
В "Толковом словаре живого великорусского языка" В.И. Даля 200 тысяч слов. В "Большом академическом словаре" -- 150 тысяч. В "Малом академическом словаре" -- 90 тысяч. В "Словаре языка Пушкина" -- 21 тысяча. А сколько слов в вашем арсенале?
Чтобы проверить это, вовсе не нужно открывать Даля или БАС и отмечать все знакомые слова: хитрому алгоритму нужно всего лишь 15-20 вопросов, чтобы оценить ваш словарный запас. А заодно то, насколько честно вы отвечали. 😏
https://telegra.ph/Defenestraciya-Ne-ne-slyshal-09-23
Чтобы проверить это, вовсе не нужно открывать Даля или БАС и отмечать все знакомые слова: хитрому алгоритму нужно всего лишь 15-20 вопросов, чтобы оценить ваш словарный запас. А заодно то, насколько честно вы отвечали. 😏
https://telegra.ph/Defenestraciya-Ne-ne-slyshal-09-23
Telegraph
Дефенестрация? Не, не слышал!
Уже несколько лет люди охотно делятся в соцсетях результатами теста своего словарного запаса. Выглядит это так: Ваш пассивный словарный запас — 88000 слов. Ваш индекс честности — 90%. Предлагаем заглянуть под капот этого теста и посмотреть какие технологии…
Задумывались ли вы о том, какие города и страны чаще всего упоминаются в стихах русских поэтов? А вот исследователи Борис Орехов и Елизавета Кузьменко задумались — и проанализировали поэтический корпус размером в 11 миллионов слов. Где жили лирические герои на протяжении трех веков? Как путешествовали? Куда устремлялись в мечтах? Оказывается, наиболее значимые места на поэтической карте можно определить с помощью нехитрых подсчетов.
https://telegra.ph/ZHit-i-umeret-v-Parizhe-300-let-russkoj-poehzii-na-karte-09-01
https://telegra.ph/ZHit-i-umeret-v-Parizhe-300-let-russkoj-poehzii-na-karte-09-01
Telegraph
«Жить и умереть в Париже»: 300 лет русской поэзии на карте
Исследование проводилось на поэтическом подкорпусе Национального корпуса русского языка. Он содержит тексты русских поэтов, написанные в XVIII — XXI веках. Авторы исследования выделили в текстах упоминания стран и городов, вычислили те, что встречаются чаще…
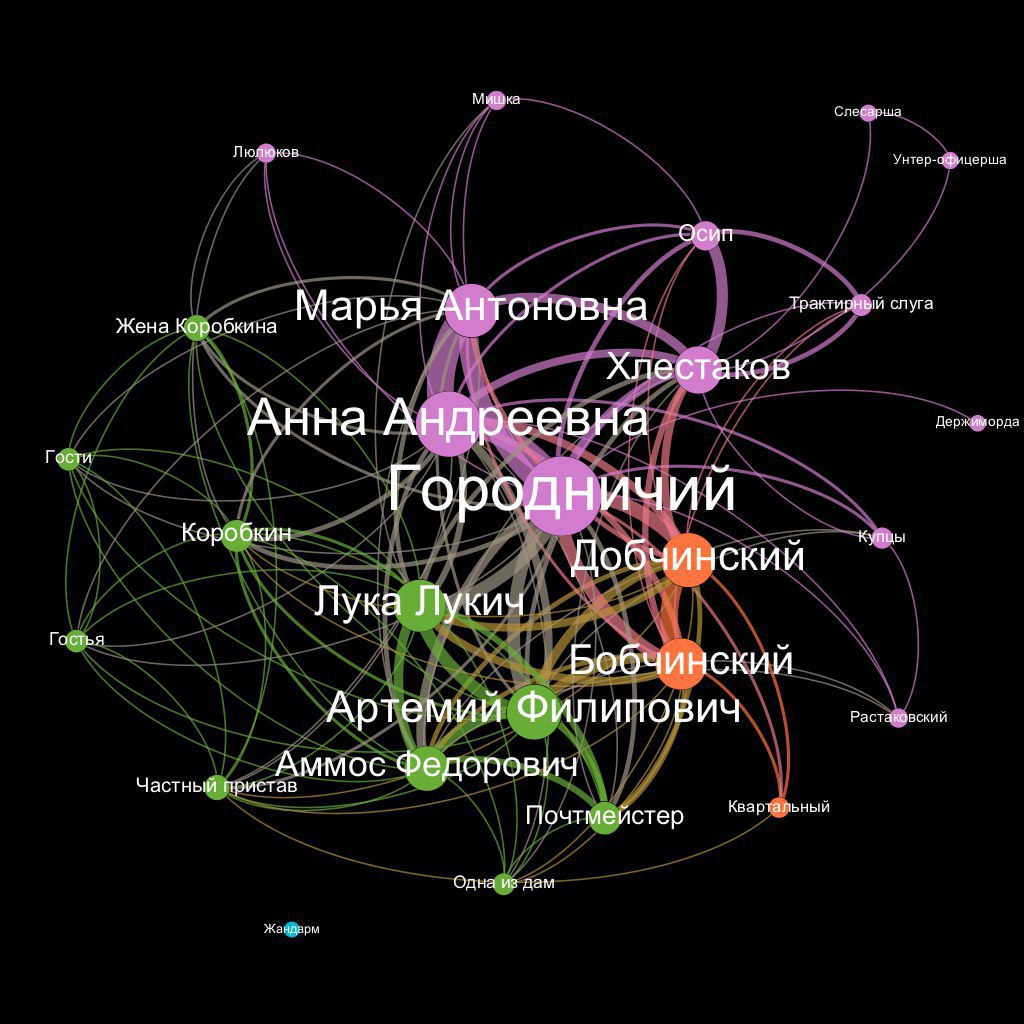
Сегодня мы продолжим разговор о цифровом литературоведении и обратимся к сетевому анализу, или анализу социальных графов. Но граф — это что-то страшное из математики, а социальные сети — это Вконтакте и Facebook! При чем здесь литературоведение?
Социальные сети бывают не только реальные, но и вымышленные. Например, не так уж сложно себе представить фейсбук Евгения Онегина: как он сначала френдит весь петербургский «свет», потом всех удаляет, потом ставит лайки Ольге Лариной, а сам тем временем разглядывает фото в профиле Татьяны. Тут Ленский ставит «Возмутительно», пишет злой коммент — и заверте...
Изучать соцсети художественных персонажей можно теми же способами, что и реальные. Социологи давно применяют теорию графов и методы анализа сетей, чтобы выделять сообщества, находить в них «центры влияния» и лидеров мнений, анализировать пути распространения информации и власти. С недавних пор тем же занялись и литературоведы — и это уже дало много интересных результатов. Например, известный «цифровой литературовед» Франко Моретти нашел зону смерти в социальной сети «Гамлета»: там умирают только те, кто одновременно тесно связан с самим Гамлетом и с его злодеем-дядей, королем Клавдием. Этот факт можно было вывести и без сетевого анализа, но он не приходил в голову никому до тех пор, пока сеть диалогов персонажей «Гамлета» не была построена и визуализирована.
