
Первого мая режиссер и волшебник Уэс Андерсон отметил пятидесятилетний юбилей. Узнать фильм Уэса Андерсона несложно: идеально симметричные кадры, теплая палитра, удивительные детали, странные костюмы… Не кино, а иллюстрированная книга — даже главы есть. Этот «кукольный» сеттинг позволяет без страха поднимать болезненные вопросы: о семейных проблемах, поиске места в жизни, одиночестве, смерти.
К юбилею режиссера мы перечитали фильмографию Уэса Андерсона и cделали визуализацию субтитров полнометражных лент. Так, как ее сделал бы Уэс, конечно!
https://sysblok.ru/visual/o-chem-govorjat-geroi-filmov-ujesa-andersona/
К юбилею режиссера мы перечитали фильмографию Уэса Андерсона и cделали визуализацию субтитров полнометражных лент. Так, как ее сделал бы Уэс, конечно!
https://sysblok.ru/visual/o-chem-govorjat-geroi-filmov-ujesa-andersona/
Системный Блокъ
О чем говорят герои фильмов Уэса Андерсона? - Системный Блокъ
Первого мая режиссер и волшебник Уэс Андерсон отмечает пятидесятилетний юбилей. Перечитываем его фильмографию и делаем визуализацию. Так, как ее сделал бы Уэс, конечно!
Всю весну кипит битва вокруг статьи The Computational Case against Computational Literary Studies. ⚡️⚡️⚡️ Автор статьи всерьез замахнулась на «закрытие» цифровой филологии как научного направления. Отдельно в этой статье досталось исследователям гендера в литературе ♀♂📚. Мол компьютерные литературоведы так любят гендер только потому, что он дает им легкое и однозначное разделение на две понятные категории, которые потом можно статистически сравнивать.
Нам кажется, что автор передергивает. Цифровые исследования репрезентации мужчин и женщин в художественных текстах — не дань моде или удобству. Они могут дать объективные сведения не только о том, как устроена литература, но и о том, как в культуре отражены гендерные стереотипы и общественные процессы. А главное — как это все эволюционирует и куда движется.
Пример такого исследования — работа о трансформации гендера в англоязычной литературе от Теда Андервуда, Дэвида Баммана и Сабрины Ли. На материале 104 тысяч книг они показывают, например, как изображение гендера становится все менее стереотипным в описаниях: в XIX веке алгоритмы машинного обучения легко справляются с разбиением персонажей на мужчин и женщин по связанным с ними прилагательным, в первой половине XX века это удается хуже, а ближе к 2000 годам — полный провал.
С другой стороны, доля внимания, которые уделяют авторы (особенно авторы-мужчины!) женским персонажам, по-прежнему несправедливо мала. Даже в XXI веке — что-то около 30%.
Подробности по ссылке:
https://sysblok.ru/philology/gendernye-trudnosti-anglijskoj-literatury/
Нам кажется, что автор передергивает. Цифровые исследования репрезентации мужчин и женщин в художественных текстах — не дань моде или удобству. Они могут дать объективные сведения не только о том, как устроена литература, но и о том, как в культуре отражены гендерные стереотипы и общественные процессы. А главное — как это все эволюционирует и куда движется.
Пример такого исследования — работа о трансформации гендера в англоязычной литературе от Теда Андервуда, Дэвида Баммана и Сабрины Ли. На материале 104 тысяч книг они показывают, например, как изображение гендера становится все менее стереотипным в описаниях: в XIX веке алгоритмы машинного обучения легко справляются с разбиением персонажей на мужчин и женщин по связанным с ними прилагательным, в первой половине XX века это удается хуже, а ближе к 2000 годам — полный провал.
С другой стороны, доля внимания, которые уделяют авторы (особенно авторы-мужчины!) женским персонажам, по-прежнему несправедливо мала. Даже в XXI веке — что-то около 30%.
Подробности по ссылке:
https://sysblok.ru/philology/gendernye-trudnosti-anglijskoj-literatury/
Системный Блокъ
Гендерные трудности английской литературы - Системный Блокъ
За двести пятьдесят лет положение женщин в обществе изменилось, и эти изменения затронули не только реальную жизнь, но и книжное пространство. Как изменялось место женщины в литературе как автора и персонажа? Возможно ли определить пол героя по его описанию?…
Вчера умер Сергей Доренко — ведущий, «телекиллер» и толстый тролль. В 1999 году Доренко помог вывести Путина в президенты, поливая грязью Лужкова и Примакова. А в 2000-м неожиданно сыграл в камикадзе, разнеся в пух и прах самого Путина прямо в прайм-тайме Первого канала — за катастрофу «Курска».
Доренко — противоречивая фигура в истории российской журналистики. Он часто менял убеждения и, кажется, никогда не был на 100% серьезен. Но в одном Доренко не откажешь: это был человек смелый до безбашенности. Умел переть напролом и рубить сплеча, не подстилая соломки — и этим отличался от 95% журналистов России. Смерть ему тоже досталась под стать характеру: разрыв аорты за рулем мотоцикла. Настоящий «Беспечный ездок» русских медиа.
А мы решили еще раз вспомнить знаковые эфиры Сергея Доренко — те самые, которые принесли ему противоречивую славу телекиллера. Для этого мы взяли расшифровки программ и визуализировали их в виде облаков частотностей слов.
Вот репортаж про Примакова и его тазобедренный сустав, где самое частотное слово — «операция». Этим выпуском Доренко уничтожил одного из политических тяжеловесов 90-х. До выпуска Примаков выглядел весомым кандидатом в преемники Ельцина. После — беспомощным и бесперспективным стариком, этаким Брежневым 3.0.
Вот выпуск про Лужкова, его жену Елену Батурину, ее братьев и фирму Мабетекс. Пятно на репутации «старика Батурина» с тех пор так и не отмылось, не позволив ему мечтать о чем-то большем, чем кресло московского мэра.
Ну и, наконец, выпуск про гибель подлодки «Курск». Ключевые слова катастрофы: «Лодка», «Экипаж», «Курск» — и те, кого призвал за нее к ответу Доренко: «президент», «власть», «путин». Власть и Путин журналиста не простили — это был его последний телеэфир на федеральном ТВ.
