
Автор или авторка: влияет ли пол автора на восприятие произведения
#society #arts
Корнелия Кулен, автор книги «Reading beyond the female: The relationship between perception of author gender and literary quality», исследует, как связана оценка литературного произведения с полом автора.
В своей книге Кулен фокусируется на оценке произведения читателями в зависимости от пола автора и реальных достоинств и недостатков текста. Она приводит данные The Riddle of Literary Quality, исследовательского проекта института истории Нидерландов и Амстердамского университета. Его цель — определить, какие факторы влияют на представление о тексте и его значимости и ценности.
Что спрашивали у читателей
В рамках проекта был проведен опрос читателей: их просили оценить роман по 7-балльной шкале и оставить краткий отзыв на одну из тех книг, которые они оценивали. В эксперименте участвовали 9791 женщина, 3897 мужчин и 96 людей, которые не раскрыли свой пол. Кулен провела регрессионный анализ результатов эксперимента. Ее интересовало, насколько точно независимые переменные — жанр, пол автора и факт перевода (переводная книга или нет) — позволяют прогнозировать зависимую, а именно рейтинг.
С помощью алгоритма множественной линейной регрессии удалось установить, что пол автора является значимым признаком: книги, написанные женщинами, получали более низкие оценки как за их литературные достоинства, так и за общее качество. Если же автором был мужчина, то рейтинг произведения увеличивался сразу на половину пункта. Также, женщины оценивают книги, написанные мужчинами выше, чем те, которые написаны женщиной, и наоборот.
Кулен задается вопросом, можно ли с помощью инструментов автоматической обработки естественного языка выявить объективную взаимосвязь пола автора и созданного им литературного произведения. Для этого был проведен ряд экспериментов.
Эксперимент 1. Бестселлеры и номинанты на премию: что волнует персонажей книг
В этом эксперименте тексты исследовали с помощью инструмента LIWC, Linguistic Inquiry and Word Count (лингвистическое исследование и подсчет слов). LIWC позволяет посчитать частоты слов из заданных списков слов (категорий) и относительную частоту этих слов для конкретного текста. Выбрали категории разных порядков: психологические, лингвистические или личные интересы.
Взяли два набора данных: корпус проекта The Riddle и корпус Nominees — номинантов на премию для нидерландских и бельгийских писателей AKO Literatuurprijs, сбалансированный по количеству мужчин и женщин (24 женщины, 25 мужчин и 1 трансгендерный мужчина).
Эксперимент 2. Машина вычисляет гендер автора
В этом эксперименте корпуса анализировали с помощью методов машинного обучения. Тексты исследуемых корпусов нужно было отнести к одному из двух классов: произведения, написанные автором-мужчиной, и тексты, написанные автором-женщиной.
За основу взяли идею обучения модели классификации с помощью метода опорных векторов на мешке слов (Bag-of-words, BOW) из 60% наиболее распространенных лемм в корпусе. Также была опробована модель на символьных триграмах — Char3grams. Обучение проводилось на корпусе the Riddle, а оценка модели проводилась сразу на двух корпусах: the Riddle и Nominees.
Эксперимент 3. Мужские и женские темы в литературе.
В этом эксперименте на основе корпуса the Riddle провели тематическое моделирование. Для этого из лемматизированного корпуса удалили служебные слова и пунктуацию и поделили его на фрагменты в 1000 токенов. Далее с помощью латентного распределения Дирихле (LDA, мы рассказываем об этом тут) были получены 50 тем и их весá в зависимости от пола автора.
О результатах экспериментов — со скриншотами, таблицами и графиками — читайте в нашей статье: https://sysblok.ru/society/avtor-ili-avtorka-vlijaet-li-pol-avtora-na-vosprijatie-proizvedenija/
Маруся Захарова, Мария Черных, Екатерина Смирнова
#society #arts
Корнелия Кулен, автор книги «Reading beyond the female: The relationship between perception of author gender and literary quality», исследует, как связана оценка литературного произведения с полом автора.
В своей книге Кулен фокусируется на оценке произведения читателями в зависимости от пола автора и реальных достоинств и недостатков текста. Она приводит данные The Riddle of Literary Quality, исследовательского проекта института истории Нидерландов и Амстердамского университета. Его цель — определить, какие факторы влияют на представление о тексте и его значимости и ценности.
Что спрашивали у читателей
В рамках проекта был проведен опрос читателей: их просили оценить роман по 7-балльной шкале и оставить краткий отзыв на одну из тех книг, которые они оценивали. В эксперименте участвовали 9791 женщина, 3897 мужчин и 96 людей, которые не раскрыли свой пол. Кулен провела регрессионный анализ результатов эксперимента. Ее интересовало, насколько точно независимые переменные — жанр, пол автора и факт перевода (переводная книга или нет) — позволяют прогнозировать зависимую, а именно рейтинг.
С помощью алгоритма множественной линейной регрессии удалось установить, что пол автора является значимым признаком: книги, написанные женщинами, получали более низкие оценки как за их литературные достоинства, так и за общее качество. Если же автором был мужчина, то рейтинг произведения увеличивался сразу на половину пункта. Также, женщины оценивают книги, написанные мужчинами выше, чем те, которые написаны женщиной, и наоборот.
Кулен задается вопросом, можно ли с помощью инструментов автоматической обработки естественного языка выявить объективную взаимосвязь пола автора и созданного им литературного произведения. Для этого был проведен ряд экспериментов.
Эксперимент 1. Бестселлеры и номинанты на премию: что волнует персонажей книг
В этом эксперименте тексты исследовали с помощью инструмента LIWC, Linguistic Inquiry and Word Count (лингвистическое исследование и подсчет слов). LIWC позволяет посчитать частоты слов из заданных списков слов (категорий) и относительную частоту этих слов для конкретного текста. Выбрали категории разных порядков: психологические, лингвистические или личные интересы.
Взяли два набора данных: корпус проекта The Riddle и корпус Nominees — номинантов на премию для нидерландских и бельгийских писателей AKO Literatuurprijs, сбалансированный по количеству мужчин и женщин (24 женщины, 25 мужчин и 1 трансгендерный мужчина).
Эксперимент 2. Машина вычисляет гендер автора
В этом эксперименте корпуса анализировали с помощью методов машинного обучения. Тексты исследуемых корпусов нужно было отнести к одному из двух классов: произведения, написанные автором-мужчиной, и тексты, написанные автором-женщиной.
За основу взяли идею обучения модели классификации с помощью метода опорных векторов на мешке слов (Bag-of-words, BOW) из 60% наиболее распространенных лемм в корпусе. Также была опробована модель на символьных триграмах — Char3grams. Обучение проводилось на корпусе the Riddle, а оценка модели проводилась сразу на двух корпусах: the Riddle и Nominees.
Эксперимент 3. Мужские и женские темы в литературе.
В этом эксперименте на основе корпуса the Riddle провели тематическое моделирование. Для этого из лемматизированного корпуса удалили служебные слова и пунктуацию и поделили его на фрагменты в 1000 токенов. Далее с помощью латентного распределения Дирихле (LDA, мы рассказываем об этом тут) были получены 50 тем и их весá в зависимости от пола автора.
О результатах экспериментов — со скриншотами, таблицами и графиками — читайте в нашей статье: https://sysblok.ru/society/avtor-ili-avtorka-vlijaet-li-pol-avtora-na-vosprijatie-proizvedenija/
Маруся Захарова, Мария Черных, Екатерина Смирнова
{kind=link}
«Слушание — это акт любви»: проет StoryCorps
#digitalmemory
Истории окружают нас повсюду — в новостях, фильмах и сериалах, соцсетях, книгах, подкастах и видеоиграх. Однако часто нас привлекают те рассказы, которые мы услышали от наших родственников, друзей и знакомых. Их истории объединяют разные поколения и события, становятся частью не только семейной, но и мировой культуры.
StoryCorps — это цифровая коллекция записей человеческих голосов, преимущественно из США и Латинской Америки. Полное собрание можно найти в Американском центре фольклора Библиотеки Конгресса в Вашингтоне, а большую часть коллекции — на платформе StoryCorps Archive. Сейчас в подборке больше 65 тыс. записей от более чем 100 тыс. участников. В нее входят публичные разговоры, записи из мобильных туров, интервью и беседы в специальных будках StoryBooths.
Миссия проекта — «налаживать связи между людьми и создавать более справедливый и сострадательный мир». Человек любой национальности, расы или вероисповедания может записать свой разговор и поделиться им с общественностью.
StoryCorps собирает материал в рамках исследования устной истории (Oral History, OH). Устная история — это сбор и изучение исторической информации об отдельных лицах, семьях, важных и повседневных событиях. Материал для изучения — аудио- и видеозаписи, транскрипции интервью. Устная история стремится получить информацию с тех точек зрения, которые часто отсутствуют в письменных источниках. Личное мнение интервьюируемого становится частью исторической памяти.
Краткая история проекта
Корпус вырос из проекта Sound Portraits Productions, который основал радиопродюсер и документалист Дэвид Исай. 23 октября 2003 года Исай открыл первую будку для записи историй на Центральном вокзале в Нью-Йорке, которая потом переместилась на Нижний Манхэттен.
StoryBooth — это небольшая студия звукозаписи, где сидит интервьюер, который в течение 40 минут направляет участников. В конце те получают бесплатный компакт-диск с записью интервью, после чего могут пожертвовать проекту $50 в качестве компенсации.
Затем будки появились в Современном еврейском музее в Сан-Франциско и в Атланте на общественной радиостанции WABE. Также StoryCorps превратила два трейлера в передвижные студии звукозаписи MobileBooth и запустила тур по стране. «Передвижники» сотрудничают с местными общественными радиостанциями, культурными учреждениями и организациями.
Не так давно команда архива запустила одноименное мобильное приложение для прослушивания и записи рассказов. Программа подготавливает вопросы для пользователей и дает советы для интервью; его длительность может быть любой. Приложение доступно для IOS и Android.
Инициативы и общественные программы StoryCorps
• Инициатива «Военные голоса» записывает и сохраняет истории ветеранов, военнослужащих и их семей.
• «11 сентября» собирает рассказы выживших, спасателей и пострадавших в теракте 11 сентября 2001 года.
• StoryCorps Legacy помогает людям с серьезными заболеваниями и их родственникам через сотрудничество с больницами, клиниками и хосписами.
• «Потеря памяти» поощряет людей с болезнью Альцгеймера и другими проблемам с памятью.
• Historias коллекционирует рассказы латиноамериканцев в США и Пуэрто-Рико.
• Griot отвечает за голоса и опыт афроамериканцев.
• OutLoud записывает истории представителей ЛГБТК.
• «Правосудие» сохраняет рассказы тех, чью жизнь изменили массовые лишения свободы и система уголовного правосудия.
Материалы StoryCorps сохраняют личную и коллективную память и фиксируют ценности культуры прошлого. Поэтому архив будет полезен не только современным исследователям, но и следующим поколениям людей.
https://sysblok.ru/digitalmemory/slushanie-jeto-akt-ljubvi-dlja-chego-nuzhen-storycorps/
Варвара Гузий
#digitalmemory
Истории окружают нас повсюду — в новостях, фильмах и сериалах, соцсетях, книгах, подкастах и видеоиграх. Однако часто нас привлекают те рассказы, которые мы услышали от наших родственников, друзей и знакомых. Их истории объединяют разные поколения и события, становятся частью не только семейной, но и мировой культуры.
StoryCorps — это цифровая коллекция записей человеческих голосов, преимущественно из США и Латинской Америки. Полное собрание можно найти в Американском центре фольклора Библиотеки Конгресса в Вашингтоне, а большую часть коллекции — на платформе StoryCorps Archive. Сейчас в подборке больше 65 тыс. записей от более чем 100 тыс. участников. В нее входят публичные разговоры, записи из мобильных туров, интервью и беседы в специальных будках StoryBooths.
Миссия проекта — «налаживать связи между людьми и создавать более справедливый и сострадательный мир». Человек любой национальности, расы или вероисповедания может записать свой разговор и поделиться им с общественностью.
StoryCorps собирает материал в рамках исследования устной истории (Oral History, OH). Устная история — это сбор и изучение исторической информации об отдельных лицах, семьях, важных и повседневных событиях. Материал для изучения — аудио- и видеозаписи, транскрипции интервью. Устная история стремится получить информацию с тех точек зрения, которые часто отсутствуют в письменных источниках. Личное мнение интервьюируемого становится частью исторической памяти.
Краткая история проекта
Корпус вырос из проекта Sound Portraits Productions, который основал радиопродюсер и документалист Дэвид Исай. 23 октября 2003 года Исай открыл первую будку для записи историй на Центральном вокзале в Нью-Йорке, которая потом переместилась на Нижний Манхэттен.
StoryBooth — это небольшая студия звукозаписи, где сидит интервьюер, который в течение 40 минут направляет участников. В конце те получают бесплатный компакт-диск с записью интервью, после чего могут пожертвовать проекту $50 в качестве компенсации.
Затем будки появились в Современном еврейском музее в Сан-Франциско и в Атланте на общественной радиостанции WABE. Также StoryCorps превратила два трейлера в передвижные студии звукозаписи MobileBooth и запустила тур по стране. «Передвижники» сотрудничают с местными общественными радиостанциями, культурными учреждениями и организациями.
Не так давно команда архива запустила одноименное мобильное приложение для прослушивания и записи рассказов. Программа подготавливает вопросы для пользователей и дает советы для интервью; его длительность может быть любой. Приложение доступно для IOS и Android.
Инициативы и общественные программы StoryCorps
• Инициатива «Военные голоса» записывает и сохраняет истории ветеранов, военнослужащих и их семей.