На русском материале интересные результаты дал анализ произведений А. С. Пушкина и Л. Н. Толстого. Например, в «Войне и мире» структура сетей совпадает с сюжетной динамикой: они плотные в мирное время, разрозненные в военное; Ростовы образуют плотное сообщество, а Курагины (о которых литературоведы давно пишут, что они «лишены семейной поэзии»), никакого сообщества не образуют. А в пушкинском «Борисе Годунове» удалось выявить особого персонажа-посланника, который — и это явно не совпадение — носит фамилию автора. Гаврилу Пушкина никто не назовет главным героем, но сетевые метрики показывают, что он самый главный «промежуточный» персонаж, через которого проходит коммуникация. И это правда так. Сейчас та же команда «цифровых филологов» из НИУ ВШЭ ведет уже автоматический поиск похожих персонажей (агентов, посланников, шпионов) в других пьесах при помощи сетевого анализа — и кое-что уже нашла. Об этом в следующих выпусках.
Социальные сети бывают не только реальные, но и вымышленные. Например, не так уж сложно себе представить фейсбук Евгения Онегина: как он сначала френдит весь петербургский «свет», потом всех удаляет, потом ставит лайки Ольге Лариной, а сам тем временем разглядывает фото в профиле Татьяны. Тут Ленский ставит «Возмутительно», пишет злой коммент — и заверте...
Изучать соцсети художественных персонажей можно теми же способами, что и реальные. Социологи давно применяют теорию графов и методы анализа сетей, чтобы выделять сообщества, находить в них «центры влияния» и лидеров мнений, анализировать пути распространения информации и власти. С недавних пор тем же занялись и литературоведы — и это уже дало много интересных результатов. Например, известный «цифровой литературовед» Франко Моретти нашел зону смерти в социальной сети «Гамлета»: там умирают только те, кто одновременно тесно связан с самим Гамлетом и с его злодеем-дядей, королем Клавдием. Этот факт можно было вывести и без сетевого анализа, но он не приходил в голову никому до тех пор, пока сеть диалогов персонажей «Гамлета» не была построена и визуализирована.
На русском материале интересные результаты дал анализ произведений А. С. Пушкина и Л. Н. Толстого. Например, в «Войне и мире» структура сетей совпадает с сюжетной динамикой: они плотные в мирное время, разрозненные в военное; Ростовы образуют плотное сообщество, а Курагины (о которых литературоведы давно пишут, что они «лишены семейной поэзии»), никакого сообщества не образуют. А в пушкинском «Борисе Годунове» удалось выявить особого персонажа-посланника, который — и это явно не совпадение — носит фамилию автора. Гаврилу Пушкина никто не назовет главным героем, но сетевые метрики показывают, что он самый главный «промежуточный» персонаж, через которого проходит коммуникация. И это правда так. Сейчас та же команда «цифровых филологов» из НИУ ВШЭ ведет уже автоматический поиск похожих персонажей (агентов, посланников, шпионов) в других пьесах при помощи сетевого анализа — и кое-что уже нашла. Об этом в следующих выпусках.
{kind=link}
Что читать современному лингвисту/филологу?
Телеграм стал площадкой для нишевых сообществ с уникальным контентом. Мы будем рассказывать о каналах, которые читаем сами. В нашем первом обзоре — четыре канала о лингвистике, четыре канала о литературе и два — о цифровых гуманитарных исследованиях.
— @linguistique_sur_un_genou — Лингвистика на коленке
"Лингвист-дилетант" Ксения пишет, в основном, о компьютерной лингвистике и романских языках. Но здесь не только обзоры лучших курсов по NLP и интересные лингвистические факты, здесь ещё и истории из жизни о собеседованиях на иностранном языке, переводах и французском лингвистическом быте.
— @linguisticmadness — Linguistic Madness
Канал о лингвистике и языках: ссылки, статьи, мнения, факты. Что если переделать "Иронию судьбы" на бандитский манер? Как выглядят граффити для незрячих? Что такое ирландский перфект в английском? Кто говорит на аэрском? И прочие лингвистические безумства.
— @vooiox — уЩербы
Увлекательные рассказы о том, откуда взялось слово "чувак", что такое гражданский брак и можно ли говорить звОнит. В общем, вся правда о русском языке, которую скрывали от нас в школе.
— @word4power — Word4Power
Канал убежденного последователя святого Иеронима о переводах и лингвистике. Будни синхрониста, полезные переводчику книжки и статьи, лингвистические откровения о русском, украинском, английском и французском. Где еще вы узнаете, как делаются субтитры к фильмам и театральным постановкам и в чем разница между Yob's comma и Oxford comma?
— @theodstavec — О литературе и около неё
Команда этого проекта, название которого в переводе с чешского означает "абзац", делает переводы статей, эссе, рецензий и заметок мировых ресурсов о литературе, чтобы они стали доступнее русскоязычному читателю. А ещё там можно опубликовать свою литературоведческую статью.
— @bookngrill — Книги жарь
Канал студента первой магистратуры Creative Writing в России. Новости современной литературы, советы начинающим писателям, литературоведческий ликбез и просто образец хорошего текста.
— @sashaandleo — Саша и Лев
Дайджест литературных новостей со всего мира — о книжных фестивалях, экранизациях, встречах с писателями, литературных премиях.
— @words_and_money — Слова и деньги
Про книги из электронов и из бумаги, деньги из книг, книги без денег и всякое прочее. Издательства, книжные ярмарки, нелитературная сторона мира литературы. По мотивам «Слов и денег» Андре Шиффрина.
— @Sense_catcher — Библиотечная крыса
Авторский канал о книгах и чтении в цифровую эпоху, "чердак цифрового литературоведа". Здесь и рассуждения о судьбах литературы и ее исследователей, и размышления о современном книгоиздании, и личные впечаления от выездных школ и курсов по Digital Humanities, и рассказы об интересных проектах в современной филологии.
— @sysblok — Системный Блокъ
Канал о переходе культуры в цифру и применении технологий в гуманитарных науках и искусстве. Как лингвисты ловят маньяков и какие сны снятся нейросетям? Что скрывают от нас соцсети персонажей? Может ли искусственный интеллект залипнуть у телевизора? Системный Блокъ — это современный Вергилий, который проведет вас через девять кругов Big Data.
Хотите рассказать нам о своем любимом сообществе? Мы уже собираем продолжение. Пишите.
Телеграм стал площадкой для нишевых сообществ с уникальным контентом. Мы будем рассказывать о каналах, которые читаем сами. В нашем первом обзоре — четыре канала о лингвистике, четыре канала о литературе и два — о цифровых гуманитарных исследованиях.
— @linguistique_sur_un_genou — Лингвистика на коленке
"Лингвист-дилетант" Ксения пишет, в основном, о компьютерной лингвистике и романских языках. Но здесь не только обзоры лучших курсов по NLP и интересные лингвистические факты, здесь ещё и истории из жизни о собеседованиях на иностранном языке, переводах и французском лингвистическом быте.
— @linguisticmadness — Linguistic Madness
Канал о лингвистике и языках: ссылки, статьи, мнения, факты. Что если переделать "Иронию судьбы" на бандитский манер? Как выглядят граффити для незрячих? Что такое ирландский перфект в английском? Кто говорит на аэрском? И прочие лингвистические безумства.
— @vooiox — уЩербы
Увлекательные рассказы о том, откуда взялось слово "чувак", что такое гражданский брак и можно ли говорить звОнит. В общем, вся правда о русском языке, которую скрывали от нас в школе.
— @word4power — Word4Power
Канал убежденного последователя святого Иеронима о переводах и лингвистике. Будни синхрониста, полезные переводчику книжки и статьи, лингвистические откровения о русском, украинском, английском и французском. Где еще вы узнаете, как делаются субтитры к фильмам и театральным постановкам и в чем разница между Yob's comma и Oxford comma?