И, конечно, фоном идет российская история рубежа 90-х — 2000-х. Скандал вокруг Скуратова, убийства и Чечня, Чечня, Чечня…
Доренко — противоречивая фигура в истории российской журналистики. Он часто менял убеждения и, кажется, никогда не был на 100% серьезен. Но в одном Доренко не откажешь: это был человек смелый до безбашенности. Умел переть напролом и рубить сплеча, не подстилая соломки — и этим отличался от 95% журналистов России. Смерть ему тоже досталась под стать характеру: разрыв аорты за рулем мотоцикла. Настоящий «Беспечный ездок» русских медиа.
А мы решили еще раз вспомнить знаковые эфиры Сергея Доренко — те самые, которые принесли ему противоречивую славу телекиллера. Для этого мы взяли расшифровки программ и визуализировали их в виде облаков частотностей слов.
Вот репортаж про Примакова и его тазобедренный сустав, где самое частотное слово — «операция». Этим выпуском Доренко уничтожил одного из политических тяжеловесов 90-х. До выпуска Примаков выглядел весомым кандидатом в преемники Ельцина. После — беспомощным и бесперспективным стариком, этаким Брежневым 3.0.
Вот выпуск про Лужкова, его жену Елену Батурину, ее братьев и фирму Мабетекс. Пятно на репутации «старика Батурина» с тех пор так и не отмылось, не позволив ему мечтать о чем-то большем, чем кресло московского мэра.
Ну и, наконец, выпуск про гибель подлодки «Курск». Ключевые слова катастрофы: «Лодка», «Экипаж», «Курск» — и те, кого призвал за нее к ответу Доренко: «президент», «власть», «путин». Власть и Путин журналиста не простили — это был его последний телеэфир на федеральном ТВ.
И, конечно, фоном идет российская история рубежа 90-х — 2000-х. Скандал вокруг Скуратова, убийства и Чечня, Чечня, Чечня…
{kind=link}
Как оцифровать азулежу? Цифровая карта португальских изразцов
В солнечной и жаркой Португалии на стенах домов, дворцов, церквей и, в общем-то, почти чего угодно вы встретите не только штукатурку и бетон, но и национальное достояние каждого португальца — изразцы азулежу. Техника росписи маленьких керамических квадратиков была изначально принесена на Пиренейский полуостров во времена арабских завоеваний и осталась здесь на долгие годы. Пика распространенности азулежу достигли с началом массового промышленного производства в середине XIX века. Плитки перестали быть предметом роскоши, и ими начали украшать фасады домов.
Проект Mapping Our Tiles ставит своей целью собрать и классифицировать как можно больше (желательно, все) рисунки таких азулежу, а также места, где они встречаются. Дело в том, что большинство изразцов, украшающих церкви и дворцы, уже описаны и изучены искусствоведами и учеными, а домами обычных граждан никто не занимался.
На страничке проекта все предельно просто — вы можете выбрать любой понравившийся вам рисунок и посмотреть на карте, в каких городах добровольцы проекта заметили такой изразец — или его вариацию.
Авторы Mapping Out Tiles приглашают всех и каждого помочь им с наполнением базы, прислав фотографию какого-либо рисунка и адрес, где его можно найти. Это можно сделать как по почте, так и просто поставив хэштег в Инстаграме. Так что оказавшись в Португалии, берите в руки телефон и используйте Инстаграм с пользой! А пока можно просто насладиться красотой португальского изразца — Mapping Our Tiles
Нелли Бурцева
В солнечной и жаркой Португалии на стенах домов, дворцов, церквей и, в общем-то, почти чего угодно вы встретите не только штукатурку и бетон, но и национальное достояние каждого португальца — изразцы азулежу. Техника росписи маленьких керамических квадратиков была изначально принесена на Пиренейский полуостров во времена арабских завоеваний и осталась здесь на долгие годы. Пика распространенности азулежу достигли с началом массового промышленного производства в середине XIX века. Плитки перестали быть предметом роскоши, и ими начали украшать фасады домов.
Проект Mapping Our Tiles ставит своей целью собрать и классифицировать как можно больше (желательно, все) рисунки таких азулежу, а также места, где они встречаются. Дело в том, что большинство изразцов, украшающих церкви и дворцы, уже описаны и изучены искусствоведами и учеными, а домами обычных граждан никто не занимался.
На страничке проекта все предельно просто — вы можете выбрать любой понравившийся вам рисунок и посмотреть на карте, в каких городах добровольцы проекта заметили такой изразец — или его вариацию.
Авторы Mapping Out Tiles приглашают всех и каждого помочь им с наполнением базы, прислав фотографию какого-либо рисунка и адрес, где его можно найти. Это можно сделать как по почте, так и просто поставив хэштег в Инстаграме. Так что оказавшись в Португалии, берите в руки телефон и используйте Инстаграм с пользой! А пока можно просто насладиться красотой португальского изразца — Mapping Our Tiles
Нелли Бурцева
{kind=link}
Как машинный перевод оценивает… машина?
Оценивать машинный перевод — сложно. Для такой оценки человек должен сопоставить адекватность, точность и естественность перевода, а это занимает много времени (недели и даже месяцы) и стоит довольно дорого. Для разработчиков систем МП это проблема — ведь им нужно ежедневно отслеживать изменения в системе и очень быстро отсеивать неудачные решения.
Так как же оценить качество перевода автоматически? Гипотеза такова: чем ближе МП к профессиональному человеческому, тем он лучше. В 2002 году команда из Научно-исследовательского центра IBM имени Томаса Дж. Уотсона создала собственную метрику точности — BLEU (BiLingual Evaluation Understudy), основная идея которой заключается в подсчете совпадений N-граммов в оцениваемом и эталонном переводах. Качество машинного перевода постепенно приближается к качеству перевода, выполненного человеком, и BLEU - маленький шаг для исследователей, но огромный скачок для всех переводчиков.
https://sysblok.ru/nlp/kak-mashinnyj-perevod-ocenivaet-mashina/
Оценивать машинный перевод — сложно. Для такой оценки человек должен сопоставить адекватность, точность и естественность перевода, а это занимает много времени (недели и даже месяцы) и стоит довольно дорого. Для разработчиков систем МП это проблема — ведь им нужно ежедневно отслеживать изменения в системе и очень быстро отсеивать неудачные решения.
