
Как нейросеть заменяет нецензурную лексику на эвфемизмы
#knowhow #nlp
Машинное обучение разрешает менять стилистику текста без изменения содержания. Например, нейросеть сгенерировала песни в стиле Егора Летова, а также ведет аккаунт Neural Meduza в Twitter`е. Однако методы генерации и стилизации текстов приносят и практическую пользу.
ВКонтакте фильтрует комментарии
ВКонтакте тестирует новые функции: сервис учится фильтровать оскорбительные комментарии в сообществах, а также предупреждать пользователей о неприемлемом тоне высказываний. Так как диаметральная смена окраски комментариев — это нарушение свободы слова, нашли полумеру: нецензурная лексика будет заменяться эвфемизмами, а остальные высказывания — «сглаживаться».
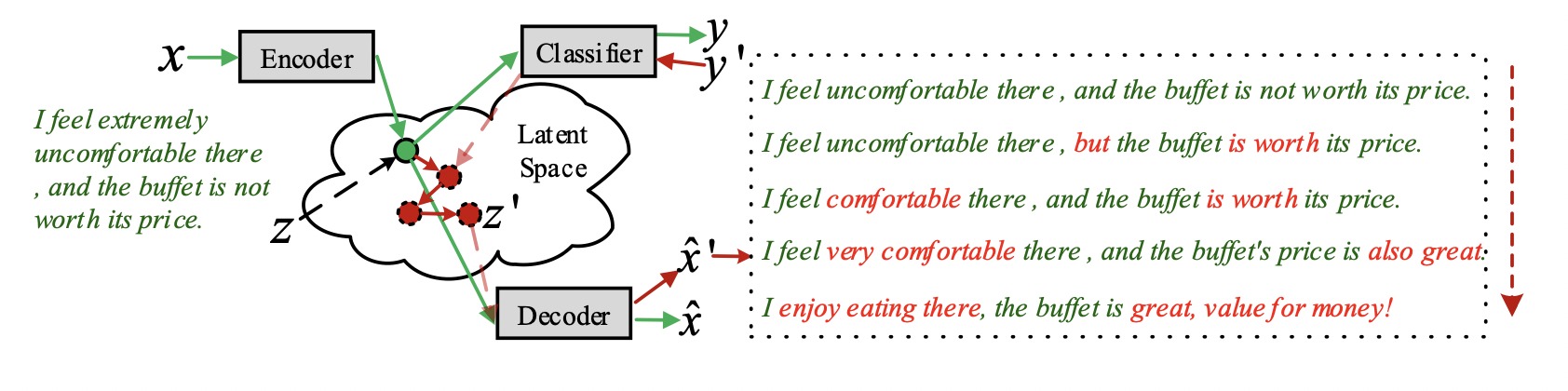
Перенос стиля: как это работает
Перенос стиля основан на изменении векторных представлений текстов. Мы уже рассказывали, как создаются такие вектора.
Чтобы научиться переносить стиль текста, потребуется:
1. два корпуса текстов с противоположными стилями: положительный и отрицательный, токсичный и обычный и т.д.
2. автокодировщик, который нужно обучить тому, как представлять тексты в виде векторов
Алгоритм следующий:
1. обучаем кодировщик на обоих корпусах
2. получаем векторные представления текстов стиля 1
3. изменяем полученные вектора в соответствии с векторами текста стиля 2
4. подаем измененные вектора на вход декодировщику
5. получаем тексты стиля 2
Основная задача — изменить векторы так, чтобы на выходе получился текст нужного стиля. Для этого берем векторные представления текстов для обоих корпусов и обучаем на них новую нейронную сеть определять стиль текста. После обучения пытаемся её обмануть: берём вектор текста стиля 1 и добавляем шум. Шум подбираем таким образом, чтобы нейросеть перепутала стиль и на выходе мы получили текст стиля 2.
