
Памяти А. А. Зализняка
#nlp #linguistics
Андрей Анатольевич Зализняк (1935–2017) был выдающимся советским и российским лингвистом и академиком РАН. Он занимался широким кругом проблем, начиная от словоизменения в русском языке и заканчивая древненовгородским диалектом.
И хотя А. А. Зализняк никогда не был и не считался «компьютерным лингвистом», его работы по русскому словоизменению легли в основу всех морфологических анализаторов для русского языка. А от морфологического анализа зависит работа поисковиков, машинных переводчиков и даже чатботов вроде «Алисы».
«Системный Блокъ» создал цикл из четырех статей, посвященных трудам и открытиям А. А. Зализняка.
Берестяные грамоты от раскопа до компьютера
А. А. Зализняк нашел существенное отличие северо-западных говоров от остальных, что привело к пересмотру уже сложившейся схемы диалектов Древней Руси. Источником сведений об этих говорах стали берестяные грамоты, первую из которых нашли в 1951 г.
Оказалось, что в X—XI вв. на территории восточного славянства членение было не таким, как можно представить на основании сегодняшнего разделения языков (великорусский, украинский, белорусский), а иным: северо-запад отличался от всех остальных говоров. Иными словами, существовала группа древненовгородских и древнепсковских диалектов и классическая форма древнерусского языка, объединявшая Киев, Суздаль, Ростов, будущую Москву и территорию Белоруссии. Это и были две главные составные части будущего русского языка.
https://sysblok.ru/nlp/berestjanye-gramoty-ot-raskopa-do-kompjutera-pamjati-a-a-zaliznjaka-chast-i/
«Слово о полку Игореве» как улика
Существует мнение, что «Слово о полку Игореве» написано не в XII веке, а несколькими веками позднее, то есть является стилизацией под древность, а не истинным памятником древнерусской словесности. А. А. Зализняк рассматривает проблему подлинности «Слова» с лингвистической точки зрения и последовательно доказывает невозможность никакой другой датировки, кроме XII века.
https://sysblok.ru/nlp/slovo-o-polku-igoreve-kak-ulika-pamjati-a-a-zaliznjaka-chast-ii/
Акцентуаторы
Русское ударение свободно и подвижно. А. А. Зализняк мечтал о программе, которая сможет расставлять ударения в тексте автоматически.
Магистры из НИУ ВШЭ воплотили его идею в жизнь и создали акцентуатор для русского языка sStress. Это автоматическая система, принимающая на вход текст на русском языке и расставляющая в нем ударения. В основе этого акцентуатора лежит рекуррентная нейронная сеть LSTM, обученная на акцентологическом подкорпусе Национального корпуса русского языка.
В качестве базы данных молодые ученые используют «Грамматический словарь русского языка» (1985) А. А. Зализняка, который насчитывает более 100 000 слов с указанным ударением (и ударной парадигмой). Второй источник — Транскрипции Русского национального корпуса (РНЦ) (Гришина, 2003). Разговорный корпус был собран из записей речи люди и стенограмм русских фильмов с расставленными ударениями.
https://sysblok.ru/nlp/akcentuatory-pamjati-a-a-zaliznjaka-chast-iii/
Морфология
Поисковики, умеющие обрабатывать русскоязычные запросы, а также навигаторы, голосовые команды и онлайн-переводчики, работающие с русским языком, появились бы на несколько лет позже, если бы не «Грамматический словарь русского языка» А. А. Зализняка — первое полное описание грамматических форм русского языка, по которому для каждого слова можно построить все его словоформы.
Словарь Зализняка лег в основу автоматического порождения всех словоизменительных форм в русском интернете. Его концепция используется для описания большинства русских слов в Викисловаре. Яндекс может не только корректно склонять и спрягать русские слова, но и строить гипотезы о том, как будет изменяться любое незнакомое системе слово.
https://sysblok.ru/nlp/morfologija-pamjati-a-a-zaliznjaka-chast-iv/
#nlp #linguistics
Андрей Анатольевич Зализняк (1935–2017) был выдающимся советским и российским лингвистом и академиком РАН. Он занимался широким кругом проблем, начиная от словоизменения в русском языке и заканчивая древненовгородским диалектом.
И хотя А. А. Зализняк никогда не был и не считался «компьютерным лингвистом», его работы по русскому словоизменению легли в основу всех морфологических анализаторов для русского языка. А от морфологического анализа зависит работа поисковиков, машинных переводчиков и даже чатботов вроде «Алисы».
«Системный Блокъ» создал цикл из четырех статей, посвященных трудам и открытиям А. А. Зализняка.
Берестяные грамоты от раскопа до компьютера
А. А. Зализняк нашел существенное отличие северо-западных говоров от остальных, что привело к пересмотру уже сложившейся схемы диалектов Древней Руси. Источником сведений об этих говорах стали берестяные грамоты, первую из которых нашли в 1951 г.
Оказалось, что в X—XI вв. на территории восточного славянства членение было не таким, как можно представить на основании сегодняшнего разделения языков (великорусский, украинский, белорусский), а иным: северо-запад отличался от всех остальных говоров. Иными словами, существовала группа древненовгородских и древнепсковских диалектов и классическая форма древнерусского языка, объединявшая Киев, Суздаль, Ростов, будущую Москву и территорию Белоруссии. Это и были две главные составные части будущего русского языка.
https://sysblok.ru/nlp/berestjanye-gramoty-ot-raskopa-do-kompjutera-pamjati-a-a-zaliznjaka-chast-i/
«Слово о полку Игореве» как улика
Существует мнение, что «Слово о полку Игореве» написано не в XII веке, а несколькими веками позднее, то есть является стилизацией под древность, а не истинным памятником древнерусской словесности. А. А. Зализняк рассматривает проблему подлинности «Слова» с лингвистической точки зрения и последовательно доказывает невозможность никакой другой датировки, кроме XII века.
https://sysblok.ru/nlp/slovo-o-polku-igoreve-kak-ulika-pamjati-a-a-zaliznjaka-chast-ii/
Акцентуаторы
Русское ударение свободно и подвижно. А. А. Зализняк мечтал о программе, которая сможет расставлять ударения в тексте автоматически.
Магистры из НИУ ВШЭ воплотили его идею в жизнь и создали акцентуатор для русского языка sStress. Это автоматическая система, принимающая на вход текст на русском языке и расставляющая в нем ударения. В основе этого акцентуатора лежит рекуррентная нейронная сеть LSTM, обученная на акцентологическом подкорпусе Национального корпуса русского языка.
В качестве базы данных молодые ученые используют «Грамматический словарь русского языка» (1985) А. А. Зализняка, который насчитывает более 100 000 слов с указанным ударением (и ударной парадигмой). Второй источник — Транскрипции Русского национального корпуса (РНЦ) (Гришина, 2003). Разговорный корпус был собран из записей речи люди и стенограмм русских фильмов с расставленными ударениями.
https://sysblok.ru/nlp/akcentuatory-pamjati-a-a-zaliznjaka-chast-iii/
Морфология
Поисковики, умеющие обрабатывать русскоязычные запросы, а также навигаторы, голосовые команды и онлайн-переводчики, работающие с русским языком, появились бы на несколько лет позже, если бы не «Грамматический словарь русского языка» А. А. Зализняка — первое полное описание грамматических форм русского языка, по которому для каждого слова можно построить все его словоформы.
Словарь Зализняка лег в основу автоматического порождения всех словоизменительных форм в русском интернете. Его концепция используется для описания большинства русских слов в Викисловаре. Яндекс может не только корректно склонять и спрягать русские слова, но и строить гипотезы о том, как будет изменяться любое незнакомое системе слово.
https://sysblok.ru/nlp/morfologija-pamjati-a-a-zaliznjaka-chast-iv/
{kind=link}
Цифровая филология 1910: как Андрей Белый вычислял отклонения ямба
#philology
Попытки применять точные методы в исследованиях стихотворений делались литературоведами задолго до возникновения компьютерных технологий и digital humanities. В начале XX века к точности в анализе поэтических текстов стремился русский поэт-символист Андрей Белый. Он одним из первых ввел в исследование стиха количественные методы.
Белый был не чужд математики. Он родился в семье декана физико-математического факультета Московского университета, и окончив гимназию, сам поступил на этот же факультет. Позднее, работая над теорией стиха, Андрей Белый решил охарактеризовать русский четырехстопный ямб методом, который сегодня назвали бы анализом данных. Он вручную проанализировал расстановку ударения в 16092 строках 27 отечественных поэтов.
Эволюция ямба
Для своего исследования Белый обратился к стихотворениям 27 отечественных поэтов, в которых доминирующим размером был четырехстопный ямб, и исследовал частотность и характеристику ускорений ямба в русской поэзии. Под ускорением Белый подразумевает наличие в стихотворении стопы, в которой есть лишний безударный слог — именно она и дает эффект ускорения, которое «слышит ухо». Пример ускорения на третьей стопе: «Чего-то ищет в небесах» (Тютчев).
Белый предлагает нам статистику по ускорениям на 596 строк у каждого поэта, отмечая частотность отклонений на той или иной стопе. Интересно, что правильный ямб составляет всего лишь 25% от всей выборки, а 75% приходится на ускорения от ямба. Как замечает Белый, именно через увеличение или уменьшение количества ускорений на той или иной стопе четырехстопный ямб и эволюционировал.
Всего Белый выделяет пять темпов, возможных при отклонении от ямба:
1. Наименьшее количество ускорений на первой стопе (13), максимальное на второй (139) и наименьшее количество ускорений на первой и третьей стопе одновременно (5) с максимальным на второй и третьей одновременно (11) было у Ломоносова;
2. К наибольшему количеству ускорений на первой стопе (46), максимальному на второй (139), наибольшему на первой и третьей одновременно (26) и наименьшему на второй и третьей стопе (1) пришел Державин;
3. Наименьшее количество отклонений на третьей стопе (230) демонстрирует Капнист;
4. Падение отклонений на второй стопе (33) и увеличение отклонений на третьей (313) показывает Батюшков;
5. Увеличение количества отклонений на второй и третьей стопах одновременно (44), много ускорений на второй стопе (52), и увеличение суммы ускорений первой стопы (99) замечаются у Жуковского.
Белый делает следующий вывод: беднота или, наоборот, обилие ускорений, во-первых, индивидуализирует стиль поэта и, во-вторых, реформирует четырехстопный ямб вообще, то есть задает те или иные «тренды» в написании стихотворений этим размером. Так главными его реформаторами оказываются Жуковский и Батюшков, но совсем не Пушкин. Пушкин только доводит начатую ими работу до конца: он повторяет сумму ускорений Батюшкова (33) и немного увеличивает ускорения третьей стопы (341) — так реформа завершается.
В русской поэзии первой половины XIX в., как замечает Белый, было стремление «увеличить до крайности ускорение первой стопы и уменьшить до крайности ускорение второй», которое проявилось в большей степени у Баратынского.
Белый также обнаружил, что отклонения от ямба образуют в стихотворениях различные геометрические фигуры, которые, вполне вероятно, могут сказать нам о содержании того или иного поэтического текста много нового. Об этом — в нашей статье: https://sysblok.ru/philology/cifrovaja-filologija-1910-kak-andrej-belyj-vychisljal-otklonenija-jamba/
Вячеслав Кутепов
#philology
Попытки применять точные методы в исследованиях стихотворений делались литературоведами задолго до возникновения компьютерных технологий и digital humanities. В начале XX века к точности в анализе поэтических текстов стремился русский поэт-символист Андрей Белый. Он одним из первых ввел в исследование стиха количественные методы.
Белый был не чужд математики. Он родился в семье декана физико-математического факультета Московского университета, и окончив гимназию, сам поступил на этот же факультет. Позднее, работая над теорией стиха, Андрей Белый решил охарактеризовать русский четырехстопный ямб методом, который сегодня назвали бы анализом данных. Он вручную проанализировал расстановку ударения в 16092 строках 27 отечественных поэтов.
Эволюция ямба
Для своего исследования Белый обратился к стихотворениям 27 отечественных поэтов, в которых доминирующим размером был четырехстопный ямб, и исследовал частотность и характеристику ускорений ямба в русской поэзии. Под ускорением Белый подразумевает наличие в стихотворении стопы, в которой есть лишний безударный слог — именно она и дает эффект ускорения, которое «слышит ухо». Пример ускорения на третьей стопе: «Чего-то ищет в небесах» (Тютчев).
Белый предлагает нам статистику по ускорениям на 596 строк у каждого поэта, отмечая частотность отклонений на той или иной стопе. Интересно, что правильный ямб составляет всего лишь 25% от всей выборки, а 75% приходится на ускорения от ямба. Как замечает Белый, именно через увеличение или уменьшение количества ускорений на той или иной стопе четырехстопный ямб и эволюционировал.
Всего Белый выделяет пять темпов, возможных при отклонении от ямба:
1. Наименьшее количество ускорений на первой стопе (13), максимальное на второй (139) и наименьшее количество ускорений на первой и третьей стопе одновременно (5) с максимальным на второй и третьей одновременно (11) было у Ломоносова;
2. К наибольшему количеству ускорений на первой стопе (46), максимальному на второй (139), наибольшему на первой и третьей одновременно (26) и наименьшему на второй и третьей стопе (1) пришел Державин;
3. Наименьшее количество отклонений на третьей стопе (230) демонстрирует Капнист;
4. Падение отклонений на второй стопе (33) и увеличение отклонений на третьей (313) показывает Батюшков;
5. Увеличение количества отклонений на второй и третьей стопах одновременно (44), много ускорений на второй стопе (52), и увеличение суммы ускорений первой стопы (99) замечаются у Жуковского.
Белый делает следующий вывод: беднота или, наоборот, обилие ускорений, во-первых, индивидуализирует стиль поэта и, во-вторых, реформирует четырехстопный ямб вообще, то есть задает те или иные «тренды» в написании стихотворений этим размером. Так главными его реформаторами оказываются Жуковский и Батюшков, но совсем не Пушкин. Пушкин только доводит начатую ими работу до конца: он повторяет сумму ускорений Батюшкова (33) и немного увеличивает ускорения третьей стопы (341) — так реформа завершается.
В русской поэзии первой половины XIX в., как замечает Белый, было стремление «увеличить до крайности ускорение первой стопы и уменьшить до крайности ускорение второй», которое проявилось в большей степени у Баратынского.
Белый также обнаружил, что отклонения от ямба образуют в стихотворениях различные геометрические фигуры, которые, вполне вероятно, могут сказать нам о содержании того или иного поэтического текста много нового. Об этом — в нашей статье: https://sysblok.ru/philology/cifrovaja-filologija-1910-kak-andrej-belyj-vychisljal-otklonenija-jamba/
Вячеслав Кутепов
{kind=link}
Поделись наушником своим: как устроены рекомендации Spotify
#musicology #knowhow
Стриминг имеет две принципиально важные черты потребления: массовизация легальной покупки музыки и культура рекомендации. Нельзя сказать, что рекомендации — это идея исключительно стримингового сервиса Spotify. До этого идею рекомендации развивали и другие компании — Spotify просто удачно скомпилировала известные инструменты в систему и постоянно ее улучшает.