Так как же оценить качество перевода автоматически? Гипотеза такова: чем ближе МП к профессиональному человеческому, тем он лучше. В 2002 году команда из Научно-исследовательского центра IBM имени Томаса Дж. Уотсона создала собственную метрику точности — BLEU (BiLingual Evaluation Understudy), основная идея которой заключается в подсчете совпадений N-граммов в оцениваемом и эталонном переводах. Качество машинного перевода постепенно приближается к качеству перевода, выполненного человеком, и BLEU - маленький шаг для исследователей, но огромный скачок для всех переводчиков.
https://sysblok.ru/nlp/kak-mashinnyj-perevod-ocenivaet-mashina/
Системный Блокъ
Как машинный перевод оценивает… машина? - Системный Блокъ
Если качество машинного перевода проверяет человек, то это долго и дорого. А если нужно быстро и дёшево?
Игра престолов: Финал
Этого ждали восемь лет.
Джордж Мартин сначала писал книги, потом адаптировал их для съемок, а потом стал писать сразу сценарий для сериала. На выживание героев делали ставки, но сегодня день, когда «ставки сделаны, ставок больше нет»: на HBO вышла последняя серия Игры престолов.
Мы решили вспомнить, как Игра престолов отражалась в инфографике: от семейных деревьев — до 50 оттенков серого в холодном мраке Вестероса и инструкции по изготовлению собственной теплой шкуры а-ля Джон Сноу! 🐲 🔥
ВНИМАНИЕ: текст содержит спойлеры о 8 сезоне. https://sysblok.ru/visual/igra-prestolov-grand-final/
Этого ждали восемь лет.
Джордж Мартин сначала писал книги, потом адаптировал их для съемок, а потом стал писать сразу сценарий для сериала. На выживание героев делали ставки, но сегодня день, когда «ставки сделаны, ставок больше нет»: на HBO вышла последняя серия Игры престолов.
Мы решили вспомнить, как Игра престолов отражалась в инфографике: от семейных деревьев — до 50 оттенков серого в холодном мраке Вестероса и инструкции по изготовлению собственной теплой шкуры а-ля Джон Сноу! 🐲 🔥
ВНИМАНИЕ: текст содержит спойлеры о 8 сезоне. https://sysblok.ru/visual/igra-prestolov-grand-final/
Системный Блокъ
Игра престолов: гранд финал - Системный Блокъ
От генеалогических деревьев Семи королевств — до 50 оттенков серого во мраке Вестероса: лучшие инфографики по Игре престолов к выходу последней серии сериала.
Лев Манович — пионер цифровых исследований культуры и новых медиа, король Instagram studies, провокатор и революционер.
«Системный Блокъ» поговорил с Мановичем о том, почему Тюмень сегодня интереснее Нью-Йорка, что ждет соцсети в будущем и почему Россия экспортирует страдание:
https://sysblok.ru/interviews/manovich/
«Системный Блокъ» поговорил с Мановичем о том, почему Тюмень сегодня интереснее Нью-Йорка, что ждет соцсети в будущем и почему Россия экспортирует страдание:
https://sysblok.ru/interviews/manovich/
Системный Блокъ
Гуманитарии должны прогнозировать культуру - Системный Блокъ
Лев Манович — о будущем соцсетей, смещении глобальных культурных центров и экспорте русского страдания
Московско-тартуская школа по цифровым методам в гуманитарных науках — это смесь хакатона, воркшопа и интенсивного научного семинара на 3-4 дня. В этом году школа пройдет в 4-й раз — а мы публикуем обзор интересных исследований с прошлых школ.
— Грамматика мотива: разработка компьютерных инструментов для автоматического выделения в тексте базовых «кирпичиков», из которых строится сюжет художественного произведения. Код. Слайды. Видеопрезентация.
— Историческая география в статистике языка. Когда в русском сближаются Москва и Петербург? В какие годы степь становится «более украинской»? Слайды.
— Сравнение характеристик отдельных частей художественного текста (упоминания персонажей, положительная или отрицательная окраска, диалоги) — и читательского поведения во время чтения. Данные логов Bookmate использовались для того, чтобы посмотреть, как и на что реагирует читатель. А еще тут есть сегментация разных пространств художественного текста с помощью дистрибутивной семантики. Слайды. Видеопрезентация.
— Цифровое исследование «Игры престолов»: цвета, социальные сети, семантическая кластеризация персонажей и мест. Код. Слайды.
Центр Digital Humanities НИУ ВШЭ приглашает исследователей принять участие в 4-й школе. Если у вас есть идея исследования по Digital Humanities, но вечно не хватает рук для ее осуществления — вам сюда. Приходите делать мастерскую вместе с нами!
— Грамматика мотива: разработка компьютерных инструментов для автоматического выделения в тексте базовых «кирпичиков», из которых строится сюжет художественного произведения. Код. Слайды. Видеопрезентация.
— Историческая география в статистике языка. Когда в русском сближаются Москва и Петербург? В какие годы степь становится «более украинской»? Слайды.
— Сравнение характеристик отдельных частей художественного текста (упоминания персонажей, положительная или отрицательная окраска, диалоги) — и читательского поведения во время чтения. Данные логов Bookmate использовались для того, чтобы посмотреть, как и на что реагирует читатель. А еще тут есть сегментация разных пространств художественного текста с помощью дистрибутивной семантики. Слайды. Видеопрезентация.
— Цифровое исследование «Игры престолов»: цвета, социальные сети, семантическая кластеризация персонажей и мест. Код. Слайды.
Центр Digital Humanities НИУ ВШЭ приглашает исследователей принять участие в 4-й школе. Если у вас есть идея исследования по Digital Humanities, но вечно не хватает рук для ее осуществления — вам сюда. Приходите делать мастерскую вместе с нами!
hum.hse.ru
IV Московско-тартуская DH-школа ждет ваших мастерских (call for tutorials)
Готовы провести мастерскую на IV Московско-тартуской школе по Digital Humanities в октябре 2019? Подавайте заявку до 23 мая включительно.