• «11 сентября» собирает рассказы выживших, спасателей и пострадавших в теракте 11 сентября 2001 года.
• StoryCorps Legacy помогает людям с серьезными заболеваниями и их родственникам через сотрудничество с больницами, клиниками и хосписами.
• «Потеря памяти» поощряет людей с болезнью Альцгеймера и другими проблемам с памятью.
• Historias коллекционирует рассказы латиноамериканцев в США и Пуэрто-Рико.
• Griot отвечает за голоса и опыт афроамериканцев.
• OutLoud записывает истории представителей ЛГБТК.
• «Правосудие» сохраняет рассказы тех, чью жизнь изменили массовые лишения свободы и система уголовного правосудия.
Материалы StoryCorps сохраняют личную и коллективную память и фиксируют ценности культуры прошлого. Поэтому архив будет полезен не только современным исследователям, но и следующим поколениям людей.
https://sysblok.ru/digitalmemory/slushanie-jeto-akt-ljubvi-dlja-chego-nuzhen-storycorps/
Варвара Гузий
YouTube
An Introduction to StoryCorps from our Founder, Dave Isay
Where did the idea for StoryCorps come from? Learn more about StoryCorps in this conversation between our founder, Dave Isay, and his nephew.
Listen to hundreds of stories at storycorps.org.
Listen to hundreds of stories at storycorps.org.
TEI: как можно кодировать тексты при оцифровке рукописей
#knowhow #digitalheritage
Сохранение текстов в электронном формате дает много новых возможностей: высокая скорость поиска информации, легкость правки, мультимедиа, гиперссылки. Поэтому появляется все больше проектов по оцифровке текстов из архивных документов, рукописей и древних надписей.
Однако, чтобы при оцифровке не утратить важную информацию, необходимо сохранять тексты со всеми нюансами и разночтениями, а также дополнять метаданными. Для этих целей был создан TEI — Text Encoding Initiative. Это машиночитаемый язык, который упрощает работу с текстом и выделяет необходимую информацию тегами.
На языке TEI можно хранить электронные текстовые источники, сведения об авторе, выходные данные, первоисточники, параметры рукописи, критический аппарат и многое другое.
Как устроен TEI
TEI был разработан в 1987 году, а кодифицирован в 1990-м. Это была попытка создать максимально исчерпывающий инструментарий разметки любых текстов: в нем есть единая система, набор рекомендаций и практик. И в отличие от других форматов, TEI можно обогащать и персонализировать в соответствии со специальными задачами.
Работа TEI основывается на формате кодирования текста XML. Самая главная часть синтаксиса XML — это теги, которые однозначно выделяют некоторые кусочки текста для компьютера. В XML нет готового предзаданного набора тегов: можно ставить свои удобные теги.
Этот формат отличается от других разметок (HTML, TeX) тем, что в XML теги принято использовать для описания содержания, а не внешнего вида или расположения текста. Например, можно описать квартиру или пошаговый рецепт приготовления хлеба. Смысл и интерпретация каждого тега задаются отдельно, то есть при кодировании нет определенного синтаксиса в виде слов.
Одной из особенностей кодирования является избирательность. TEI раскрывает только те особенности текста, которые интересуют кодировщика.
И конечно, кроме разметки самого текста TEI хранит множество мета-информации: время написания, дата публикации, библиография, особенности рукописи, даже гендеры действующих лиц — все это можно закодировать по стандартной процедуре.
О примерах использования TEI — в нашей статье: https://sysblok.ru/digital-heritage/tei-tekstovyj-instrumentarij-kotoryj-smog/
Полина Долгова
#knowhow #digitalheritage
Сохранение текстов в электронном формате дает много новых возможностей: высокая скорость поиска информации, легкость правки, мультимедиа, гиперссылки. Поэтому появляется все больше проектов по оцифровке текстов из архивных документов, рукописей и древних надписей.
Однако, чтобы при оцифровке не утратить важную информацию, необходимо сохранять тексты со всеми нюансами и разночтениями, а также дополнять метаданными. Для этих целей был создан TEI — Text Encoding Initiative. Это машиночитаемый язык, который упрощает работу с текстом и выделяет необходимую информацию тегами.
На языке TEI можно хранить электронные текстовые источники, сведения об авторе, выходные данные, первоисточники, параметры рукописи, критический аппарат и многое другое.
Как устроен TEI
TEI был разработан в 1987 году, а кодифицирован в 1990-м. Это была попытка создать максимально исчерпывающий инструментарий разметки любых текстов: в нем есть единая система, набор рекомендаций и практик. И в отличие от других форматов, TEI можно обогащать и персонализировать в соответствии со специальными задачами.
Работа TEI основывается на формате кодирования текста XML. Самая главная часть синтаксиса XML — это теги, которые однозначно выделяют некоторые кусочки текста для компьютера. В XML нет готового предзаданного набора тегов: можно ставить свои удобные теги.
Этот формат отличается от других разметок (HTML, TeX) тем, что в XML теги принято использовать для описания содержания, а не внешнего вида или расположения текста. Например, можно описать квартиру или пошаговый рецепт приготовления хлеба. Смысл и интерпретация каждого тега задаются отдельно, то есть при кодировании нет определенного синтаксиса в виде слов.
Одной из особенностей кодирования является избирательность. TEI раскрывает только те особенности текста, которые интересуют кодировщика.
И конечно, кроме разметки самого текста TEI хранит множество мета-информации: время написания, дата публикации, библиография, особенности рукописи, даже гендеры действующих лиц — все это можно закодировать по стандартной процедуре.
О примерах использования TEI — в нашей статье: https://sysblok.ru/digital-heritage/tei-tekstovyj-instrumentarij-kotoryj-smog/
Полина Долгова
{kind=link}
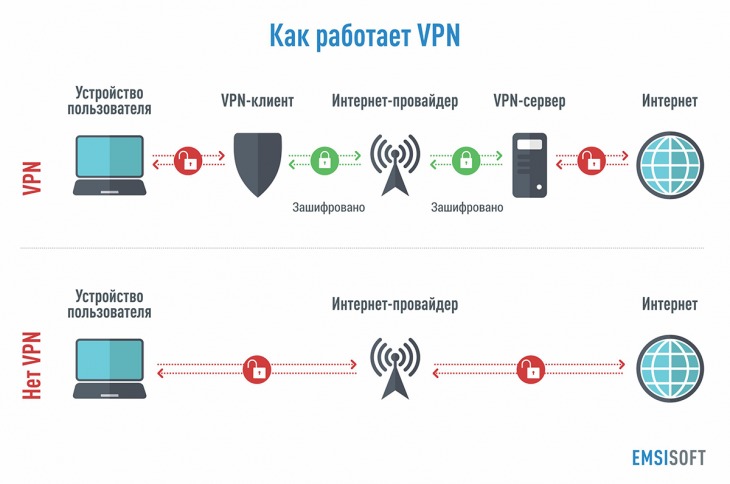
Что такое VPN и зачем его использовать
#society
VPN, или виртуальную частную сеть, сравнивают с плащом-невидимкой, туннелем или машиной с тонированными стеклами. Все эти метафоры указывают на одно: технология может что-то от кого-то скрыть.
Действительно, VPN — это закодированное безопасное соединение между пользователем и сетью, или между сетями. Система скрывает личные данные пользователя от остального Интернета и позволяет сохранить конфиденциальность действий.
VPN не заменяет интернет-подключение, а работает «поверх» него. Сначала интернет-трафик шифруется, затем направляется провайдеру, после чего пересылается на VPN-сервер. Этот сервер расшифровывает трафик и отправляет условному получателю (например, веб-сайту) уже дешифрованные данные. Это позволяет скрывать не только запросы пользователя, но и данные о его местоположении. Грубо говоря, технология скрывает IP от сайтов, а сайты от провайдера.
Когда VPN будет полезен
Когда нужно обеспечить защиту личных данных в Интернете при подключении к общедоступной сети WI-FI. Так, злоумышленники не смогут отследить посещаемые веб-адреса, перехватить реквизиты карт или другую приватную информацию.
Но сейчас эта функция постепенно себя изживает. Сегодня наши данные шифрует не только VPN, но и каждый сайт в браузере, который использует протокол https и помечен замком, каждое приложение iOS с 2016 и Android с 2018 года.
Когда нужно открыть доступ к заблокированным на определенной территории ресурсам. Это могут быть социальные сети, различные сайты или нежелательный контент. Например, через VPN вы сможете попасть из России на сайт заблокированной Роскомнадзором соцсети LinkedIn.
Виртуальную частную сеть активно используют финансовые компании, которым важно сохранить персональные данные клиентов. Банковские филиалы, например, предпочитают обмениваться зашифрованной информацией. Сейчас удаленный тип работы практикуют повсеместно, поэтому к корпоративным серверам подключаются через VPN, чтобы рабочие данные не попали к провайдеру.
Недостатки VPN
Не смотря на преимущества технологии, у нее есть и свои недостатки:
• Снижение скорости работы устройства из-за более долгого и сложного пути, который приходится преодолевать данным.
• Сложность в поиске надежного VPN-провайдера. Единого стандарта качества обслуживания у этих программ пока нет, поэтому приходится полагаться на отзывы других пользователей и метод «проб и ошибок».
• Все еще не полная конфиденциальность, так как файлы cookie могут вас распознать (но их можно отключить).
• Провайдер понимает, что от него что-то скрывают, так как видит проходящий через него VPN трафик. Выглядит это примерно так же, как когда кто-то пытается не привлекать внимания, насвистывая в неестественной позе. Так что если прятаться с умом, часть трафика, в котором нет ничего сверхсекретного (поиск рецепта в гугле), лучше оставлять без VPN.
• VPN-провайдеры знают ваш реальный IP и могут запросто его раскрыть (снова к вопросу о поиске надежного VPN-провайдера).
Насколько использование VPN законно
В каждой стране к VPN относятся по-разному. В России, например, есть закон «о запрете анонимайзеров и VPN» от 2017 года. Закон препятствует использованию технологии не полностью. Он не позволяет предоставлять услуги для доступа к запрещенным на территории России ресурсам. Если сервисы VPN игнорируют требования российского законодательства, их могут заблокировать.
Важно, что закон касается именно сервисов — пользователям по российским законам пока ничего не грозит.
https://sysblok.ru/society/tri-volshebnye-bukvy-chto-takoe-vpn-i-zachem-ego-ispolzovat/
Эвелина Григорьян
#society
VPN, или виртуальную частную сеть, сравнивают с плащом-невидимкой, туннелем или машиной с тонированными стеклами. Все эти метафоры указывают на одно: технология может что-то от кого-то скрыть.
Действительно, VPN — это закодированное безопасное соединение между пользователем и сетью, или между сетями. Система скрывает личные данные пользователя от остального Интернета и позволяет сохранить конфиденциальность действий.
VPN не заменяет интернет-подключение, а работает «поверх» него. Сначала интернет-трафик шифруется, затем направляется провайдеру, после чего пересылается на VPN-сервер. Этот сервер расшифровывает трафик и отправляет условному получателю (например, веб-сайту) уже дешифрованные данные. Это позволяет скрывать не только запросы пользователя, но и данные о его местоположении. Грубо говоря, технология скрывает IP от сайтов, а сайты от провайдера.
Когда VPN будет полезен
Когда нужно обеспечить защиту личных данных в Интернете при подключении к общедоступной сети WI-FI. Так, злоумышленники не смогут отследить посещаемые веб-адреса, перехватить реквизиты карт или другую приватную информацию.
Но сейчас эта функция постепенно себя изживает. Сегодня наши данные шифрует не только VPN, но и каждый сайт в браузере, который использует протокол https и помечен замком, каждое приложение iOS с 2016 и Android с 2018 года.
Когда нужно открыть доступ к заблокированным на определенной территории ресурсам. Это могут быть социальные сети, различные сайты или нежелательный контент. Например, через VPN вы сможете попасть из России на сайт заблокированной Роскомнадзором соцсети LinkedIn.
Виртуальную частную сеть активно используют финансовые компании, которым важно сохранить персональные данные клиентов. Банковские филиалы, например, предпочитают обмениваться зашифрованной информацией. Сейчас удаленный тип работы практикуют повсеместно, поэтому к корпоративным серверам подключаются через VPN, чтобы рабочие данные не попали к провайдеру.
Недостатки VPN
Не смотря на преимущества технологии, у нее есть и свои недостатки:
• Снижение скорости работы устройства из-за более долгого и сложного пути, который приходится преодолевать данным.
• Сложность в поиске надежного VPN-провайдера. Единого стандарта качества обслуживания у этих программ пока нет, поэтому приходится полагаться на отзывы других пользователей и метод «проб и ошибок».
• Все еще не полная конфиденциальность, так как файлы cookie могут вас распознать (но их можно отключить).
• Провайдер понимает, что от него что-то скрывают, так как видит проходящий через него VPN трафик. Выглядит это примерно так же, как когда кто-то пытается не привлекать внимания, насвистывая в неестественной позе. Так что если прятаться с умом, часть трафика, в котором нет ничего сверхсекретного (поиск рецепта в гугле), лучше оставлять без VPN.
• VPN-провайдеры знают ваш реальный IP и могут запросто его раскрыть (снова к вопросу о поиске надежного VPN-провайдера).
Насколько использование VPN законно
В каждой стране к VPN относятся по-разному. В России, например, есть закон «о запрете анонимайзеров и VPN» от 2017 года. Закон препятствует использованию технологии не полностью. Он не позволяет предоставлять услуги для доступа к запрещенным на территории России ресурсам. Если сервисы VPN игнорируют требования российского законодательства, их могут заблокировать.
