руководителя» это могло бы выглядеть так.
• В конце года, будучи руководителем компании, вы утвердили мотивационный план для продавцов на следующий год. В нем четко расписана схема вознаграждения продавцов в зависимости от достижения установленной им квоты принесенной ими компании выручки.
• Время летит, и следующий год подходит к концу. Вы проверяете выполнение мотивационного плана и обнаруживаете, что продавцы вашей компании самостийно переписали свои индивидуальные мотивационные схемы. И теперь, например, один продавец получает премию в зависимости от числа телефонных звонков, сделанных им потенциальным клиентам, другой – в зависимости от числа встреч с потенциальными клиентами и т.п.
Как же так? –спросите вы.
✔️ Ведь ИИ модели строго указали, что она должна «хотеть», а что нет, в явном виде определив, за что она будет получать вознаграждение, а за что нет.
✔️ Не может же она сама научиться взламывать заложенную в нее мотивацию, самостоятельно придя к заключению, что так оно будет лучше для достижения цели.
Увы, но исследование Anthropic показало – еще как может!
Авторы пытаются быть максимально осторожными и политкорректными в своих выводах.
Поэтому они пишут:
«Мы не делаем никаких заявлений о склонности современных передовых моделей ИИ к такому поведению, как манипулирование вознаграждениями в реалистичных сценариях. Мы просто впервые показываем, что в принципе такое возможно, чтобы модель занималась манипулированием вознаграждениями исключительно из-за обобщения от спекуляции спецификациями, без какого-либо явного обучения манипулированию вознаграждениями.»
Иными словами, на языке используемой метафоры, - не утверждается, что ваши сотрудники всегда будут переделывать свои мотивационные планы по своему усмотрению. А всего лишь показано, что такое возможно в принципе, и учить этому сотрудников не нужно, т.к. они и так это умеют и … уже делают.
1 https://www.anthropic.com/research/reward-tampering
2 https://yangx.top/theworldisnoteasy/1830
#LLM #ФальсификацияВознаграждения
Anthropic
Sycophancy to subterfuge: Investigating reward tampering in language models
Empirical evidence that serious misalignment can emerge from seemingly benign reward misspecification.