Мы публикуем перевод статьи профессора Аннет Маркхам о том, как антропологи и этнографы работают с цифровыми феноменами. Маркхам с 1980-х годов занимается исследованием поведения людей в цифровой среде и пишет об интернете как пространстве и способе существования, о сопротивлении «датафикации» человека и об ответственности ученого за будущее.
(статья публикуется в двух частях)
https://sysblok.ru/society/ethnography-in-the-digital-internet-era-1
https://sysblok.ru/society/ethnography-in-the-digital-internet-era-2/
(статья публикуется в двух частях)
https://sysblok.ru/society/ethnography-in-the-digital-internet-era-1
https://sysblok.ru/society/ethnography-in-the-digital-internet-era-2/
{kind=link}
Раньше машинные переводчики работали по правилам, которые писали лингвисты. Лингвистов нужно было много, правила писались долго, а перевод все равно получался далеким от идеала. Но потом на помощь человеку пришла статистика, и появился он — рецепт хорошего перевода:
1) Загрузить в компьютер много текстов с готовыми переводами.
2) Указать какие предложения на разных языках соответствуют друг другу.
3) Научить компьютер находить соответствия между конкретными фразами, даже если они разной длины в разных языках.
4) Готово! Теперь компьютер, пользуясь своей коллекцией текстов, научился переводить.
Разобраться подробнее, с примерами и понятными картинками, можно тут:
https://sysblok.ru/knowhow/kak-rabotaet-statisticheskij-perevod-po-frazam/
1) Загрузить в компьютер много текстов с готовыми переводами.
2) Указать какие предложения на разных языках соответствуют друг другу.
3) Научить компьютер находить соответствия между конкретными фразами, даже если они разной длины в разных языках.
4) Готово! Теперь компьютер, пользуясь своей коллекцией текстов, научился переводить.
Разобраться подробнее, с примерами и понятными картинками, можно тут:
https://sysblok.ru/knowhow/kak-rabotaet-statisticheskij-perevod-po-frazam/
Системный Блокъ
Как работает статистический перевод по фразам? - Системный Блокъ
Разбираемся, как научиться переводить, не зная ни одного языка
Почему на Невском есть модная кофейня, а на моей улице нет?
Рассказываем, почему мы редко гуляем по спальным районам, часто ездим в центр, стоим в пробках, и при чем тут космический синтаксис.
https://sysblok.ru/urban/i-na-tvoej-vysoko-integrirovannoj-ulice-budet-prazdnik/
Рассказываем, почему мы редко гуляем по спальным районам, часто ездим в центр, стоим в пробках, и при чем тут космический синтаксис.
https://sysblok.ru/urban/i-na-tvoej-vysoko-integrirovannoj-ulice-budet-prazdnik/
Системный Блокъ
И на твоей (высоко интегрированной) улице будет праздник - Системный Блокъ
В каждом городе есть улицы, где людей больше, и улицы, где людей меньше. Потому ли, что на центральной улице много магазинов, ресторанов и кофеен? А может, потому что на тихой улице спального района нечем заняться, кроме как на лавочке сидеть? А причём тут…
“стоят перед ним три собаки: собака с глазами, как чайные чашки, собака с глазами, как мельничные колеса, и собака с глазами, как круглая башня...”
С чем писатели чаще всего сравнивают размеры предметов?
https://sysblok.ru/nlp/fasolina-ili-jajco-s-chem-sravnivajut-razmery-veshhej/
С чем писатели чаще всего сравнивают размеры предметов?
https://sysblok.ru/nlp/fasolina-ili-jajco-s-chem-sravnivajut-razmery-veshhej/
Системный Блокъ
Фасолина или яйцо? С чем сравнивают размеры вещей - Системный Блокъ
Какие метафоры популярны при описании габаритов предмета, как они изменялись со временем и почему из сравнений исчезли голубиные яйца
Диалоги в голливудских фильмах: герои против героинь
В последнее время Голливуд борется с неравенством на экране. Но белые мужчины все равно получают больше экранного времени. Насколько больше?
Исследователи из проекта The Pudding рассмотрели гендер в кино со всех сторон и посчитали реплики персонажей мужского и женского пола в 8000 сценариев, которые потом превратились в 2000 фильмов. Теперь мы знаем, что даже в мультике про Мулан женщины произносят только четверть всех слов — что уж говорить про Стар Трек (9%) или боевики.
А еще женщины с возрастом получают все меньше и меньше ролей. У мужчин такие проблемы начинаются после 60 — до этого режиссеры с удовольствием их снимают.
https://sysblok.ru/society/dialogi-v-gollivudskih-filmah-geroi-protiv-geroin/
В последнее время Голливуд борется с неравенством на экране. Но белые мужчины все равно получают больше экранного времени. Насколько больше?
Исследователи из проекта The Pudding рассмотрели гендер в кино со всех сторон и посчитали реплики персонажей мужского и женского пола в 8000 сценариев, которые потом превратились в 2000 фильмов. Теперь мы знаем, что даже в мультике про Мулан женщины произносят только четверть всех слов — что уж говорить про Стар Трек (9%) или боевики.
А еще женщины с возрастом получают все меньше и меньше ролей. У мужчин такие проблемы начинаются после 60 — до этого режиссеры с удовольствием их снимают.
https://sysblok.ru/society/dialogi-v-gollivudskih-filmah-geroi-protiv-geroin/
Системный Блокъ
Диалоги в голливудских фильмах: герои против героинь - Системный Блокъ
8000 сценариев. 2000 фильмов. 2 гендера
Сверточные нейросети – как это работает?
С технологиями компьютерного зрения мы встречаемся каждый день, но часто не замечаем этого. Мы привыкли, что в ВК, Фейсбуке или Инстаграме можно за пару секунд наложить фильтр: размыть картинку, подправить цвет, яркость и контрастность. Если разобраться, окажется, что в своей основе фильтр размытия в Инстаграме и сверточная нейросеть работают одинаково:
Сначала алгоритм выделяет на картинке очень конкретные и низкоуровневые признаки - группы пикселей, оказавшихся рядом с каким-нибудь цветовым пятном. Эти признаки усложняются, а исходное изображение превращается в бесконечные комбинации, где активированы те или иные пиксели. Так изображение медленно сжимается, доходя в размерах до единственной точки - сигнала, передаваемого нейроном. Такой сигнал комбинируется с другими сигналами и активирует нейронную цепочку в полносвязной сети, на конце которой один-единственный нейрон, сложив достаточное количество «очков» от других нейронов, заявляет: «Я вижу на картинке лицо!»