— @theodstavec — О литературе и около неё
Команда этого проекта, название которого в переводе с чешского означает "абзац", делает переводы статей, эссе, рецензий и заметок мировых ресурсов о литературе, чтобы они стали доступнее русскоязычному читателю. А ещё там можно опубликовать свою литературоведческую статью.
— @bookngrill — Книги жарь
Канал студента первой магистратуры Creative Writing в России. Новости современной литературы, советы начинающим писателям, литературоведческий ликбез и просто образец хорошего текста.
— @sashaandleo — Саша и Лев
Дайджест литературных новостей со всего мира — о книжных фестивалях, экранизациях, встречах с писателями, литературных премиях.
— @words_and_money — Слова и деньги
Про книги из электронов и из бумаги, деньги из книг, книги без денег и всякое прочее. Издательства, книжные ярмарки, нелитературная сторона мира литературы. По мотивам «Слов и денег» Андре Шиффрина.
— @Sense_catcher — Библиотечная крыса
Авторский канал о книгах и чтении в цифровую эпоху, "чердак цифрового литературоведа". Здесь и рассуждения о судьбах литературы и ее исследователей, и размышления о современном книгоиздании, и личные впечаления от выездных школ и курсов по Digital Humanities, и рассказы об интересных проектах в современной филологии.
— @sysblok — Системный Блокъ
Канал о переходе культуры в цифру и применении технологий в гуманитарных науках и искусстве. Как лингвисты ловят маньяков и какие сны снятся нейросетям? Что скрывают от нас соцсети персонажей? Может ли искусственный интеллект залипнуть у телевизора? Системный Блокъ — это современный Вергилий, который проведет вас через девять кругов Big Data.
Хотите рассказать нам о своем любимом сообществе? Мы уже собираем продолжение. Пишите.
В одном из прошлых постов мы рассказывали, что такое сетевой анализ литературных произведений. Но как применить это в исследованиях? Цифровые филологи из Германии знают ответ! Оказывается, комедии и трагедии отличаются по структуре социальной сети геров, так что можно определить жанр произведения, просто взглянув на граф.
https://telegra.ph/Drama-v-seti-09-01
https://telegra.ph/Drama-v-seti-09-01
Telegraph
Праздник или смерть? Драма в сети!
Мы уже писали о том, как анализ социальных сетей (социальных графов) персонажей произведения помогает филологам в исследованиях. Сеть общения героев — своеобразный скелет текста, в котором можно увидеть неявные структурные особенности, героев-«проводников»…
Как вы думаете, что скрывается за загадочным термином "N-граммы"? Программы? Нет, все не так уж страшно. N-граммы — это такие хитрые последовательности звуков, слогов, слов или букв и они очень важны для компьютерной лингвистики. В этой статье мы расскажем, как они устроены и чем помогают при автоматической обработке текста.
https://telegra.ph/N-grammy-09-01
https://telegra.ph/N-grammy-09-01
Telegraph
Что такое N-граммы и с чем их едят?
N-грамма — это просто последовательность из n элементов (звуков, слогов, слов или букв). На практике чаще имеют в виду ряд слов (реже — букв). Последовательность из двух последовательных элементов называют биграмма, из трёх элементов — триграмма. Например…
За несколько тысяч лет нарратив претерпел значительные изменения, эволюционировав от устной истории до ветвящихся сценариев компьютерных игр через стадии классического романа и постмодернистского текста-калейдоскопа.
Впрочем, цифровой нарратив не ограничивается компьютерными играми – это любой интерактивный мультисенсорный текст, который нельзя превратить в печатную версию без существенных потерь. Итак, в сегодняшней статье мы рассказываем об особенностях и формах цифрового нарратива.
https://telegra.ph/Multinarrativ-programmiruemaya-istoriya-10-21
Впрочем, цифровой нарратив не ограничивается компьютерными играми – это любой интерактивный мультисенсорный текст, который нельзя превратить в печатную версию без существенных потерь. Итак, в сегодняшней статье мы рассказываем об особенностях и формах цифрового нарратива.
https://telegra.ph/Multinarrativ-programmiruemaya-istoriya-10-21
Telegraph
Мультинарратив: программируемая история
Долгое время люди рассказывали друг другу истории только устно. Поскольку память имеет ограниченный ресурс, эти истории обычно звучали в разных вариациях. С появлением письменности сюжеты историй оказались «заморожены» — и стали четко определенными последовательностями…
Сегодня у Соловецкого камня в Москве читают имена жертв репрессий. Но можем ли мы действительно назвать всех? Имена жертв — и имена палачей? Ко Дню памяти жертв репрессий — рассказ о базах данных «Международного Мемориала» @toposmemoru.
https://telegra.ph/Bolshie-dannye-Bolshogo-terrora-10-28
https://telegra.ph/Bolshie-dannye-Bolshogo-terrora-10-28
Telegraph
Большие данные Большого террора
Жертвами советского государственного террора стали миллионы людей. От тех, кто погребен в расстрельных рвах Бутовского полигона и «Коммунарки», надорвался на Беломорканале или замерз на рудниках Колымы, не осталось почти ничего. Но репрессивная машина не…
Нейросеть научилась диагностировать депрессию
Исследователи из Массачуссетского технологического института (MIT) разработали алгоритм диагностики депрессии на основе нейросети. Модель ставит диагноз по аудиозаписям и текстовыми расшифровкам интервью с пациентами, обнаруживая в речи специфические «депрессивные паттерны».
Ранее машинное обучение уже применялось для помощи психологам в диагностике. Однако прежде алгоритмы оценивали конкретные ответы на конкретные вопросы, что накладывало сильные ограничения на применимость. Новый алгоритм позволяет анализировать произвольные разговоры пациента.
Исследователи надеются, что в будущем их разработка может быть встроена в мобильные приложения, которые следят за здоровьем. Тогда первые признаки депрессии можно будет отловить задолго до того, как человек соберется ко врачу или в форточку.
Подробнее узнать о нейросети-психологе можно тут.
#neuroscience #sysblok
Исследователи из Массачуссетского технологического института (MIT) разработали алгоритм диагностики депрессии на основе нейросети. Модель ставит диагноз по аудиозаписям и текстовыми расшифровкам интервью с пациентами, обнаруживая в речи специфические «депрессивные паттерны».
Ранее машинное обучение уже применялось для помощи психологам в диагностике. Однако прежде алгоритмы оценивали конкретные ответы на конкретные вопросы, что накладывало сильные ограничения на применимость. Новый алгоритм позволяет анализировать произвольные разговоры пациента.
Исследователи надеются, что в будущем их разработка может быть встроена в мобильные приложения, которые следят за здоровьем. Тогда первые признаки депрессии можно будет отловить задолго до того, как человек соберется ко врачу или в форточку.
Подробнее узнать о нейросети-психологе можно тут.
#neuroscience #sysblok
{kind=link}
В последнее время тема искусственного интеллекта стала очень популярной. Сложно поверить, но его история началась почти 100 лет назад! За это время он прошел немало эволюционных этапов, от идеи «Россумских универсальных роботов» Карела Чапека до самообучающихся нейросетей.