Альтернативное решение
Есть более сложный и продвинутый метод, который позволяет менять стиль и содержание текста независимо друг от друга. В этом случае вся информация о стиле содержится в одной части вектора, а информация о содержании — в другой.
https://sysblok.ru/knowhow/v-prostranstve-tekstov-detoksikacija-kommentariev-poddelka-otzyvov-i-nejrocenzura/
Михаил Ким
#knowhow #nlp
Машинное обучение разрешает менять стилистику текста без изменения содержания. Например, нейросеть сгенерировала песни в стиле Егора Летова, а также ведет аккаунт Neural Meduza в Twitter`е. Однако методы генерации и стилизации текстов приносят и практическую пользу.
ВКонтакте фильтрует комментарии
ВКонтакте тестирует новые функции: сервис учится фильтровать оскорбительные комментарии в сообществах, а также предупреждать пользователей о неприемлемом тоне высказываний. Так как диаметральная смена окраски комментариев — это нарушение свободы слова, нашли полумеру: нецензурная лексика будет заменяться эвфемизмами, а остальные высказывания — «сглаживаться».
Перенос стиля: как это работает
Перенос стиля основан на изменении векторных представлений текстов. Мы уже рассказывали, как создаются такие вектора.
Чтобы научиться переносить стиль текста, потребуется:
1. два корпуса текстов с противоположными стилями: положительный и отрицательный, токсичный и обычный и т.д.
2. автокодировщик, который нужно обучить тому, как представлять тексты в виде векторов
Алгоритм следующий:
1. обучаем кодировщик на обоих корпусах
2. получаем векторные представления текстов стиля 1
3. изменяем полученные вектора в соответствии с векторами текста стиля 2
4. подаем измененные вектора на вход декодировщику
5. получаем тексты стиля 2
Основная задача — изменить векторы так, чтобы на выходе получился текст нужного стиля. Для этого берем векторные представления текстов для обоих корпусов и обучаем на них новую нейронную сеть определять стиль текста. После обучения пытаемся её обмануть: берём вектор текста стиля 1 и добавляем шум. Шум подбираем таким образом, чтобы нейросеть перепутала стиль и на выходе мы получили текст стиля 2.
Альтернативное решение
Есть более сложный и продвинутый метод, который позволяет менять стиль и содержание текста независимо друг от друга. В этом случае вся информация о стиле содержится в одной части вектора, а информация о содержании — в другой.
https://sysblok.ru/knowhow/v-prostranstve-tekstov-detoksikacija-kommentariev-poddelka-otzyvov-i-nejrocenzura/
Михаил Ким
{kind=link}
Как работает BERT
#knowhow #nlp
BERT или Bidirectional Encoder Representations from Transformers — это нейросетевая модель-трансформер от Google, на которой строится большинство инструментов автоматической обработки языка. Код модели выложен в открытый доступ. Саму нейросеть можно запустить как на локальном компьютере, так и на бесплатном серверном GPU на Google Colab.
Эмбеддинги и бенчмарки
Языковая модель работает с текстом, но для компьютера текст сам по себе ничего не значит. Чтобы закодировать текст в осмысленные числа, люди придумали векторные представления слов, которые основаны на контекстах употребления этих слов. Такие векторные представления называются эмбеддинги. Они кодируют семантические близости слов, причем с учетом контекста конкретного предложения.
Языковая модель принимает на вход эмбеддинги токенов и выдает результат в зависимости от задачи: стандартный набор задач, который выполняют на стандартном наборе данных, чтобы доказать, что нейросеть справляется с пониманием текста. Стандартные задачи называются в NLP бенчмарками («ориентир», «отметка» по-английски). BERT тестировали на наборах бенчмарков GLUE — «Оценка общего
понимания языка», SQuAD и SWAG.
Обучение нейросети
В зависимости от конечной цели используют либо машинное обучение с учителем (supervised learning), либо без него (unsupervised learning).
Для сложных нейросетей используют процессы «предобучения» и «дообучения». В первом методе нейросеть прогоняют на больших объемах текстов. Во втором – обнуляют финальный слой весов и тренируют модель на новом наборе данных.
Обучение BERT
Новшество BERTа — в способе предобучения. Ранние архитектуры, чтобы обучиться, предсказывали, какое слово вероятнее будет стоять следующим, учитывая слова до него. BERT же предобучается на «маскированной языковой модели»: нужно предсказать слово не в конце предложения, а посередине. Главная задача — угадать, какие слова пропущены (выдать числовой код) и сказать, подходит ли второе предложение к первому.