Важно, что закон касается именно сервисов — пользователям по российским законам пока ничего не грозит.
https://sysblok.ru/society/tri-volshebnye-bukvy-chto-takoe-vpn-i-zachem-ego-ispolzovat/
Эвелина Григорьян
{kind=link}
Что хранит крупнейший онлайн-архив исторических документов Америки
#digitalheritage #history
Современная технология архивации старинных материалов позволяет хранить документы не только в шкафах, но и на просторах всемирной паутины. Архив института Гилдера-Лермана — крупнейшее и наиболее продвинутое хранилище документов американской истории.
Обширная коллекция знаний историков и более 70 000 документов коллекции доступны преподавателям, студентам и всем пользователям интернета, что дает прямой доступ к первоисточникам. Миссия архива — продвижение знаний и привлечение внимания к американской истории с помощью образовательных программ и ресурсов.
Какие документы хранятся в архиве
Исторический охват представленных данных составляет более четырехсот пятидесяти лет, с 1493-го года (т. е. сразу после открытия Америки) по настоящее время. Временные периоды разделены по тематикам: Колонизация и заселение Америки, Американская революция, Гражданская война, подъем индустриальной Америки и т. д.
Для учителей истории и их учеников есть особые вкладки с планами уроков, ресурсами для их проведения и первоисточниками исторических документов. Студенты могут пользоваться гайдами по прохождению выпускных и квалификационных экзаменов по истории, посещать онлайн-выставки американских музеев и смотреть документальные видео, которые помогут им в учебе.
Посетители сайта могут получить полный цифровой доступ по подписке или пользоваться всеми материалами архива бесплатно в течение тридцати дней в рамках пробного периода.
Все подробности — в нашей статье: https://sysblok.ru/digital-heritage/chto-hranit-krupnejshij-onlajn-arhiv-istoricheskih-dokumentov-ameriki/
Юлия Лундышева
#digitalheritage #history
Современная технология архивации старинных материалов позволяет хранить документы не только в шкафах, но и на просторах всемирной паутины. Архив института Гилдера-Лермана — крупнейшее и наиболее продвинутое хранилище документов американской истории.
Обширная коллекция знаний историков и более 70 000 документов коллекции доступны преподавателям, студентам и всем пользователям интернета, что дает прямой доступ к первоисточникам. Миссия архива — продвижение знаний и привлечение внимания к американской истории с помощью образовательных программ и ресурсов.
Какие документы хранятся в архиве
Исторический охват представленных данных составляет более четырехсот пятидесяти лет, с 1493-го года (т. е. сразу после открытия Америки) по настоящее время. Временные периоды разделены по тематикам: Колонизация и заселение Америки, Американская революция, Гражданская война, подъем индустриальной Америки и т. д.
Для учителей истории и их учеников есть особые вкладки с планами уроков, ресурсами для их проведения и первоисточниками исторических документов. Студенты могут пользоваться гайдами по прохождению выпускных и квалификационных экзаменов по истории, посещать онлайн-выставки американских музеев и смотреть документальные видео, которые помогут им в учебе.
Посетители сайта могут получить полный цифровой доступ по подписке или пользоваться всеми материалами архива бесплатно в течение тридцати дней в рамках пробного периода.
Все подробности — в нашей статье: https://sysblok.ru/digital-heritage/chto-hranit-krupnejshij-onlajn-arhiv-istoricheskih-dokumentov-ameriki/
Юлия Лундышева
{kind=link}
Искусство до и после: как создать онлайн-выставку на Google Arts&Culture
#digitalheritage #digitalmemory
Фонд «Четверг» делится опытом создания онлайн-выставки АРТ-ПАМЯТЬ — социокультурного проекта, специально адаптированного для платформы Google Arts&Culture во время карантина.
Идея проекта АРТ-ПАМЯТЬ
Идея проекта АРТ-ПАМЯТЬ родилась из размышлений о феномене памяти: все, что мы помним, по-своему важно, а передача памяти — одна из ключевых традиций человеческой культуры. Но почему некоторые воспоминания исчезают быстрее, чем другие? Что происходит с индивидуальной памятью с течением времени? Эти вопросы помогли сформировать базовую концепцию проекта: иногда наша память нуждается в посреднике, и этим посредником может быть искусство.
Героями проекта стали жители московского дома престарелых, которые в силу социальной изолированности лишены возможности зафиксировать, передать и сохранить свою память. Молодость этих людей пришлась на 60-е годы прошлого века, и сегодня их воспоминания — редкие свидетельства стремительно удаляющейся от нас эпохи.
Фонд объявил опен колл для современных художников и предложил им стать медиаторами памяти, которая по какой-то случайности оказалась никому не нужна. Так участниками проекта стали 18 художников, среди которых были представители актуального искусства и последователи классической школы, резиденты культурных институций и независимые художники.
Организация выставки
Созданные работы представили на закрытой выставке современного искусства, которую организовали в самом пансионате. Жители пансионата узнавали себя в каждой работе даже тогда, когда они не были основаны именно на их историях. Образ 60-х годов, кристаллизовавшийся на наших глазах из фрагментов воспоминаний, сочетал в себе внутреннюю, субъективную реальность людей и условия объективной реальности того времени.
После этого планировали провести выставку для широкой публики в пространстве одного из московских музеев, но режим самоизоляции исключил такую возможность. Тогда решили организовать онлайн-выставку на площадке с устойчивой аудиторией и отлаженной механикой цифровизации контента — платформе Google Arts&Culture.
Главная особенность платформы Google — фокус на сторителлинг. Платформа заточена на создание проектов, которые рассказывают истории с помощью произведений искусства.
О том, как выставку адаптировали к такому формату, и о специфике работы с платформой — читайте по ссылке: https://sysblok.ru/digitalmemory/iskusstvo-do-i-posle-kak-sozdat-onlajn-vystavku-na-google-arts-culture/
Дарья Дмитриева, Ксения Башмакова, Анастасия Ковальчук
#digitalheritage #digitalmemory
Фонд «Четверг» делится опытом создания онлайн-выставки АРТ-ПАМЯТЬ — социокультурного проекта, специально адаптированного для платформы Google Arts&Culture во время карантина.
Идея проекта АРТ-ПАМЯТЬ
Идея проекта АРТ-ПАМЯТЬ родилась из размышлений о феномене памяти: все, что мы помним, по-своему важно, а передача памяти — одна из ключевых традиций человеческой культуры. Но почему некоторые воспоминания исчезают быстрее, чем другие? Что происходит с индивидуальной памятью с течением времени? Эти вопросы помогли сформировать базовую концепцию проекта: иногда наша память нуждается в посреднике, и этим посредником может быть искусство.
Героями проекта стали жители московского дома престарелых, которые в силу социальной изолированности лишены возможности зафиксировать, передать и сохранить свою память. Молодость этих людей пришлась на 60-е годы прошлого века, и сегодня их воспоминания — редкие свидетельства стремительно удаляющейся от нас эпохи.
Фонд объявил опен колл для современных художников и предложил им стать медиаторами памяти, которая по какой-то случайности оказалась никому не нужна. Так участниками проекта стали 18 художников, среди которых были представители актуального искусства и последователи классической школы, резиденты культурных институций и независимые художники.
Организация выставки
Созданные работы представили на закрытой выставке современного искусства, которую организовали в самом пансионате. Жители пансионата узнавали себя в каждой работе даже тогда, когда они не были основаны именно на их историях. Образ 60-х годов, кристаллизовавшийся на наших глазах из фрагментов воспоминаний, сочетал в себе внутреннюю, субъективную реальность людей и условия объективной реальности того времени.
После этого планировали провести выставку для широкой публики в пространстве одного из московских музеев, но режим самоизоляции исключил такую возможность. Тогда решили организовать онлайн-выставку на площадке с устойчивой аудиторией и отлаженной механикой цифровизации контента — платформе Google Arts&Culture.
Главная особенность платформы Google — фокус на сторителлинг. Платформа заточена на создание проектов, которые рассказывают истории с помощью произведений искусства.
О том, как выставку адаптировали к такому формату, и о специфике работы с платформой — читайте по ссылке: https://sysblok.ru/digitalmemory/iskusstvo-do-i-posle-kak-sozdat-onlajn-vystavku-na-google-arts-culture/
Дарья Дмитриева, Ксения Башмакова, Анастасия Ковальчук
{kind=link}
Онлайн-выставки, цифровое кураторство и музейные IT: интервью с Владимиром Определеновым
#interviw #arts
Коронавирус повысил важность цифровой трансформации для музеев. «Системный Блокъ» поговорил о цифровом кураторстве, IT-трендах в музейной сфере и о внедрении искусственного интеллекта в Пушкинский музей с Владимиром Определеновым, заместителем директора по цифровому развитию ГМИИ им. Пушкина.
О чем мы поговорили с Владимиром Викторовичем
• О том, какие знания и навыки нужны специалистам по цифровым проектами в музейной сфере
• О самых актуальных ИТ-трендах в музейной сфере
• О том, как можно усовершенствовать работу IT-отделов в российских музеях и где можно применять ИИ
• О накапливании цифрового мусора
• О создании доменов для каждого музейного экспоната
• О доступности музея для всех категорий посетителей
• О том, насколько виртуальное посещение музеев может заменить реальное
Онлайн-проекты музея
• Лекции, материалы и виртуальный музей доступны в разделе «Наедине с Пушкинским».
• На платформе «Виртуальный Пушкинский» можно прогуляться по выставкам Цая Гоцяна, Щукина, проекта «Тату» и многим другим.
• Также можно посетить полноценный цифровой двойник выставки «От Дюрера до Матисса. Избранные рисунки из собрания ГМИИ им. А. С. Пушкина» в формате 4D, посмотреть на каждую вещь, приблизить ее.
https://sysblok.ru/arts/onlajn-vystavki-cifrovoe-kuratorstvo-i-muzejnye-it-intervju-s-vladimirom-opredelenovym/
Дарья Джиоева, Василиса Александрова, Даниил Скоринкин
#interviw #arts
Коронавирус повысил важность цифровой трансформации для музеев. «Системный Блокъ» поговорил о цифровом кураторстве, IT-трендах в музейной сфере и о внедрении искусственного интеллекта в Пушкинский музей с Владимиром Определеновым, заместителем директора по цифровому развитию ГМИИ им. Пушкина.
О чем мы поговорили с Владимиром Викторовичем
• О том, какие знания и навыки нужны специалистам по цифровым проектами в музейной сфере
• О самых актуальных ИТ-трендах в музейной сфере
• О том, как можно усовершенствовать работу IT-отделов в российских музеях и где можно применять ИИ
• О накапливании цифрового мусора
• О создании доменов для каждого музейного экспоната
• О доступности музея для всех категорий посетителей
• О том, насколько виртуальное посещение музеев может заменить реальное
Онлайн-проекты музея
• Лекции, материалы и виртуальный музей доступны в разделе «Наедине с Пушкинским».
• На платформе «Виртуальный Пушкинский» можно прогуляться по выставкам Цая Гоцяна, Щукина, проекта «Тату» и многим другим.
• Также можно посетить полноценный цифровой двойник выставки «От Дюрера до Матисса. Избранные рисунки из собрания ГМИИ им. А. С. Пушкина» в формате 4D, посмотреть на каждую вещь, приблизить ее.
https://sysblok.ru/arts/onlajn-vystavki-cifrovoe-kuratorstvo-i-muzejnye-it-intervju-s-vladimirom-opredelenovym/
Дарья Джиоева, Василиса Александрова, Даниил Скоринкин
{kind=link}
Не обделены вниманием: как IT-компании взаимодействуют с органами власти
#society
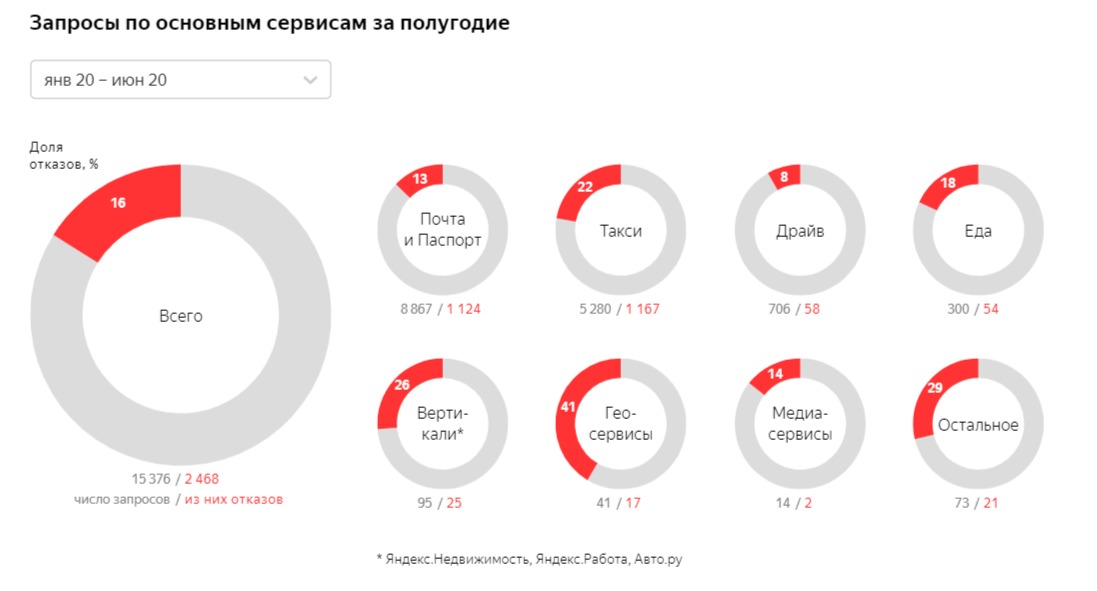
Недавно «Яндекс» раскрыл информацию о количестве запросов на раскрытие пользовательских данных, которые поступают к нему от госорганов. Это не первый случай, когда в России публикуется так называемый «отчет о прозрачности» (transparency report).