Подробнее рассказываем в наших материалах по этой теме:
https://sysblok.ru/knowhow/kak-rabotajut-filtry-v-instagrame/
https://sysblok.ru/knowhow/kak-posmotret-na-mir-glazami-nejrosetej/
С технологиями компьютерного зрения мы встречаемся каждый день, но часто не замечаем этого. Мы привыкли, что в ВК, Фейсбуке или Инстаграме можно за пару секунд наложить фильтр: размыть картинку, подправить цвет, яркость и контрастность. Если разобраться, окажется, что в своей основе фильтр размытия в Инстаграме и сверточная нейросеть работают одинаково:
Сначала алгоритм выделяет на картинке очень конкретные и низкоуровневые признаки - группы пикселей, оказавшихся рядом с каким-нибудь цветовым пятном. Эти признаки усложняются, а исходное изображение превращается в бесконечные комбинации, где активированы те или иные пиксели. Так изображение медленно сжимается, доходя в размерах до единственной точки - сигнала, передаваемого нейроном. Такой сигнал комбинируется с другими сигналами и активирует нейронную цепочку в полносвязной сети, на конце которой один-единственный нейрон, сложив достаточное количество «очков» от других нейронов, заявляет: «Я вижу на картинке лицо!»
Подробнее рассказываем в наших материалах по этой теме:
https://sysblok.ru/knowhow/kak-rabotajut-filtry-v-instagrame/
https://sysblok.ru/knowhow/kak-posmotret-na-mir-glazami-nejrosetej/
Системный Блокъ
Как работают фильтры в Инстаграме - Системный Блокъ
Разбираемся в том, как устроено компьютерное зрение, что такое ядро свертки — и при чем тут фильтры в Инстаграме
6 июня центре Москвы был задержан спецкор «Медузы» Иван Голунов — один из лучших журналистов-расследователей в России. Голунова обвиняют в распространении наркотиков, которые у него якобы нашли полицейские. Сам журналист говорит, что наркотики грубо подбросили — его рюкзак после задержания был у сотрудников МВД. Сверток лежал поверх вещей Голунова — то есть его могли подложить в любой момент. Далее полиция заявила, что наркотики найдены у Голунова дома, но фотографии «нарколаборатории» оказались не из его квартиры. Сейчас Голунов помещен под домашний арест.
В защиту журналиста выступили Юрий Дудь, Оксимирон, Борис Гребенщиков, Юрий Шевчук, Владимир Познер, а также тысячи людей, вышедших на пикеты по всей России. Все они уверены, что арест Голунова — месть за расследования, в которых журналист вскрывал коррупционные схемы московских властей и властных группировок в других регионах, провокации ФСБ и Роснефти, сомнительную деятельность ГРУ, махинации депутатов Госдумы. Путаница и подлоги в заявлениях МВД о наркотиках подтверждают эту версию.
Всего Иван Голунов написал для «Медузы» свыше сотни текстов. Так как не у всех есть время читать длинные расследования, мы собрали статистику и сделали инфографику по текстам Голунова. По инфографике можно понять, какие темы освещал Иван Голунов — и какие «болевые точки» коррумпированной власти он задевал.
Из списка наиболее частотных слов (за вычетом служебных слов и глаголов вроде «говорить») видно, что Голунов занимался экономическими расследованиями — и в основном в Москве. Топ-5 слов во всем массиве его текстов на Медузе — компания, рубль, Москва, Россия, миллион. Очень часто упоминаются мэрия, центр, деньги, миллиард. Голунов и правда много писал о том, как Москва тратит огромные деньги на сомнительные закупки — то бордюров, то плитки, то туалетов, то новогодних украшений. А миллиарды за это получали люди, давно и тесно связанные с городскими или федеральными властями.
Самые интересные расследования Ивана Голунова о Москве:
— Откуда берется гранитная плитка на московских улицах и почему она со временем ржавеет
— Кто будет вывозить мусор из Москвы и как они связаны с московской мэрией
— Кто заработал на новогоднем оформлении Москвы — и при чем тут братья Ротенберги
— Как чиновники, силовики и бандиты делят похоронный рынок — и при чем тут Максим Тесак
Еще заметнее городская тематика, если взять только 2019 год. Здесь мэрия входит в топ 10 самых частых слов, округ — в топ-5, Москва на 3 месте по частоте упоминания, а слово квартира — на втором (первая по-прежнему компания).
В 2019 Голунов написал о
— Ограждениях для сугробов, на которых заработали приближенные префекта ЦАО
— Конфликте вокруг Дома звукозаписи на Малой Никитской. Там находится уникальная звукозаписывающая студия размером с концертный зал, изолированная от внешних шумов по принципу «комната в комнате». Здание передали под офисы издательству «Известия», которым руководит дочь фигуранта расследования «Он вам не Димон», посвященного Дмитрию Медведеву.
— Очередном масштабном «перекопе» Москвы летом 2019 года
Настойчивый интерес Голунова к действиям московских городских властей виден и на графиках упоминания мэрии за три года. Кстати, лично мэра Москвы Сергея Собянина Голунов тоже упоминает в своих расследованиях регулярно. Сочетание «мэр Москвы Сергей Собянин» — одна из самых частотных 4-грамм (сочетаний из 4 слов) в текстах Голунова.
В защиту журналиста выступили Юрий Дудь, Оксимирон, Борис Гребенщиков, Юрий Шевчук, Владимир Познер, а также тысячи людей, вышедших на пикеты по всей России. Все они уверены, что арест Голунова — месть за расследования, в которых журналист вскрывал коррупционные схемы московских властей и властных группировок в других регионах, провокации ФСБ и Роснефти, сомнительную деятельность ГРУ, махинации депутатов Госдумы. Путаница и подлоги в заявлениях МВД о наркотиках подтверждают эту версию.
