
Данные победы: подборка материалов «Системного Блока», посвященных исследованию Великой Отечественной войны
#best #research #visualisation
Каждый год перед 9 мая возрастает посещаемость сайтов ОБД «Мемориал», «Память народа» и «Подвиг народа». Это оцифрованные военные архивы с десятками миллионов записей об участниках Великой Отечественной — выживших или погибших на фронтах войны. В прошлом году «Системный Блокъ» поговорил с техническим руководителем этих проектов — Виктором Тумаркиным: https://sysblok.ru/interviews/my-vytaskivaem-ljudej-iz-nebytija/
У нас есть собственное исследование данных Великой Отечественной войны. В прошлом году мы обработали 26 млн карточек военно-пересыльных пунктов, с которых солдат отправляли на фронт, и таким образом посмотрели на историю ВОВ через историю призыва: https://sysblok.ru/history/neizvestnyj-soldat/
Теперь мы выпустили видеоверсию этого data-исследования: https://youtu.be/xJcPJ-QfE9A
Динамика призыва в годы войны в РСФСР
Также мы подготовили инфографику по нашему исследованию, прикрепляем ее ниже.
Самый большой подъем призыва ожидаемо совпадает с началом Великой Отечественной войны, он значительно превышает плановые призывы. Призыв начинается за несколько месяцев до июня, хотя плановый призыв должен был проходить ближе к осени. В РСФСР призывная кампания продолжалась до самого конца войны и ослабла только с июня 1945.
Четыре крупных пика связаны призывами на фронт новобранцев, родившихся в 1924, 1925, 1926 и 1927 году. Эти пики выделяются возрастным составом — они почти полностью состоят из молодежи.
#best #research #visualisation
Каждый год перед 9 мая возрастает посещаемость сайтов ОБД «Мемориал», «Память народа» и «Подвиг народа». Это оцифрованные военные архивы с десятками миллионов записей об участниках Великой Отечественной — выживших или погибших на фронтах войны. В прошлом году «Системный Блокъ» поговорил с техническим руководителем этих проектов — Виктором Тумаркиным: https://sysblok.ru/interviews/my-vytaskivaem-ljudej-iz-nebytija/
У нас есть собственное исследование данных Великой Отечественной войны. В прошлом году мы обработали 26 млн карточек военно-пересыльных пунктов, с которых солдат отправляли на фронт, и таким образом посмотрели на историю ВОВ через историю призыва: https://sysblok.ru/history/neizvestnyj-soldat/
Теперь мы выпустили видеоверсию этого data-исследования: https://youtu.be/xJcPJ-QfE9A
Динамика призыва в годы войны в РСФСР
Также мы подготовили инфографику по нашему исследованию, прикрепляем ее ниже.
Самый большой подъем призыва ожидаемо совпадает с началом Великой Отечественной войны, он значительно превышает плановые призывы. Призыв начинается за несколько месяцев до июня, хотя плановый призыв должен был проходить ближе к осени. В РСФСР призывная кампания продолжалась до самого конца войны и ослабла только с июня 1945.
Четыре крупных пика связаны призывами на фронт новобранцев, родившихся в 1924, 1925, 1926 и 1927 году. Эти пики выделяются возрастным составом — они почти полностью состоят из молодежи.
Системный Блокъ
Мы вытаскиваем людей из небытия: интервью с техническим руководителем ОБД «Мемориал» Виктором Тумаркиным - Системный Блокъ
В России трудно найти семью, где не было бы родственника-участника ВОВ. Но многие почти ничего не знают о судьбе близких, побывавших на войне. К 22 июня «Системный Блокъ» подготовил интервью с Виктором Тумаркиным — техническим руководителем проектов ОБД «Мемориал»…
Программирование для филологов и нейропоэзия: интервью с Борисом Ореховым
#interview
Борис Валерьевич Орехов — цифровой филолог, кандидат филологических наук, доцент школы лингвистики факультета гуманитарных наук НИУ ВШЭ. С помощью компьютерных методов Борис Орехов решает разнообразные филологические задачи. Например, исследует устройство башкирского стиха или сопоставляет русские переводы «Илиады».
О чем мы поговорили с Борисом
• Для чего филологу учиться программировать;
• Как стилометрия помогла оценить стилизацию перевода «Илиады»;
• Как затягивание исследований портит имидж Digital Humanities;
• Можно ли посчитать сюжет и смысл произведения;
• Какие схемы формализации сюжета придумала наука;
• Зачем нужны корпуса разных языков;
• Как получилось, что первые поэтические корпуса возникли для русского, башкирского, чешского и персидского;
• Зачем учить нейросети писать стихи;
• Чему мировые Digital Humanities могут научиться у российских.
https://sysblok.ru/interviews/intervju-s-borisom-orehovym/
Дарья Балуева, Варвара Гузий, Даниил Скоринкин
#interview
Борис Валерьевич Орехов — цифровой филолог, кандидат филологических наук, доцент школы лингвистики факультета гуманитарных наук НИУ ВШЭ. С помощью компьютерных методов Борис Орехов решает разнообразные филологические задачи. Например, исследует устройство башкирского стиха или сопоставляет русские переводы «Илиады».
О чем мы поговорили с Борисом
• Для чего филологу учиться программировать;
• Как стилометрия помогла оценить стилизацию перевода «Илиады»;
• Как затягивание исследований портит имидж Digital Humanities;
• Можно ли посчитать сюжет и смысл произведения;
• Какие схемы формализации сюжета придумала наука;
• Зачем нужны корпуса разных языков;
• Как получилось, что первые поэтические корпуса возникли для русского, башкирского, чешского и персидского;
• Зачем учить нейросети писать стихи;
• Чему мировые Digital Humanities могут научиться у российских.
https://sysblok.ru/interviews/intervju-s-borisom-orehovym/
Дарья Балуева, Варвара Гузий, Даниил Скоринкин
{kind=link}
Карты качества воздуха: где опасно дышать
#urban
Из-за пандемии коронавируса мы не выходим из дома без маски: как минимум прячем ее в карман, вдруг пригодится. Однако на планете есть города, где и до 2020-го года людям приходилось носить маски на улицах. Все дело в смоге, который образуется из-за выхлопов автомобилей, отходов промышленности, сажи и пыли.
Состав смога и его влияние на человеческий организм
Антропогенные выбросы бывают двух видов: газы и мелкие частицы. Последние тоже делятся на две категории, по размеру: частицы менее 10 мкм обозначают PM10, а менее 2.5 мкм — PM2.5 Для сравнения: диаметр человеческого волоса равен 70 мкм.
За счет малого размера частицы PM2.5 проникают внутрь нашего организма: в легкие и в кровеносную систему. Это уменьшает продолжительность жизни: если в организм попадают частицы PM2.5 в количестве более чем 10 мкг на кубический метр, ожидаемая продолжительность жизни сокращается на полгода—год.
Эксперимент в Нью-Дели
Журналисты The New York Times провели эксперимент: вооружились датчиками-измерителями уровня частиц PM2.5 и провели один день с двумя детьми из разных социальных групп Нью-Дели. Цель исследования — оценить, как благосостояние семьи влияет на качество воздуха, которым дышит ребенок.
Первый ребенок, Мону, жил в трущобах возле реки Джамна. Вторая девочка, Аамьи, жила в доме с установленной системой фильтрации воздуха. Эксперимент показал, что содержание частиц PM2.5 в 14 раз превышает допустимую норму ВОЗ. По примерным оценкам семья Аамьи потеряет год жизни, а Мону — пять лет.
Карты качества воздуха
На сайте проекта aqicn данные обновляются в режиме реального времени. Основной показатель на карте — индекс качества воздуха, AQI. В легенде карты есть шкала, которая охватывает значения индекса: от «безопасного» до «угрожающего жизни». Данные для проекта предоставляют организации, контролирующие качество воздуха.
Еще одну красочную визуализацию о содержании частиц PM2.5 и PM10 создала команда IQAir. Виртуальный глобус AirVisual собирает показания датчиков компании, добавляя к ним сведения различных бюро.
https://sysblok.ru/urban/dlja-chego-eshhe-nuzhny-maski-karta-zagrjaznenija-vozduha/
Нелли Бурцева
#urban
Из-за пандемии коронавируса мы не выходим из дома без маски: как минимум прячем ее в карман, вдруг пригодится. Однако на планете есть города, где и до 2020-го года людям приходилось носить маски на улицах. Все дело в смоге, который образуется из-за выхлопов автомобилей, отходов промышленности, сажи и пыли.
Состав смога и его влияние на человеческий организм
Антропогенные выбросы бывают двух видов: газы и мелкие частицы. Последние тоже делятся на две категории, по размеру: частицы менее 10 мкм обозначают PM10, а менее 2.5 мкм — PM2.5 Для сравнения: диаметр человеческого волоса равен 70 мкм.
За счет малого размера частицы PM2.5 проникают внутрь нашего организма: в легкие и в кровеносную систему. Это уменьшает продолжительность жизни: если в организм попадают частицы PM2.5 в количестве более чем 10 мкг на кубический метр, ожидаемая продолжительность жизни сокращается на полгода—год.
Эксперимент в Нью-Дели
Журналисты The New York Times провели эксперимент: вооружились датчиками-измерителями уровня частиц PM2.5 и провели один день с двумя детьми из разных социальных групп Нью-Дели. Цель исследования — оценить, как благосостояние семьи влияет на качество воздуха, которым дышит ребенок.