Отчёт о прозрачности раскрывает статистику о том, сколько раз за последнее полугодие органы государственной власти запрашивали у компании данные о пользователях, требовали удалить материалы или ограничить к ним доступ.
Прозрачность на Западе
Первой подобный отчёт опубликовала компания Google в 2010 году. Предпосылкой стал конфликт между интернет-гигантом и министерством юстиции США и последующая обеспокоенность нарушением конфиденциальности данных со стороны государства.
В конце 2009 года Google публикует в корпоративном блоге заявление о приверженности открытости и через несколько месяцев обнародует первый отчет, охватывающий полугодичный период, и в последующем добавляет дополнительные разделы: данные по ограничению трафика, основания предъявляемых требований, долю выполнения запросов.
К кампании по прозрачности присоединяются Twitter, Apple, Facebook и др. Наличие отчета улучшает положение компании в глазах пользователей.
Ситуация в России
Первыми в России отчет о прозрачности опубликовал Habr. В заявлении авторы указали на недоверие со стороны ряда пользователей в связи с трансформациями сайта и сервисов. Решением этой проблемы стала публикация в 2018 году отчёта и появление нового раздела о взаимодействии с госорганами и его постоянная актуализация.
В 2020 году к кампании по прозрачности присоединился Пикабу, также заявив, что цель подобных заявлений — это «демонстрация широкой публики открытость организации» и выполнение запросов собственных пользователей портала.
Интернет-компании Яндекс и Mail. ru ранее обвинялись в нераскрытии информации о взаимодействиях с органами власти. Заявление Яндекса начинается с тезиса о том, что компания «регулярно получает запросы от органов государственной власти» и не смотря ни на что вынуждена на них отвечать из-за действующего законодательства. Однако не указано, что компания заинтересована в открытости этих данных и желает выстроить доверительное взаимодействие с пользователями путём раскрытия подобных практик.
Что можно узнать из отчетов о прозрачности
Отчет о прозрачности — это не просто отчет о запросах данных пользователей, это широкий спектр практик взаимодействия с госорганами.
У компаний нет единых стандартов раскрытия информации: Яндекс сделал разбивку по сервисам, Хабр и Пикабу выделили заявителей (в лице МВД, Роскомнадзора и др.), а также сами требования (запрос информации о пользователе, исключение из результатов поиска, запрос о представлении пояснений).
Часто хотелось бы также видеть количество элементов, на которые направлены запросы, и количество затрагиваемых пользователей. Например, в отчете Google за вторую половину 2019 года со стороны России было 258 запроса, которые касались 463 аккаунтов — один запрос содержал несколько аккаунтов.
Взаимодействие с законом
Благодаря публикации отчетов о прозрачности виден масштаб взаимодействия частных компаний и государства, тенденции в работе правоохранительных и государственных органов. Возможности компаний и сервисов в публикациях отчётов дополнительно ограничены национальным законодательством, которое в случае чего может быть ужесточено.
В интересах гражданского общества и академических сообществ — требовать послабление условий публикации запросов. Например, через законных представителей в парламенте или через сбор подписей и формирование инициативных групп. Построение прозрачного и открытого общества требует усилий как компаний, так и самих пользователей.
Подробности со скриншотами — в нашей статье: https://sysblok.ru/society/ne-obdeleny-vnimaniem-kak-it-kompanii-vzaimodejstvujut-s-organami-vlasti/
Дмитрий Васильев
#society
Недавно «Яндекс» раскрыл информацию о количестве запросов на раскрытие пользовательских данных, которые поступают к нему от госорганов. Это не первый случай, когда в России публикуется так называемый «отчет о прозрачности» (transparency report).
Отчёт о прозрачности раскрывает статистику о том, сколько раз за последнее полугодие органы государственной власти запрашивали у компании данные о пользователях, требовали удалить материалы или ограничить к ним доступ.
Прозрачность на Западе
Первой подобный отчёт опубликовала компания Google в 2010 году. Предпосылкой стал конфликт между интернет-гигантом и министерством юстиции США и последующая обеспокоенность нарушением конфиденциальности данных со стороны государства.
В конце 2009 года Google публикует в корпоративном блоге заявление о приверженности открытости и через несколько месяцев обнародует первый отчет, охватывающий полугодичный период, и в последующем добавляет дополнительные разделы: данные по ограничению трафика, основания предъявляемых требований, долю выполнения запросов.
К кампании по прозрачности присоединяются Twitter, Apple, Facebook и др. Наличие отчета улучшает положение компании в глазах пользователей.
Ситуация в России
Первыми в России отчет о прозрачности опубликовал Habr. В заявлении авторы указали на недоверие со стороны ряда пользователей в связи с трансформациями сайта и сервисов. Решением этой проблемы стала публикация в 2018 году отчёта и появление нового раздела о взаимодействии с госорганами и его постоянная актуализация.
В 2020 году к кампании по прозрачности присоединился Пикабу, также заявив, что цель подобных заявлений — это «демонстрация широкой публики открытость организации» и выполнение запросов собственных пользователей портала.
Интернет-компании Яндекс и Mail. ru ранее обвинялись в нераскрытии информации о взаимодействиях с органами власти. Заявление Яндекса начинается с тезиса о том, что компания «регулярно получает запросы от органов государственной власти» и не смотря ни на что вынуждена на них отвечать из-за действующего законодательства. Однако не указано, что компания заинтересована в открытости этих данных и желает выстроить доверительное взаимодействие с пользователями путём раскрытия подобных практик.
Что можно узнать из отчетов о прозрачности
Отчет о прозрачности — это не просто отчет о запросах данных пользователей, это широкий спектр практик взаимодействия с госорганами.
У компаний нет единых стандартов раскрытия информации: Яндекс сделал разбивку по сервисам, Хабр и Пикабу выделили заявителей (в лице МВД, Роскомнадзора и др.), а также сами требования (запрос информации о пользователе, исключение из результатов поиска, запрос о представлении пояснений).
Часто хотелось бы также видеть количество элементов, на которые направлены запросы, и количество затрагиваемых пользователей. Например, в отчете Google за вторую половину 2019 года со стороны России было 258 запроса, которые касались 463 аккаунтов — один запрос содержал несколько аккаунтов.
Взаимодействие с законом
Благодаря публикации отчетов о прозрачности виден масштаб взаимодействия частных компаний и государства, тенденции в работе правоохранительных и государственных органов. Возможности компаний и сервисов в публикациях отчётов дополнительно ограничены национальным законодательством, которое в случае чего может быть ужесточено.
В интересах гражданского общества и академических сообществ — требовать послабление условий публикации запросов. Например, через законных представителей в парламенте или через сбор подписей и формирование инициативных групп. Построение прозрачного и открытого общества требует усилий как компаний, так и самих пользователей.
Подробности со скриншотами — в нашей статье: https://sysblok.ru/society/ne-obdeleny-vnimaniem-kak-it-kompanii-vzaimodejstvujut-s-organami-vlasti/
Дмитрий Васильев
{kind=link}
Мы с Тамарой ходим парой: как работает современный алгоритм токенизации текстов
#nlp
За последние несколько лет NLP совершила огромный скачок. Перевести текст в машиночитаемый формат можно с помощью различных инструментов: от матриц совместной встречаемости и Word2Vec до RNN и трансформеров.
А в качестве первого шага в обработке любого текста обычно проводится токенизация. На этом этапе происходит разделение текста на более мелкие единицы — на предложения и слова. Затем обычно создается словарь, в который заносятся уникальные лексемы, встретившиеся в корпусе или тексте. На этих этапах ученые сталкиваются с несколькими проблемами.
Проблема 1: языки с богатой морфологией
Это языки с развитыми системами склонений и спряжений слов. При работе с текстами на этих языках сложность возникает при составлении словаря, когда нужно найти и объединить все словоформы одной и той же лексемы.
Пример — русский язык, в котором есть падежи. При переводе слова в векторное пространство нужно учитывать, что стол, столу и столом – это одно слово в разных падежных формах, а не 3 уникальных лексемы. Чтобы решить эту задачу, текст можно предварительно лемматизировать, или применить стемминг (от английского stem – стебель), то есть просто отрезать у слов окончания.
Проблема 2: языки с продуктивным сложением основ
В германских языках (в английском, немецком, шведском и т.д.) очень продуктивно образуются новые сложные слова. Значения таких слов выводятся из значения их элементов, их можно создавать бесконечно долго, и большинство из них не зафиксировано в “бумажном” словаре.
При работе с этими языками сложность также возникает на этапе составления словаря. При составлении словаря модели ориентируются на частотность (например, сохраняем слово, если оно встретилось чаще пяти раз), поэтому не будут запоминать такое длинное и сложное слово.
Проблема 3: определение границ слова
Современные лингвисты до сих пор не могут придумать универсальное определение понятию слово и в каждой конкретной ситуации объясняют его по-разному. Для нас, привыкших к языкам европейского типа, слово — это набор букв между пробелами и знаками препинания. По таким разделителям компьютер тоже может легко найти слово.
Но в английском языке многие сложные слова пишутся раздельно, я в японском, наоборот, между словами вообще нет пробелов. Поэтому универсальный токенизатор создать было нелегко.
Решение — Byte Pair Encoding
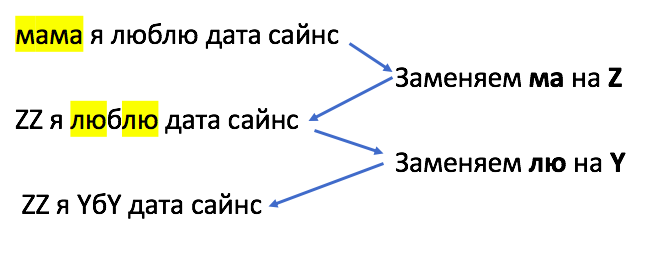
Первый настоящий прорыв в этом направлении был сделан исследователями из Эдинбургского университета. Они создали подслова в нейронном машинном переводе, используя алгоритм BPE — Byte Pair Encoding.
Изначально BPE был представлен как простой алгоритм сжатия данных без потерь. В феврале 1994 года Филипп Гейдж в статье «Новый алгоритм сжатия данных» описал метод, который работает так: самые частотные пары символов заменяются на другой символ, который не встречается в данных, при этом объем используемой памяти снижается с двух байт до одного. Пример кодировки прикрепляем ниже.
Для задач NLP алгоритм BPE был немного изменен: часто встречающиеся группы символов не заменяются на другой символ, а объединяются в токен и добавляются в словарь. Алгоритм токенизации на основе BPE позволяет моделям узнавать как можно больше слов при ограниченном объеме словаря и выглядит так:
Шаг 0. Создаем словарь.
Шаг 1. Представляем слова из текста как списки букв.
Шаг 2. Считаем количество вхождений каждой пары букв.
Шаг 3. Объединяем самые частотные в токен и добавляем в словарь.
Шаг 4. Повторяем шаг 3 до тех пор, пока не получим словарь заданного размера.
Сегодня схемы токенизации подслов стали нормой в самых продвинутых моделях, включая очень популярное семейство контекстных моделей, таких как BERT, GPT-2, RoBERTa и т. д.
https://sysblok.ru/nlp/7250/
Анна Аксенова
#nlp
За последние несколько лет NLP совершила огромный скачок. Перевести текст в машиночитаемый формат можно с помощью различных инструментов: от матриц совместной встречаемости и Word2Vec до RNN и трансформеров.
А в качестве первого шага в обработке любого текста обычно проводится токенизация. На этом этапе происходит разделение текста на более мелкие единицы — на предложения и слова. Затем обычно создается словарь, в который заносятся уникальные лексемы, встретившиеся в корпусе или тексте. На этих этапах ученые сталкиваются с несколькими проблемами.
Проблема 1: языки с богатой морфологией
Это языки с развитыми системами склонений и спряжений слов. При работе с текстами на этих языках сложность возникает при составлении словаря, когда нужно найти и объединить все словоформы одной и той же лексемы.
Пример — русский язык, в котором есть падежи. При переводе слова в векторное пространство нужно учитывать, что стол, столу и столом – это одно слово в разных падежных формах, а не 3 уникальных лексемы. Чтобы решить эту задачу, текст можно предварительно лемматизировать, или применить стемминг (от английского stem – стебель), то есть просто отрезать у слов окончания.
Проблема 2: языки с продуктивным сложением основ
В германских языках (в английском, немецком, шведском и т.д.) очень продуктивно образуются новые сложные слова. Значения таких слов выводятся из значения их элементов, их можно создавать бесконечно долго, и большинство из них не зафиксировано в “бумажном” словаре.
При работе с этими языками сложность также возникает на этапе составления словаря. При составлении словаря модели ориентируются на частотность (например, сохраняем слово, если оно встретилось чаще пяти раз), поэтому не будут запоминать такое длинное и сложное слово.
Проблема 3: определение границ слова
Современные лингвисты до сих пор не могут придумать универсальное определение понятию слово и в каждой конкретной ситуации объясняют его по-разному. Для нас, привыкших к языкам европейского типа, слово — это набор букв между пробелами и знаками препинания. По таким разделителям компьютер тоже может легко найти слово.
Но в английском языке многие сложные слова пишутся раздельно, я в японском, наоборот, между словами вообще нет пробелов. Поэтому универсальный токенизатор создать было нелегко.
Решение — Byte Pair Encoding
Первый настоящий прорыв в этом направлении был сделан исследователями из Эдинбургского университета. Они создали подслова в нейронном машинном переводе, используя алгоритм BPE — Byte Pair Encoding.