Всего Иван Голунов написал для «Медузы» свыше сотни текстов. Так как не у всех есть время читать длинные расследования, мы собрали статистику и сделали инфографику по текстам Голунова. По инфографике можно понять, какие темы освещал Иван Голунов — и какие «болевые точки» коррумпированной власти он задевал.
Из списка наиболее частотных слов (за вычетом служебных слов и глаголов вроде «говорить») видно, что Голунов занимался экономическими расследованиями — и в основном в Москве. Топ-5 слов во всем массиве его текстов на Медузе — компания, рубль, Москва, Россия, миллион. Очень часто упоминаются мэрия, центр, деньги, миллиард. Голунов и правда много писал о том, как Москва тратит огромные деньги на сомнительные закупки — то бордюров, то плитки, то туалетов, то новогодних украшений. А миллиарды за это получали люди, давно и тесно связанные с городскими или федеральными властями.
Самые интересные расследования Ивана Голунова о Москве:
— Откуда берется гранитная плитка на московских улицах и почему она со временем ржавеет
— Кто будет вывозить мусор из Москвы и как они связаны с московской мэрией
— Кто заработал на новогоднем оформлении Москвы — и при чем тут братья Ротенберги
— Как чиновники, силовики и бандиты делят похоронный рынок — и при чем тут Максим Тесак
Еще заметнее городская тематика, если взять только 2019 год. Здесь мэрия входит в топ 10 самых частых слов, округ — в топ-5, Москва на 3 месте по частоте упоминания, а слово квартира — на втором (первая по-прежнему компания).
В 2019 Голунов написал о
— Ограждениях для сугробов, на которых заработали приближенные префекта ЦАО
— Конфликте вокруг Дома звукозаписи на Малой Никитской. Там находится уникальная звукозаписывающая студия размером с концертный зал, изолированная от внешних шумов по принципу «комната в комнате». Здание передали под офисы издательству «Известия», которым руководит дочь фигуранта расследования «Он вам не Димон», посвященного Дмитрию Медведеву.
— Очередном масштабном «перекопе» Москвы летом 2019 года
Настойчивый интерес Голунова к действиям московских городских властей виден и на графиках упоминания мэрии за три года. Кстати, лично мэра Москвы Сергея Собянина Голунов тоже упоминает в своих расследованиях регулярно. Сочетание «мэр Москвы Сергей Собянин» — одна из самых частотных 4-грамм (сочетаний из 4 слов) в текстах Голунова.
{kind=link}
Корпус статей Ивана Голунова и скрипт для его получения выложен в нашем репозитории на github'e. Скрипт для скачивания корпуса написан на Python и использует фреймворк Scrapy. Теперь все желающие могут сами поэкспериментировать с визуализацией и аналитикой по расследованиям.
Мы использовали сервис WordClouds для построения облаков слов и сервис Voyant-Tools для отрисовки графика.
Вы можете попробовать сделать что-то более сложное — например, извлечь персон-фигурантов расследований и названия компаний, построить сеть связей между ними... Напишите нам, если готовы поучаствовать.
Мы использовали сервис WordClouds для построения облаков слов и сервис Voyant-Tools для отрисовки графика.
Вы можете попробовать сделать что-то более сложное — например, извлечь персон-фигурантов расследований и названия компаний, построить сеть связей между ними... Напишите нам, если готовы поучаствовать.
GitHub
GitHub - sysblok/corpus_golunov_articles: Свободу Ивану Голунову! http://gg.gg/golunov-petition
Свободу Ивану Голунову! http://gg.gg/golunov-petition - sysblok/corpus_golunov_articles
Если вам срочно понадобилось написать роман, скорее всего, вы начнете придумывать сюжет.
Но есть ли какие-то правила, по которым надо его строить?
Чтобы понять, как формируется «традиционный» английский сюжет, исследователи из Cтэнфордской литературной лаборатории составили корпус из ~50 тысяч английских романов и посчитали, как 50 самых употребимых английских слов распределяются внутри повествования.
Каждый текст корпуса делится на N одинаковых по размеру фрагментов. Дальше мы можем подсчитать, сколько раз нужное нам слово повторяется в каждом из них во всех романах сразу. Например слово любовь встречается 9418 раз в первой части повествования и 25 132 раз в последней.
Это очень простой способ оценить семантическую нагрузку каждого слова, и определить имеет ли наша любовь (или смерть) тенденцию группироваться в какой-то части текста.
Начало романов чаще всего заполнено описаниями людей, мест и вещей, рождения, детства, образования, перечислениями семейных отношений. Оружие, смерть и война достигают пика употребления в кульминационных моментах. В середине романа у героя зачастую случается внутренний кризис и переоценка ценностей, а в финалах выбор невелик, там царят брак и смерть.
Некоторые слова демонстрируют и менее очевидные закономерности. Например все, что связанно с едой, разговорами и женскими персонажами, группируется в первых 10-20% повествования. Обед или званый ужин — очень удобный способ «познакомить» и «представить» читателю действующих лиц (Вспомните ту же Войну и Мир или Лунный Камень).
Но есть ли какие-то правила, по которым надо его строить?
Чтобы понять, как формируется «традиционный» английский сюжет, исследователи из Cтэнфордской литературной лаборатории составили корпус из ~50 тысяч английских романов и посчитали, как 50 самых употребимых английских слов распределяются внутри повествования.
Каждый текст корпуса делится на N одинаковых по размеру фрагментов. Дальше мы можем подсчитать, сколько раз нужное нам слово повторяется в каждом из них во всех романах сразу. Например слово любовь встречается 9418 раз в первой части повествования и 25 132 раз в последней.
Это очень простой способ оценить семантическую нагрузку каждого слова, и определить имеет ли наша любовь (или смерть) тенденцию группироваться в какой-то части текста.
Начало романов чаще всего заполнено описаниями людей, мест и вещей, рождения, детства, образования, перечислениями семейных отношений. Оружие, смерть и война достигают пика употребления в кульминационных моментах. В середине романа у героя зачастую случается внутренний кризис и переоценка ценностей, а в финалах выбор невелик, там царят брак и смерть.