Рекомендательные инструменты Spotify
1. Пользователь «оценивает» пользователя
Первый метод по созданию рекомендаций — коллаборативная фильтрация (Collaborative Filtering). Про этот инструмент мы подробно рассказывали в другой нашей статье. Впервые его внедрили на Last.fm, а популяризировал Netflix. У этого американского сервиса видеостриминга метод строится на основе оценок, которые зрители ставят сериалам, фильмам и шоу.
У Spotify оценок нет — поэтому там рекомендации работают на основе косвенного фидбека — можно сказать, что пользователи оставляют оценки в виде метаданных: количество прослушиваний, лайк или пропуск трека (до тридцатой секунды), посещение страницы артиста, прослушивание альбома с песней и т. д.
На основе анализа метаданных высчитывается оценка, которая вкладывается в отдельную ячейку матрицы: по горизонтали — оценки одного из 286 миллионов пользователей (по данным на июль 2020 года), по вертикали — оценки одного трека (более 50 миллионов по заявлениям компании). Получается, что Spotify хранит 14,3 квадриллиона оценок!
Затем система высчитывает векторы пользователя и векторы отдельных треков. Чем ближе вектор трека к вектору пользователя, тем больше вероятность, что этот трек ему порекомендуют.
2. Нейросеть оценивает музыку
Второй метод аналитики — анализ самой музыки. Нейросеть оценивает энергичность треков, присутствие вокала, темп, тональность и так далее. Это позволяет создавать кластеры, которые примеряются на пользователя в комплексе.
Такой анализ важен при рассмотрении треков, которые невозможно оценить другими методами. Например, так анализируют треки начинающих исполнителей, которые слушают крайне мало людей, и еще меньше людей о них пишут.
В данном случае используется сверточная нейронная сеть. Ее задача — сжать объект, не потеряв при этом отношения между его элементами. В таком случае мы можем выявить не просто отношения между отдельно взятыми элементами, но и какую-либо общую тенденцию.
3. Нейросеть оценивает текст песни
Третий метод — анализ текста медиа. На серверах собираются тексты о музыкальных композициях, которые представлены на платформе. Затем с помощью инструментов NLP нейросеть анализирует, какими словами описывают те или иные песни в медиа. Полученные данные агрегируются, после чего вырабатывается система своеобразных тегов. Это не теги/хэштеги в привычном для нас twitter-понимании — «хэштег привязан к событию» —, а скорее бирки — «тег привязан к характеристике».
Например, музыку польской группы Behemoth блоггеры и музыкальные критики никогда в жизни не назовут милой группой — скорее там будут превалировать характеристики вроде «черный», «тяжелый», «эпатажный», «сатанинский» и т. д. Поэтому поляков не порекомендуют любителям Кэти Перри.
Хоумскрин с ИИ
Домашний экран вашего Spotify — это искусственный интеллект «Bandits for Recommendations as Treatments» (BaRT). Он работает на основе полок: одна полка — одна тематика. BaRT — хороший личный ассистент в подборе музыки, если вы долго слушаете музыку на одной полке. Также оценивается и продолжительность прослушивания одного трека. Меньше тридцати секунд не считается, после тридцатой, каждая новая идет треку «в актив», композиции наподобие этой будут чаще появляться в вашем плейлисте.
Алгоритм Spotify защищен от разового прослушивания — если вы включите «Happy Birthday to You» или один раз послушали «шум дождя» перед сном — это не повлияет на ваши рекомендации.
А о системе сбора и хранения данных Spotify — читайте в нашей статье: https://sysblok.ru/musicology/podelis-naushnikom-svoim-eshhe-raz-o-tom-kak-ustroeny-rekomendacii-spotify/
Артур Хисматулин
#musicology #knowhow
Стриминг имеет две принципиально важные черты потребления: массовизация легальной покупки музыки и культура рекомендации. Нельзя сказать, что рекомендации — это идея исключительно стримингового сервиса Spotify. До этого идею рекомендации развивали и другие компании — Spotify просто удачно скомпилировала известные инструменты в систему и постоянно ее улучшает.
Рекомендательные инструменты Spotify
1. Пользователь «оценивает» пользователя
Первый метод по созданию рекомендаций — коллаборативная фильтрация (Collaborative Filtering). Про этот инструмент мы подробно рассказывали в другой нашей статье. Впервые его внедрили на Last.fm, а популяризировал Netflix. У этого американского сервиса видеостриминга метод строится на основе оценок, которые зрители ставят сериалам, фильмам и шоу.
У Spotify оценок нет — поэтому там рекомендации работают на основе косвенного фидбека — можно сказать, что пользователи оставляют оценки в виде метаданных: количество прослушиваний, лайк или пропуск трека (до тридцатой секунды), посещение страницы артиста, прослушивание альбома с песней и т. д.
На основе анализа метаданных высчитывается оценка, которая вкладывается в отдельную ячейку матрицы: по горизонтали — оценки одного из 286 миллионов пользователей (по данным на июль 2020 года), по вертикали — оценки одного трека (более 50 миллионов по заявлениям компании). Получается, что Spotify хранит 14,3 квадриллиона оценок!
Затем система высчитывает векторы пользователя и векторы отдельных треков. Чем ближе вектор трека к вектору пользователя, тем больше вероятность, что этот трек ему порекомендуют.
2. Нейросеть оценивает музыку
Второй метод аналитики — анализ самой музыки. Нейросеть оценивает энергичность треков, присутствие вокала, темп, тональность и так далее. Это позволяет создавать кластеры, которые примеряются на пользователя в комплексе.
Такой анализ важен при рассмотрении треков, которые невозможно оценить другими методами. Например, так анализируют треки начинающих исполнителей, которые слушают крайне мало людей, и еще меньше людей о них пишут.
В данном случае используется сверточная нейронная сеть. Ее задача — сжать объект, не потеряв при этом отношения между его элементами. В таком случае мы можем выявить не просто отношения между отдельно взятыми элементами, но и какую-либо общую тенденцию.
3. Нейросеть оценивает текст песни
Третий метод — анализ текста медиа. На серверах собираются тексты о музыкальных композициях, которые представлены на платформе. Затем с помощью инструментов NLP нейросеть анализирует, какими словами описывают те или иные песни в медиа. Полученные данные агрегируются, после чего вырабатывается система своеобразных тегов. Это не теги/хэштеги в привычном для нас twitter-понимании — «хэштег привязан к событию» —, а скорее бирки — «тег привязан к характеристике».
Например, музыку польской группы Behemoth блоггеры и музыкальные критики никогда в жизни не назовут милой группой — скорее там будут превалировать характеристики вроде «черный», «тяжелый», «эпатажный», «сатанинский» и т. д. Поэтому поляков не порекомендуют любителям Кэти Перри.
Хоумскрин с ИИ
Домашний экран вашего Spotify — это искусственный интеллект «Bandits for Recommendations as Treatments» (BaRT). Он работает на основе полок: одна полка — одна тематика. BaRT — хороший личный ассистент в подборе музыки, если вы долго слушаете музыку на одной полке. Также оценивается и продолжительность прослушивания одного трека. Меньше тридцати секунд не считается, после тридцатой, каждая новая идет треку «в актив», композиции наподобие этой будут чаще появляться в вашем плейлисте.
Алгоритм Spotify защищен от разового прослушивания — если вы включите «Happy Birthday to You» или один раз послушали «шум дождя» перед сном — это не повлияет на ваши рекомендации.
А о системе сбора и хранения данных Spotify — читайте в нашей статье: https://sysblok.ru/musicology/podelis-naushnikom-svoim-eshhe-raz-o-tom-kak-ustroeny-rekomendacii-spotify/
Артур Хисматулин
{kind=link}
География данных: какой статистикой делятся государства
#society #opendata
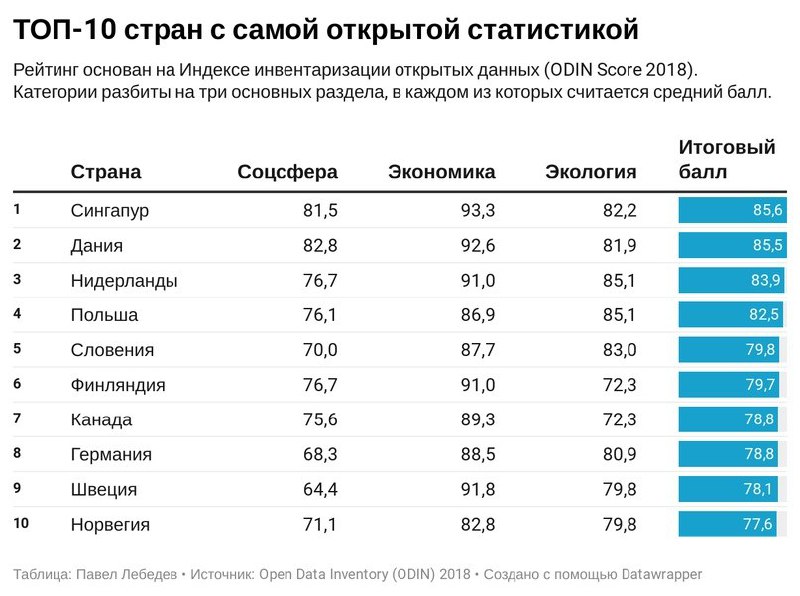
Во всем мире регулярно выходят рейтинги открытости статистики правительств разных стран. Международная некоммерческая организация Open Data Watch готовит один из таких рейтингов. Open Data Inventory (ODIN) Score представляет собой оценку охвата и открытости официальной статистики в 178 странах мира. Оценивается наличие статистических показателей в 21 категории социальной, экономической и экологической статистики. Мы попытались разобраться, какой информацией страны делятся охотнее всего.
Сингапур: открытая экономика
В рейтинге ODIN Score 2018/2019 первое место занял Сингапур. За год он смог подняться с 20 строчки рейтинга и потеснить европейские страны. Это удалось благодаря увеличению охвата и открытости по всем категориям. Особенно сильно возросло количество данных по земельным и энергетическим ресурсам, которыми ранее это островное государство не делилось.
Стало больше и показателей экономической статистики, что вывело Сингапур на первое место по охвату данных в экономике, банковской сфере и балансовых платежах правительства. Сингапуру выгодно делиться информацией о своей экономической сфере, которая является одной из самых передовых в мире: таким образом город-государство привлекает новых инвесторов и партнеров.
Кроме того, эта страна также занимает первое место по гендерной статистике и статистике рождаемости. Во всех представленных показателях данные Сингапура на 100% открыты.
Дания и Норвегия: социальная статистика и зарплаты
Дания занимает второе место в общем рейтинге и первое место по охвату данных в социальной статистике и информации о ресурсах и законах. Норвегия заняла по этому показателю 9 место, хотя в 2016 году делила второе место с Данией.
За последние годы в Норвегии упала открытость данных статистического ведомства, налоговой службы и других ведомств. На протяжении 200 лет Норвегия публиковала в открытом доступе данные о заработке своих граждан. Сначала это были ежегодные сборники, затем информация в сети стала доступна любым желающим на сайте налоговой службы.
Однако с 2014 года вход в систему стал возможен только через национальный идентификационный номер. Также каждый житель видит, кто искал информацию на него. Это убавило количество желающих посмотреть информацию о том, сколько получает знакомый или сосед, но по-прежнему позволяет общественности и СМИ контролировать уровень доходов местных чиновников.
Нидерланды и Польша: окружающая среда и земельные ресурсы
Охотнее всего информацией об окружающей среде делятся Нидерланды и Польша. Эти две страны делят первое место по охвату данных в этой категории в рейтинге ODIN score за 2018 год.
Например, на сайте статистического ведомства Нидерландов выложена статистика по типу земель, начиная с 1900 года. В отдельном датасете представлены все современные земельные участки Нидерландов по типу использования — сельскохозяйственные угодья, леса, водные территории и т. д.
Россия: данные о ценах на товары и услуги
Россия занимает 47 место в общем рейтинге за 2018 год. Однако по такому показателю, как Индекс потребительских цен, находится на первом месте.
Росстат регулярно публикует данные о ценах на товары и услуги на региональных и федеральном уровне. Общественность пристально следит за этими показателями, выходит много публикаций в СМИ, составляются различные рейтинги, например, рейтинг оливье или рейтинг окрошки. На основе показателя индекса цен рассчитывается уровень инфляции в стране.
Одной из главных проблем России является недостаток данных в машиночитаемых форматах для их последующей обработки активистами и журналистами. У данных сложная структура, не хватает визуализаций, которые помогали бы жителям в оперативном режиме следить за изменениями в показателях.
https://sysblok.ru/society/geografija-dannyh-kakoj-statistikoj-gosudarstva-deljatsja-ohotnee-vsego/
Павел Лебедев
#society #opendata
Во всем мире регулярно выходят рейтинги открытости статистики правительств разных стран. Международная некоммерческая организация Open Data Watch готовит один из таких рейтингов. Open Data Inventory (ODIN) Score представляет собой оценку охвата и открытости официальной статистики в 178 странах мира. Оценивается наличие статистических показателей в 21 категории социальной, экономической и экологической статистики. Мы попытались разобраться, какой информацией страны делятся охотнее всего.
Сингапур: открытая экономика
В рейтинге ODIN Score 2018/2019 первое место занял Сингапур. За год он смог подняться с 20 строчки рейтинга и потеснить европейские страны. Это удалось благодаря увеличению охвата и открытости по всем категориям. Особенно сильно возросло количество данных по земельным и энергетическим ресурсам, которыми ранее это островное государство не делилось.
Стало больше и показателей экономической статистики, что вывело Сингапур на первое место по охвату данных в экономике, банковской сфере и балансовых платежах правительства. Сингапуру выгодно делиться информацией о своей экономической сфере, которая является одной из самых передовых в мире: таким образом город-государство привлекает новых инвесторов и партнеров.
Кроме того, эта страна также занимает первое место по гендерной статистике и статистике рождаемости. Во всех представленных показателях данные Сингапура на 100% открыты.
Дания и Норвегия: социальная статистика и зарплаты
Дания занимает второе место в общем рейтинге и первое место по охвату данных в социальной статистике и информации о ресурсах и законах. Норвегия заняла по этому показателю 9 место, хотя в 2016 году делила второе место с Данией.
За последние годы в Норвегии упала открытость данных статистического ведомства, налоговой службы и других ведомств. На протяжении 200 лет Норвегия публиковала в открытом доступе данные о заработке своих граждан. Сначала это были ежегодные сборники, затем информация в сети стала доступна любым желающим на сайте налоговой службы.
Однако с 2014 года вход в систему стал возможен только через национальный идентификационный номер. Также каждый житель видит, кто искал информацию на него. Это убавило количество желающих посмотреть информацию о том, сколько получает знакомый или сосед, но по-прежнему позволяет общественности и СМИ контролировать уровень доходов местных чиновников.
Нидерланды и Польша: окружающая среда и земельные ресурсы
Охотнее всего информацией об окружающей среде делятся Нидерланды и Польша. Эти две страны делят первое место по охвату данных в этой категории в рейтинге ODIN score за 2018 год.
Например, на сайте статистического ведомства Нидерландов выложена статистика по типу земель, начиная с 1900 года. В отдельном датасете представлены все современные земельные участки Нидерландов по типу использования — сельскохозяйственные угодья, леса, водные территории и т. д.
Россия: данные о ценах на товары и услуги
Россия занимает 47 место в общем рейтинге за 2018 год. Однако по такому показателю, как Индекс потребительских цен, находится на первом месте.