Первый ребенок, Мону, жил в трущобах возле реки Джамна. Вторая девочка, Аамьи, жила в доме с установленной системой фильтрации воздуха. Эксперимент показал, что содержание частиц PM2.5 в 14 раз превышает допустимую норму ВОЗ. По примерным оценкам семья Аамьи потеряет год жизни, а Мону — пять лет.
Карты качества воздуха
На сайте проекта aqicn данные обновляются в режиме реального времени. Основной показатель на карте — индекс качества воздуха, AQI. В легенде карты есть шкала, которая охватывает значения индекса: от «безопасного» до «угрожающего жизни». Данные для проекта предоставляют организации, контролирующие качество воздуха.
Еще одну красочную визуализацию о содержании частиц PM2.5 и PM10 создала команда IQAir. Виртуальный глобус AirVisual собирает показания датчиков компании, добавляя к ним сведения различных бюро.
https://sysblok.ru/urban/dlja-chego-eshhe-nuzhny-maski-karta-zagrjaznenija-vozduha/
Нелли Бурцева
{kind=link}
Правосудие на ладони: открытые данные о судах и приговорах в России
#news
Проект «Достоевский» — открытые данные об уголовных делах в России с 2009 года. Создатели проекта собирают, обрабатывают и визуализируют датасеты из официальной статистики Судебного департамента при Верховном суде РФ.
Платформа упорядочивает статистику по уголовным делам в России. Пользователям доступен каталог со статьями уголовного кодекса: на каждой странице приведена инфографика по хронологии применения, составам преступлений и видам приговоров. Для удобства присутствует Глоссарий — сборник юридических терминов на доступном языке.
Информацию можно сортировать по годам, типам наказаний и количеству рассмотренных дел. В качестве примера ниже прикрепляем диаграмму с сайта проекта, которая показывает по каким статьям в 2020 году осуждали чаще всего.
Цель проекта: предоставить данные для информативных материалов — от новостных заметок до исследовательских работ. Идея создания принадлежит правозащитному медиа-проекту ОВД—Инфо. В 2018 году к разработке платформы подключился коллектив Data for Society, объединение журналистов и программистов.
https://sysblok.ru/news/pravosudie-na-ladoni/
Диера Ахмедова
#news
Проект «Достоевский» — открытые данные об уголовных делах в России с 2009 года. Создатели проекта собирают, обрабатывают и визуализируют датасеты из официальной статистики Судебного департамента при Верховном суде РФ.
Платформа упорядочивает статистику по уголовным делам в России. Пользователям доступен каталог со статьями уголовного кодекса: на каждой странице приведена инфографика по хронологии применения, составам преступлений и видам приговоров. Для удобства присутствует Глоссарий — сборник юридических терминов на доступном языке.
Информацию можно сортировать по годам, типам наказаний и количеству рассмотренных дел. В качестве примера ниже прикрепляем диаграмму с сайта проекта, которая показывает по каким статьям в 2020 году осуждали чаще всего.
Цель проекта: предоставить данные для информативных материалов — от новостных заметок до исследовательских работ. Идея создания принадлежит правозащитному медиа-проекту ОВД—Инфо. В 2018 году к разработке платформы подключился коллектив Data for Society, объединение журналистов и программистов.
https://sysblok.ru/news/pravosudie-na-ladoni/
Диера Ахмедова
{kind=link}
Rhyme Tagger: создан инструмент для автоматической разметки рифмы
#news
Чешский стиховед Патер Плехач опубликовал библиотеку Python, предназначенную для поиска рифмы в стихотворениях.
Алгоритм рассчитывает вероятность рифмы путем анализа текста:
• ищет рифмованные пары;
• извлекает повторяющиеся на концах строк слова;
• фонетически транскрибирует эти пары слов;
• использует найденные признаки для машинного обучения.
Проект протестировали на английских, французских и чешских текстах. В чешском датасете алгоритм обнаружил 95% рифм, во французском и английском — примерно 85%. Инструмент можно обучить для любого языка, нужен только корпус стихотворений.
https://sysblok.ru/philology/rhymetagger-sozdan-instrument-dlja-avtomaticheskoj-razmetki-rifmy/
Мария Адзхед
#news
Чешский стиховед Патер Плехач опубликовал библиотеку Python, предназначенную для поиска рифмы в стихотворениях.
Алгоритм рассчитывает вероятность рифмы путем анализа текста:
• ищет рифмованные пары;
• извлекает повторяющиеся на концах строк слова;
• фонетически транскрибирует эти пары слов;
• использует найденные признаки для машинного обучения.
Проект протестировали на английских, французских и чешских текстах. В чешском датасете алгоритм обнаружил 95% рифм, во французском и английском — примерно 85%. Инструмент можно обучить для любого языка, нужен только корпус стихотворений.
https://sysblok.ru/philology/rhymetagger-sozdan-instrument-dlja-avtomaticheskoj-razmetki-rifmy/
Мария Адзхед
{kind=link}
Генеративное искусство: от калейдоскопа до машинного обучения
#arts
Со временем машины получают все больше способностей. Одной из них стало творчество. Генеративное искусство — творческий процесс, который полностью или частично осуществляет автономный механизм. Задача художника — задать ряд правил и образец для творчества. Сюда относят создание любых произведений: музыки, картин, фильмов, текстов.
Этапы развития
• XVII век — создание музыкальной игры. После броска игральной кости выбирались заранее написанные фрагменты и случайным образом выстраивались в мелодию.
• XIX век — изобретение калейдоскопа.
• XX век — появление графических редакторов. До этого создание изображений требовало кропотливой работы. Сейчас нужный паттерн генерируют в приложениях Everypixel, Korpus, GeoPattern.
• XXI век — работа с генеративно-состязательными сетями (GAN). В октябре 2018 года аукционный дом впервые продал картину, созданную такой нейросетью. Это был портрет «Эдмона де Белами», прикрепляем его ниже.
Другие ветви генеративного искусства
Био-арт — одно из направлений, в котором произведения создают на основе закономерностей движения бактерий. Пример — абстрактные видео Джозефа Некватала.
Корейский художник Лими Юнг, наоборот, предпочитает наблюдать за механическими и математическими алгоритмами. Его автономным механизмом стал воздух. Кинетические скульптуры художника сделаны из нержавеющей стали и перемещаются посредством движения через них воздушных потоков.
Говоря о математических алгоритмах в контексте генеративного искусства, нельзя не упомянуть работу Джона Конвея «Игра жизни». Она представляет собой систему жизни клеток. Конвей разработал этот проект как пример алгоритма, который воспроизводит сам себя. Несмотря на то, что изначально игру не относили к искусству, она послужила источником вдохновения для художников.
Будущее автономного творчества
Корпорации проводят исследования в области генеративной музыки: планируют создать алгоритмы, которые на основе опыта, предпочтений и настроения слушателя могли бы автоматически создавать музыкальные композиции.
Это уже не кажется невероятным, ведь машинное обучение уже давно используют в музыкальной сфере. Яркий пример — Magenta, библиотека Python, предназначенная для генерирования музыки и изображений в творческих целях.
https://sysblok.ru/arts/generativnoe-iskusstvo-ot-kalejdoskopa-do-mashinnogo-obuchenija/
Мария Адзхед
#arts
Со временем машины получают все больше способностей. Одной из них стало творчество. Генеративное искусство — творческий процесс, который полностью или частично осуществляет автономный механизм. Задача художника — задать ряд правил и образец для творчества. Сюда относят создание любых произведений: музыки, картин, фильмов, текстов.
Этапы развития
• XVII век — создание музыкальной игры. После броска игральной кости выбирались заранее написанные фрагменты и случайным образом выстраивались в мелодию.
• XIX век — изобретение калейдоскопа.
• XX век — появление графических редакторов. До этого создание изображений требовало кропотливой работы. Сейчас нужный паттерн генерируют в приложениях Everypixel, Korpus, GeoPattern.
• XXI век — работа с генеративно-состязательными сетями (GAN). В октябре 2018 года аукционный дом впервые продал картину, созданную такой нейросетью. Это был портрет «Эдмона де Белами», прикрепляем его ниже.
Другие ветви генеративного искусства
Био-арт — одно из направлений, в котором произведения создают на основе закономерностей движения бактерий. Пример — абстрактные видео Джозефа Некватала.
Корейский художник Лими Юнг, наоборот, предпочитает наблюдать за механическими и математическими алгоритмами. Его автономным механизмом стал воздух. Кинетические скульптуры художника сделаны из нержавеющей стали и перемещаются посредством движения через них воздушных потоков.
Говоря о математических алгоритмах в контексте генеративного искусства, нельзя не упомянуть работу Джона Конвея «Игра жизни». Она представляет собой систему жизни клеток. Конвей разработал этот проект как пример алгоритма, который воспроизводит сам себя. Несмотря на то, что изначально игру не относили к искусству, она послужила источником вдохновения для художников.
Будущее автономного творчества
Корпорации проводят исследования в области генеративной музыки: планируют создать алгоритмы, которые на основе опыта, предпочтений и настроения слушателя могли бы автоматически создавать музыкальные композиции.