Сегодня мы поговорим о юности и двух «зимах» искуственного интеллекта, об изобретении теста Тьюринга и об экспертных системах.
https://telegra.ph/Kratkaya-istoriya-iskusstvennogo-intellekta-chast-I-11-05
Сегодня мы поговорим о юности и двух «зимах» искуственного интеллекта, об изобретении теста Тьюринга и об экспертных системах.
https://telegra.ph/Kratkaya-istoriya-iskusstvennogo-intellekta-chast-I-11-05
Telegraph
Краткая история искусственного интеллекта (часть I)
Предисловие В последнее время тема искусственного интеллекта стала очень популярной. Но что такое ИИ на самом деле? Каких результатов он уже достиг и в каком направлении будет развиваться в будущем? Вокруг этой темы ведется много споров. Сначала неплохо выяснить…
Вчера мы писали о ранних этапах эволюции искусственного интеллекта, а теперь обратимся к современности и посмотрим, что такое Deep Blue и Deep Mind, каких результатов достиг искусственный интеллект в XXI веке и в каком направлении он будет развиваться в будущем.
https://telegra.ph/Kratkaya-istoriya-iskusstvennogo-intellekta-chast-II-11-05
https://telegra.ph/Kratkaya-istoriya-iskusstvennogo-intellekta-chast-II-11-05
Telegraph
Краткая история искусственного интеллекта (часть II)
В предыдущей части мы рассказали, как зарождались идеи ИИ, а теперь обратимся к современности. Deep Blue После долгих лет взлетов и падений произошло значимое событие для ИИ: 11 мая 1997 года шахматный суперкомпьютер Deep Blue, разработанный компанией IBM…
В двух предыдущих статьях мы рассказывали об истории искусственного интеллекта, а теперь перейдём непосредственно к нейронным сетям — первой технологии, которая действительно напоминает интеллект.
Нейросети порождают никогда до этого не существовавшие слова и тексты, пишут картины, успешно управляют беспилотными машинами в незнакомой местности, распознают объекты на снимках гораздо точнее человека, а также видят в данных сложные закономерности.
Как устроены эти алгоритмы? Что такое искусственные нейроны и чем они отличаются от настоящих? И кто же все-таки победит: мозг или компьютер?
#knowhow #sysblok
https://telegra.ph/Mozg-protiv-kompyutera-11-05
Нейросети порождают никогда до этого не существовавшие слова и тексты, пишут картины, успешно управляют беспилотными машинами в незнакомой местности, распознают объекты на снимках гораздо точнее человека, а также видят в данных сложные закономерности.
Как устроены эти алгоритмы? Что такое искусственные нейроны и чем они отличаются от настоящих? И кто же все-таки победит: мозг или компьютер?
#knowhow #sysblok
https://telegra.ph/Mozg-protiv-kompyutera-11-05
Telegraph
Мозг против компьютера
Нейронные сети — первая искусственная технология, которая действительно напоминает интеллект. Нейросети порождают никогда до этого не существовавшие слова и тексты, пишут картины, успешно управляют беспилотными машинами в незнакомой местности, распознают…
Нагугли мелодию: поисковик для музыкантов
IncipitSearch — метапоисковик, который умеет искать по размеченным нотным текстам, размещенным в открытом доступе. Для поиска нужно при помощи виртуальной клавиатуры фортепиано ввести начальную фразу музыкального произведения — так называемый инципит.
Впервые идея создания человеко- и машиночитаемого формата, который бы позволял искать произведения по начальным звукам мелодии, возникла еще в 1960-е годы. Тогда в помощь музыкальным библиотекарям был создан Plaine & Easie Code, который переводит нотный текст в комбинацию цифр и букв.
IncipitSearch опирается на Plaine & Easie, однако ставит своей задачей пойти дальше — например, научиться читать другие форматы, такие как abc notation и MEI, о котором мы уже писали.
К настоящему моменту IncipitSearch позволяет искать по инципитам музыкальных произведений, находящихся в следующих каталогах: Полное собрание сочинений Кристофа Виллибальда Глюка (Christoph Willibald Gluck — Sämtliche Werke), Каталог Национальной библиотечной службы Италии (SBN OPAC), Международный каталог музыкальных источников (RISM OPAC) и выборочные данные из Каталога симфоний издательства Breitkopf за 1762 год.
#musicology #sysblok
IncipitSearch — метапоисковик, который умеет искать по размеченным нотным текстам, размещенным в открытом доступе. Для поиска нужно при помощи виртуальной клавиатуры фортепиано ввести начальную фразу музыкального произведения — так называемый инципит.
Впервые идея создания человеко- и машиночитаемого формата, который бы позволял искать произведения по начальным звукам мелодии, возникла еще в 1960-е годы. Тогда в помощь музыкальным библиотекарям был создан Plaine & Easie Code, который переводит нотный текст в комбинацию цифр и букв.
IncipitSearch опирается на Plaine & Easie, однако ставит своей задачей пойти дальше — например, научиться читать другие форматы, такие как abc notation и MEI, о котором мы уже писали.
К настоящему моменту IncipitSearch позволяет искать по инципитам музыкальных произведений, находящихся в следующих каталогах: Полное собрание сочинений Кристофа Виллибальда Глюка (Christoph Willibald Gluck — Sämtliche Werke), Каталог Национальной библиотечной службы Италии (SBN OPAC), Международный каталог музыкальных источников (RISM OPAC) и выборочные данные из Каталога симфоний издательства Breitkopf за 1762 год.
#musicology #sysblok
{kind=link}
Роботы научились обыгрывать людей в го, но задача освоить человеческий язык, вести дискуссии и убеждать долгое время оставалась не по зубам искусственному интеллекту.
Недавно мы рассказывали о роботе, который дважды победил человека в дебатах. Теперь разберемся, как машина научилась быть убедительным оппонентом.
#nlp #sysblok
https://telegra.ph/ZHeleznye-argumenty-kak-ustroen-Project-Debator-11-05
Недавно мы рассказывали о роботе, который дважды победил человека в дебатах. Теперь разберемся, как машина научилась быть убедительным оппонентом.
#nlp #sysblok
https://telegra.ph/ZHeleznye-argumenty-kak-ustroen-Project-Debator-11-05
Telegraph
Железные аргументы: как устроен Project Debator
Недавно мы рассказывали о роботе, который дважды победил человека в дебатах. Теперь разберемся, как машина научилась быть убедительным оппонентом. В чём сложность? Роботы научились обыгрывать людей в го, но задача освоить человеческий язык, вести дискуссии…
Выходные — отличный повод прогуляться! Если вам не хочется бродить по городу бесцельно, можно воспользоваться Sight Safari — сервисом, который умеет прокладывать пешие маршруты так, чтобы пешеход обязательно увидел какую-нибудь местную достопримечательность.
Достопримечательности могут быть как известными на весь мир, как Медный Всадник, так и мемориальной доской, граффити или зениткой в парке. Алгоритм позволяет выбрать золотую середину между кратчайшим пешим маршрутом и насыщенным туром по всем близлежащим возможным интересным местам.
Сервис создан одним единственным человеком на основе геосервиса Open Street Map и абсолютно бесплатен. Только представьте, сколько крутых вещей позволяют сделать открытые данные и немного программирования!
#urban #sysblok
https://telegra.ph/Peshkom--s-umom-11-05
Достопримечательности могут быть как известными на весь мир, как Медный Всадник, так и мемориальной доской, граффити или зениткой в парке. Алгоритм позволяет выбрать золотую середину между кратчайшим пешим маршрутом и насыщенным туром по всем близлежащим возможным интересным местам.