Росстат регулярно публикует данные о ценах на товары и услуги на региональных и федеральном уровне. Общественность пристально следит за этими показателями, выходит много публикаций в СМИ, составляются различные рейтинги, например, рейтинг оливье или рейтинг окрошки. На основе показателя индекса цен рассчитывается уровень инфляции в стране.
Одной из главных проблем России является недостаток данных в машиночитаемых форматах для их последующей обработки активистами и журналистами. У данных сложная структура, не хватает визуализаций, которые помогали бы жителям в оперативном режиме следить за изменениями в показателях.
https://sysblok.ru/society/geografija-dannyh-kakoj-statistikoj-gosudarstva-deljatsja-ohotnee-vsego/
Павел Лебедев
{kind=link}
Ресурсы для цифровых стиховедов: поэтические корпуса
#philology #survey
Поэтический корпус — это электронная коллекция стихотворных текстов. Корпус отличается от электронной библиотеки тем, что в нем есть разметка. В поэтических корпусах размечают формальные показатели стиха: метрику, рифму, строфику. Общеизвестных доступных корпусов с такой разметкой четыре: поэтический подкорпус Национального корпуса русского языка (НКРЯ), а также Башкирский, Чешский и Персидский поэтические корпуса.
На базе поэтических корпусов проводятся количественные стиховедческие исследования, например, исследование семантического ореола метра, акцентологические исследования (исследования ударения), ставятся эксперименты по автоматическому определению авторства и изучается творчество отдельных поэтов.
Поэтический подкорпус НКРЯ
Поэтический корпус в составе Национального корпуса русского языка — первый в истории поэтический корпус. На данный момент объем корпуса — 89 124 текстов, 12 407 747 слов. В корпусе представлен 951 автор.
Стиховедческая разметка поэтического подкорпуса НКРЯ включает метр, строфику, клаузулы и другие параметры. Помимо стиховедческой, в поэтическом подкорпусе есть морфологическая и метатекстовая разметка (автор, дата создания, жанр). По метру, строфике, клаузуле и другим признакам можно искать информацию и задавать подкорпус. Определения сложных слов можно искать в терминологическом указателе.
В подкорпусе доступны полные тексты всех произведений. Напрямую из корпуса их скачать нельзя, но мы уже рассказывали, как написать программу для скачивания текстов.
Башкирский поэтический корпус
Объём Башкирского поэтического корпуса составляет более 1,8 млн слов. Коллекция текстов состоит из произведений 103 башкирских поэтов XX и начала XXI века. Авторские права на использованные стихотворения остаются за поэтами.
Для грамматического разбора словоформ Б. В. Орехов и А. А. Галлямов разработали систему автоматического морфологического анализа Bashmorph. А для поиска словоформ по базе была адаптирована поисковая система Восточноармянского национального корпуса, созданная компанией Corpus Technologies.
Тексты в корпусе снабжены морфологической разметкой и стиховедческой разметкой, которая позволяет осуществлять поиск в строках, написанных определенным метром, в зоне рифмовки и т. д. Корпус поддерживает два вида поиска — лексический и грамматический, можно искать как само слово, так и формы по определенным грамматическим признакам. Также есть возможность задавать корпус отдельного автора.
Чешский поэтический корпус
На данный момент в корпусе чешского стиха собраны тексты чешских поэтов XIX — начала XX веков, и его объем более 14,6 млн слов. Каждой словоформе в корпусе присвоена начальная форма данного слова, фонетическая транскрипция и грамматические категории; для каждого стиха определены метр, число стоп, тип клаузулы и метрическая схема.
На основе корпуса создано приложение «Эвфонометр». Эвфония — это учение о благозвучии, раздел поэтики, изучающий в стихе качественную сторону речевых звуков, накладывающих известную эмоциональную окраску на художественное произведение. С помощью Эвфонометра можно вычислить степень благозвучия любого поэтического текста в корпусе.
Персидский поэтический корпус
Персидский поэтический корпус был опубликован весной 2020 года и строился по той же модели, что и все предыдущие. Он содержит тексты классической персидской поэзии IX–XVII веков в объеме 4,3 млн словоупотреблений. Это 16 842 произведения или 330 723 бейта — так называется минимальная строфическая единица тюркской и персидской поэзии. Тексты морфологически размечены, доступен поиск по словам в позиции редифа и рифмы, часть текстов размечена метрически.
Больше подробностей — в нашей статье: https://sysblok.ru/philology/resursy-dlja-cifrovyh-stihovedov-pojeticheskie-korpusa/
Ольга Лисицкая
#philology #survey
Поэтический корпус — это электронная коллекция стихотворных текстов. Корпус отличается от электронной библиотеки тем, что в нем есть разметка. В поэтических корпусах размечают формальные показатели стиха: метрику, рифму, строфику. Общеизвестных доступных корпусов с такой разметкой четыре: поэтический подкорпус Национального корпуса русского языка (НКРЯ), а также Башкирский, Чешский и Персидский поэтические корпуса.
На базе поэтических корпусов проводятся количественные стиховедческие исследования, например, исследование семантического ореола метра, акцентологические исследования (исследования ударения), ставятся эксперименты по автоматическому определению авторства и изучается творчество отдельных поэтов.
Поэтический подкорпус НКРЯ
Поэтический корпус в составе Национального корпуса русского языка — первый в истории поэтический корпус. На данный момент объем корпуса — 89 124 текстов, 12 407 747 слов. В корпусе представлен 951 автор.
Стиховедческая разметка поэтического подкорпуса НКРЯ включает метр, строфику, клаузулы и другие параметры. Помимо стиховедческой, в поэтическом подкорпусе есть морфологическая и метатекстовая разметка (автор, дата создания, жанр). По метру, строфике, клаузуле и другим признакам можно искать информацию и задавать подкорпус. Определения сложных слов можно искать в терминологическом указателе.
В подкорпусе доступны полные тексты всех произведений. Напрямую из корпуса их скачать нельзя, но мы уже рассказывали, как написать программу для скачивания текстов.
Башкирский поэтический корпус
Объём Башкирского поэтического корпуса составляет более 1,8 млн слов. Коллекция текстов состоит из произведений 103 башкирских поэтов XX и начала XXI века. Авторские права на использованные стихотворения остаются за поэтами.
Для грамматического разбора словоформ Б. В. Орехов и А. А. Галлямов разработали систему автоматического морфологического анализа Bashmorph. А для поиска словоформ по базе была адаптирована поисковая система Восточноармянского национального корпуса, созданная компанией Corpus Technologies.
Тексты в корпусе снабжены морфологической разметкой и стиховедческой разметкой, которая позволяет осуществлять поиск в строках, написанных определенным метром, в зоне рифмовки и т. д. Корпус поддерживает два вида поиска — лексический и грамматический, можно искать как само слово, так и формы по определенным грамматическим признакам. Также есть возможность задавать корпус отдельного автора.
Чешский поэтический корпус
На данный момент в корпусе чешского стиха собраны тексты чешских поэтов XIX — начала XX веков, и его объем более 14,6 млн слов. Каждой словоформе в корпусе присвоена начальная форма данного слова, фонетическая транскрипция и грамматические категории; для каждого стиха определены метр, число стоп, тип клаузулы и метрическая схема.
На основе корпуса создано приложение «Эвфонометр». Эвфония — это учение о благозвучии, раздел поэтики, изучающий в стихе качественную сторону речевых звуков, накладывающих известную эмоциональную окраску на художественное произведение. С помощью Эвфонометра можно вычислить степень благозвучия любого поэтического текста в корпусе.
Персидский поэтический корпус
Персидский поэтический корпус был опубликован весной 2020 года и строился по той же модели, что и все предыдущие. Он содержит тексты классической персидской поэзии IX–XVII веков в объеме 4,3 млн словоупотреблений. Это 16 842 произведения или 330 723 бейта — так называется минимальная строфическая единица тюркской и персидской поэзии. Тексты морфологически размечены, доступен поиск по словам в позиции редифа и рифмы, часть текстов размечена метрически.
Больше подробностей — в нашей статье: https://sysblok.ru/philology/resursy-dlja-cifrovyh-stihovedov-pojeticheskie-korpusa/
Ольга Лисицкая
{kind=link}
Чем живет публичная история + бонус: подборка крутых русских digital-проектов
#history #digitalmemory
Публичная история создается во взаимодействии между представителями академической науки, медиа и публики. Она включает в себя производство материалов СМИ, исторических романов, фильмов и сериалов, компьютерных игр, спектаклей, реконструкций и др.
В 1980 году в США был создан Национальный совет по вопросам общественной истории (National Council on Public History). Цель ассоциации — сделать прошлое полезным в настоящем и развивать сотрудничество между историками и обществом. Организация активно работает и в наши дни: разрабатывает профессиональные стандарты, этику публичной истории, поддерживает интересные разработки, образовательные программы и сообщество приверженцев подхода, а также издает ежеквартальный журнал «Публичный историк» («The Public Historian»).
Самый масштабный публично-исторический проект в нашей стране — это мультимедийные выставки «Россия — моя история». Одноименный исторический парк находится в 57 павильоне ВДНХ в Москве и включает четыре выставки: «Романовы», «Рюриковичи», «1914–1945: от великих потрясений к Великой Победе» и «Россия — моя история. 1945–2016». Вслед за столицей мультимедийные экспозиции стали создавать по всей стране, и сейчас площадки проекта есть в 21 городе.
Проекты Public History в российском digital-пространстве
1) 1917. День за днем
Проект от историков и филологов из МГУ. Ежедневные выписки из источников, а также статьи о том, как относились к революции 1917 года интеллектуалы, общество и власть на разных этапах истории.
2) Три проекта команды Михаила Зыгаря:
1917. Свободная история
Исторические свидетельства из 1917 года, упакованные в формат современных социальных сетей, похожий то на Фейсбук, то на Твиттер, то на Инстаграм. Здесь «посты» Колчака и Троцкого, Блока и Ахматовой, Вильгельма II и Керенского, Ленина и Николая II.
1968.DIGITAL
Проект про протестный 1968-й год и эпоху вокруг него. Позиционировался как «Первый сериал для мобильных телефонов». Проект сделан по той же модели переноса старых свидетельств в новую медиа среду: здесь у The Beatles есть чат в WhatsApp, у Гагарина — аккаунт в VK, а у Энди Уорхола — инстаграм.
«Карта истории»
Это документальная игра, в которой можно почувствовать себя русским рокером-кочегаром в перестроечные 80-е, полуподпольным кооперативным миллионером, участником путча в генеральских погонах и т. д. Из более ранних эпох можно примерить на себя роли Сахарова, Высоцкого, Косыгина, Хрущева, Гагарина и даже советского агента в МИ-6 Кима Филби.
3) Прожито
Проект историка Михаила Мельниченко по оцифровке дневников. Сегодня в корпусе «Прожито» больше 4000 тысяч дневников (свыше 450 тысяч записей). Команда проекта проводит регулярные лаборатории по расшифровке и оцифровке дневников и иных эго-документов. «Прожито» — один из самых удачных краудсорсинговых проектов в области изучения повседневности.
4) Родина
Научно-популярный исторический журнал от «Российской газеты».
5) Страдающее Средневековье
Известный в ВК паблик с мемными картинками из средневековых манускриптов. Отдельную известность обрел легендарный персонаж Коля.
6) Устная история
Записи бесед с известными людьми и их потомками, а также просто звуковые артефакты истории: Михаил Бахтин читает «Медного всадника», Лев Термен вспоминает прошлое, Николай Тимофеев-Ресовский рассказывает анекдоты.
7) Diletant.media
Научно-популярный журнал, родившийся под крылом «Эха Москвы». Грешит желтыми обложками и заголовками в стиле журнала «Оракул», но с популяризацией истории справляется неплохо.
О том, откуда берет начало публичная история, как развивается и кто ее развивает, а также почему ее не любят академические историки, читайте в нашей статье: https://sysblok.ru/history/publichnaja-istorija-kak-istoriki-stali-praktikami-i-osvoili-internet/
Анастасия Уткина
#history #digitalmemory
Публичная история создается во взаимодействии между представителями академической науки, медиа и публики. Она включает в себя производство материалов СМИ, исторических романов, фильмов и сериалов, компьютерных игр, спектаклей, реконструкций и др.
В 1980 году в США был создан Национальный совет по вопросам общественной истории (National Council on Public History). Цель ассоциации — сделать прошлое полезным в настоящем и развивать сотрудничество между историками и обществом. Организация активно работает и в наши дни: разрабатывает профессиональные стандарты, этику публичной истории, поддерживает интересные разработки, образовательные программы и сообщество приверженцев подхода, а также издает ежеквартальный журнал «Публичный историк» («The Public Historian»).
Самый масштабный публично-исторический проект в нашей стране — это мультимедийные выставки «Россия — моя история». Одноименный исторический парк находится в 57 павильоне ВДНХ в Москве и включает четыре выставки: «Романовы», «Рюриковичи», «1914–1945: от великих потрясений к Великой Победе» и «Россия — моя история. 1945–2016». Вслед за столицей мультимедийные экспозиции стали создавать по всей стране, и сейчас площадки проекта есть в 21 городе.
Проекты Public History в российском digital-пространстве
1) 1917. День за днем
Проект от историков и филологов из МГУ. Ежедневные выписки из источников, а также статьи о том, как относились к революции 1917 года интеллектуалы, общество и власть на разных этапах истории.
2) Три проекта команды Михаила Зыгаря:
1917. Свободная история
Исторические свидетельства из 1917 года, упакованные в формат современных социальных сетей, похожий то на Фейсбук, то на Твиттер, то на Инстаграм. Здесь «посты» Колчака и Троцкого, Блока и Ахматовой, Вильгельма II и Керенского, Ленина и Николая II.
1968.DIGITAL
Проект про протестный 1968-й год и эпоху вокруг него. Позиционировался как «Первый сериал для мобильных телефонов». Проект сделан по той же модели переноса старых свидетельств в новую медиа среду: здесь у The Beatles есть чат в WhatsApp, у Гагарина — аккаунт в VK, а у Энди Уорхола — инстаграм.
«Карта истории»
Это документальная игра, в которой можно почувствовать себя русским рокером-кочегаром в перестроечные 80-е, полуподпольным кооперативным миллионером, участником путча в генеральских погонах и т. д. Из более ранних эпох можно примерить на себя роли Сахарова, Высоцкого, Косыгина, Хрущева, Гагарина и даже советского агента в МИ-6 Кима Филби.
3) Прожито
Проект историка Михаила Мельниченко по оцифровке дневников. Сегодня в корпусе «Прожито» больше 4000 тысяч дневников (свыше 450 тысяч записей). Команда проекта проводит регулярные лаборатории по расшифровке и оцифровке дневников и иных эго-документов. «Прожито» — один из самых удачных краудсорсинговых проектов в области изучения повседневности.
4) Родина
Научно-популярный исторический журнал от «Российской газеты».
5) Страдающее Средневековье
Известный в ВК паблик с мемными картинками из средневековых манускриптов. Отдельную известность обрел легендарный персонаж Коля.
6) Устная история
Записи бесед с известными людьми и их потомками, а также просто звуковые артефакты истории: Михаил Бахтин читает «Медного всадника», Лев Термен вспоминает прошлое, Николай Тимофеев-Ресовский рассказывает анекдоты.