Для дообучения (файнтьюнинга) в BERT не нужно стирать «часть памяти» модели. Вместо этого «поверх» модели добавляют новый слой нейронов. Его матрицы весов заполнены случайными числами, которые настраивают так, чтобы на новой задаче ошибка была минимальной.
BERT используется в Google: поначалу эта модель работала только для английского языка, позже добавили в поиск и на других языках. Нейросеть можно использовать для модерации текстов, поиска ответов на юридические вопросы, оптимизации работы с SEO-сайтами. Кроме того, практически половина NLP использует BERT и BERT-подобные архитектуры.
https://sysblok.ru/knowhow/kak-ustroena-nejroset-bert-ot-google/
Камилла Кубелекова, Владимир Селеверстов
#knowhow #nlp
BERT или Bidirectional Encoder Representations from Transformers — это нейросетевая модель-трансформер от Google, на которой строится большинство инструментов автоматической обработки языка. Код модели выложен в открытый доступ. Саму нейросеть можно запустить как на локальном компьютере, так и на бесплатном серверном GPU на Google Colab.
Эмбеддинги и бенчмарки
Языковая модель работает с текстом, но для компьютера текст сам по себе ничего не значит. Чтобы закодировать текст в осмысленные числа, люди придумали векторные представления слов, которые основаны на контекстах употребления этих слов. Такие векторные представления называются эмбеддинги. Они кодируют семантические близости слов, причем с учетом контекста конкретного предложения.
Языковая модель принимает на вход эмбеддинги токенов и выдает результат в зависимости от задачи: стандартный набор задач, который выполняют на стандартном наборе данных, чтобы доказать, что нейросеть справляется с пониманием текста. Стандартные задачи называются в NLP бенчмарками («ориентир», «отметка» по-английски). BERT тестировали на наборах бенчмарков GLUE — «Оценка общего
понимания языка», SQuAD и SWAG.
Обучение нейросети
В зависимости от конечной цели используют либо машинное обучение с учителем (supervised learning), либо без него (unsupervised learning).
Для сложных нейросетей используют процессы «предобучения» и «дообучения». В первом методе нейросеть прогоняют на больших объемах текстов. Во втором – обнуляют финальный слой весов и тренируют модель на новом наборе данных.
Обучение BERT
Новшество BERTа — в способе предобучения. Ранние архитектуры, чтобы обучиться, предсказывали, какое слово вероятнее будет стоять следующим, учитывая слова до него. BERT же предобучается на «маскированной языковой модели»: нужно предсказать слово не в конце предложения, а посередине. Главная задача — угадать, какие слова пропущены (выдать числовой код) и сказать, подходит ли второе предложение к первому.
Для дообучения (файнтьюнинга) в BERT не нужно стирать «часть памяти» модели. Вместо этого «поверх» модели добавляют новый слой нейронов. Его матрицы весов заполнены случайными числами, которые настраивают так, чтобы на новой задаче ошибка была минимальной.
BERT используется в Google: поначалу эта модель работала только для английского языка, позже добавили в поиск и на других языках. Нейросеть можно использовать для модерации текстов, поиска ответов на юридические вопросы, оптимизации работы с SEO-сайтами. Кроме того, практически половина NLP использует BERT и BERT-подобные архитектуры.
https://sysblok.ru/knowhow/kak-ustroena-nejroset-bert-ot-google/
Камилла Кубелекова, Владимир Селеверстов
{kind=link}
UniLM — языковая модель для тех, кому мало BERT
#nlp
Мы уже рассказывали о языковых моделях BERT и GPT-2. Теперь разбираемся, как работает еще одна нейросетевая языковая модель.
UniLM расшифровывается как Unified pre-training Language Model. По архитектуре это многослойный трансформер, предварительно обученный на больших объемах текста. В отличие от BERT, UniLM используют как для задач понимания естественного языка (NLU), так и для генерации задач для NLU — NLG (Natural Language Generation).