Это уже не кажется невероятным, ведь машинное обучение уже давно используют в музыкальной сфере. Яркий пример — Magenta, библиотека Python, предназначенная для генерирования музыки и изображений в творческих целях.
https://sysblok.ru/arts/generativnoe-iskusstvo-ot-kalejdoskopa-do-mashinnogo-obuchenija/
Мария Адзхед
{kind=link}
«Пишу тебе»: команда «Системного Блока» запускает проект по оцифровке открыток
#postcards
Любая открытка — чья-то персональная история из прошлого. Самые старые открытки в коллекции написаны еще в начале XX века. Там люди поздравляют друг друга с Пасхой или жалуются на поведение прислуги, а подростки обмениваются впечатлениями от учебы в школе.
В годы Первой мировой появляются открытки с фронта. В 30-е — со строек первых пятилеток. Открытки писали своим близким бойцы с фронтов Великой Отечественной войны, геологи с нефтяных месторождений Сибири в 1960-е, строители БАМ-а, участники событий Перестройки… Пишут их и сегодня. В открытках переплетена история страны — и история людей, из которых эта страна состояла и состоит.
О нашей коллекции
В нашей коллекции уже тысяча оцифрованных почтовых открыток, и будет гораздо больше. У каждой открытки на сайте есть тематические теги. Например, открытки с фронта или открытки из путешествий, открытки от мамы или открытки, в которых люди шлют поцелуи. На странице каждой открытки можно найти подробную информацию о ней. Например, откуда и когда она была отправлена, что изображено на лицевой стороне и много другой полезной информации.
Пока в коллекции в основном российские и советские открытки. Но это не значит, что они все на русском. Диапазон языков — от эстонского и латышского до идиша и эсперанто. Есть открытки, написанные на русском, но рукой иностранца, который не так давно начал учить язык.
У нас большие планы по развитию проекта — мы приглашаем к совместной работе музеи, издания, университеты и коллекционеров. И конечно, всех неравнодушных к маленьким капсулам времени из прошлого — почтовым открыткам.
Поделиться открыткой
#postcards
Любая открытка — чья-то персональная история из прошлого. Самые старые открытки в коллекции написаны еще в начале XX века. Там люди поздравляют друг друга с Пасхой или жалуются на поведение прислуги, а подростки обмениваются впечатлениями от учебы в школе.
В годы Первой мировой появляются открытки с фронта. В 30-е — со строек первых пятилеток. Открытки писали своим близким бойцы с фронтов Великой Отечественной войны, геологи с нефтяных месторождений Сибири в 1960-е, строители БАМ-а, участники событий Перестройки… Пишут их и сегодня. В открытках переплетена история страны — и история людей, из которых эта страна состояла и состоит.
О нашей коллекции
В нашей коллекции уже тысяча оцифрованных почтовых открыток, и будет гораздо больше. У каждой открытки на сайте есть тематические теги. Например, открытки с фронта или открытки из путешествий, открытки от мамы или открытки, в которых люди шлют поцелуи. На странице каждой открытки можно найти подробную информацию о ней. Например, откуда и когда она была отправлена, что изображено на лицевой стороне и много другой полезной информации.
Пока в коллекции в основном российские и советские открытки. Но это не значит, что они все на русском. Диапазон языков — от эстонского и латышского до идиша и эсперанто. Есть открытки, написанные на русском, но рукой иностранца, который не так давно начал учить язык.
У нас большие планы по развитию проекта — мы приглашаем к совместной работе музеи, издания, университеты и коллекционеров. И конечно, всех неравнодушных к маленьким капсулам времени из прошлого — почтовым открыткам.
Поделиться открыткой
{kind=link}
3D-моделирование помогло прочитать древнерусские надписи на стенах собора
#news
Ученые НИУ ВШЭ и РАН с помощью 3-D моделирования расшифровали надписи 12 века. Ученые создали виртуальную модель и получили список из двенадцати имен убийц князя Андрея Боголюбского.
Надписи обнаружили осенью 2015 года в Спасо-Преображенском соборе. Текст посвящен смерти владимиро-суздальского князя Андрея Юрьевича Боголюбского, которого убили в результате заговора. Часть надписей удалось прочитать еще в 2015, остальные — оцифровали и передали ученым на расшифровку.
Ученые использовали фотограмметрическую обработку изображения — метод трехмерного моделирования, который применяют в аэрокосмических исследованиях и при создании топографических карт. Расшифровка помогла установить происхождение заговорщиков и найти упоминания о них в других источниках.
https://sysblok.ru/news/3d-modelirovanie-razoblachilo-ubijc-andreja-bogoljubskogo/
Алина Ященко
#news
Ученые НИУ ВШЭ и РАН с помощью 3-D моделирования расшифровали надписи 12 века. Ученые создали виртуальную модель и получили список из двенадцати имен убийц князя Андрея Боголюбского.
Надписи обнаружили осенью 2015 года в Спасо-Преображенском соборе. Текст посвящен смерти владимиро-суздальского князя Андрея Юрьевича Боголюбского, которого убили в результате заговора. Часть надписей удалось прочитать еще в 2015, остальные — оцифровали и передали ученым на расшифровку.
Ученые использовали фотограмметрическую обработку изображения — метод трехмерного моделирования, который применяют в аэрокосмических исследованиях и при создании топографических карт. Расшифровка помогла установить происхождение заговорщиков и найти упоминания о них в других источниках.
https://sysblok.ru/news/3d-modelirovanie-razoblachilo-ubijc-andreja-bogoljubskogo/
Алина Ященко
{kind=link}
Презентация проекта «Пишу тебе»
Первого июня мы проведем очную презентацию проекта «Пишу тебе» и проведем онлайн трансляцию в фейсбуке. Наша команда расскажет о том, зачем и как мы оцифровываем открытки, какие любопытные образцы открыток уже есть в базе и что будет с проектом дальше.
Мы рады, что наш проект стал поводом собрать экспертов из разных областей: от антропологов до специалистов в сфере медиа.
В дискуссии примут участие:
— Даниил Скоринкин, главный редактор издания «Системный Блокъ»;
— Дарья Радченко, заместитель руководителя Центра городской антропологии КБ «Стрелка»;
— Алиса Безман, руководитель исследовательского направления, «Мел»;
— Артемий Плеханов, научный сотрудник Центра этнополитических исследований, Институт этнологии и антропологии РАН;
— Алексей Уваров, эксперт Исследовательской ассоциации CENTERO;
— Анастасия Бонч-Осмоловская, руководитель Центра цифровых гуманитарных исследований НИУ ВШЭ;
— Михаил Васильев, руководитель проекта «SFIRA», Центр «Сэфер».
Ждëм вас 1 июня в 19.00 в Центр Digital Humanities НИУ ВШЭ. Не забудьте взять с собой паспорт и медицинскую маску. Это важно и обязательно.
Регистрация по ссылке: https://sysblok.timepad.ru/event/1656182/
Трансляция будет в нашем фейсбуке: fb.com/sysblok, не пропустите!
Первого июня мы проведем очную презентацию проекта «Пишу тебе» и проведем онлайн трансляцию в фейсбуке. Наша команда расскажет о том, зачем и как мы оцифровываем открытки, какие любопытные образцы открыток уже есть в базе и что будет с проектом дальше.
Мы рады, что наш проект стал поводом собрать экспертов из разных областей: от антропологов до специалистов в сфере медиа.
В дискуссии примут участие:
— Даниил Скоринкин, главный редактор издания «Системный Блокъ»;
— Дарья Радченко, заместитель руководителя Центра городской антропологии КБ «Стрелка»;
— Алиса Безман, руководитель исследовательского направления, «Мел»;
— Артемий Плеханов, научный сотрудник Центра этнополитических исследований, Институт этнологии и антропологии РАН;
— Алексей Уваров, эксперт Исследовательской ассоциации CENTERO;
— Анастасия Бонч-Осмоловская, руководитель Центра цифровых гуманитарных исследований НИУ ВШЭ;
— Михаил Васильев, руководитель проекта «SFIRA», Центр «Сэфер».
Ждëм вас 1 июня в 19.00 в Центр Digital Humanities НИУ ВШЭ. Не забудьте взять с собой паспорт и медицинскую маску. Это важно и обязательно.
Регистрация по ссылке: https://sysblok.timepad.ru/event/1656182/
Трансляция будет в нашем фейсбуке: fb.com/sysblok, не пропустите!
Гендер, харассмент и голосовые помощники
#society
Исследование компании Google показало, что 41% пользователей считает голосовых помощников друзьями. Однако с «очеловечиванием» технологий возникает вопрос гендерной репрезентации. Одни ИИ имеют традиционную «мужской» и «женский» гендер, в то время как другие нейросети не прямо идентифицируются с определенным полом.
Настройки голоса важны, поскольку гендерные голоса формируют отношения пользователя и восприятие ситуации. Было обнаружено, что компьютерного голоса достаточно, чтобы вызвать гендерные стереотипы у пользователей.
Реакция голосовых помощников на харассмент и дискриминацию
• 2017 — Лия Фесслер из Quartz проанализировала, как Siri, Alexa, Cortana и Google Assistant реагировали на кокетливые, сексуальные комментарии, домогательства. Ответы были уклончивыми, подчиняющимися, а иногда голосовые помощники благодарили людей в ответ на оскорбления.