Изначально BPE был представлен как простой алгоритм сжатия данных без потерь. В феврале 1994 года Филипп Гейдж в статье «Новый алгоритм сжатия данных» описал метод, который работает так: самые частотные пары символов заменяются на другой символ, который не встречается в данных, при этом объем используемой памяти снижается с двух байт до одного. Пример кодировки прикрепляем ниже.
Для задач NLP алгоритм BPE был немного изменен: часто встречающиеся группы символов не заменяются на другой символ, а объединяются в токен и добавляются в словарь. Алгоритм токенизации на основе BPE позволяет моделям узнавать как можно больше слов при ограниченном объеме словаря и выглядит так:
Шаг 0. Создаем словарь.
Шаг 1. Представляем слова из текста как списки букв.
Шаг 2. Считаем количество вхождений каждой пары букв.
Шаг 3. Объединяем самые частотные в токен и добавляем в словарь.
Шаг 4. Повторяем шаг 3 до тех пор, пока не получим словарь заданного размера.
Сегодня схемы токенизации подслов стали нормой в самых продвинутых моделях, включая очень популярное семейство контекстных моделей, таких как BERT, GPT-2, RoBERTa и т. д.
https://sysblok.ru/nlp/7250/
Анна Аксенова
{kind=link}
«Цифровой антрополог отличается от Data Scientist’а вниманием к деталям»: интервью с Дарьей Радченко
#interview
В 2020 году в нашей повседневности многое изменилось. Чтобы лучше понять, что происходило с обществом, провалившимся в онлайн во время пандемии, «Системный Блокъ» обратился к специалисту по цифровым социальным исследованиям — Дарье Радченко, заместителю руководителя Центра городской антропологии КБ «Стрелка».
В марте 2020 года команда аналитиков из КБ «Стрелка» задалась вопросом о том, как город меняется во время карантина. К этому моменту уже появился, например, «Индекс самоизоляции» Яндекса, но им был интересен немного иной ракурс. При помощи анализа данных из Инстаграма и других социальных сетей они провели свое исследование.
О чем мы поговорили с Дарьей
• Какие подходы цифровые антропологи используют в своих исследованиях;
• Что говорят об эффективности весеннего карантина данные Инстаграма и других соцмедиа;
• Как люди на самоизоляции «переоткрыли» заново свои спальные районы;
• Каковы ограничения Data Science в социальных исследованиях.
https://sysblok.ru/interviews/cifrovoj-antropolog-otlichaetsja-ot-data-scientist-a-vnimaniem-k-detaljam-intervju-s-darej-radchenko-kb-strelka/
Оля Ивлиева, Даниил Скоринкин
#interview
В 2020 году в нашей повседневности многое изменилось. Чтобы лучше понять, что происходило с обществом, провалившимся в онлайн во время пандемии, «Системный Блокъ» обратился к специалисту по цифровым социальным исследованиям — Дарье Радченко, заместителю руководителя Центра городской антропологии КБ «Стрелка».
В марте 2020 года команда аналитиков из КБ «Стрелка» задалась вопросом о том, как город меняется во время карантина. К этому моменту уже появился, например, «Индекс самоизоляции» Яндекса, но им был интересен немного иной ракурс. При помощи анализа данных из Инстаграма и других социальных сетей они провели свое исследование.
О чем мы поговорили с Дарьей
• Какие подходы цифровые антропологи используют в своих исследованиях;
• Что говорят об эффективности весеннего карантина данные Инстаграма и других соцмедиа;
• Как люди на самоизоляции «переоткрыли» заново свои спальные районы;
• Каковы ограничения Data Science в социальных исследованиях.
https://sysblok.ru/interviews/cifrovoj-antropolog-otlichaetsja-ot-data-scientist-a-vnimaniem-k-detaljam-intervju-s-darej-radchenko-kb-strelka/
Оля Ивлиева, Даниил Скоринкин
{kind=link}
Социальный digital вместо нелегальных помидоров: интервью с сооснователем IT-проекта для беженцев TaQadam
#society #interview
Платформа TaQadam — пример интеграции социальных задач и IT-предпринимательства. Проект направлен на помощь одному из самых незащищенных слоев населения Ливана — беженцам. «Системный Блокъ» поговорил с сооснователем проекта Кариной Грошевой о том, как можно и нужно обеспечивать беженцев работой, которая не требует специального разрешения.
Статус беженца позволяет человеку без вида на жительство или гражданства легально находиться на территории страны, но не всегда разрешает работать. Из Сирии в соседний Ливан люди бежали от войны в надежде, что скоро вернутся домой. Сейчас временное пристанище стало для них постоянным.
Многие беженцы работают нелегально. Например, торгуют продуктами на рынке или продают одежду. Они часто пытаются перебраться в Европу, где есть шанс получить стабильное трудоустройство. Согласно данным BBC, в 2015 году в страны ЕС прибыли от 1 до 1,5 миллиона беженцев и нелегальных мигрантов.
Некоторые беженцы, оказавшиеся в Ливане, тоже пытаются добраться до Европы, но большинство все еще остается в стране. Несмотря на нестабильную экономическую ситуацию, заработок приходится искать внутри Ливана.
Проект TaQadam
IT-стартап TaQadam (с арабского — «прогресс») — один из вариантов легального трудоустройства. Суть работы — разметка спутниковых снимков. Беженцы отмечают на изображениях жилые дома и коммерческие здания, посевные поля и фермы, лес и траву. Создателям платформы поступает заказ на разметку определенной территории, а работники-беженцы выполняют заказ, после чего получают зарплату в долларах.
Пока штат работников невелик — около 80 человек трудятся на постоянной основе. Платформа живет от заказа к заказу, поэтому большее количество беженцев задействовать не получается.
О чем мы поговорили с Кариной
• Как возникла идея создать такой проект;
• Как создавалась платформа и как она работает сейчас;
• Почему TaQadam занимается спутниковыми снимками;
• Как беженцу начать работать с TaQadam и что конкретно он будет делать;
• Сколько можно заработать на разметке;
• О демографии работников и экосистеме стартапов в Ливане.
https://sysblok.ru/society/socialnyj-digital-vmesto-nelegalnyh-pomidorov-intervju-s-soosnovatelnicej-it-proekta-dlja-bezhencev-taqadam/
Виктория Багдасарьянц
#society #interview
Платформа TaQadam — пример интеграции социальных задач и IT-предпринимательства. Проект направлен на помощь одному из самых незащищенных слоев населения Ливана — беженцам. «Системный Блокъ» поговорил с сооснователем проекта Кариной Грошевой о том, как можно и нужно обеспечивать беженцев работой, которая не требует специального разрешения.
Статус беженца позволяет человеку без вида на жительство или гражданства легально находиться на территории страны, но не всегда разрешает работать. Из Сирии в соседний Ливан люди бежали от войны в надежде, что скоро вернутся домой. Сейчас временное пристанище стало для них постоянным.
Многие беженцы работают нелегально. Например, торгуют продуктами на рынке или продают одежду. Они часто пытаются перебраться в Европу, где есть шанс получить стабильное трудоустройство. Согласно данным BBC, в 2015 году в страны ЕС прибыли от 1 до 1,5 миллиона беженцев и нелегальных мигрантов.
Некоторые беженцы, оказавшиеся в Ливане, тоже пытаются добраться до Европы, но большинство все еще остается в стране. Несмотря на нестабильную экономическую ситуацию, заработок приходится искать внутри Ливана.
Проект TaQadam
IT-стартап TaQadam (с арабского — «прогресс») — один из вариантов легального трудоустройства. Суть работы — разметка спутниковых снимков. Беженцы отмечают на изображениях жилые дома и коммерческие здания, посевные поля и фермы, лес и траву. Создателям платформы поступает заказ на разметку определенной территории, а работники-беженцы выполняют заказ, после чего получают зарплату в долларах.
Пока штат работников невелик — около 80 человек трудятся на постоянной основе. Платформа живет от заказа к заказу, поэтому большее количество беженцев задействовать не получается.
О чем мы поговорили с Кариной
• Как возникла идея создать такой проект;
• Как создавалась платформа и как она работает сейчас;
• Почему TaQadam занимается спутниковыми снимками;
• Как беженцу начать работать с TaQadam и что конкретно он будет делать;
• Сколько можно заработать на разметке;
• О демографии работников и экосистеме стартапов в Ливане.
https://sysblok.ru/society/socialnyj-digital-vmesto-nelegalnyh-pomidorov-intervju-s-soosnovatelnicej-it-proekta-dlja-bezhencev-taqadam/
Виктория Багдасарьянц
{kind=link}
Как работают трансформеры — крутейшие нейросети наших дней
#knowhow
Трансформер — самая модная сегодня нейросетевая архитектура. Она появилась в 2017 и перевернула всю обработку языка машинами. Мы расскажем о структуре трансформера без кода — чтобы потом при взгляде на код вы могли понять, что он делает.
Трансформер придумали ученые из Google Research и Google Brain. Целью исследований была обработка естественного языка, но позже другие авторы адаптировали трансформерную архитектуру под любые последовательности. Сегодня если нейросеть распознает или генерирует текст, музыку или голос, скорее всего, где-то замешан трансформер.
В первой части нашей статьи
• Расскажем, что такое «внимание на себя» (self-attention) и зачем нужна нейросеть с прямой связью
• Введем новые термины, которые придумали изобретатели трансформера
• Расскажем подробнее о dot product attention, «скалярном внимании», (обычно это название не переводят).
• Расскажем о том, как из «скалярного внимания» сделать «взвешенное скалярное внимание»
• Объясним, зачем одну и ту же операцию «взвешенного скалярного внимания» повторять несколько раз с разными настройками: так получится описание «multi-head attention» — «многоголового внимания». Именно этот механизм задействован в нейросети-трансформере.
https://sysblok.ru/knowhow/kak-rabotajut-transformery-krutejshie-nejroseti-nashih-dnej/
Во второй части нашей статьи
• Добавим нормализацию;
• Добавим позиционное кодирование (перед самым первым слоем энкодера);
• Разберем устройство декодера, его отличия от энкодера;
• Сравним внимание «на себя» и не на себя;
• Объясним, что является результатом работы нейросети;
• Расскажем, что такое маскировка значений и зачем она нужна;
https://sysblok.ru/knowhow/nejroseti-transformery-iznutri-kak-rabotaet-dekoder/
Владимир Селеверстов
#knowhow
Трансформер — самая модная сегодня нейросетевая архитектура. Она появилась в 2017 и перевернула всю обработку языка машинами. Мы расскажем о структуре трансформера без кода — чтобы потом при взгляде на код вы могли понять, что он делает.
Трансформер придумали ученые из Google Research и Google Brain. Целью исследований была обработка естественного языка, но позже другие авторы адаптировали трансформерную архитектуру под любые последовательности. Сегодня если нейросеть распознает или генерирует текст, музыку или голос, скорее всего, где-то замешан трансформер.
В первой части нашей статьи
• Расскажем, что такое «внимание на себя» (self-attention) и зачем нужна нейросеть с прямой связью
• Введем новые термины, которые придумали изобретатели трансформера
• Расскажем подробнее о dot product attention, «скалярном внимании», (обычно это название не переводят).
• Расскажем о том, как из «скалярного внимания» сделать «взвешенное скалярное внимание»
• Объясним, зачем одну и ту же операцию «взвешенного скалярного внимания» повторять несколько раз с разными настройками: так получится описание «multi-head attention» — «многоголового внимания». Именно этот механизм задействован в нейросети-трансформере.
https://sysblok.ru/knowhow/kak-rabotajut-transformery-krutejshie-nejroseti-nashih-dnej/
Во второй части нашей статьи
• Добавим нормализацию;
• Добавим позиционное кодирование (перед самым первым слоем энкодера);
• Разберем устройство декодера, его отличия от энкодера;
• Сравним внимание «на себя» и не на себя;
• Объясним, что является результатом работы нейросети;
• Расскажем, что такое маскировка значений и зачем она нужна;
https://sysblok.ru/knowhow/nejroseti-transformery-iznutri-kak-rabotaet-dekoder/
Владимир Селеверстов
{kind=link}
«Системный Блокъ» запускает подкаст
#podcasts
Наш подкаст — об искусственном интеллекте. Сегодня словосочетание «искусственный интеллект» звучит отовсюду, но не значит примерно ничего. Поэтому наш подкаст называется «неопознанный искусственный интеллект», сокращенно «НИИ». Мы хотим разобраться, что называют искусственным интеллектом сегодня, как работают эти технологии, есть ли там настоящая «интеллектуальность» и появится ли она в будущем.
К нам в «НИИ» приходят люди, причастные к созданию искусственного интеллекта, — программисты, инженеры, лингвисты, математики, а также специалисты и ученые из других областей.
Наши гости
• Татьяна Шаврина, руководитель команды, которая занимается обработкой языка и искусственным интеллектом в Сбере;
• Константин Воронцов, профессор Вышки, профессор МФТИ, профессор РАН;
• Виктор Кантор, chief data scientist в МТС;
• Дмитрий Ветров, профессор, исследователь факультета компьютерных наук Высшей школы экономики
и другие эксперты в области машинного обучения, анализа данных и искусственного интеллекта.
Что мы обсуждаем с гостями
• где потолок развития нейросетей;
• что умеют GPT-2 и GPT-3;
• как понять, что машина стала разумной;
• нужны ли лингвисты для создания «сильного» ИИ;
• и не уничтожит ли такой ИИ человеческую цивилизацию💥
Где нас слушать
Первый выпуск подкаста «НИИ» мы выложим 7 декабря. А пока послушайте наш 3-минутный трейлер и подпишитесь на нас в Яндекс.Музыке или Apple Podcasts. Есть мы и в ВК.