Обучение нейросети
Обычно для обучения нейросетей используются три типа задач языкового моделирования (LM, Language Model): однонаправленная LM, двунаправленная LM, sequence-to-sequence LM. В случае с UniLM происходит единый процесс обучения и используется одна языковая модель Transformeк с общими параметрами и архитектурой для различных видов моделирования. Сеть не нужно отдельно обучать каждой задаче и отдельно хранить результаты.
Представление текста в UniLM такое же, как в BERT: сначала текст токенизируется, для этого используется алгоритм WordPiece: текст делится на ограниченный набор «подслов», частей слов. Из входной последовательности токенов случайным образом выбираются некоторые токены и заменяются на специальный токен MASK. Далее нейросеть обучается предсказывать замененные токены — стандартный на сегодня способ тренировки языковых моделей.
Для различных задач языкового моделирования используются различные матрицы масок.
• однонаправленная LM — использование left-to-right, right-to-left задач языкового моделирования.
• двунаправленная LM — кодировка контекстной информации и генерация контекстных представлений текста.
• sequence-to-sequence LM — при генерации токена участвуют токены из первой последовательности (источника), а из второй (целевой) последовательности берутся только токены слева от целевого токена и сам целевой токен. В итоге, для токенов в целевой последовательности блокируются токены, расположенные справа от них.
Архитектура UniLM соответствует архитектуре BERT LARGE. Размер словаря — 28 996 токенов, максимальная длина входной последовательности — 512. Вероятность маскирования токена составляет 15%. Процедура обучения состоит из 770 000 шагов.
Результаты работы UniLM
Нейросетевая языковая модель использовалась для задач автоматического реферирования — генерации краткого резюме входного текста. В качестве входных данных использовался датасет CNN / Daily Mail и корпус Gigaword для дообучения модели.
Так же модель тестировали на задаче ответов на вопросы — QA (Question Answering). Задача состоит в том, чтобы ответить на вопрос с учетом отрывка текста. Есть два варианта задачи: с извлечением ответа из текста и с порождением ответа на основе текста. Эксперименты показали, что при генерации ответов UniLM по качеству превосходит результаты лучших на момент проведения экспериментов моделей: Seq2Seq и PGNet.
Применение модели
Архитектура UniLM подходит для решения задач языкового моделирования, однако для конкретной задачи по-прежнему требуется дообучение на специфических данных для конкретной задачи. Это ограничивает применение языковой модели в практических целях: к примеру, для исправления грамматики или генерации рецензии к короткому рассказу трудно собрать набор дообучающих данных.
Нередко случается, что большие предобученные модели не обобщаются для узкоспециализированных задач. Поэтому появляются модели, для обучения которых используют метод контекстного обучения.
https://sysblok.ru/nlp/unilm-jazykovaja-model-dlja-teh-komu-malo-bert/
Светлана Бесаева
#nlp
Мы уже рассказывали о языковых моделях BERT и GPT-2. Теперь разбираемся, как работает еще одна нейросетевая языковая модель.
UniLM расшифровывается как Unified pre-training Language Model. По архитектуре это многослойный трансформер, предварительно обученный на больших объемах текста. В отличие от BERT, UniLM используют как для задач понимания естественного языка (NLU), так и для генерации задач для NLU — NLG (Natural Language Generation).
Обучение нейросети
Обычно для обучения нейросетей используются три типа задач языкового моделирования (LM, Language Model): однонаправленная LM, двунаправленная LM, sequence-to-sequence LM. В случае с UniLM происходит единый процесс обучения и используется одна языковая модель Transformeк с общими параметрами и архитектурой для различных видов моделирования. Сеть не нужно отдельно обучать каждой задаче и отдельно хранить результаты.
Представление текста в UniLM такое же, как в BERT: сначала текст токенизируется, для этого используется алгоритм WordPiece: текст делится на ограниченный набор «подслов», частей слов. Из входной последовательности токенов случайным образом выбираются некоторые токены и заменяются на специальный токен MASK. Далее нейросеть обучается предсказывать замененные токены — стандартный на сегодня способ тренировки языковых моделей.
Для различных задач языкового моделирования используются различные матрицы масок.
• однонаправленная LM — использование left-to-right, right-to-left задач языкового моделирования.