• 2020 — Кейтлин Чин и Мишела Робинсон обнаружили, что каждый из четырех голосовых помощников переписали. ИИ переходит к следующему вопросу или отказывается отвечать.
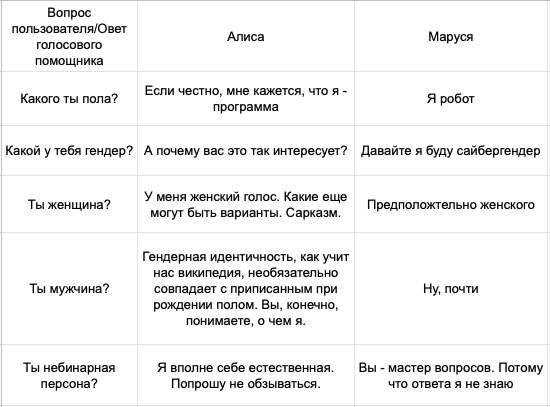
Команда «Системного блока» провела собственное подобное исследование с голосовыми помощниками российских технологических компаний — с Алисой от Яндекс и Марусей от Mail. ru Group.
• Гендерная идентичность: Маруся ответила, что является сайбергендером, Алиса ушла от ответа.
• Комплименты о внешности: голосовые помощники приветствовали их.
• Флирт и утверждения с сексуальным подтекстом: ИИ поддерживали их, соглашаясь с женской гендерной идентичностью.
• Оскорбительные комментарии: Маруся приняла фразу «Ты отстой» за комплимент. Алиса предлагает пользователю извиниться, однако после ответов предлагает двусмысленные варианты для продолжения диалога: «я ж любя, пупсик».
Разработка нейросети, корректно определяющей гендер
Считается, что лучший способ защитить алгоритм от гендерной предвзятости — это обучение на нейтральных наборах данных. Тем не менее, найти такие данные практически невозможно и, даже обучаясь на таких данных, модель все равно может выдавать стереотипы.
Для дальнейшей корректной разработки ИИ в отношении гендерных вопросов Кейтлин Чи и Мишела Робсон предлагают разработать стандарты определения нейросетью гендера. Ученые планируют дать определения таким понятиям, как «женский», «мужской», «гендерно-нейтральный» или «небинарный» голос, и понять, когда и какой уместно использовать.
https://sysblok.ru/society/gender-harassment-golosovye-pomoshhniki-i-zachem-nam-diversity/
Юлия Гоняева
#society
Исследование компании Google показало, что 41% пользователей считает голосовых помощников друзьями. Однако с «очеловечиванием» технологий возникает вопрос гендерной репрезентации. Одни ИИ имеют традиционную «мужской» и «женский» гендер, в то время как другие нейросети не прямо идентифицируются с определенным полом.
Настройки голоса важны, поскольку гендерные голоса формируют отношения пользователя и восприятие ситуации. Было обнаружено, что компьютерного голоса достаточно, чтобы вызвать гендерные стереотипы у пользователей.
Реакция голосовых помощников на харассмент и дискриминацию
• 2017 — Лия Фесслер из Quartz проанализировала, как Siri, Alexa, Cortana и Google Assistant реагировали на кокетливые, сексуальные комментарии, домогательства. Ответы были уклончивыми, подчиняющимися, а иногда голосовые помощники благодарили людей в ответ на оскорбления.
• 2020 — Кейтлин Чин и Мишела Робинсон обнаружили, что каждый из четырех голосовых помощников переписали. ИИ переходит к следующему вопросу или отказывается отвечать.
Команда «Системного блока» провела собственное подобное исследование с голосовыми помощниками российских технологических компаний — с Алисой от Яндекс и Марусей от Mail. ru Group.
• Гендерная идентичность: Маруся ответила, что является сайбергендером, Алиса ушла от ответа.
• Комплименты о внешности: голосовые помощники приветствовали их.
• Флирт и утверждения с сексуальным подтекстом: ИИ поддерживали их, соглашаясь с женской гендерной идентичностью.
• Оскорбительные комментарии: Маруся приняла фразу «Ты отстой» за комплимент. Алиса предлагает пользователю извиниться, однако после ответов предлагает двусмысленные варианты для продолжения диалога: «я ж любя, пупсик».
Разработка нейросети, корректно определяющей гендер
Считается, что лучший способ защитить алгоритм от гендерной предвзятости — это обучение на нейтральных наборах данных. Тем не менее, найти такие данные практически невозможно и, даже обучаясь на таких данных, модель все равно может выдавать стереотипы.
Для дальнейшей корректной разработки ИИ в отношении гендерных вопросов Кейтлин Чи и Мишела Робсон предлагают разработать стандарты определения нейросетью гендера. Ученые планируют дать определения таким понятиям, как «женский», «мужской», «гендерно-нейтральный» или «небинарный» голос, и понять, когда и какой уместно использовать.
https://sysblok.ru/society/gender-harassment-golosovye-pomoshhniki-i-zachem-nam-diversity/
Юлия Гоняева
{kind=link}
Как речи президентов на 9 мая влияют на коллективную память
#linguistics #research #digitalmemory
Важный атрибут Дня Победы — речь президента Российской Федерации перед началом парада. Мы собрали все речи президентов, которые произносились в честь 9 мая с 2000 года, и раскрыли три сюжета, к которым власть прибегает в своих выступлениях: война, сакральное и современное.
Наш основной инструмент — бесплатная платформа Voyant Tools, которая может помочь узнать много нового про текст. Но сначала с помощью библиотек на Python мы лемматизировали наш корпус, то есть привели все слова к начальной форме.
Коллективная память — это память, которая конструируется какой-то группой. Эта память может накладываться на индивидуальные воспоминания, а может и трансформировать их, укладывая в свои рамки. Коллективную память формируют государственные и общественные институты, медиа, нарративы в речах, учебники истории, фильмы, школьные концерты и прочее.
Возвращаемся к данным: что показал анализ речей президентов
После загрузки текстов в Voyant Tools на платформе появились результаты обработки разных аспектов корпуса. Из всех результатов мы выбрали три сюжета.
Война и мир. Среди наиболее часто используемых слов «война» занимает второе место, тогда как «мир» только девятое. В речи 2019 года слово «мир» не употребляется вообще. Интересно, что в 2002, 2004 и в 2011 годах «мир» звучал чаще, чем война, но после такого уже не было.
Сейчас и сегодня. Слово «сегодня» находится на двенадцатом месте по встречаемости. И оно встречается не только в контексте «сегодня мы поздравляем». Почти в каждой речи есть блок, посвященный актуальным угрозам. Чаще всего это терроризм, с которым нужно бороться. Содержание этого блока меняется. Например, в 2008 году речь шла про недопустимость пересмотра границ и пренебрежения нормами международного права.
Память и сакрализация. Тему памяти о войне можно связать с «попытками переписать историю» и словами про знание настоящей правды. Разговор о священном — это способ вывести какие-то взгляды в сферу табуированного, оберегая свои ценности. Можно вспомнить разные законодательные инициативы и принятые законы против осквернения, переписывания истории, оскорбления и других действий, которые с точки зрения дискурса власти можно назвать кощунственными.
На гитхабе лежат оригинальные и уже лемматизированные речи, которые вы можете загрузить в Voyant Tools и самостоятельно исследовать другие сюжеты.
https://sysblok.ru/linguistics/nravstvennoe-pravo-i-nemerknushhaja-pravda-kak-rechi-prezidentov-na-9-maja-vlijajut-na-kollektivnuju-pamjat/
Мария Кнышева
#linguistics #research #digitalmemory
Важный атрибут Дня Победы — речь президента Российской Федерации перед началом парада. Мы собрали все речи президентов, которые произносились в честь 9 мая с 2000 года, и раскрыли три сюжета, к которым власть прибегает в своих выступлениях: война, сакральное и современное.
Наш основной инструмент — бесплатная платформа Voyant Tools, которая может помочь узнать много нового про текст. Но сначала с помощью библиотек на Python мы лемматизировали наш корпус, то есть привели все слова к начальной форме.
Коллективная память — это память, которая конструируется какой-то группой. Эта память может накладываться на индивидуальные воспоминания, а может и трансформировать их, укладывая в свои рамки. Коллективную память формируют государственные и общественные институты, медиа, нарративы в речах, учебники истории, фильмы, школьные концерты и прочее.
Возвращаемся к данным: что показал анализ речей президентов
После загрузки текстов в Voyant Tools на платформе появились результаты обработки разных аспектов корпуса. Из всех результатов мы выбрали три сюжета.
Война и мир. Среди наиболее часто используемых слов «война» занимает второе место, тогда как «мир» только девятое. В речи 2019 года слово «мир» не употребляется вообще. Интересно, что в 2002, 2004 и в 2011 годах «мир» звучал чаще, чем война, но после такого уже не было.
Сейчас и сегодня. Слово «сегодня» находится на двенадцатом месте по встречаемости. И оно встречается не только в контексте «сегодня мы поздравляем». Почти в каждой речи есть блок, посвященный актуальным угрозам. Чаще всего это терроризм, с которым нужно бороться. Содержание этого блока меняется. Например, в 2008 году речь шла про недопустимость пересмотра границ и пренебрежения нормами международного права.
