
Определяем дату написания картины онлайн
#knowhow #research
Когда цифровизация стала глобальным трендом, в открытом доступе появились тематические датасеты, которые состоят из десятков тысяч картин различных авторов и эпох. Работая с такими датасетами, можно генерировать дополнительные метаданные — в нашем случаем это возраст изображений, тем самым автоматизируя работу искусствоведов.
Возможность определять возраст или стиль изображений полезна не только искусствоведам и коллекционерам. С помощью этого инструмента можно изучать тенденции современного искусства и выявлять закономерности, которые позволяют понять, к стилю какой из эпох более всего склонен автор.
Задача и стратегии ее решения
Ключевая фигура в решении задачи — сверточная нейронная сеть для выделения признаков на изображениях. Рассматривались архитектуры ResNet18 и VGG-19, однако последняя дала лучшие результаты.
Если не углубляться в теоретические основы глубокого обучения, то сверточные сети можно описать как алгоритм последовательного сжатия изображений, который способен выделять их ключевые особенности на разных уровнях абстракции (подробнее можно почитать на хабре).
Примененив сверточную сеть с обрезанными полносвязными слоями, мы вычисляем матрицу Грама, а также применяем классификацию или регрессию. В нашем случае в роли модели классификатора выступает SVM.
Матрица Грама является специальным представлением изображения — это матрица попарных скалярных произведения численного значения пикселей. Её использование позволяет конвертировать преобразованную сверточной сетью картину в формат, удобный для определения стиля. Матрица Грама сглаживает пространственную структуру, позволяя получить больше информации о текстуре изображения, чем о присутствующих на ней конкретных объектах.
В итоге оказалось, что наилучший MSE даёт VGG-19, а лучшее значение F1-меры достигается той же сетью с батч-нормализацией. Использование F1 в данной задаче обусловлено отсутствием в выбранном датасете баланса классов, каждый из которых представлял собой временной промежуток в 50 лет. Применение этой метрики позволяет более объективно оценить качество моделей.
Результаты и их интерпретация
Использование матрицы Грама позволило почти в два раза улучшить качество моделей на представленном датасете. Для многих классов ошибочных классификаций совсем немного.
Однако использование информации о стиле для определения временного отрезка гарантированно работает только для эпохи премодерна, которой характерно последовательное совершенствование техник изобразительного искусства.
Наш небольшой эксперимент показал, что задача определения возраста картины может быть решена посредством использования методов искусственного интеллекта. Следующий этап — увеличение количества данных, усложнение модели, масштабирование задачи на XX и XXI века, а также увеличение количества временных промежутков.
Код проекта можно найти на github.
Модель работает онлайн — протестировать можно здесь.
https://sysblok.ru/knowhow/opredeljaem-datu-napisanija-kartiny-onlajn-bez-registracii-i-sms/
Дарья Петрова, Вадим Порватов, Валерий Покровский
#knowhow #research
Когда цифровизация стала глобальным трендом, в открытом доступе появились тематические датасеты, которые состоят из десятков тысяч картин различных авторов и эпох. Работая с такими датасетами, можно генерировать дополнительные метаданные — в нашем случаем это возраст изображений, тем самым автоматизируя работу искусствоведов.
Возможность определять возраст или стиль изображений полезна не только искусствоведам и коллекционерам. С помощью этого инструмента можно изучать тенденции современного искусства и выявлять закономерности, которые позволяют понять, к стилю какой из эпох более всего склонен автор.
Задача и стратегии ее решения
Ключевая фигура в решении задачи — сверточная нейронная сеть для выделения признаков на изображениях. Рассматривались архитектуры ResNet18 и VGG-19, однако последняя дала лучшие результаты.
Если не углубляться в теоретические основы глубокого обучения, то сверточные сети можно описать как алгоритм последовательного сжатия изображений, который способен выделять их ключевые особенности на разных уровнях абстракции (подробнее можно почитать на хабре).