7) Diletant.media
Научно-популярный журнал, родившийся под крылом «Эха Москвы». Грешит желтыми обложками и заголовками в стиле журнала «Оракул», но с популяризацией истории справляется неплохо.
О том, откуда берет начало публичная история, как развивается и кто ее развивает, а также почему ее не любят академические историки, читайте в нашей статье: https://sysblok.ru/history/publichnaja-istorija-kak-istoriki-stali-praktikami-i-osvoili-internet/
Анастасия Уткина
{kind=link}
«Персональный ассистент может стать независимой версией нашей личности» — интервью с Аннет Маркхэм, цифровым этнографом
#interview
Аннет Маркхэм — профессор в Орхусском университете в Дании и в Университете Лойола, Чикаго. Преподает информационную науку и цифровую этику. Основная область исследований — цифровая этнография.
Аннет изучает, как воздействуют цифровые технологии, гаджеты и социальные сети на общество и нашу повседневную жизнь, как при этом складываются отношения между людьми, как происходит их общение, как индивид осознает себя как личность, как мы узнаем и распространяем новости, и как организовываем свою жизнь.
В книге «Жизнь онлайн: исследование реального опыта в виртуальном пространстве» Аннет Маркхэм показывает, как личность, социум и отношения между людьми трансформируются под действием виртуальной среды, насколько реален цифровой опыт и что с этим делать исследователю.
О чем мы поговорили в интервью с Аннет
• об этапах цифровой революции;
• о дополненной реальности;
• о том, как изучать свое цифровое поведение;
• о трендах и этических проблемах будущего.
Примеры трендов и этических проблем
Тренд: общение с цифровым персональным помощником типа Alexa, Siri или Google Assistant.
Проблема: многие предпочитают, чтобы персональный ассистент был женского пола — это проекция наших стереотипов на цифровую среду. Из-за этого женщинам становится еще тяжелее преодолевать данные стереотипы.
Тренд: применение алгоритмов, которые предсказывают, что пользователь захочет увидеть в своей ленте в социальных сетях.
Проблема: в 2016 произошел случай, когда девушка покончила жизнь самоубийством из-за того, что в ее новостной ленте появлялось все больше постов о причинении себе вреда, потому что она сама делала посты на похожую тему.
https://sysblok.ru/interviews/cifrovaja-jetnografija-i-djavolskij-znachok-uvedomlenij/
Даниил Скоринкин, Герман Пальчиков, Ольга Ивлиева, Вусале Агасиева
#interview
Аннет Маркхэм — профессор в Орхусском университете в Дании и в Университете Лойола, Чикаго. Преподает информационную науку и цифровую этику. Основная область исследований — цифровая этнография.
Аннет изучает, как воздействуют цифровые технологии, гаджеты и социальные сети на общество и нашу повседневную жизнь, как при этом складываются отношения между людьми, как происходит их общение, как индивид осознает себя как личность, как мы узнаем и распространяем новости, и как организовываем свою жизнь.
В книге «Жизнь онлайн: исследование реального опыта в виртуальном пространстве» Аннет Маркхэм показывает, как личность, социум и отношения между людьми трансформируются под действием виртуальной среды, насколько реален цифровой опыт и что с этим делать исследователю.
О чем мы поговорили в интервью с Аннет
• об этапах цифровой революции;
• о дополненной реальности;
• о том, как изучать свое цифровое поведение;
• о трендах и этических проблемах будущего.
Примеры трендов и этических проблем
Тренд: общение с цифровым персональным помощником типа Alexa, Siri или Google Assistant.
Проблема: многие предпочитают, чтобы персональный ассистент был женского пола — это проекция наших стереотипов на цифровую среду. Из-за этого женщинам становится еще тяжелее преодолевать данные стереотипы.
Тренд: применение алгоритмов, которые предсказывают, что пользователь захочет увидеть в своей ленте в социальных сетях.
Проблема: в 2016 произошел случай, когда девушка покончила жизнь самоубийством из-за того, что в ее новостной ленте появлялось все больше постов о причинении себе вреда, потому что она сама делала посты на похожую тему.
https://sysblok.ru/interviews/cifrovaja-jetnografija-i-djavolskij-znachok-uvedomlenij/
Даниил Скоринкин, Герман Пальчиков, Ольга Ивлиева, Вусале Агасиева
{kind=link}
Мифы о защите персональных данных: как не надо прятаться от Большого Брата
#society #opendata
Разбираемся, какие способы защиты личной информации не помогут избавиться от цифровых следов в интернете.
Миф 1. Если я создам фейковый аккаунт, никто не поймет, кому он принадлежит
Что будет, если оставить основной аккаунт для общения с коллегами, а с фейкового лайкать свои же фотографии? От коллег скрыться можно, а от компаний, собирающих данные, — нет: они установят связь дубликата и основной страницы, даже если имена на них не совпадают.
Для этого они проанализируют поведение пользователя: IP-адрес, с которого он заходит; посещаемые страницы; лайки в сообществах; списки друзей; геолокацию и др. Все это вместе дает довольно надежную идентификацию. Даже «пустая» страница без информации, фотографий и подписок на сообщества может многое сообщить о ее владельце, если он активно ей пользуется.
Миф 2. Если я удалю свой аккаунт, я сотру свои данные из интернета
Соцсети хранят данные об удаленном аккаунте длительное время — на случай восстановления страницы. Их можно сопоставить с данными о фейке, если он есть, или с новосозданной страницей, где нет компрометирующих мемов 2010 года.
Известен случай долгого судебного дела, когда пользователь из Твери несколько месяцев пытался заставить ВКонтакте стереть все данные о нем с сайта.
Миф 3. Если я отмечу фальшивую геолокацию, никто не узнает, где я был на самом деле
В 2019 году сотрудницы BuzzFeed провели эксперимент: целую неделю они постили в Instagram фотографии и сториз из своей поездки в Лондон. На самом деле никакой поездки не было, а все фотографии были сделаны в Америке, но большинство подписчиков девушек поверили в этот отпуск.
Метод с фальшивыми геолокациями подойдет, чтобы подшутить над друзьями. Но если цель — не пошутить, а скрыться, метод вряд ли сработает: нейросети уже умеют узнавать даже не самые очевидные места по заднему плану на фотографиях.
Миф 4. Если я выхожу в сеть через браузер Tor, никто не узнает мои личные данные и IP-адрес
Использование браузера Tor — один из наиболее надежных способов защитить персональные данные. В основе работы Tor технология луковой, или луковичной, маршрутизации, поэтому Tor расшифровывается как The Onion Routing.
Технология работает так: информация выходит из одного источника — например, компьютера, — и не сразу достигает конечной цели, а проходит несколько узлов — других компьютеров, — которые удаляют предыдущий слой шифрования и зашифровывают информацию по-новому.
Чаще всего первоначальный источник трафика не выявить. Но если пользователь не использует зашифрованный протокол — HTTPS, SSH или TLS — и источник содержит идентифицирующую информацию, точку выхода из сети можно отследить.
При использовании Tor стоит позаботиться о том, чтобы каждый раз использовать новый ник и не допускать ошибку Росса Ульбрихта. Ульбрихт — основатель Silk Road, анонимной торговой площадки, где продавались наркотики и психоактивные вещества. В 2013 году его нашла полиция, когда во время поиска IT-профессионалов в свою команду он указал личную электронную почту, названную его именем и фамилией.
Не миф: технологии анонимизации и шифрования
Чтобы надежно защитить данные, можно использовать специально разработанные технологии анонимизации и шифрования. К ним относятся:
• упомянутые выше безопасные протоколы обмена информацией по сети — HTTPS и SSH;
• виртуальные частные сети — VPN;
• асинхронное шифрование при передаче сообщений по сети — алгоритм RSA, который используется в популярной системе шифрования PGP;
• всевозможные анонимизирующие прокси-серверы.
Но и эти инструменты помогут, только если применять их в правильной комбинации и с умом.
https://sysblok.ru/society/mify-o-zashhite-personalnyh-dannyh-kak-ne-nado-prjatatsja-ot-bolshogo-brata/
Анна Купина
#society #opendata
Разбираемся, какие способы защиты личной информации не помогут избавиться от цифровых следов в интернете.
Миф 1. Если я создам фейковый аккаунт, никто не поймет, кому он принадлежит
Что будет, если оставить основной аккаунт для общения с коллегами, а с фейкового лайкать свои же фотографии? От коллег скрыться можно, а от компаний, собирающих данные, — нет: они установят связь дубликата и основной страницы, даже если имена на них не совпадают.
Для этого они проанализируют поведение пользователя: IP-адрес, с которого он заходит; посещаемые страницы; лайки в сообществах; списки друзей; геолокацию и др. Все это вместе дает довольно надежную идентификацию. Даже «пустая» страница без информации, фотографий и подписок на сообщества может многое сообщить о ее владельце, если он активно ей пользуется.
Миф 2. Если я удалю свой аккаунт, я сотру свои данные из интернета
Соцсети хранят данные об удаленном аккаунте длительное время — на случай восстановления страницы. Их можно сопоставить с данными о фейке, если он есть, или с новосозданной страницей, где нет компрометирующих мемов 2010 года.
Известен случай долгого судебного дела, когда пользователь из Твери несколько месяцев пытался заставить ВКонтакте стереть все данные о нем с сайта.
Миф 3. Если я отмечу фальшивую геолокацию, никто не узнает, где я был на самом деле
В 2019 году сотрудницы BuzzFeed провели эксперимент: целую неделю они постили в Instagram фотографии и сториз из своей поездки в Лондон. На самом деле никакой поездки не было, а все фотографии были сделаны в Америке, но большинство подписчиков девушек поверили в этот отпуск.
Метод с фальшивыми геолокациями подойдет, чтобы подшутить над друзьями. Но если цель — не пошутить, а скрыться, метод вряд ли сработает: нейросети уже умеют узнавать даже не самые очевидные места по заднему плану на фотографиях.
Миф 4. Если я выхожу в сеть через браузер Tor, никто не узнает мои личные данные и IP-адрес
Использование браузера Tor — один из наиболее надежных способов защитить персональные данные. В основе работы Tor технология луковой, или луковичной, маршрутизации, поэтому Tor расшифровывается как The Onion Routing.
Технология работает так: информация выходит из одного источника — например, компьютера, — и не сразу достигает конечной цели, а проходит несколько узлов — других компьютеров, — которые удаляют предыдущий слой шифрования и зашифровывают информацию по-новому.
Чаще всего первоначальный источник трафика не выявить. Но если пользователь не использует зашифрованный протокол — HTTPS, SSH или TLS — и источник содержит идентифицирующую информацию, точку выхода из сети можно отследить.
При использовании Tor стоит позаботиться о том, чтобы каждый раз использовать новый ник и не допускать ошибку Росса Ульбрихта. Ульбрихт — основатель Silk Road, анонимной торговой площадки, где продавались наркотики и психоактивные вещества. В 2013 году его нашла полиция, когда во время поиска IT-профессионалов в свою команду он указал личную электронную почту, названную его именем и фамилией.
Не миф: технологии анонимизации и шифрования
Чтобы надежно защитить данные, можно использовать специально разработанные технологии анонимизации и шифрования. К ним относятся:
• упомянутые выше безопасные протоколы обмена информацией по сети — HTTPS и SSH;
• виртуальные частные сети — VPN;
• асинхронное шифрование при передаче сообщений по сети — алгоритм RSA, который используется в популярной системе шифрования PGP;
• всевозможные анонимизирующие прокси-серверы.
Но и эти инструменты помогут, только если применять их в правильной комбинации и с умом.
https://sysblok.ru/society/mify-o-zashhite-personalnyh-dannyh-kak-ne-nado-prjatatsja-ot-bolshogo-brata/
Анна Купина
{kind=link}
Джеймс против Джойса: можно ли измерить сложность художественной литературы
#philology
Художественный текст сложный по определению, так как авторы используют средства художественной выразительности — метафоры, эксперименты с синтаксисом и лексической многозначностью, аллюзии и др. Кроме того, понимание сложности текста меняется. То, что было ново и непривычно для читателя начала XX века, читателя XXI века не удивит и покажется простым в восприятии.
В этой статье рассказываем, как исследователи из Кембриджского университета измеряли сложность разнообразных по жанру и стилю произведений английской литературы XIX–XX веков.
Индекс Флеша
Чтобы найти индекс Флеша, вычисляют среднюю длину предложений в тексте, а также количество слогов в словах. Подробнее об индексе Флеша мы уже рассказывали в другой нашей статье.
Выяснилось, что многие тексты первой половины XIX века, например, «Чувство и чувствительность» Остин, имеют по этому критерию показатели выше, чем у авангардных романов Джойса «Улисс» и «Поминки по Финнегану».
Поэтому меры удобочитаемости (readability) не дают объективной картины для художественной литературы.
Абстрактность используемых слов
Существует словарь, в котором слова размечены носителями языка по степени абстрактности-конкретности: испытуемые оценивали слова, ставя баллы от 1 до 5 напротив каждого слова. Каждый текст из выборки был оценен по среднему значению конкретности тех слов, которые есть и в словаре, и в самом тексте.
Вестерн Кормака Маккарни «Кровавый меридиан» предсказуемо оказался в самом верху шкалы конкретности. Однако авангардный «Улисс» соседствует с приключенческим романом «Остров сокровищ» Стивенсона, а степень конкретности Джойса остается одинаковой, несмотря на значительную эволюцию его стиля от реалистических «Дублинцев» до экспериментального романа «Поминки по Финнегану».
Этот факт ставит под сомнение тезис, что по лексической абстрактности можно судить о сложности текста.
Измерение культурного контекста
Исследователи Ewan Jones и Paul Nulty предлагают новую методику определения сложности художественного текста: они измеряют сложность текста в сравнении с окружающим его контекстом — большим текстовым корпусом. Для своей задачи исследователи использовали Google Books Fiction — раздел с английской художественной литературой с 1800 по 1915 год, который состоит из примерно 7.1 миллиардов токенов.
Ключевой параметр — относительная частота употребления слов: чем больше в тексте знакомых слов, тем текст для нас «предсказуемее», легче. Для каждого слова в датасете и в «испытуемых» произведениях из первых экспериментов вычисляется мера Ципфа: насколько часто встречается слово в конкретном произведении и насколько часто встречается оно же во всем корпусе. При этом учитываются только те слова, которые встречаются и там, и там.
Затем меру Ципфа в корпусе для каждого слова сравнили с мерой Ципфа каждого конкретного произведения. Наименьшее значение получил роман «Поминки по Финнегану» (Finnegan’s Wake) Джойса, а наибольшее — «Крылья голубки» (Wings of the dove) Джеймса.
Кажется, это значит, что Джойс максимально отличается от литературного контекста, а Джеймс максимально на него похож. Но это не так: близость к контексту определяется близостью к среднему значению, т. к. сравнивается относительная сложность произведений.
Наиболее близкий к контексту текст — это «Записки Пиквикского клуба» Диккенса: именно его показатель ближе всего к общему среднему по корпусу. А экстремумы — это непохожесть на контекст, причем эта непохожесть может быть как простотой, так и сложностью.
https://sysblok.ru/philology/dzhejms-protiv-dzhojsa-o-slozhnosti-v-hudozhestvennoj-literature/
Мария Захарова
#philology
Художественный текст сложный по определению, так как авторы используют средства художественной выразительности — метафоры, эксперименты с синтаксисом и лексической многозначностью, аллюзии и др. Кроме того, понимание сложности текста меняется. То, что было ново и непривычно для читателя начала XX века, читателя XXI века не удивит и покажется простым в восприятии.