Сервис создан одним единственным человеком на основе геосервиса Open Street Map и абсолютно бесплатен. Только представьте, сколько крутых вещей позволяют сделать открытые данные и немного программирования!
#urban #sysblok
https://telegra.ph/Peshkom--s-umom-11-05
Telegraph
Пешком — с умом
Суббота. Ранний вечер. Вы вышли из бара, где встречались с друзьями, и медленным шагом направились к метро или автобусу. Торопиться некуда, вам в другую сторону от всех остальных, местные переулки вы знаете плохо — самое время спросить дорогу у вашего навигатора…
Жуткие видения робота-психопата
Нейросети на пике хайпа считают чем-то вроде магии. Но на самом деле они, как и всякое машинное обучение, всего лишь алгоритм, который умеет обобщать данные. Именно поэтому так важно, ЧТО за данные поступают на вход... Отличный способ убедиться в этом — познакомиться с Норманом из Массачуссетского технологического института.
Норман — это нейросеть, порождающая текстовые подписи к картинкам. Только обучена она не на обычных данных, а на одном известном сабреддите, посвященном теме смерти, убийств, расчленёнки и прочим мрачным вещам. Назван Норман в честь героя фильма Хичкока «Психо» — маньяка Нормана Бейтса.
Психологическая травма, которую нанесли нейросети её жестокие создатели, видна невооруженным глазом. Для этого достаточно подвергнуть алгоритм старому доброму психологическому тесту Роршаха. Во время теста пациенту показывают чернильные кляксы и просят описать возникающие образы и ассоциации. Считается, что таким образом можно определять эмоциональное состояние и диагностировать некоторые психические отклонения.
Там, где обычный алгоритм видит «стаю птиц», Норман обнаруживает «казнь человека на электрическом стуле»; вместо «пары людей, стоящих рядом» — «разбившаяся на стройке беременная женщина», вместо «черно-белого фото бейсбольной перчатки» — прилюдный расстрел из пулемета, а вместо человека, держащего зонт под дождем — убийство мужчины «на глазах у его кричащей жены».
А наша самая любимая подпись от Нормана — «человека затягивает в миксер для муки». Нормальная нейросеть видит там маленькую птичку.
Посмотреть все подписи можно тут.
Нейросети на пике хайпа считают чем-то вроде магии. Но на самом деле они, как и всякое машинное обучение, всего лишь алгоритм, который умеет обобщать данные. Именно поэтому так важно, ЧТО за данные поступают на вход... Отличный способ убедиться в этом — познакомиться с Норманом из Массачуссетского технологического института.
Норман — это нейросеть, порождающая текстовые подписи к картинкам. Только обучена она не на обычных данных, а на одном известном сабреддите, посвященном теме смерти, убийств, расчленёнки и прочим мрачным вещам. Назван Норман в честь героя фильма Хичкока «Психо» — маньяка Нормана Бейтса.
Психологическая травма, которую нанесли нейросети её жестокие создатели, видна невооруженным глазом. Для этого достаточно подвергнуть алгоритм старому доброму психологическому тесту Роршаха. Во время теста пациенту показывают чернильные кляксы и просят описать возникающие образы и ассоциации. Считается, что таким образом можно определять эмоциональное состояние и диагностировать некоторые психические отклонения.
Там, где обычный алгоритм видит «стаю птиц», Норман обнаруживает «казнь человека на электрическом стуле»; вместо «пары людей, стоящих рядом» — «разбившаяся на стройке беременная женщина», вместо «черно-белого фото бейсбольной перчатки» — прилюдный расстрел из пулемета, а вместо человека, держащего зонт под дождем — убийство мужчины «на глазах у его кричащей жены».
А наша самая любимая подпись от Нормана — «человека затягивает в миксер для муки». Нормальная нейросеть видит там маленькую птичку.
Посмотреть все подписи можно тут.
{kind=link}
Нейросеть-коп раскусит всех
В последние годы в Испании был зафиксирован рост преступлений, связанных с ложными обвинениями. Поскольку это явление создает лишнюю нагрузку на правоохранительные органы, с ним пытаются бороться самыми разными способами. Группа исследователей из Испании разработала для этой цели систему VeriPol, способную проанализировать заявление о преступлении и с высокой степенью точности определить, является ли оно правдой.
«В частности, мы создали VeriPol для краж, хищений, ограблений, сопряженных с насилием и запугиванием свидетелей, поскольку в последние годы возросло число ложных обвинений именно в данной категории преступлений», — уточняет Федерико Либераторе, один из исследователей.
VeriPol представляет собой нейросеть, которую обучают на двух корпусах заявлений о кражах — истинных и ложных. Она выявляет наиболее характерные для каждого из них особенности построения фразы. В 2015 году, например, системе предъявили 1122 заявления (534 истинных и 588 ложных) из уже закрытых дел — только тех, в которых либо преступник был задержан, либо заявитель признался во лжи.
Идея принадлежит инспектору Мигелю Камачо, специалисту в области математики и статистики. Еще в 2012 году он предположил, что искусственный интеллект можно использовать для автоматического выявления маркеров, указывающих на истинность или ложность утверждений. Хотя каждый считает свою ложь уникальной, на самом деле это не так — и нейросеть с легкостью найдет в ложных обвинениях соответствующие паттерны.
Правдивые показания зачастую изобилуют подробностями, тогда как лгун старается их избежать, чтобы потом в них не запутаться. Поэтому одним из наиболее ярких маркеров лжи VeriPol считает дату. Лгун скорее скажет, что преступление имело место «несколько дней назад», «в какой-то день» или «два или три дня назад», а не «вчера» или «в четверг». Заявление с большой долей вероятности оказывается ложью, если заявитель утверждает, что на него напали «сзади» или «со спины» — так он избавляет себя от необходимости описывать детали. Нейросеть выяснила, что выдуманные нападения чаще всего совершают люди «в черном» и что в ложных показаниях чаще, чем в правдивых, встречаются слова «надежный», «адвокат», «мобильный», «айфон», «компания» или «контракт».
VeriPol анализирует также наиболее популярные грамматические и синтаксические средства. Личные и указательные местоимения, а также глаголы «быть» и «находиться» чаще появляются в правдивых показаниях. В этом случае заявитель охотнее рассказывает о том, как произошло преступление, а также говорит о своем «взаимодействии» с преступником. В ложных свидетельствах, наоборот, преобладает неопределенность. Фразы с наречием «едва» — к примеру, «едва видел» или «едва помню», — да и отрицания вроде «не слышал», «не узнал», по статистике, часто указывают на ложь.
Конечно, все приведенные языковые средства только в определенном контексте могут указывать на вероятность лжи. Никто не обвинит человека, который правда не запомнил или не рассмотрел нападавшего. Поэтому VeriPol — это всего лишь один из инструментов в распоряжении правоохранительных органов. «Система напоминает старика-полицейского с колоссальным опытом работы, который просто помогает полиции, указывая, что ему кажется правдой, а что — ложью», — говорит исследователь Лара Кихано.
Проект стартовал в 2014 году, а летом 2017-го VeriPol протестировали сотрудники Национального полицейского корпуса Испании. Тогда было установлено, что система с 91-процентной точностью способна распознать ложь, тогда как эксперту это удается в 75% случаев.