Примененив сверточную сеть с обрезанными полносвязными слоями, мы вычисляем матрицу Грама, а также применяем классификацию или регрессию. В нашем случае в роли модели классификатора выступает SVM.
Матрица Грама является специальным представлением изображения — это матрица попарных скалярных произведения численного значения пикселей. Её использование позволяет конвертировать преобразованную сверточной сетью картину в формат, удобный для определения стиля. Матрица Грама сглаживает пространственную структуру, позволяя получить больше информации о текстуре изображения, чем о присутствующих на ней конкретных объектах.
В итоге оказалось, что наилучший MSE даёт VGG-19, а лучшее значение F1-меры достигается той же сетью с батч-нормализацией. Использование F1 в данной задаче обусловлено отсутствием в выбранном датасете баланса классов, каждый из которых представлял собой временной промежуток в 50 лет. Применение этой метрики позволяет более объективно оценить качество моделей.
Результаты и их интерпретация
Использование матрицы Грама позволило почти в два раза улучшить качество моделей на представленном датасете. Для многих классов ошибочных классификаций совсем немного.
Однако использование информации о стиле для определения временного отрезка гарантированно работает только для эпохи премодерна, которой характерно последовательное совершенствование техник изобразительного искусства.
Наш небольшой эксперимент показал, что задача определения возраста картины может быть решена посредством использования методов искусственного интеллекта. Следующий этап — увеличение количества данных, усложнение модели, масштабирование задачи на XX и XXI века, а также увеличение количества временных промежутков.
Код проекта можно найти на github.
Модель работает онлайн — протестировать можно здесь.
https://sysblok.ru/knowhow/opredeljaem-datu-napisanija-kartiny-onlajn-bez-registracii-i-sms/
Дарья Петрова, Вадим Порватов, Валерий Покровский
{kind=link}
Как нейросеть реставрирует старые советские мультфильмы
#arts #knowhow
Главная проблема старых мультфильмов — низкое разрешение видеозаписи. Нейросеть DeepHD увеличивает изображение и делает его четким. Программа работает не только со старыми пленками, но и с прямыми трансляциями. Задача алгоритма — убрать шумы и искажения, которые возникают в процессе передачи или сжатия картинки.
Работа нейросети
Технология состоит из двух этапов:
• устранение помех — восстановление деталей.
• увеличение изображения — преобразование картинки в карты признаков и уменьшение расстояния между ними.
Программу обучали на картинках высокого качества, которые уменьшали для приближения к действительности. После обработки «дискриминатор» проверял достоверность исходного и улучшенного изображений. Если «подделку» было трудно отличить от «подлинника», результат работы нейросети считался положительным. С помощью новых датасетов, программа научилась различать объекты различных размеров и качеств.
DeepHD в кино
В мае 2018 года нейросеть испытали на нескольких советских фильмах: «Летят журавли», «Судьба человека», «Иваново детство» и др. У героев фильмов улучшились мимика и фактура одежды, исчезли пересветы.
С помощью технологии также улучшили 10 анимационных лент «Союзмультфильма»: «Котенок по имени Гав», «Дюймовочка», «Аленький цветочек» и др. Персонажи стали четче, повысилось качество фонов, вернулись детали, пропавшие при оцифровке. Все картины можно посмотреть на «КиноПоиске».
Альтернативные способы реставрации
Реставраторы-любители считают, что можно обойтись и без DeepHD. Вначале исходник, оцифрованный в Adobe Premier, разбивают на куски. После поправляют цвет, повышают резкость и убирают шумы. Это можно сделать с помощью программ Conbustion или VirtualDubMod. Восстановление займет много времени, но результат будет похож на DeepHD.
https://sysblok.ru/arts/vozvrashhenie-chetkogo-popugaja-kak-nejroset-restavriruet-starye-sovetskie-multfilmy/
Варвара Гузий
#arts #knowhow
Главная проблема старых мультфильмов — низкое разрешение видеозаписи. Нейросеть DeepHD увеличивает изображение и делает его четким. Программа работает не только со старыми пленками, но и с прямыми трансляциями. Задача алгоритма — убрать шумы и искажения, которые возникают в процессе передачи или сжатия картинки.