Некоторые слова демонстрируют и менее очевидные закономерности. Например все, что связанно с едой, разговорами и женскими персонажами, группируется в первых 10-20% повествования. Обед или званый ужин — очень удобный способ «познакомить» и «представить» читателю действующих лиц (Вспомните ту же Войну и Мир или Лунный Камень).
{kind=link}
«Системный Блокъ» поговорил с Александрой Элбакян — создателем проекта Sci-Hub.
Исследователи по всему миру ежедневно используют его в научной работе — а власти и издательства пытаются заблокировать доступ к сайту, не признающему копирайт. Александра рассказала как возник и работает Sci-Hub, а еще о том, почему открытый доступ к научной информации это важно.
«Я ожидала, что Sci-Hub будет кейсом, который доказывает, что авторское право, которое препятствует распространению науки, должно быть отменено».
«Без закрытого доступа организовать процесс рецензирования возможно. Это не какая-то фантазия — это то, что уже работает».
https://sysblok.ru/interviews/hochu-sdelat-sci-hub-legalnoj-platformoj/
Исследователи по всему миру ежедневно используют его в научной работе — а власти и издательства пытаются заблокировать доступ к сайту, не признающему копирайт. Александра рассказала как возник и работает Sci-Hub, а еще о том, почему открытый доступ к научной информации это важно.
«Я ожидала, что Sci-Hub будет кейсом, который доказывает, что авторское право, которое препятствует распространению науки, должно быть отменено».
«Без закрытого доступа организовать процесс рецензирования возможно. Это не какая-то фантазия — это то, что уже работает».
https://sysblok.ru/interviews/hochu-sdelat-sci-hub-legalnoj-platformoj/
Системный Блокъ
«Хочу сделать Sci-Hub легальной платформой» - Системный Блокъ
Создатель Sci-Hub Александра Элбакян — о том, как работает Sci-Hub, что нужно, чтобы этот ресурс стал легальным, и чем грозит изоляция Рунета.
Розовые слоны и красные деревья: цвета в языке и в реальной жизни
Системный блок писал про дистрибутивную семантику и раньше, а в этой статье речь будет идти о том, как с помощью нее можно сравнивать цвета в языке и в реальном мире.
Интерес к связи между языком и восприятием возник ещё в 1950-е годы, когда была сформулирована гипотеза Сепира-Уорфа: человеческое восприятие формируется под воздействием семантических и грамматических категорий языка. Цветовое поле предоставляет материал, который удобен для подтверждения или опровержения этой гипотезы. Чтобы выяснить, в каком отношении находятся цветовые характеристики и категории восприятия в языке и в реальном мире, было проведено несколько экспериментов.
В первом эксперименте сравниваются цветовые обозначения для понятий из разных категорий: животные, растения, одежда. Нас интересует, для каких категорий будет характерно большее цветовое разнообразие, а какие описываются меньшим количеством цветов.
Для описания животных или цветочных растений люди используют десятки оттенков, но обычно один из цветов доминирует. Розы скорее будут красными, васильки голубыми, львы жёлтыми. А для описания предметов одежды, тоже очень разных по цветовой гамме, доминантного цвета обычно нет.
Чтобы выяснить, для каких категорий характерно разнообразие, мы извлекаем вектора совместной встречаемости слов с цветовыми понятиями, а затем для каждого слова вычисляем дисперсию значений. Слова с высокой дисперсией (то есть большим разнообразием) относятся к категориям «животные» и «растения», как мы и предполагали. Слова с низкой дисперсией включают в себя черты внешности и абстрактные понятия.
Во втором эксперименте мы подсчитываем совместную встречаемость слова с цветами (сколько раз слово «слон» встречалось со словом «красный», «синий», «фиолетовый» и т.д.) и опускаем все остальные слова. Для 500 слов с наибольшей вариативностью цветов и 500 слов с наименьшей вариативностью (слова взяты из первого эксперимента) мы извлекаем ближайших семантических соседей в обоих дистрибутивных пространствах.
Если соседи-слова в полном пространстве и во втором «цветовом» дистрибутивном пространстве совпадут, то это означает, что для данного конкретного слова цвет действительно очень важен.
Елизавета Кузьменко
https://sysblok.ru/nlp/rozovye-slony-i-krasnye-derevja-cveta-v-jazyke-i-v-realnoj-zhizni/
Системный блок писал про дистрибутивную семантику и раньше, а в этой статье речь будет идти о том, как с помощью нее можно сравнивать цвета в языке и в реальном мире.
Интерес к связи между языком и восприятием возник ещё в 1950-е годы, когда была сформулирована гипотеза Сепира-Уорфа: человеческое восприятие формируется под воздействием семантических и грамматических категорий языка. Цветовое поле предоставляет материал, который удобен для подтверждения или опровержения этой гипотезы. Чтобы выяснить, в каком отношении находятся цветовые характеристики и категории восприятия в языке и в реальном мире, было проведено несколько экспериментов.
В первом эксперименте сравниваются цветовые обозначения для понятий из разных категорий: животные, растения, одежда. Нас интересует, для каких категорий будет характерно большее цветовое разнообразие, а какие описываются меньшим количеством цветов.
Для описания животных или цветочных растений люди используют десятки оттенков, но обычно один из цветов доминирует. Розы скорее будут красными, васильки голубыми, львы жёлтыми. А для описания предметов одежды, тоже очень разных по цветовой гамме, доминантного цвета обычно нет.
Чтобы выяснить, для каких категорий характерно разнообразие, мы извлекаем вектора совместной встречаемости слов с цветовыми понятиями, а затем для каждого слова вычисляем дисперсию значений. Слова с высокой дисперсией (то есть большим разнообразием) относятся к категориям «животные» и «растения», как мы и предполагали. Слова с низкой дисперсией включают в себя черты внешности и абстрактные понятия.
Во втором эксперименте мы подсчитываем совместную встречаемость слова с цветами (сколько раз слово «слон» встречалось со словом «красный», «синий», «фиолетовый» и т.д.) и опускаем все остальные слова. Для 500 слов с наибольшей вариативностью цветов и 500 слов с наименьшей вариативностью (слова взяты из первого эксперимента) мы извлекаем ближайших семантических соседей в обоих дистрибутивных пространствах.