Это первая подобная система, получившая от властей официальное разрешение на использование. В ближайшие месяцы VeriPol планируют внедрить на полицейских участках по всей Испании, потом ее будут адаптировать для других преступлений.
Почитать про исследование по-испански можно здесь.
В последние годы в Испании был зафиксирован рост преступлений, связанных с ложными обвинениями. Поскольку это явление создает лишнюю нагрузку на правоохранительные органы, с ним пытаются бороться самыми разными способами. Группа исследователей из Испании разработала для этой цели систему VeriPol, способную проанализировать заявление о преступлении и с высокой степенью точности определить, является ли оно правдой.
«В частности, мы создали VeriPol для краж, хищений, ограблений, сопряженных с насилием и запугиванием свидетелей, поскольку в последние годы возросло число ложных обвинений именно в данной категории преступлений», — уточняет Федерико Либераторе, один из исследователей.
VeriPol представляет собой нейросеть, которую обучают на двух корпусах заявлений о кражах — истинных и ложных. Она выявляет наиболее характерные для каждого из них особенности построения фразы. В 2015 году, например, системе предъявили 1122 заявления (534 истинных и 588 ложных) из уже закрытых дел — только тех, в которых либо преступник был задержан, либо заявитель признался во лжи.
Идея принадлежит инспектору Мигелю Камачо, специалисту в области математики и статистики. Еще в 2012 году он предположил, что искусственный интеллект можно использовать для автоматического выявления маркеров, указывающих на истинность или ложность утверждений. Хотя каждый считает свою ложь уникальной, на самом деле это не так — и нейросеть с легкостью найдет в ложных обвинениях соответствующие паттерны.
Правдивые показания зачастую изобилуют подробностями, тогда как лгун старается их избежать, чтобы потом в них не запутаться. Поэтому одним из наиболее ярких маркеров лжи VeriPol считает дату. Лгун скорее скажет, что преступление имело место «несколько дней назад», «в какой-то день» или «два или три дня назад», а не «вчера» или «в четверг». Заявление с большой долей вероятности оказывается ложью, если заявитель утверждает, что на него напали «сзади» или «со спины» — так он избавляет себя от необходимости описывать детали. Нейросеть выяснила, что выдуманные нападения чаще всего совершают люди «в черном» и что в ложных показаниях чаще, чем в правдивых, встречаются слова «надежный», «адвокат», «мобильный», «айфон», «компания» или «контракт».
VeriPol анализирует также наиболее популярные грамматические и синтаксические средства. Личные и указательные местоимения, а также глаголы «быть» и «находиться» чаще появляются в правдивых показаниях. В этом случае заявитель охотнее рассказывает о том, как произошло преступление, а также говорит о своем «взаимодействии» с преступником. В ложных свидетельствах, наоборот, преобладает неопределенность. Фразы с наречием «едва» — к примеру, «едва видел» или «едва помню», — да и отрицания вроде «не слышал», «не узнал», по статистике, часто указывают на ложь.
Конечно, все приведенные языковые средства только в определенном контексте могут указывать на вероятность лжи. Никто не обвинит человека, который правда не запомнил или не рассмотрел нападавшего. Поэтому VeriPol — это всего лишь один из инструментов в распоряжении правоохранительных органов. «Система напоминает старика-полицейского с колоссальным опытом работы, который просто помогает полиции, указывая, что ему кажется правдой, а что — ложью», — говорит исследователь Лара Кихано.
Проект стартовал в 2014 году, а летом 2017-го VeriPol протестировали сотрудники Национального полицейского корпуса Испании. Тогда было установлено, что система с 91-процентной точностью способна распознать ложь, тогда как эксперту это удается в 75% случаев.
Это первая подобная система, получившая от властей официальное разрешение на использование. В ближайшие месяцы VeriPol планируют внедрить на полицейских участках по всей Испании, потом ее будут адаптировать для других преступлений.
Почитать про исследование по-испански можно здесь.
{kind=link}
Когда появилась машинная поэзия и в чем особенности стихов, созданных именно нейросетями? Чем такая поэзия отличается от авторской? Представляет ли она какую-нибудь ценность для литературоведения? И так ли легко определить, что написано человеком, а что — алгоритмом?
Ответы на эти и другие вопросы в нашем сегодняшнем лонгриде о нейросетевой поэзии и смерти автора.
#knowhow #neuropoetry #sysblok
https://telegra.ph/Nejroseti-i-smert-avtora-11-14
Ответы на эти и другие вопросы в нашем сегодняшнем лонгриде о нейросетевой поэзии и смерти автора.
#knowhow #neuropoetry #sysblok
https://telegra.ph/Nejroseti-i-smert-avtora-11-14
Telegraph
Нейросети и смерть автора
Если заходит разговор о нейросетевой генерации стихов, эрудированные люди сразу вспоминают множественные прецеденты машинной поэзии из прошлого. Все думают, что компьютер сочинял стихи уже тысячу лет (ну ладно, не тысячу, но такие опыты и правда ставились…
Вас обслуживает Искусственный Интеллект
В последние годы банковская отрасль особенно заинтересовалась продуктами искусственного интеллекта. Практически каждая большая консалтинговая компания уже провела и опубликовала исследование о будущем влиянии ИИ на банковский сектор, а на разработки в этой области направлено огромное количество инвестиций. Одновременно усиливаются и опасения, что новые технологии снизят спрос на человеческий труд.
Суть проста: если банк может позволить себе автоматизировать какой-то процесс, ему больше не нужно нанимать на эту должность людей.
Например, 10 лет назад с распространением информационных технологий профессия представителя компании стала менее востребованной, многие отделы закрылись. По тому же принципу банки теперь внедряют в сферу обслуживания продукты ИИ. По данным Consultancy.uk на 2017 год, 30,8% всех финансовых организаций используют искусственный интеллект при работе с клиентами.
Некоторые крупные банки разработали чат-ботов и виртуальных ассистентов на основе искусственного интеллекта. Например, J.P.Morgan Chase (первое место в США по общей сумме вкладов) c помощью ИИ отвечает на вопросы клиентов и прогнозирует их финансовые потребности. А виртуальный ассистент UBS (швейцарского инвестиционного банка, который в 2018 занял первое место в рейтинге лучших частных банков мира) работает по принципу Amazon Alexa. Скорее всего, именно эти алгоритмы займут рабочие места живых людей. Чем больше их применяют, тем больше они учатся, а значит, с каждым днем они все лучше обслуживают клиентов без помощи менеджеров.
Крупнейшие банки применяют системы искусственного интеллекта, чтобы выслеживать мошенников или операции по отмыванию денег. Это действительно работает: следователи тратят намного меньше времени на ложные положительные срабатывания (например, если клиент заходит в онлайн-банк с адресов из разных стран в течение дня — это подозрительно, и служба безопасности может заблокировать его аккаунт до выяснения обстоятельств). В этом смысле алгоритмы ИИ не столько позволяют сэкономить на рабочих местах, сколько дают следователям больше времени на детальное изучение настоящих преступлений.
Есть банки, которые используют ИИ в алгоритмической торговле (совершение сделок с помощью торговых роботов). Еще машинное обучение используется для персонализации обслуживания: клиентам предлагают услуги, приспособленные под их нужды..
Банки также используют ИИ в управлении рисками. Современные алгоритмы пока не способны принимать решения за людей, но искусственный интеллект упорядочивает сам процесс: снижает субъективность и улучшает конечный результат как для организаций, так и для клиентов, не лишая работников должности.