Работа нейросети
Технология состоит из двух этапов:
• устранение помех — восстановление деталей.
• увеличение изображения — преобразование картинки в карты признаков и уменьшение расстояния между ними.
Программу обучали на картинках высокого качества, которые уменьшали для приближения к действительности. После обработки «дискриминатор» проверял достоверность исходного и улучшенного изображений. Если «подделку» было трудно отличить от «подлинника», результат работы нейросети считался положительным. С помощью новых датасетов, программа научилась различать объекты различных размеров и качеств.
DeepHD в кино
В мае 2018 года нейросеть испытали на нескольких советских фильмах: «Летят журавли», «Судьба человека», «Иваново детство» и др. У героев фильмов улучшились мимика и фактура одежды, исчезли пересветы.
С помощью технологии также улучшили 10 анимационных лент «Союзмультфильма»: «Котенок по имени Гав», «Дюймовочка», «Аленький цветочек» и др. Персонажи стали четче, повысилось качество фонов, вернулись детали, пропавшие при оцифровке. Все картины можно посмотреть на «КиноПоиске».
Альтернативные способы реставрации
Реставраторы-любители считают, что можно обойтись и без DeepHD. Вначале исходник, оцифрованный в Adobe Premier, разбивают на куски. После поправляют цвет, повышают резкость и убирают шумы. Это можно сделать с помощью программ Conbustion или VirtualDubMod. Восстановление займет много времени, но результат будет похож на DeepHD.
https://sysblok.ru/arts/vozvrashhenie-chetkogo-popugaja-kak-nejroset-restavriruet-starye-sovetskie-multfilmy/
Варвара Гузий
YouTube
Хиты «Союзмультфильма» в DeepHD
Вам всегда хотелось рассмотреть наряд Снежной Королевы и живность в «Путешествии муравья» во всех подробностях? Теперь это возможно: в Яндексе появилась собственная технология DeepHD, улучшающая изображения и видео при помощи искусственного интеллекта.
Смотрите…
Смотрите…
Как нейросеть заменяет нецензурную лексику на эвфемизмы
#knowhow #nlp
Машинное обучение разрешает менять стилистику текста без изменения содержания. Например, нейросеть сгенерировала песни в стиле Егора Летова, а также ведет аккаунт Neural Meduza в Twitter`е. Однако методы генерации и стилизации текстов приносят и практическую пользу.
ВКонтакте фильтрует комментарии
ВКонтакте тестирует новые функции: сервис учится фильтровать оскорбительные комментарии в сообществах, а также предупреждать пользователей о неприемлемом тоне высказываний. Так как диаметральная смена окраски комментариев — это нарушение свободы слова, нашли полумеру: нецензурная лексика будет заменяться эвфемизмами, а остальные высказывания — «сглаживаться».