В этой статье рассказываем, как исследователи из Кембриджского университета измеряли сложность разнообразных по жанру и стилю произведений английской литературы XIX–XX веков.
Индекс Флеша
Чтобы найти индекс Флеша, вычисляют среднюю длину предложений в тексте, а также количество слогов в словах. Подробнее об индексе Флеша мы уже рассказывали в другой нашей статье.
Выяснилось, что многие тексты первой половины XIX века, например, «Чувство и чувствительность» Остин, имеют по этому критерию показатели выше, чем у авангардных романов Джойса «Улисс» и «Поминки по Финнегану».
Поэтому меры удобочитаемости (readability) не дают объективной картины для художественной литературы.
Абстрактность используемых слов
Существует словарь, в котором слова размечены носителями языка по степени абстрактности-конкретности: испытуемые оценивали слова, ставя баллы от 1 до 5 напротив каждого слова. Каждый текст из выборки был оценен по среднему значению конкретности тех слов, которые есть и в словаре, и в самом тексте.
Вестерн Кормака Маккарни «Кровавый меридиан» предсказуемо оказался в самом верху шкалы конкретности. Однако авангардный «Улисс» соседствует с приключенческим романом «Остров сокровищ» Стивенсона, а степень конкретности Джойса остается одинаковой, несмотря на значительную эволюцию его стиля от реалистических «Дублинцев» до экспериментального романа «Поминки по Финнегану».
Этот факт ставит под сомнение тезис, что по лексической абстрактности можно судить о сложности текста.
Измерение культурного контекста
Исследователи Ewan Jones и Paul Nulty предлагают новую методику определения сложности художественного текста: они измеряют сложность текста в сравнении с окружающим его контекстом — большим текстовым корпусом. Для своей задачи исследователи использовали Google Books Fiction — раздел с английской художественной литературой с 1800 по 1915 год, который состоит из примерно 7.1 миллиардов токенов.
Ключевой параметр — относительная частота употребления слов: чем больше в тексте знакомых слов, тем текст для нас «предсказуемее», легче. Для каждого слова в датасете и в «испытуемых» произведениях из первых экспериментов вычисляется мера Ципфа: насколько часто встречается слово в конкретном произведении и насколько часто встречается оно же во всем корпусе. При этом учитываются только те слова, которые встречаются и там, и там.
Затем меру Ципфа в корпусе для каждого слова сравнили с мерой Ципфа каждого конкретного произведения. Наименьшее значение получил роман «Поминки по Финнегану» (Finnegan’s Wake) Джойса, а наибольшее — «Крылья голубки» (Wings of the dove) Джеймса.
Кажется, это значит, что Джойс максимально отличается от литературного контекста, а Джеймс максимально на него похож. Но это не так: близость к контексту определяется близостью к среднему значению, т. к. сравнивается относительная сложность произведений.
Наиболее близкий к контексту текст — это «Записки Пиквикского клуба» Диккенса: именно его показатель ближе всего к общему среднему по корпусу. А экстремумы — это непохожесть на контекст, причем эта непохожесть может быть как простотой, так и сложностью.
https://sysblok.ru/philology/dzhejms-protiv-dzhojsa-o-slozhnosti-v-hudozhestvennoj-literature/
Мария Захарова
{kind=link}
Виртуальный театр: VR-спектакли в России, Европе и Америке
VR — это способ погрузиться в другой мир, оставаясь в нашей реальности. Все дело в специальных очках и наушниках, которые проецируют цифровую картинку и звуки на то пространство, в котором находится пользователь.
В театре VR помогает сломать так называемую «четвертую стену», традиционно отделяющую зрителя от актеров, а также дает возможности для экспериментов.
Первый проект
Использование VR-технологий в искусстве началось в Америке в конце XX века. Все началось с эксперимента дизайнера и исследователя видеоигр Бренды Лорел, которая в 1994 году совместно с режиссером документального кино Рейчел Стриклэнд создала проект Placeholder.
Основой истории внутри постановки были взаимоотношения древних людей с местами, в которых они обитали. Каждый участник мог выбрать себе локацию и тотемное животное. На протяжении всего действия, участники могли оставлять голосовые сообщения, которые оставались в истории. Так зрители впервые попробовали себя в роли актеров, а создатели смогли воплотить новую форму повествования — многоуровневую, сложную концепцию.
Что VR дает театру
Для теоретиков театра внедрение VR-технологий — поле для рассуждений о новых концепциях взаимодействия актера и зрителя, новых формах сценографии и выстраивания мизансцен. VR-технологии меняют форму повествования в спектакле: нарратив становится не линейным, как это принято в классическом театре, а многомерным.
Здесь может возникнуть вопрос: если зритель сам выбирает, как разворачивается действие, то неужели история и действия героев от этого не меняются? Тупак Мартир, режиссер одного из британских VR-спектаклей, ответил на этот вопрос так: «История никогда не меняется, зритель выбирает то, на что ему смотреть. Мы лишь следуем тому пути, по которому они идут, понимая историю».
VR- спектакли на русской сцене
В нашей первой статье о VR-спектаклях рассказываем об отечественных постановках:
• «Клетка с попугаями» (реж. М. Диденко)
• «В поисках автора» (реж. Д. Чащин)
• «Я убил царя» (реж. М.Патласов)
https://sysblok.ru/arts/virtualnyj-teatr-vr-spektakli-v-rossii/
VR-спектакли в Европе
Во второй части трилогии рассказываем о Британских постановках:
• «Водолаз» (ориг. «Frogman»)
• «Нарисуй меня рядом» (ориг. «Draw Me Close»)
• «Космос внутри нас» (ориг. «Cosmos Within Us»)
• «Все виды Лимбо» (ориг. «All Kinds of Limbo»)
https://sysblok.ru/arts/virtualnyj-teatr-obzor-vr-spektaklej-v-evrope/
VR-спектакли в США
Несмотря на первенство американского театра в использовании VR, сегодня на американской сцене можно найти лишь два действительно крупных проекта:
• «Гамлет 360: дух отца» (ориг. «Hamlet 360: The Father’s Spirit»)
• «Под подарками» (ориг. «The Under Presents»)
https://sysblok.ru/arts/virtualnyj-teatr-vr-spektakli-v-ssha-pozvoljajut-pobyt-otcom-gamleta/
Даша Масленко
VR — это способ погрузиться в другой мир, оставаясь в нашей реальности. Все дело в специальных очках и наушниках, которые проецируют цифровую картинку и звуки на то пространство, в котором находится пользователь.
В театре VR помогает сломать так называемую «четвертую стену», традиционно отделяющую зрителя от актеров, а также дает возможности для экспериментов.
Первый проект
Использование VR-технологий в искусстве началось в Америке в конце XX века. Все началось с эксперимента дизайнера и исследователя видеоигр Бренды Лорел, которая в 1994 году совместно с режиссером документального кино Рейчел Стриклэнд создала проект Placeholder.
Основой истории внутри постановки были взаимоотношения древних людей с местами, в которых они обитали. Каждый участник мог выбрать себе локацию и тотемное животное. На протяжении всего действия, участники могли оставлять голосовые сообщения, которые оставались в истории. Так зрители впервые попробовали себя в роли актеров, а создатели смогли воплотить новую форму повествования — многоуровневую, сложную концепцию.
Что VR дает театру
Для теоретиков театра внедрение VR-технологий — поле для рассуждений о новых концепциях взаимодействия актера и зрителя, новых формах сценографии и выстраивания мизансцен. VR-технологии меняют форму повествования в спектакле: нарратив становится не линейным, как это принято в классическом театре, а многомерным.
Здесь может возникнуть вопрос: если зритель сам выбирает, как разворачивается действие, то неужели история и действия героев от этого не меняются? Тупак Мартир, режиссер одного из британских VR-спектаклей, ответил на этот вопрос так: «История никогда не меняется, зритель выбирает то, на что ему смотреть. Мы лишь следуем тому пути, по которому они идут, понимая историю».
VR- спектакли на русской сцене
В нашей первой статье о VR-спектаклях рассказываем об отечественных постановках:
• «Клетка с попугаями» (реж. М. Диденко)
• «В поисках автора» (реж. Д. Чащин)
• «Я убил царя» (реж. М.Патласов)
https://sysblok.ru/arts/virtualnyj-teatr-vr-spektakli-v-rossii/
VR-спектакли в Европе
Во второй части трилогии рассказываем о Британских постановках:
• «Водолаз» (ориг. «Frogman»)
• «Нарисуй меня рядом» (ориг. «Draw Me Close»)
• «Космос внутри нас» (ориг. «Cosmos Within Us»)
• «Все виды Лимбо» (ориг. «All Kinds of Limbo»)
https://sysblok.ru/arts/virtualnyj-teatr-obzor-vr-spektaklej-v-evrope/
VR-спектакли в США
Несмотря на первенство американского театра в использовании VR, сегодня на американской сцене можно найти лишь два действительно крупных проекта:
• «Гамлет 360: дух отца» (ориг. «Hamlet 360: The Father’s Spirit»)
• «Под подарками» (ориг. «The Under Presents»)
https://sysblok.ru/arts/virtualnyj-teatr-vr-spektakli-v-ssha-pozvoljajut-pobyt-otcom-gamleta/
Даша Масленко
{kind=link}
История адресной системы: как появились номера на домах
#history
Разбираемся, когда на домах появились адреса, кому они понадобились, как связаны с Просвещением, призывом в армию и дискриминацией евреев в Европе.
Античность. В античные времена дома носили имена своих владельцев, так как большинство общественных отношений того времени основывалось на личных знакомствах. Все друг друга знали, и найти дом Гая Ливия в столице древней Римской империи не составило бы труда.
Средневековье. В Средневековье находить нужные дома становилось труднее, так как города росли, и в одной Вене XVIII века домов с именем «Золотой орел» в центре было 6, а на окраинах — 23. Приходит пора менять адресную систему.
Эпоха Просвещения. Государство начинает присваивать зданиям номера, и люди начинают воспринимать дома отдельно от своих хозяев. В первую очередь нумерация домов, похожая на современную, начинает появляться в Лондоне, Париже, Праге и Ливерпуле.
Дома в Европе нумеровали, чтобы упростить работу пожарных служб, полиции и муниципалитета, а также процедуру военного призыва, координацию войск и их снабжение жильем на время стоянки в городе.
Способы нумеровать дома
С появлением номеров возникает вопрос: в каком порядке нумеровать дома? Вариантов множество, и отсюда — ужасная путаница. Для решения этой проблемы были придуманы несколько систем нумерации домов.
Европейская система. Это самая популярная система: по одной стороне улицы располагаются дома с четными номерами, напротив — с нечетными. Впервые она появилась в Филадельфии в 1790 году, и только спустя 15 лет — в Европе.
Возрастная система. Город застраивался от дома под номером один и постепенно разрастался, причем каждому новому дому присваивался номер больше предыдущего. Так, например, в старинной Праге застройка шла от первого дома в историческом районе Градчаны, Пражском Граде.
Районная система. В немецких Аугсбурге и Нюрнберге номера домов состояли из цифр и букв, причем последние соответствовали району города. Вокруг церкви Святого Себальда (район S — St. Sebald) по такой схеме расположились дома с номерами от S1 до S1706, а в районе церкви Святого Лаврентия (район L — St. Lorenz) — от L1 до L1578.
Поквартальная система. Распространена в нынешнем Мадриде. Отдельный номер присваивается каждому кварталу, называемому манзана, а каждому дому, расположенному внутри этого квартала, присваивается еще своя буква или цифра. Таким образом, чтобы найти нужный адрес нужно знать номер квартала, номер (или букву) дома и улицу, на которой он расположен.
Последовательная система. Нумерация идет сначала по одной стороне, а дойдя до конца улицы, разворачивается. В итоге первый дом расположен напротив последнего.
Метрическая система. Номер дома равен расстоянию от этого дома до нулевой отметки, то есть начала улицы. Подобные улицы часто можно встретить в странах Латинской Америки.
Декаметрическая система. Сочетание метрической и европейской систем: номер дома свидетельствует о расстоянии от него до нулевой отметки, при этом четные и нечетные номера расположены на разных сторонах улицы.
Как с помощью нумерации выражали антисемитизм
Во времена правления династии Габсбургов в Европе на одной улице можно было встретить дома с арабскими и римскими номерами. Арабскими цифрами помечались дома европейцев, римскими — евреев. Такое выражение антисемитизма часто встречалось в центральной Европе вплоть до XIX века.
Больше подробностей — в нашей статье: https://sysblok.ru/history/kak-na-domah-pojavilis-nomera-adresa-segodnja-i-300-let-nazad/
Мария Черных
#history
Разбираемся, когда на домах появились адреса, кому они понадобились, как связаны с Просвещением, призывом в армию и дискриминацией евреев в Европе.
Античность. В античные времена дома носили имена своих владельцев, так как большинство общественных отношений того времени основывалось на личных знакомствах. Все друг друга знали, и найти дом Гая Ливия в столице древней Римской империи не составило бы труда.
Средневековье. В Средневековье находить нужные дома становилось труднее, так как города росли, и в одной Вене XVIII века домов с именем «Золотой орел» в центре было 6, а на окраинах — 23. Приходит пора менять адресную систему.
Эпоха Просвещения. Государство начинает присваивать зданиям номера, и люди начинают воспринимать дома отдельно от своих хозяев. В первую очередь нумерация домов, похожая на современную, начинает появляться в Лондоне, Париже, Праге и Ливерпуле.
Дома в Европе нумеровали, чтобы упростить работу пожарных служб, полиции и муниципалитета, а также процедуру военного призыва, координацию войск и их снабжение жильем на время стоянки в городе.
Способы нумеровать дома
С появлением номеров возникает вопрос: в каком порядке нумеровать дома? Вариантов множество, и отсюда — ужасная путаница. Для решения этой проблемы были придуманы несколько систем нумерации домов.
Европейская система. Это самая популярная система: по одной стороне улицы располагаются дома с четными номерами, напротив — с нечетными. Впервые она появилась в Филадельфии в 1790 году, и только спустя 15 лет — в Европе.
Возрастная система. Город застраивался от дома под номером один и постепенно разрастался, причем каждому новому дому присваивался номер больше предыдущего. Так, например, в старинной Праге застройка шла от первого дома в историческом районе Градчаны, Пражском Граде.
Районная система. В немецких Аугсбурге и Нюрнберге номера домов состояли из цифр и букв, причем последние соответствовали району города. Вокруг церкви Святого Себальда (район S — St. Sebald) по такой схеме расположились дома с номерами от S1 до S1706, а в районе церкви Святого Лаврентия (район L — St. Lorenz) — от L1 до L1578.
Поквартальная система. Распространена в нынешнем Мадриде. Отдельный номер присваивается каждому кварталу, называемому манзана, а каждому дому, расположенному внутри этого квартала, присваивается еще своя буква или цифра. Таким образом, чтобы найти нужный адрес нужно знать номер квартала, номер (или букву) дома и улицу, на которой он расположен.
Последовательная система. Нумерация идет сначала по одной стороне, а дойдя до конца улицы, разворачивается. В итоге первый дом расположен напротив последнего.