Так, рано или поздно внедрение ИИ в банковскую отрасль приведет к сокращению определенных позиций. Но это не значит, что систему ждет переворот, при котором сокращения будут массовыми. Искусственный интеллект может по-другому помочь отрасли: например, сняв с людей мелкие рутинные задачи, он позволяет эффективнее отслеживать действительно преступления по отмыванию денег. А передача умным чат-ботам типовых запросов дает возможность повысить качество клиентского обслуживания.
В последние годы банковская отрасль особенно заинтересовалась продуктами искусственного интеллекта. Практически каждая большая консалтинговая компания уже провела и опубликовала исследование о будущем влиянии ИИ на банковский сектор, а на разработки в этой области направлено огромное количество инвестиций. Одновременно усиливаются и опасения, что новые технологии снизят спрос на человеческий труд.
Суть проста: если банк может позволить себе автоматизировать какой-то процесс, ему больше не нужно нанимать на эту должность людей.
Например, 10 лет назад с распространением информационных технологий профессия представителя компании стала менее востребованной, многие отделы закрылись. По тому же принципу банки теперь внедряют в сферу обслуживания продукты ИИ. По данным Consultancy.uk на 2017 год, 30,8% всех финансовых организаций используют искусственный интеллект при работе с клиентами.
Некоторые крупные банки разработали чат-ботов и виртуальных ассистентов на основе искусственного интеллекта. Например, J.P.Morgan Chase (первое место в США по общей сумме вкладов) c помощью ИИ отвечает на вопросы клиентов и прогнозирует их финансовые потребности. А виртуальный ассистент UBS (швейцарского инвестиционного банка, который в 2018 занял первое место в рейтинге лучших частных банков мира) работает по принципу Amazon Alexa. Скорее всего, именно эти алгоритмы займут рабочие места живых людей. Чем больше их применяют, тем больше они учатся, а значит, с каждым днем они все лучше обслуживают клиентов без помощи менеджеров.
Крупнейшие банки применяют системы искусственного интеллекта, чтобы выслеживать мошенников или операции по отмыванию денег. Это действительно работает: следователи тратят намного меньше времени на ложные положительные срабатывания (например, если клиент заходит в онлайн-банк с адресов из разных стран в течение дня — это подозрительно, и служба безопасности может заблокировать его аккаунт до выяснения обстоятельств). В этом смысле алгоритмы ИИ не столько позволяют сэкономить на рабочих местах, сколько дают следователям больше времени на детальное изучение настоящих преступлений.
Есть банки, которые используют ИИ в алгоритмической торговле (совершение сделок с помощью торговых роботов). Еще машинное обучение используется для персонализации обслуживания: клиентам предлагают услуги, приспособленные под их нужды..
Банки также используют ИИ в управлении рисками. Современные алгоритмы пока не способны принимать решения за людей, но искусственный интеллект упорядочивает сам процесс: снижает субъективность и улучшает конечный результат как для организаций, так и для клиентов, не лишая работников должности.
Так, рано или поздно внедрение ИИ в банковскую отрасль приведет к сокращению определенных позиций. Но это не значит, что систему ждет переворот, при котором сокращения будут массовыми. Искусственный интеллект может по-другому помочь отрасли: например, сняв с людей мелкие рутинные задачи, он позволяет эффективнее отслеживать действительно преступления по отмыванию денег. А передача умным чат-ботам типовых запросов дает возможность повысить качество клиентского обслуживания.
{kind=link}
Второе пришествие кокаина: наркостатистика в Google Books
Наркотики, как и кинозвезды, имеют свои моменты популярности — и забвения.
Как узнать, когда случился «звездный час» марихуаны? Конечно, с помощью анализа огромного корпуса текстов, протяженного во времени. Самый большой из доступных — Google Books (более 500 миллиардов слов). Используем интерфейс Google Ngram Viewer для анализа частотности употребления названий основных наркотиков.
Рубеж XIX — XX веков — эпоха кокаина. Это конец Викторианской эры, декаданс начала XX века, экзальтированные дамы увлекаются спиритизмом... Кокаин хвалят ярчайшие писатели и интеллектуалы: Жюль Верн, Эмиль Золя, Томас Эдисон, Генрик Ибсен, Зигмунд Фрейд. Даже главный герой эпохи, Шерлок Холмс, — открытый кокаинист.
Изобретенный тогда же героин долго считался безопасным средством от кашля и продавался без рецепта. Фармкомпании гребли прибыль, а правительства заподозрили неладное и начали запрещать его только к середине 1920-х, когда на героине сидела половина звезд джаза и толпы их поклонников. Переток от кокаиновой наркомании к героиновой отражается в текстах.
Традиционный морфий, на замену которому и пришел героин, становится сверхактуален во время Второй мировой — конечно, не как наркотик, а как обезболивающее.
А вскоре после войны наступает эпоха хиппи — и в 60-е мы наблюдаем настоящий наркотический взрыв. Особенно резко взлетает частотность марихуаны. Следом подтягиваются только что изобретенные синтетические наркотики — ЛСД и (чуть позже) амфетамины. Подскакивает и героин — теперь вместо джазменов на нем сидят рокеры, а вот дедовский кокаин уже не моден и уходит в тень. Его возрождение (и это отлично видно на графике!) случится к 80-м. Кокаин теперь — престижный наркотик для «белых воротничков». И вот уже нью-йоркские юристы в ультрадорогих пентхаусах делят дорожки белого порошка с помощью золотых кредиток, а поставляющая им наркотики латиноамериканская мафия переживает небывалый расцвет (см. игру GTA Vice City и прочую массовую культуру про американские 80-е).
Наркотики, как и кинозвезды, имеют свои моменты популярности — и забвения.
Как узнать, когда случился «звездный час» марихуаны? Конечно, с помощью анализа огромного корпуса текстов, протяженного во времени. Самый большой из доступных — Google Books (более 500 миллиардов слов). Используем интерфейс Google Ngram Viewer для анализа частотности употребления названий основных наркотиков.
Рубеж XIX — XX веков — эпоха кокаина. Это конец Викторианской эры, декаданс начала XX века, экзальтированные дамы увлекаются спиритизмом... Кокаин хвалят ярчайшие писатели и интеллектуалы: Жюль Верн, Эмиль Золя, Томас Эдисон, Генрик Ибсен, Зигмунд Фрейд. Даже главный герой эпохи, Шерлок Холмс, — открытый кокаинист.
Изобретенный тогда же героин долго считался безопасным средством от кашля и продавался без рецепта. Фармкомпании гребли прибыль, а правительства заподозрили неладное и начали запрещать его только к середине 1920-х, когда на героине сидела половина звезд джаза и толпы их поклонников. Переток от кокаиновой наркомании к героиновой отражается в текстах.
Традиционный морфий, на замену которому и пришел героин, становится сверхактуален во время Второй мировой — конечно, не как наркотик, а как обезболивающее.
А вскоре после войны наступает эпоха хиппи — и в 60-е мы наблюдаем настоящий наркотический взрыв. Особенно резко взлетает частотность марихуаны. Следом подтягиваются только что изобретенные синтетические наркотики — ЛСД и (чуть позже) амфетамины. Подскакивает и героин — теперь вместо джазменов на нем сидят рокеры, а вот дедовский кокаин уже не моден и уходит в тень. Его возрождение (и это отлично видно на графике!) случится к 80-м. Кокаин теперь — престижный наркотик для «белых воротничков». И вот уже нью-йоркские юристы в ультрадорогих пентхаусах делят дорожки белого порошка с помощью золотых кредиток, а поставляющая им наркотики латиноамериканская мафия переживает небывалый расцвет (см. игру GTA Vice City и прочую массовую культуру про американские 80-е).