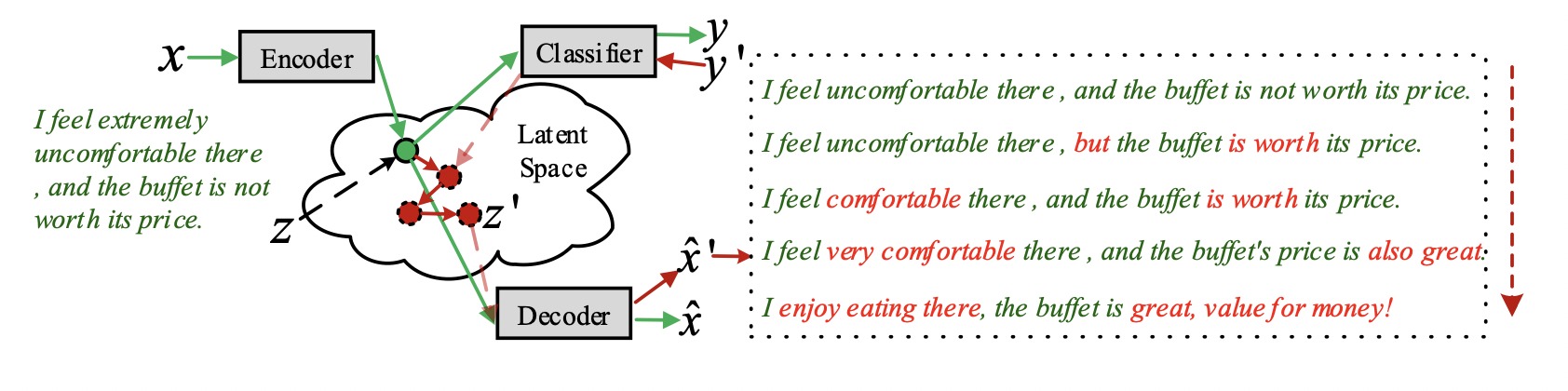
Перенос стиля: как это работает
Перенос стиля основан на изменении векторных представлений текстов. Мы уже рассказывали, как создаются такие вектора.
Чтобы научиться переносить стиль текста, потребуется:
1. два корпуса текстов с противоположными стилями: положительный и отрицательный, токсичный и обычный и т.д.
2. автокодировщик, который нужно обучить тому, как представлять тексты в виде векторов
Алгоритм следующий:
1. обучаем кодировщик на обоих корпусах
2. получаем векторные представления текстов стиля 1
3. изменяем полученные вектора в соответствии с векторами текста стиля 2
4. подаем измененные вектора на вход декодировщику
5. получаем тексты стиля 2
Основная задача — изменить векторы так, чтобы на выходе получился текст нужного стиля. Для этого берем векторные представления текстов для обоих корпусов и обучаем на них новую нейронную сеть определять стиль текста. После обучения пытаемся её обмануть: берём вектор текста стиля 1 и добавляем шум. Шум подбираем таким образом, чтобы нейросеть перепутала стиль и на выходе мы получили текст стиля 2.
Альтернативное решение
Есть более сложный и продвинутый метод, который позволяет менять стиль и содержание текста независимо друг от друга. В этом случае вся информация о стиле содержится в одной части вектора, а информация о содержании — в другой.
https://sysblok.ru/knowhow/v-prostranstve-tekstov-detoksikacija-kommentariev-poddelka-otzyvov-i-nejrocenzura/
Михаил Ким
#knowhow #nlp
Машинное обучение разрешает менять стилистику текста без изменения содержания. Например, нейросеть сгенерировала песни в стиле Егора Летова, а также ведет аккаунт Neural Meduza в Twitter`е. Однако методы генерации и стилизации текстов приносят и практическую пользу.
ВКонтакте фильтрует комментарии
ВКонтакте тестирует новые функции: сервис учится фильтровать оскорбительные комментарии в сообществах, а также предупреждать пользователей о неприемлемом тоне высказываний. Так как диаметральная смена окраски комментариев — это нарушение свободы слова, нашли полумеру: нецензурная лексика будет заменяться эвфемизмами, а остальные высказывания — «сглаживаться».
Перенос стиля: как это работает
Перенос стиля основан на изменении векторных представлений текстов. Мы уже рассказывали, как создаются такие вектора.
Чтобы научиться переносить стиль текста, потребуется:
1. два корпуса текстов с противоположными стилями: положительный и отрицательный, токсичный и обычный и т.д.