• двунаправленная LM — кодировка контекстной информации и генерация контекстных представлений текста.
• sequence-to-sequence LM — при генерации токена участвуют токены из первой последовательности (источника), а из второй (целевой) последовательности берутся только токены слева от целевого токена и сам целевой токен. В итоге, для токенов в целевой последовательности блокируются токены, расположенные справа от них.
Архитектура UniLM соответствует архитектуре BERT LARGE. Размер словаря — 28 996 токенов, максимальная длина входной последовательности — 512. Вероятность маскирования токена составляет 15%. Процедура обучения состоит из 770 000 шагов.
Результаты работы UniLM
Нейросетевая языковая модель использовалась для задач автоматического реферирования — генерации краткого резюме входного текста. В качестве входных данных использовался датасет CNN / Daily Mail и корпус Gigaword для дообучения модели.
Так же модель тестировали на задаче ответов на вопросы — QA (Question Answering). Задача состоит в том, чтобы ответить на вопрос с учетом отрывка текста. Есть два варианта задачи: с извлечением ответа из текста и с порождением ответа на основе текста. Эксперименты показали, что при генерации ответов UniLM по качеству превосходит результаты лучших на момент проведения экспериментов моделей: Seq2Seq и PGNet.
Применение модели
Архитектура UniLM подходит для решения задач языкового моделирования, однако для конкретной задачи по-прежнему требуется дообучение на специфических данных для конкретной задачи. Это ограничивает применение языковой модели в практических целях: к примеру, для исправления грамматики или генерации рецензии к короткому рассказу трудно собрать набор дообучающих данных.
Нередко случается, что большие предобученные модели не обобщаются для узкоспециализированных задач. Поэтому появляются модели, для обучения которых используют метод контекстного обучения.
https://sysblok.ru/nlp/unilm-jazykovaja-model-dlja-teh-komu-malo-bert/
Светлана Бесаева
{kind=link}
Анализ тональности отзывов о запрещенных веществах
#nlp
Язык интернета имеет свои особенности, и его активно исследуют лингвисты. Однако мало известно о характеристиках русского языка, используемого для нелегальной деятельности в DarkNet'е. DarkNet — это та часть интернета, которая не индексируется поисковыми системами и требует специального софта для входа. Именно там происходит большая часть нелегальной онлайн-активности
Сбор материала
Цель нашего мини-исследования: выявить и описать специфические лексические средства, используемые в отзывах о запрещенных веществах. Для этого мы провели анализ тональности — это автоматическое определение отрицательности или положительности отзыва. С помощью анализа можно выявить эмоционально окрашенную лексику.
Для этого с одной из крупнейших площадок для продажи наркотических веществ в DarkNet'е были собраны тренировочная и тестовая выборки. В тренировочную выборку входят 1000 отзывов о пяти разных наркотических веществах; в тестовую — 200 отзывов. Положительные отзывы были размечены как 1, а отрицательные как -1.
Обучение модели
• приведение всех слов в начальную форму, удаление стоп-слов. Длина всех положительных отзывов составила 10403 слова, а отрицательных — 10624.
• превращение текстов в цифровые вектора с помощью TF-IDF и Count Vectorizer'а.
• разделение отзывов по лексическому составу. Для этого воспользуемся decision_function: функция сообщает, где в пространстве значений, по мнению модели, лежит тот или иной отзыв. Итог: большая часть положительных отзывов имеют схожую лексику — как и большинство отрицательных.
• определение характерных слов для положительных и отрицательных отзывов. Для этого использовали модели логистической регрессии (Logistic Regression) и метода опорных векторов (Support Vector Machines).
Характеристика отзывов
Самым решающим словом для определения отрицательности отзыва является «ненаход», а для положительности — «касание». «Ненаход» обозначает ситуацию, когда покупатель не обнаружил на месте приобретенный товар. Слово «клад» фигурирует в жалобах на неудачные места для тайников. Кроме того, в пределах двух слов от «клада» 35 раз встречается слово «ненаход».
«Касание» наоборот значит, что тайник было легко забрать. «Касание» может употребляться как в качестве самостоятельного слова, так и с предлогом в, а также с глаголами забрать, снять и поднять.