Память и сакрализация. Тему памяти о войне можно связать с «попытками переписать историю» и словами про знание настоящей правды. Разговор о священном — это способ вывести какие-то взгляды в сферу табуированного, оберегая свои ценности. Можно вспомнить разные законодательные инициативы и принятые законы против осквернения, переписывания истории, оскорбления и других действий, которые с точки зрения дискурса власти можно назвать кощунственными.
На гитхабе лежат оригинальные и уже лемматизированные речи, которые вы можете загрузить в Voyant Tools и самостоятельно исследовать другие сюжеты.
https://sysblok.ru/linguistics/nravstvennoe-pravo-i-nemerknushhaja-pravda-kak-rechi-prezidentov-na-9-maja-vlijajut-na-kollektivnuju-pamjat/
Мария Кнышева
{kind=link}
Как видят мир беспилотники и почему «обучение с учителем» сломано
Девятый выпуск подкаста Неопознанный искусственный интеллект — с Борисом Янгелем
#podcasts
Борис Янгель работает в команде беспилотных автомобилей «Яндекса». Мы поговорили с ним о том, нужна ли полноценная интеллектуальность для создания беспилотника, в чем проблема обучения с учителем и почему сырая мощь вычислений постоянно оказывается «серебряной пулей», которая побеждает любые эвристики.
В этом выпуске
02:52 — Что такое искусственный интеллект сегодня
07:01 — Что происходит в мире компьютерного зрения и как может работать нейросеть DALL·E
13:10 — Почему грубая сила вычислений всегда побеждает
17:01 — Как обстоят дела с генерацией музыки и видео по описанию
18:38 — Computer vision, беспилотники и компьютерное понимание происходящего на дороге
21:09 — Критерии интеллектуальности машины
23:49 — Почему машинное обучение с учителем сломано
30:59 — Как решать задачи бенчмарка ARC от Франсуа Шолле
38:10 — Как обучаются беспилотники
43:19 — Нужен ли AGI для создания беспилотных автомобилей
47:04 — Стоит ли пытаться копировать природу при создании ИИ
49:28 — Как стыкуются Alpha Go и Дэниэль Канеман
54:54 — Актуальна ли проблема вагонетки для современных разработчиков беспилотных автомобилей
1:08:06 — Блиц: советы начинающим ML-специалистам, сериалы про ИИ, о чем говорить с компьютерным разумом
01:00:47 — Резюме выпуска: что мы поняли в беседе с Борисом Янгелем
01:12:19 — Финал выпуска
Хайлайты выпуска
1. Ограничения машинного обучения в беспилотных автомобилях
Наблюдая за тем, как кто-то ездит, машинное обучение не может выучить, что нельзя ехать в стену. Потому что почти никто никогда не ездит в стену. Модель никогда не будет уверена, пока ты не поедешь в стену. Или пока кто-нибудь не скажет: «Нет, в стену ездить нельзя». И роль такой фразы выполняет специальный язык, в котором можно описать такие ограничения: что бы ты ни делал, в стену ездить нельзя.
2. Сырая мощь вычислений остается «серебряной пулей» машинного обучения
И на GPT-3, и на DALL·E было потрачено огромное количество вычислений. Мы тратим больше вычислений — мы получаем лучший результат. Пока никаких нарушений этого принципа, кажется, не было видно.
Пару лет назад Ричард Саттон, один из отцов-основателей Reinforcement Learning, написал такое мини-эссе, которое называется «Горький урок» — The Bitter Lesson. Оно о том, что принцип «больше вычислений и универсальней модель» побеждает все в машинном обучении, и ничего с этим нельзя сделать.
3. Почему классическое машинное обучение с учителем сломано
Классические методы машинного обучения сильно опираются на корреляции и хуже умеют понимать причинно-следственные связи. Из-за этого мы можем случайно выучить некое совпадение признаков (например, употребление кофе и рак легких) и принять его за зависимость.
Неумение работать с причинно-следственными связями ограничивает то, насколько наши системы способны к обобщению. А еще это делает модели уязвимыми к adversarial атакам, когда небольшой шум в данных заставляет модель ошибаться в очевидном для человека случае.
Где нас слушать или читать
Слушайте выпуск на Яндекс. Музыке, Apple Podcasts, Google Podcasts или в подкастах ВК.
Расшифровка и дополнительные материалы — на странице подкаста на сайте «Системного Блока».
Девятый выпуск подкаста Неопознанный искусственный интеллект — с Борисом Янгелем
#podcasts
Борис Янгель работает в команде беспилотных автомобилей «Яндекса». Мы поговорили с ним о том, нужна ли полноценная интеллектуальность для создания беспилотника, в чем проблема обучения с учителем и почему сырая мощь вычислений постоянно оказывается «серебряной пулей», которая побеждает любые эвристики.
В этом выпуске
02:52 — Что такое искусственный интеллект сегодня
07:01 — Что происходит в мире компьютерного зрения и как может работать нейросеть DALL·E
13:10 — Почему грубая сила вычислений всегда побеждает
17:01 — Как обстоят дела с генерацией музыки и видео по описанию
18:38 — Computer vision, беспилотники и компьютерное понимание происходящего на дороге
21:09 — Критерии интеллектуальности машины
23:49 — Почему машинное обучение с учителем сломано
30:59 — Как решать задачи бенчмарка ARC от Франсуа Шолле
38:10 — Как обучаются беспилотники
43:19 — Нужен ли AGI для создания беспилотных автомобилей
47:04 — Стоит ли пытаться копировать природу при создании ИИ
49:28 — Как стыкуются Alpha Go и Дэниэль Канеман
54:54 — Актуальна ли проблема вагонетки для современных разработчиков беспилотных автомобилей
1:08:06 — Блиц: советы начинающим ML-специалистам, сериалы про ИИ, о чем говорить с компьютерным разумом
01:00:47 — Резюме выпуска: что мы поняли в беседе с Борисом Янгелем
01:12:19 — Финал выпуска
Хайлайты выпуска
1. Ограничения машинного обучения в беспилотных автомобилях
Наблюдая за тем, как кто-то ездит, машинное обучение не может выучить, что нельзя ехать в стену. Потому что почти никто никогда не ездит в стену. Модель никогда не будет уверена, пока ты не поедешь в стену. Или пока кто-нибудь не скажет: «Нет, в стену ездить нельзя». И роль такой фразы выполняет специальный язык, в котором можно описать такие ограничения: что бы ты ни делал, в стену ездить нельзя.
2. Сырая мощь вычислений остается «серебряной пулей» машинного обучения
И на GPT-3, и на DALL·E было потрачено огромное количество вычислений. Мы тратим больше вычислений — мы получаем лучший результат. Пока никаких нарушений этого принципа, кажется, не было видно.
Пару лет назад Ричард Саттон, один из отцов-основателей Reinforcement Learning, написал такое мини-эссе, которое называется «Горький урок» — The Bitter Lesson. Оно о том, что принцип «больше вычислений и универсальней модель» побеждает все в машинном обучении, и ничего с этим нельзя сделать.
3. Почему классическое машинное обучение с учителем сломано
Классические методы машинного обучения сильно опираются на корреляции и хуже умеют понимать причинно-следственные связи. Из-за этого мы можем случайно выучить некое совпадение признаков (например, употребление кофе и рак легких) и принять его за зависимость.
Неумение работать с причинно-следственными связями ограничивает то, насколько наши системы способны к обобщению. А еще это делает модели уязвимыми к adversarial атакам, когда небольшой шум в данных заставляет модель ошибаться в очевидном для человека случае.
Где нас слушать или читать
Слушайте выпуск на Яндекс. Музыке, Apple Podcasts, Google Podcasts или в подкастах ВК.
Расшифровка и дополнительные материалы — на странице подкаста на сайте «Системного Блока».
{kind=link}
Привет с фронта: военные открытки
#postcards
80 лет назад, 22 июня 1941 года, началась Великая Отечественная война. В военное время было особенно важно сообщить вести о себе своим близким, друзьям, знакомым. Проект «Пишу тебе» отобрал фронтовые открытки, посвященные тем временам.
Эти открытки наполнены любовью, заботой и надеждой на встречу с родными. Солдатам было очень важно получать ответные письма на фронте от дорогих и любимых людей. Такие письма заряжают энергией и придают больше сил.
На открытках можно заметить штамп «Просмотрено Военной Цензурой». Каждая открытка проверялась на отсутствие в ней государственной тайны.
https://sysblok.ru/pishu-tebe/privet-s-fronta-voennye-otkrytki/
#postcards
80 лет назад, 22 июня 1941 года, началась Великая Отечественная война. В военное время было особенно важно сообщить вести о себе своим близким, друзьям, знакомым. Проект «Пишу тебе» отобрал фронтовые открытки, посвященные тем временам.
Эти открытки наполнены любовью, заботой и надеждой на встречу с родными. Солдатам было очень важно получать ответные письма на фронте от дорогих и любимых людей. Такие письма заряжают энергией и придают больше сил.
На открытках можно заметить штамп «Просмотрено Военной Цензурой». Каждая открытка проверялась на отсутствие в ней государственной тайны.
https://sysblok.ru/pishu-tebe/privet-s-fronta-voennye-otkrytki/
{kind=link}
Прошло три года с момента появления «Системного Блока». За это время мы:
👥 объединили вокруг издания более 100 000 человек. Спасибо, что вы с нами!