2. автокодировщик, который нужно обучить тому, как представлять тексты в виде векторов
Алгоритм следующий:
1. обучаем кодировщик на обоих корпусах
2. получаем векторные представления текстов стиля 1
3. изменяем полученные вектора в соответствии с векторами текста стиля 2
4. подаем измененные вектора на вход декодировщику
5. получаем тексты стиля 2
Основная задача — изменить векторы так, чтобы на выходе получился текст нужного стиля. Для этого берем векторные представления текстов для обоих корпусов и обучаем на них новую нейронную сеть определять стиль текста. После обучения пытаемся её обмануть: берём вектор текста стиля 1 и добавляем шум. Шум подбираем таким образом, чтобы нейросеть перепутала стиль и на выходе мы получили текст стиля 2.
Альтернативное решение
Есть более сложный и продвинутый метод, который позволяет менять стиль и содержание текста независимо друг от друга. В этом случае вся информация о стиле содержится в одной части вектора, а информация о содержании — в другой.
https://sysblok.ru/knowhow/v-prostranstve-tekstov-detoksikacija-kommentariev-poddelka-otzyvov-i-nejrocenzura/
Михаил Ким
{kind=link}
Transkribus: как компьютерное зрение помогает переводить тексты сирийских мистиков
#digitalheritage #knowhow
Transkribus — платформа для оцифровки и распознавания текста на основе технологии HTR (Handwritten Text Recognition), которая позволяет обучать специальные модули распознавания текста. Обученные модули способны распознавать рукописные, машинописные и печатные документы на самых разных языках.
Например, на классическом сирийском — главном языке восточного христианства. К сожалению, пласт текстов так и остался неизученным: сюда относится всемирная хроника Йоханнана бар Пенкайе. В издании 300 рукописных страниц — все нужно набрать вручную, а это долго и требует постоянной высокой концентрации внимания. Transkribus ускорил процесс.
Обучение нейросети
• сбор необходимого количества данных для модуля — для Transkribus это 80 страниц. Язык или тип письменности не важны.
• распознавание почерка — программу тренируют на собранных данных. Чем их больше, тем точнее будет работать модуль.
• сравнение транскрипций — программа сравнивает первоначально распозанный текст с правильной отредактированной версией.
Ошибки Transkribus
После тренировки модуля эффективность оценивается на тестовом образце. Она оценивается по проценту ошибочных символов. Модули, которые распознают тексты с ошибочностью менее 10%, считаются эффективными.
Три условия для хорошей работы модуля:
• хорошее качество транскрипции, которую вы производили, когда обучали модуль;
• аккуратность/неаккуратность почерка;
• хорошая сохранность рукописи (высокое разрешение и контрастность отсканированного изображения).
Сирийские средневековые рукописи писались профессиональными писцами, в них мало индивидуальных особенностей и не отличаются почерки. С таким материалом Transkribus справляется точнее и лучше.
Функции платформы
Разработчики платформы говорят, что существует 70 публичных модулей и 8 400 частных. Среди них есть и сирийские модули , разработанные Beth Mardutho — организацией, занимающейся изучением сирийского наследия. Для разных видов сирийского письма — серто, эстрангело, восточносирийское — сделаны отдельные модули.
С помощью платформы можно массово детализировать рукописи и создавать корпуса: функционирует поиск по ключевым словам или по регулярным фрагментам в уже распознанном тексте. Transkribus способен распознавать и оцифровывать тексты на языках, относящимся к историческим периодам, что делает нейросеть полезной для пользователей.
https://sysblok.ru/digital-heritage/transkribus-kak-kompjuternoe-zrenie-pomogaet-perevodit-teksty-sirijskih-mistikov/
Ксения Костомарова
#digitalheritage #knowhow
Transkribus — платформа для оцифровки и распознавания текста на основе технологии HTR (Handwritten Text Recognition), которая позволяет обучать специальные модули распознавания текста. Обученные модули способны распознавать рукописные, машинописные и печатные документы на самых разных языках.