Слово «квест» обозначает сам процесс получения товара. В положительных отзывах «квест» обычно употребляют в контексте того, как легко было найти и забрать товар. Вообще легкость получения «клада» — ключевой фактор для тональности всего отзыва.
https://sysblok.ru/nlp/kladmen-mudak-analiz-tonalnosti-otzyvov-o-zapreshhennyh-veshhestvah/
P.S. От редакции: употреблять наркотики смертельно опасно, а хранить их и тем более торговать ими — еще и уголовно наказуемо. Наш текст посвящен сугубо научному исследованию лингвистических аспектов этой противозаконной деятельности. Редакция против наркотиков, поэтому мы не раскрываем название площадки и способы попасть туда.
#nlp
Язык интернета имеет свои особенности, и его активно исследуют лингвисты. Однако мало известно о характеристиках русского языка, используемого для нелегальной деятельности в DarkNet'е. DarkNet — это та часть интернета, которая не индексируется поисковыми системами и требует специального софта для входа. Именно там происходит большая часть нелегальной онлайн-активности
Сбор материала
Цель нашего мини-исследования: выявить и описать специфические лексические средства, используемые в отзывах о запрещенных веществах. Для этого мы провели анализ тональности — это автоматическое определение отрицательности или положительности отзыва. С помощью анализа можно выявить эмоционально окрашенную лексику.
Для этого с одной из крупнейших площадок для продажи наркотических веществ в DarkNet'е были собраны тренировочная и тестовая выборки. В тренировочную выборку входят 1000 отзывов о пяти разных наркотических веществах; в тестовую — 200 отзывов. Положительные отзывы были размечены как 1, а отрицательные как -1.
Обучение модели
• приведение всех слов в начальную форму, удаление стоп-слов. Длина всех положительных отзывов составила 10403 слова, а отрицательных — 10624.
• превращение текстов в цифровые вектора с помощью TF-IDF и Count Vectorizer'а.
• разделение отзывов по лексическому составу. Для этого воспользуемся decision_function: функция сообщает, где в пространстве значений, по мнению модели, лежит тот или иной отзыв. Итог: большая часть положительных отзывов имеют схожую лексику — как и большинство отрицательных.
• определение характерных слов для положительных и отрицательных отзывов. Для этого использовали модели логистической регрессии (Logistic Regression) и метода опорных векторов (Support Vector Machines).
Характеристика отзывов
Самым решающим словом для определения отрицательности отзыва является «ненаход», а для положительности — «касание». «Ненаход» обозначает ситуацию, когда покупатель не обнаружил на месте приобретенный товар. Слово «клад» фигурирует в жалобах на неудачные места для тайников. Кроме того, в пределах двух слов от «клада» 35 раз встречается слово «ненаход».
«Касание» наоборот значит, что тайник было легко забрать. «Касание» может употребляться как в качестве самостоятельного слова, так и с предлогом в, а также с глаголами забрать, снять и поднять.
Слово «квест» обозначает сам процесс получения товара. В положительных отзывах «квест» обычно употребляют в контексте того, как легко было найти и забрать товар. Вообще легкость получения «клада» — ключевой фактор для тональности всего отзыва.
https://sysblok.ru/nlp/kladmen-mudak-analiz-tonalnosti-otzyvov-o-zapreshhennyh-veshhestvah/
P.S. От редакции: употреблять наркотики смертельно опасно, а хранить их и тем более торговать ими — еще и уголовно наказуемо. Наш текст посвящен сугубо научному исследованию лингвистических аспектов этой противозаконной деятельности. Редакция против наркотиков, поэтому мы не раскрываем название площадки и способы попасть туда.
Forwarded from Kali Novskaya
🌸Про ABBYY и будущее лингвистики🌸
#nlp #про_nlp
По тг разошёлся текст Системного Блока про ABBYY, да и правда, после истории массовых увольнений очень хотелось подвести какую-то черту. Напишу свои 5 копеек, потому что можно сказать, что вокруг ABBYY начиналась моя карьера.
ABBYY долгое время считалась самой лучшей компанией, куда мог бы устроиться лингвист.