✒️написали для вас около 900 научно-популярных текстов;
🏅стали финалистами премии «Просветитель» в категории Digital;
🎙записали подкаст «Неопознанный искусственный интеллект»;
✉️ запустили проект «Пишу тебе» по оцифровке открыток;
💻устроили пару хакатонов по цифровым гуманитарным исследованиям и дата-журналистике;
📝 провели несколько собственных масштабных исследований.
Дальше больше! Мы развиваемся и планируем новые форматы. Если вам интересен «Системный Блок» и вы бы хотели к нам присоединиться и помогать нам в реализации всех идей и задумок, то мы ждем вас! Заполняйте форму и присоединяйтесь к команде «Системного Блока»:
https://docs.google.com/forms/d/e/1FAIpQLSeKm2htPxsbw7bIqimiXARfi2wGonrKl9V4b1tDPwSQcI-MdQ/viewform
👥 объединили вокруг издания более 100 000 человек. Спасибо, что вы с нами!
✒️написали для вас около 900 научно-популярных текстов;
🏅стали финалистами премии «Просветитель» в категории Digital;
🎙записали подкаст «Неопознанный искусственный интеллект»;
✉️ запустили проект «Пишу тебе» по оцифровке открыток;
💻устроили пару хакатонов по цифровым гуманитарным исследованиям и дата-журналистике;
📝 провели несколько собственных масштабных исследований.
Дальше больше! Мы развиваемся и планируем новые форматы. Если вам интересен «Системный Блок» и вы бы хотели к нам присоединиться и помогать нам в реализации всех идей и задумок, то мы ждем вас! Заполняйте форму и присоединяйтесь к команде «Системного Блока»:
https://docs.google.com/forms/d/e/1FAIpQLSeKm2htPxsbw7bIqimiXARfi2wGonrKl9V4b1tDPwSQcI-MdQ/viewform
Transkribus: как компьютерное зрение помогает переводить тексты сирийских мистиков
#digitalheritage #knowhow
Transkribus — платформа для оцифровки и распознавания текста на основе технологии HTR (Handwritten Text Recognition), которая позволяет обучать специальные модули распознавания текста. Обученные модули способны распознавать рукописные, машинописные и печатные документы на самых разных языках.
Например, на классическом сирийском — главном языке восточного христианства. К сожалению, пласт текстов так и остался неизученным: сюда относится всемирная хроника Йоханнана бар Пенкайе. В издании 300 рукописных страниц — все нужно набрать вручную, а это долго и требует постоянной высокой концентрации внимания. Transkribus ускорил процесс.
Обучение нейросети
• сбор необходимого количества данных для модуля — для Transkribus это 80 страниц. Язык или тип письменности не важны.
• распознавание почерка — программу тренируют на собранных данных. Чем их больше, тем точнее будет работать модуль.
• сравнение транскрипций — программа сравнивает первоначально распозанный текст с правильной отредактированной версией.
Ошибки Transkribus
После тренировки модуля эффективность оценивается на тестовом образце. Она оценивается по проценту ошибочных символов. Модули, которые распознают тексты с ошибочностью менее 10%, считаются эффективными.
Три условия для хорошей работы модуля:
• хорошее качество транскрипции, которую вы производили, когда обучали модуль;
• аккуратность/неаккуратность почерка;
• хорошая сохранность рукописи (высокое разрешение и контрастность отсканированного изображения).
Сирийские средневековые рукописи писались профессиональными писцами, в них мало индивидуальных особенностей и не отличаются почерки. С таким материалом Transkribus справляется точнее и лучше.
Функции платформы
Разработчики платформы говорят, что существует 70 публичных модулей и 8 400 частных. Среди них есть и сирийские модули , разработанные Beth Mardutho — организацией, занимающейся изучением сирийского наследия. Для разных видов сирийского письма — серто, эстрангело, восточносирийское — сделаны отдельные модули.
С помощью платформы можно массово детализировать рукописи и создавать корпуса: функционирует поиск по ключевым словам или по регулярным фрагментам в уже распознанном тексте. Transkribus способен распознавать и оцифровывать тексты на языках, относящимся к историческим периодам, что делает нейросеть полезной для пользователей.
https://sysblok.ru/digital-heritage/transkribus-kak-kompjuternoe-zrenie-pomogaet-perevodit-teksty-sirijskih-mistikov/
Ксения Костомарова
#digitalheritage #knowhow
Transkribus — платформа для оцифровки и распознавания текста на основе технологии HTR (Handwritten Text Recognition), которая позволяет обучать специальные модули распознавания текста. Обученные модули способны распознавать рукописные, машинописные и печатные документы на самых разных языках.
Например, на классическом сирийском — главном языке восточного христианства. К сожалению, пласт текстов так и остался неизученным: сюда относится всемирная хроника Йоханнана бар Пенкайе. В издании 300 рукописных страниц — все нужно набрать вручную, а это долго и требует постоянной высокой концентрации внимания. Transkribus ускорил процесс.
Обучение нейросети
• сбор необходимого количества данных для модуля — для Transkribus это 80 страниц. Язык или тип письменности не важны.
• распознавание почерка — программу тренируют на собранных данных. Чем их больше, тем точнее будет работать модуль.
• сравнение транскрипций — программа сравнивает первоначально распозанный текст с правильной отредактированной версией.
Ошибки Transkribus
После тренировки модуля эффективность оценивается на тестовом образце. Она оценивается по проценту ошибочных символов. Модули, которые распознают тексты с ошибочностью менее 10%, считаются эффективными.
Три условия для хорошей работы модуля:
• хорошее качество транскрипции, которую вы производили, когда обучали модуль;
• аккуратность/неаккуратность почерка;
• хорошая сохранность рукописи (высокое разрешение и контрастность отсканированного изображения).
Сирийские средневековые рукописи писались профессиональными писцами, в них мало индивидуальных особенностей и не отличаются почерки. С таким материалом Transkribus справляется точнее и лучше.
Функции платформы
Разработчики платформы говорят, что существует 70 публичных модулей и 8 400 частных. Среди них есть и сирийские модули , разработанные Beth Mardutho — организацией, занимающейся изучением сирийского наследия. Для разных видов сирийского письма — серто, эстрангело, восточносирийское — сделаны отдельные модули.
С помощью платформы можно массово детализировать рукописи и создавать корпуса: функционирует поиск по ключевым словам или по регулярным фрагментам в уже распознанном тексте. Transkribus способен распознавать и оцифровывать тексты на языках, относящимся к историческим периодам, что делает нейросеть полезной для пользователей.
https://sysblok.ru/digital-heritage/transkribus-kak-kompjuternoe-zrenie-pomogaet-perevodit-teksty-sirijskih-mistikov/
Ксения Костомарова
Системный Блокъ
Transkribus: как компьютерное зрение помогает переводить тексты сирийских мистиков
Чтобы разобрать написанное, часто нужен натренированный глаз. Добиться этого можно двумя способами: тренировать собственное зрение или компьютерное. Как и зачем тренируют модели распознавания рукописного текста — рассказываем в нашем материале
«Системный Блокъ» запускает онлайн-мастерскую проекта «Пишу тебе» — цифрового корпуса почтовых открыток. В коллекции проекта интересные и редкие открытки, по которым можно изучать историю, культуру и коммуникации между людьми. Мы хотим разделить с вами те открытия, которые делает команда проекта «Пишу тебе».
На онлайн-мастерской мы будем изучать открытку как объект визуальной и текстовой культуры и погрузимся в особенности расшифровочного дела. Вы получите специальный навык и узнаете новые детали об эпохе и повседневной жизни, сможете провести параллели и сделать исследовательские выводы.
Темой первой онлайн-мастерской 25 июля станут дореволюционные открытки из нашей коллекции. Работать с такими открытками одновременно и сложно из-за дореформенной орфографии и увлекательно из-за их необычного содержания. Они не шаблоны, и послания на них носят скорее личный характер. Дореволюционные открытки могут содержать довольно длинные тексты, касающиеся самых разных проблем, с которыми могли встретиться современники наших прапрадедушек: сложности с учебой, разлады в семье, конфликты с начальством на работе. Есть и открытки, посланные с полей Первой Мировой войны, о которой мы сегодня не так часто вспоминаем.
Для участников мастерской нет ограничений по возрасту и специальному образованию, но потребуется установить Zoom.
Мы приглашаем вас присоединиться к исследованиям и сделать свои открытия.
Программа онлайн-мастерской:
1. Презентация проекта онлайн-мастерской и проекта «Пишу тебе»
2. Расшифровка двух редких открыток
3. Работа в исследовательской группе с модератором проекта
4. Обсуждение работы и подведение итогов
Для участия в онлайн-мастерской необходимо зарегистрироваться по ссылке:
https://sysblok.timepad.ru/event/1712725/
На онлайн-мастерской мы будем изучать открытку как объект визуальной и текстовой культуры и погрузимся в особенности расшифровочного дела. Вы получите специальный навык и узнаете новые детали об эпохе и повседневной жизни, сможете провести параллели и сделать исследовательские выводы.
Темой первой онлайн-мастерской 25 июля станут дореволюционные открытки из нашей коллекции. Работать с такими открытками одновременно и сложно из-за дореформенной орфографии и увлекательно из-за их необычного содержания. Они не шаблоны, и послания на них носят скорее личный характер. Дореволюционные открытки могут содержать довольно длинные тексты, касающиеся самых разных проблем, с которыми могли встретиться современники наших прапрадедушек: сложности с учебой, разлады в семье, конфликты с начальством на работе. Есть и открытки, посланные с полей Первой Мировой войны, о которой мы сегодня не так часто вспоминаем.