Метрическая система. Номер дома равен расстоянию от этого дома до нулевой отметки, то есть начала улицы. Подобные улицы часто можно встретить в странах Латинской Америки.
Декаметрическая система. Сочетание метрической и европейской систем: номер дома свидетельствует о расстоянии от него до нулевой отметки, при этом четные и нечетные номера расположены на разных сторонах улицы.
Как с помощью нумерации выражали антисемитизм
Во времена правления династии Габсбургов в Европе на одной улице можно было встретить дома с арабскими и римскими номерами. Арабскими цифрами помечались дома европейцев, римскими — евреев. Такое выражение антисемитизма часто встречалось в центральной Европе вплоть до XIX века.
Больше подробностей — в нашей статье: https://sysblok.ru/history/kak-na-domah-pojavilis-nomera-adresa-segodnja-i-300-let-nazad/
Мария Черных
{kind=link}
Над пропастью поржи: интервью с техноблогером Вастриком
#interview
Технологический блогер vas3k (в миру программист Василий Зубарев) известен всему просвещенному интернету как автор постов о машинном обучении, VR, машинном переводе, блокчейне и других хайповых технологиях.
Вастрик — пример успешного авторского инди-блога про IT. Его посты переводят на английский, используют как пособие при трудоустройстве и учебный материал для лекций в университете.
Посты Вастрика — это панк-версия журнала «Юный техник» для читателей 18+. Погружение в инженерные детали сочетается с шутками в стиле «сибирский IT-гопник» и картинками в духе XKCD.
Буквально за неделю до COVID-карантина спецгруппа «Системного Блока» съездила в Берлин и записала это интервью.
О чем мы поговорили с Вастриком
• о том, для кого он пишет;
• о внутренней мотивации писать посты;
• о хайпе вокруг IT-образования;
• о пользе гуманитариев в решении проблем;
• о том, надо ли не-айтишнику глубоко разбираться в IT;
• об искусственном интеллекте;
• о тех, кто вдохновляет Вастрика;
• о переходе к закрытому комьюнити с подпиской.
https://sysblok.ru/interviews/nad-propastju-porzhi-intervju-s-tehnoblogerom-vastrikom/
Даниил Скоринкин, Илья Булгаков
#interview
Технологический блогер vas3k (в миру программист Василий Зубарев) известен всему просвещенному интернету как автор постов о машинном обучении, VR, машинном переводе, блокчейне и других хайповых технологиях.
Вастрик — пример успешного авторского инди-блога про IT. Его посты переводят на английский, используют как пособие при трудоустройстве и учебный материал для лекций в университете.
Посты Вастрика — это панк-версия журнала «Юный техник» для читателей 18+. Погружение в инженерные детали сочетается с шутками в стиле «сибирский IT-гопник» и картинками в духе XKCD.
Буквально за неделю до COVID-карантина спецгруппа «Системного Блока» съездила в Берлин и записала это интервью.
О чем мы поговорили с Вастриком
• о том, для кого он пишет;
• о внутренней мотивации писать посты;
• о хайпе вокруг IT-образования;
• о пользе гуманитариев в решении проблем;
• о том, надо ли не-айтишнику глубоко разбираться в IT;
• об искусственном интеллекте;
• о тех, кто вдохновляет Вастрика;
• о переходе к закрытому комьюнити с подпиской.
https://sysblok.ru/interviews/nad-propastju-porzhi-intervju-s-tehnoblogerom-vastrikom/
Даниил Скоринкин, Илья Булгаков
{kind=link}
Как выделяют и классифицируют сущности в художественных текстах
#nlp #philology
Человек схватывает новую информацию на лету: из контекста, из интонации, из невербального общения. А как помочь компьютеру понять, что Гарри — волшебник, Гендальф — майар, а Джон Сноу — одновременно Старк и Таргариен?
В NLP эти задачи называются Named-entity recognition (NER), то есть выделение сущностей, и Entity Typing (ET) — классификация сущностей. С помощью NER и ET филологи подсчитывают, сколько раз появляется персонаж в тексте, строят сеть связей между героями книг и собирают все прозвища героя, а историки работают с оцифрованными текстами древних рукописей.
Какие корпуса используют для классифицируют сущности
Обычно для выделения особенностей сущности и их классификации используются тексты Википедии. Этот метод работает, если нужно разобрать текст о реальном мире. Но если мы скормим программе текст «Властелина Колец», она выдаст неполный результат, т. к. в Википедии не хватает информации о вымышленных вселенных.
Эту проблему решили исследователи из Института Макса Планка. Они создали систему ENTIFY (ENtity TYping on FIctional texts), которая может работать с художественными текстами, в том числе и фэнтези и science-fiction вселенными.
В основе ENTYFI лежит тот же принцип, что и в базовых инструментах NLP — поиск и классификация сущностей, но к корпусу текстов из Википедии добавляются размеченные тексты с платформы fandom.com (ранее Wikia). Это платформа, которая позволяет создавать отдельные тематические википедии о вселенных из книг, кино, игр и т. д. Поэтому ENTYFI смогла определить, что «Фродо Бэггинс» — «хоббит» из племени «мохноног» (harfoot).
Как работает ENTYFI
Сначала статьи Wikia объединяются в группы, в которых все статьи описывают одну и ту же вселенную — Властелин колец, Гарри Поттер, Марвел и др. Затем программа ранжирует массив «каноничных вселенных» по количеству совпадений в статьях Wikia об одной вселенной и анализируемом тексте и с помощью нейросети LSTM выделяются сущности. Дальше программа ищет найденные в тексте сущности в корпусах Wikia и Википедии.
Одновременно с этими процессами проходят еще два: авторы ENTYFI называют их Unsupervised typing и KB lookup. Unsupervised typing — это поиск класса сущности внутри того предложения, в котором сущность найдена. ET при нахождении сущности подразделяет ее на токены (слова в ней), находит их класс (метку) и добавляет к ним префиксы — элементы разметки текста.
KB lookup — метод, позволяющий вычислить класс (метку) сущности через контекст, который есть в анализируемом тексте. Сначала программа анализирует то, что вокруг сущности (не обязательно близко по тексту), выделяет контекст, формирует связи и из этих связей выделяет классы (метки) сущности. На прикрепленной схеме показано, как программа понимает, что Фродо — «cousin» Бильбо и его наследник.
Информация консолидируется методами Inductive logic programming — Индуктивного логического программирования. Система перепроверяет метки (классы), которые она присвоила персонажам.
Сопоставляя факты, ENTYFI узнает, что Дрого Бэггинс, отец Фродо Бэггинса, ещё и троюродный брат Бильбо Бэггинса по мужской линии; а Примула Брендибак, мать Фродо Бэггинса — двоюродная сестра Бильбо Бэггинса по женской линии. Следовательно, Фродо Бэггинс — дважды племянник Бильбо Бэггинса: двоюродный по матери и троюродный по отцу. Поэтому в «борьбе» меток cousin и nephew победит последняя — потому что Фродо действительно племянник, а не кузен Бильбо.
Авторы ENTYFI выложили исходный код программы на Github.
Также есть демонстратор возможностей библиотеки SpaCy для Python.
https://sysblok.ru/philology/bjegginsy-kolca-i-saurony-kak-nauchit-kompjuter-ponimat-kto-est-kto/
Артур Хисматулин
#nlp #philology
Человек схватывает новую информацию на лету: из контекста, из интонации, из невербального общения. А как помочь компьютеру понять, что Гарри — волшебник, Гендальф — майар, а Джон Сноу — одновременно Старк и Таргариен?
В NLP эти задачи называются Named-entity recognition (NER), то есть выделение сущностей, и Entity Typing (ET) — классификация сущностей. С помощью NER и ET филологи подсчитывают, сколько раз появляется персонаж в тексте, строят сеть связей между героями книг и собирают все прозвища героя, а историки работают с оцифрованными текстами древних рукописей.
Какие корпуса используют для классифицируют сущности
Обычно для выделения особенностей сущности и их классификации используются тексты Википедии. Этот метод работает, если нужно разобрать текст о реальном мире. Но если мы скормим программе текст «Властелина Колец», она выдаст неполный результат, т. к. в Википедии не хватает информации о вымышленных вселенных.
Эту проблему решили исследователи из Института Макса Планка. Они создали систему ENTIFY (ENtity TYping on FIctional texts), которая может работать с художественными текстами, в том числе и фэнтези и science-fiction вселенными.
В основе ENTYFI лежит тот же принцип, что и в базовых инструментах NLP — поиск и классификация сущностей, но к корпусу текстов из Википедии добавляются размеченные тексты с платформы fandom.com (ранее Wikia). Это платформа, которая позволяет создавать отдельные тематические википедии о вселенных из книг, кино, игр и т. д. Поэтому ENTYFI смогла определить, что «Фродо Бэггинс» — «хоббит» из племени «мохноног» (harfoot).
Как работает ENTYFI
Сначала статьи Wikia объединяются в группы, в которых все статьи описывают одну и ту же вселенную — Властелин колец, Гарри Поттер, Марвел и др. Затем программа ранжирует массив «каноничных вселенных» по количеству совпадений в статьях Wikia об одной вселенной и анализируемом тексте и с помощью нейросети LSTM выделяются сущности. Дальше программа ищет найденные в тексте сущности в корпусах Wikia и Википедии.
Одновременно с этими процессами проходят еще два: авторы ENTYFI называют их Unsupervised typing и KB lookup. Unsupervised typing — это поиск класса сущности внутри того предложения, в котором сущность найдена. ET при нахождении сущности подразделяет ее на токены (слова в ней), находит их класс (метку) и добавляет к ним префиксы — элементы разметки текста.
KB lookup — метод, позволяющий вычислить класс (метку) сущности через контекст, который есть в анализируемом тексте. Сначала программа анализирует то, что вокруг сущности (не обязательно близко по тексту), выделяет контекст, формирует связи и из этих связей выделяет классы (метки) сущности. На прикрепленной схеме показано, как программа понимает, что Фродо — «cousin» Бильбо и его наследник.
Информация консолидируется методами Inductive logic programming — Индуктивного логического программирования. Система перепроверяет метки (классы), которые она присвоила персонажам.
Сопоставляя факты, ENTYFI узнает, что Дрого Бэггинс, отец Фродо Бэггинса, ещё и троюродный брат Бильбо Бэггинса по мужской линии; а Примула Брендибак, мать Фродо Бэггинса — двоюродная сестра Бильбо Бэггинса по женской линии. Следовательно, Фродо Бэггинс — дважды племянник Бильбо Бэггинса: двоюродный по матери и троюродный по отцу. Поэтому в «борьбе» меток cousin и nephew победит последняя — потому что Фродо действительно племянник, а не кузен Бильбо.
Авторы ENTYFI выложили исходный код программы на Github.
Также есть демонстратор возможностей библиотеки SpaCy для Python.
https://sysblok.ru/philology/bjegginsy-kolca-i-saurony-kak-nauchit-kompjuter-ponimat-kto-est-kto/
Артур Хисматулин
{kind=link}
Распределение субсидий: кому помогает государство
#opendata
С конца 2019 года российские власти публикуют список топ-20 крупнейших государственных субсидий. Их получатели — РЖД, Сбербанк, Федеральная кадастровая палата, телеканал Russia Today и другие организации и госструктуры. «Системный Блокъ» изучил этот список и визуализировал для вас, кто, откуда и сколько миллиардов получил.
Самая крупная субсидия в 2020 году досталась Сбербанку. Ее размер 104,38 млрд рублей. В постановлении правительства сообщается, что эти деньги призваны помочь средним и малым предприятиям, которые сильнее всего пострадали от коронавируса.
Некоторые субсидии рассчитываются сразу на несколько лет. Так, в течение трех лет фонду Президентских грантов будет выделено более 27 млрд рублей. Назначение субсидии — на проекты, развивающие гражданское общество. А субсидия в 15 млрд рублей будет выдана Государственной автоматизированной системе РФ «Правосудие» на выполнение государственного задания. Субсидия рассчитана на четыре года, в этом году уже выданы более 5 млрд рублей.
Каждый год Управление по делам президента выделяет субсидии Специальному летному отряду «Россия», который занимается обслуживанием самолетов первых лиц государства и глав ведомств. Несмотря на вопросы о неэффективном расходовании бюджетных средств, которые освещала Счетная палата России, расходы на деятельность отряда только увеличиваются и в этом году почти достигли 17,5 млрд рублей. Годом ранее отряду было выделено 14,65 млрд рублей.
В ноябре прошлого года Счетная палата России также запустила портал «Госрасходы». На этом портале доступен рейтинг «20 крупнейших субсидий за 2020 год». Кроме обзора субсидий в проекте агрегируются данные о государственных финансах из разных источников и формулируются профили национальных проектов. Наборы данных можно скачать в машиночитаемых форматах для последующего анализа, а также доступен открытый API.
https://sysblok.ru/otkrytye-dannye/kak-raspredeljajutsja-krupnye-gosudarstvennye-subsidii/
Павел Лебедев
#opendata
С конца 2019 года российские власти публикуют список топ-20 крупнейших государственных субсидий. Их получатели — РЖД, Сбербанк, Федеральная кадастровая палата, телеканал Russia Today и другие организации и госструктуры. «Системный Блокъ» изучил этот список и визуализировал для вас, кто, откуда и сколько миллиардов получил.
Самая крупная субсидия в 2020 году досталась Сбербанку. Ее размер 104,38 млрд рублей. В постановлении правительства сообщается, что эти деньги призваны помочь средним и малым предприятиям, которые сильнее всего пострадали от коронавируса.
Некоторые субсидии рассчитываются сразу на несколько лет. Так, в течение трех лет фонду Президентских грантов будет выделено более 27 млрд рублей. Назначение субсидии — на проекты, развивающие гражданское общество. А субсидия в 15 млрд рублей будет выдана Государственной автоматизированной системе РФ «Правосудие» на выполнение государственного задания. Субсидия рассчитана на четыре года, в этом году уже выданы более 5 млрд рублей.
Каждый год Управление по делам президента выделяет субсидии Специальному летному отряду «Россия», который занимается обслуживанием самолетов первых лиц государства и глав ведомств. Несмотря на вопросы о неэффективном расходовании бюджетных средств, которые освещала Счетная палата России, расходы на деятельность отряда только увеличиваются и в этом году почти достигли 17,5 млрд рублей. Годом ранее отряду было выделено 14,65 млрд рублей.
В ноябре прошлого года Счетная палата России также запустила портал «Госрасходы». На этом портале доступен рейтинг «20 крупнейших субсидий за 2020 год». Кроме обзора субсидий в проекте агрегируются данные о государственных финансах из разных источников и формулируются профили национальных проектов. Наборы данных можно скачать в машиночитаемых форматах для последующего анализа, а также доступен открытый API.
https://sysblok.ru/otkrytye-dannye/kak-raspredeljajutsja-krupnye-gosudarstvennye-subsidii/
Павел Лебедев
{kind=link}
Технологии Big Data в индустрии моды
#arts
В модной индустрии большие данные обычно используются в маркетинговых и аналитических целях. А информационный дизайнер Джорджия Лупи на основе больших данных создает принты для одежды. Она считает, что так она придает сырым данным большую человечность.