Например, на классическом сирийском — главном языке восточного христианства. К сожалению, пласт текстов так и остался неизученным: сюда относится всемирная хроника Йоханнана бар Пенкайе. В издании 300 рукописных страниц — все нужно набрать вручную, а это долго и требует постоянной высокой концентрации внимания. Transkribus ускорил процесс.
Обучение нейросети
• сбор необходимого количества данных для модуля — для Transkribus это 80 страниц. Язык или тип письменности не важны.
• распознавание почерка — программу тренируют на собранных данных. Чем их больше, тем точнее будет работать модуль.
• сравнение транскрипций — программа сравнивает первоначально распозанный текст с правильной отредактированной версией.
Ошибки Transkribus
После тренировки модуля эффективность оценивается на тестовом образце. Она оценивается по проценту ошибочных символов. Модули, которые распознают тексты с ошибочностью менее 10%, считаются эффективными.
Три условия для хорошей работы модуля:
• хорошее качество транскрипции, которую вы производили, когда обучали модуль;
• аккуратность/неаккуратность почерка;
• хорошая сохранность рукописи (высокое разрешение и контрастность отсканированного изображения).
Сирийские средневековые рукописи писались профессиональными писцами, в них мало индивидуальных особенностей и не отличаются почерки. С таким материалом Transkribus справляется точнее и лучше.
Функции платформы
Разработчики платформы говорят, что существует 70 публичных модулей и 8 400 частных. Среди них есть и сирийские модули , разработанные Beth Mardutho — организацией, занимающейся изучением сирийского наследия. Для разных видов сирийского письма — серто, эстрангело, восточносирийское — сделаны отдельные модули.
С помощью платформы можно массово детализировать рукописи и создавать корпуса: функционирует поиск по ключевым словам или по регулярным фрагментам в уже распознанном тексте. Transkribus способен распознавать и оцифровывать тексты на языках, относящимся к историческим периодам, что делает нейросеть полезной для пользователей.
https://sysblok.ru/digital-heritage/transkribus-kak-kompjuternoe-zrenie-pomogaet-perevodit-teksty-sirijskih-mistikov/
Ксения Костомарова
Системный Блокъ
Transkribus: как компьютерное зрение помогает переводить тексты сирийских мистиков
Чтобы разобрать написанное, часто нужен натренированный глаз. Добиться этого можно двумя способами: тренировать собственное зрение или компьютерное. Как и зачем тренируют модели распознавания рукописного текста — рассказываем в нашем материале
Как работает BERT
#knowhow #nlp
BERT или Bidirectional Encoder Representations from Transformers — это нейросетевая модель-трансформер от Google, на которой строится большинство инструментов автоматической обработки языка. Код модели выложен в открытый доступ. Саму нейросеть можно запустить как на локальном компьютере, так и на бесплатном серверном GPU на Google Colab.
Эмбеддинги и бенчмарки
Языковая модель работает с текстом, но для компьютера текст сам по себе ничего не значит. Чтобы закодировать текст в осмысленные числа, люди придумали векторные представления слов, которые основаны на контекстах употребления этих слов. Такие векторные представления называются эмбеддинги. Они кодируют семантические близости слов, причем с учетом контекста конкретного предложения.
Языковая модель принимает на вход эмбеддинги токенов и выдает результат в зависимости от задачи: стандартный набор задач, который выполняют на стандартном наборе данных, чтобы доказать, что нейросеть справляется с пониманием текста. Стандартные задачи называются в NLP бенчмарками («ориентир», «отметка» по-английски). BERT тестировали на наборах бенчмарков GLUE — «Оценка общего
понимания языка», SQuAD и SWAG.
Обучение нейросети
В зависимости от конечной цели используют либо машинное обучение с учителем (supervised learning), либо без него (unsupervised learning).
Для сложных нейросетей используют процессы «предобучения» и «дообучения». В первом методе нейросеть прогоняют на больших объемах текстов. Во втором – обнуляют финальный слой весов и тренируют модель на новом наборе данных.