Для участников мастерской нет ограничений по возрасту и специальному образованию, но потребуется установить Zoom.
Мы приглашаем вас присоединиться к исследованиям и сделать свои открытия.
Программа онлайн-мастерской:
1. Презентация проекта онлайн-мастерской и проекта «Пишу тебе»
2. Расшифровка двух редких открыток
3. Работа в исследовательской группе с модератором проекта
4. Обсуждение работы и подведение итогов
Для участия в онлайн-мастерской необходимо зарегистрироваться по ссылке:
https://sysblok.timepad.ru/event/1712725/
sysblok.timepad.ru
Онлайн-мастерская проекта "Пишу тебе" / События на TimePad.ru
“Системный Блокъ” запускает онлайн-мастерскую проекта “Пишу тебе” — цифрового корпуса почтовых открыток. Мы будем изучать открытку как объект визуальной и текстовой культуры и погрузимся в особенности расшифровочного дела. Приглашаем вас присоединиться…
«Орнамика»: цифровой архив узоров и вдохновение для дизайнера
#art
Цифровой проект «Орнамика» — это открытый архив узоров России, который насчитывает 8000 оригинальных орнаментов и 200 техник декоративно-прикладного искусства.
Проект разрабатывался в течение двух лет. Целью было создать хранилище, которое «помогало бы быстро представить себе все разнообразие стилей декоративно-прикладного искусства России». Создательница библиотеки, Мария Лолейт, планирует расширить коллекцию до 50 тыс. узоров. Платформа состоит из двух разделов: архива оригиналов и лаборатории.
Хранилище узоров
Архив «Орнамики» покрывает 11 веков, 50 регионов, 20 типов и более 200 техник и стилей искусства. Для упрощения поиска в поиск встроены фильтры.
• география объекта — к примеру, название федерального округа.
• время создания орнамента — можно выбрать в диапазоне IX — начала XX веков или указать «неизвестный век».
• вид искусства — художественная резьба по камню, бисероплетение, ковроткачество и т.д.
• композиция — бесконечная или симметричная, в зависимости от расположения узора.
• изображение на орнаменте — животные, птицы, растения, люди, надпись, здание, оружие, музыкальный инструмент и т.д.
• тип объекта — в зависимости от поверхности нанесения узора: одежда, текстиль, украшения, инструменты труда, печи и т.д.
Быстрее всего найти нужный узор можно по индивидуальному номеру.
Лаборатория «Орнамики»
• реконструкции — детальные цифровые копии исторических узоров. Например, реконструкции узоров из книги С.Н.Писарева «Древнерусский орнамент» 1903 года.
• интерпретации — примеры развития мотивов оригинальных узоров, созданные для решения современных графических задач. Пример: проект художницы Яны Кузнецовой, совмещающий узоры пазырыкской культуры и древнейшие качественные орнаментальные мотивы, обнаруженные в Горном Алтае в VI — III вв. до н.э.
• аналитика — экспертные статьи по отдельным направлениям узорной графики. Последняя актуальная статья «Детство в узорах» реконструирует быт и традиции, связанные с воспитанием детей в XIX веке.
https://sysblok.ru/?p=12074
Дарья Сотникова
#art
Цифровой проект «Орнамика» — это открытый архив узоров России, который насчитывает 8000 оригинальных орнаментов и 200 техник декоративно-прикладного искусства.
Проект разрабатывался в течение двух лет. Целью было создать хранилище, которое «помогало бы быстро представить себе все разнообразие стилей декоративно-прикладного искусства России». Создательница библиотеки, Мария Лолейт, планирует расширить коллекцию до 50 тыс. узоров. Платформа состоит из двух разделов: архива оригиналов и лаборатории.
Хранилище узоров
Архив «Орнамики» покрывает 11 веков, 50 регионов, 20 типов и более 200 техник и стилей искусства. Для упрощения поиска в поиск встроены фильтры.
• география объекта — к примеру, название федерального округа.
• время создания орнамента — можно выбрать в диапазоне IX — начала XX веков или указать «неизвестный век».
• вид искусства — художественная резьба по камню, бисероплетение, ковроткачество и т.д.
• композиция — бесконечная или симметричная, в зависимости от расположения узора.
• изображение на орнаменте — животные, птицы, растения, люди, надпись, здание, оружие, музыкальный инструмент и т.д.
• тип объекта — в зависимости от поверхности нанесения узора: одежда, текстиль, украшения, инструменты труда, печи и т.д.
Быстрее всего найти нужный узор можно по индивидуальному номеру.
Лаборатория «Орнамики»
• реконструкции — детальные цифровые копии исторических узоров. Например, реконструкции узоров из книги С.Н.Писарева «Древнерусский орнамент» 1903 года.
• интерпретации — примеры развития мотивов оригинальных узоров, созданные для решения современных графических задач. Пример: проект художницы Яны Кузнецовой, совмещающий узоры пазырыкской культуры и древнейшие качественные орнаментальные мотивы, обнаруженные в Горном Алтае в VI — III вв. до н.э.
• аналитика — экспертные статьи по отдельным направлениям узорной графики. Последняя актуальная статья «Детство в узорах» реконструирует быт и традиции, связанные с воспитанием детей в XIX веке.
https://sysblok.ru/?p=12074
Дарья Сотникова
{kind=link}
Как работает BERT
#knowhow #nlp
BERT или Bidirectional Encoder Representations from Transformers — это нейросетевая модель-трансформер от Google, на которой строится большинство инструментов автоматической обработки языка. Код модели выложен в открытый доступ. Саму нейросеть можно запустить как на локальном компьютере, так и на бесплатном серверном GPU на Google Colab.
Эмбеддинги и бенчмарки
Языковая модель работает с текстом, но для компьютера текст сам по себе ничего не значит. Чтобы закодировать текст в осмысленные числа, люди придумали векторные представления слов, которые основаны на контекстах употребления этих слов. Такие векторные представления называются эмбеддинги. Они кодируют семантические близости слов, причем с учетом контекста конкретного предложения.
Языковая модель принимает на вход эмбеддинги токенов и выдает результат в зависимости от задачи: стандартный набор задач, который выполняют на стандартном наборе данных, чтобы доказать, что нейросеть справляется с пониманием текста. Стандартные задачи называются в NLP бенчмарками («ориентир», «отметка» по-английски). BERT тестировали на наборах бенчмарков GLUE — «Оценка общего
понимания языка», SQuAD и SWAG.
Обучение нейросети
В зависимости от конечной цели используют либо машинное обучение с учителем (supervised learning), либо без него (unsupervised learning).
Для сложных нейросетей используют процессы «предобучения» и «дообучения». В первом методе нейросеть прогоняют на больших объемах текстов. Во втором – обнуляют финальный слой весов и тренируют модель на новом наборе данных.
Обучение BERT
Новшество BERTа — в способе предобучения. Ранние архитектуры, чтобы обучиться, предсказывали, какое слово вероятнее будет стоять следующим, учитывая слова до него. BERT же предобучается на «маскированной языковой модели»: нужно предсказать слово не в конце предложения, а посередине. Главная задача — угадать, какие слова пропущены (выдать числовой код) и сказать, подходит ли второе предложение к первому.
Для дообучения (файнтьюнинга) в BERT не нужно стирать «часть памяти» модели. Вместо этого «поверх» модели добавляют новый слой нейронов. Его матрицы весов заполнены случайными числами, которые настраивают так, чтобы на новой задаче ошибка была минимальной.
BERT используется в Google: поначалу эта модель работала только для английского языка, позже добавили в поиск и на других языках. Нейросеть можно использовать для модерации текстов, поиска ответов на юридические вопросы, оптимизации работы с SEO-сайтами. Кроме того, практически половина NLP использует BERT и BERT-подобные архитектуры.
https://sysblok.ru/knowhow/kak-ustroena-nejroset-bert-ot-google/
Камилла Кубелекова, Владимир Селеверстов
#knowhow #nlp
BERT или Bidirectional Encoder Representations from Transformers — это нейросетевая модель-трансформер от Google, на которой строится большинство инструментов автоматической обработки языка. Код модели выложен в открытый доступ. Саму нейросеть можно запустить как на локальном компьютере, так и на бесплатном серверном GPU на Google Colab.
Эмбеддинги и бенчмарки
Языковая модель работает с текстом, но для компьютера текст сам по себе ничего не значит. Чтобы закодировать текст в осмысленные числа, люди придумали векторные представления слов, которые основаны на контекстах употребления этих слов. Такие векторные представления называются эмбеддинги. Они кодируют семантические близости слов, причем с учетом контекста конкретного предложения.
Языковая модель принимает на вход эмбеддинги токенов и выдает результат в зависимости от задачи: стандартный набор задач, который выполняют на стандартном наборе данных, чтобы доказать, что нейросеть справляется с пониманием текста. Стандартные задачи называются в NLP бенчмарками («ориентир», «отметка» по-английски). BERT тестировали на наборах бенчмарков GLUE — «Оценка общего
понимания языка», SQuAD и SWAG.
Обучение нейросети
В зависимости от конечной цели используют либо машинное обучение с учителем (supervised learning), либо без него (unsupervised learning).