«Будучи людьми, мы не способны увидеть в сырых данных на листах Excel паттерны человеческого поведения, — рассказала Лупи Vogue. — Только через дизайн и визуализацию данных можно получить доступ к этим знаниям». Также Лупи выступила на TedTalks, посмотреть выступление.
Совместно с брендом & Other Stories в 2019 году Лупи выпустила коллекцию одежды. Данные для принтов она собрала из биографий трех женщин-ученых — Ады Лавлейс, Рэйчел Карсон и Мэй Джемисон.
Ада Лавлейс
Ада Лавлейс знаменита тем, что в середине XIX века она описала первую в истории компьютерную программу. В примечании к своей научной статье об устройстве механической вычислительной машины она рассказала, как ее можно использовать для вычисления последовательности Фибоначчи. Это и была первая попытка запрограммировать машину для вычисления сложных математических задач.
Фрагменты алгоритма Лавлейс представлены в коллекции Лупи серией ярких разноцветных штрихов. Ниже прикрепляем фотографию готовой одежды с этими принтами.
Рэйчел Карсон
Рэйчел Карсон — биолог, защитница окружающей среды и автор нескольких книг. Для серии принтов о Рэйчел Карсон дизайнер использовала данные из ее книги «Безмолвная весна»: количество слов и символов в книге, типы знаков препинания. Также Лупи собрала информацию о различных видах растений, о которых писала Карсон, и ее исследованиях антропогенного изменения климата.
Мэй Джемисон
Мэй Джемисон — первая темнокожая женщина в космосе. В 1992 году она отправилась на орбиту во время миссии STS-47. Лупи визуализировала дни, проведенные Джемисон в космосе, ее восприятие других людей на станции и проведенные научные эксперименты на орбите.
Посмотреть всю коллекцию
https://sysblok.ru/arts/big-data-modnaja-skazka-o-chelovecheskih-zhiznjah/
Даша Джиоева
#arts
В модной индустрии большие данные обычно используются в маркетинговых и аналитических целях. А информационный дизайнер Джорджия Лупи на основе больших данных создает принты для одежды. Она считает, что так она придает сырым данным большую человечность.
«Будучи людьми, мы не способны увидеть в сырых данных на листах Excel паттерны человеческого поведения, — рассказала Лупи Vogue. — Только через дизайн и визуализацию данных можно получить доступ к этим знаниям». Также Лупи выступила на TedTalks, посмотреть выступление.
Совместно с брендом & Other Stories в 2019 году Лупи выпустила коллекцию одежды. Данные для принтов она собрала из биографий трех женщин-ученых — Ады Лавлейс, Рэйчел Карсон и Мэй Джемисон.
Ада Лавлейс
Ада Лавлейс знаменита тем, что в середине XIX века она описала первую в истории компьютерную программу. В примечании к своей научной статье об устройстве механической вычислительной машины она рассказала, как ее можно использовать для вычисления последовательности Фибоначчи. Это и была первая попытка запрограммировать машину для вычисления сложных математических задач.
Фрагменты алгоритма Лавлейс представлены в коллекции Лупи серией ярких разноцветных штрихов. Ниже прикрепляем фотографию готовой одежды с этими принтами.
Рэйчел Карсон
Рэйчел Карсон — биолог, защитница окружающей среды и автор нескольких книг. Для серии принтов о Рэйчел Карсон дизайнер использовала данные из ее книги «Безмолвная весна»: количество слов и символов в книге, типы знаков препинания. Также Лупи собрала информацию о различных видах растений, о которых писала Карсон, и ее исследованиях антропогенного изменения климата.
Мэй Джемисон
Мэй Джемисон — первая темнокожая женщина в космосе. В 1992 году она отправилась на орбиту во время миссии STS-47. Лупи визуализировала дни, проведенные Джемисон в космосе, ее восприятие других людей на станции и проведенные научные эксперименты на орбите.
Посмотреть всю коллекцию
https://sysblok.ru/arts/big-data-modnaja-skazka-o-chelovecheskih-zhiznjah/
Даша Джиоева
{kind=link}
Цифровая эпиграфика: удаленный доступ к архивам эпиграфических памятников
#digitalheritage
Эпиграфика изучает содержание и формы надписей на твёрдых носителях: камне, керамике, металлических поверхностях. Классические методы эпиграфики — переписывание текста, зарисовка или эстампирование (создание оттиска) — часто приводят к неточностям и ошибкам.
С изобретением цифровой фотографии и 3D-моделирования документирование эпиграфического памятников изменилось. Рассказываем, как это делают сегодня и какие есть проекты в области цифровой эпиграфики.
Корпус древних надписей Северного Причерноморья
Для этого проекта международная группа эпиграфистов и технических специалистов собрала многочисленный древний эпиграфический материал Северопонтийского региона. Исследователи фотографировали эпиграфические памятники и расшифровывали их.
Корпус включает в себя надписи на камне, керамике, металле и кости. Сами надписи сделаны на латинском и греческом языках с третьей четверти 17-го века до н. э. и до падения Константинополя в 1453 г. н. э.
В корпусе собрано около 5000 текстов разной длины. Можно искать нужный текст по дате, происхождению, типу, критериям датировки, именам, материалу и институтам хранения эпиграфических памятников Северопонтийского региона.
«Свод русских надписей»
Для этого проекта исследователи собрали эпиграфические памятники XV–XVII веков и, в меньшей степени, XI–XIV веков. В «Своде» содержатся надписи, выполненные на территории Руси, не только на русском и древнерусском языках, но и латинском, греческом, итальянском и голландском. Всего в «Своде» задокументировано 1332 памятника.
В настоящее время база данных «Свода русских надписей» находится в разработке, а на сайте проекта демонстрируются лишь отдельные примеры. Но в скором времени исследователи смогут просматривать трехмерные модели и растровые изображения эпиграфических памятников, осуществлять сортировку и фильтрацию надписей по нескольким критериям, а также полнотекстовый поиск.
Исследователи «Свода» пришли к выводу, что самым эффективным методом формирования трехмерной модели памятника является фотограмметрическая обработка фотографий, сделанных с помощью цифрового фотоаппарата с полноразмерной матрицей высокого разрешения. Благодаря цифровым трехмерным моделям стало возможным воспроизведение объектов любого размера, корректное воспроизведение цвета, сложных поверхностей.
Ogham in 3D
Цель проекта Ogham in 3D — документирование и описание всех памятников огамического письма на территории Ирландии. Исследовательская группа задокументировала 131 объект из 400 известных, дала их описания, создала интерактивную карту и объединила все надписи в единую базу данных. Памятники сканировали с использованием «структурированного света».
Камни огама — важное культурное наследие Ирландии. На этих перпендикулярных камнях нанесены надписи на уникальном древнем алфавите кельтов. На камнях содержатся имена выдающихся людей, иногда — племенная принадлежность или географический район. Эти надписи представляют собой самую раннюю зарегистрированную форму ирландского языка.
На сайте проекта «Ogham in 3D» все надписи хранятся в одном разделе, сгруппированы по алфавиту, каждая надпись имеет описание, отмечена на интерактивной карте.
https://sysblok.ru/digital-heritage/steret-nelzja-ocifrovat-jepigrafika-otkryvaet-vtoroe-dyhanie/
Этери Джафарова
#digitalheritage
Эпиграфика изучает содержание и формы надписей на твёрдых носителях: камне, керамике, металлических поверхностях. Классические методы эпиграфики — переписывание текста, зарисовка или эстампирование (создание оттиска) — часто приводят к неточностям и ошибкам.
С изобретением цифровой фотографии и 3D-моделирования документирование эпиграфического памятников изменилось. Рассказываем, как это делают сегодня и какие есть проекты в области цифровой эпиграфики.
Корпус древних надписей Северного Причерноморья
Для этого проекта международная группа эпиграфистов и технических специалистов собрала многочисленный древний эпиграфический материал Северопонтийского региона. Исследователи фотографировали эпиграфические памятники и расшифровывали их.
Корпус включает в себя надписи на камне, керамике, металле и кости. Сами надписи сделаны на латинском и греческом языках с третьей четверти 17-го века до н. э. и до падения Константинополя в 1453 г. н. э.
В корпусе собрано около 5000 текстов разной длины. Можно искать нужный текст по дате, происхождению, типу, критериям датировки, именам, материалу и институтам хранения эпиграфических памятников Северопонтийского региона.
«Свод русских надписей»
Для этого проекта исследователи собрали эпиграфические памятники XV–XVII веков и, в меньшей степени, XI–XIV веков. В «Своде» содержатся надписи, выполненные на территории Руси, не только на русском и древнерусском языках, но и латинском, греческом, итальянском и голландском. Всего в «Своде» задокументировано 1332 памятника.
В настоящее время база данных «Свода русских надписей» находится в разработке, а на сайте проекта демонстрируются лишь отдельные примеры. Но в скором времени исследователи смогут просматривать трехмерные модели и растровые изображения эпиграфических памятников, осуществлять сортировку и фильтрацию надписей по нескольким критериям, а также полнотекстовый поиск.
Исследователи «Свода» пришли к выводу, что самым эффективным методом формирования трехмерной модели памятника является фотограмметрическая обработка фотографий, сделанных с помощью цифрового фотоаппарата с полноразмерной матрицей высокого разрешения. Благодаря цифровым трехмерным моделям стало возможным воспроизведение объектов любого размера, корректное воспроизведение цвета, сложных поверхностей.
Ogham in 3D
Цель проекта Ogham in 3D — документирование и описание всех памятников огамического письма на территории Ирландии. Исследовательская группа задокументировала 131 объект из 400 известных, дала их описания, создала интерактивную карту и объединила все надписи в единую базу данных. Памятники сканировали с использованием «структурированного света».
Камни огама — важное культурное наследие Ирландии. На этих перпендикулярных камнях нанесены надписи на уникальном древнем алфавите кельтов. На камнях содержатся имена выдающихся людей, иногда — племенная принадлежность или географический район. Эти надписи представляют собой самую раннюю зарегистрированную форму ирландского языка.
На сайте проекта «Ogham in 3D» все надписи хранятся в одном разделе, сгруппированы по алфавиту, каждая надпись имеет описание, отмечена на интерактивной карте.
https://sysblok.ru/digital-heritage/steret-nelzja-ocifrovat-jepigrafika-otkryvaet-vtoroe-dyhanie/
Этери Джафарова
{kind=link}
Как нейросети генерируют ложные варианты для тестов
#nlp
Составлять тесты сложно: кроме правильного ответа надо придумать и неправильные. Причем придумать их с умом: чтобы варианты не были слишком очевидно неверными — но и не оказались бы при этом подходящей альтернативой верному варианту.
В англоязычной литературе для неправильных вариантов ответа в тестах существует специальное название — дистракторы (distractors, букв. «отвлекатели»). Подбор хороших дистракторов при разработке тестов очень важен. Сейчас ученые пробуют автоматически генерировать дистракторы с помощью нейросетей.
Если у нас есть хорошие примеры дистракторов, сделанных людьми, мы можем включить их в обучающую выборку и решать задачу обучения нейросети с учителем (supervised learning). А если таких примеров нет, мы будем обучать нейросеть без учителя (unsupervised learning).
Когда и как применяют обучение с учителем
Задача порождения дистракторов сводится к подбору списка слов-кандидатов и обучению ранжированию. Вопросы нужного формата обычно собираются из оцифрованных копий учебников или интернет-ресурсов.
Алгоритм должен присваивать наиболее высокие ранги словам или предложениям, которые являются дистракторами для данного вопроса, то есть помечены как дистракторы в тестовой выборке.
Получив на вход текст вопроса и текст «кандидата в дистракторы», классификатор должен «решить», насколько хорошо данный ответ может сойти за правильный в контексте данного вопроса, выдав определенную вероятность в виде числа. Подтверждением успешного обучения является получение настоящими дистракторами большего, чем у остальных кандидатов, рейтинга.
Когда применяют обучение без учителя
Когда готовый пул вопросов нужного формата отсутствует, применяют unsupervised-подход. Такая ситуация возникает, когда сами вопросы генерируются из определенного корпуса текстов. В таком случае к ним нет готового обучающего набора отвлекающих неправильных ответов.
Пример такого варианта — gap-filling questions. Это вопросы, которые получаются, если заменить какое-либо слова или словосочетание в корпусном предложении на пропуск. Задача проходящего тест — догадаться, какая единица должна быть на месте пропуска.
Как проводят обучение без учителя (на примере корпуса ошибок REALEC)
Для языкового тестирования gap-filling questions можно получить, используя специальный корпус ошибок. Так называют корпуса, которые содержат тексты, написанные не-носителями определенного языка. Эти тексты содержат области, размеченные как ошибки, а также их исправления.
Корпус ошибок REALEC содержит тексты на английском языке, написанные русскоязычными студентами в качестве письменных заданий-эссе. В системе LangExBank каждый тестовый вопрос — предложение корпуса REALEC, в котором область ошибки заменена на пропуск. Таким образом, правильный ответ и один неправильный ответ в исходных данных уже есть — это исправление и оригинальная область ошибки. Задача — получить ещё 2–3 неправильных варианта.
В LangExBank реализована генерация дистракторов из вопросов, полученных на основе лексических ошибок и ошибок на употребление предлогов. Для подбора дистракторов используется классификатор в виде рекуррентной нейронной сети. Нейросеть должна заполнить пропуск, но в обучение модели внесена принципиальная поправка: если модель предсказывала правильный вариант (т. е. слово-исправление), штраф для неё увеличивался в 2 раза.
Так как в датасете изначально не содержатся дистракторы, качество сгенерированных вариантов можно проверить только вручную. Результаты пока далеки от совершенства, поэтому платформа поддерживает редактирование полученных из корпуса тестов.
Устройство нейросети и примеры ее работы — в нашей статье: https://sysblok.ru/linguistics/zaputat-nelzja-ugadat-kak-nejroseti-generirujut-lozhnye-primanki-dlja-testov/
Никита Логин
#nlp
Составлять тесты сложно: кроме правильного ответа надо придумать и неправильные. Причем придумать их с умом: чтобы варианты не были слишком очевидно неверными — но и не оказались бы при этом подходящей альтернативой верному варианту.
В англоязычной литературе для неправильных вариантов ответа в тестах существует специальное название — дистракторы (distractors, букв. «отвлекатели»). Подбор хороших дистракторов при разработке тестов очень важен. Сейчас ученые пробуют автоматически генерировать дистракторы с помощью нейросетей.
Если у нас есть хорошие примеры дистракторов, сделанных людьми, мы можем включить их в обучающую выборку и решать задачу обучения нейросети с учителем (supervised learning). А если таких примеров нет, мы будем обучать нейросеть без учителя (unsupervised learning).
Когда и как применяют обучение с учителем
Задача порождения дистракторов сводится к подбору списка слов-кандидатов и обучению ранжированию. Вопросы нужного формата обычно собираются из оцифрованных копий учебников или интернет-ресурсов.
Алгоритм должен присваивать наиболее высокие ранги словам или предложениям, которые являются дистракторами для данного вопроса, то есть помечены как дистракторы в тестовой выборке.
Получив на вход текст вопроса и текст «кандидата в дистракторы», классификатор должен «решить», насколько хорошо данный ответ может сойти за правильный в контексте данного вопроса, выдав определенную вероятность в виде числа. Подтверждением успешного обучения является получение настоящими дистракторами большего, чем у остальных кандидатов, рейтинга.