Обучение BERT
Новшество BERTа — в способе предобучения. Ранние архитектуры, чтобы обучиться, предсказывали, какое слово вероятнее будет стоять следующим, учитывая слова до него. BERT же предобучается на «маскированной языковой модели»: нужно предсказать слово не в конце предложения, а посередине. Главная задача — угадать, какие слова пропущены (выдать числовой код) и сказать, подходит ли второе предложение к первому.
Для дообучения (файнтьюнинга) в BERT не нужно стирать «часть памяти» модели. Вместо этого «поверх» модели добавляют новый слой нейронов. Его матрицы весов заполнены случайными числами, которые настраивают так, чтобы на новой задаче ошибка была минимальной.
BERT используется в Google: поначалу эта модель работала только для английского языка, позже добавили в поиск и на других языках. Нейросеть можно использовать для модерации текстов, поиска ответов на юридические вопросы, оптимизации работы с SEO-сайтами. Кроме того, практически половина NLP использует BERT и BERT-подобные архитектуры.
https://sysblok.ru/knowhow/kak-ustroena-nejroset-bert-ot-google/
Камилла Кубелекова, Владимир Селеверстов
#knowhow #nlp
BERT или Bidirectional Encoder Representations from Transformers — это нейросетевая модель-трансформер от Google, на которой строится большинство инструментов автоматической обработки языка. Код модели выложен в открытый доступ. Саму нейросеть можно запустить как на локальном компьютере, так и на бесплатном серверном GPU на Google Colab.
Эмбеддинги и бенчмарки
Языковая модель работает с текстом, но для компьютера текст сам по себе ничего не значит. Чтобы закодировать текст в осмысленные числа, люди придумали векторные представления слов, которые основаны на контекстах употребления этих слов. Такие векторные представления называются эмбеддинги. Они кодируют семантические близости слов, причем с учетом контекста конкретного предложения.
Языковая модель принимает на вход эмбеддинги токенов и выдает результат в зависимости от задачи: стандартный набор задач, который выполняют на стандартном наборе данных, чтобы доказать, что нейросеть справляется с пониманием текста. Стандартные задачи называются в NLP бенчмарками («ориентир», «отметка» по-английски). BERT тестировали на наборах бенчмарков GLUE — «Оценка общего
понимания языка», SQuAD и SWAG.
Обучение нейросети
В зависимости от конечной цели используют либо машинное обучение с учителем (supervised learning), либо без него (unsupervised learning).
Для сложных нейросетей используют процессы «предобучения» и «дообучения». В первом методе нейросеть прогоняют на больших объемах текстов. Во втором – обнуляют финальный слой весов и тренируют модель на новом наборе данных.
Обучение BERT
Новшество BERTа — в способе предобучения. Ранние архитектуры, чтобы обучиться, предсказывали, какое слово вероятнее будет стоять следующим, учитывая слова до него. BERT же предобучается на «маскированной языковой модели»: нужно предсказать слово не в конце предложения, а посередине. Главная задача — угадать, какие слова пропущены (выдать числовой код) и сказать, подходит ли второе предложение к первому.
Для дообучения (файнтьюнинга) в BERT не нужно стирать «часть памяти» модели. Вместо этого «поверх» модели добавляют новый слой нейронов. Его матрицы весов заполнены случайными числами, которые настраивают так, чтобы на новой задаче ошибка была минимальной.
BERT используется в Google: поначалу эта модель работала только для английского языка, позже добавили в поиск и на других языках. Нейросеть можно использовать для модерации текстов, поиска ответов на юридические вопросы, оптимизации работы с SEO-сайтами. Кроме того, практически половина NLP использует BERT и BERT-подобные архитектуры.
https://sysblok.ru/knowhow/kak-ustroena-nejroset-bert-ot-google/
Камилла Кубелекова, Владимир Селеверстов
{kind=link}