Для сложных нейросетей используют процессы «предобучения» и «дообучения». В первом методе нейросеть прогоняют на больших объемах текстов. Во втором – обнуляют финальный слой весов и тренируют модель на новом наборе данных.
Обучение BERT
Новшество BERTа — в способе предобучения. Ранние архитектуры, чтобы обучиться, предсказывали, какое слово вероятнее будет стоять следующим, учитывая слова до него. BERT же предобучается на «маскированной языковой модели»: нужно предсказать слово не в конце предложения, а посередине. Главная задача — угадать, какие слова пропущены (выдать числовой код) и сказать, подходит ли второе предложение к первому.
Для дообучения (файнтьюнинга) в BERT не нужно стирать «часть памяти» модели. Вместо этого «поверх» модели добавляют новый слой нейронов. Его матрицы весов заполнены случайными числами, которые настраивают так, чтобы на новой задаче ошибка была минимальной.
BERT используется в Google: поначалу эта модель работала только для английского языка, позже добавили в поиск и на других языках. Нейросеть можно использовать для модерации текстов, поиска ответов на юридические вопросы, оптимизации работы с SEO-сайтами. Кроме того, практически половина NLP использует BERT и BERT-подобные архитектуры.
https://sysblok.ru/knowhow/kak-ustroena-nejroset-bert-ot-google/
Камилла Кубелекова, Владимир Селеверстов
{kind=link}
TikTok — самое популярное приложение в России и в мире. Бум ТикТока больше нельзя игнорировать. Поэтому «Системный Блокъ» запускает серию образовательных роликов о языках мира. Лингвист и популяризатор науки Александр Пиперски рассказывает о том, чем интересны разные языки, как эти языки связаны с русским (если связаны), какие в них есть любопытные звуки и слова.
Первый выпуск посвящен сербскому языку. Чем интересен сербский:
— Кириллица или latinica? Не важно! Сербы могут писать на своем языке и так, и так.
— В сербском есть жуткие сочетания согласных с р. «На врх брда врба мрда» — нормальная сербская фраза.
— В сербском много слов, похожих на русские, но некоторые сходства обманчивы: «неделя», «банка», «право» и «позориште» значат совсем не то, что вы подумали.
https://vm.tiktok.com/ZSJnUuHtB/
Первый выпуск посвящен сербскому языку. Чем интересен сербский:
— Кириллица или latinica? Не важно! Сербы могут писать на своем языке и так, и так.
— В сербском есть жуткие сочетания согласных с р. «На врх брда врба мрда» — нормальная сербская фраза.
— В сербском много слов, похожих на русские, но некоторые сходства обманчивы: «неделя», «банка», «право» и «позориште» значат совсем не то, что вы подумали.
https://vm.tiktok.com/ZSJnUuHtB/
{kind=link}
UniLM — языковая модель для тех, кому мало BERT
#nlp
Мы уже рассказывали о языковых моделях BERT и GPT-2. Теперь разбираемся, как работает еще одна нейросетевая языковая модель.
UniLM расшифровывается как Unified pre-training Language Model. По архитектуре это многослойный трансформер, предварительно обученный на больших объемах текста. В отличие от BERT, UniLM используют как для задач понимания естественного языка (NLU), так и для генерации задач для NLU — NLG (Natural Language Generation).
Обучение нейросети
Обычно для обучения нейросетей используются три типа задач языкового моделирования (LM, Language Model): однонаправленная LM, двунаправленная LM, sequence-to-sequence LM. В случае с UniLM происходит единый процесс обучения и используется одна языковая модель Transformeк с общими параметрами и архитектурой для различных видов моделирования. Сеть не нужно отдельно обучать каждой задаче и отдельно хранить результаты.
Представление текста в UniLM такое же, как в BERT: сначала текст токенизируется, для этого используется алгоритм WordPiece: текст делится на ограниченный набор «подслов», частей слов. Из входной последовательности токенов случайным образом выбираются некоторые токены и заменяются на специальный токен MASK. Далее нейросеть обучается предсказывать замененные токены — стандартный на сегодня способ тренировки языковых моделей.
Для различных задач языкового моделирования используются различные матрицы масок.
• однонаправленная LM — использование left-to-right, right-to-left задач языкового моделирования.
• двунаправленная LM — кодировка контекстной информации и генерация контекстных представлений текста.
• sequence-to-sequence LM — при генерации токена участвуют токены из первой последовательности (источника), а из второй (целевой) последовательности берутся только токены слева от целевого токена и сам целевой токен. В итоге, для токенов в целевой последовательности блокируются токены, расположенные справа от них.
Архитектура UniLM соответствует архитектуре BERT LARGE. Размер словаря — 28 996 токенов, максимальная длина входной последовательности — 512. Вероятность маскирования токена составляет 15%. Процедура обучения состоит из 770 000 шагов.
Результаты работы UniLM
Нейросетевая языковая модель использовалась для задач автоматического реферирования — генерации краткого резюме входного текста. В качестве входных данных использовался датасет CNN / Daily Mail и корпус Gigaword для дообучения модели.
Так же модель тестировали на задаче ответов на вопросы — QA (Question Answering). Задача состоит в том, чтобы ответить на вопрос с учетом отрывка текста. Есть два варианта задачи: с извлечением ответа из текста и с порождением ответа на основе текста. Эксперименты показали, что при генерации ответов UniLM по качеству превосходит результаты лучших на момент проведения экспериментов моделей: Seq2Seq и PGNet.
Применение модели
Архитектура UniLM подходит для решения задач языкового моделирования, однако для конкретной задачи по-прежнему требуется дообучение на специфических данных для конкретной задачи. Это ограничивает применение языковой модели в практических целях: к примеру, для исправления грамматики или генерации рецензии к короткому рассказу трудно собрать набор дообучающих данных.
Нередко случается, что большие предобученные модели не обобщаются для узкоспециализированных задач. Поэтому появляются модели, для обучения которых используют метод контекстного обучения.
https://sysblok.ru/nlp/unilm-jazykovaja-model-dlja-teh-komu-malo-bert/
Светлана Бесаева
#nlp
Мы уже рассказывали о языковых моделях BERT и GPT-2. Теперь разбираемся, как работает еще одна нейросетевая языковая модель.
UniLM расшифровывается как Unified pre-training Language Model. По архитектуре это многослойный трансформер, предварительно обученный на больших объемах текста. В отличие от BERT, UniLM используют как для задач понимания естественного языка (NLU), так и для генерации задач для NLU — NLG (Natural Language Generation).
Обучение нейросети
Обычно для обучения нейросетей используются три типа задач языкового моделирования (LM, Language Model): однонаправленная LM, двунаправленная LM, sequence-to-sequence LM. В случае с UniLM происходит единый процесс обучения и используется одна языковая модель Transformeк с общими параметрами и архитектурой для различных видов моделирования. Сеть не нужно отдельно обучать каждой задаче и отдельно хранить результаты.
Представление текста в UniLM такое же, как в BERT: сначала текст токенизируется, для этого используется алгоритм WordPiece: текст делится на ограниченный набор «подслов», частей слов. Из входной последовательности токенов случайным образом выбираются некоторые токены и заменяются на специальный токен MASK. Далее нейросеть обучается предсказывать замененные токены — стандартный на сегодня способ тренировки языковых моделей.
Для различных задач языкового моделирования используются различные матрицы масок.
• однонаправленная LM — использование left-to-right, right-to-left задач языкового моделирования.
• двунаправленная LM — кодировка контекстной информации и генерация контекстных представлений текста.
• sequence-to-sequence LM — при генерации токена участвуют токены из первой последовательности (источника), а из второй (целевой) последовательности берутся только токены слева от целевого токена и сам целевой токен. В итоге, для токенов в целевой последовательности блокируются токены, расположенные справа от них.
Архитектура UniLM соответствует архитектуре BERT LARGE. Размер словаря — 28 996 токенов, максимальная длина входной последовательности — 512. Вероятность маскирования токена составляет 15%. Процедура обучения состоит из 770 000 шагов.
Результаты работы UniLM
Нейросетевая языковая модель использовалась для задач автоматического реферирования — генерации краткого резюме входного текста. В качестве входных данных использовался датасет CNN / Daily Mail и корпус Gigaword для дообучения модели.
Так же модель тестировали на задаче ответов на вопросы — QA (Question Answering). Задача состоит в том, чтобы ответить на вопрос с учетом отрывка текста. Есть два варианта задачи: с извлечением ответа из текста и с порождением ответа на основе текста. Эксперименты показали, что при генерации ответов UniLM по качеству превосходит результаты лучших на момент проведения экспериментов моделей: Seq2Seq и PGNet.
Применение модели
Архитектура UniLM подходит для решения задач языкового моделирования, однако для конкретной задачи по-прежнему требуется дообучение на специфических данных для конкретной задачи. Это ограничивает применение языковой модели в практических целях: к примеру, для исправления грамматики или генерации рецензии к короткому рассказу трудно собрать набор дообучающих данных.
Нередко случается, что большие предобученные модели не обобщаются для узкоспециализированных задач. Поэтому появляются модели, для обучения которых используют метод контекстного обучения.
https://sysblok.ru/nlp/unilm-jazykovaja-model-dlja-teh-komu-malo-bert/
Светлана Бесаева
{kind=link}