А еще загляните на страничку «НИИ» на сайте «Системного Блока» — там есть дополнительные материалы для всех, кому интересны ИИ, data science и машинное обучение.
#podcasts
Наш подкаст — об искусственном интеллекте. Сегодня словосочетание «искусственный интеллект» звучит отовсюду, но не значит примерно ничего. Поэтому наш подкаст называется «неопознанный искусственный интеллект», сокращенно «НИИ». Мы хотим разобраться, что называют искусственным интеллектом сегодня, как работают эти технологии, есть ли там настоящая «интеллектуальность» и появится ли она в будущем.
К нам в «НИИ» приходят люди, причастные к созданию искусственного интеллекта, — программисты, инженеры, лингвисты, математики, а также специалисты и ученые из других областей.
Наши гости
• Татьяна Шаврина, руководитель команды, которая занимается обработкой языка и искусственным интеллектом в Сбере;
• Константин Воронцов, профессор Вышки, профессор МФТИ, профессор РАН;
• Виктор Кантор, chief data scientist в МТС;
• Дмитрий Ветров, профессор, исследователь факультета компьютерных наук Высшей школы экономики
и другие эксперты в области машинного обучения, анализа данных и искусственного интеллекта.
Что мы обсуждаем с гостями
• где потолок развития нейросетей;
• что умеют GPT-2 и GPT-3;
• как понять, что машина стала разумной;
• нужны ли лингвисты для создания «сильного» ИИ;
• и не уничтожит ли такой ИИ человеческую цивилизацию💥
Где нас слушать
Первый выпуск подкаста «НИИ» мы выложим 7 декабря. А пока послушайте наш 3-минутный трейлер и подпишитесь на нас в Яндекс.Музыке или Apple Podcasts. Есть мы и в ВК.
А еще загляните на страничку «НИИ» на сайте «Системного Блока» — там есть дополнительные материалы для всех, кому интересны ИИ, data science и машинное обучение.
Яндекс Музыка
Неопознанный Искусственный Интеллект (НИИ)
НИИ — подкаст про искусственный интеллект от издания «Системный Блокъ».
К нам в гости приходят ... • Подкаст • 3613 подписчиков
К нам в гости приходят ... • Подкаст • 3613 подписчиков
Интерактивная минералогия: как старинные рисунки камней стали цифровым проектом
#digitalheritage
Проект «Британская и экзотическая минералогия» — это коллаж из 718 изображений различных минералов мира. Ранее они входили в 7-томный сборник натуралиста, иллюстратора и минералога Джеймса Сауерби, созданный им в начале 19 века. Он создал наиболее точные и подробные рисунки известных полезных ископаемых и расположил их по цвету.
Исследователь собрал изображения в 2 серии из 718 пластин. После он поделил их на 5 томов о минералах Великобритании и 2 издания об экзотической минералогии. Работы ученого до сих пор считаются одними из лучших в этой области.
Кто и зачем создал интерактивный коллаж
В конце весны 2020 года трудом Сауерби заинтересовался веб-дизайнер Николас Ружо. Для этого художник данных обратился к отсканированным изданиям. Ружо «очистил» и восстановил первоначальную яркость и даты изображений. Все материалы по полезным ископаемым состояли из 718 ключевых цветов и 2242 рисунков.
Ружо хотел создать не репродукцию, а «уникальный взгляд на старую тему». В итоге у Николаса получился интерактивный коллаж. К каждому ископаемому прилагается подробное описание, список имен исследователей, характеристики и детали классификации.
Как Ружо создавал коллаж
Из-за ограничений по сборке, упаковке и сохранению размера картинок, Ружо обрабатывал иллюстрации блоками по 10 изображений и так перемещал их в редактор. Затем он отсортировал все цвета ископаемых по оттенку и разделил их на равные группы, которые сложились в столбцы.
Столбцы дизайнер разложил по яркости, чтобы расположить по ним восстановленные иллюстрации. Все они упаковывались с помощью программы InDesign в специальную сетку в соответствующие места. На видео можно посмотреть, как происходила расстановка первых 400 объектов.
На этом Николас не остановился: он сделал коллаж интерактивным, добавил плитки для масштабирования и горячие точки. Изображения стали кликабельными, у них появились характеристики и описания. Последние Ружо скопировал с оригинальных архивных иллюстраций и переформатировал.
Сам проект, по его словам, занял 4 месяца. Время подготовки финального коллажа составило 4,5 часа ручного перемещения элементов. Ниже прикрепляем финальную версию постера.
На странице проекта есть краткая инструкция о том, как находить данные и перемещаться по коллажу. При выборе объекта пользователь видит специальное окно с информацией об ископаемом. Справка содержит увеличенное изображение минерала, его синонимичные названия, описание его форм и физических характеристик.
Также, на сайте проекта можно заказать пазл или постер с коллажом.
https://sysblok.ru/digital-heritage/interaktivnaja-mineralogija-kak-starinnye-risunki-kamnej-stali-cifrovym-proektom/
Варвара Гузий
#digitalheritage
Проект «Британская и экзотическая минералогия» — это коллаж из 718 изображений различных минералов мира. Ранее они входили в 7-томный сборник натуралиста, иллюстратора и минералога Джеймса Сауерби, созданный им в начале 19 века. Он создал наиболее точные и подробные рисунки известных полезных ископаемых и расположил их по цвету.
Исследователь собрал изображения в 2 серии из 718 пластин. После он поделил их на 5 томов о минералах Великобритании и 2 издания об экзотической минералогии. Работы ученого до сих пор считаются одними из лучших в этой области.
Кто и зачем создал интерактивный коллаж
В конце весны 2020 года трудом Сауерби заинтересовался веб-дизайнер Николас Ружо. Для этого художник данных обратился к отсканированным изданиям. Ружо «очистил» и восстановил первоначальную яркость и даты изображений. Все материалы по полезным ископаемым состояли из 718 ключевых цветов и 2242 рисунков.
Ружо хотел создать не репродукцию, а «уникальный взгляд на старую тему». В итоге у Николаса получился интерактивный коллаж. К каждому ископаемому прилагается подробное описание, список имен исследователей, характеристики и детали классификации.
Как Ружо создавал коллаж
Из-за ограничений по сборке, упаковке и сохранению размера картинок, Ружо обрабатывал иллюстрации блоками по 10 изображений и так перемещал их в редактор. Затем он отсортировал все цвета ископаемых по оттенку и разделил их на равные группы, которые сложились в столбцы.
Столбцы дизайнер разложил по яркости, чтобы расположить по ним восстановленные иллюстрации. Все они упаковывались с помощью программы InDesign в специальную сетку в соответствующие места. На видео можно посмотреть, как происходила расстановка первых 400 объектов.
На этом Николас не остановился: он сделал коллаж интерактивным, добавил плитки для масштабирования и горячие точки. Изображения стали кликабельными, у них появились характеристики и описания. Последние Ружо скопировал с оригинальных архивных иллюстраций и переформатировал.
Сам проект, по его словам, занял 4 месяца. Время подготовки финального коллажа составило 4,5 часа ручного перемещения элементов. Ниже прикрепляем финальную версию постера.
На странице проекта есть краткая инструкция о том, как находить данные и перемещаться по коллажу. При выборе объекта пользователь видит специальное окно с информацией об ископаемом. Справка содержит увеличенное изображение минерала, его синонимичные названия, описание его форм и физических характеристик.
Также, на сайте проекта можно заказать пазл или постер с коллажом.
https://sysblok.ru/digital-heritage/interaktivnaja-mineralogija-kak-starinnye-risunki-kamnej-stali-cifrovym-proektom/
Варвара Гузий
{kind=link}
Первый выпуск подкаста НИИ: как прийти к «сильному» искусственному интеллекту 🤖
#podcasts
Темы первого выпуска
• Что может и чего не может современный «искусственный интеллект»
• Почему у нас нет универсальных роботов-помощников, подобных R2D2, JARVIS и C3PO
• В чем «узкий ИИ» (Narrow AI) еще бесконечно далек от человека
• Нужно ли моделировать ИИ на основе человеческого интеллекта и человеческого мозга
• Чем плох тест Тьюринга и какой тест позволил бы надежно определить интеллектуальность машины
• Почему подкаст называется «Неопознанный искусственный интеллект»
• И главное: что будет происходить в следующих выпусках, когда появятся гости
Хайлайты выпуска
1. Эпоха «узкого» ИИ
Мы живем в эпоху Narrow Artificial Intelligence или узкого искусственного интеллекта. Есть множество машин, которые умеют решать отдельные интеллектуальные задачи: Например, AlphaGo играет в Го, сверточная нейросеть в фотоприложении отличает кошечек от собачек, а антиблокировочная система в автомобиле управляет тормозами и понимает, когда их надо сжимать и разжимать — это тоже весьма интеллектуальная операция.
2. В чем проблема «узкого» ИИ
Узкие ИИ-системы неадаптивны — они не умеют приспосабливаться к разным задачам в процессе своей работы. Узкий ИИ противопоставляется общему или «сильному» ИИ — General Artificial Intelligence. «Сильный» ИИ должен приспосабливаться к новой среде и новым правилам, примерно как это делает человек. Но такого ИИ еще не существует.
3. Как тестировать ИИ на интеллектуальность
Тест Тьюринга слишком зависит от того, кто его проводит и какие вопросы он задает. Этот тест можно усложнить — например, не просто разговаривать с машиной, а пытаться научить ее играть в игру. Причем, любую — даже выдуманную на ходу. В этом суть «теста Старостина». Подробнее о тесте можно послушать в первом выпуске подкаста НИИ.
Где нас слушать или читать
Слушайте выпуск на Яндекс. Музыке, Apple Podcasts, Android Podcasts или в подкастах ВК.
Читайте нашу расшифровку, дополнительные материалы есть на страничке подкаста на сайте «Системного Блока».
#podcasts
Темы первого выпуска
• Что может и чего не может современный «искусственный интеллект»
• Почему у нас нет универсальных роботов-помощников, подобных R2D2, JARVIS и C3PO
• В чем «узкий ИИ» (Narrow AI) еще бесконечно далек от человека
• Нужно ли моделировать ИИ на основе человеческого интеллекта и человеческого мозга
• Чем плох тест Тьюринга и какой тест позволил бы надежно определить интеллектуальность машины
• Почему подкаст называется «Неопознанный искусственный интеллект»
• И главное: что будет происходить в следующих выпусках, когда появятся гости
Хайлайты выпуска
1. Эпоха «узкого» ИИ
Мы живем в эпоху Narrow Artificial Intelligence или узкого искусственного интеллекта. Есть множество машин, которые умеют решать отдельные интеллектуальные задачи: Например, AlphaGo играет в Го, сверточная нейросеть в фотоприложении отличает кошечек от собачек, а антиблокировочная система в автомобиле управляет тормозами и понимает, когда их надо сжимать и разжимать — это тоже весьма интеллектуальная операция.
2. В чем проблема «узкого» ИИ
Узкие ИИ-системы неадаптивны — они не умеют приспосабливаться к разным задачам в процессе своей работы. Узкий ИИ противопоставляется общему или «сильному» ИИ — General Artificial Intelligence. «Сильный» ИИ должен приспосабливаться к новой среде и новым правилам, примерно как это делает человек. Но такого ИИ еще не существует.
3. Как тестировать ИИ на интеллектуальность
Тест Тьюринга слишком зависит от того, кто его проводит и какие вопросы он задает. Этот тест можно усложнить — например, не просто разговаривать с машиной, а пытаться научить ее играть в игру. Причем, любую — даже выдуманную на ходу. В этом суть «теста Старостина». Подробнее о тесте можно послушать в первом выпуске подкаста НИИ.
Где нас слушать или читать
Слушайте выпуск на Яндекс. Музыке, Apple Podcasts, Android Podcasts или в подкастах ВК.
Читайте нашу расшифровку, дополнительные материалы есть на страничке подкаста на сайте «Системного Блока».
{kind=link}
Как измеряют вес исторических событий и личностей в коллективной памяти общества
#history #digitalmemory
Есть исторические события, о которых помнят, думают и спорят миллионы людей. А есть такие, которые никому не интересны, и никакие государственные выходные вроде Дня народного единства этого не изменят.
Ученые из Люксембургского центра современной цифровой истории, Токийского столичного университета и Киотского университета решили исследовать, как пользователи Twitter относятся к истории и какие события и исторические личности для них являются ключевыми.
Сбор данных
Исследователи работали с англоязычными твитами за март 2016 — февраль 2017, отобранными по специальному списку хэштегов — от #onthisday до #HistoryTeacher. Твитов было собрано около 1 миллиона.
На их основании ученые пытались определить популярность исторической личности или события, которым посвящен хэштег, а заодно привязать его к временной школе. Все относительные временные выражения были конвертированы в явные.
Какие даты интересуют пользователей
В первую очередь анализировались годы и исторические периоды, которые чаще всего интересуют пользователей. Выяснилось, что наибольший интерес представляют события сравнительно недавнего прошлого, произошедшие за последние 50 лет. Исключениями являются всего три даты:
• 1916 год — Верденская мясорубка;
• 1941 — вторжение Германии в СССР в июне, атака Японии на Перл-Харбор и вступление США в войну в декабре;
• 1945 — окончание второй мировой войны.
Больше всего твитов и ретвитов посвящено событиям 2016 года: выборам президента США и столетию событий Первой Мировой войны — битве при Вердене, битве на Сомме и Пасхальному восстанию в Дублине.
Какие субъекты истории интересуют пользователей
Все субъекты были разделены на пять категорий: «человек», «группа», «место», «событие» и «другое». Среди 30 самых популярных исторических субъектов — 22 географических наименования, два события и три исторических личности. Однако, несмотря на то, что больше всего упоминаются различные места, чаще всего употребляются исторические персоналии.