{kind=link}
Что читать современному лингвисту/филологу?
Мы уже рассказывали о каналах, которые будут интересны современным лингвистам и филологам и которые мы с удовольствием читаем сами. Во второй части нашего обзора — семь лингвистических каналов, один литературный и три переводческих.
— @glazslov — Глазарий языка
Все важное и неважное о русском языке и не только. Откуда в «Лиге плюща» взялся плющ? Когда в русском языке появилась современная терминология арифметики и геометрии? Сколько в немецком языке пословиц о колбасе? Как отогнать свинью на Кубани и овцу в Смоленске? Что такое «автожир» и «пейсмейкер»?
— @wordsofsnow — мамкина ленгвистка
Ненастоящая лингвистка Соня рассказывает разные интересные штуки про языки — про то, как заикаются на разных языках, про братскую судьбу русского «хер» и ивритского «зайн», про карго-Иисуса Миклухо Маклая и русские заимствования в папуасских языках and what not.
— @superprikladnayalinguistika — Супер прикладная лингвистика
Аспирантка Мюнстерского университета Аня пишет об экспериментальной лингвистике, современных методах анализа лингвистических данных и трендах в исследованиях. Если хотите узнать о когнитивной, компьютерной, судебной, клинической, эволюционной и ещё много какой лингвистике, вам сюда!
— @Lingvoed — Lingvoed
Преподаватель русского языка как иностранного задаёт непростые лингвистические загадки на знание самых разных языков, делится тонкостями своей профессии и рассказывает байки из преподавательской жизни.
— @franrusse — бонжур ёбта
Канал преподавательницы русского как иностранного и французского из Лиона. Истории из жизни, любопытные наблюдения о языке, экскурсы в страноведение и перлы учеников.
— @lingvovesti — Лингвовести: языки и лингвистика
Новости о языках, языковой политике и событиях из мира лингвистики, а также анонсы открытых познавательных мероприятий на эту тему в Санкт-Петербурге и Москве.
— @gzombify — Гзом
Канал о тонкостях и пунктирностях русского языка, грамматике и стилистике, работе редактора и работе мозга, заморских и уже не очень словах — затейливо, с внятной аргументацией и без занудства.
— @slowlearner — I'm Writing a Novel
Жизнь, мнения и сентиментальное путешествие Игоря Кириенкова. Гуманитарный нон-фикшн, филологический взгляд на кино, литературные премии и открытые дискуссии о книгах — в общем, всё, что находится в поле филологии, но вне фокуса.
— @breat_gritain — Сюрдоперевод
Канал о переводческих ляпах и о том, как с ними бороться, с примерами из реальной практики редактора переводов. И просто посмеяться, и набраться бесценного опыта.
— @interpreteratwork — interpreter at work
Канал о буднях устного переводчика. Просто представьте, что вам нужно сходу перевести текст, где встречаются отливка алюминия, накладные волосы, тукан, клапан для надувания секс-игрушки, жёлтая пресса, викторианский корсет, ксилофон и голенища.
— @mamlingvist — Tsundoku-sempai
Канал о переводах, локализации видеоигр и тяготах фриланса. Как работать с вымышленными вселенными, не видя их? Что такое аудиодескрипция? Переводчики — герои или негодяи, которые портят любимые фильмы?
Обзор подготовлен редакцией канала о культуре в век цифры «Системный Блокъ» @sysblok.
Мы уже рассказывали о каналах, которые будут интересны современным лингвистам и филологам и которые мы с удовольствием читаем сами. Во второй части нашего обзора — семь лингвистических каналов, один литературный и три переводческих.
— @glazslov — Глазарий языка
Все важное и неважное о русском языке и не только. Откуда в «Лиге плюща» взялся плющ? Когда в русском языке появилась современная терминология арифметики и геометрии? Сколько в немецком языке пословиц о колбасе? Как отогнать свинью на Кубани и овцу в Смоленске? Что такое «автожир» и «пейсмейкер»?
— @wordsofsnow — мамкина ленгвистка
Ненастоящая лингвистка Соня рассказывает разные интересные штуки про языки — про то, как заикаются на разных языках, про братскую судьбу русского «хер» и ивритского «зайн», про карго-Иисуса Миклухо Маклая и русские заимствования в папуасских языках and what not.
— @superprikladnayalinguistika — Супер прикладная лингвистика
Аспирантка Мюнстерского университета Аня пишет об экспериментальной лингвистике, современных методах анализа лингвистических данных и трендах в исследованиях. Если хотите узнать о когнитивной, компьютерной, судебной, клинической, эволюционной и ещё много какой лингвистике, вам сюда!
— @Lingvoed — Lingvoed
Преподаватель русского языка как иностранного задаёт непростые лингвистические загадки на знание самых разных языков, делится тонкостями своей профессии и рассказывает байки из преподавательской жизни.
— @franrusse — бонжур ёбта
Канал преподавательницы русского как иностранного и французского из Лиона. Истории из жизни, любопытные наблюдения о языке, экскурсы в страноведение и перлы учеников.
— @lingvovesti — Лингвовести: языки и лингвистика
Новости о языках, языковой политике и событиях из мира лингвистики, а также анонсы открытых познавательных мероприятий на эту тему в Санкт-Петербурге и Москве.
— @gzombify — Гзом
Канал о тонкостях и пунктирностях русского языка, грамматике и стилистике, работе редактора и работе мозга, заморских и уже не очень словах — затейливо, с внятной аргументацией и без занудства.
— @slowlearner — I'm Writing a Novel
Жизнь, мнения и сентиментальное путешествие Игоря Кириенкова. Гуманитарный нон-фикшн, филологический взгляд на кино, литературные премии и открытые дискуссии о книгах — в общем, всё, что находится в поле филологии, но вне фокуса.
— @breat_gritain — Сюрдоперевод
Канал о переводческих ляпах и о том, как с ними бороться, с примерами из реальной практики редактора переводов. И просто посмеяться, и набраться бесценного опыта.
— @interpreteratwork — interpreter at work
Канал о буднях устного переводчика. Просто представьте, что вам нужно сходу перевести текст, где встречаются отливка алюминия, накладные волосы, тукан, клапан для надувания секс-игрушки, жёлтая пресса, викторианский корсет, ксилофон и голенища.
— @mamlingvist — Tsundoku-sempai
Канал о переводах, локализации видеоигр и тяготах фриланса. Как работать с вымышленными вселенными, не видя их? Что такое аудиодескрипция? Переводчики — герои или негодяи, которые портят любимые фильмы?
Обзор подготовлен редакцией канала о культуре в век цифры «Системный Блокъ» @sysblok.
Telegram
Системный Блокъ
Что читать современному лингвисту/филологу?
Телеграм стал площадкой для нишевых сообществ с уникальным контентом. Мы будем рассказывать о каналах, которые читаем сами. В нашем первом обзоре — четыре канала о лингвистике, четыре канала о литературе и два…
Телеграм стал площадкой для нишевых сообществ с уникальным контентом. Мы будем рассказывать о каналах, которые читаем сами. В нашем первом обзоре — четыре канала о лингвистике, четыре канала о литературе и два…