Когда я только поступала на ОТиПЛ, туда шли работать лучшие выпускники. При этом ходило мнение, что вот, дескать, интеллектуальная эксплуатация — забирают лучших выпускников, которые могли бы быть успешными учёными, и фуллтайм заставляют писать правила на Compreno. (Ну и правда, в 2012 году там 40-60к платили, а в академии меньше.)
Помимо прочего, ABBYY оранизовывала самую большую NLP конференцию — Диалог, а также создала интернет-корпус русского языка, спонсировала кучу NLP-соревнований и shared tasks, которые распаляли многих проверить свои гипотезы на практике.
🟣 Что же теперь делать лингвистике?
Лингвистика разберётся!
Я думаю, текущий вызов даже не самый серьёзный за историю существования кафедры. Да, последние годы приходилось работать под давлением общественного мнения, хайпом LLM...ну так он пройдёт.
Аналитическая, теоретическая лингвистика нужна самой себе и другим наукам:
— как понять и описать происхождение языка,
— как определить биологические ограничения, повлиявшие на язык
— как язык влияет на мышление и обратно,
— как смоделировать максимально общую теоретическую модель языка, описывающую процессы в языках мира,
— как проверить и описать, что находится в корпусе.
Все эти вопросы остаются нужны, и остаются ключевыми вопросами лингвистики.
А языковые модели и NLP потихоньку поглощают уже другие науки:
— OpenAI нанимает филдсевских лауреатов в т ч для составления SFT датасета по математике
— они же нанимают PhD в разных дисциплинах для разметки и валидации данных.
Так что в жернова ИИ пойдут уже выпускники других специальностей. А лингвистика будет заниматься делом.
#nlp #про_nlp
По тг разошёлся текст Системного Блока про ABBYY, да и правда, после истории массовых увольнений очень хотелось подвести какую-то черту. Напишу свои 5 копеек, потому что можно сказать, что вокруг ABBYY начиналась моя карьера.
ABBYY долгое время считалась самой лучшей компанией, куда мог бы устроиться лингвист.
Когда я только поступала на ОТиПЛ, туда шли работать лучшие выпускники. При этом ходило мнение, что вот, дескать, интеллектуальная эксплуатация — забирают лучших выпускников, которые могли бы быть успешными учёными, и фуллтайм заставляют писать правила на Compreno. (Ну и правда, в 2012 году там 40-60к платили, а в академии меньше.)
Помимо прочего, ABBYY оранизовывала самую большую NLP конференцию — Диалог, а также создала интернет-корпус русского языка, спонсировала кучу NLP-соревнований и shared tasks, которые распаляли многих проверить свои гипотезы на практике.
Лингвистика разберётся!
Я думаю, текущий вызов даже не самый серьёзный за историю существования кафедры. Да, последние годы приходилось работать под давлением общественного мнения, хайпом LLM...ну так он пройдёт.
Аналитическая, теоретическая лингвистика нужна самой себе и другим наукам:
— как понять и описать происхождение языка,
— как определить биологические ограничения, повлиявшие на язык
— как язык влияет на мышление и обратно,
— как смоделировать максимально общую теоретическую модель языка, описывающую процессы в языках мира,
— как проверить и описать, что находится в корпусе.
Все эти вопросы остаются нужны, и остаются ключевыми вопросами лингвистики.
А языковые модели и NLP потихоньку поглощают уже другие науки:
— OpenAI нанимает филдсевских лауреатов в т ч для составления SFT датасета по математике
— они же нанимают PhD в разных дисциплинах для разметки и валидации данных.
Так что в жернова ИИ пойдут уже выпускники других специальностей. А лингвистика будет заниматься делом.
Please open Telegram to view this post
VIEW IN TELEGRAM
Системный Блокъ
Горький урок ABBYY: как лингвисты проиграли последнюю битву за NLP - Системный Блокъ
Недавно СМИ облетела новость об увольнении всех российских программистов из компании ABBYY (тоже в прошлом российской, а теперь уже совсем нет). Теперь, когда страсти вокруг обсуждения дискриминации сотрудников по паспорту улеглись, хочется поговорить о более…
❤🔥48👍25🔥16❤8🥴5💔5😁4😢2