Например, с выборами 2016 года в Twitter связано всего одно место действия — Соединенные Штаты, а упоминаемых личностей как минимум пять: Дональд Трамп, Барак Обама, Билл Клинтон, Джордж Вашингтон и Авраам Линкольн.
Какой хештэг встречается чаще всего
Одним из самых популярных оказался хештэг #throwbackThursday (#TBT) — он задает тренд, в рамках которого пользователи публикуют картинки, вызывающие у них ностальгию. Но такая его популярность прослеживается лишь в рамках третьей категории, где считаются непосредственно количество пользователей, поставивших его под своими публикациями.
В оригинальных твитах и ретвитах чаще всего встречаются хэштеги #onthisday или #otd. Эти хештэги чаще всего используются специалистами-историками или на тематических страницах, а трендовый #TBT — в личных блогах.
Хэштеги также разделили на несколько тематических групп: «общеисторические» (#history, #historyfacts), с ярко выраженной национальной принадлежностью (#ancientgreece), тематическая история (#sportshistory), памятные (#onthisday, #weremember), событийные (#wwi, #sevenyearswar) и персональные (#stalin, #napoleon). Тематическая и «общеисторическая» категории составляют почти половину от общего числа твитов (29,4% и 22,4%), а следом с небольшим отрывом следуют памятные хэштеги (20,6%).
Больше подробностей, подтвержденных графиками и диаграммами, — в нашей статье: https://sysblok.ru/history/ot-verdena-do-hirosimy-ot-gitlera-do-trampa-kak-ustroena-kollektivnaja-pamjat-v-twitter/
Мария Черных
#history #digitalmemory
Есть исторические события, о которых помнят, думают и спорят миллионы людей. А есть такие, которые никому не интересны, и никакие государственные выходные вроде Дня народного единства этого не изменят.
Ученые из Люксембургского центра современной цифровой истории, Токийского столичного университета и Киотского университета решили исследовать, как пользователи Twitter относятся к истории и какие события и исторические личности для них являются ключевыми.
Сбор данных
Исследователи работали с англоязычными твитами за март 2016 — февраль 2017, отобранными по специальному списку хэштегов — от #onthisday до #HistoryTeacher. Твитов было собрано около 1 миллиона.
На их основании ученые пытались определить популярность исторической личности или события, которым посвящен хэштег, а заодно привязать его к временной школе. Все относительные временные выражения были конвертированы в явные.
Какие даты интересуют пользователей
В первую очередь анализировались годы и исторические периоды, которые чаще всего интересуют пользователей. Выяснилось, что наибольший интерес представляют события сравнительно недавнего прошлого, произошедшие за последние 50 лет. Исключениями являются всего три даты:
• 1916 год — Верденская мясорубка;
• 1941 — вторжение Германии в СССР в июне, атака Японии на Перл-Харбор и вступление США в войну в декабре;
• 1945 — окончание второй мировой войны.
Больше всего твитов и ретвитов посвящено событиям 2016 года: выборам президента США и столетию событий Первой Мировой войны — битве при Вердене, битве на Сомме и Пасхальному восстанию в Дублине.
Какие субъекты истории интересуют пользователей
Все субъекты были разделены на пять категорий: «человек», «группа», «место», «событие» и «другое». Среди 30 самых популярных исторических субъектов — 22 географических наименования, два события и три исторических личности. Однако, несмотря на то, что больше всего упоминаются различные места, чаще всего употребляются исторические персоналии.
Например, с выборами 2016 года в Twitter связано всего одно место действия — Соединенные Штаты, а упоминаемых личностей как минимум пять: Дональд Трамп, Барак Обама, Билл Клинтон, Джордж Вашингтон и Авраам Линкольн.
Какой хештэг встречается чаще всего
Одним из самых популярных оказался хештэг #throwbackThursday (#TBT) — он задает тренд, в рамках которого пользователи публикуют картинки, вызывающие у них ностальгию. Но такая его популярность прослеживается лишь в рамках третьей категории, где считаются непосредственно количество пользователей, поставивших его под своими публикациями.
В оригинальных твитах и ретвитах чаще всего встречаются хэштеги #onthisday или #otd. Эти хештэги чаще всего используются специалистами-историками или на тематических страницах, а трендовый #TBT — в личных блогах.
Хэштеги также разделили на несколько тематических групп: «общеисторические» (#history, #historyfacts), с ярко выраженной национальной принадлежностью (#ancientgreece), тематическая история (#sportshistory), памятные (#onthisday, #weremember), событийные (#wwi, #sevenyearswar) и персональные (#stalin, #napoleon). Тематическая и «общеисторическая» категории составляют почти половину от общего числа твитов (29,4% и 22,4%), а следом с небольшим отрывом следуют памятные хэштеги (20,6%).
Больше подробностей, подтвержденных графиками и диаграммами, — в нашей статье: https://sysblok.ru/history/ot-verdena-do-hirosimy-ot-gitlera-do-trampa-kak-ustroena-kollektivnaja-pamjat-v-twitter/
Мария Черных
{kind=link}
Эрмитаж онлайн: как служебный музейный каталог становится доступным для всех
#digitalheritage #arts
Единая система учета экспонатов Эрмитажа была создана еще в первой половине 20-го века. Однако до недавнего времени каталоги были доступны только «избранным» — музейным сотрудникам и профессиональным исследователям, — а пользоваться ими было крайне сложно.
Сейчас Эрмитаж постепенно переносит всю свою экспозицию в онлайн. Уже оцифрована примерно 1/10 всей коллекции, то есть около 400 тысяч экспонатов.
Сотрудники Эрмитажа параллельно развивают два проекта. Первый будет больше интересен туристам, а второй — специалистам. Подробнее о цифровой трансформации музеев России можно узнать из нашего интервью с Владимиром Определеновым.
Проект «В фокусе»
На сайте проекта «В фокусе» пока доступно всего 53 экспоната. Зато про каждый из них снято видео, в котором об экспонате рассказывают сами хранители и заведующие отделами, что гарантирует качество и достоверность информации. Среди видео-экскурсий есть короткие, которые длятся несколько минут, а есть — полноценные получасовые лекции.
На сайте представлены не только всем знакомые «обязательные для осмотра» экспонаты, но и менее известные произведения искусства и даже некоторые предметы интерьера. Для примера ниже прикрепляем видео с рассказом про «Мадонну с Младенцем» Леонардо да Винчи.
На все экспонаты можно посмотреть с хорошего ракурса, что затруднительно сделать в реальности из-за толп туристов. Также есть обзоры некоторых выставок и работает поиск по сайту, который позволяет сгруппировать объекты по времени их создания, по тематике и др.
Онлайн-коллекция Эрмитажа
Этот электронный каталог полезен тем, кто занимается искусством или историей профессионально. В онлайн-коллекции есть живопись, скульптура, нумизматика, археологические находки и другие экспонаты. Однако, так как на сайте сотни тысяч оцифрованных предметов, для всех экспонатов указана только самая ключевая информация.
Чтобы что-то найти, нужно воспользоваться расширенным поиском. Можно выбрать школу, к которой принадлежал автор работ, или организацию — например, продукция завода в Гусь-Хрустальном. Есть возможность сгруппировать экспонаты по коллекциям или выставкам. Также, можно выбрать конкретный объект, чтобы посмотреть детали.
Потенциально оба проекта могут развиваться до бесконечности, а точнее — до тех пор, пока не будут оцифрованы абсолютно все экспонаты. Ведь у каждого предмета есть своя интересная история, которую было бы здорово рассказать всему миру.
https://sysblok.ru/digital-heritage/kak-shodit-v-jermitazh-onlajn/
Светлана Филатова
#digitalheritage #arts
Единая система учета экспонатов Эрмитажа была создана еще в первой половине 20-го века. Однако до недавнего времени каталоги были доступны только «избранным» — музейным сотрудникам и профессиональным исследователям, — а пользоваться ими было крайне сложно.
Сейчас Эрмитаж постепенно переносит всю свою экспозицию в онлайн. Уже оцифрована примерно 1/10 всей коллекции, то есть около 400 тысяч экспонатов.
Сотрудники Эрмитажа параллельно развивают два проекта. Первый будет больше интересен туристам, а второй — специалистам. Подробнее о цифровой трансформации музеев России можно узнать из нашего интервью с Владимиром Определеновым.
Проект «В фокусе»
На сайте проекта «В фокусе» пока доступно всего 53 экспоната. Зато про каждый из них снято видео, в котором об экспонате рассказывают сами хранители и заведующие отделами, что гарантирует качество и достоверность информации. Среди видео-экскурсий есть короткие, которые длятся несколько минут, а есть — полноценные получасовые лекции.
На сайте представлены не только всем знакомые «обязательные для осмотра» экспонаты, но и менее известные произведения искусства и даже некоторые предметы интерьера. Для примера ниже прикрепляем видео с рассказом про «Мадонну с Младенцем» Леонардо да Винчи.
На все экспонаты можно посмотреть с хорошего ракурса, что затруднительно сделать в реальности из-за толп туристов. Также есть обзоры некоторых выставок и работает поиск по сайту, который позволяет сгруппировать объекты по времени их создания, по тематике и др.
Онлайн-коллекция Эрмитажа
Этот электронный каталог полезен тем, кто занимается искусством или историей профессионально. В онлайн-коллекции есть живопись, скульптура, нумизматика, археологические находки и другие экспонаты. Однако, так как на сайте сотни тысяч оцифрованных предметов, для всех экспонатов указана только самая ключевая информация.
Чтобы что-то найти, нужно воспользоваться расширенным поиском. Можно выбрать школу, к которой принадлежал автор работ, или организацию — например, продукция завода в Гусь-Хрустальном. Есть возможность сгруппировать экспонаты по коллекциям или выставкам. Также, можно выбрать конкретный объект, чтобы посмотреть детали.
Потенциально оба проекта могут развиваться до бесконечности, а точнее — до тех пор, пока не будут оцифрованы абсолютно все экспонаты. Ведь у каждого предмета есть своя интересная история, которую было бы здорово рассказать всему миру.
https://sysblok.ru/digital-heritage/kak-shodit-v-jermitazh-onlajn/
Светлана Филатова
YouTube
Мадонна с Младенцем. Леонардо да Винчи
Одно из немногих подлинных произведений Леонардо да Винчи и безусловный шедевр итальянского Возрождения, картина «Мадонна с Младенцем» («Мадонна с цветком») была написана Леонардо в 1478–1480 гг. во Флоренции и считается одной из первых самостоятельных работ…
Как лингвисты делают искусственный интеллект, а компьютер решает ЕГЭ
Второй выпуск подкаста Неопознанный Искусственный Интеллект — с Татьяной Шавриной
#podcasts
В студии подкаста Неопознанный Искусственный Интеллект — Татьяна Шаврина. Лингвист, программист, руководитель команды по обработке естественного языка и искусственному интеллекту в Сбере, соорганизатор AI Journey.
«Лингвистика для нас — центр всего. И программирование, и когнитивные науки, и гуманитарные вещи — все соединяются в ней».
О чем мы поговорили с Татьяной
• Как разработка искусственного интеллекта объединила лингвистику, программирование и когнитивные науки
• Что должен уметь «сильный ИИ» и как его построить
• Должен ли ИИ быть устроен как человеческий мозг
• Как должен быть устроен тест на интеллектуальность
• Чем растущий ребенок отличается от обучающейся нейросети
• Как нейросети решают ЕГЭ
• Как устроен русский SuperGLUE: головоломки для ИИ
• Что такое колониализм в ИИ
• Кого заменят роботы и какие статьи об ИИ стоит почитать
Хайлайты выпуска
1. Каковы критерии «сильного» ИИ
• Мультимодальность: он работает одновременно с информацией из разных источников — текстом, картинками, звуками, — и обрабатывает это все вместе.
• Мультидоменность: он одинаково хорошо работает в разных предметных областях и способен разбираться в новых.
• Адаптивность: он может сам приобретать новые навыки, причем на небольшом количестве примеров — на таком же, как это мог бы сделать человек, или даже меньше.
2. Как оценивают работу новых нейросетей и сравнивают их друг с другом
Когда выходит новая модель, ее оценивают по тому, как она справляется с решением benchmark’ов. Benchmark подразумевает, что у нас есть несколько типов заданий, у каждого из которых есть свой набор данных — в нем тренировочная выборка и тестовая. Тестовая выборка может быть открыта, а может быть скрыта. После оценки нейросеть добавляют в рейтинг, чтобы увидеть, где произошел прорыв, а где — просадка по качеству.
3. Как проявляется колониализм в цифровой среде
Происходящее в data science и вообще в интернет коммуникациях можно объяснить колониальной экономикой и политикой. Кто первый построил новую инфраструктуру, тот выкачивает все дорогостоящие данные, устанавливает свои правила и облагает остальных пользователей налогами.
Где нас слушать или читать
Слушайте выпуск на Яндекс. Музыке, Apple Podcasts, Google Podcasts или в подкастах ВК.
Расшифровка и дополнительные материалы — на странице подкаста на сайте «Системного Блока».
Второй выпуск подкаста Неопознанный Искусственный Интеллект — с Татьяной Шавриной
#podcasts
В студии подкаста Неопознанный Искусственный Интеллект — Татьяна Шаврина. Лингвист, программист, руководитель команды по обработке естественного языка и искусственному интеллекту в Сбере, соорганизатор AI Journey.
«Лингвистика для нас — центр всего. И программирование, и когнитивные науки, и гуманитарные вещи — все соединяются в ней».