Если соседи-слова в полном пространстве и во втором «цветовом» дистрибутивном пространстве совпадут, то это означает, что для данного конкретного слова цвет действительно очень важен.
Елизавета Кузьменко
https://sysblok.ru/nlp/rozovye-slony-i-krasnye-derevja-cveta-v-jazyke-i-v-realnoj-zhizni/
{kind=link}
Как искусственные нейроны помогают управлять живыми
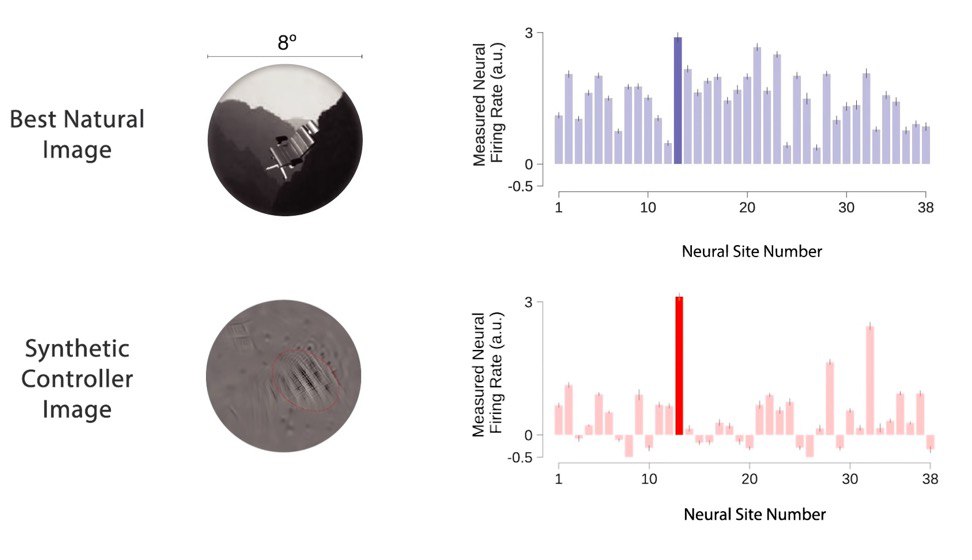
Специалисты по нейросетям из Массачусетского технологического института создали и протестировали на животных компьютерные модели, имитирующие работу зрительной коры мозга.
Модели обучались на более чем 1 миллионе изображений: на вход подавалось размеченная картинка с указанием самого важного объекта на ней, а модель по разметке училась распознавать, что на изображении - стул или самолет. Так ученые определили, что в ответ на одно и то же изображение искусственные нейроны генерируют сигналы, схожие с сигналами нейронов зрительной коры.
А можно ли с помощью этих моделей контролировать нейронную активность коры головного мозга? Для ответа на этот вопрос ученые сопоставили активность нейронов модели и нейронов животных в ответ на изображения и составили карту поля V4 зрительной коры, которое отвечает за восприятие цветов. Каждому нейрону соответствовал узел компьютерной модели. Но поскольку в зоне V4 миллионы нейронов, карты были составлены для групп из 5-40 нейронов.
Затем ученые попытались использовать предсказания полученной модели, чтобы управлять активностью нейронов зрительной коры мозга. Первой целью было создать изображение, на которое нейрон отреагировал бы сильнее, чем на обычную картинку. Эти искусственные картинки были созданы моделями и не были похожи ни на какие реальные объекты.
В результате, на эти изображения нейроны отреагировали в среднем на 40% активнее. Это первый случай подобного управления активностью нейронов. Кроме того, ученым удалось создать изображение, которое повысило активность целевого нейрона, снизив при этом реакцию соседних.
Модели также использовали, чтобы предсказать реакцию нейронов мозга на искусственные изображения. Точность предсказаний составила около 54%. Сейчас ученые стремятся приблизить этот показатель к точности предсказаний моделей на реальных изображениях, которая доходит до 90%.
В будущем управление нейронами мозга может помочь в лечении расстройств настроения, например депрессии. Сейчас ученые расширяют свою модель до височной доли, в которой есть миндалина, участвующая в эмоциональных реакциях.
Ксения Михайлова
Специалисты по нейросетям из Массачусетского технологического института создали и протестировали на животных компьютерные модели, имитирующие работу зрительной коры мозга.
Модели обучались на более чем 1 миллионе изображений: на вход подавалось размеченная картинка с указанием самого важного объекта на ней, а модель по разметке училась распознавать, что на изображении - стул или самолет. Так ученые определили, что в ответ на одно и то же изображение искусственные нейроны генерируют сигналы, схожие с сигналами нейронов зрительной коры.
А можно ли с помощью этих моделей контролировать нейронную активность коры головного мозга? Для ответа на этот вопрос ученые сопоставили активность нейронов модели и нейронов животных в ответ на изображения и составили карту поля V4 зрительной коры, которое отвечает за восприятие цветов. Каждому нейрону соответствовал узел компьютерной модели. Но поскольку в зоне V4 миллионы нейронов, карты были составлены для групп из 5-40 нейронов.
Затем ученые попытались использовать предсказания полученной модели, чтобы управлять активностью нейронов зрительной коры мозга. Первой целью было создать изображение, на которое нейрон отреагировал бы сильнее, чем на обычную картинку. Эти искусственные картинки были созданы моделями и не были похожи ни на какие реальные объекты.
В результате, на эти изображения нейроны отреагировали в среднем на 40% активнее. Это первый случай подобного управления активностью нейронов. Кроме того, ученым удалось создать изображение, которое повысило активность целевого нейрона, снизив при этом реакцию соседних.
Модели также использовали, чтобы предсказать реакцию нейронов мозга на искусственные изображения. Точность предсказаний составила около 54%. Сейчас ученые стремятся приблизить этот показатель к точности предсказаний моделей на реальных изображениях, которая доходит до 90%.
В будущем управление нейронами мозга может помочь в лечении расстройств настроения, например депрессии. Сейчас ученые расширяют свою модель до височной доли, в которой есть миндалина, участвующая в эмоциональных реакциях.
Ксения Михайлова
{kind=link}