Когда применяют обучение без учителя
Когда готовый пул вопросов нужного формата отсутствует, применяют unsupervised-подход. Такая ситуация возникает, когда сами вопросы генерируются из определенного корпуса текстов. В таком случае к ним нет готового обучающего набора отвлекающих неправильных ответов.
Пример такого варианта — gap-filling questions. Это вопросы, которые получаются, если заменить какое-либо слова или словосочетание в корпусном предложении на пропуск. Задача проходящего тест — догадаться, какая единица должна быть на месте пропуска.
Как проводят обучение без учителя (на примере корпуса ошибок REALEC)
Для языкового тестирования gap-filling questions можно получить, используя специальный корпус ошибок. Так называют корпуса, которые содержат тексты, написанные не-носителями определенного языка. Эти тексты содержат области, размеченные как ошибки, а также их исправления.
Корпус ошибок REALEC содержит тексты на английском языке, написанные русскоязычными студентами в качестве письменных заданий-эссе. В системе LangExBank каждый тестовый вопрос — предложение корпуса REALEC, в котором область ошибки заменена на пропуск. Таким образом, правильный ответ и один неправильный ответ в исходных данных уже есть — это исправление и оригинальная область ошибки. Задача — получить ещё 2–3 неправильных варианта.
В LangExBank реализована генерация дистракторов из вопросов, полученных на основе лексических ошибок и ошибок на употребление предлогов. Для подбора дистракторов используется классификатор в виде рекуррентной нейронной сети. Нейросеть должна заполнить пропуск, но в обучение модели внесена принципиальная поправка: если модель предсказывала правильный вариант (т. е. слово-исправление), штраф для неё увеличивался в 2 раза.
Так как в датасете изначально не содержатся дистракторы, качество сгенерированных вариантов можно проверить только вручную. Результаты пока далеки от совершенства, поэтому платформа поддерживает редактирование полученных из корпуса тестов.
Устройство нейросети и примеры ее работы — в нашей статье: https://sysblok.ru/linguistics/zaputat-nelzja-ugadat-kak-nejroseti-generirujut-lozhnye-primanki-dlja-testov/
Никита Логин
{kind=link}
Покажи мне свой Spotify, и я покажу тебе, кто ты
#musicology #opendata
«Spotify опоздал» — говорят одни. «Spotify — всего лишь один из многих!», — говорят другие. «Spotify неудобен» — говорят третьи. А мы говорим: «У Spotify есть открытый API — и мы идем исследовать себя!»
Мы уже писали о том, как Spotify угадывает наши предпочтения в музыке. В этой статье мы попытаемся сами проанализировать наши музыкальные предпочтения с помощью WEB API от Spotify и понять, что о нашем вкусе говорит наш плейлист.
На своих серверах Spotify хранит информацию о каждом треке. Есть данные о размерности трека, его энергичности, темпе и прочие музыкальные характеристики. С ними мы и будем работать.
Какие задачи мы будем решать
• зарегистрируемся на Spotify как разработчики,
• создадим свое приложение,
• подключим наше приложение к Spotify API,
• получим информацию о своем плейлисте,
• сформируем из данных таблицу и скачаем ее на компьютер,
• визуализируем данные в IDE — в среде разработки, в которой мы будем писать код.
Подробное решение всех задач — в нашей статье: https://sysblok.ru/musicology/pokazhi-mne-svoj-spotify-i-ja-pokazhu-tebe-kto-ty/
Артур Хисматулин
#musicology #opendata
«Spotify опоздал» — говорят одни. «Spotify — всего лишь один из многих!», — говорят другие. «Spotify неудобен» — говорят третьи. А мы говорим: «У Spotify есть открытый API — и мы идем исследовать себя!»
Мы уже писали о том, как Spotify угадывает наши предпочтения в музыке. В этой статье мы попытаемся сами проанализировать наши музыкальные предпочтения с помощью WEB API от Spotify и понять, что о нашем вкусе говорит наш плейлист.
На своих серверах Spotify хранит информацию о каждом треке. Есть данные о размерности трека, его энергичности, темпе и прочие музыкальные характеристики. С ними мы и будем работать.
Какие задачи мы будем решать
• зарегистрируемся на Spotify как разработчики,
• создадим свое приложение,
• подключим наше приложение к Spotify API,
• получим информацию о своем плейлисте,
• сформируем из данных таблицу и скачаем ее на компьютер,
• визуализируем данные в IDE — в среде разработки, в которой мы будем писать код.
Подробное решение всех задач — в нашей статье: https://sysblok.ru/musicology/pokazhi-mne-svoj-spotify-i-ja-pokazhu-tebe-kto-ty/
Артур Хисматулин
{kind=link}
Тиндер 1917 года и революция в цифре
#digitalmemory #history
Историческое знание нуждается в новых формах представления, особенно онлайн. Публичная история (public history) связывает современного человека и историю в медиапространстве, образуя активный социальный диалог. Public history предлагает digital-проекты для изучения истории в игровой форме. Самый популярный из них — цифровая реинкарнация 1917 года от команд Михаила Зыгаря и Сергея Лунёва.
Михаил Зыгарь — бывший главный редактор телеканала «Дождь», автор бестселлера «Вся кремлевская рать» и основатель креативной студии «История будущего». Три года назад, к столетию октябрьской революции, он запустил мультимедийный проект «1917. Свободная история», в котором репрезентировалась история современников 1917 года в виде странички в Facebook: адаптированные посты, трансляции и фото.
Проект «1917. Свободная история»
В проекте больше 1500 героев. У поэтессы Зинаиды Гиппиус стоит статус «Главное — не ныть. Не размазывать своих „страданий“. Подумаешь! У всякого своя боль. Вот у меня кашель, например», это ее цитата. В разделе «место работы» у архитектора Эля Лисицкого написано, что он занимает должность секретаря оргкомитета и готовит к открытию Выставку художников-евреев в Москве.
Команда провела трансляцию с первого заседания Государственной Думы, прославившуюся выступлением оппозиционера Павла Милюкова, открытие долгожданной выставки общества «Бубновый валет», осветила тайную свадьбу сестры императора Ольги. А еще на сайте можно отправить письмо чат-боту с Распутиным, зайти в Тиндер1917, узнать интимные прозвища звезд времен революции и многое другое.
Проект «1917. День за днем»
Второй проект про «сложное» прошлое — «1917. День за днем» Сергея Лунёва, историка и создателя познавательного журнала о русскоязычной цивилизации «VATNIKSTAN», — менее динамичный. Он разделен на две части — столетние архивы и статьи студентов МГУ. В «Источниках» можно найти вырезки из газеты «Вперед», «Русские Ведомости», тексты декретов, воспоминания. В «Статьях» хранятся публикации с тематикой интервью, историографии, литературоведения, политической и социальной истории и т. д.
Ученые негодуют: почему историки выступили против проекта Зыгаря
Однако многие приверженцы академической истории скептично относятся к проекту «1917. Свободная история», критикуя его за необоснованные сокращения, которые превращают факты в домыслы. По их мнению, так теряются важные причинно-следственные связи: читателя вводят в заблуждение, выдавая художественное за историческое. Например, фразы типа «Я точно зверь травленный: все загрызть хотят… Поперек горла им стою» в игре «Поговори с Распутиным» могли им и не произноситься.
Сами авторы называют «Свободную историю» инновационным сторителлингом и утверждают, что, пытаясь сделать историю общедоступной и понятной, они не подменяли исторические факты. Содержание публикаций основывается на письмах и личных дневниках.
Запустив «1917. Свободную историю» и «1917. День за днем» Зыгарь и Лунёв не воссоздали точную историческую копию России 1917 года, да и не имели такой цели. Создатели проектов посмотрели на события революции сквозь призму особого личного понимания, построенного на достоверных фактах. Теперь историки могут изучать не только минувшие события, но и их современные репрезентации, которые накладываются друг на друга, образуя новые образы прошлого в культуре.
https://sysblok.ru/digitalmemory/tinder-1917-goda-i-revoljucija-v-cifre/
Яна Олейник
#digitalmemory #history
Историческое знание нуждается в новых формах представления, особенно онлайн. Публичная история (public history) связывает современного человека и историю в медиапространстве, образуя активный социальный диалог. Public history предлагает digital-проекты для изучения истории в игровой форме. Самый популярный из них — цифровая реинкарнация 1917 года от команд Михаила Зыгаря и Сергея Лунёва.
Михаил Зыгарь — бывший главный редактор телеканала «Дождь», автор бестселлера «Вся кремлевская рать» и основатель креативной студии «История будущего». Три года назад, к столетию октябрьской революции, он запустил мультимедийный проект «1917. Свободная история», в котором репрезентировалась история современников 1917 года в виде странички в Facebook: адаптированные посты, трансляции и фото.
Проект «1917. Свободная история»
В проекте больше 1500 героев. У поэтессы Зинаиды Гиппиус стоит статус «Главное — не ныть. Не размазывать своих „страданий“. Подумаешь! У всякого своя боль. Вот у меня кашель, например», это ее цитата. В разделе «место работы» у архитектора Эля Лисицкого написано, что он занимает должность секретаря оргкомитета и готовит к открытию Выставку художников-евреев в Москве.
Команда провела трансляцию с первого заседания Государственной Думы, прославившуюся выступлением оппозиционера Павла Милюкова, открытие долгожданной выставки общества «Бубновый валет», осветила тайную свадьбу сестры императора Ольги. А еще на сайте можно отправить письмо чат-боту с Распутиным, зайти в Тиндер1917, узнать интимные прозвища звезд времен революции и многое другое.
Проект «1917. День за днем»
Второй проект про «сложное» прошлое — «1917. День за днем» Сергея Лунёва, историка и создателя познавательного журнала о русскоязычной цивилизации «VATNIKSTAN», — менее динамичный. Он разделен на две части — столетние архивы и статьи студентов МГУ. В «Источниках» можно найти вырезки из газеты «Вперед», «Русские Ведомости», тексты декретов, воспоминания. В «Статьях» хранятся публикации с тематикой интервью, историографии, литературоведения, политической и социальной истории и т. д.
Ученые негодуют: почему историки выступили против проекта Зыгаря
Однако многие приверженцы академической истории скептично относятся к проекту «1917. Свободная история», критикуя его за необоснованные сокращения, которые превращают факты в домыслы. По их мнению, так теряются важные причинно-следственные связи: читателя вводят в заблуждение, выдавая художественное за историческое. Например, фразы типа «Я точно зверь травленный: все загрызть хотят… Поперек горла им стою» в игре «Поговори с Распутиным» могли им и не произноситься.
Сами авторы называют «Свободную историю» инновационным сторителлингом и утверждают, что, пытаясь сделать историю общедоступной и понятной, они не подменяли исторические факты. Содержание публикаций основывается на письмах и личных дневниках.
Запустив «1917. Свободную историю» и «1917. День за днем» Зыгарь и Лунёв не воссоздали точную историческую копию России 1917 года, да и не имели такой цели. Создатели проектов посмотрели на события революции сквозь призму особого личного понимания, построенного на достоверных фактах. Теперь историки могут изучать не только минувшие события, но и их современные репрезентации, которые накладываются друг на друга, образуя новые образы прошлого в культуре.
https://sysblok.ru/digitalmemory/tinder-1917-goda-i-revoljucija-v-cifre/
Яна Олейник
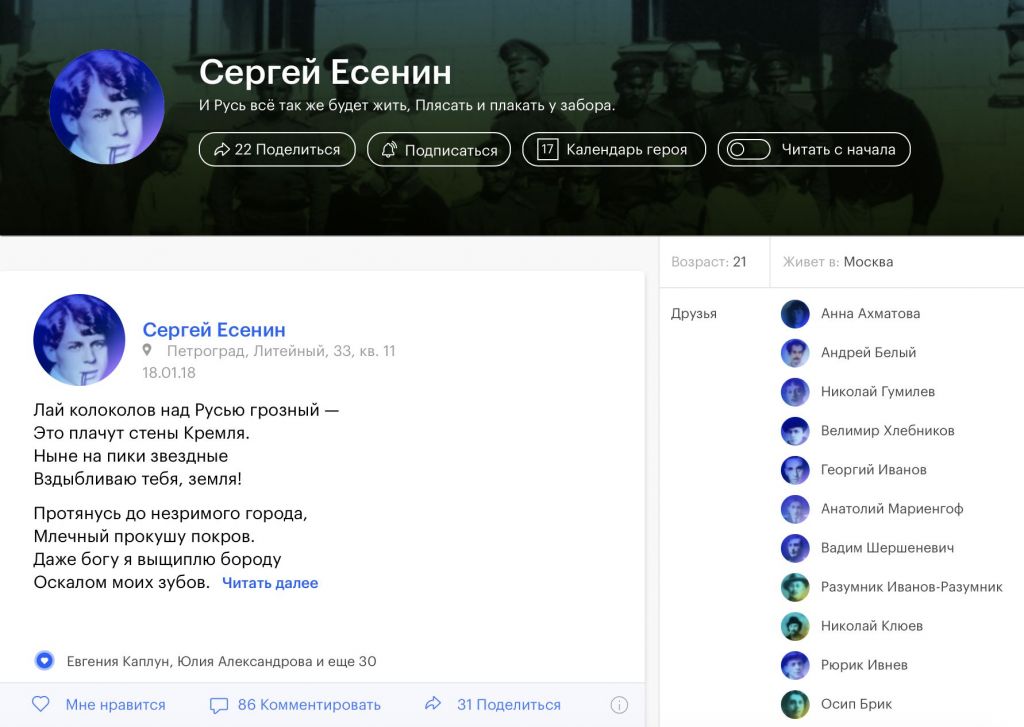{kind=link}
Тест Тьюринга для переводчиков: вычисли машину
#test
В этом тесте мы предлагаем вам попробовать отличить человеческий перевод — от сделанного компьютером. И заодно покажем, что у всех переводчиков, даже машинных, есть свой стиль. А в качестве примеров возьмем фразы из известных фильмов.
Тяжело выбрать, каким переводчиком лучше воспользоваться — ведь «жизнь как коробка шоколадных конфет: никогда не знаешь, какая начинка тебе попадётся». Узнали цитату? Интересно, как бы она звучала, если бы переводчики Форреста Гампа воспользовались Google. Translate или Яндекс. А главное, смогли бы вы понять, что при переводе использовали машину?
Мы подобрали для вас еще несколько цитат — и предлагаем угадать, какой из переводов сделан человеком.
https://sysblok.ru/test/test-tjuringa-dlja-perevodchikov-vychisli-mashinu/
#test
В этом тесте мы предлагаем вам попробовать отличить человеческий перевод — от сделанного компьютером. И заодно покажем, что у всех переводчиков, даже машинных, есть свой стиль. А в качестве примеров возьмем фразы из известных фильмов.
Тяжело выбрать, каким переводчиком лучше воспользоваться — ведь «жизнь как коробка шоколадных конфет: никогда не знаешь, какая начинка тебе попадётся». Узнали цитату? Интересно, как бы она звучала, если бы переводчики Форреста Гампа воспользовались Google. Translate или Яндекс. А главное, смогли бы вы понять, что при переводе использовали машину?
Мы подобрали для вас еще несколько цитат — и предлагаем угадать, какой из переводов сделан человеком.
https://sysblok.ru/test/test-tjuringa-dlja-perevodchikov-vychisli-mashinu/
{kind=link}