О чем мы поговорили с Татьяной
• Как разработка искусственного интеллекта объединила лингвистику, программирование и когнитивные науки
• Что должен уметь «сильный ИИ» и как его построить
• Должен ли ИИ быть устроен как человеческий мозг
• Как должен быть устроен тест на интеллектуальность
• Чем растущий ребенок отличается от обучающейся нейросети
• Как нейросети решают ЕГЭ
• Как устроен русский SuperGLUE: головоломки для ИИ
• Что такое колониализм в ИИ
• Кого заменят роботы и какие статьи об ИИ стоит почитать
Хайлайты выпуска
1. Каковы критерии «сильного» ИИ
• Мультимодальность: он работает одновременно с информацией из разных источников — текстом, картинками, звуками, — и обрабатывает это все вместе.
• Мультидоменность: он одинаково хорошо работает в разных предметных областях и способен разбираться в новых.
• Адаптивность: он может сам приобретать новые навыки, причем на небольшом количестве примеров — на таком же, как это мог бы сделать человек, или даже меньше.
2. Как оценивают работу новых нейросетей и сравнивают их друг с другом
Когда выходит новая модель, ее оценивают по тому, как она справляется с решением benchmark’ов. Benchmark подразумевает, что у нас есть несколько типов заданий, у каждого из которых есть свой набор данных — в нем тренировочная выборка и тестовая. Тестовая выборка может быть открыта, а может быть скрыта. После оценки нейросеть добавляют в рейтинг, чтобы увидеть, где произошел прорыв, а где — просадка по качеству.
3. Как проявляется колониализм в цифровой среде
Происходящее в data science и вообще в интернет коммуникациях можно объяснить колониальной экономикой и политикой. Кто первый построил новую инфраструктуру, тот выкачивает все дорогостоящие данные, устанавливает свои правила и облагает остальных пользователей налогами.
Где нас слушать или читать
Слушайте выпуск на Яндекс. Музыке, Apple Podcasts, Google Podcasts или в подкастах ВК.
Расшифровка и дополнительные материалы — на странице подкаста на сайте «Системного Блока».
{kind=link}
Как работает GPT-2 и в чем его особенности
#nlp #knowhow
GPT-2 — нейросеть, которая способна генерировать образцы синтетического текста с вполне логичным повествованием, если задать ей любое начало. Модель учитывает стиль и содержание заданного ей фрагмента и уже на их основании создает свое продолжение истории. На момент релиза в ней было рекордное число параметров — 1,5 млрд против обычных 100–300 млн.
История создания и особенности GPT-2
Первая версия GPT (Generative Pre-trained Transformer) от OpenAI появилась еще летом 2018 года. Ее обучали на выборке текстов из Wikipedia и литературных произведений. Однако выяснилось, что нейросеть быстрее учится понимать естественную речь на основе простых постов в интернете. Поэтому в 2019 году OpenAI обучили GPT на больших объемах текстов — 8 млн. страниц из интернета. Новая версия нейросети получила название GPT-2.
Особенность GPT-2 в том, что она сразу — без дообучения — показала отличные результаты, близкие к state-of-the-art. Сразу после обучения нейросеть уже готова сгенерировать текст со всеми логическими вставками: повторное упоминание имен героев, цитаты, отсылки, выдержка одного стиля на протяжении всего текста, связанное повествование.
Таким образом GPT-2 могла понять суть задания примерно как человек — просто по его виду: если есть пропуски — дописать их, задают вопрос — попытаться ответить и т. д.
Что умеет GPT-2
Помимо простого создания текстов, модель можно использовать для следующих целей:
1. Краткий пересказ текста или обобщение.
В качестве входных данных нужно подать не просто фрагмент, а целый текст, состоящий из хотя бы пары абзацев (но лучше — страниц). Если в конце добавить «TL;DR», модель выдаст краткое содержание рассказа.
2. Ответы на вопросы исходя из содержания текста.
На входе подается несколько примеров в виде «Вопрос-Ответ», в конце же дается реальный вопрос, на который нейросеть выдает по тому же макету ответ.
3. Перевод текстов.
Механизм работы с переводами похож на механизм работы с ответами на вопросы. Главное — подать модели правильное начало, то есть нужную структуру текста. В оригинале GPT-2 подавали фрагменты в виде «hello- = привет» и так далее, используя английский и французский. В итоге, когда в конце была фраза «cat = …», нейросеть, следуя логике, выдала «кошку».
О том, как обучали GPT-2 и почему OpenAI предоставили доступ к его полной версии только через год после создания — читайте в нашей статье: https://sysblok.ru/knowhow/kak-rabotaet-gpt-2-i-v-chem-ego-osobennosti/
Камилла Кубелекова, Владимир Селеверстов
#nlp #knowhow
GPT-2 — нейросеть, которая способна генерировать образцы синтетического текста с вполне логичным повествованием, если задать ей любое начало. Модель учитывает стиль и содержание заданного ей фрагмента и уже на их основании создает свое продолжение истории. На момент релиза в ней было рекордное число параметров — 1,5 млрд против обычных 100–300 млн.
История создания и особенности GPT-2
Первая версия GPT (Generative Pre-trained Transformer) от OpenAI появилась еще летом 2018 года. Ее обучали на выборке текстов из Wikipedia и литературных произведений. Однако выяснилось, что нейросеть быстрее учится понимать естественную речь на основе простых постов в интернете. Поэтому в 2019 году OpenAI обучили GPT на больших объемах текстов — 8 млн. страниц из интернета. Новая версия нейросети получила название GPT-2.
Особенность GPT-2 в том, что она сразу — без дообучения — показала отличные результаты, близкие к state-of-the-art. Сразу после обучения нейросеть уже готова сгенерировать текст со всеми логическими вставками: повторное упоминание имен героев, цитаты, отсылки, выдержка одного стиля на протяжении всего текста, связанное повествование.
Таким образом GPT-2 могла понять суть задания примерно как человек — просто по его виду: если есть пропуски — дописать их, задают вопрос — попытаться ответить и т. д.
Что умеет GPT-2
Помимо простого создания текстов, модель можно использовать для следующих целей:
1. Краткий пересказ текста или обобщение.
В качестве входных данных нужно подать не просто фрагмент, а целый текст, состоящий из хотя бы пары абзацев (но лучше — страниц). Если в конце добавить «TL;DR», модель выдаст краткое содержание рассказа.
2. Ответы на вопросы исходя из содержания текста.
На входе подается несколько примеров в виде «Вопрос-Ответ», в конце же дается реальный вопрос, на который нейросеть выдает по тому же макету ответ.
3. Перевод текстов.
Механизм работы с переводами похож на механизм работы с ответами на вопросы. Главное — подать модели правильное начало, то есть нужную структуру текста. В оригинале GPT-2 подавали фрагменты в виде «hello- = привет» и так далее, используя английский и французский. В итоге, когда в конце была фраза «cat = …», нейросеть, следуя логике, выдала «кошку».
О том, как обучали GPT-2 и почему OpenAI предоставили доступ к его полной версии только через год после создания — читайте в нашей статье: https://sysblok.ru/knowhow/kak-rabotaet-gpt-2-i-v-chem-ego-osobennosti/
Камилла Кубелекова, Владимир Селеверстов
{kind=link}
Как обучать датасаентистов, играя в шляпу
Третий выпуск подкаста Неопознанный Искусственный Интеллект — с Виктором Кантором
#podcasts
В студии подкаста — Виктор Кантор. Виктор руководит Data Science в МТС и преподает машинное обучение. Виктор — соавтор популярной специализации по машинному обучению на Coursera, преподает в вузах и на офлайн-курсах по машинному обучению «Data Mining in Action».
Мы пригласили его в наш подкаст, чтобы обсудить преподавание Data Science, развитие технологий машинного обучения и, конечно, будущее искусственного интеллекта.
О чем мы поговорили с Виктором
• Как обучать крутых датасаентистов;
• Как распознать инфоцыган, продающих некачественное образование
• Чем отличаются Data Mining, машинное обучение и Data Science;
• Возможен ли сильный искусственный интеллект;
• Что мешает преодолеть «узость» ИИ и так ли универсален человеческий мозг;
• Как научить робота ловить рыбу и будем ли мы программировать на естественном языке;
• Как стать крутым преподавателем Data Science и чем помогает игра в шляпу;
• Как запускать космические корабли в далеком будущем;
• Кто самый крутой русский датасаентист и о чем говорить с искусственным интеллектом.
Хайлайты выпуска
1. Как развивать General Artificial Intelligence
Наука не развивается по плану: для того, чтобы развивать General Artificial Intelligence, не обязательно верить, что-то получится, и не обязательно знать заранее, что мы воспринимаем как GAI. Можно просто решать больше задач, которые сейчас кажутся неподъемными, и постепенно приходить в ту точку, когда то, что получится, люди назовут General Artificial Intelligence.
То есть постепенно мы будем закрывать все больше узких задач, и постепенно у нас будут появляться алгоритмы, которые будут такое количество узких задач решать, что нам уже не так принципиально будет, что все они такие узкие.
2. На каком языке мы общаемся с ИИ
Чтобы роботы выполняли наши задачи, нам нужно уметь формулировать их так, чтобы их можно было выполнить в точности. На естественном языке можно выразить любой, доступный человеку смысл, но и интерпретировать его можно по-разному. General AI, наверное, должен сам уметь что-то делать с недостаточно точно сформулированной задачей.
Однако узкие ИИ так не умеют, поэтому мы пока перебираем разные возможные языки общения. Один из языков общения — обучающая выборка, примеры. ИИ учится на них, а мы ему говорим, что надо оптимизировать. Другой язык общения — среда, которая позволяет ИИ действовать определенным образом и периодически выдает ему фидбек, вознаграждает за какие-то действия. Это называется Reinforcement Learning, или обучение с подкреплением.
3. Что важно для преподавателя в Data Science
Будучи преподавателем, главное, себя не обманывать — понимать, какой у тебя есть реальный опыт и стараться учить в рамках него, а не пытаться себя выдавать за того, кем ты не являешься.
К преподаванию мотивирует осознание того, что ты вроде бы приходишь просто лекцию читать, но если делаешь это действительно хорошо — получается, что на самом деле в будущем запускаешь корабли в космос. Потому что сформированные с твоей помощью крутые специалисты и будут менять наше будущее.
Где нас слушать или читать
Слушайте выпуск на Яндекс. Музыке, Apple Podcasts, Google Podcasts или в подкастах ВК.
Расшифровка и дополнительные материалы — на странице подкаста на сайте «Системного Блока».
Третий выпуск подкаста Неопознанный Искусственный Интеллект — с Виктором Кантором
#podcasts
В студии подкаста — Виктор Кантор. Виктор руководит Data Science в МТС и преподает машинное обучение. Виктор — соавтор популярной специализации по машинному обучению на Coursera, преподает в вузах и на офлайн-курсах по машинному обучению «Data Mining in Action».
Мы пригласили его в наш подкаст, чтобы обсудить преподавание Data Science, развитие технологий машинного обучения и, конечно, будущее искусственного интеллекта.
О чем мы поговорили с Виктором
• Как обучать крутых датасаентистов;
• Как распознать инфоцыган, продающих некачественное образование
• Чем отличаются Data Mining, машинное обучение и Data Science;
• Возможен ли сильный искусственный интеллект;
• Что мешает преодолеть «узость» ИИ и так ли универсален человеческий мозг;
• Как научить робота ловить рыбу и будем ли мы программировать на естественном языке;
• Как стать крутым преподавателем Data Science и чем помогает игра в шляпу;
• Как запускать космические корабли в далеком будущем;
• Кто самый крутой русский датасаентист и о чем говорить с искусственным интеллектом.
Хайлайты выпуска
1. Как развивать General Artificial Intelligence
Наука не развивается по плану: для того, чтобы развивать General Artificial Intelligence, не обязательно верить, что-то получится, и не обязательно знать заранее, что мы воспринимаем как GAI. Можно просто решать больше задач, которые сейчас кажутся неподъемными, и постепенно приходить в ту точку, когда то, что получится, люди назовут General Artificial Intelligence.
То есть постепенно мы будем закрывать все больше узких задач, и постепенно у нас будут появляться алгоритмы, которые будут такое количество узких задач решать, что нам уже не так принципиально будет, что все они такие узкие.
2. На каком языке мы общаемся с ИИ
Чтобы роботы выполняли наши задачи, нам нужно уметь формулировать их так, чтобы их можно было выполнить в точности. На естественном языке можно выразить любой, доступный человеку смысл, но и интерпретировать его можно по-разному. General AI, наверное, должен сам уметь что-то делать с недостаточно точно сформулированной задачей.
Однако узкие ИИ так не умеют, поэтому мы пока перебираем разные возможные языки общения. Один из языков общения — обучающая выборка, примеры. ИИ учится на них, а мы ему говорим, что надо оптимизировать. Другой язык общения — среда, которая позволяет ИИ действовать определенным образом и периодически выдает ему фидбек, вознаграждает за какие-то действия. Это называется Reinforcement Learning, или обучение с подкреплением.
3. Что важно для преподавателя в Data Science
Будучи преподавателем, главное, себя не обманывать — понимать, какой у тебя есть реальный опыт и стараться учить в рамках него, а не пытаться себя выдавать за того, кем ты не являешься.
К преподаванию мотивирует осознание того, что ты вроде бы приходишь просто лекцию читать, но если делаешь это действительно хорошо — получается, что на самом деле в будущем запускаешь корабли в космос. Потому что сформированные с твоей помощью крутые специалисты и будут менять наше будущее.
Где нас слушать или читать
Слушайте выпуск на Яндекс. Музыке, Apple Podcasts, Google Podcasts или в подкастах ВК.
Расшифровка и дополнительные материалы — на странице подкаста на сайте «Системного Блока».
{kind=link}